Presentado el 28 de Julio 2020 para Elixir Developers México
https://www.youtube.com/watch?v=sYFwwIV3T1Q AGENDA
Manejo de errores en elixir.
Herramientas de recuperación de errores.
Conceptos de OO.
DoC.
Excepciones.
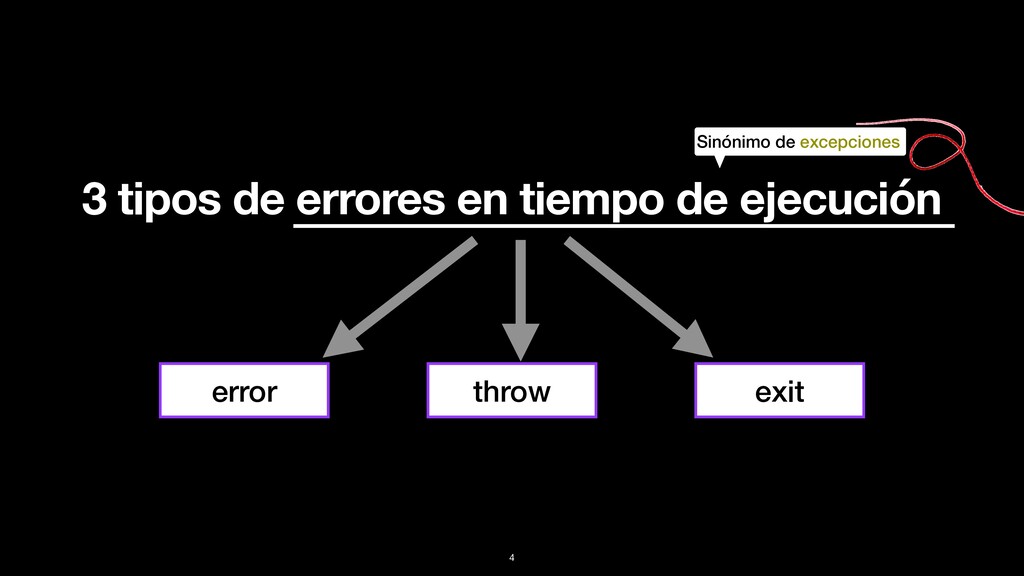
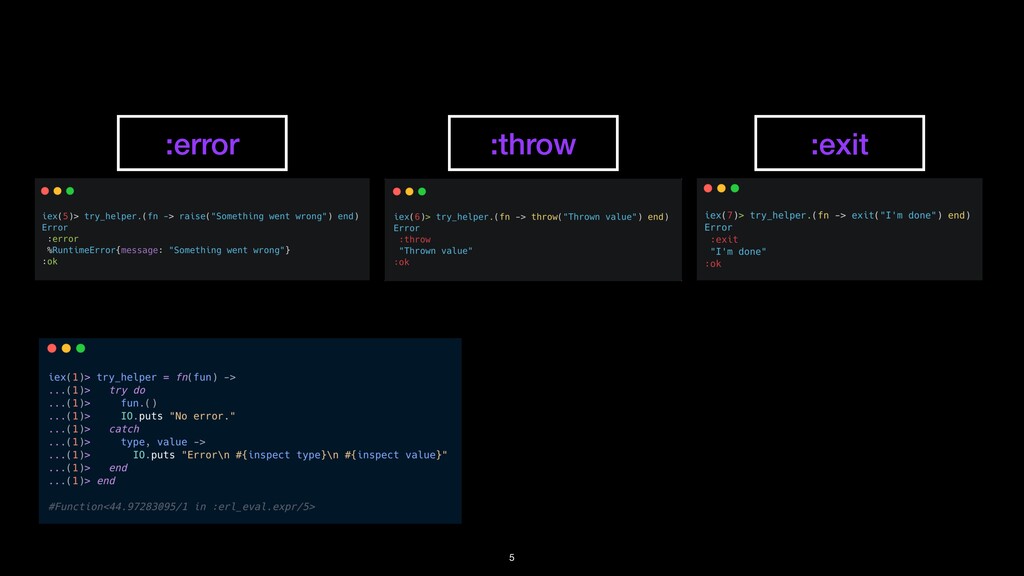
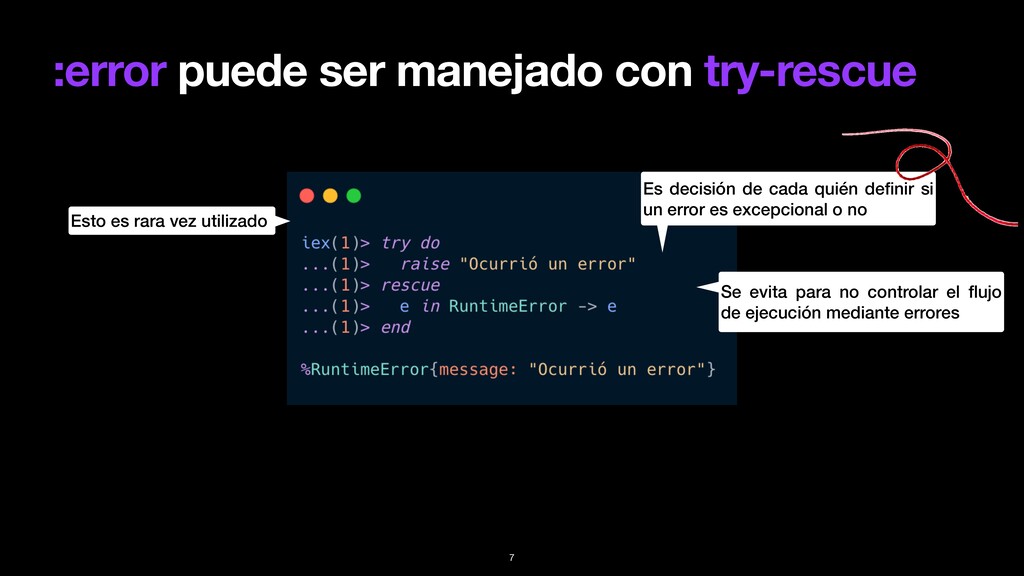
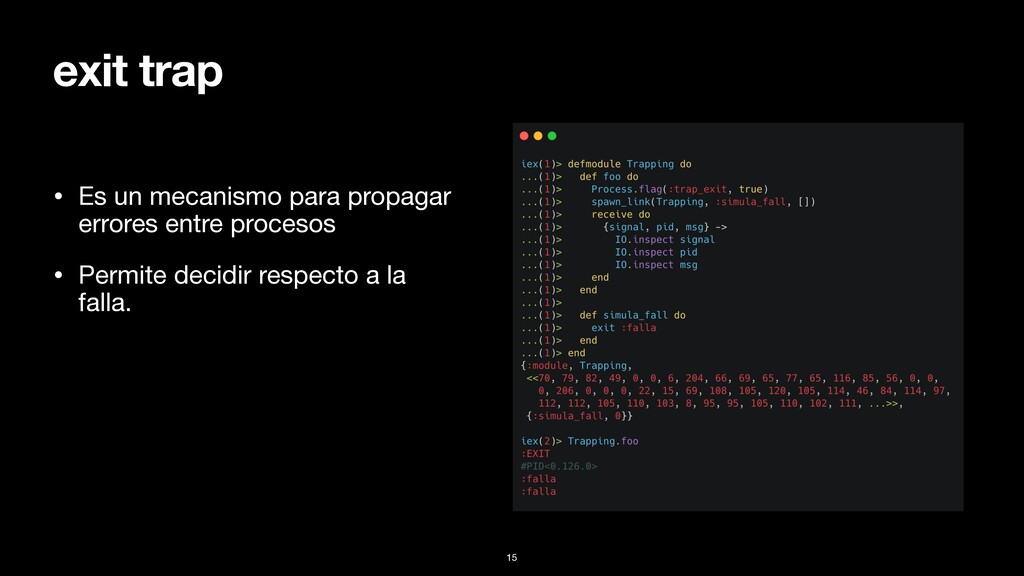
pasa. • Para crearlo se utiliza la macro: raise/1 • Podemos crear nuestros propios errores con: defexception • Pueden ser rescatados utilizando: try-rescue 6
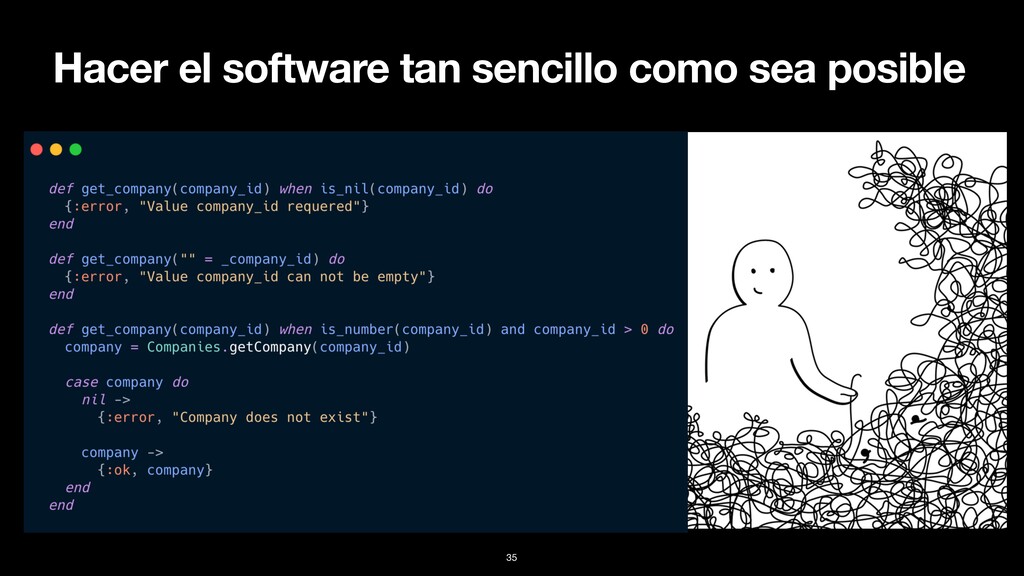
situación considerada realmente un caso excepcional, se debe utilizar la función con el carácter “!” Es común encontrar: 1. File.read 2. File.read! ¿Debo tener 2 versiones de las funciones en mi código siempre? 9
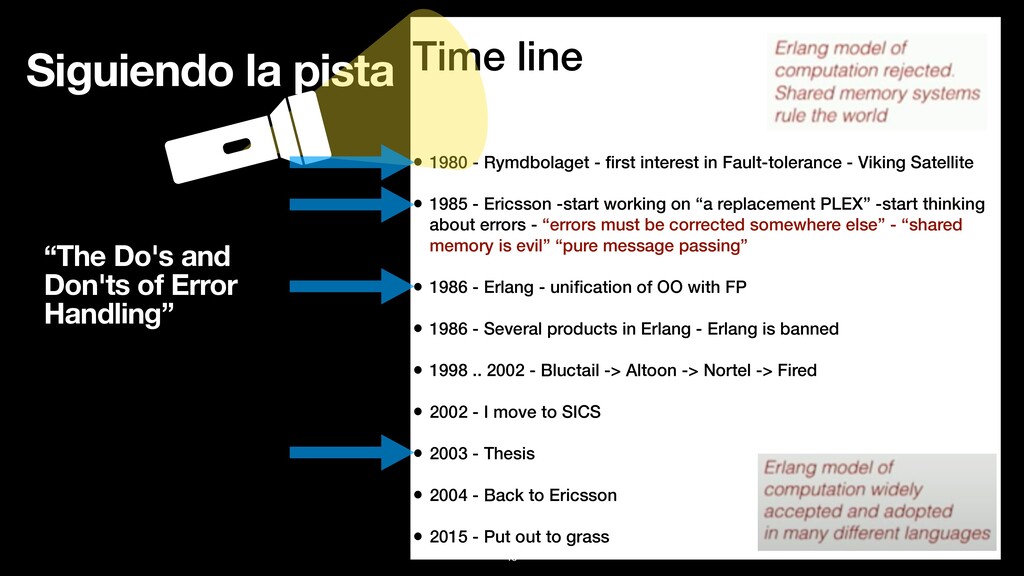
Fault-tolerance - Viking Satellite • 1985 - Ericsson -start working on “a replacement PLEX” -start thinking about errors - “errors must be corrected somewhere else” - “shared memory is evil” “pure message passing” • 1986 - Erlang - unification of OO with FP • 1986 - Several products in Erlang - Erlang is banned • 1998 .. 2002 - Bluctail -> Altoon -> Nortel -> Fired • 2002 - I move to SICS • 2003 - Thesis • 2004 - Back to Ericsson • 2015 - Put out to grass “The Do's and Don'ts of Error Handling” Siguiendo la pista 18
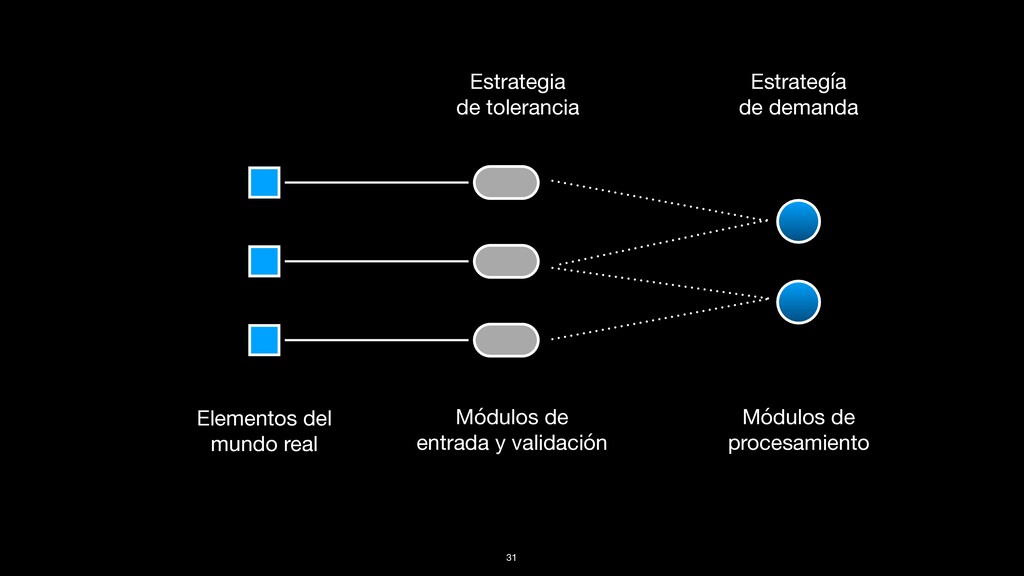
tener para ser tolerante a fallas • Concurrencia • Encapsulamiento de errores • Detección de fallas • Identificación de fallas • Actualización de código • Almacenamiento estable 20
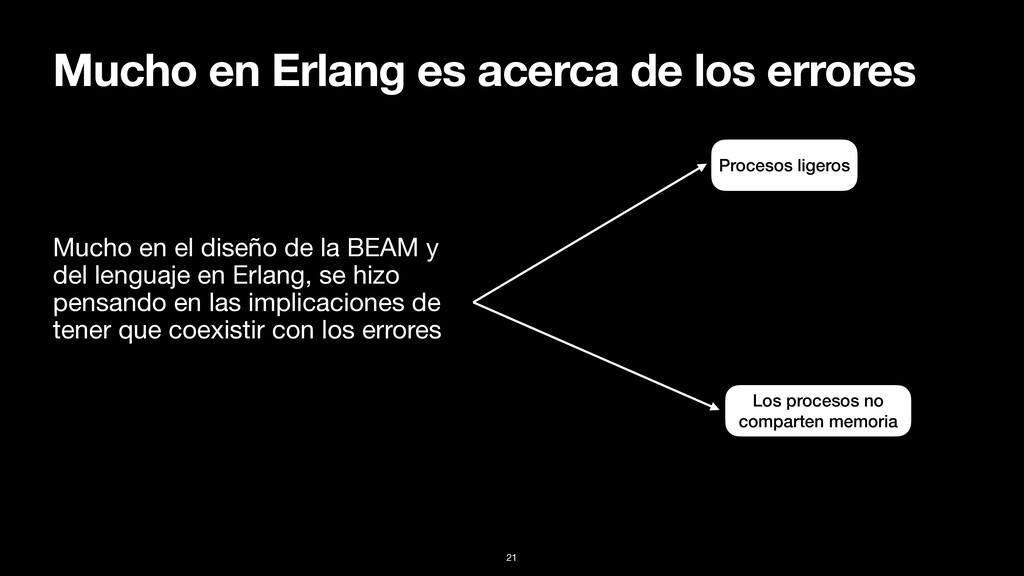
en Erlang, se hizo pensando en las implicaciones de tener que coexistir con los errores Procesos ligeros Los procesos no comparten memoria Mucho en Erlang es acerca de los errores 21
realicen la recuperación de un error. • Si como proceso, no puedes completar tu objetivo, entonces: ¡muere! • Déjalo fallar • No programes defensivamente 22
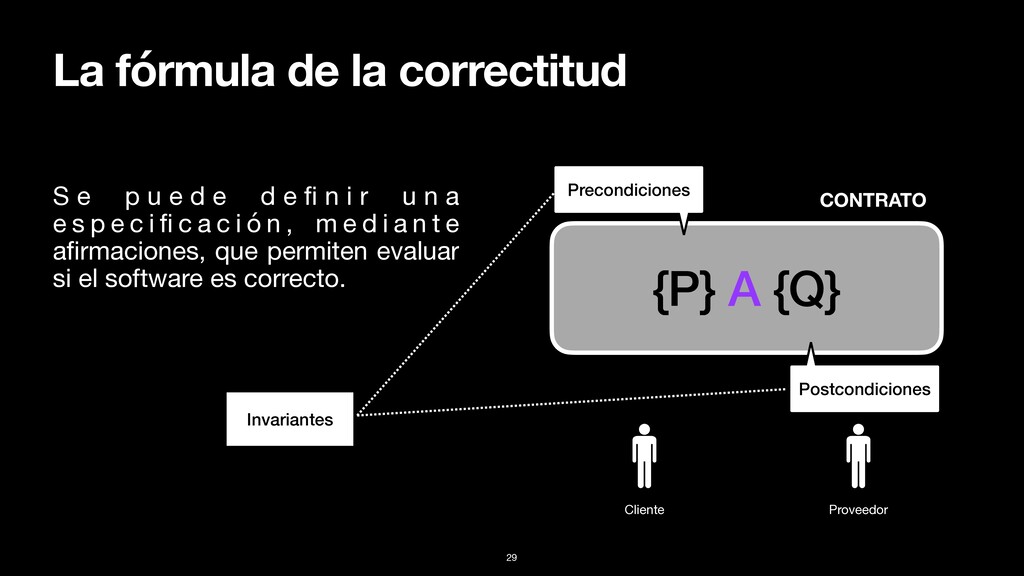
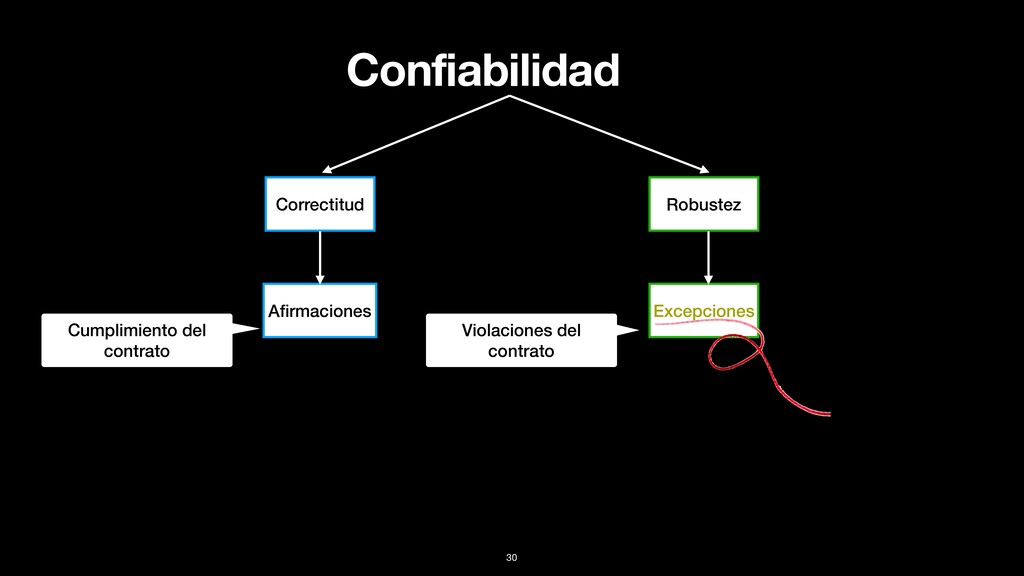
CONTRATO S e p u e d e d e fi n i r u n a e s p e c i fi c a c i ó n , m e d i a n t e afirmaciones, que permiten evaluar si el software es correcto. Invariantes 29 Proveedor Cliente
y de soluciones futuras. • Facilita la tarea de documentar. • Proporciona las bases para pruebas sistemáticas. ¿TDD? • Producir software que es presumiblemente consistente con su especificación, porque fue diseñado desde el inicio para serlo y además puede demostrar que lo es. 32
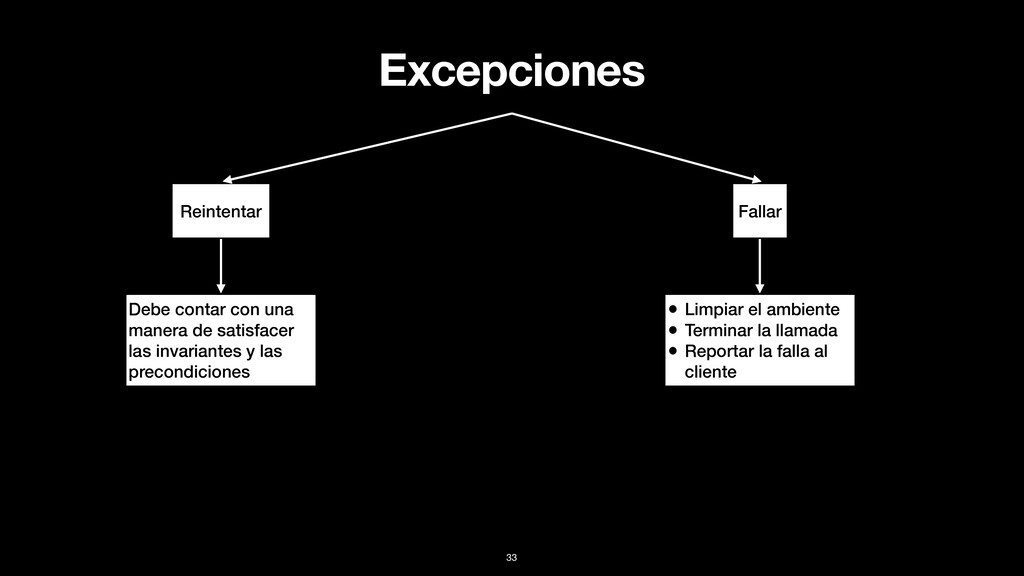
Fallar rápido • Registrar el error en la bitácora • Agregar información que permita identificar el error • Hacer un re-intento • Cumplir con las invariantes + las precondiciones • Intentar hacer algo más simple 36
No hacer programación defensiva • Hacer pruebas automatizadas • Usar “property based testing” es una manera de utilizar las invariantes • Poner atención al diseño • Aplicar los conceptos de DoC • Dejar que alguien más resuelva el error: como la estructura de nuestro árbol de supervisión. • Revisar las referencias de esta plática 37
watch?v=TTM_b7EJg5E 2. Tesis de Joe: http://erlang.org/download/ armstrong_thesis_2003.pdf 3. The zen of erlang: https://ferd.ca/the-zen-of-erlang.html 4. Let it crash meets it shouldn’t crash: https://www.youtube.com/ watch?v=OcbE6nL1QEk 5. Guía de inicio de elixir para: try, catch y rescue https://elixir- lang.org/getting-started/try-catch-and-rescue.html 6. Object Orientes Software Construction Bertrand Meyer 39
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}