Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DMS を使って MySQL のデータを Snowflake に同期する
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
DragonTaro1031
December 10, 2021
2.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
DMS を使って MySQL のデータを Snowflake に同期する
社内の勉強会で話した内容です。
DragonTaro1031
December 10, 2021
More Decks by DragonTaro1031
See All by DragonTaro1031
大規模データを扱うクラウドセキュリティプラットフォームのアーキテクチャ変遷
dragontaro
1
8.7k
CDK で未対応のパラメータを付与する方法
dragontaro
0
230
CloudbaseでのAWS CDKとAWS Step Functionsを用いたバッチ処理基盤の爆速構築
dragontaro
0
590
Redshift から Snowflake に移行した話
dragontaro
2
2.2k
Featured
See All Featured
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.5k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
330
RailsConf 2023
tenderlove
30
1.5k
How to make the Groovebox
asonas
2
2.3k
Building the Perfect Custom Keyboard
takai
2
810
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
220
KATA
mclloyd
PRO
35
15k
How to Ace a Technical Interview
jacobian
281
24k
HDC tutorial
michielstock
2
740
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Transcript
DMS を使って MySQL のデータを Snowflake に同期する AI事業本部 AirTrack 宮川竜太朗
お話する内容 1. DMS とは 2. MySQL と Snowflake を同期するアーキテクチャ 3.
View で MySQL テーブルを復元する 4. DMS の課題点と改善ポイント
1. DMS とは
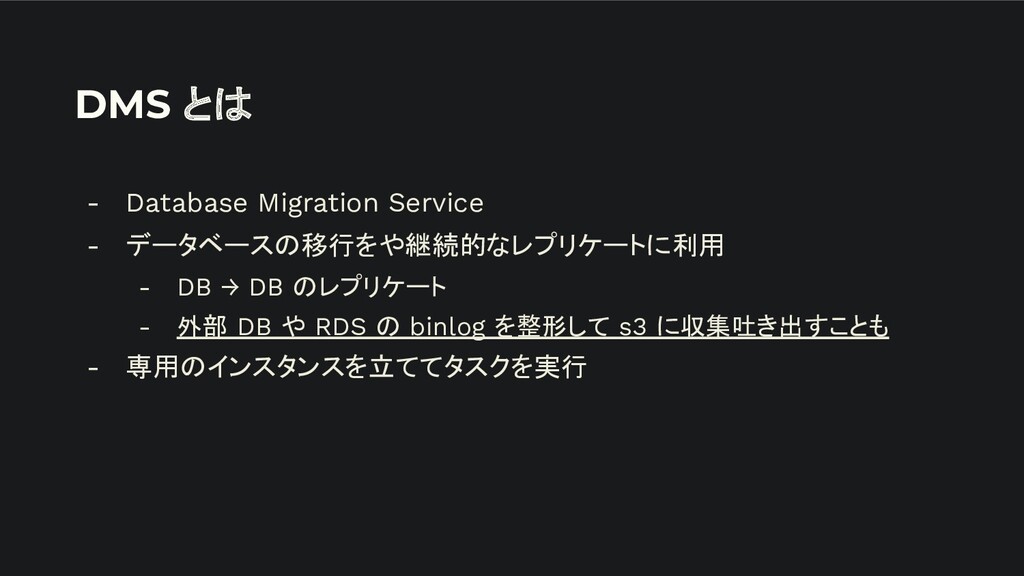
DMS とは - Database Migration Service - データベースの移行をや継続的なレプリケートに利用 - DB
→ DB のレプリケート - 外部 DB や RDS の binlog を整形して s3 に収集吐き出すことも - 専用のインスタンスを立ててタスクを実行
DMS の概要図
s3 への抽出のログフォーマット 以下のテーブルを例に紹介します。
- カラムの情報のみ - ヘッダーなし - /[table名]/LOADXXXX.csv csv の場合(初回ロード時)
- 同じくヘッダーなし - 処理の種類とその時のスナップショット - /[table名]/YYYY/MM/DD/xxx.csv - 先頭に処理の種類が付与 - I:
Insert - U: Update - D: Delete - Insert して Update すると左のように csv の場合(レプリケート時)
parquet の場合 - ターゲットエンドポイントを設定することで利用可 能 - csv 同様に - 初回ロード時は全テーブルデータのみ
- レプリケーション時は テーブルデータ + オペレーションタイプ - parquet なのでもちろんカラムのデータも ※ json で表示
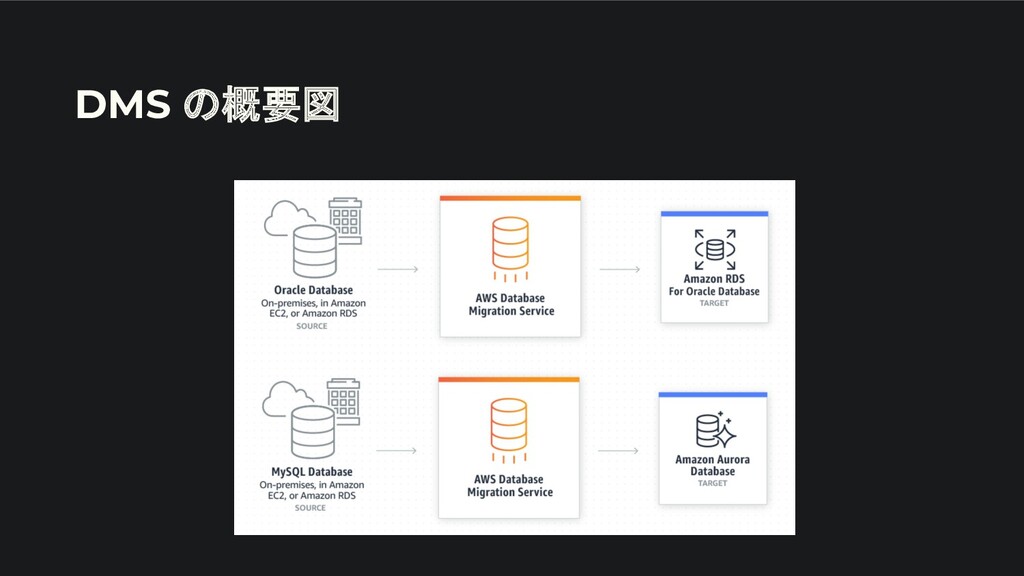
2. MySQL と Snowflake を同期する アーキテクチャ
MySQL と Snowflake を同期するアーキテクチャ
3. View で MySQL テーブルを復元する
View で MySQL を再現する手順 1. DMS でタスクを定期実行する 2. ログテーブルを作成する 3.
初回データを Snowflake に一気に入れる 4. SnowPipe で s3 のログデータを継続的に取り込む 5. View でログデータの順序から現在の状態を再現する
DMS でタスクを定期実行する - レプリケーションインスタンス - 移行タスクを実行するための専用インスタンス - ソースエンドポイント - MySQL
- binlog_format を RAW にするなど制約あり - ターゲットエンドポイント - s3 - パスとファイルフォーマットの指定
MySQL と Snowflake を同期するアーキテクチャ
DMS でタスクを定期実行する - ソース・ターゲット・レプリケーションインスタンスを指定 - 対象テーブルのフィルター - 移行タイプの選択(既存の移行とレプリケートを今回は選択)
ログテーブルを作成する - View を構築するためのメタデータも必要 - 何のアクション(Insert or Update or ...)なのか
- 変更が加えられた順序をどう保証するのか - 順序を保証するためにログ作成時間とログファイルの行数を取る - DMS のファイル名 (metadata$file_name) から日付をパース - 行数は metadata$file_row_number
ログテーブルを作成する
初回データを Snowflake に一気に入れる - 初回ロード分に関しては I や U はつかない -
type: ‘L’ として取り込む
SnowPipe で継続的に取り込む - s3 に吐かれたログデータを Snowflake に取り込む - 初回ロード分を除く -
実行されたアクションの取り込み - メタデータの取り込み - ファイル作成日 - 行番号
SnowPipe で継続的に取り込む
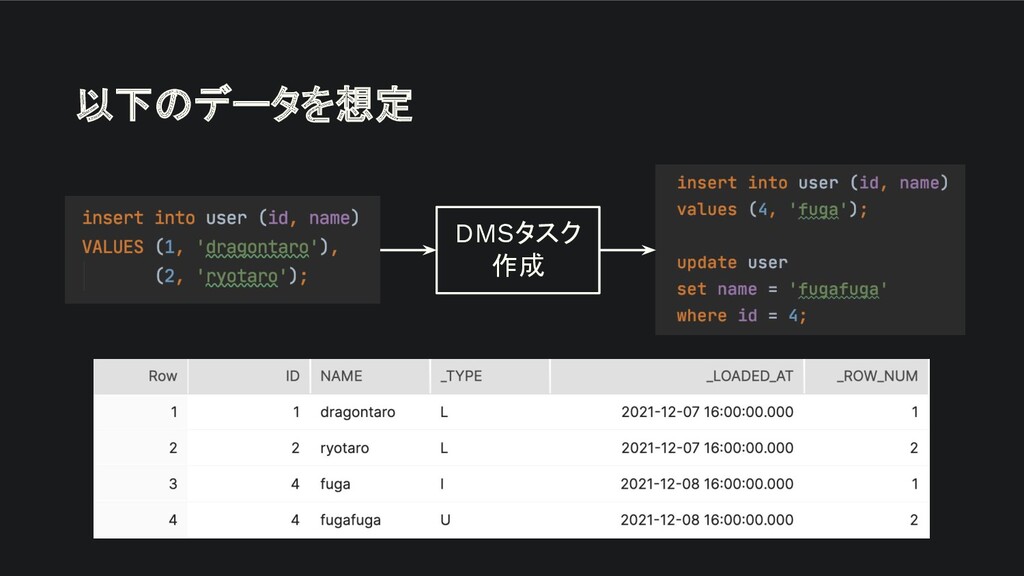
生ログから View を構築する - それぞれのログがレコードのスナップショット - メタデータから最新の状態を判断して取り出す
以下のデータを想定 DMSタスク 作成
生ログから View を構築する
4. DMS の課題点と改善ポイント
DMS の課題点と改善ポイント - csv で s3 に吐かれるため変更に弱い - parquet を指定するオプションがあるが頭が回ってなかった
- 停止・再開の挙動がよくわからない - チェックポイントがあるがトランザクション中なら壊れるらしい - 毎回新しい DMS タスクとテーブルを作った方が安全では? - エラーが起きたときの対応方法が掴めていない - 今のところエラーなく動いてくれてるからいいけど。。
おまけ
ちなみに Firebase なら。。 - Firestore のデータをポチポチで BQ に同期してくれます!? - しかも
view も自動で構築してくれます!? - レコード自体は json で入れられるのでパースが面倒だが。。 - スキーマがないからそうするしかないよね
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![- カラムの情報のみ - ヘッダーなし - /[table名]/LOADXXXX.csv csv の場合(初回ロード時)](https://files.speakerdeck.com/presentations/c0cf0c0f37344550941908a68fc9695e/slide_6.jpg){kind=link}
![- 同じくヘッダーなし - 処理の種類とその時のスナップショット - /[table名]/YYYY/MM/DD/xxx.csv - 先頭に処理の種類が付与 - I:](https://files.speakerdeck.com/presentations/c0cf0c0f37344550941908a68fc9695e/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}