in image or PDF format Challenge: RAG needs robust table handling across formats Our approach: render HTML → solve as multimodal QA Goal: develop a practical method usable in business RAG Motivation 2 Clean HTML structure (Given in U4 task) Real-world input format (Our challenge) <table><tr><td colspan="2">回次</td><td>第65 期</td><td>第66期</td><td>第67期</td><td>第 68期</td><td>第69期</td></tr><tr><td colspan="2">決算年月</td><td>2016年1月 </td><td>2017年1月</td><td>2018年1月 </td><td>2019年1月</td>……..</table>
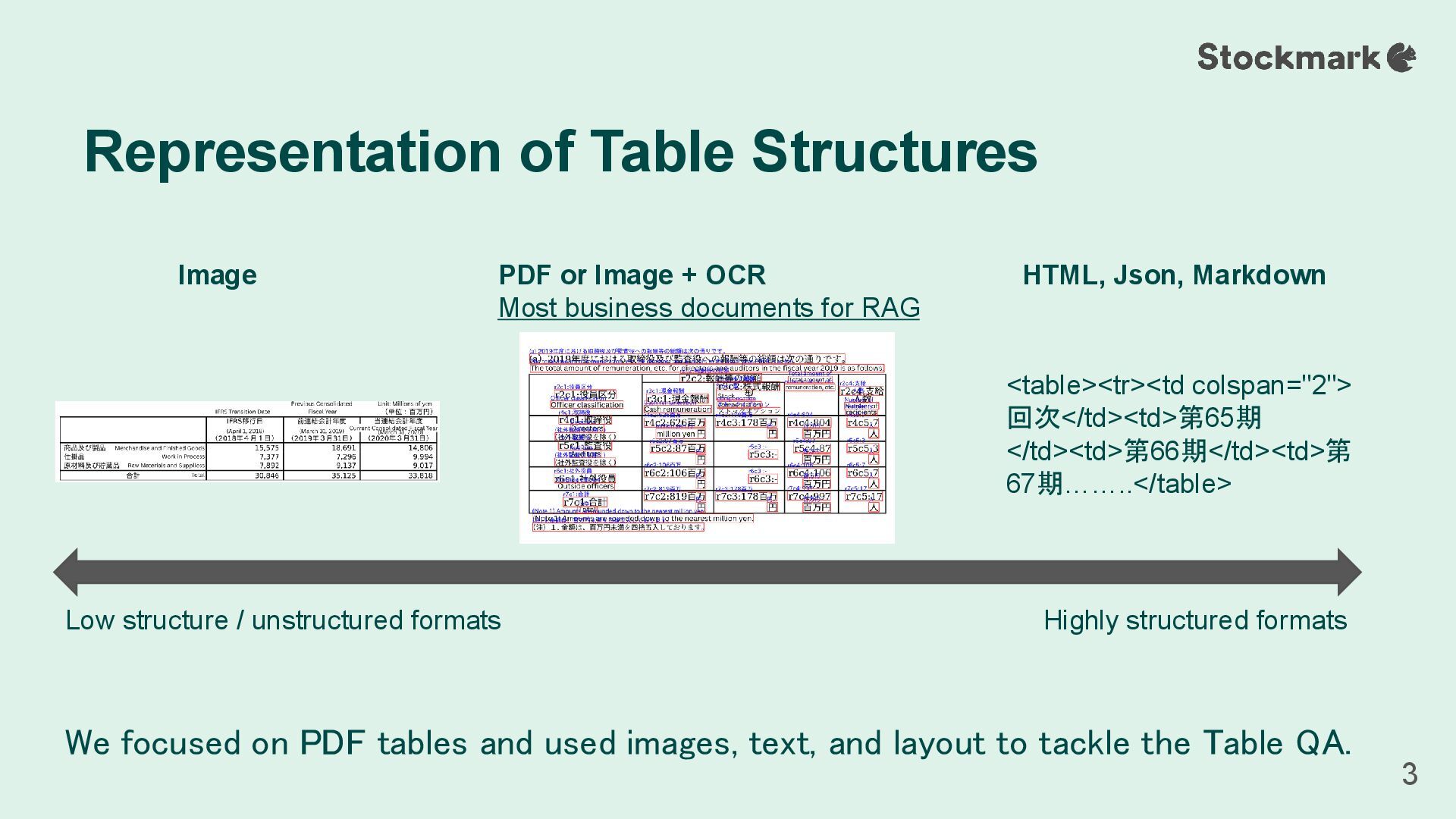
layout to tackle the Table QA. Representation of Table Structures 3 Highly structured formats Low structure / unstructured formats <table><tr><td colspan="2"> 回次</td><td>第65期 </td><td>第66期</td><td>第 67期……..</table> HTML, Json, Markdown Image PDF or Image + OCR Most business documents for RAG
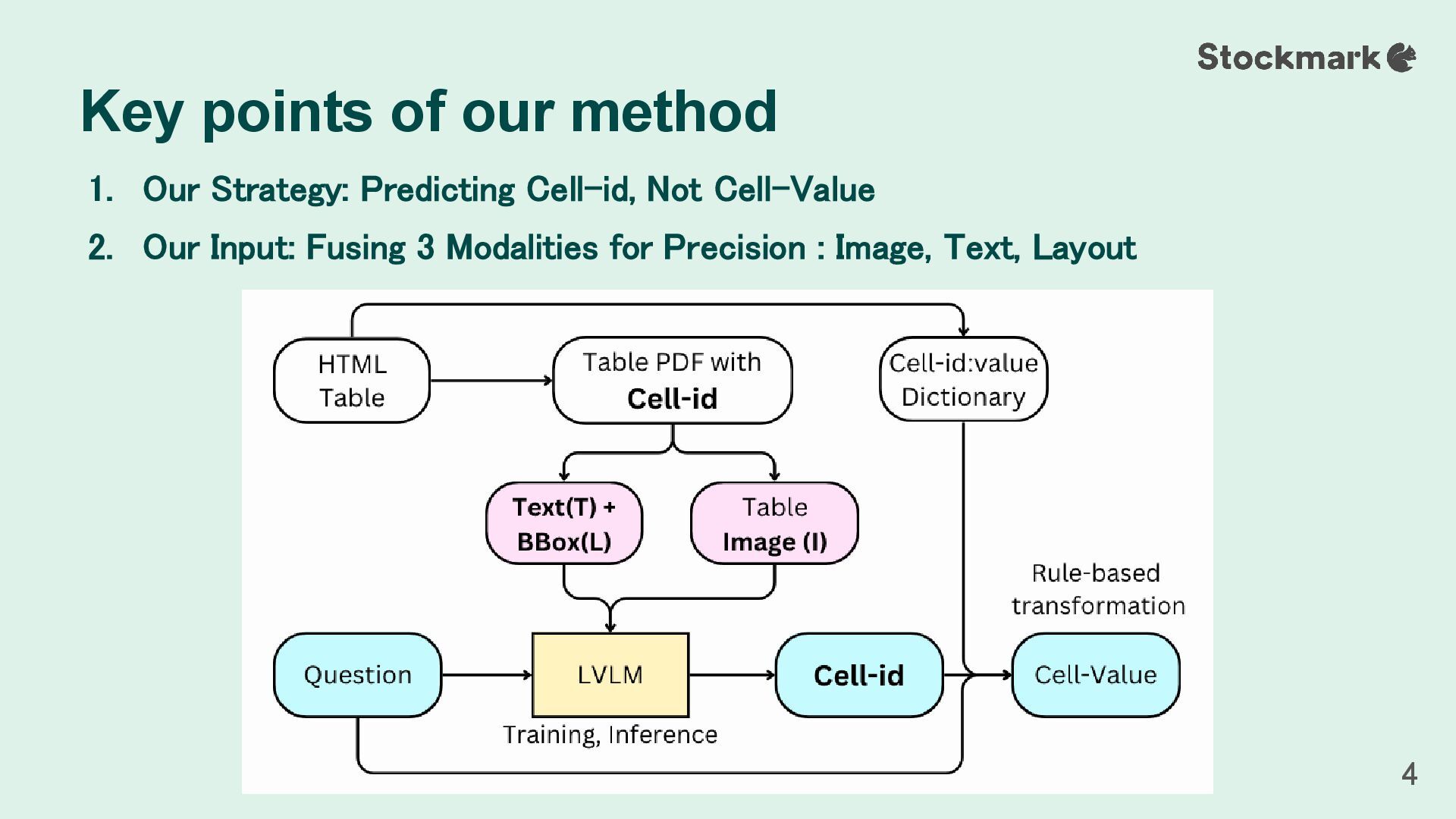
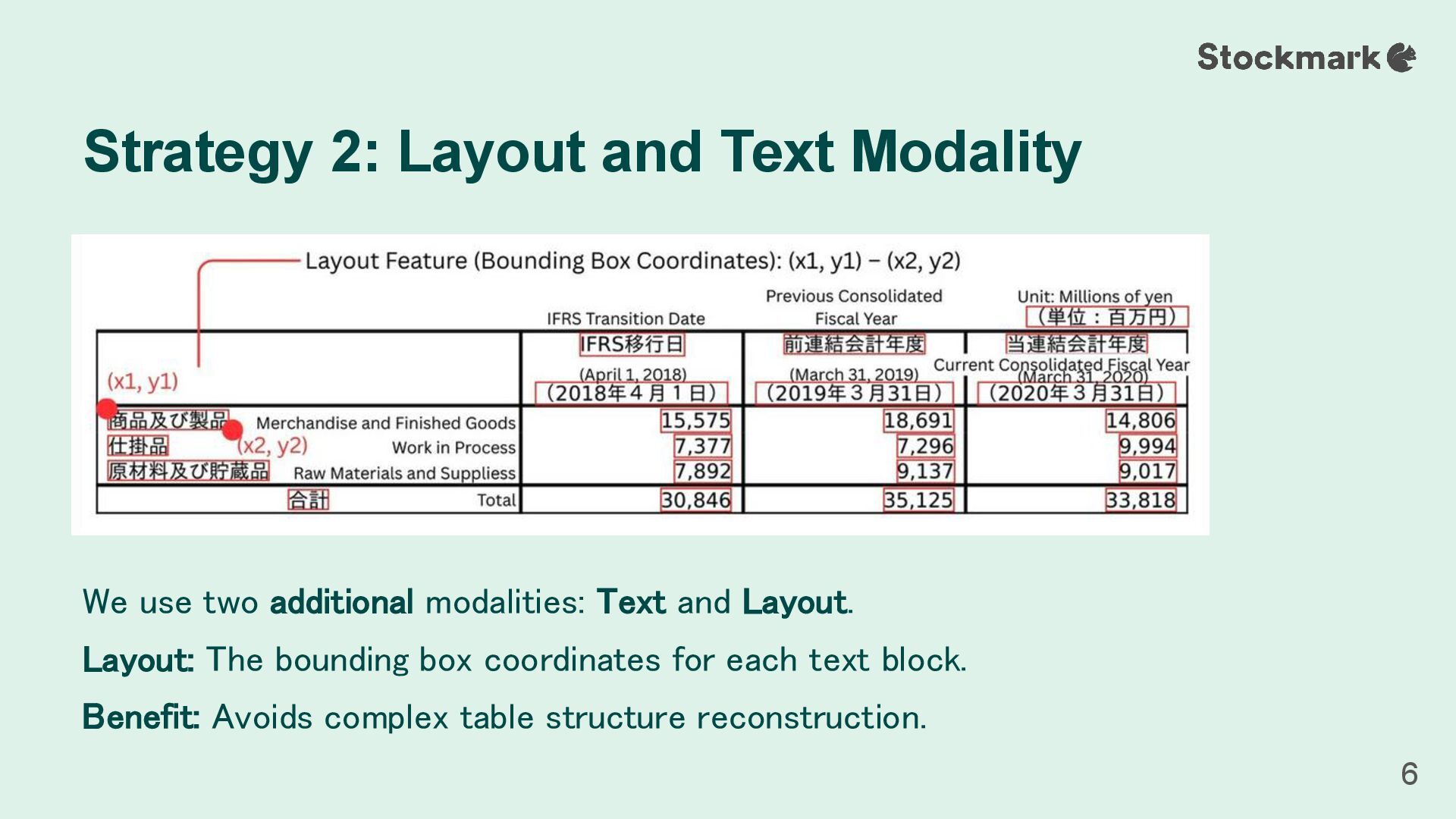
in math. Cell-IDs (e.g., “r3c1”) are rendered directly onto the table image as visual objects. This transforms the QA task into a more straightforward visual recognition problem. Strategy 1: Cell-ID Embedding 5
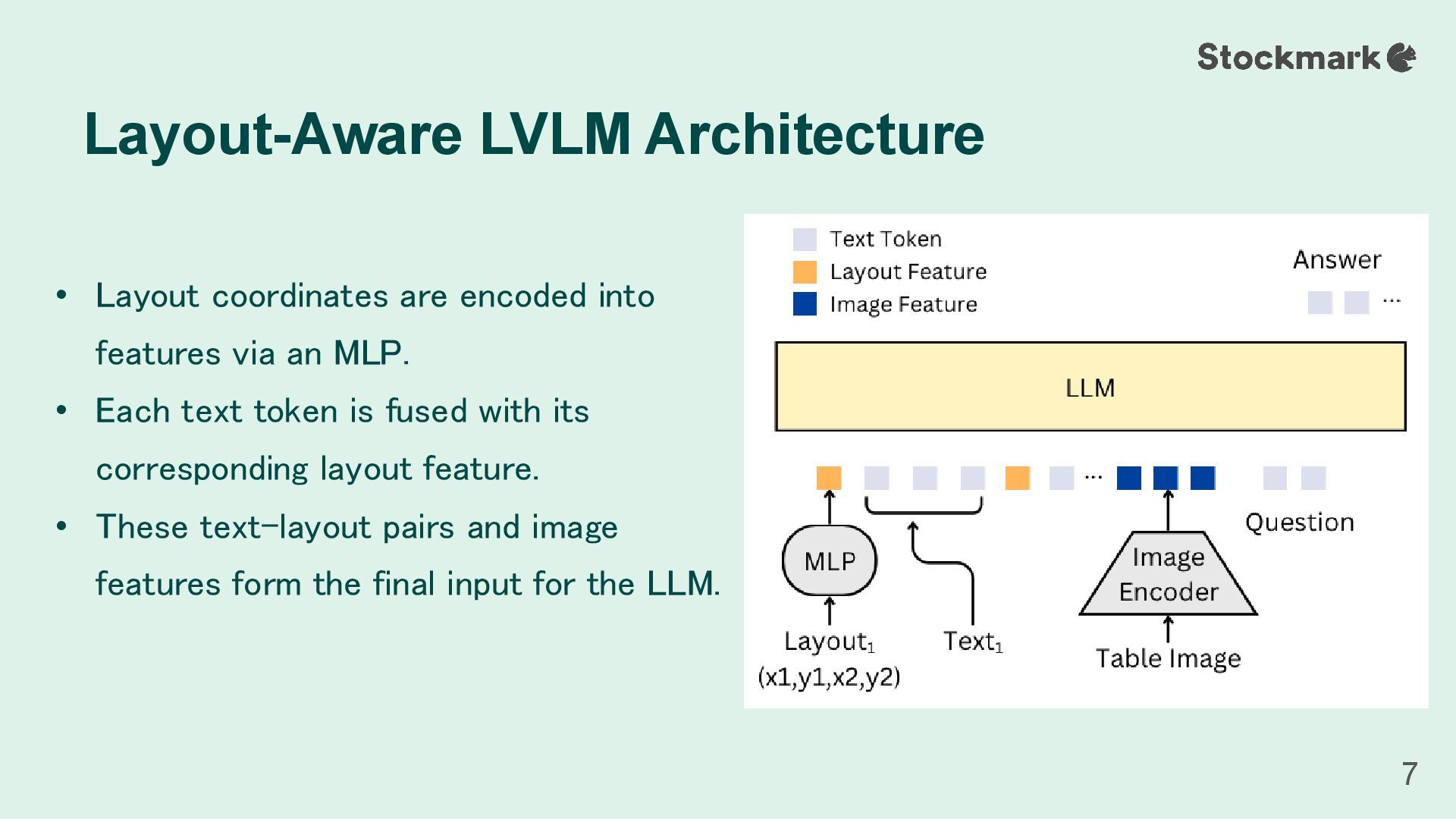
• Each text token is fused with its corresponding layout feature. • These text-layout pairs and image features form the final input for the LLM. Layout-Aware LVLM Architecture 7
models were fine-tuned on the Table QA dataset for 3 epochs with a learning rate of 1e-5. 2. Ablation Study Conditions • To analyze the impact of each modality, we compared the following four settings. Experiments 8 I+T+L Training with Image, Text and Layout T+L Training with Text and Layout I+T Training with Image and Text I Training with Image w/o Pre-Training
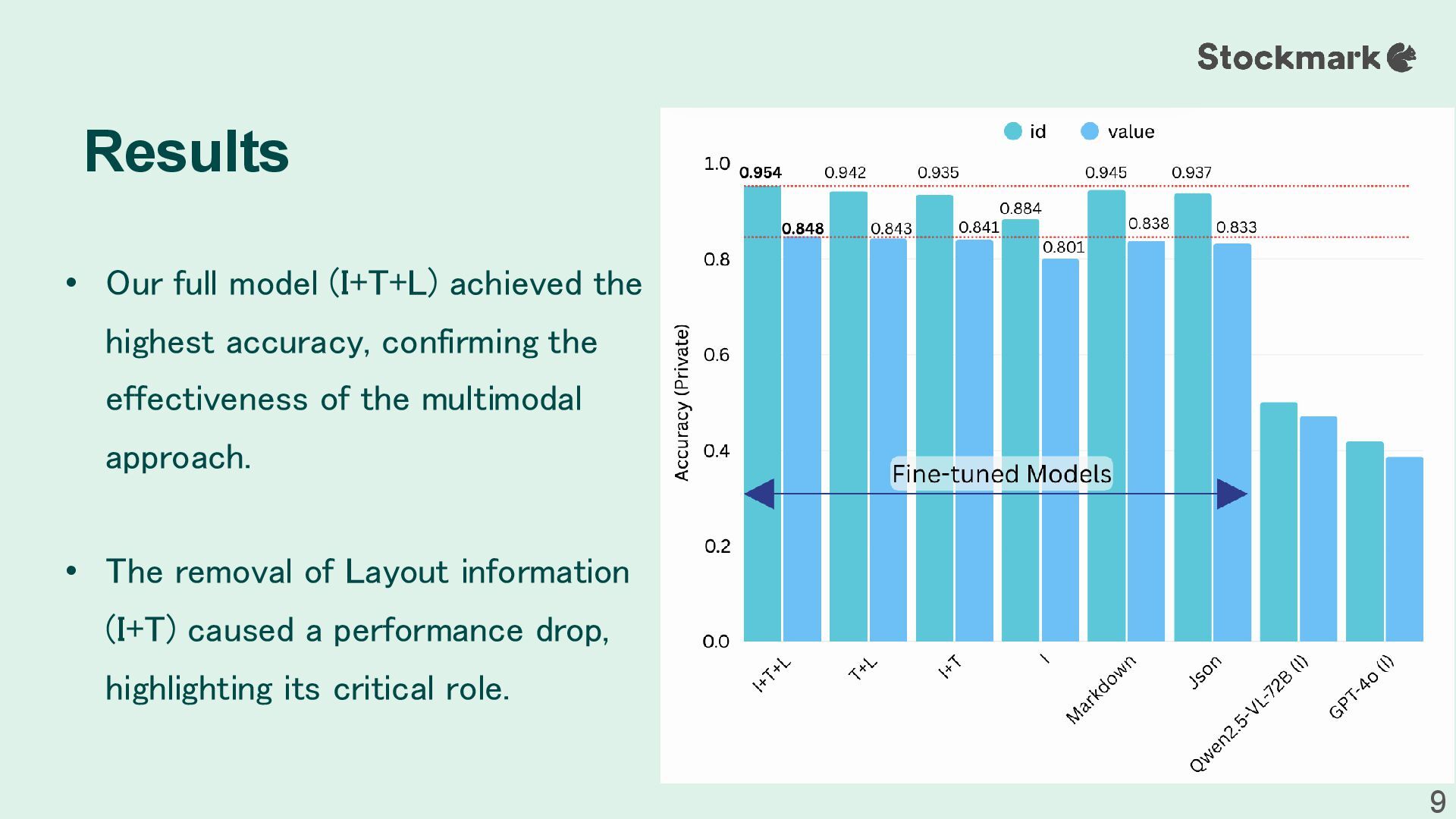
the effectiveness of the multimodal approach. • The removal of Layout information (I+T) caused a performance drop, highlighting its critical role. Results 9
Without Layout: The model is misled by the inconsistent cell-id. With Layout: Bounding box coordinates reveal the true table structure. Case Study: Why Layout Modality is Crucial 10 r2c4 r6c5
documents. • Assumption of Clean Text: Not robust to noisy or handwritten tables with OCR errors. Future Work • Direct Value Prediction: To eliminate the dependency on cell-ids. • Robustness for Noisy Documents: By exploring end-to-end models or enhanced OCR. Limitations / Future Work 11
task, integrating Image, Text, and Layout information. • Our experiments showed this method is highly effective, with Text and Layout proving to be the most critical modalities for achieving high accuracy. • This study highlights that combining visual, textual, and spatial context is key to robustly understanding complex structured data. Conclusion 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}