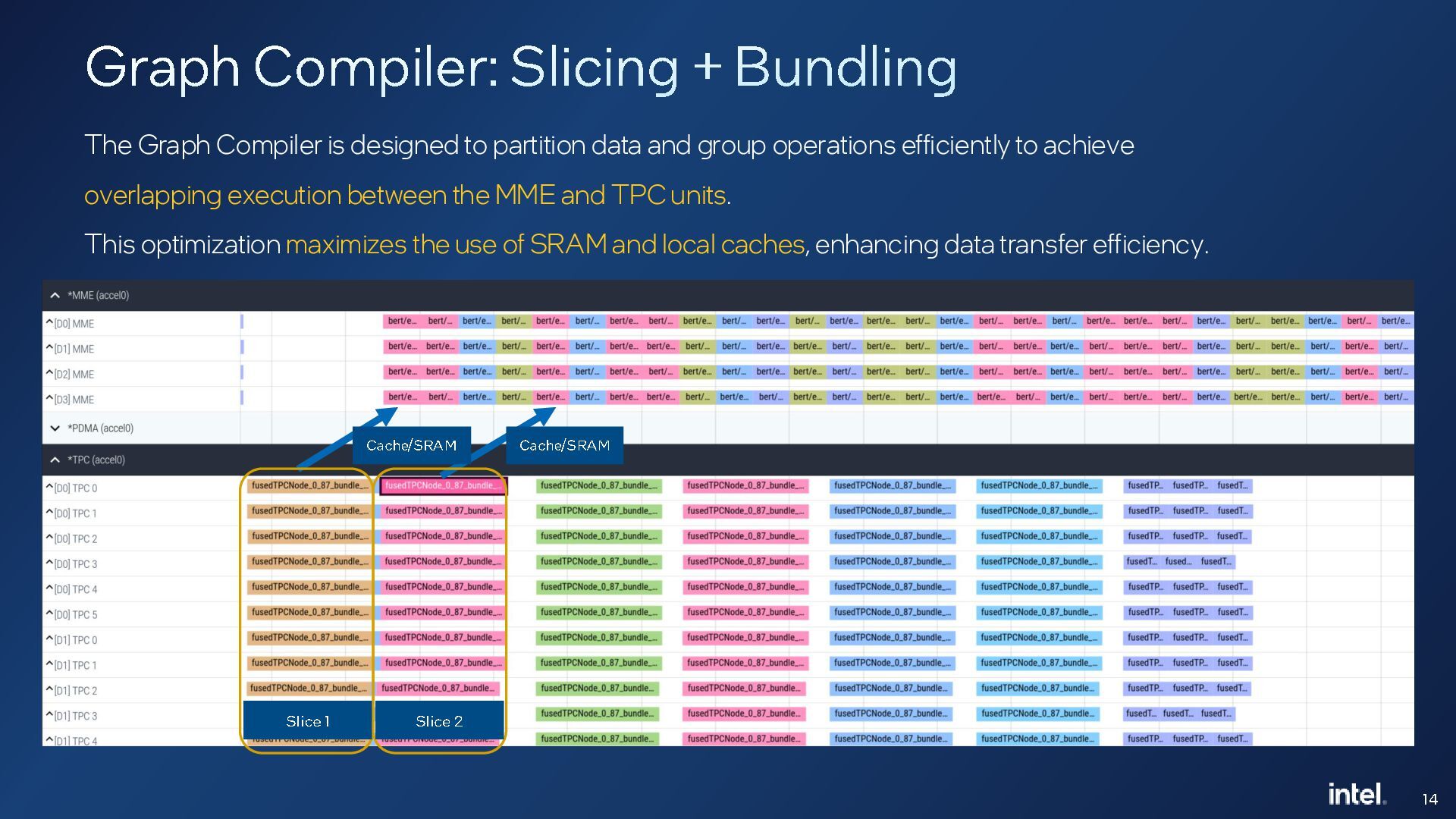
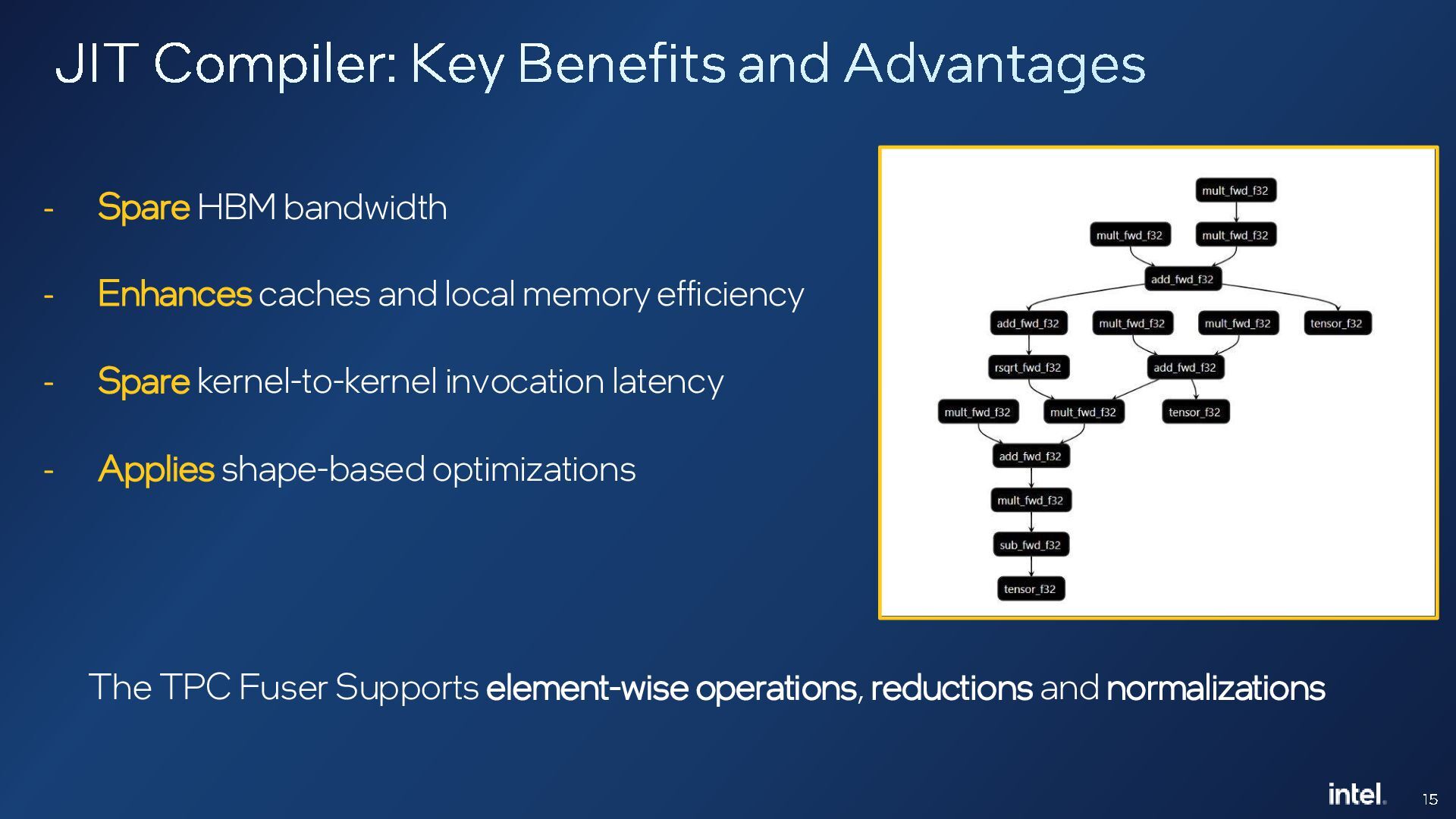
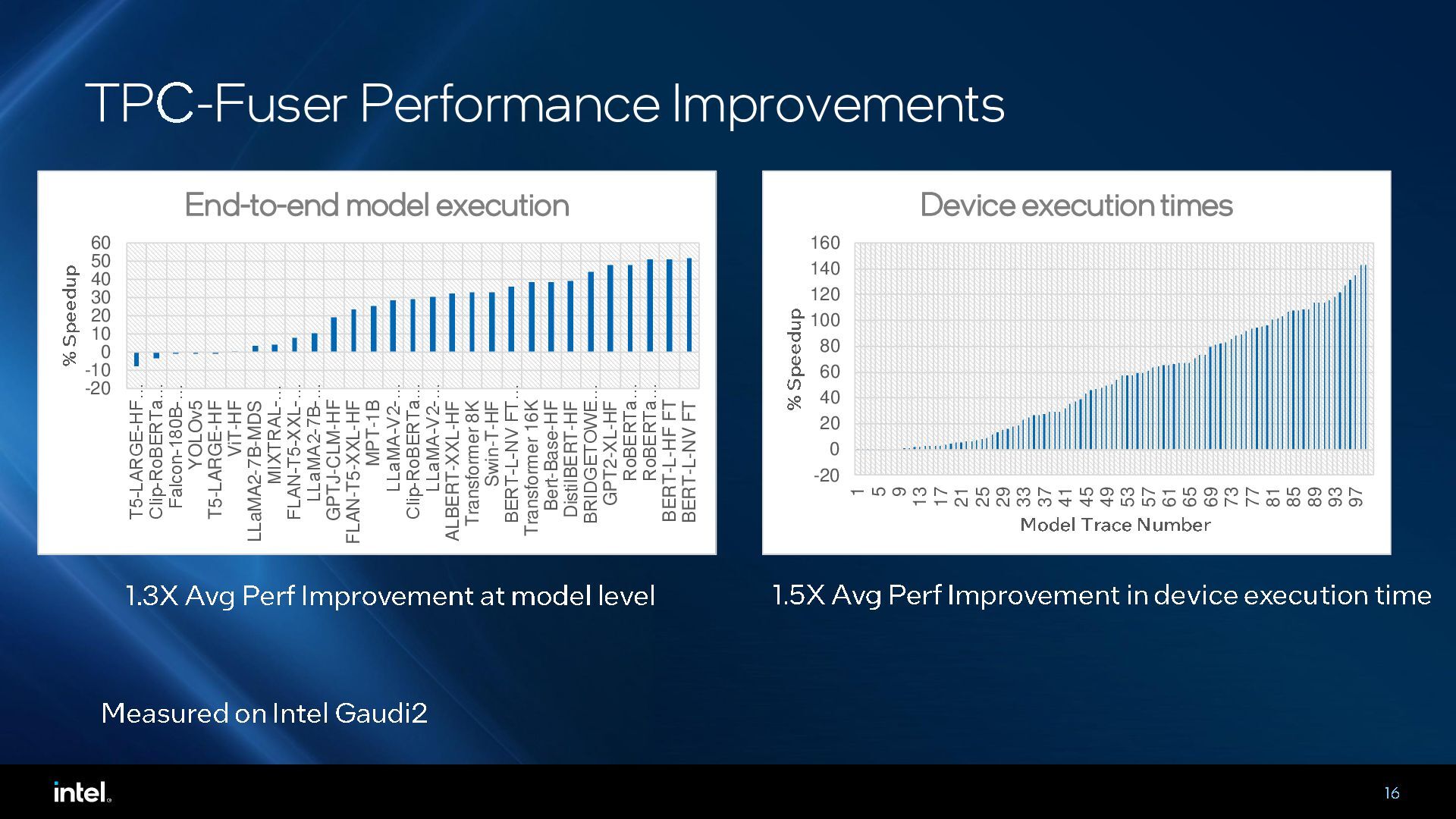
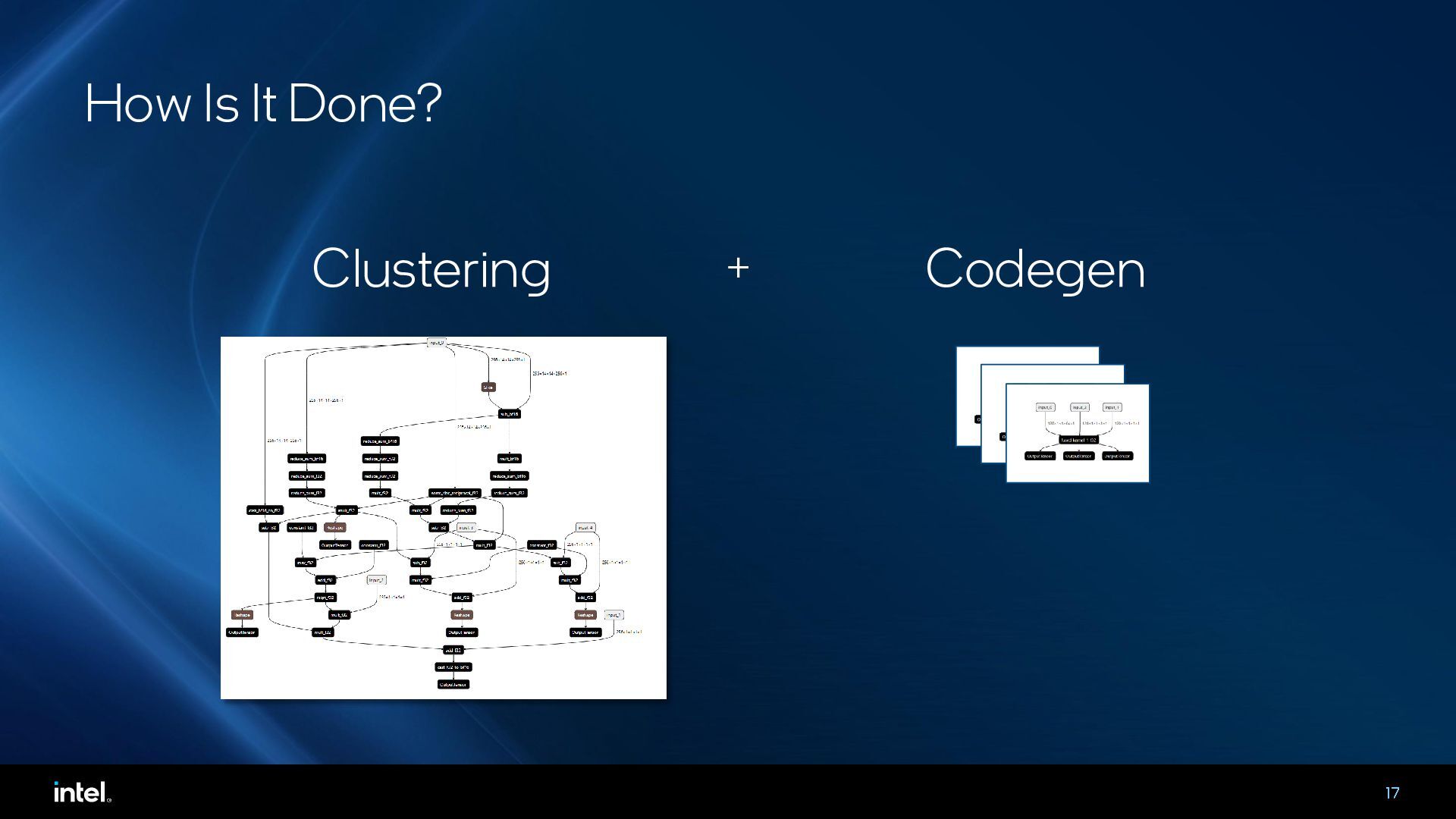
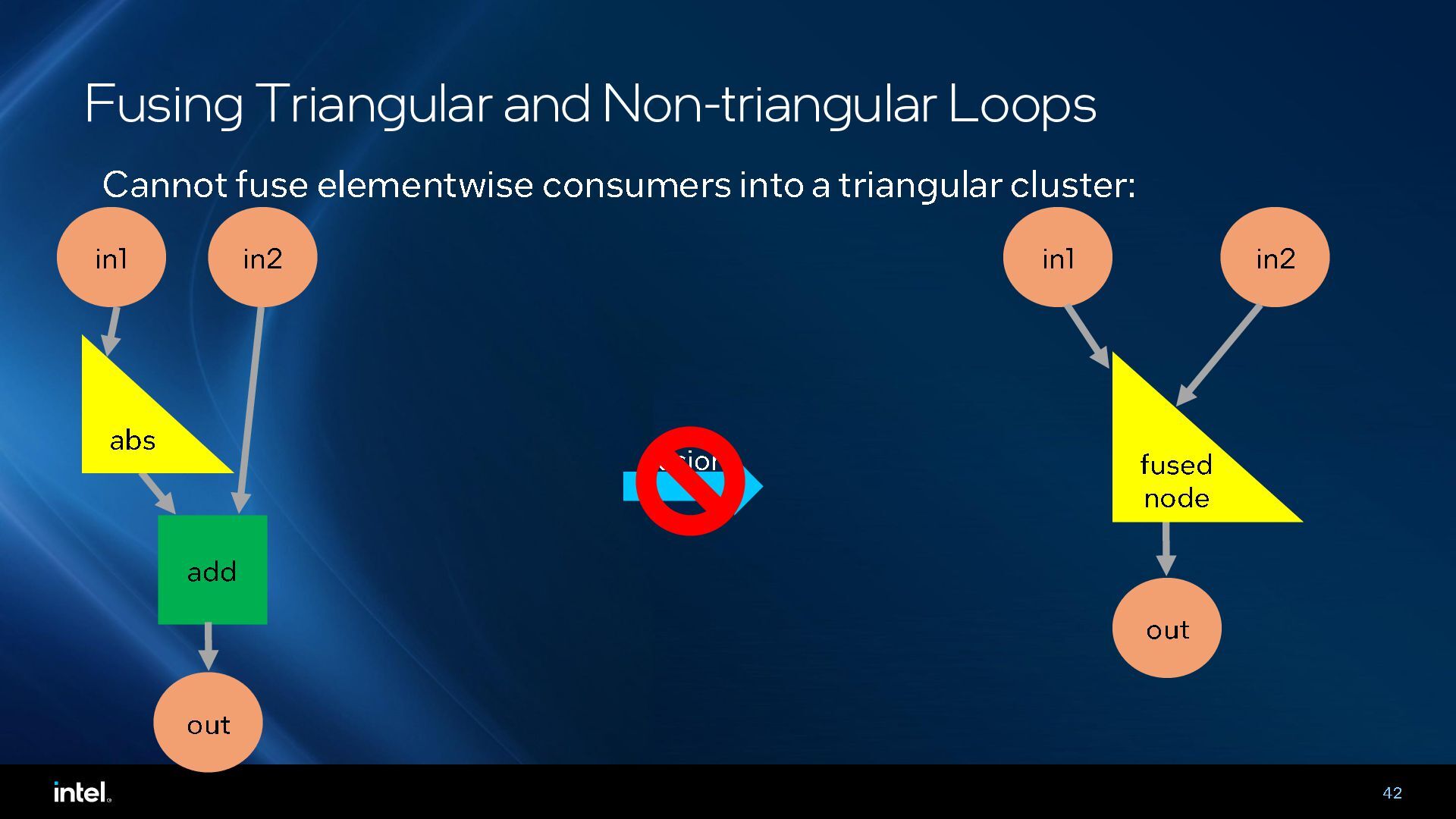
Middle-end optimizations play a critical role in generating high-performance code for deep learning accelerators. In this talk, we will present an MLIR-based fusing compiler that generates optimized LLVM IR from high-level graph IR, which is then compiled by an LLVM backend for execution on tensor processing cores in Intel Gaudi deep learning (DL) accelerator. This compiler has been in use for the past three generations of Gaudi products and provides around 54% average performance improvements at a model-level. The talk will cover the lowering pipeline, how we leverage upstream MLIR dialects and some key optimizations and learnings for compiling deep learning workloads to Gaudi.
Authors: Dafna Mordechai, Omer Paparo Bivas, Jayaram Bobba, Sergei Grechanik, Tzachi Cohen, Dibyendu Das
{kind=link}
{kind=link}
{kind=link}
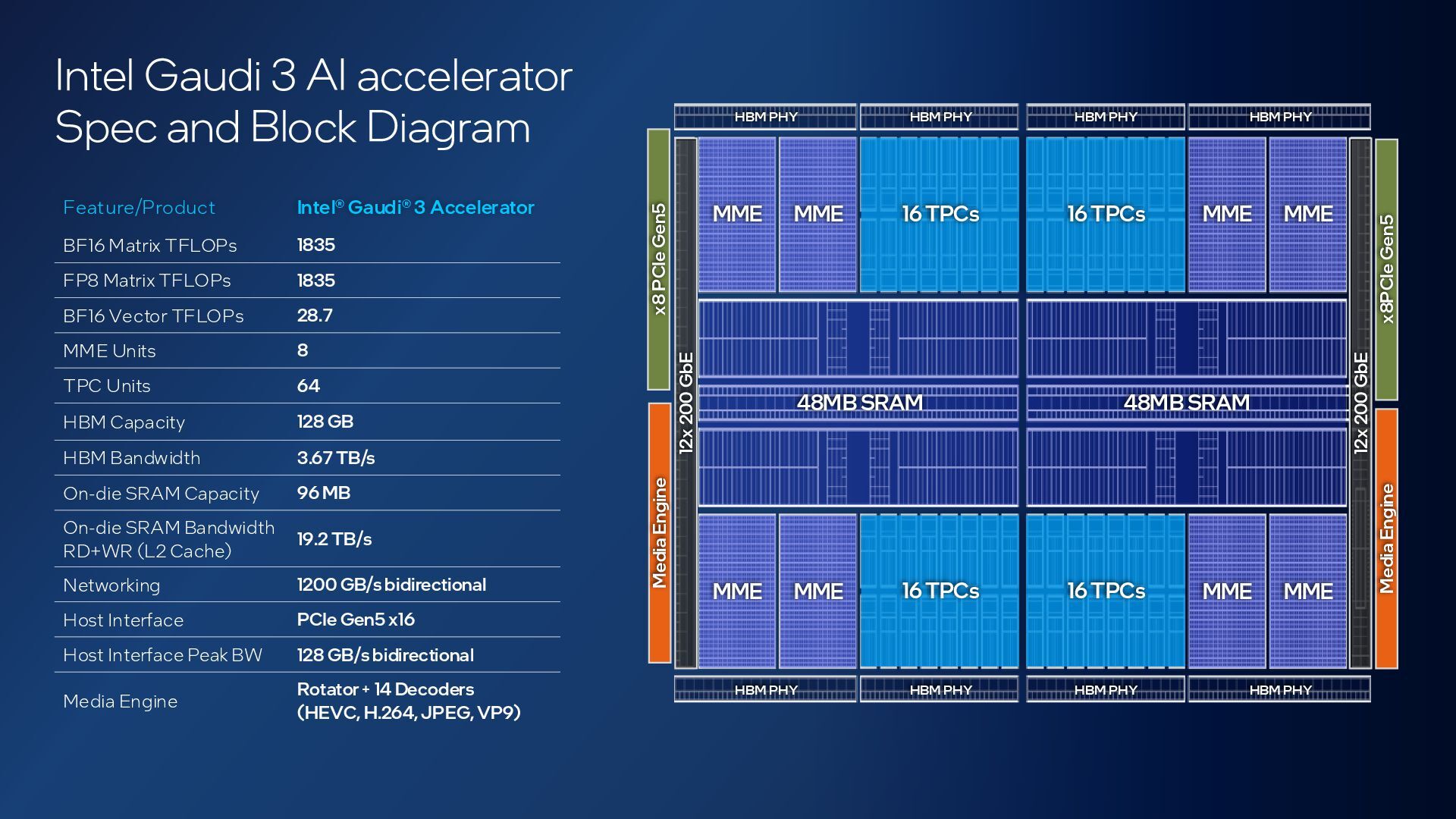{kind=link}
{kind=link}
{kind=link}
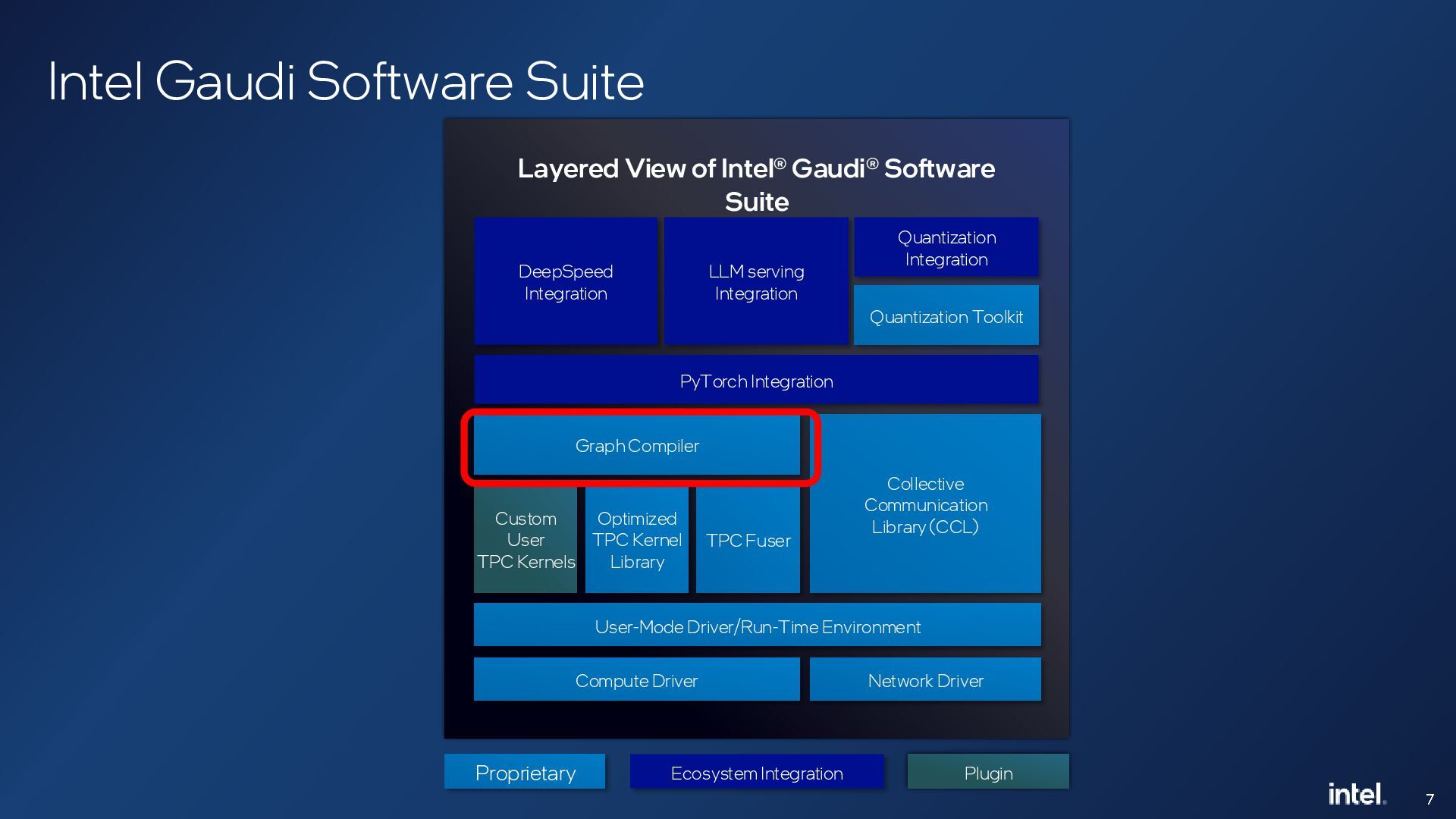{kind=link}
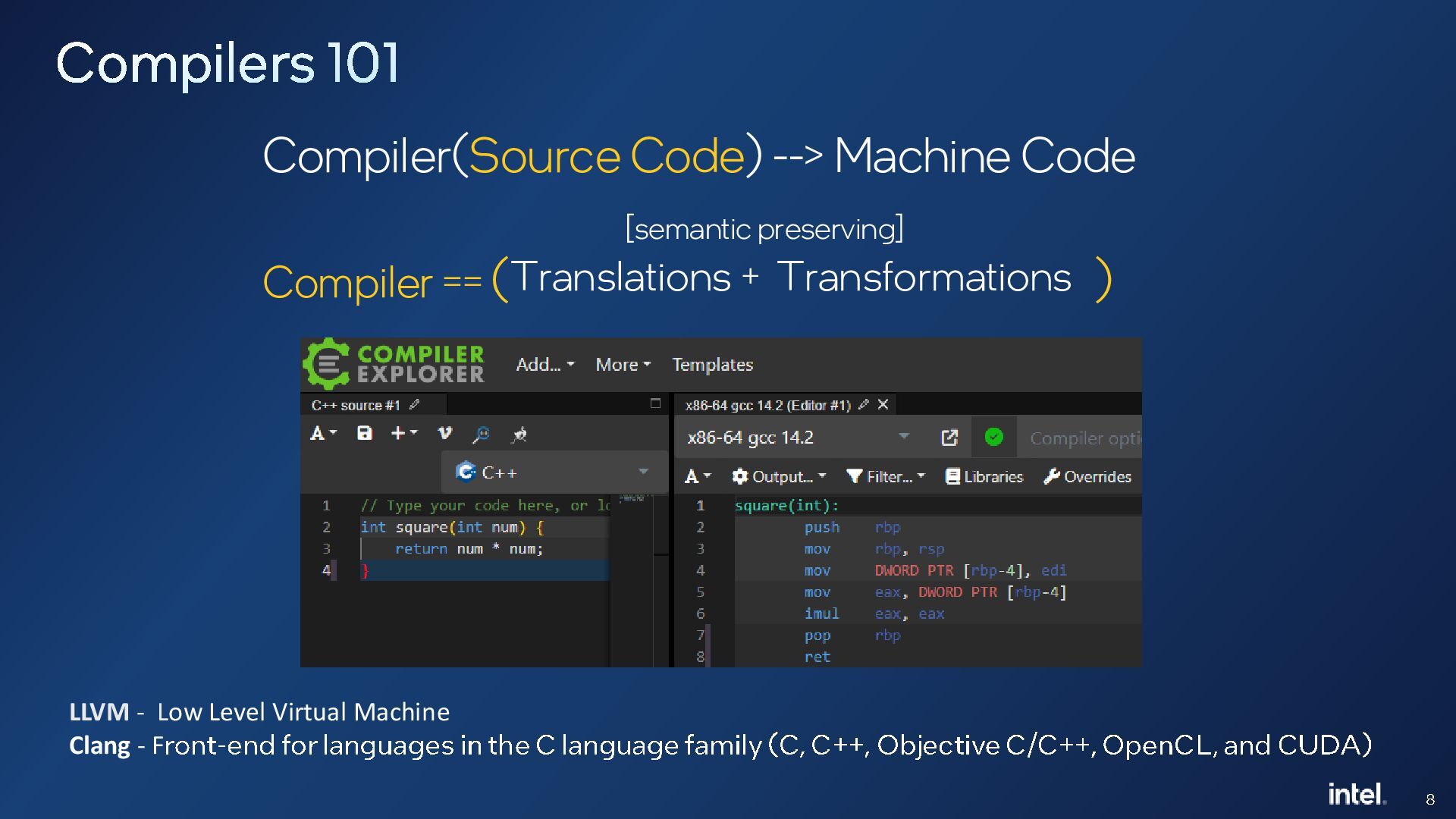{kind=link}
{kind=link}
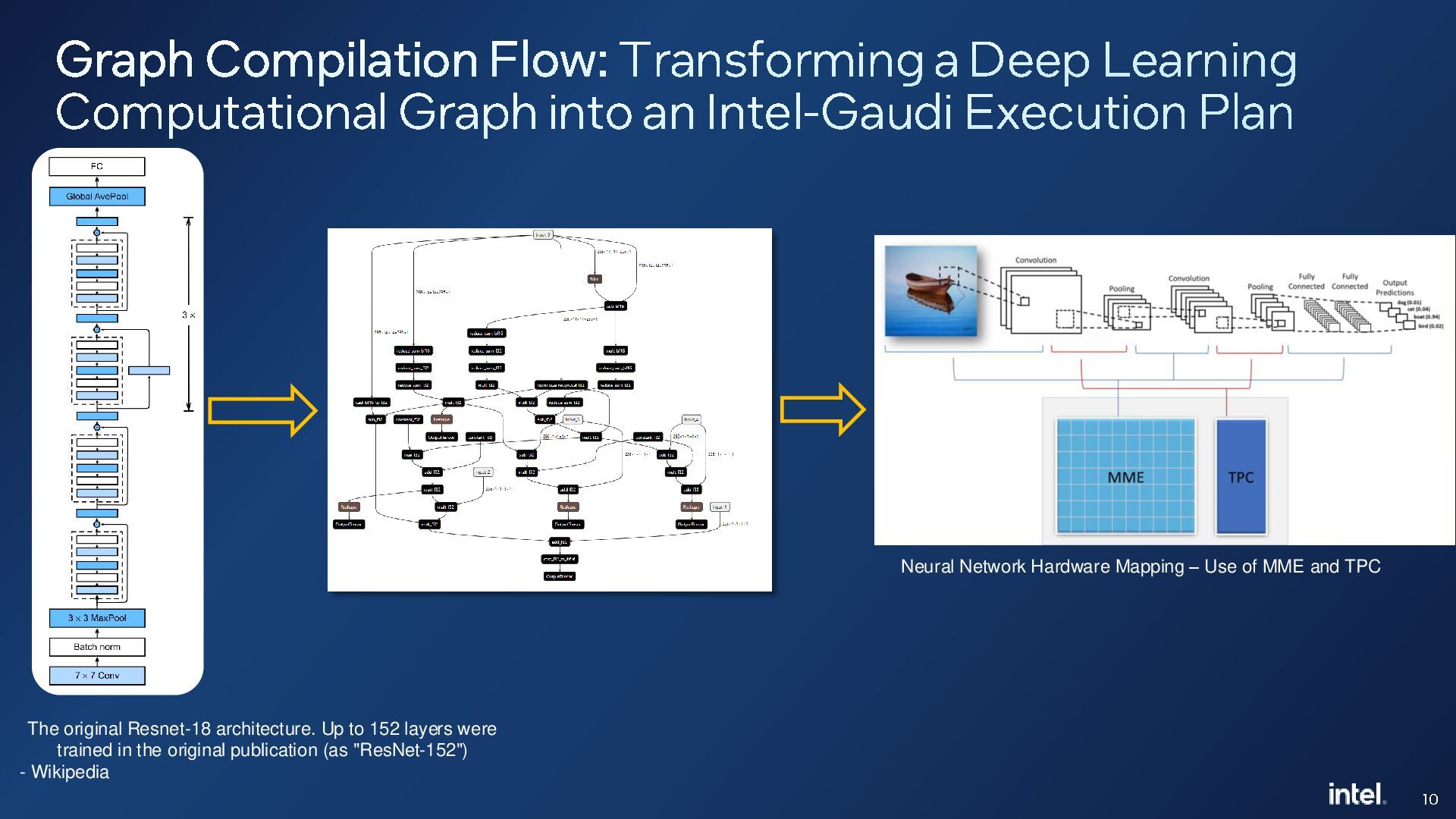{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
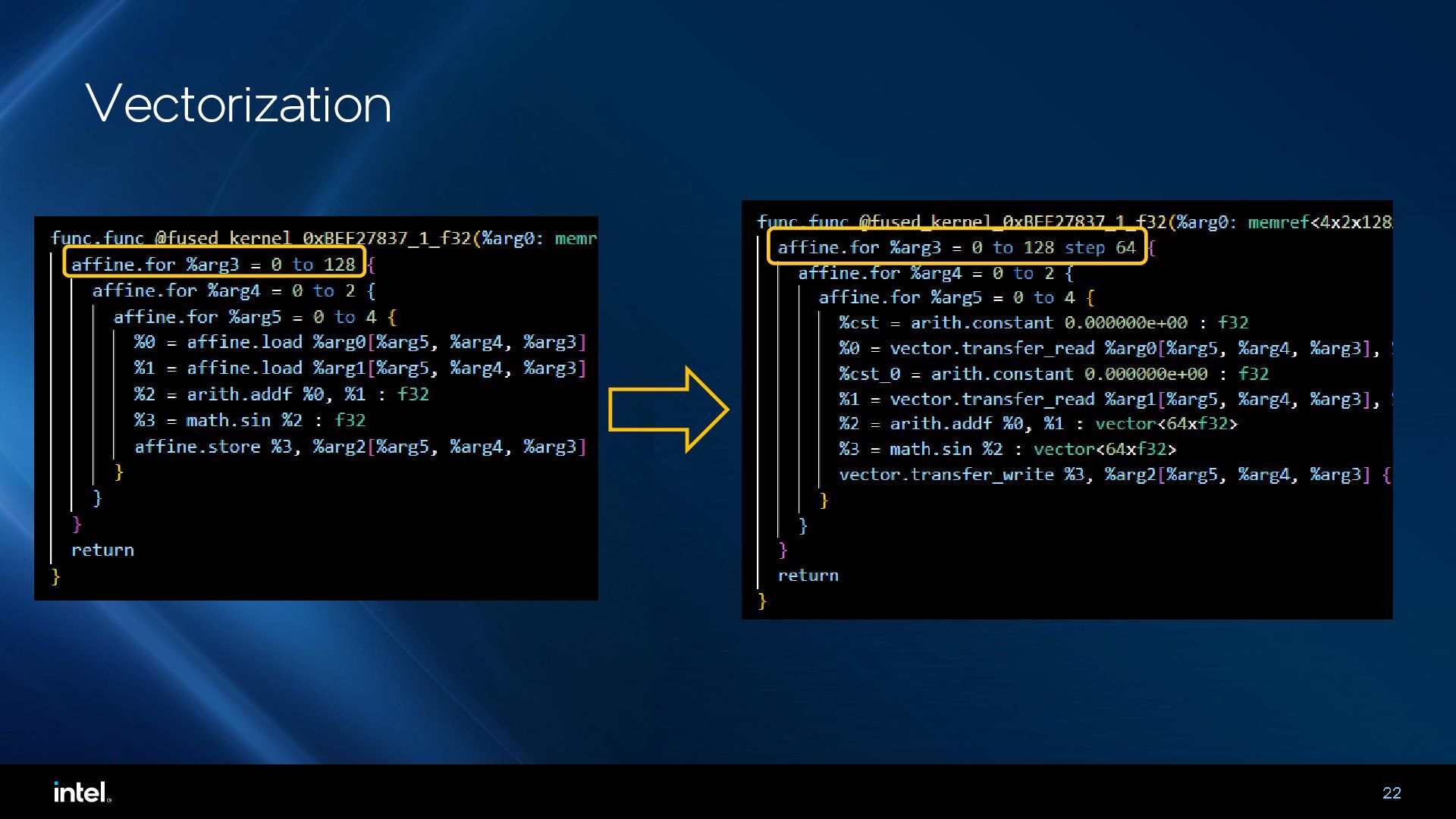{kind=link}
{kind=link}
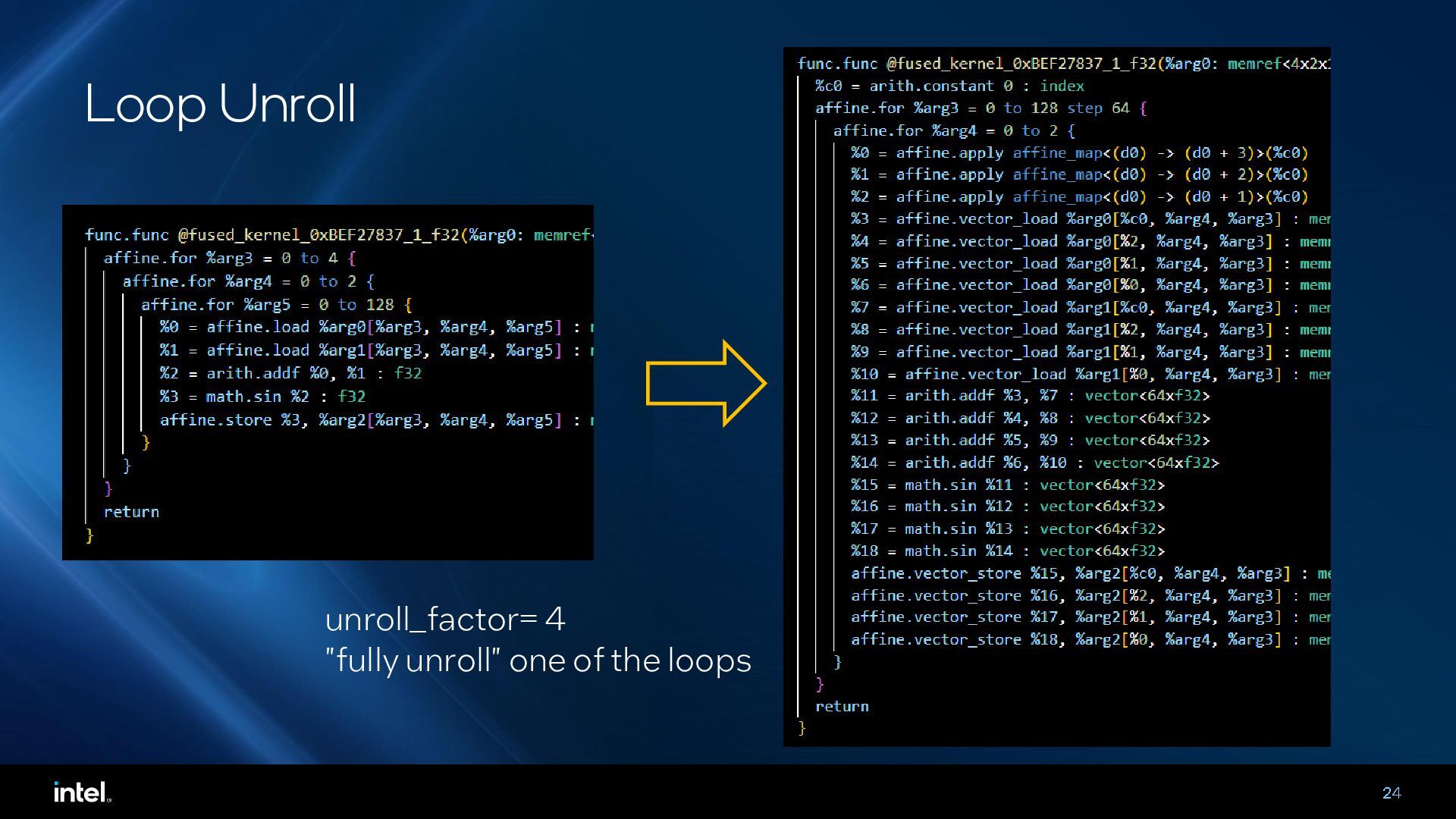{kind=link}
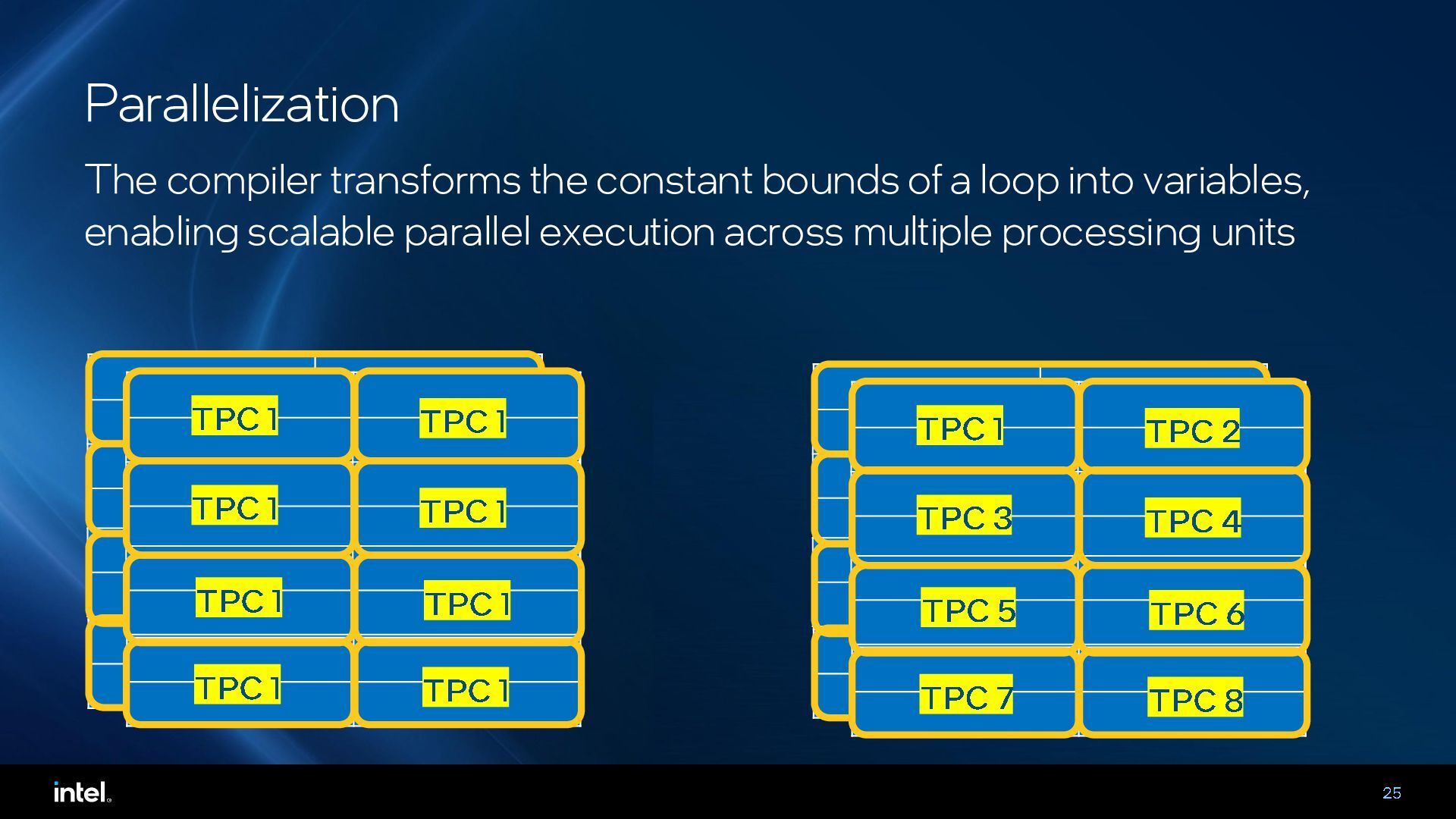{kind=link}
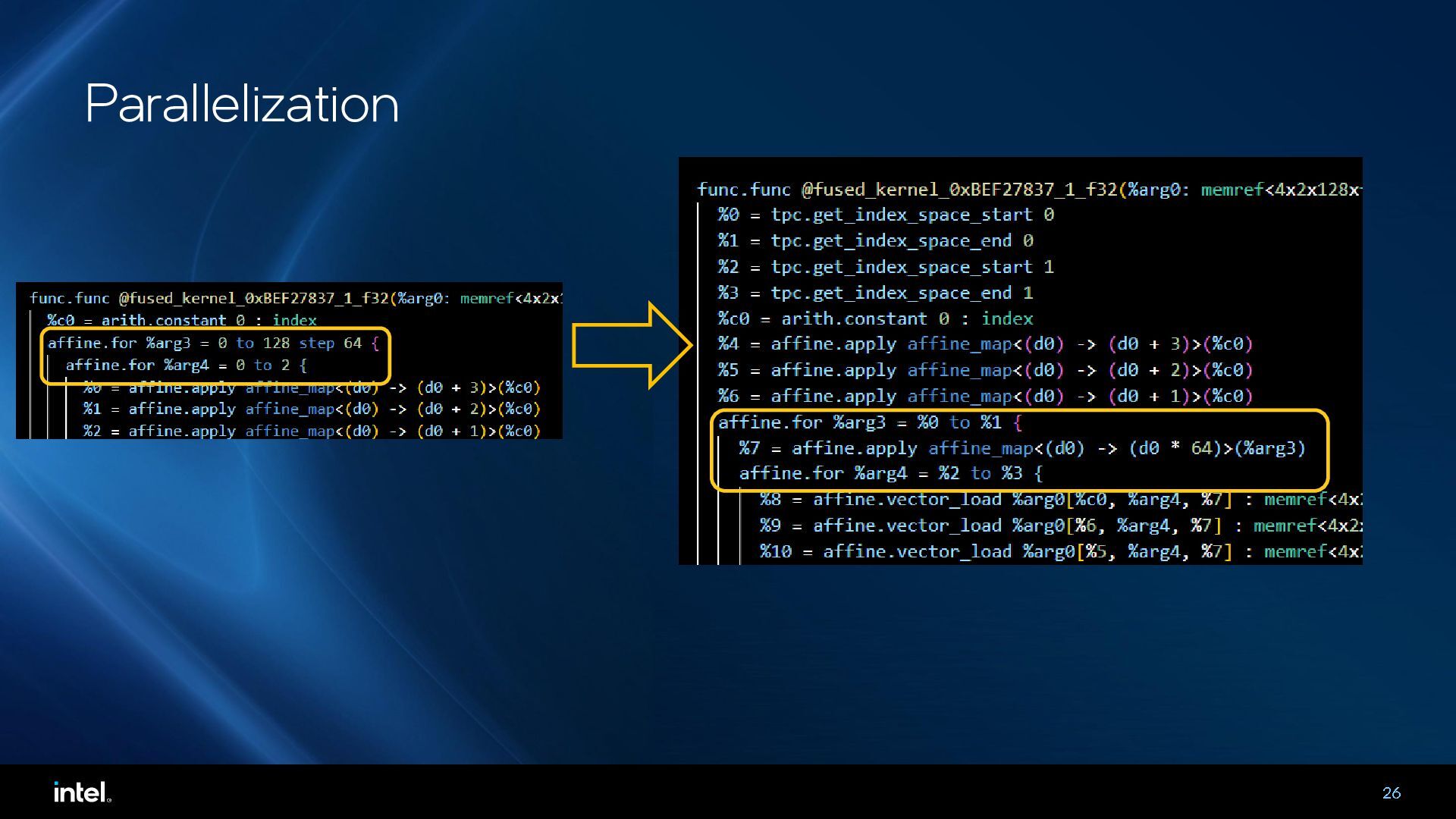{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
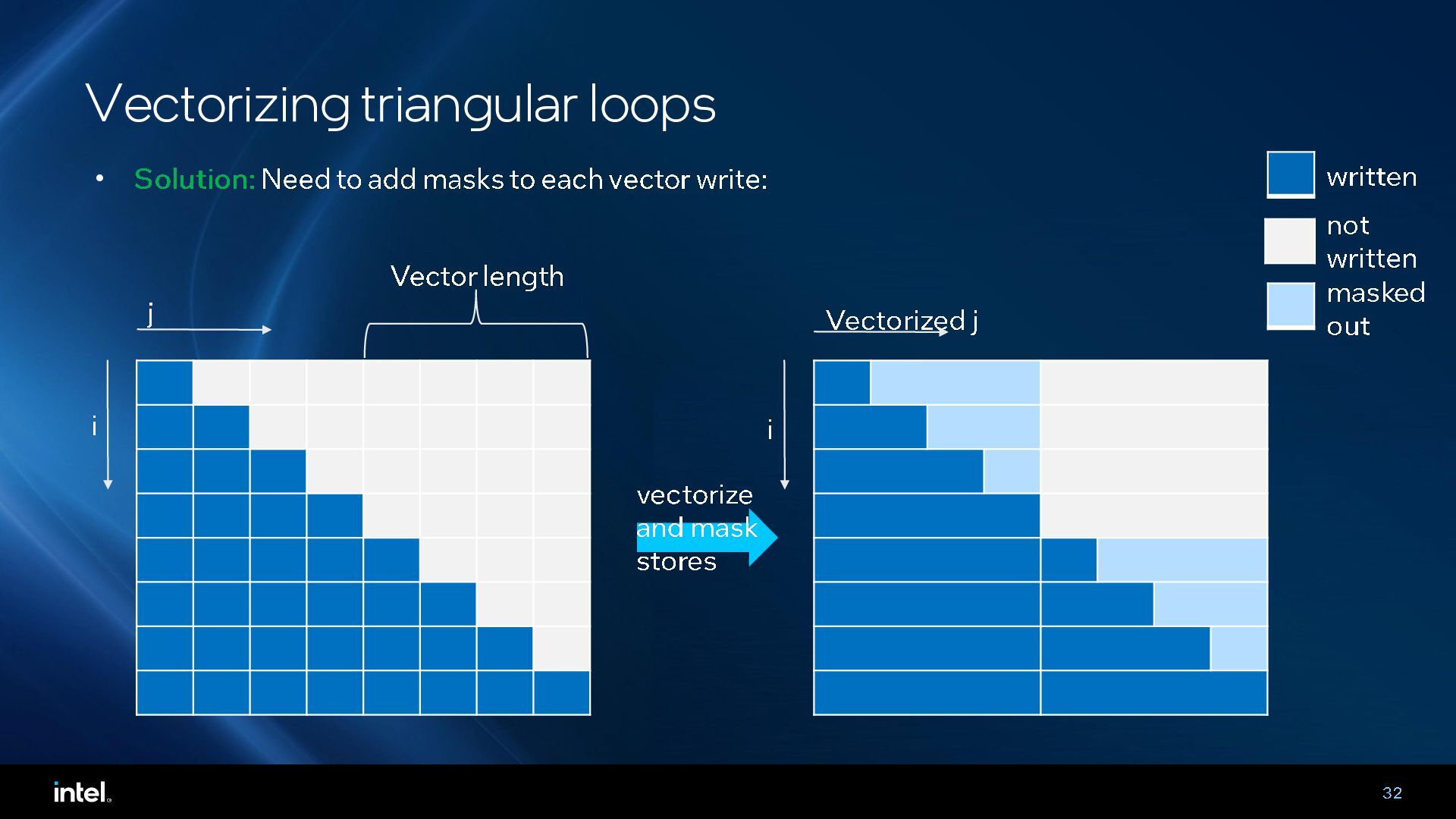{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
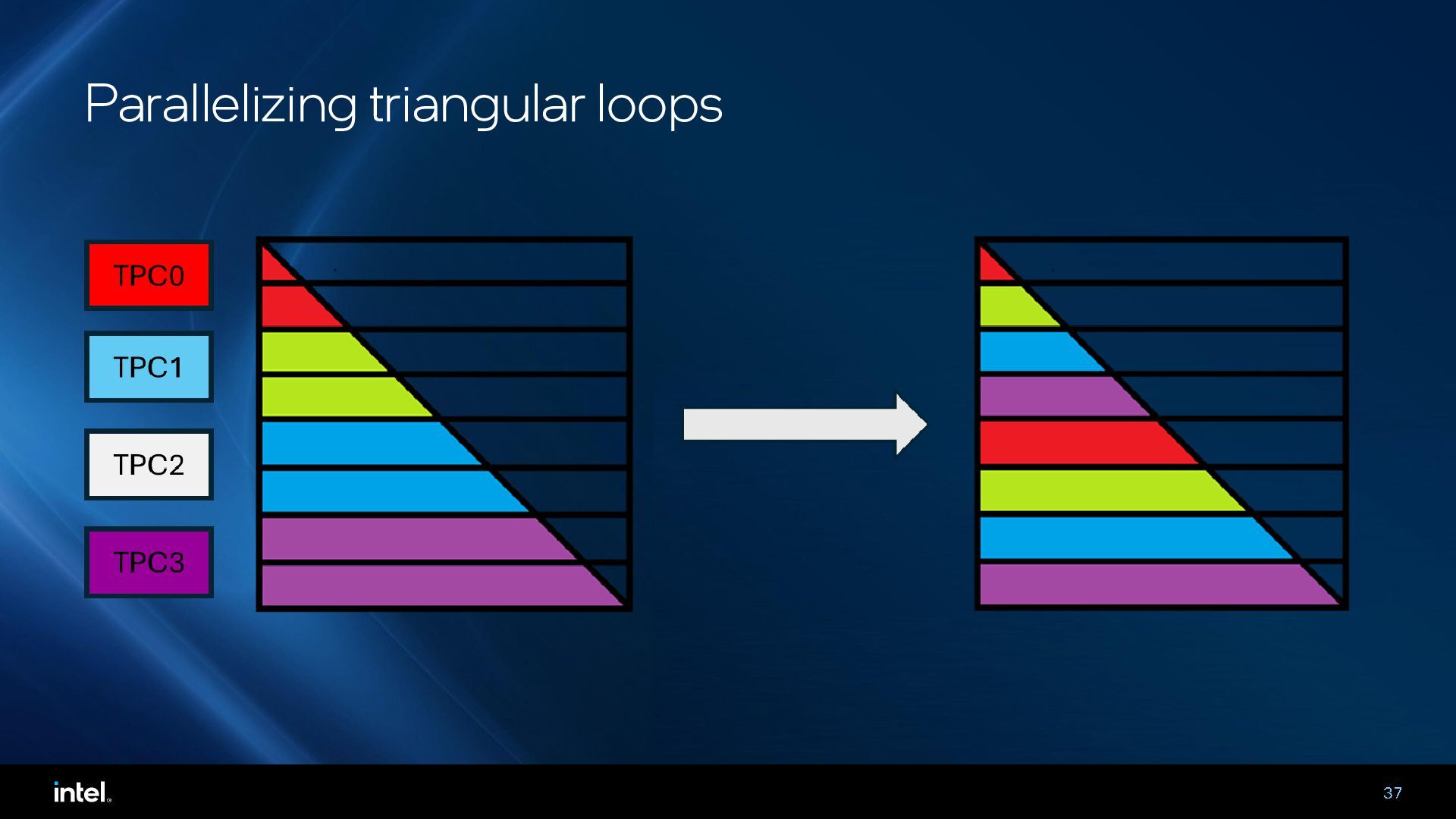{kind=link}
{kind=link}
{kind=link}
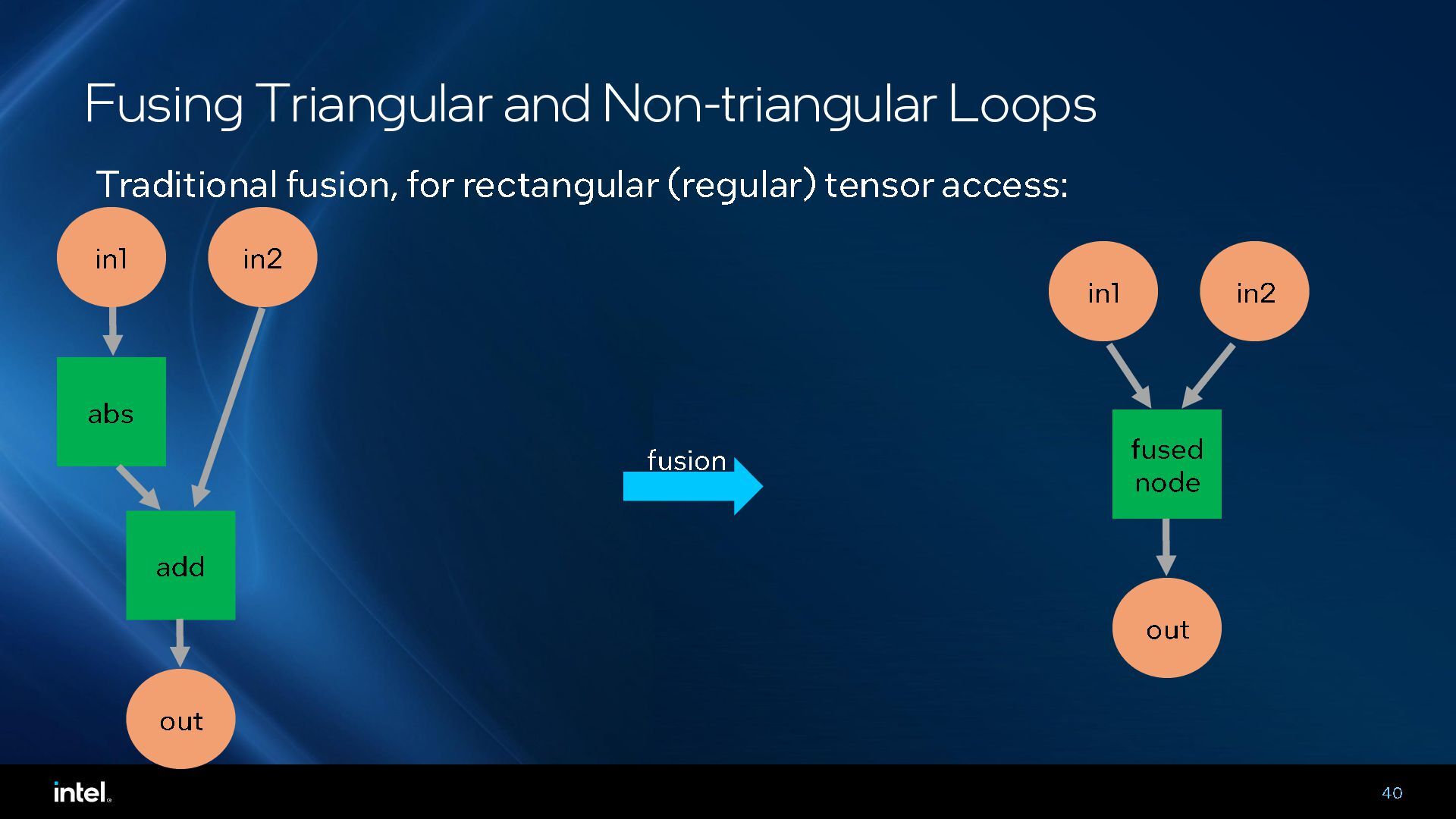{kind=link}
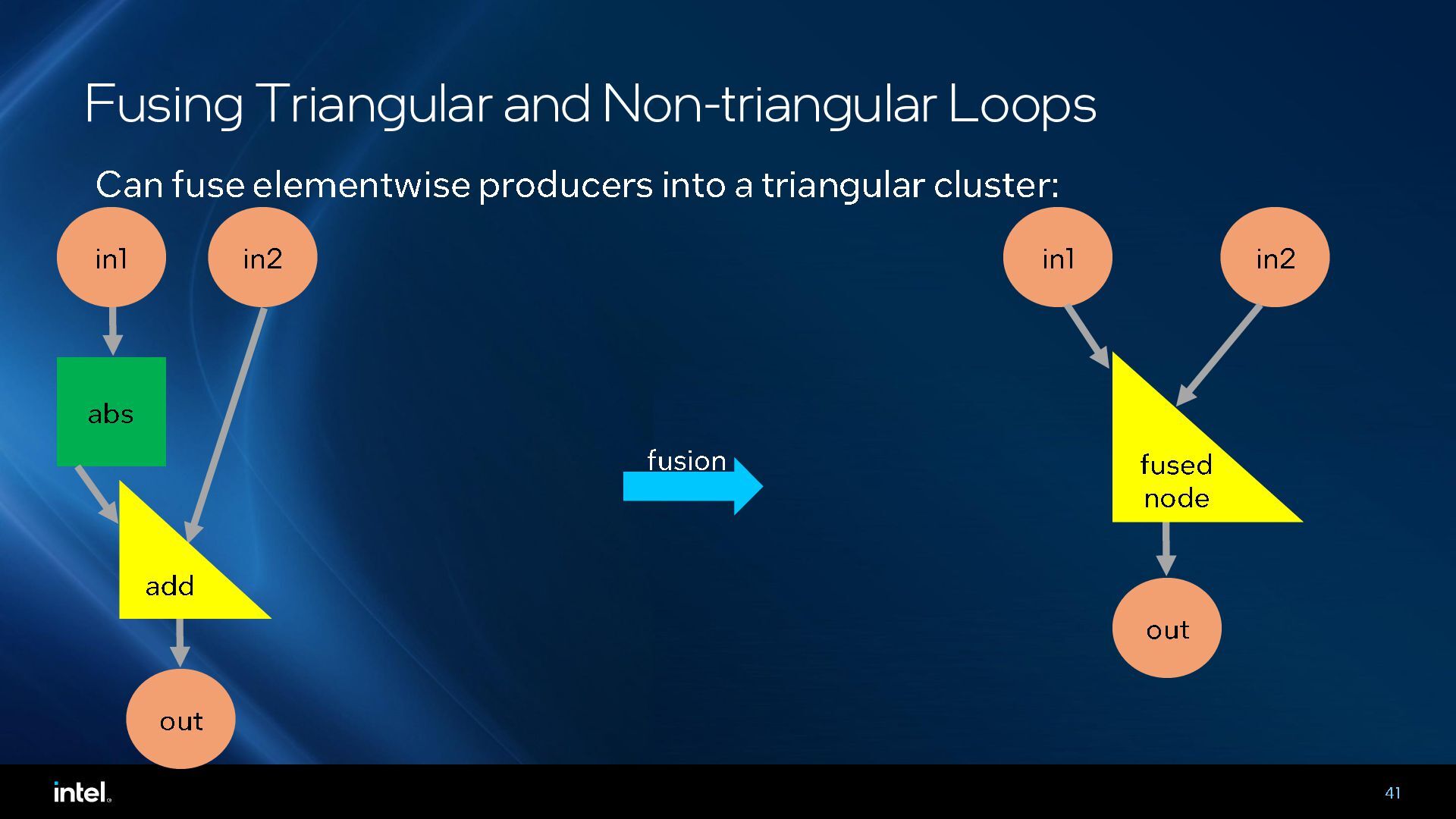{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}