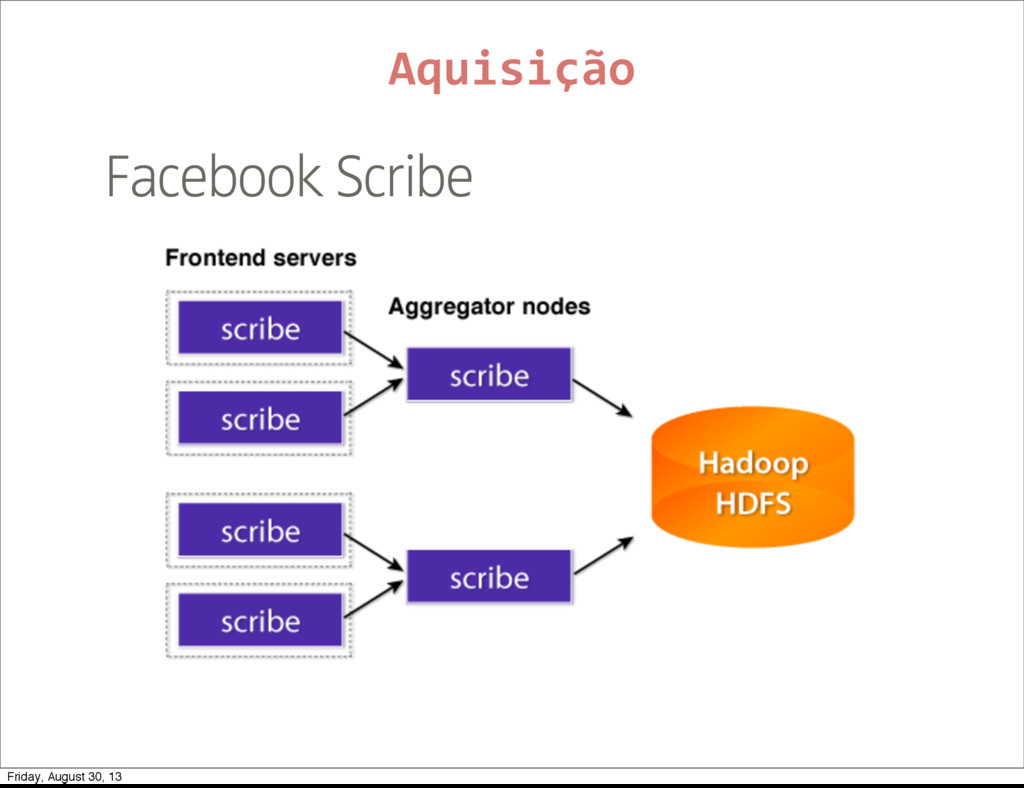
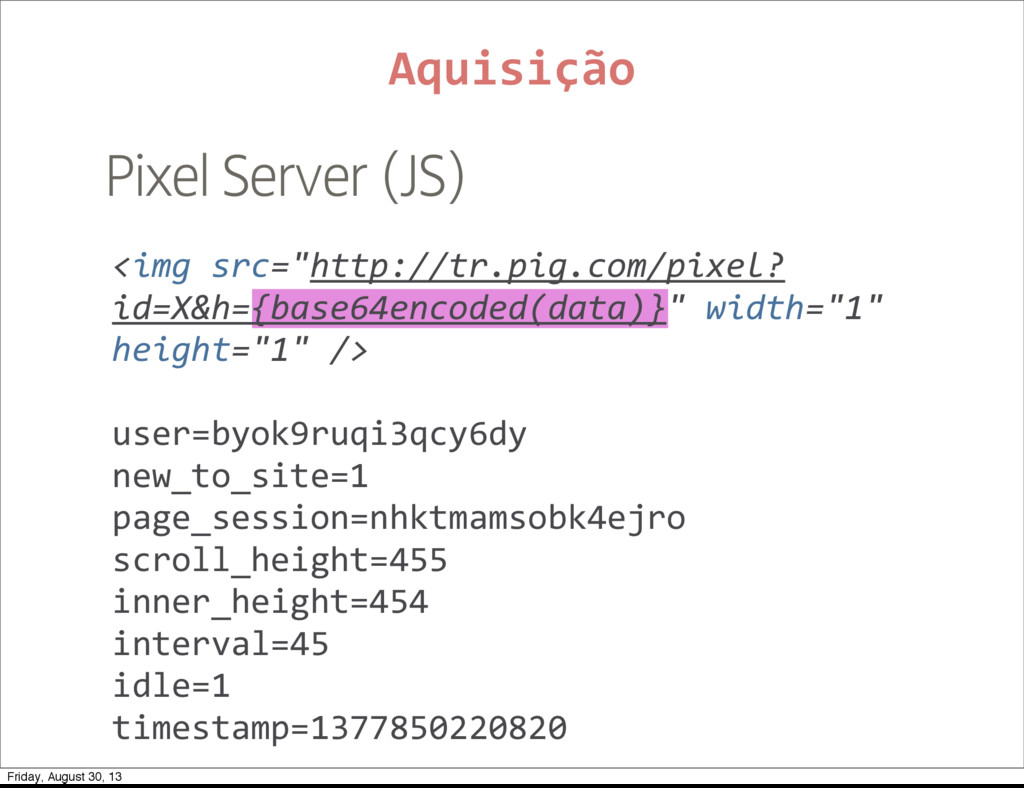
Foursquare ‣ Google Analytics Aquisição * Facebook tende a dificultar as coisas de tempos em tempos. Então temos que tomar cuidado com features cruciais dependentes do facebook. Friday, August 30, 13
fd = urlib.urlopen(url) content = fd.read() links = parse_links(content) for link in links: queue.put(link) crawler(queue) Aquisição Um crawler minimalista Friday, August 30, 13
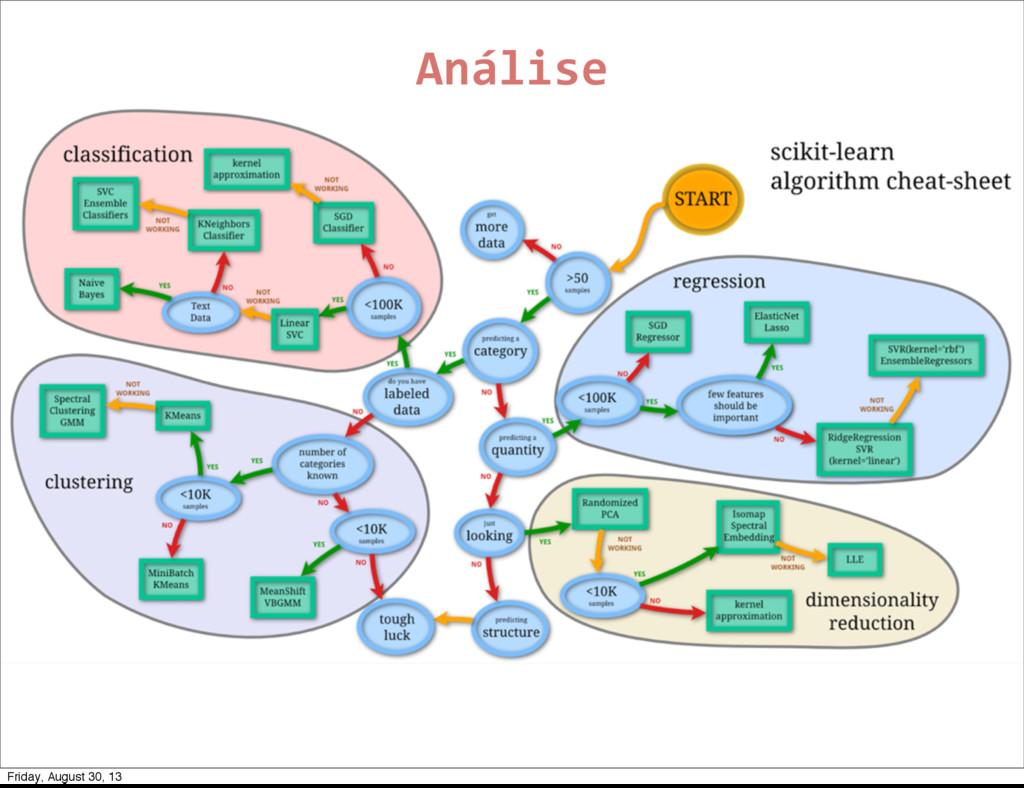
de uma fonte de dados. ‣ Redes Neurais ‣ Max de Expectativas (distrib) ‣ K-means (centroides) ‣ DBSCAN (densidade) ‣ Graph Based Models Friday, August 30, 13
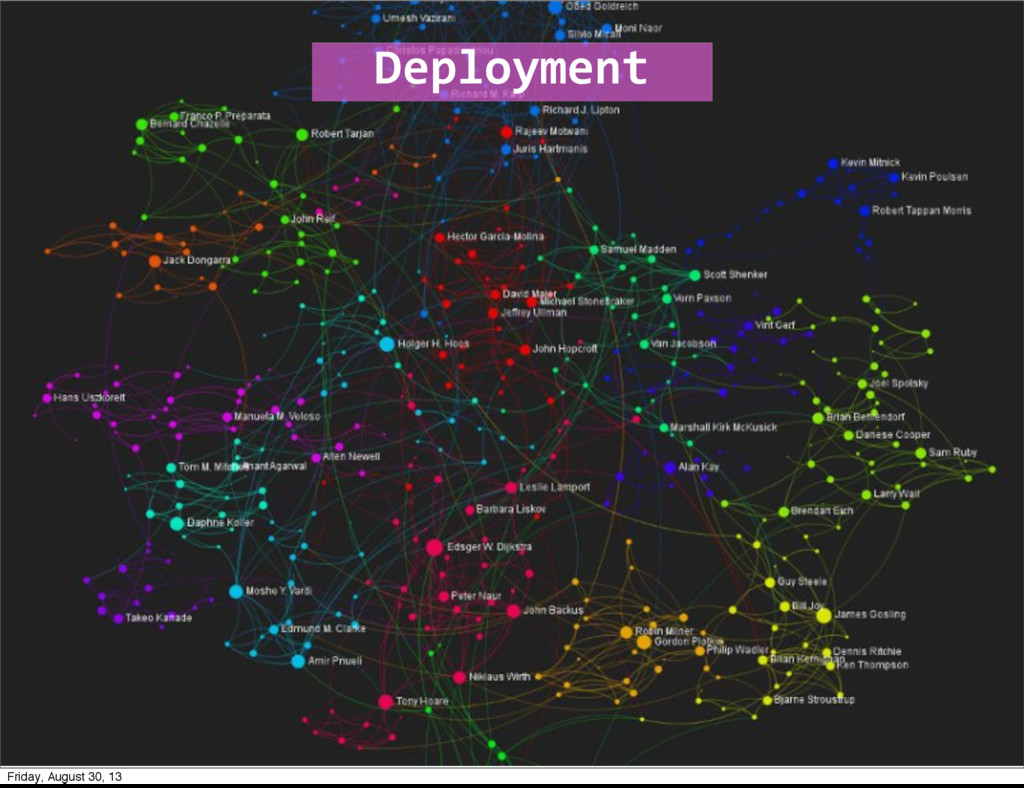
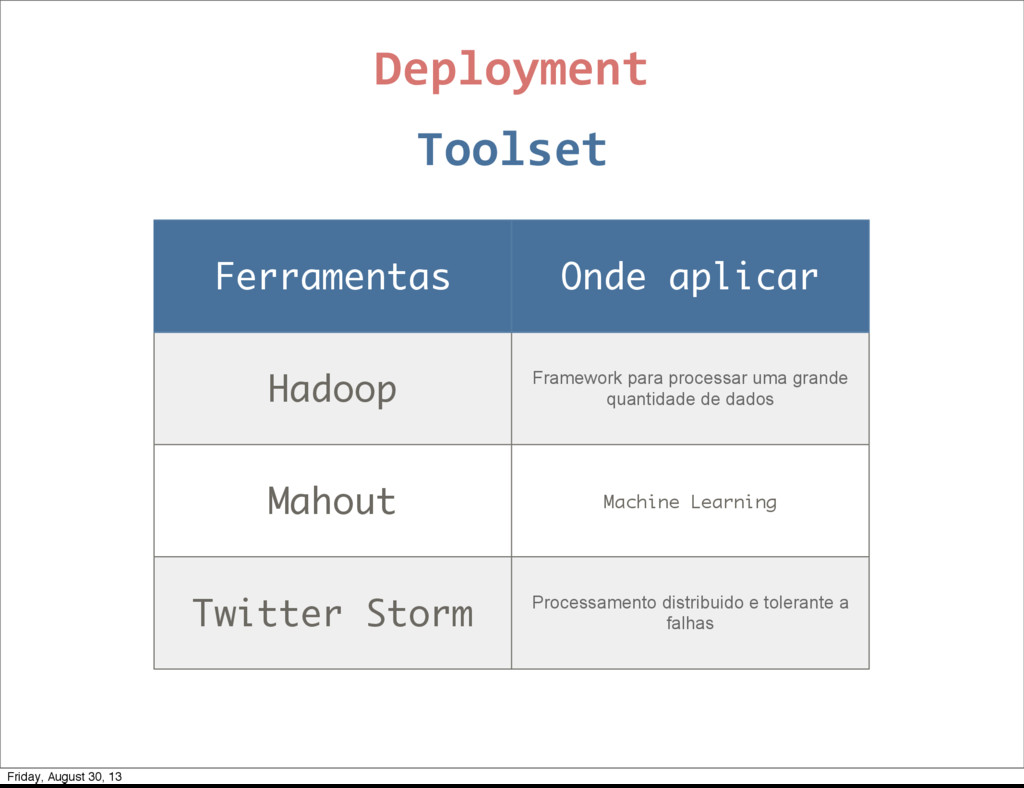
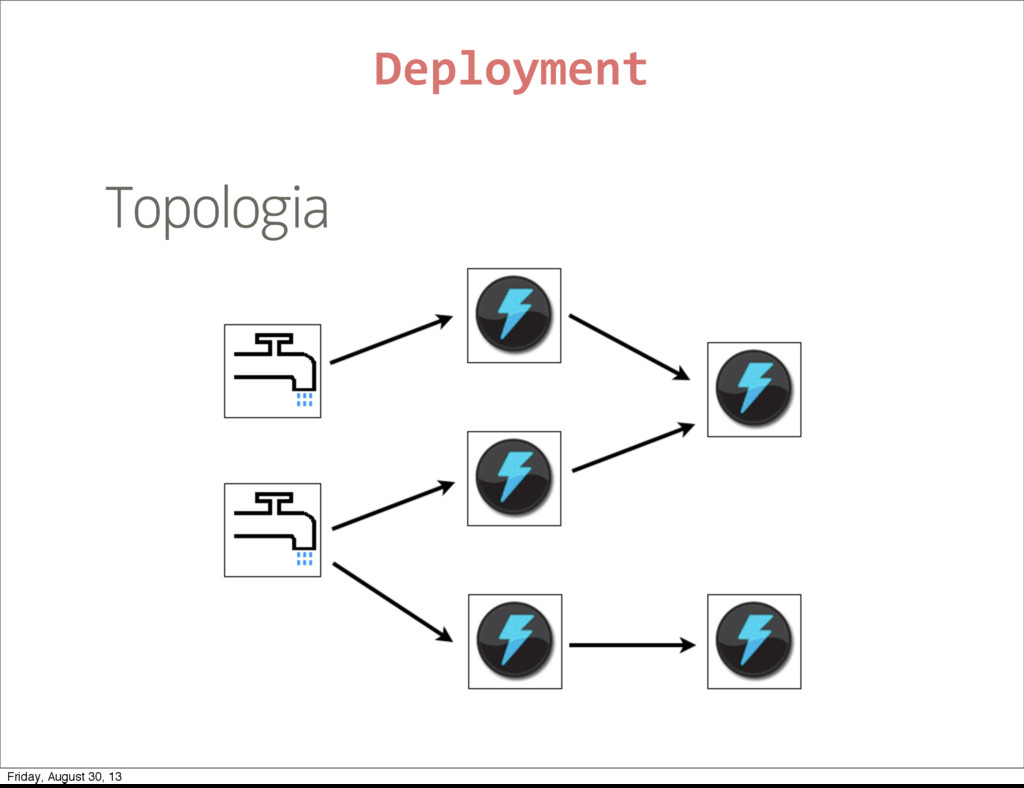
public void open public void nextTuple() public void ack(Object id) public void fail(Object id) public void declareOutputFields(OutputFieldsDeclarer d) } Deployment Friday, August 30, 13
Tente várias abordagens ‣ Converse com outras pessoas sobre seus dados/técnicas ‣ Veja como problemas similares foram modelados ( kaggle.com) Friday, August 30, 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}