la psycho-acoustique Des algorithmes de Digital Signal Processing (DSP) Transformations du signal Quantification La théorie de l'information Codage sans pertes (Loss-less Coding) Et enfin...
une échelle logarithmique? Pourquoi les niveaux de pression sonore sont représentés selon une échelle logarithmique? ( le dB est une représentation logarithmique)
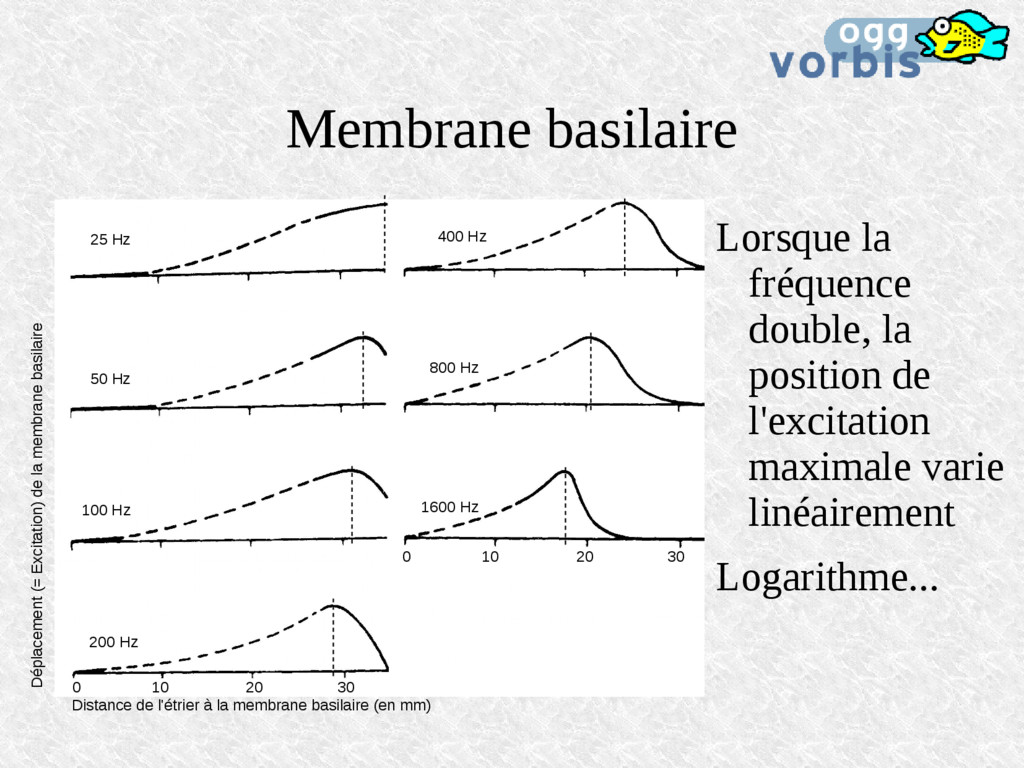
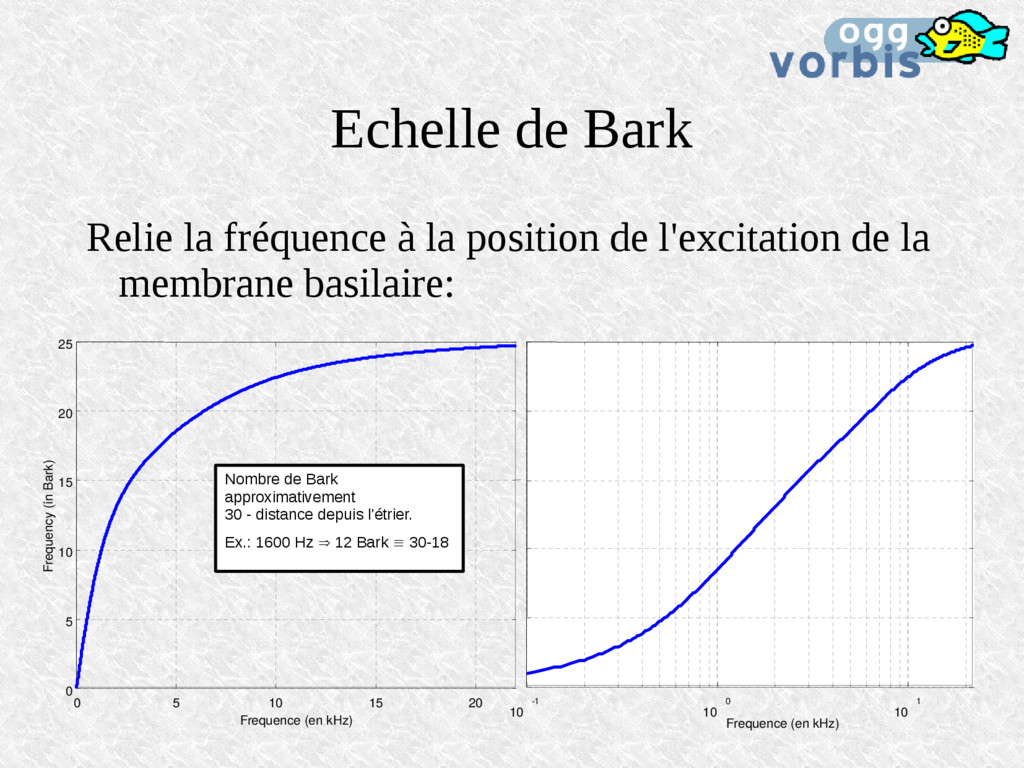
400 Hz 800 Hz 1600 Hz 0 10 20 30 Distance de l'étrier à la membrane basilaire (en mm) 0 10 20 30 Déplacement (= Excitation) de la membrane basilaire Lorsque la fréquence double, la position de l'excitation maximale varie linéairement Logarithme...
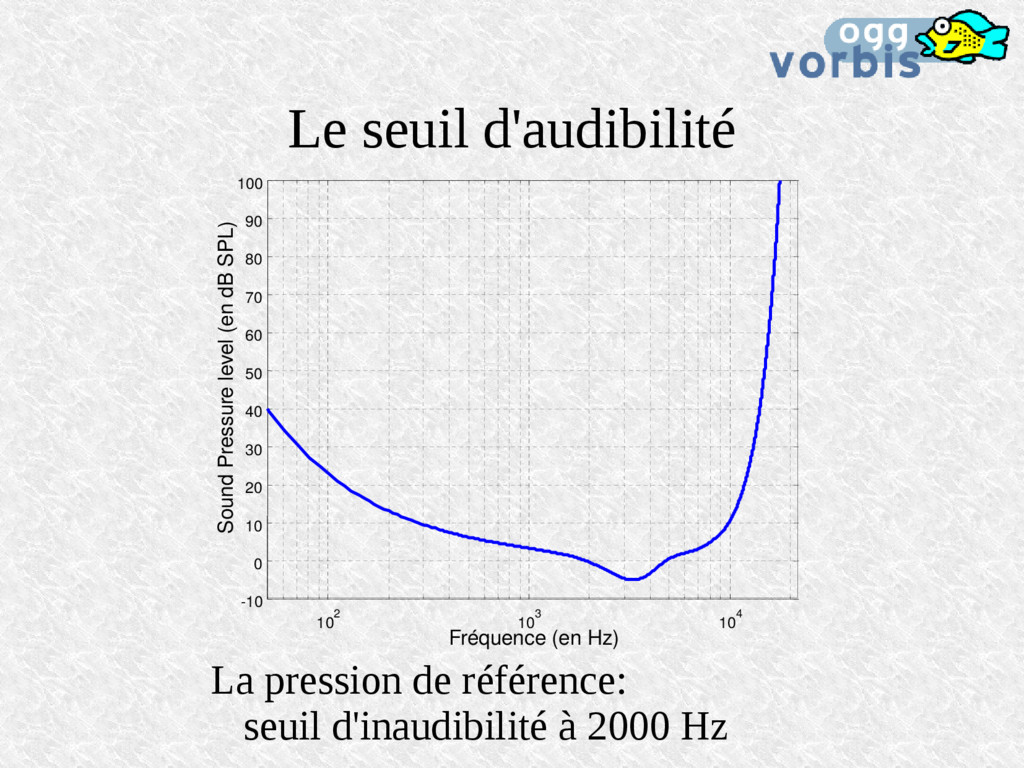
font pas deux fois plus de bruit qu'une seule tondeuse... Lorsque la pression sonore double, la sensation ne double pas. Logarithme... SPL: Sound Pressure Level sur une échelle en dB relative à une pression de référence. Les seuils de perception sont représentés sur une échelle de SPL en dB.
nombres entiers représentant une amplitude et les dB SPL? Une solution: Une sinusoïde avec la plus petite amplitude (1 LSB) a un niveau correspondant au seuil absolu d'audibilité à 4kHz, soit -5 dB SPL. ½A2 pour A=1 équivaut à -3dB + K -5 dB SPL K=-2 dB 16 bits couvrent environ 90 dB de dynamique.
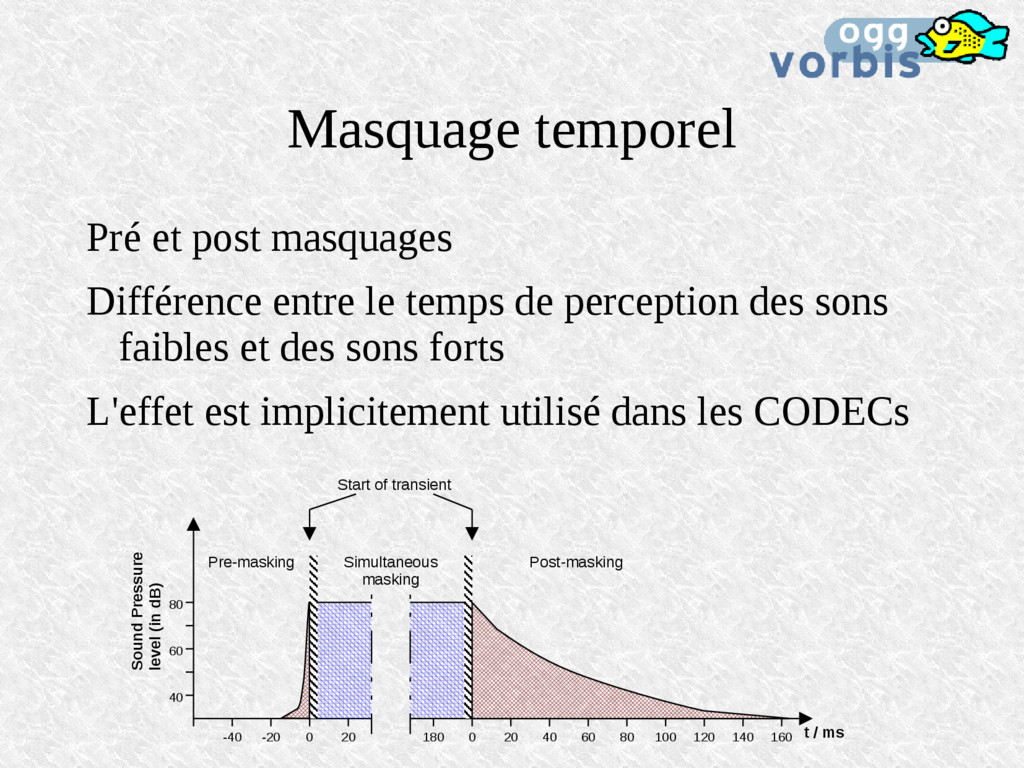
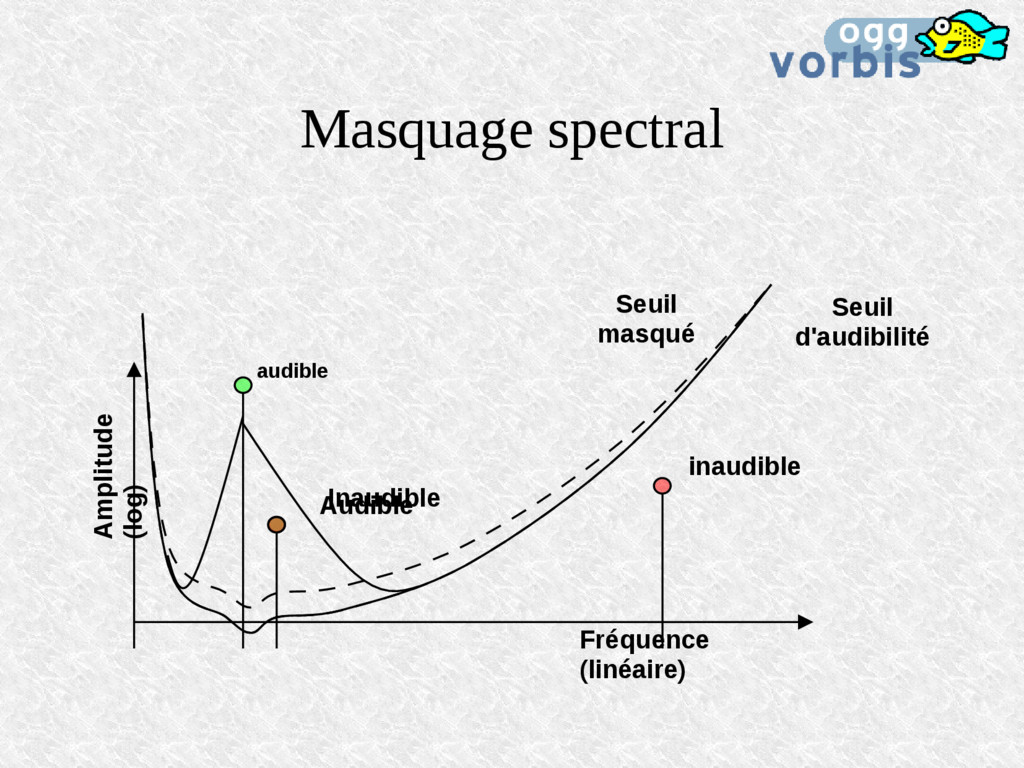
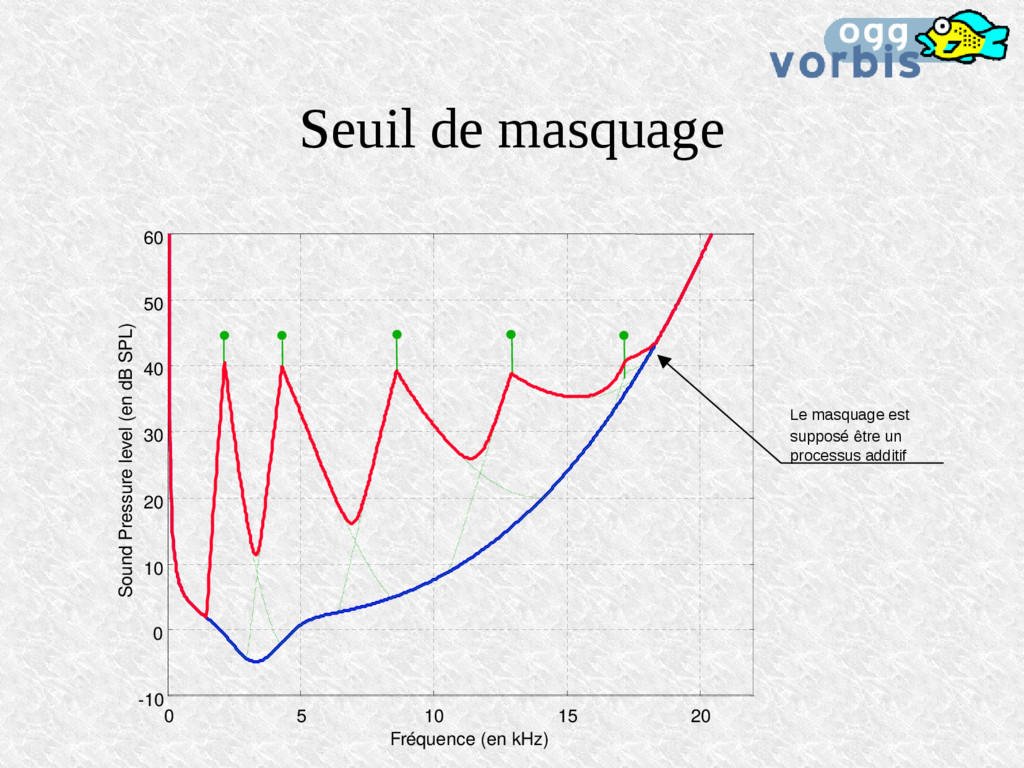
de perception des sons faibles et des sons forts L'effet est implicitement utilisé dans les CODECs Simultaneous masking Pre-masking Post-masking -40 -20 0 20 180 0 20 40 60 80 100 120 140 160 t / ms Sound Pressure level (in dB) 40 60 80 Start of transient
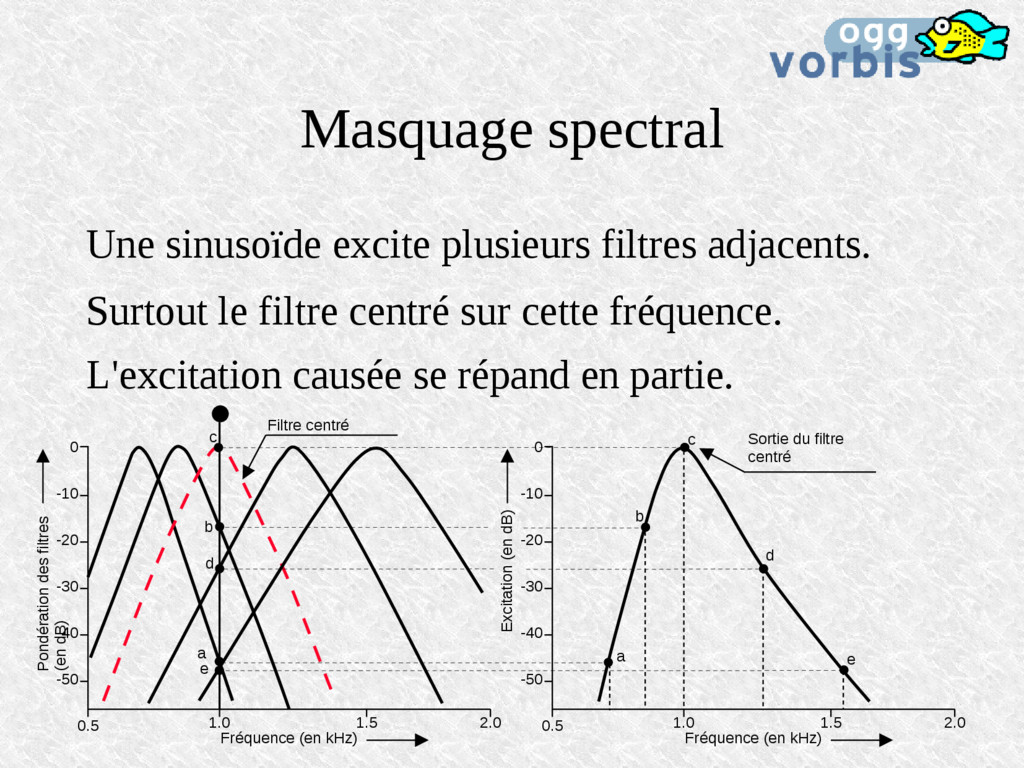
un ensemble de filtres passe-bande (les cils) A chaque filtre correspond l'excitation d'une cellule nerveuse. 0.5 1.0 1.5 2.0 0 -10 -40 -30 -20 -50 Pondération des filtres (en dB) Fréquence (en kHz)
filtre centré sur cette fréquence. L'excitation causée se répand en partie. 0.5 1.0 1.5 2.0 Fréquence (en kHz) 0.5 1.0 1.5 2.0 Fréquence (en kHz) 0 -10 -40 -30 -20 -50 Pondération des filtres (en dB) 0 -10 -40 -30 -20 -50 Excitation (en dB) Filtre centré Sortie du filtre centré a a b b c c d d e e
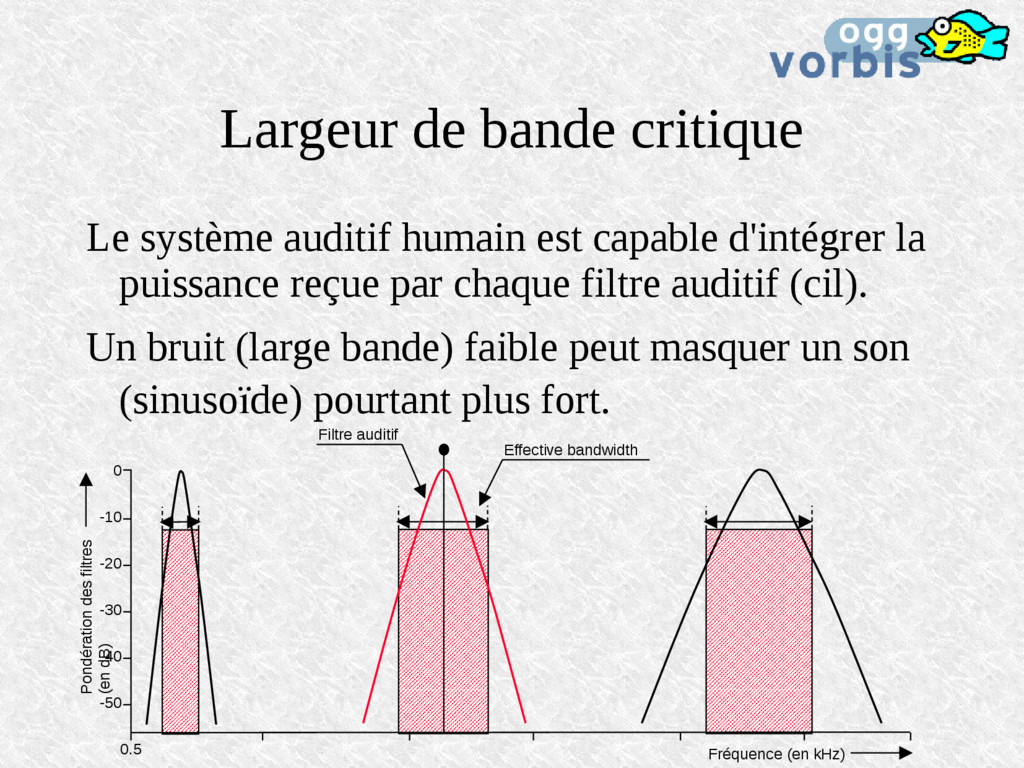
d'intégrer la puissance reçue par chaque filtre auditif (cil). Un bruit (large bande) faible peut masquer un son (sinusoïde) pourtant plus fort. Effective bandwidth 0.5 0 -10 -40 -30 -20 -50 Pondération des filtres (en dB) Filtre auditif Fréquence (en kHz)
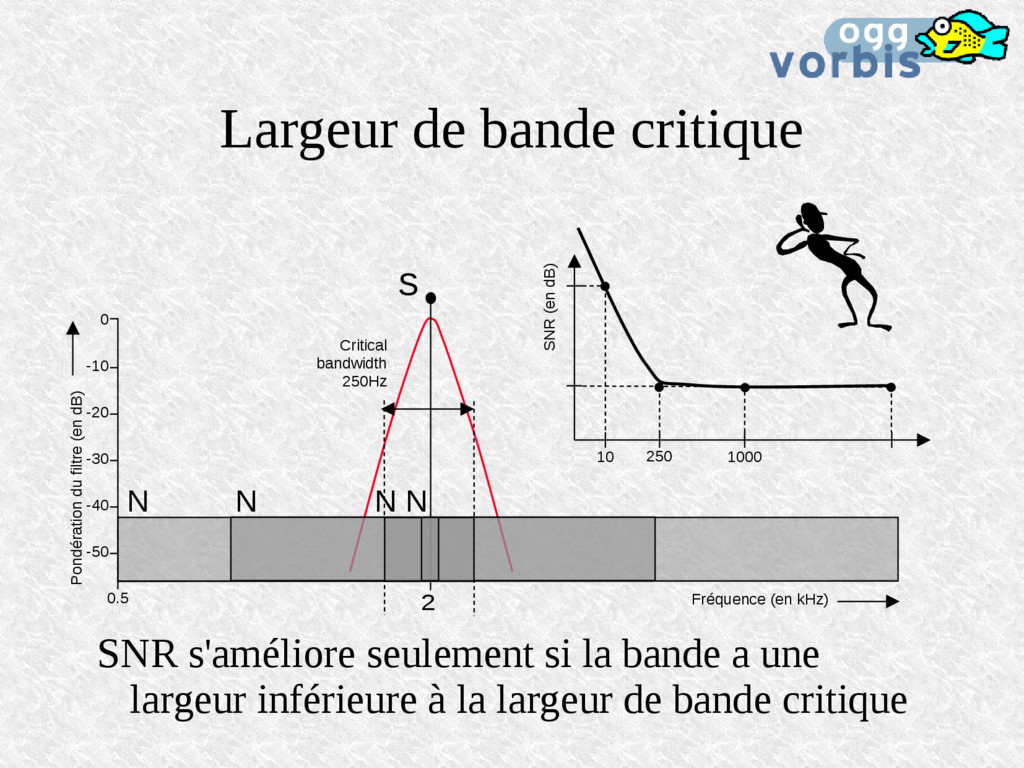
a une largeur inférieure à la largeur de bande critique 0.5 Fréquence (en kHz) 0 -10 -40 -30 -20 -50 Pondération du filtre (en dB) SNR (en dB) S N 1000 N 250 N 10 N Critical bandwidth 250Hz 2
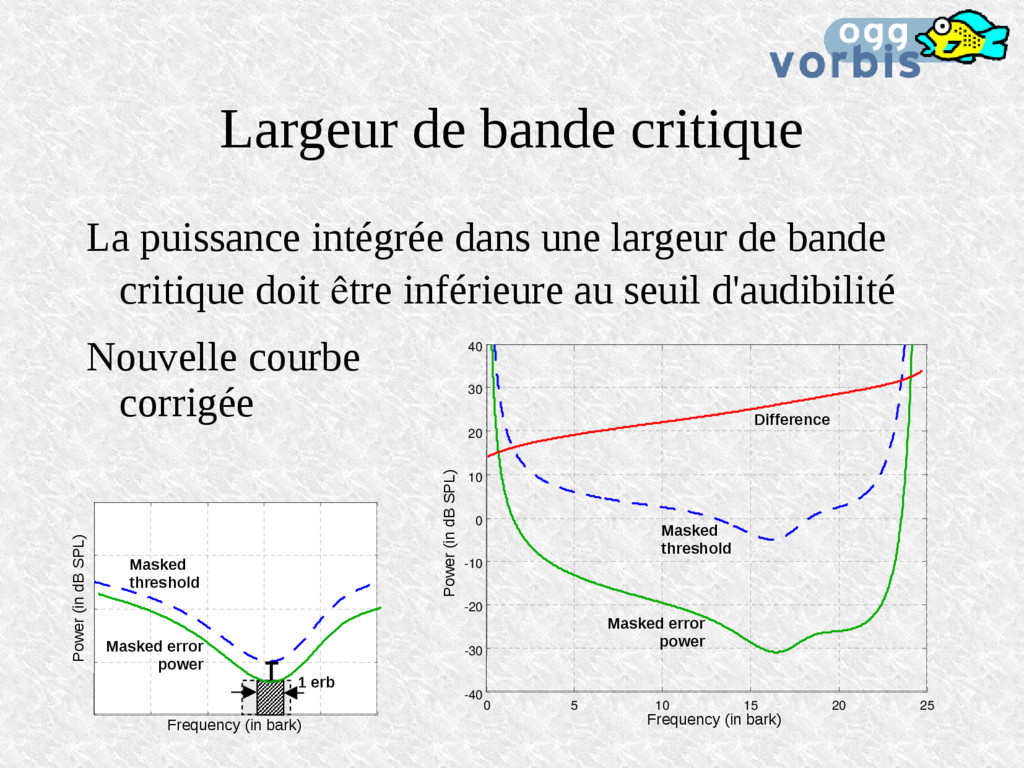
de bande critique doit être inférieure au seuil d'audibilité Nouvelle courbe corrigée 0 5 10 15 20 25 -40 -30 -20 -10 0 10 20 30 40 1 erb Masked threshold Masked error power Masked error power Masked threshold Frequency (in bark) Frequency (in bark) Power (in dB SPL) Power (in dB SPL) Difference
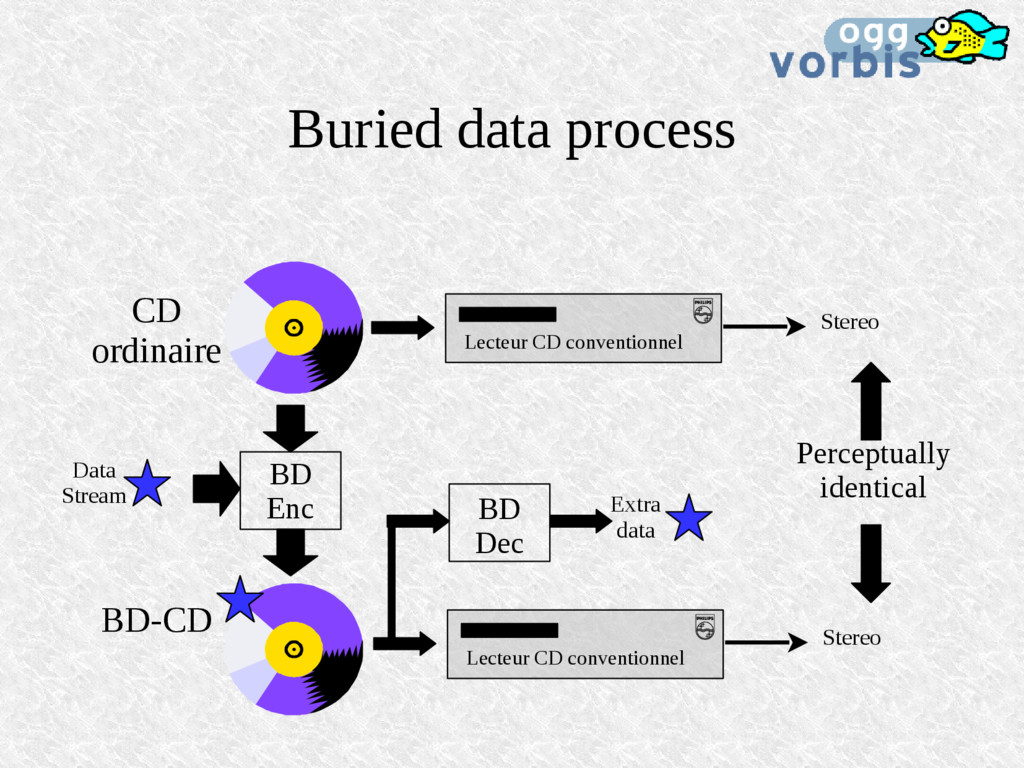
peut ajouter un bruit au signal jusqu'au seuil de masquage corrigé. Le signal audio reste perceptuellement identique au signal audio original. Le bruit représente en fait un data-stream. Ce data-stream peut être récupéré par après. Jusqu'à 1/3 de la capacité d'un CD peut être ainsi utilisée sans différence de perception.
comprendre totalement le message Infrmtn qi n'e pa ncesair pr comprndr ttlmnt l msg Irrélévance: Information qui fait partie du message, mais qui ne change pas la perception de ce message
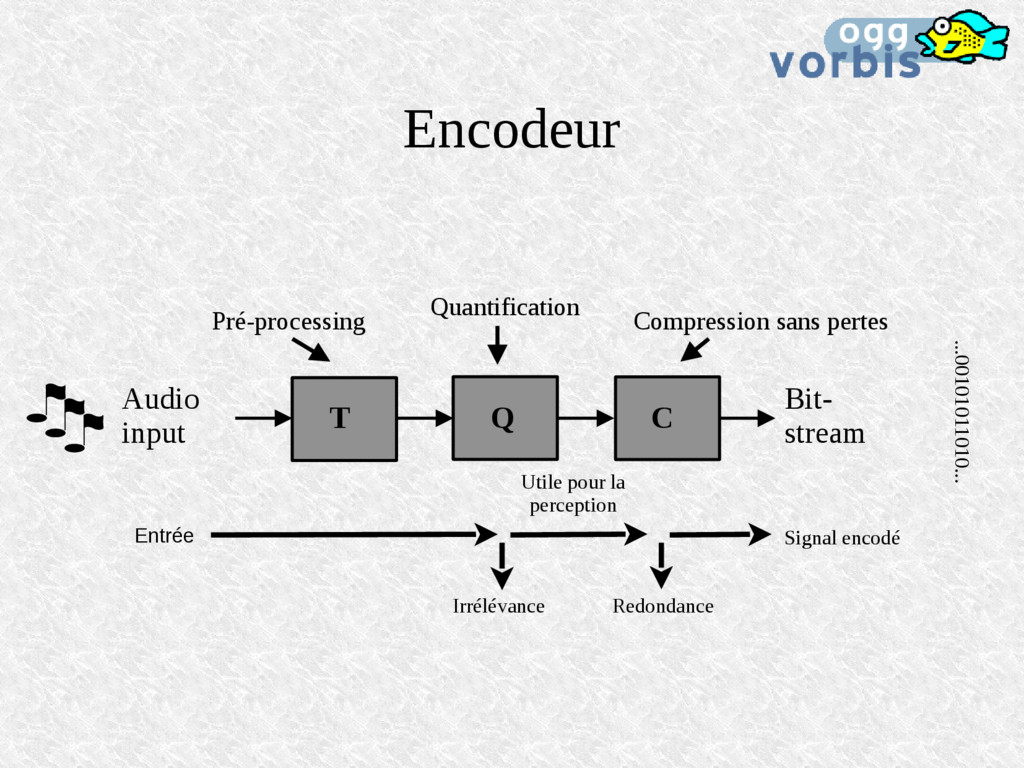
Output Input Exploite Redondance seulement Redondance & Irrélévance Avec pertes Sans pertes Tests perceptuels Non Oui Compression ratio > 2 > 30 Qualité Objective (max) Subjective Bit rate Variable Fixe ou variable
du signal intégrées en bandes de fréquence peuvent être mises facilement en relation avec le seuil de masquage. 'Noise-shaping' perceptuel Le bruit de quantification de chaque bande peut être choisi séparément selon le seuil de masquage.
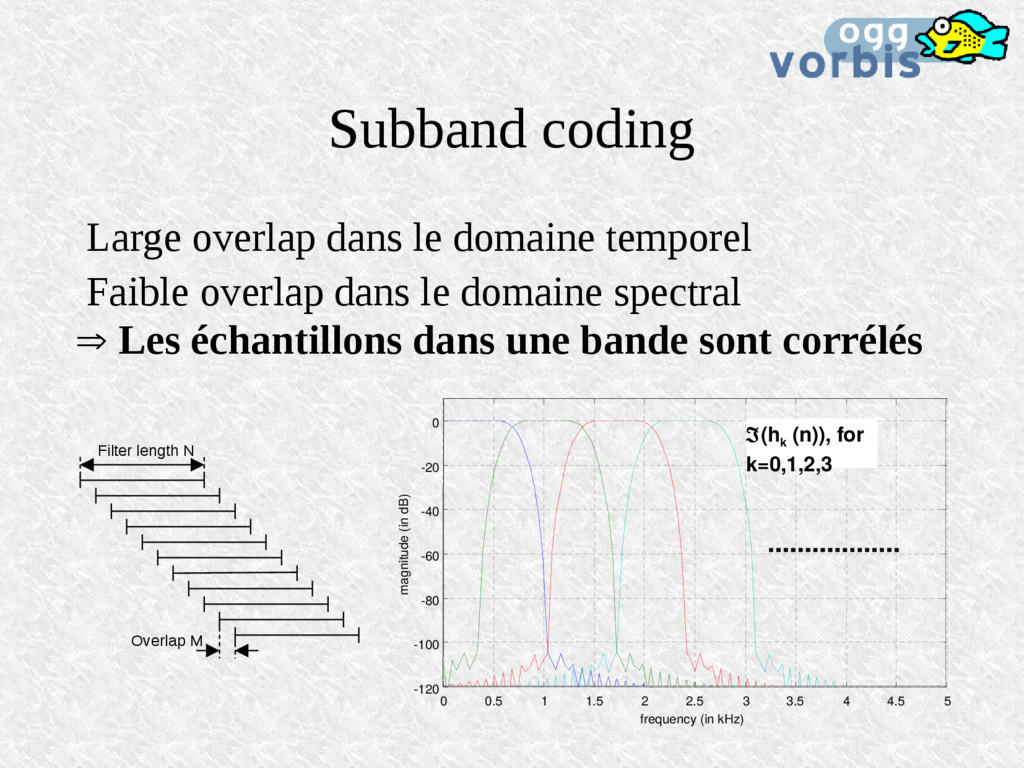
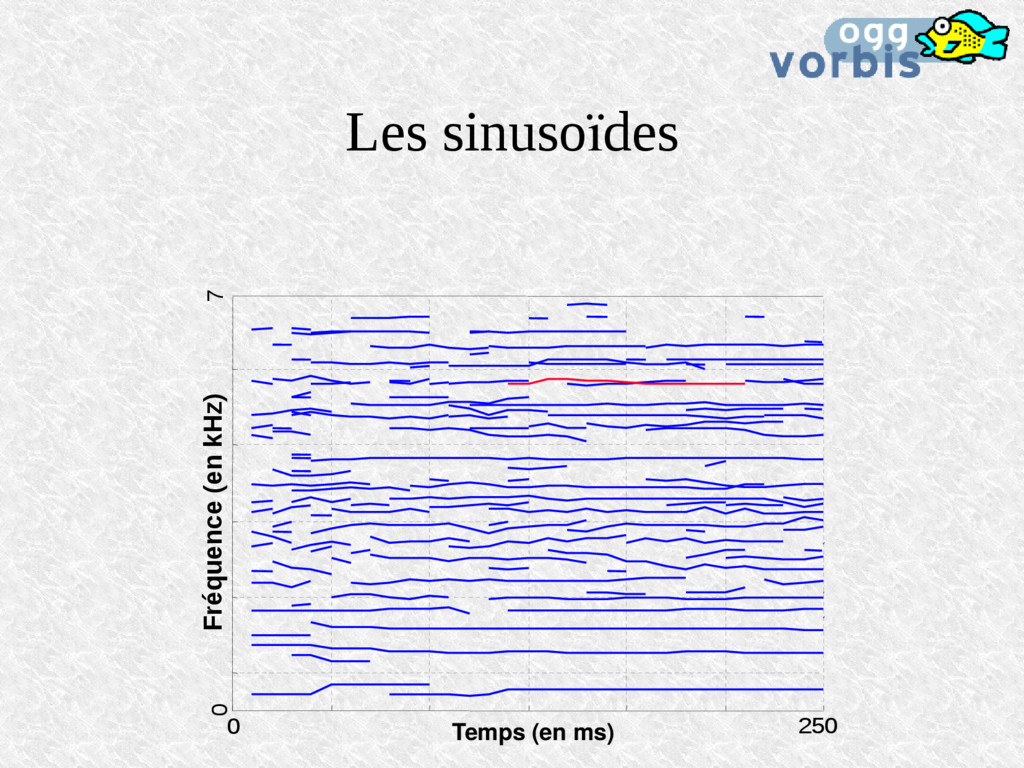
dans le domaine spectral Les échantillons dans une bande sont corrélés 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 -120 -100 -80 -60 -40 -20 0 frequency (in kHz) magnitude (in dB) (h k (n)), for k=0,1,2,3 Filter length N Overlap M
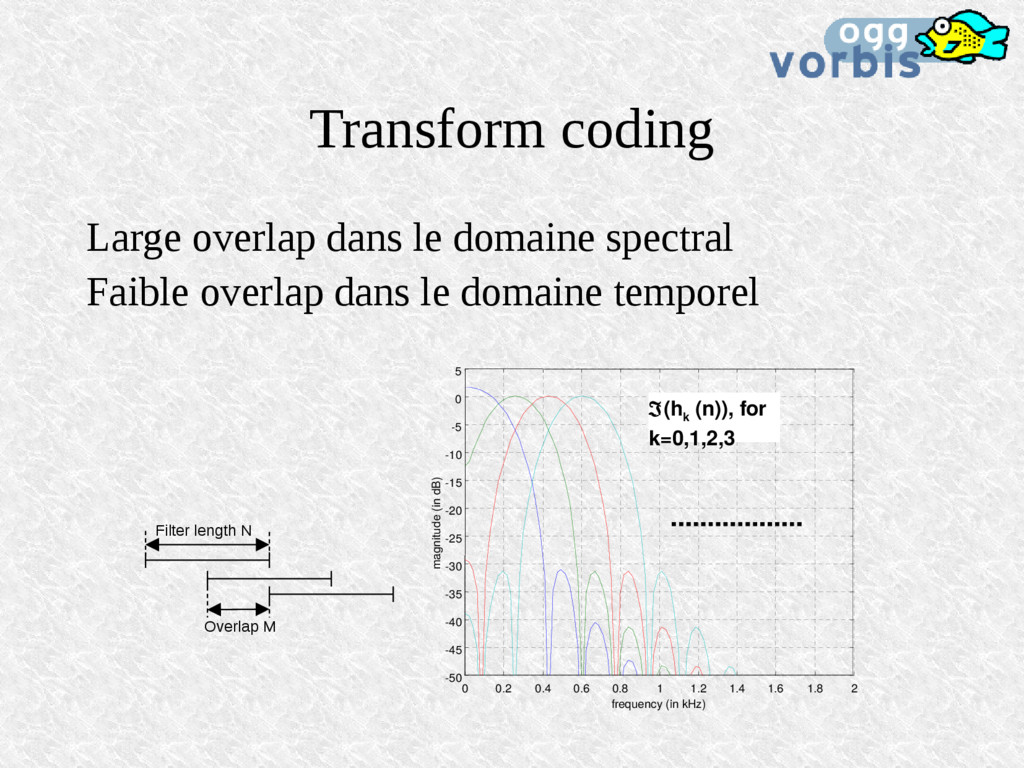
dans le domaine temporel Filter length N Overlap M 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 -50 -45 -40 -35 -30 -25 -20 -15 -10 -5 0 5 frequency (in kHz) magnitude (in dB) (h k (n)), for k=0,1,2,3
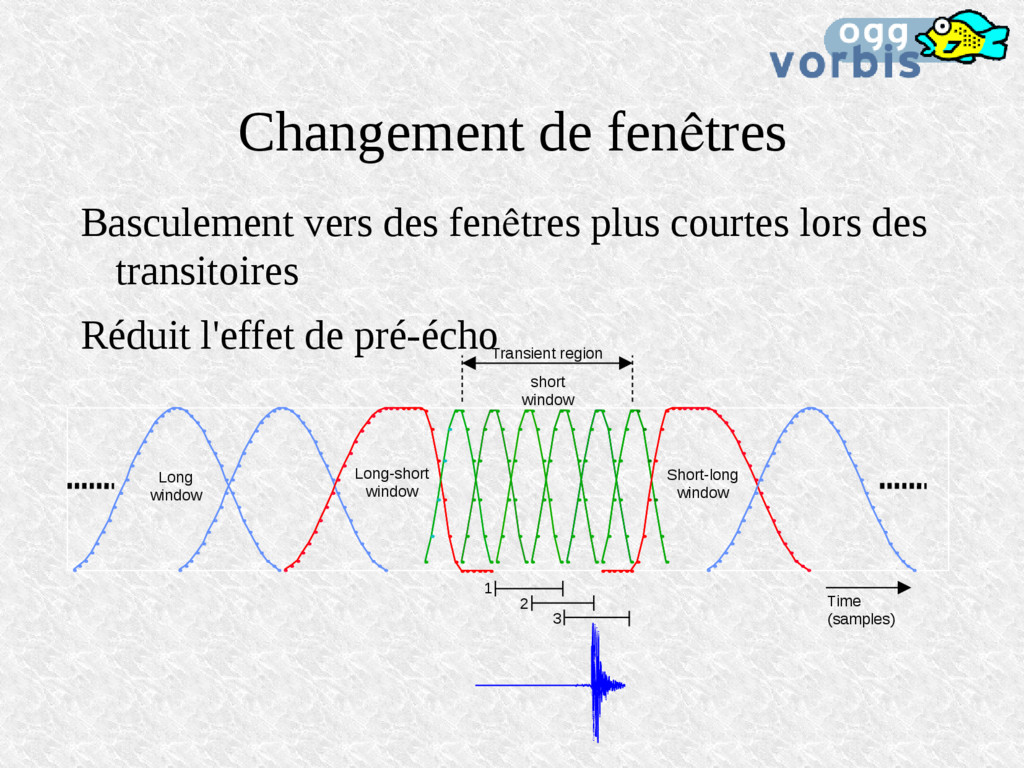
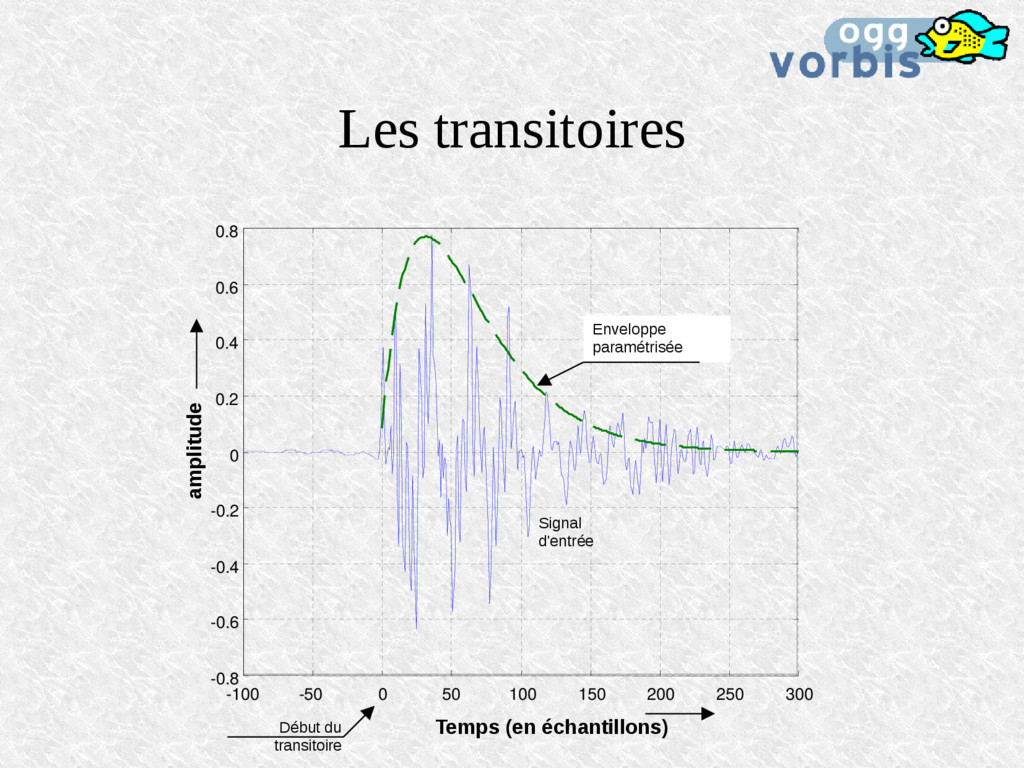
en temporel lors de la synthèse du son: 2500 3000 3500 4000 4500 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 magnitude 2500 3000 3500 4000 4500 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 time (in samples) magnitude time (in samples) Composantes à haute énergie 1 2 Pre-echo 3 1 2 3 Analyse Synthèse Peu d'énergie pour toute la longueur du filtre peu de bits utilisés relativement bcp d'erreurs de quantification
compression sans pertes, ...) subband coding et transform coding sont comparables en termes de performances/complexité FFT 256...2048 2 TC Polyphase matrix 2...64 2...64 SBC Implémentation M N/M Type
-.. E . F ..-. G --. H .... I .. J .--- K -.- L .-.. M -- N -. O --- P .--. Q --.- R .-. S ... T - U ..- V ...- W .-- X -..- Y -.-- Z --.. 0 ----- 1 .---- 2 ..--- 3 ...-- 4 ....- 5 ..... 6 -.... 7 --... 8 ---.. 9 ----. 36 symboles Morse nécessitent 6 bit -> 64 possibilités (A=000001, B=000010, ...) En exploitant les probabilités des lettres dans les mots, la longueur moyenne des symboles en Morse (A .. Z) 3.2
séparément (efficace pour les basses fréquences) L+R: év. 1 bit en plus L-R: nettement moins de bits si canaux fort corrélés Ajustement du modèle perceptuel et de la quantification nécessaires L = [(L-R) + (L+R)] / 2 R = [(L+R) - (L-R)] / 2
transitoires PNS: Perceptual noise shaping Substitue les bandes de fréquence par une synthèse de bruit blanc dans le décodeur (applaudissements=bruit blanc...) LTP: Long term prediction Réduction supplémentaire de la corrélation dans les sous-bandes par prédiction dans le domaine temporel TWIN-VQ Autre type de quantification dans les sous-bandes ...
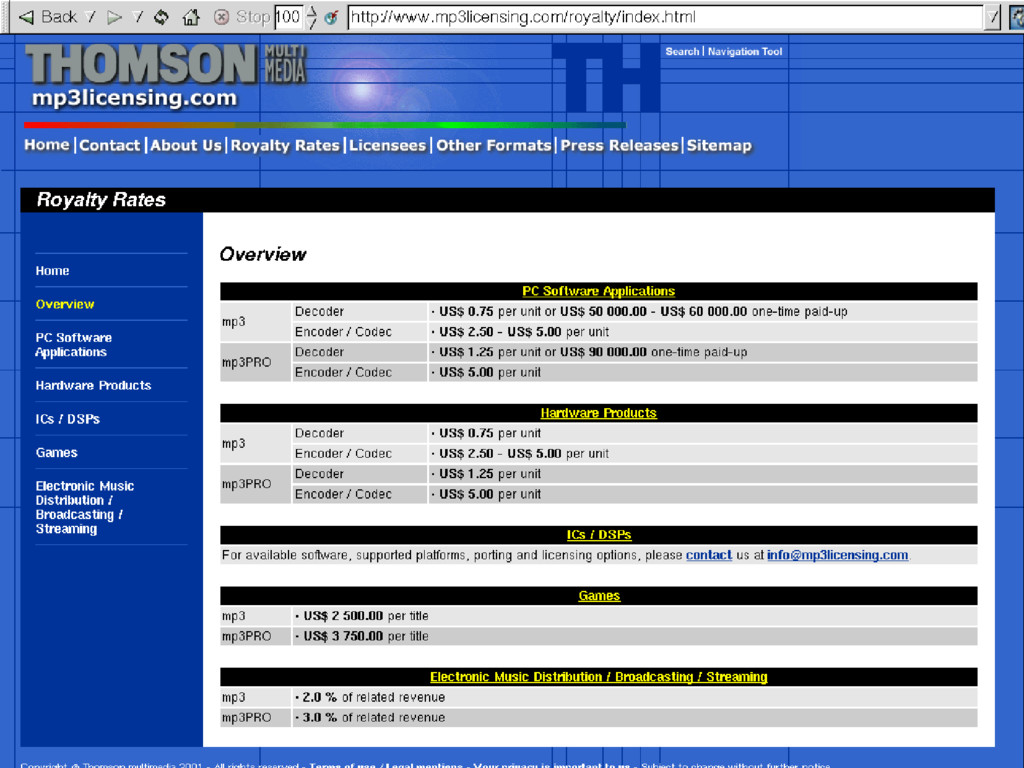
Développé par FhG et AT&T Basé en partie sur le MPEG Layer II THE Internet codec mp3 De-facto mode is stereo at 128 kbit/s High quality at 160 kbit/s
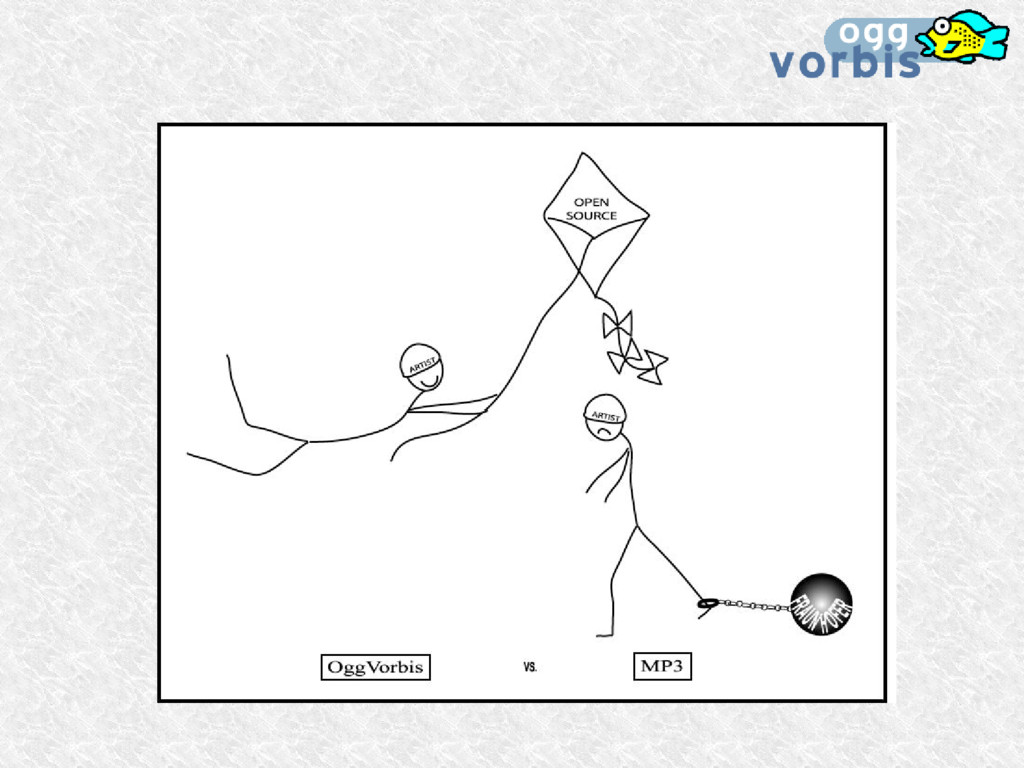
MP3 La plupart de Thompson et Fraunhofer Si l'utilisateur peut en bénéficier gratuitement, Rien ne garantit que cela le restera dans le futur Il n'en est pas de même pour l'encodage...
Développé par Dolby, FhG, AT&T, Sony et d'autres Trois profils: Main, Low complexity, Sampling rate scalable* (Sony)) Twin-VQ (MPEG4 tool) pour les faibles bit-rates* Qualité stéréo HiFi à 128 kbit/s Qualité stéréo mp3-like à 80-96 kbit/s * peu de preuves de réelle efficacité
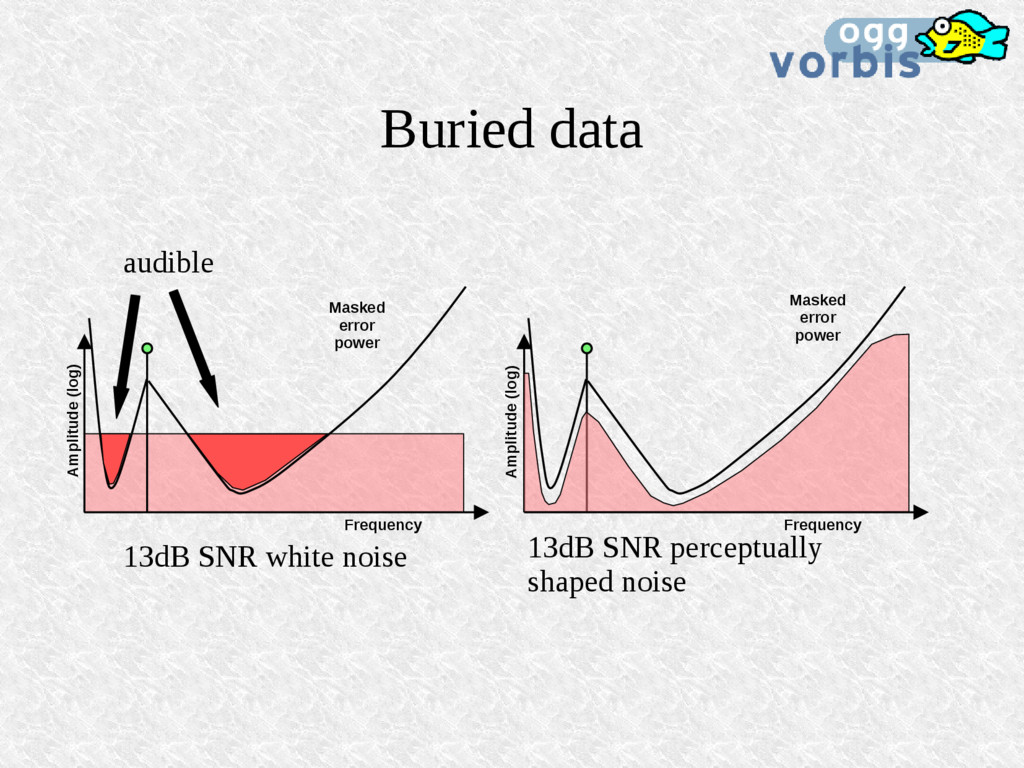
comme le SNR sont sans valeur marketing pour les CODECs audio (SNR 13 dB !) Il faut faire des mesures qui tiennent compte du caractère perceptuel utilisé dans les CODECs Méthode rapide et bon marché pour évaluer les CODECs Où est le meilleur modèle? Dans le CODEC? ou dans l'outil de mesure objectif?
et ouvert pour l'éternité! L'idée initiale a germé en 1993 Le projet Ogg Vorbis a débuté à l'automne 1998, peu après que Fraunhofer décida de reprendre le mp3 et de poursuivre tous les projets libres autour du mp3
un peu programmeurs] qui se sont transformés peu à peu en [programmateurs un peu musiciens]! C'est un exemple typique de la communauté des logiciels libres: Si quelquechose manque, on ne s'en plaint pas, on le crée... Le projet continue à évoluer: meilleur encodeur, outils plus rapides, error correction, etc.
complet, aussi bien pour l'audio que la vidéo (cf Mpeg4) Vorbis et le nom du CODEC audio Xiph est la société hébergeant les principaux développeurs, Xiph nous a déjà donné l'excellent cdparanoia, outil d'extraction audio, sous la license libre GPL. Tarkin est le prochain grand projet de Xiph: avoir également un CODEC libre pour la vidéo Tous ces noms et symboles tordus sont expliqués: http://www.xiph.org/xiphname.html
à l'AAC et au mp3pro? Exemples... Streaming radio avec la BBC... Supporté par de plus en plus de softs: Winamp, Freeamp, JAVA, etc, etc VBR: penser en terme de qualité plutôt que de bitrate (CBR ou ABR)
des transitoires Pourquoi pas tout le temps? La résolution fréquentielle est moins bonne C'est le compromis résolution temporelle <> résolution spectrale
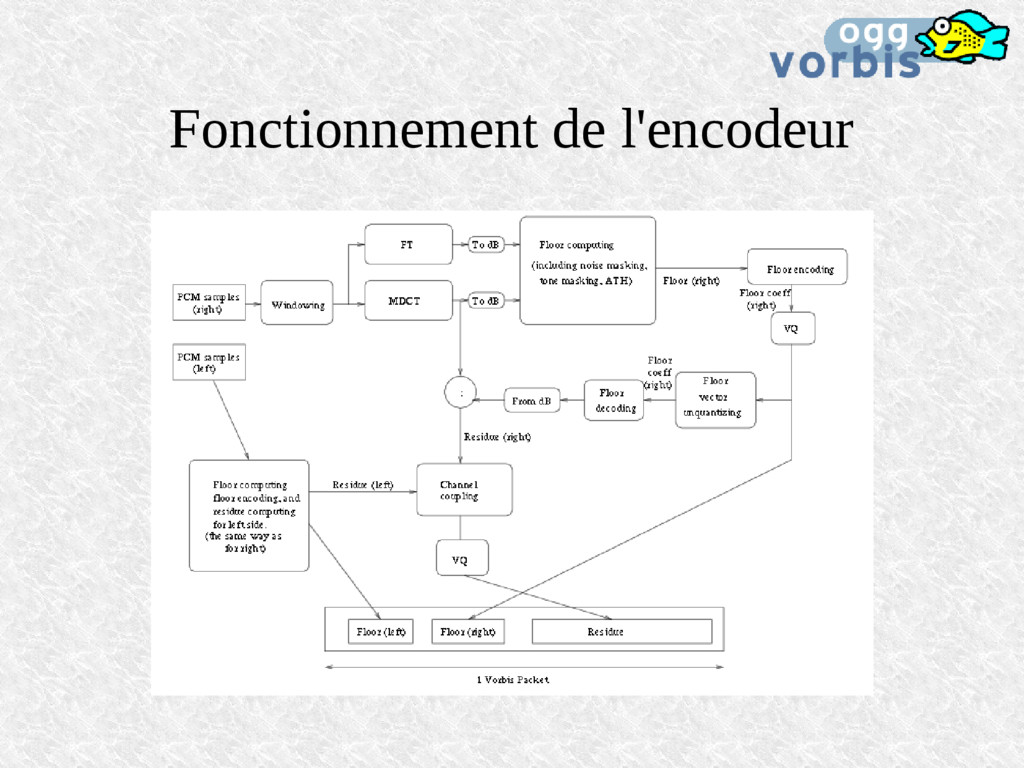
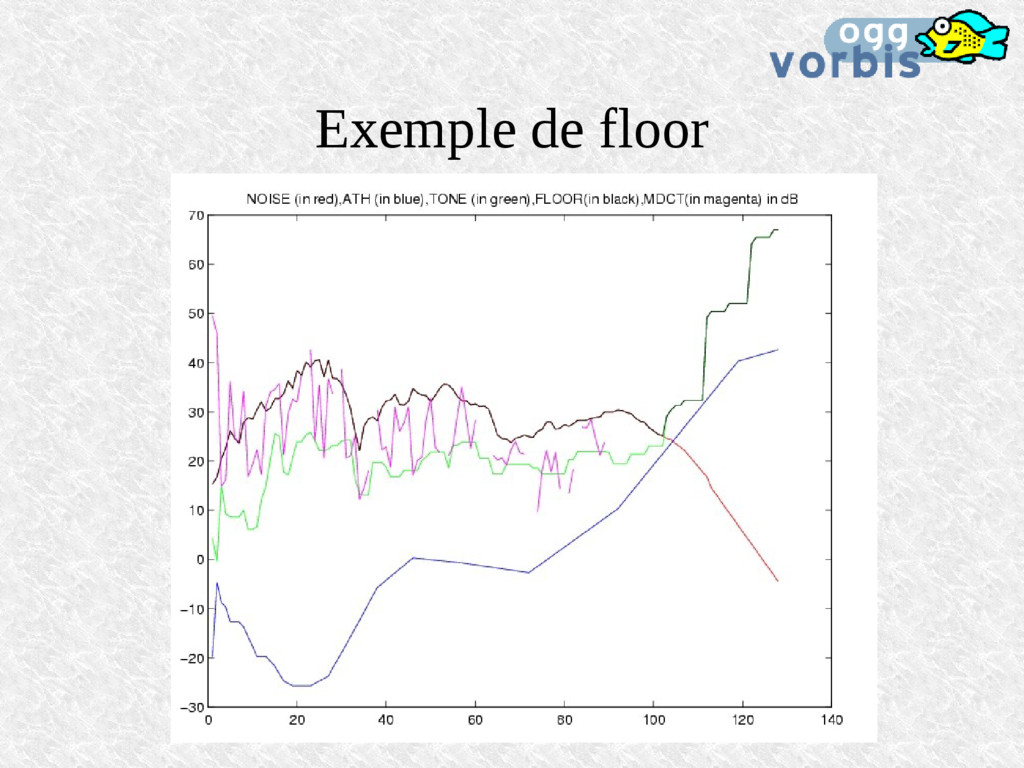
bruit de quantification permis (modèle basé sur les travaux de Robert Ehmer, années '50) Le floor est la courbe maximale de 3 autres: Le max. de masquage par le bruit (cf expérience) Le masquage dû aux sons (tone masking) L'ATH: absolute threshold of hearing en dernier recours, tout en tenant compte que l'utilisateur peut augmenter le son lors des 'blancs'
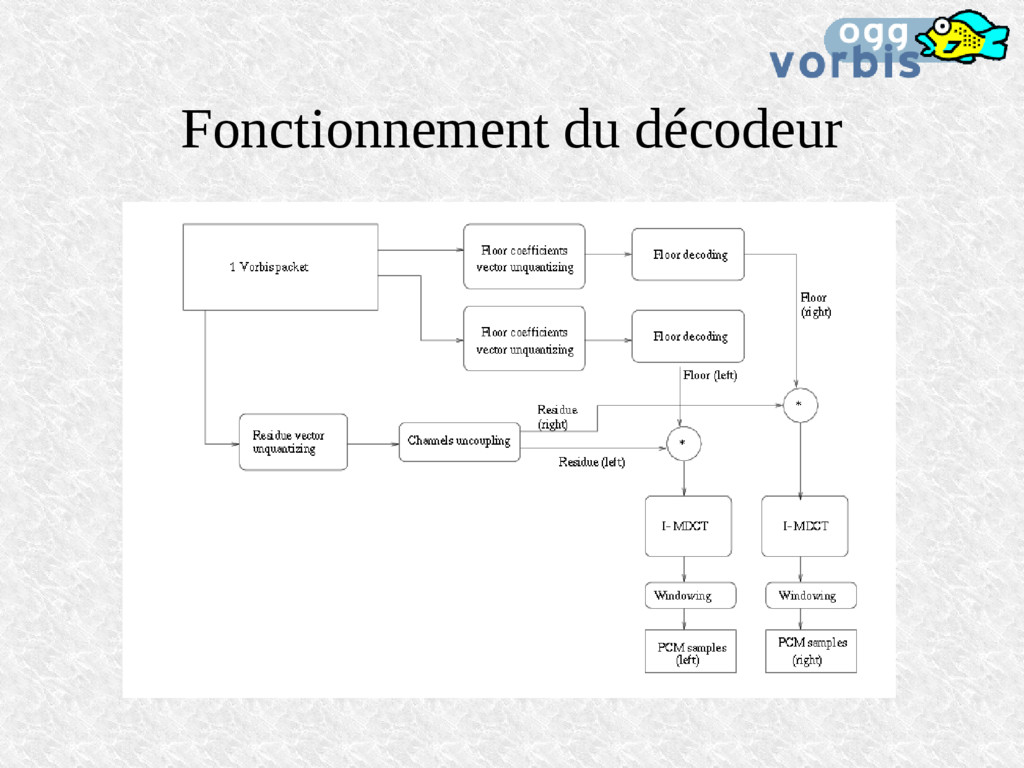
reste à coder les résidus, différence entre le signal original et le floor. Mais le floor sera quantifié dans le bitstream donc on va d'abord calculer cette quantification, se servir de la sortie quantifiée, la décoder puis seulement la soustraire au signal Ainsi l'erreur de quantification du floor ne se répercutera pas sur le calcul des résidus.
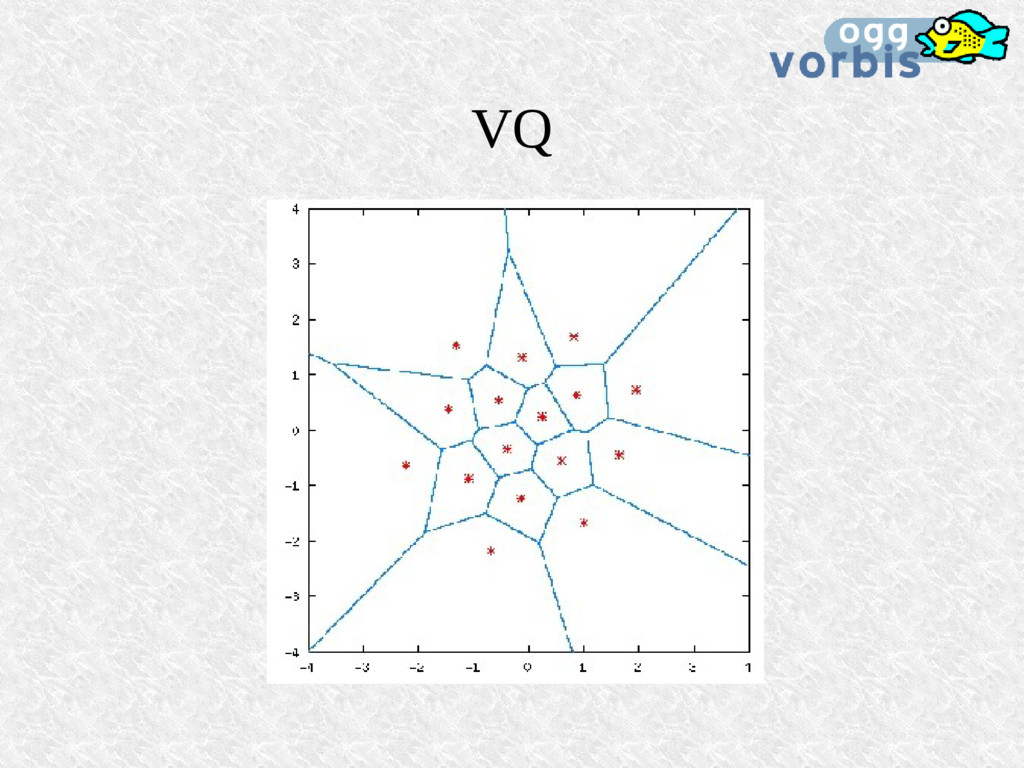
pour chaque canal On peut leur appliquer le channel coupling: Passage en coordonnées polaires rectangulaires L'angle (la phase) est fortement quantifié Puis la quantification vectorielle: Emploi de codebooks joints au bitstream Les mots des codebooks sont choisis selon un arbre d'Huffman
video, ... Ajoute ses propres headers, sorte d'enveloppe supplémentaire autour du bitstream Vorbis Permet le streaming et la re-synchronisation Il est possible de s'en passer: utiliser l'UDP Cf Icecast
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}