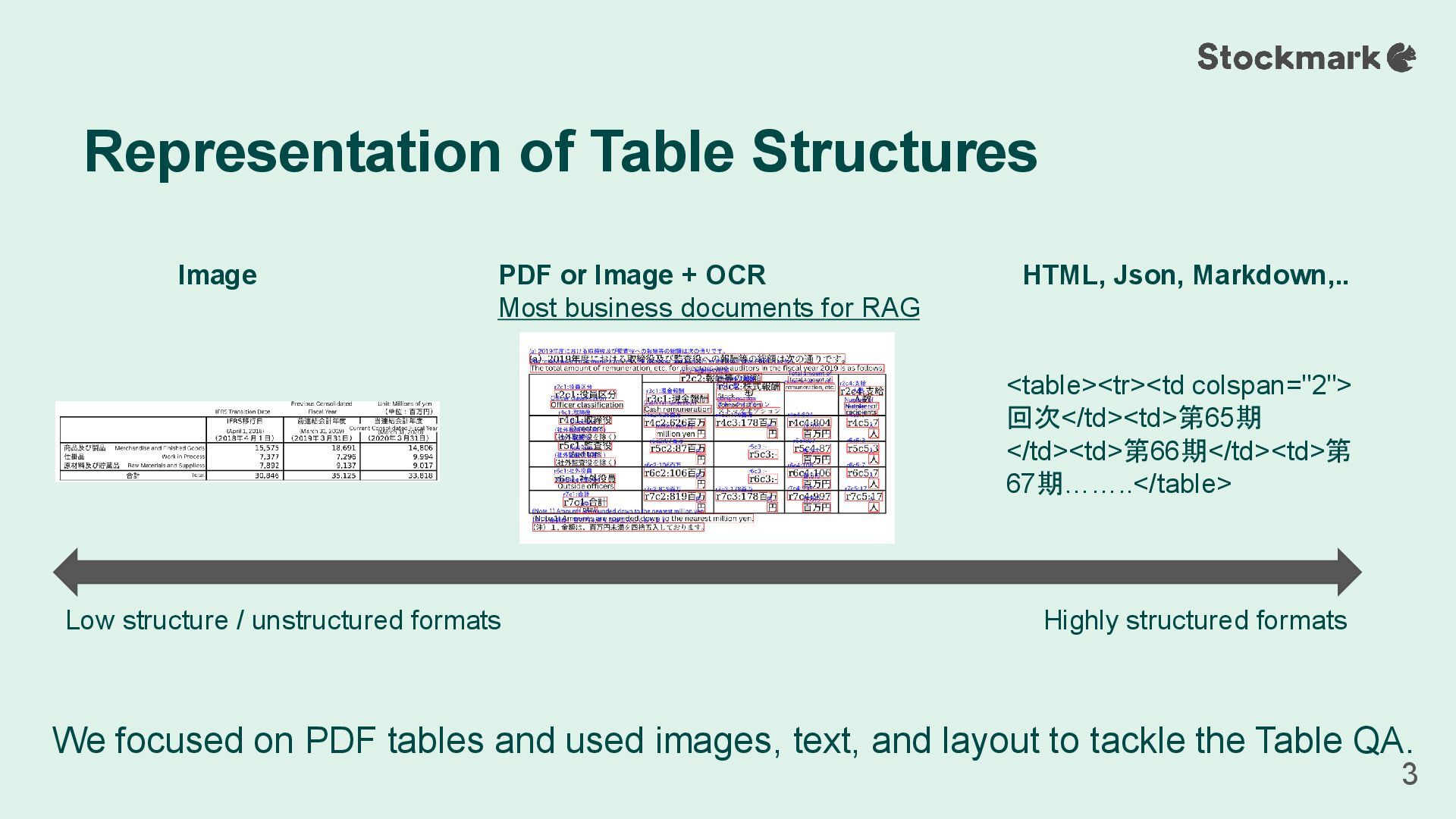
• This poses a major challenge for practical RAG systems • LVLMs offer a format-agnostic approach by treating any table as an image • However, their accuracy remains a critical hurdle for real-world use • Goal: Enhance LVLM table understanding by adding modalities to complement the image Motivation 2 Clean HTML structure (Given in NTCIR18-U4, Table QA dataset) Real-world input format (Our challenge) <table><tr><td colspan="2">回次</td><td>第65 期</td><td>第66期</td><td>第67期</td><td>第 68期</td><td>第69期</td></tr><tr><td colspan="2">決算年月</td><td>2016年1月 </td><td>2017年1月</td><td>2018年1月 </td><td>2019年1月</td>……..</table>
layout to tackle the Table QA. Representation of Table Structures 3 Highly structured formats Low structure / unstructured formats <table><tr><td colspan="2"> 回次</td><td>第65期 </td><td>第66期</td><td>第 67期……..</table> HTML, Json, Markdown,.. Image PDF or Image + OCR Most business documents for RAG
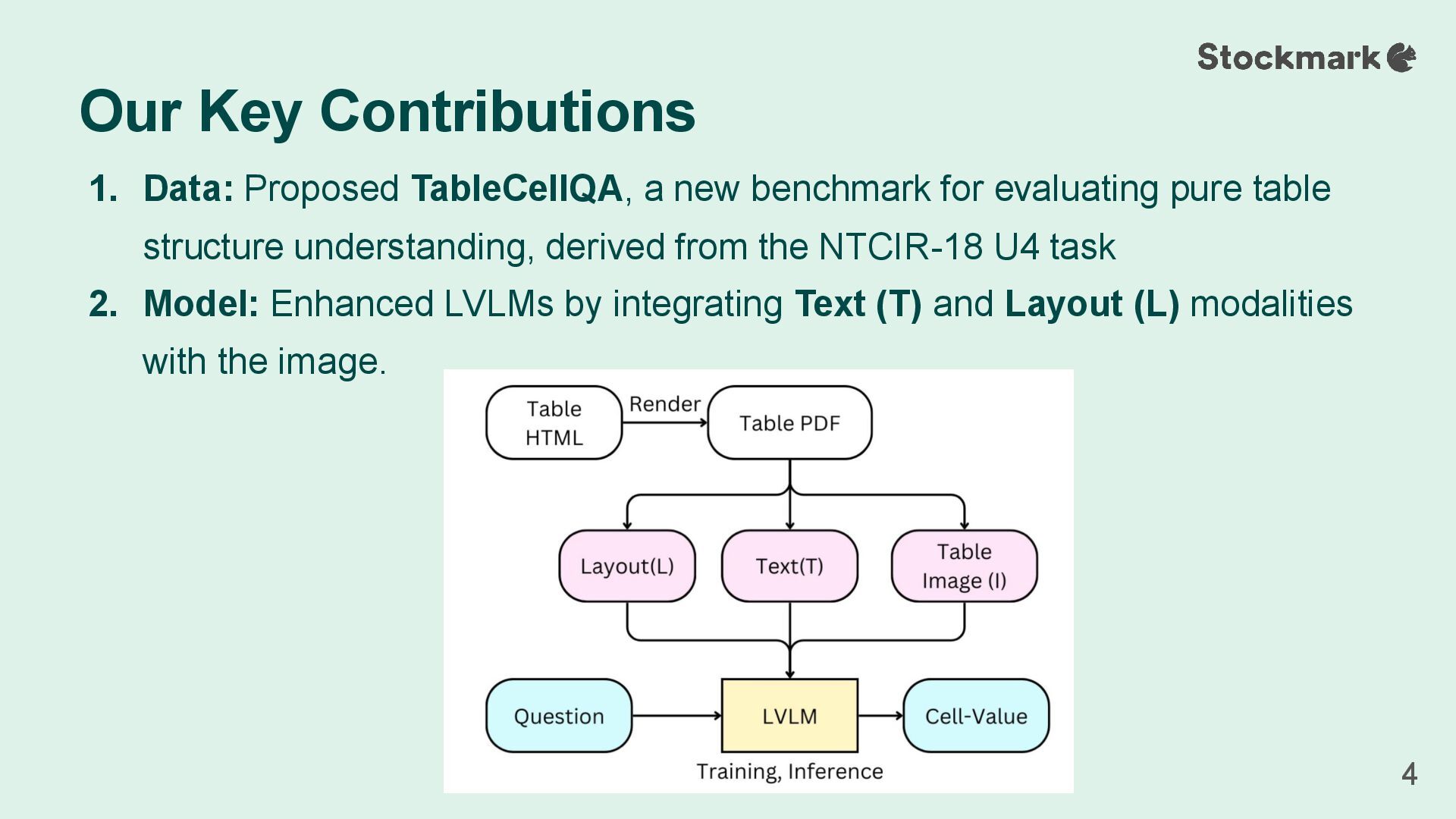
table structure understanding, derived from the NTCIR-18 U4 task 2. Model: Enhanced LVLMs by integrating Text (T) and Layout (L) modalities with the image. Our Key Contributions 4
Our Goal: To create a task that purely evaluates a model's ability to understand table structure, separate from its reasoning skills Our Solution (TableCellQA): The answer is always the raw value of a single cell, with no calculations needed. Task Definition: TableCellQA 5
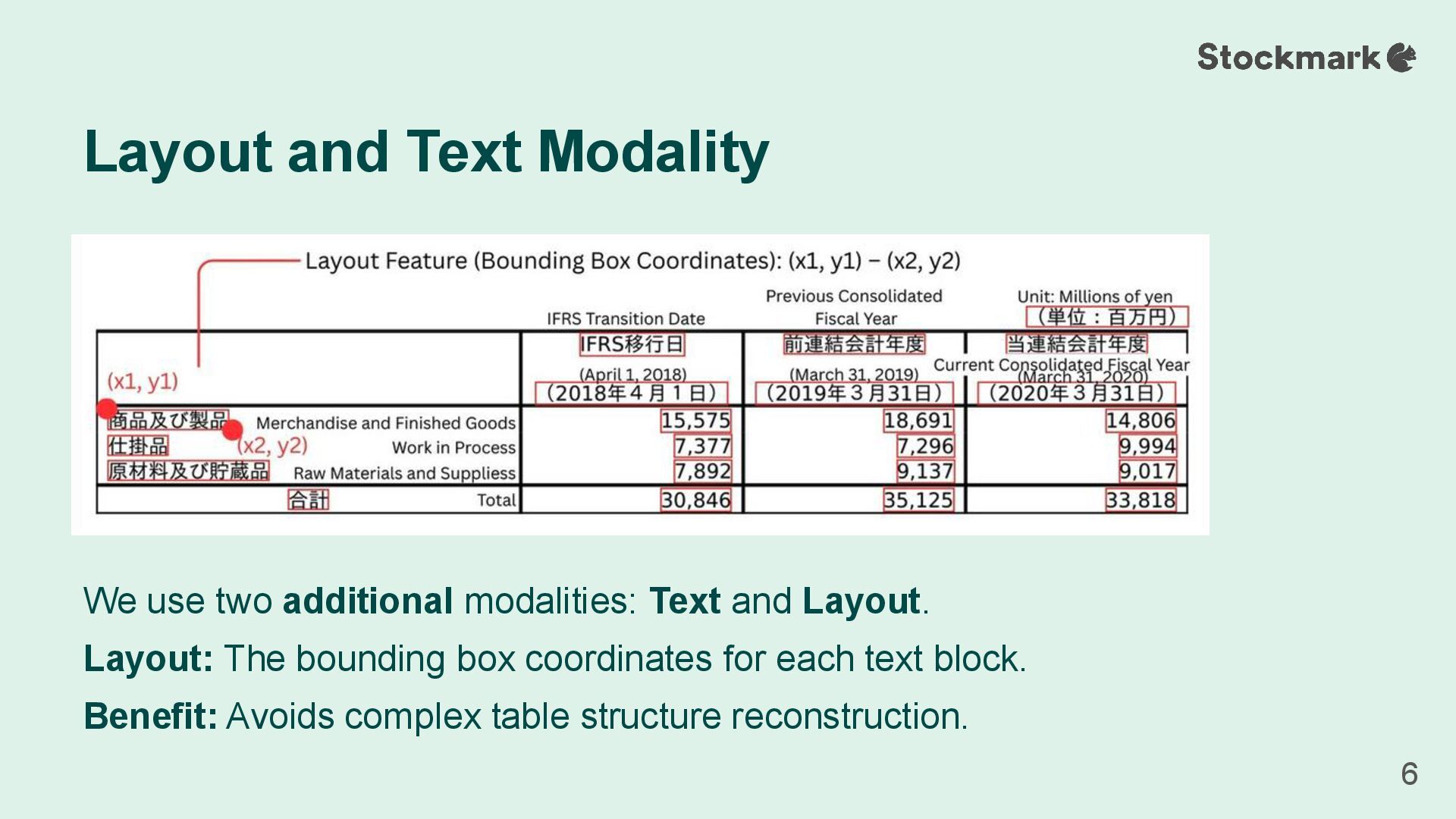
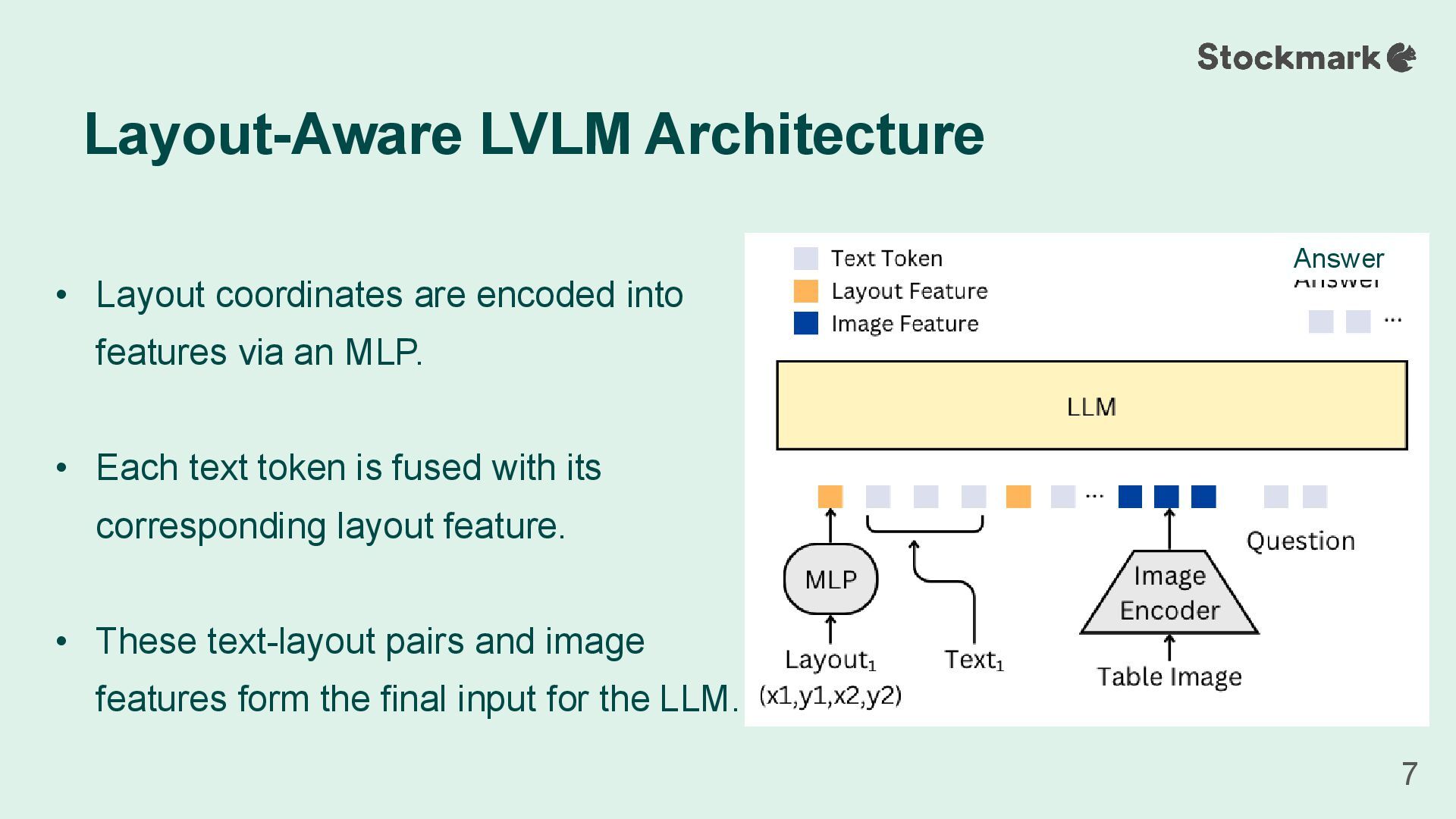
• Each text token is fused with its corresponding layout feature. • These text-layout pairs and image features form the final input for the LLM. Layout-Aware LVLM Architecture 7 Answer
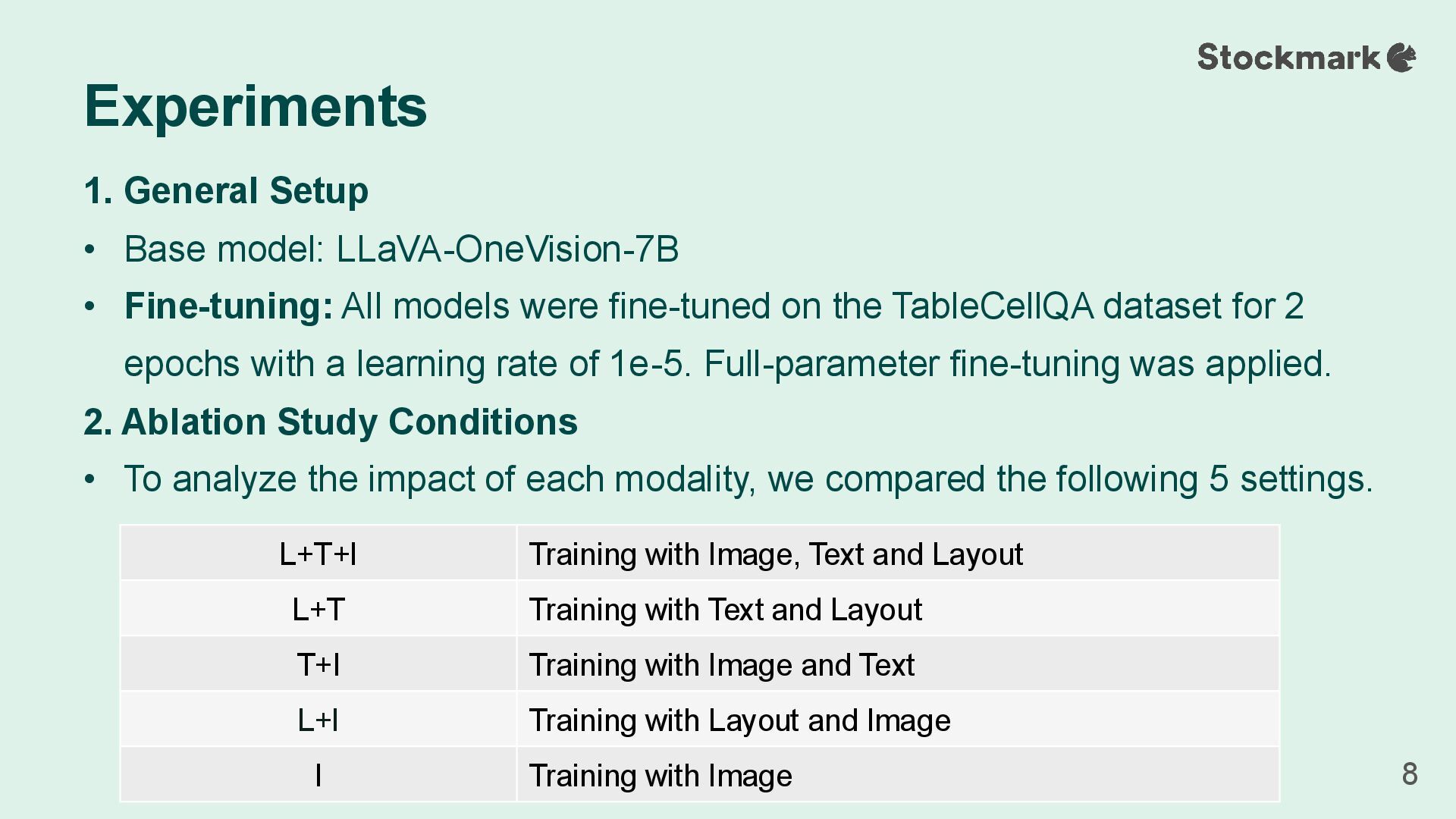
models were fine-tuned on the TableCellQA dataset for 2 epochs with a learning rate of 1e-5. Full-parameter fine-tuning was applied. 2. Ablation Study Conditions • To analyze the impact of each modality, we compared the following 5 settings. Experiments 8 L+T+I Training with Image, Text and Layout L+T Training with Text and Layout T+I Training with Image and Text L+I Training with Layout and Image I Training with Image
dense text. Without Text: Image-only model (I): Susceptible to minor recognition errors With Text + Layout: Providing clean text data: Bypasses visual errors, leading to correct value extraction. Case Study 2: Why Text Modality is Crucial 11
• However, this clean data is unavailable in most real-world documents like PDFs. • Our L+T+I model's performance is remarkably close to this upper bound, making it a practical substitute. Comparison with structured Table 12 0.876 0.948 0.954 0.956 0.966 0.914 0.967 0.966 0.969 0.976 0 0.2 0.4 0.6 0.8 1 I L+T+I Markdown JSON HTML ANLS Acc.
structured text (like HTML) still achieves the highest absolute performance when available. • While our LVLM architecture has potential for visual elements like figures, the scope of the TableCellQA dataset currently limits our evaluation to text- based tables. Future Work • Robustness for Noisy Documents: By exploring end-to-end models or enhanced OCR. Limitations / Future Work 13
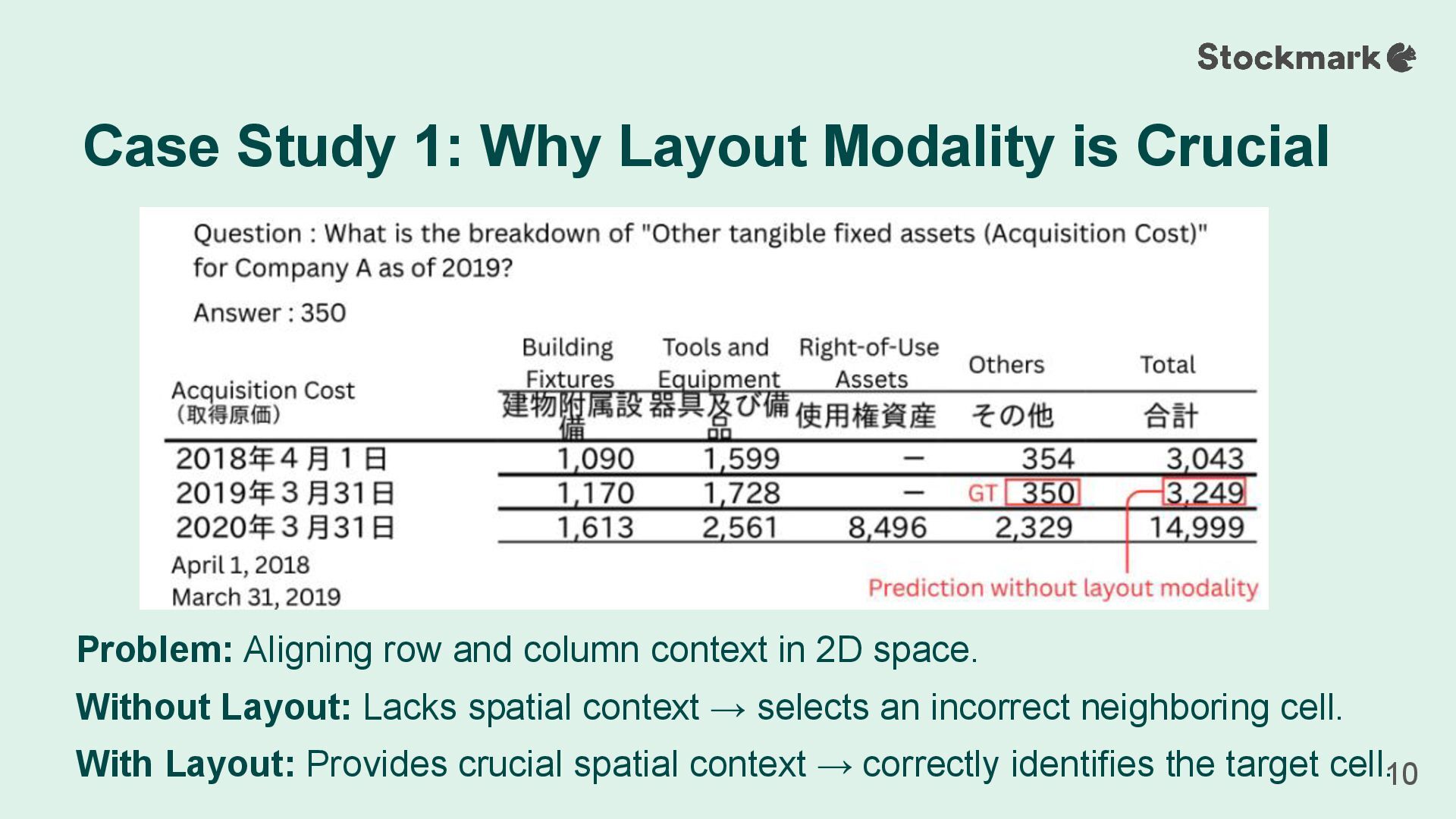
Layout (L) modalities significantly improves table question answering performance. • Our analysis revealed a clear hierarchy of importance for accuracy: Text > Layout > Image. • Our multimodal approach serves as a practical intermediate solution, bridging the gap between image-only models and methods that require perfectly structured data. Conclusion 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}