Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データ分析基盤のきほん
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Sae Horino
February 09, 2024
130
1
Share
データ分析基盤のきほん
データエンジニアについてとデータ分析基盤についてがわかる(かもしれない)スライド
Sae Horino
February 09, 2024
Featured
See All Featured
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
720
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
Paper Plane (Part 1)
katiecoart
PRO
0
8.5k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
830
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Speed Design
sergeychernyshev
33
1.8k
Transcript
データ分析基盤のきほん 2024/02/09
そもそもデータエンジニアって何…???どういう仕事してんの…???? いわゆるITエンジニアっていうとなんとなくwebページとかwebサービスとかを作ってるんだろうなあ、っていうイメージが強いんですけど、そういうわけでもないし、 じゃあデータエンジニアっていうのがどういう役割で何をやってるのか…?というのが正直さっぱりでした
おそらくこの発表を聞いている皆さんの多くも、正直データエンジニアって何やってんのかよくわからんなあと思っているのではないかと思います
というわけで、あんまり知らないけど知ってみると意外と身近な存在…かもしれないデータエンジニアの仕事について、皆さんに知ってもらおう!というのがこの発表の目的です
今日はこのような流れでお話ししたいと思います
ではさっそく、データ分析基盤とは、というところからお話ししたいと思います
で、結局データエンジニアってなんなん?というのを一言で言うと、、、 「データ分析基盤」の構築や運用・保守をしています …って言うと、じゃあデータ分析基盤ってなんぞ???ってなりますよね データ分析基盤というのは、
読んで字のごとく、データを分析するための基盤です、ということなんですが、データを分析する基盤ってことはわかっても、どういうものかはあんまり想像つかないですよね、 なので詳しく説明していきたいと思うのですが、
そのデータ分析基盤について詳しく説明をする前に、そもそもなんでデータ分析したいんだっけ?という背景のところからお話ししたいと思います
皆さんも一度は「データ利活用」とか「データドリブン」とかいう言葉を聞いたことがあると思いますが、 そういった言葉からもわかる通り、データというのは企業が活動する上でなくてはならない重要なものなんですね
例を挙げると、サービスの売り上げや新規会員登録数など、事業の目標や実績を確認するにはそのデータが不可欠ですし、目標を達成するための施策を検討したり、その施策に効果があったかを検証するのにもデータが必要です。広告などの効果を測定するのにも売り上げや費用のデータが必要ですし、最近ではレコメンドを行うためにデータをコンピューターに学習させる、いわゆる機械学習にもデータが必要になってきます
今さきほど例として出したように、ディレクターの皆さんの中には施策を考える中でSQLを使ったり、あるいはtableauやLooker Studio, Power BIなどのBIツールと呼ばれるものを使ってデータを見てみたり、という経験がある方もいるのではないでしょうか?SQL勉強会みたいな話も最近社内でよく耳にするので、データを見られているディレクターの方々も多いのかな、と思います では、皆さんが見てるそのデータって果たしてどこから来てるんでしょうか??
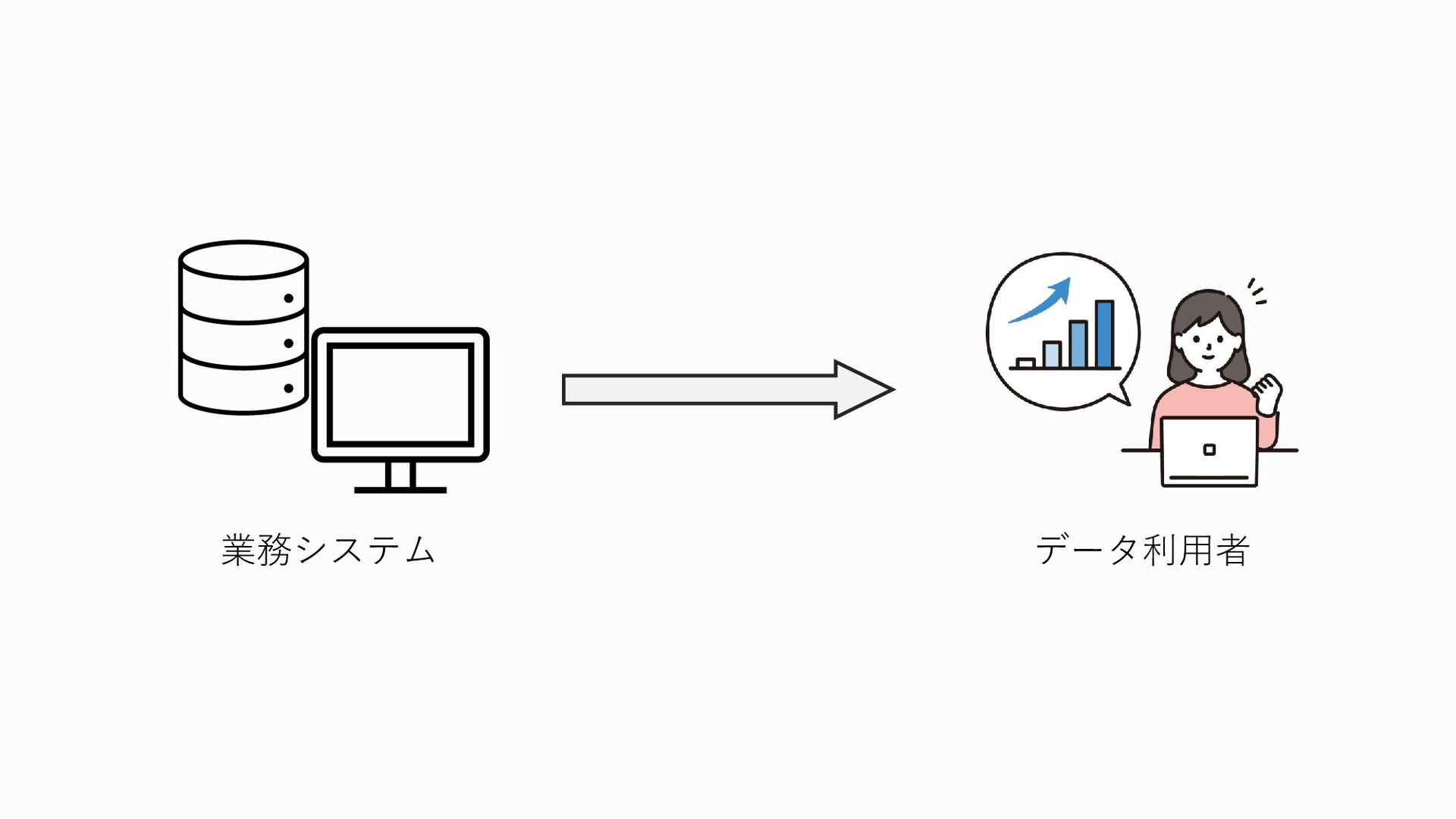
企業の活動、たとえばサービスの会員情報の管理だったり、ECサイトであれば商品や在庫の管理、あるいは顧客との取引の記録や経理とか会計の記録は、 今どきだとほとんど全てがコンピューター上で管理されている、というのは皆さんも想像がつくと思います
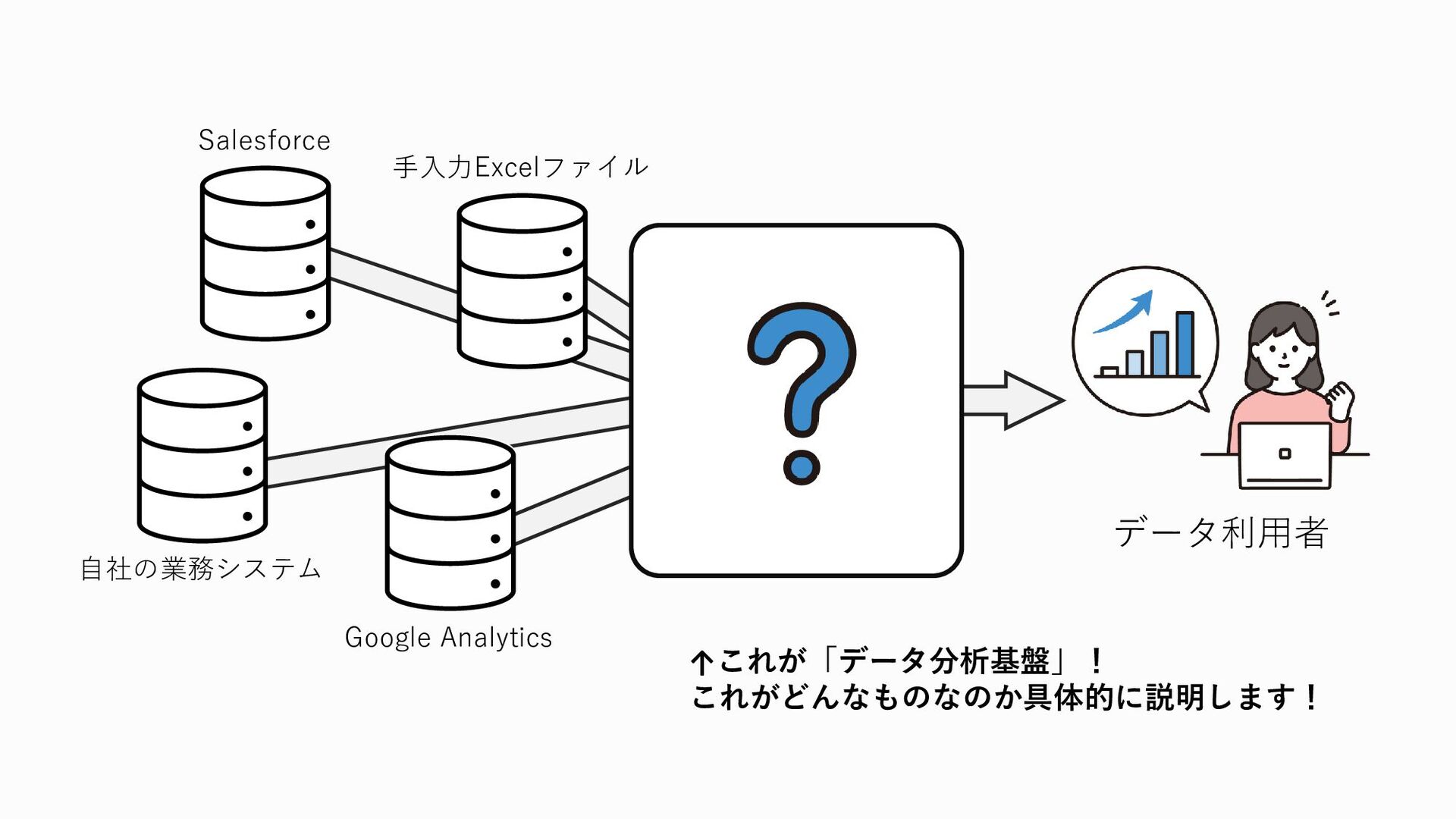
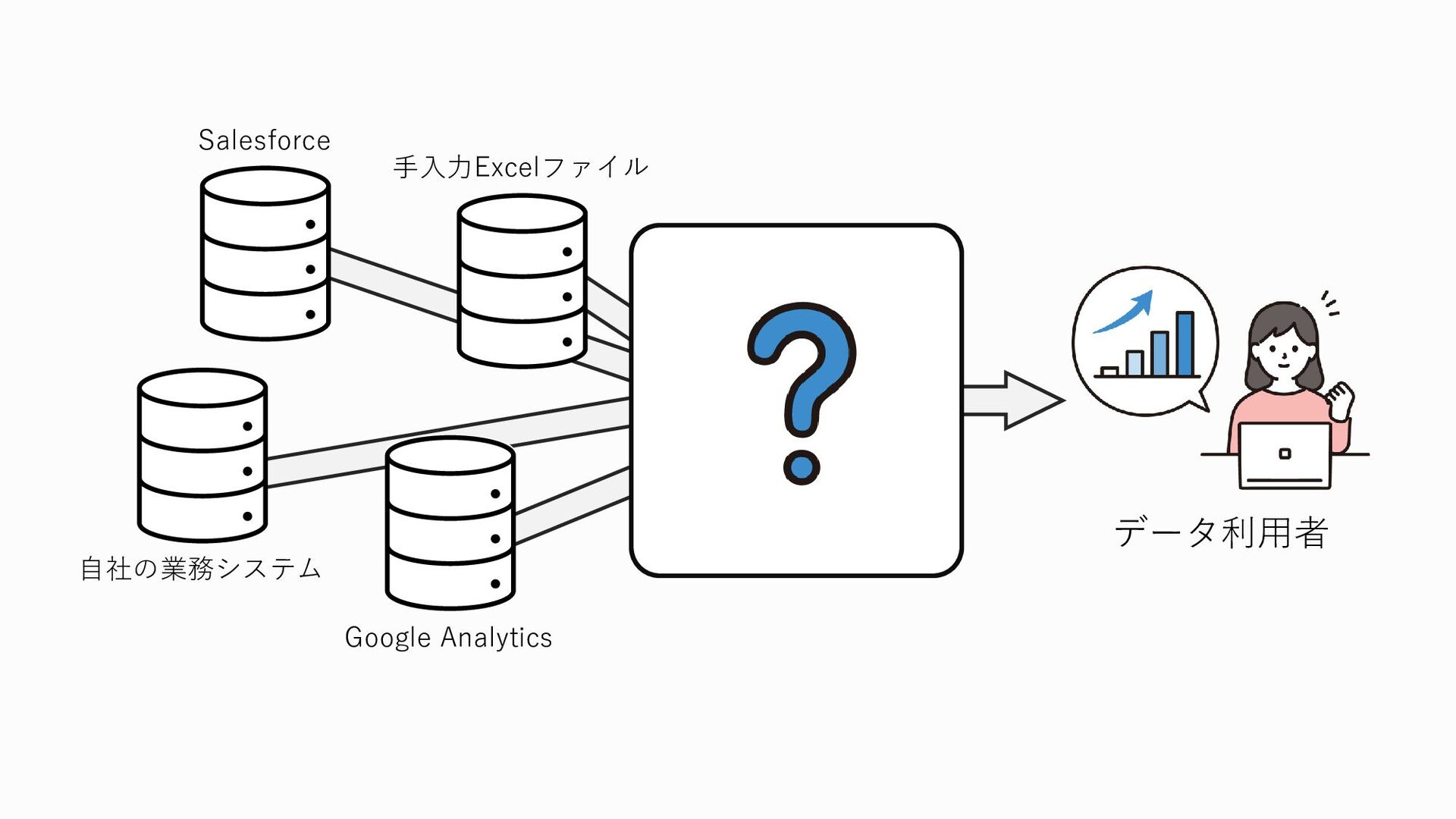
では、これらの業務に関わるデータを業務システムから直接参照して分析に使っているのかというと
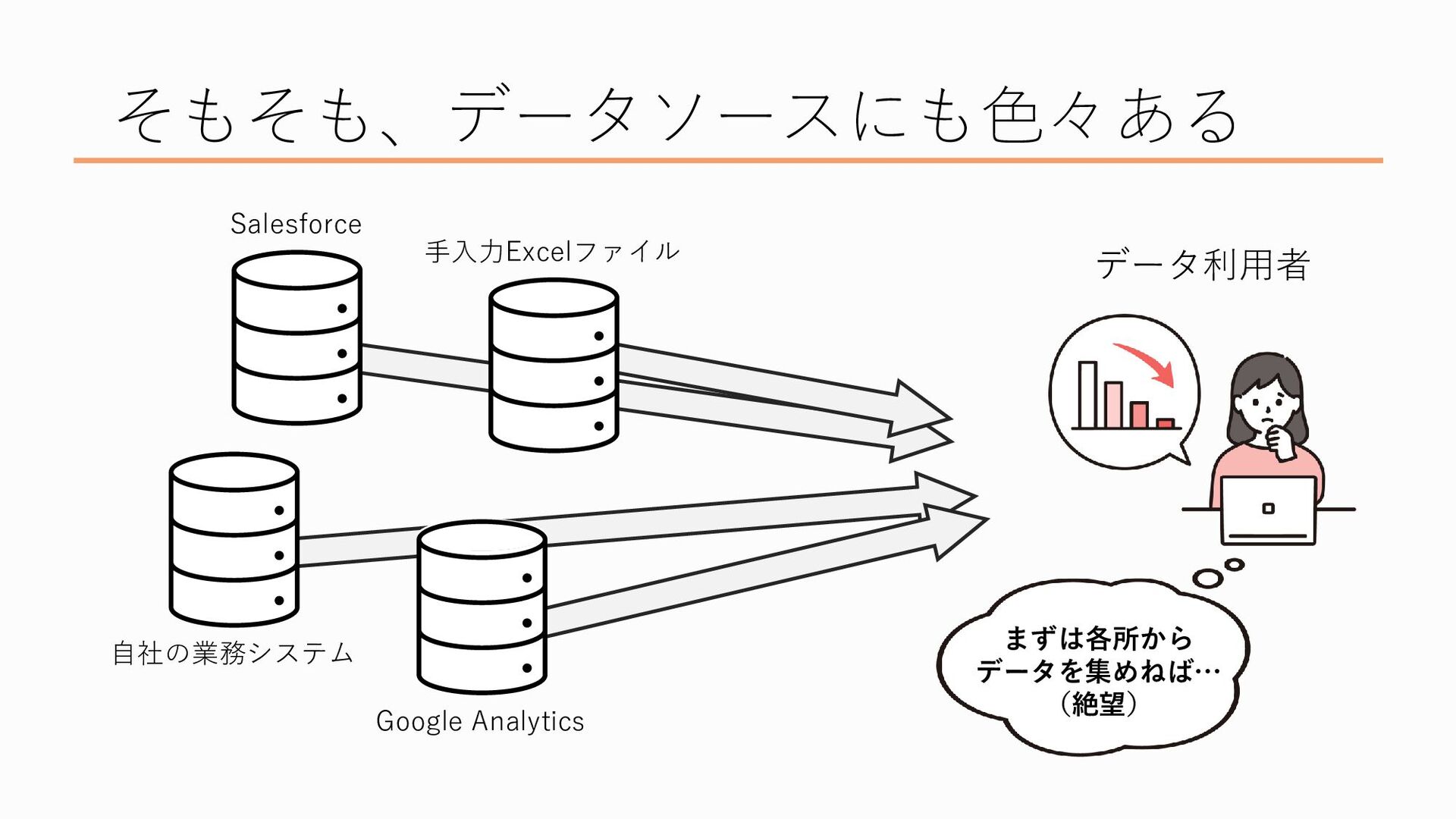
そういうわけではないんですね 業務に使っているシステムのデータベースに分析用途での利用者がアクセスしてデータを取り出したりしようとすると、データベースに余計な負荷がかかってしまい、そのせいで業務自体や下手するとユーザーに提供しているサービスが重くなってしまうなどの悪影響を与えてしまう可能性があります また、業務システムのデータベースには、当然顧客の名前や住所、電話番号やメールアドレスなどの個人情報が存在します。 分析用途でのみ使う人が、分析には必要無いのに、ユーザーの個人情報にアクセスできてしまうのも問題です。個人情報が漏洩してしまう可能性が高まりますし、プライバシー的な部分でそもそも個人情報を勝手に分析に使っていいんだっけ?というのもあります。 しかも、データはこの図のように一か所にまとまって保管されているのかというとそうではありません
データ、改めデータソースにも色々な種類があります データソースというのはオリジナルのデータ、データの発生源という意味なのですが、 たとえば先ほど挙げたような会員情報や購買履歴など、社外秘やそれに近いデータ等は自社の業務システム内のデータベースに保管されていることが多いです しかしそれだけではなく、例えば皆さんもよく耳にするであろうGoogle Analyitcs 通称GAなどのアクセス解析ツールと呼ばれるもの、これで取得できるユーザーの行動ログ、イベントログは、GA上にデータが保管されています また、営業に関わるデータは営業管理ツールに、経理・会計に関わるデータは会計管理ツールに、というふうに、データソースというのは様々な場所に散らばっているものです
こんな風にいろんなところにいろんなデータがあるので、集めるだけでも一苦労なんです
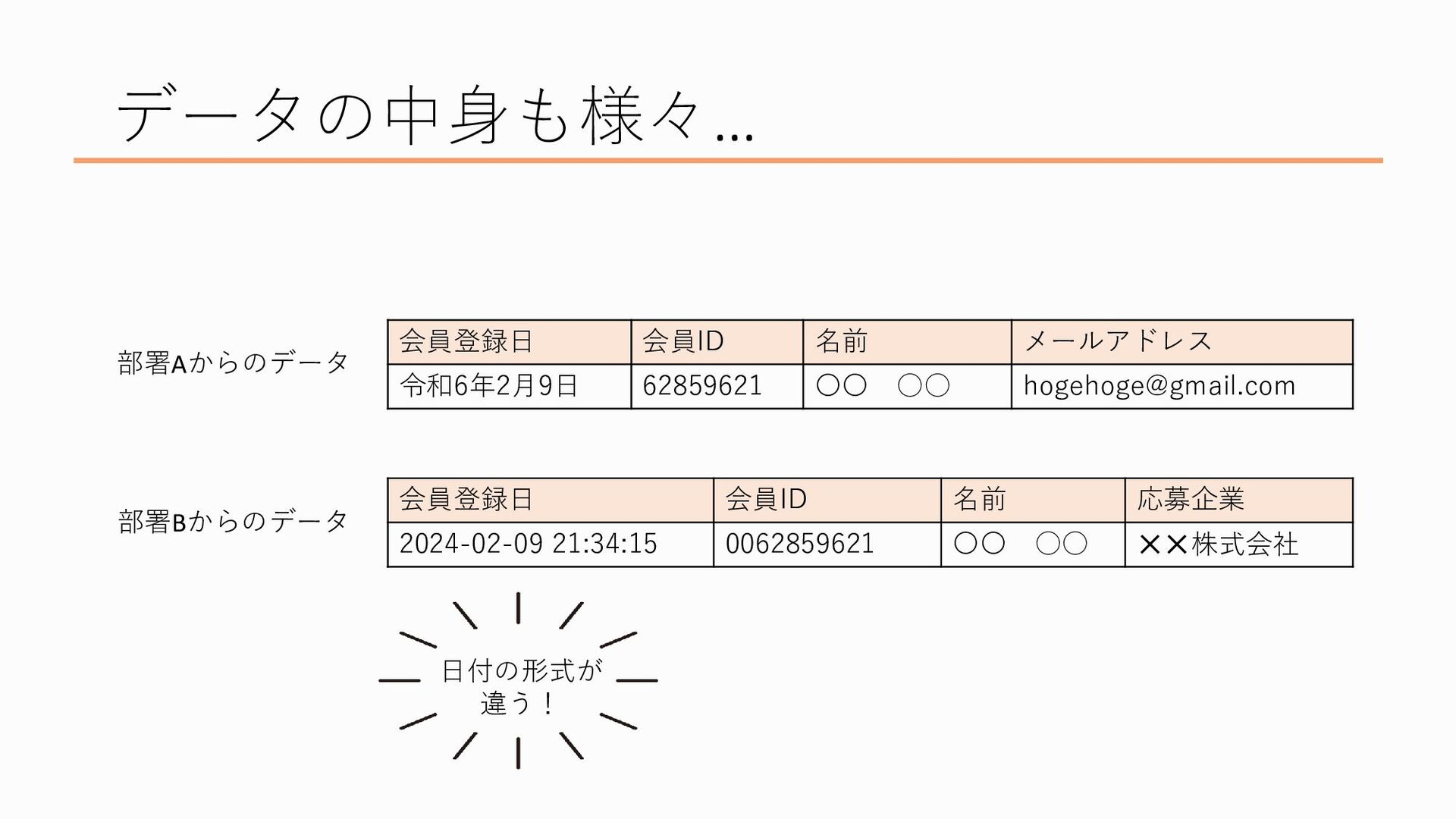
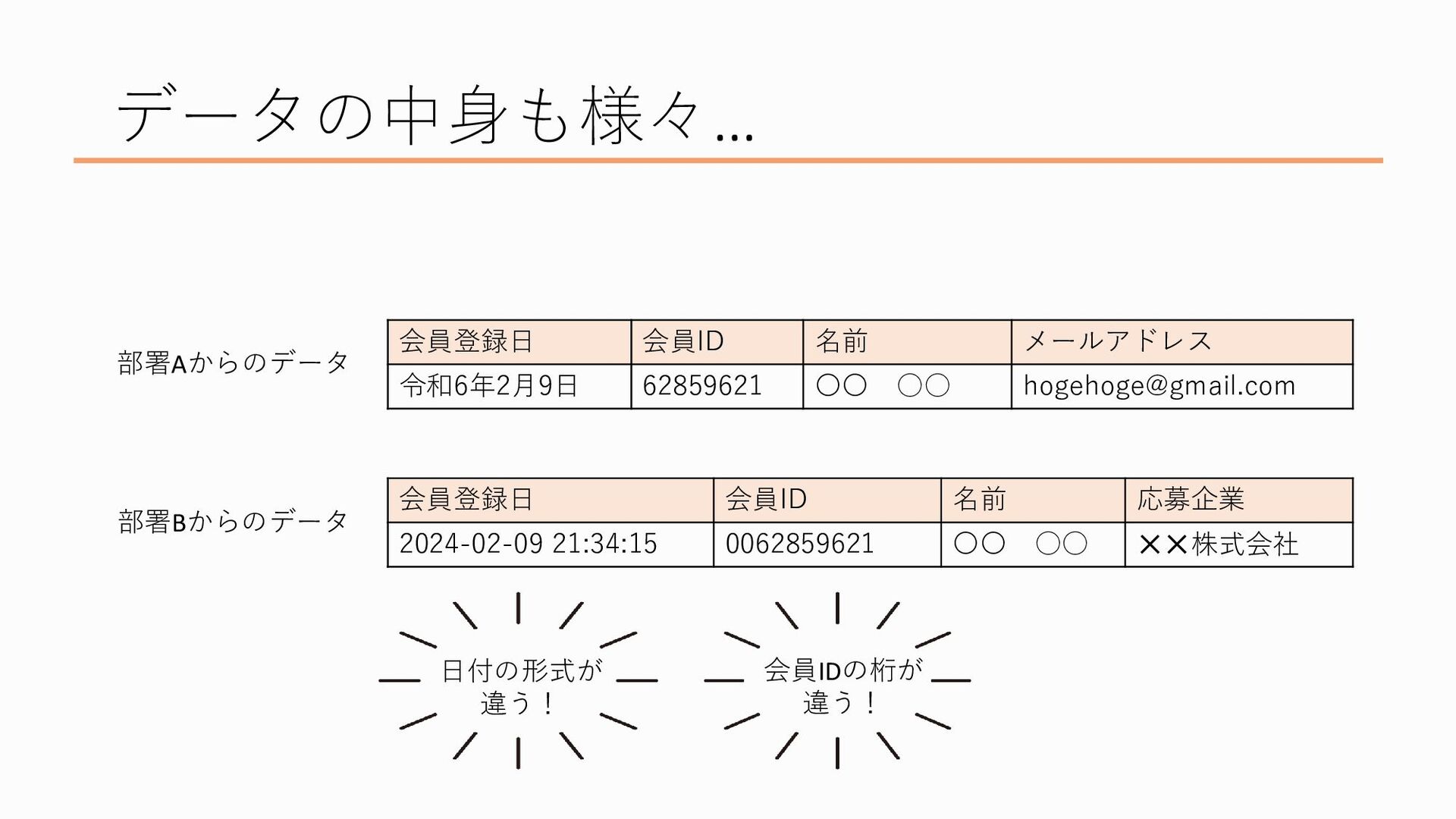
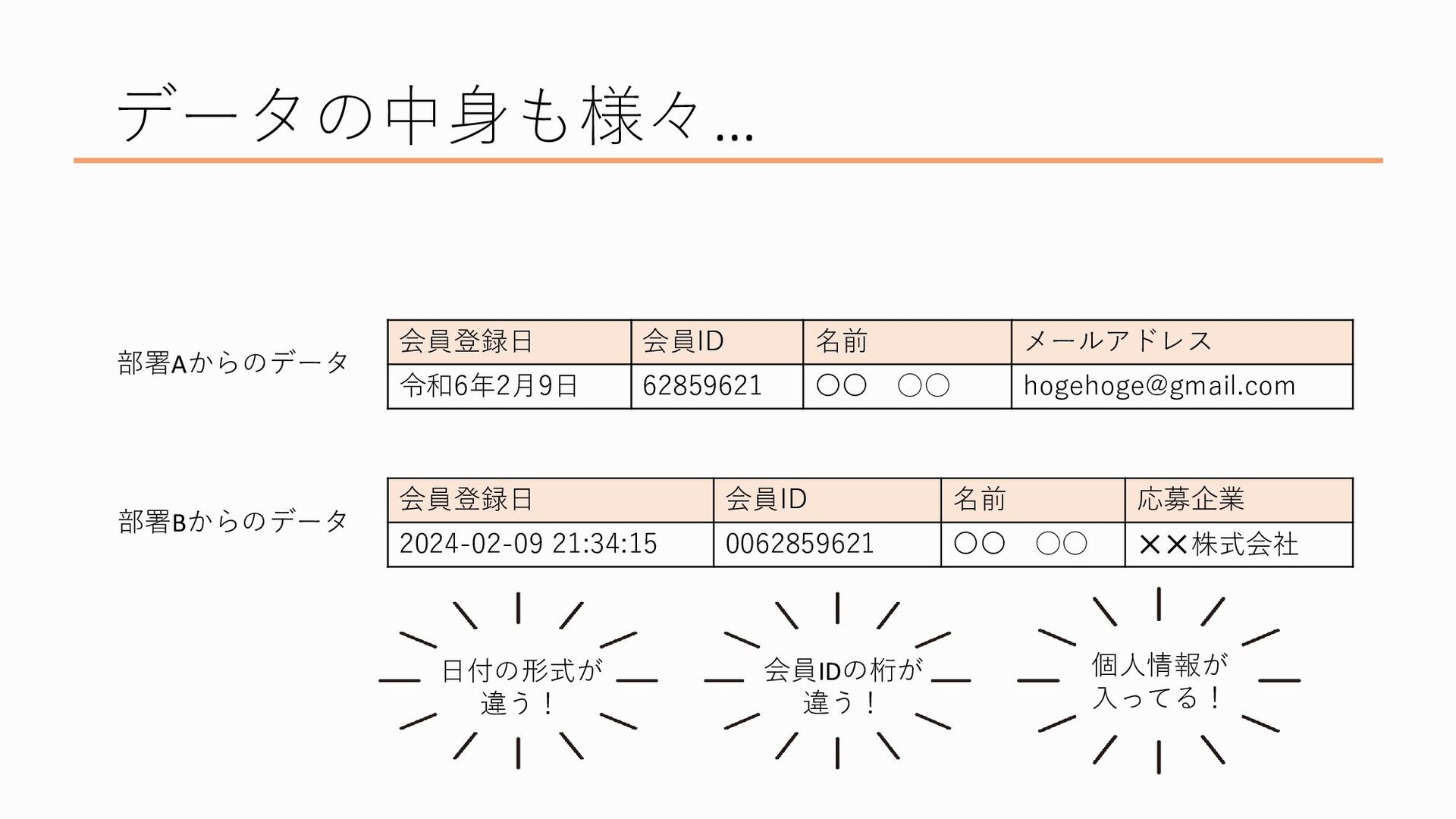
しかも、データの中身にも様々なものがあり、たとえばこれは別々の部署で作られたデータ2つの比較なんですが、
たとえば、部署Aで作られたデータは日付が和暦(令和何年)になってるし日付までしか入っていない、かと思えば部署Bで作られたデータは西暦で入っているし時刻まで入っているしで日付の形式が違うだったり、
同じ会員IDでも部署Aのものは8桁になっているのに対し、部署Bでは0で詰めて10桁の会員IDが入れられているだったり、
どちらのデータにも名前やメアドなどの個人情報が記載されている、 など、データの中身にも分析するにあたってのハードルが色々あるんですね
これだとデータを分析するどころか、欲しいデータを色んなところからかき集めて形式を整えて…としているだけでめちゃくちゃ時間がかかってしまいます、 これだとデータ利活用どころの騒ぎじゃないですよね、ということで、
ここまでお話ししたような問題を一つ一つ解決して、データの利用者がデータを分析しやすくするためのものが「データ分析基盤」というものです
図でイメージするとこんな感じなのですが、ではそのデータ分析基盤の中ではどういうことが行われているのでしょうか、ということで、
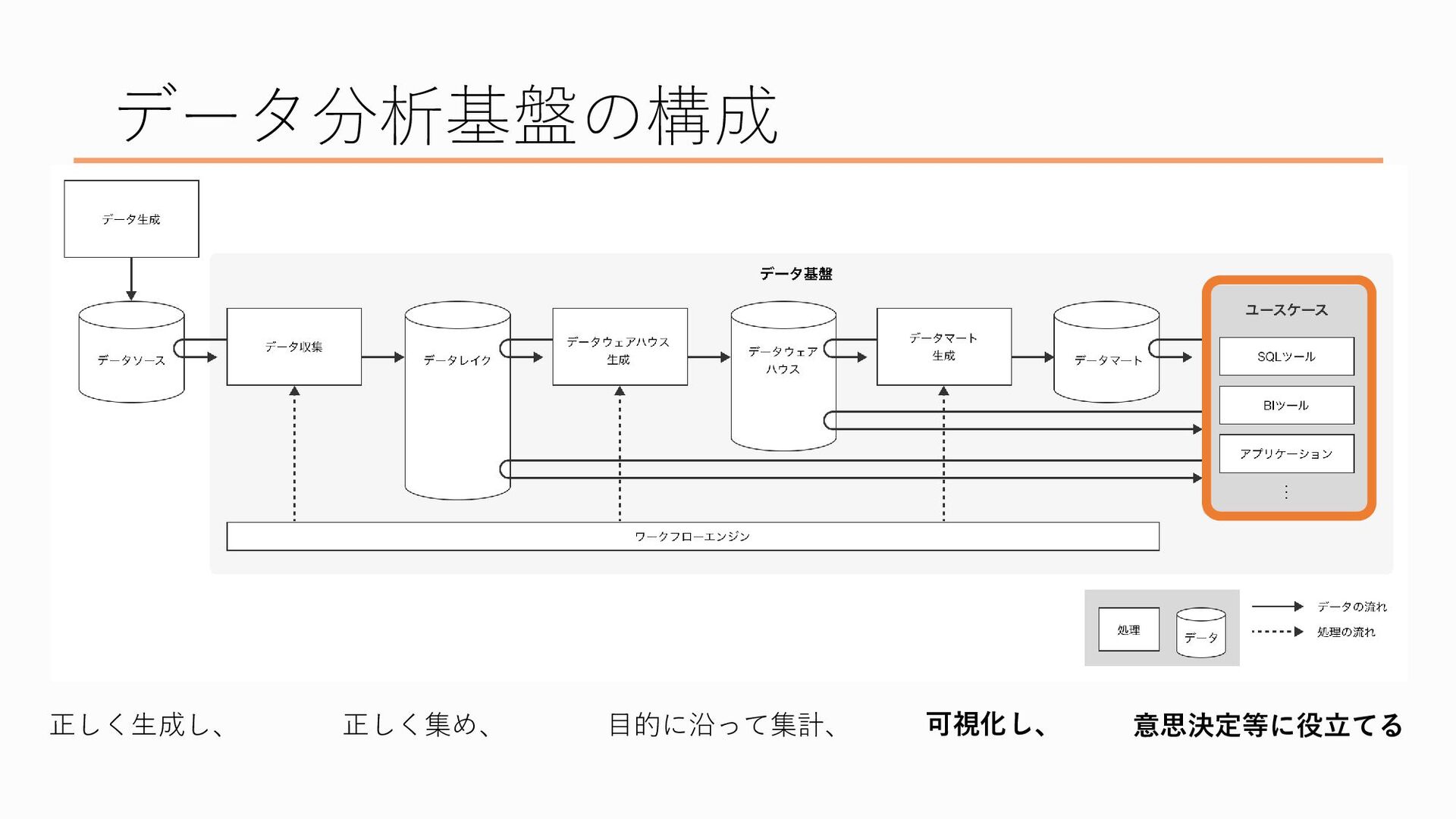
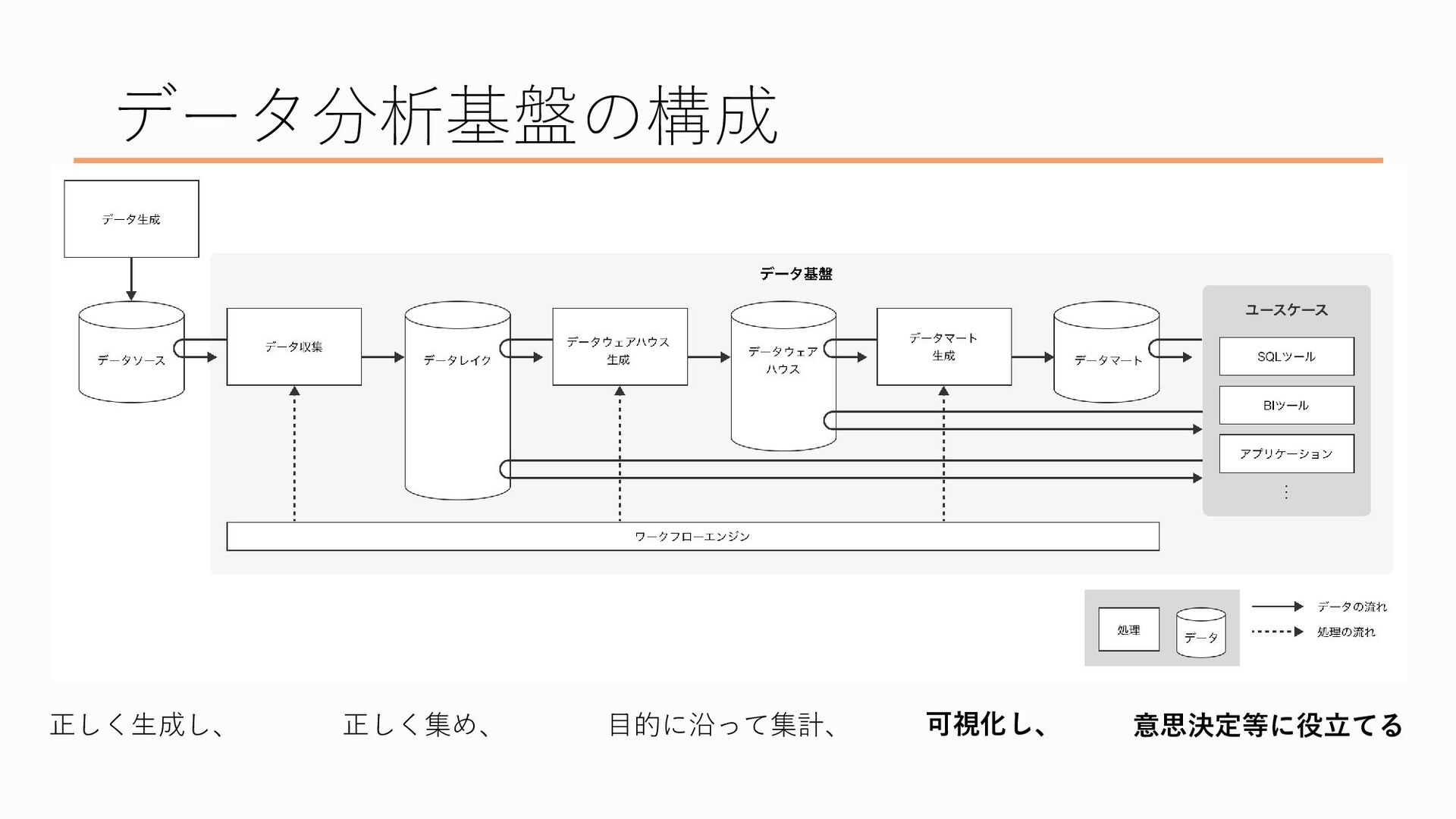
データ分析基盤の構成についてお話ししたいと思います
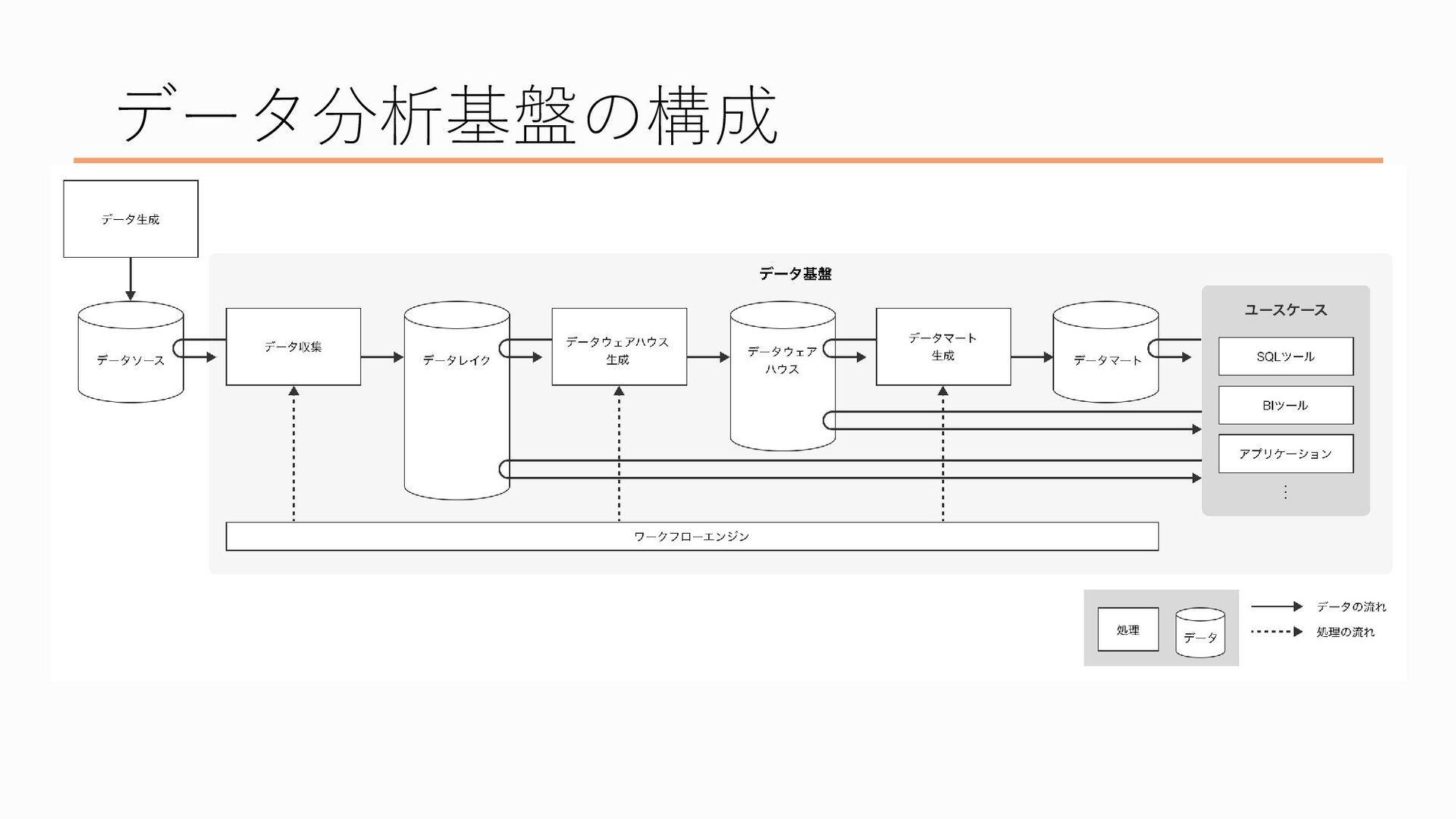
改めて、データ分析基盤とはなんぞや?というのを少し詳しめに言語化すると、「必要なデータを正しく生成し、正しく集め、目的に沿って集計・可視化し、意思決定に役立てるためのシステム」です 言われてみればそうなんだろうなあという感じもするかもですが、つまり何をしてるの?なんでそんなことするの?というのをお話しします
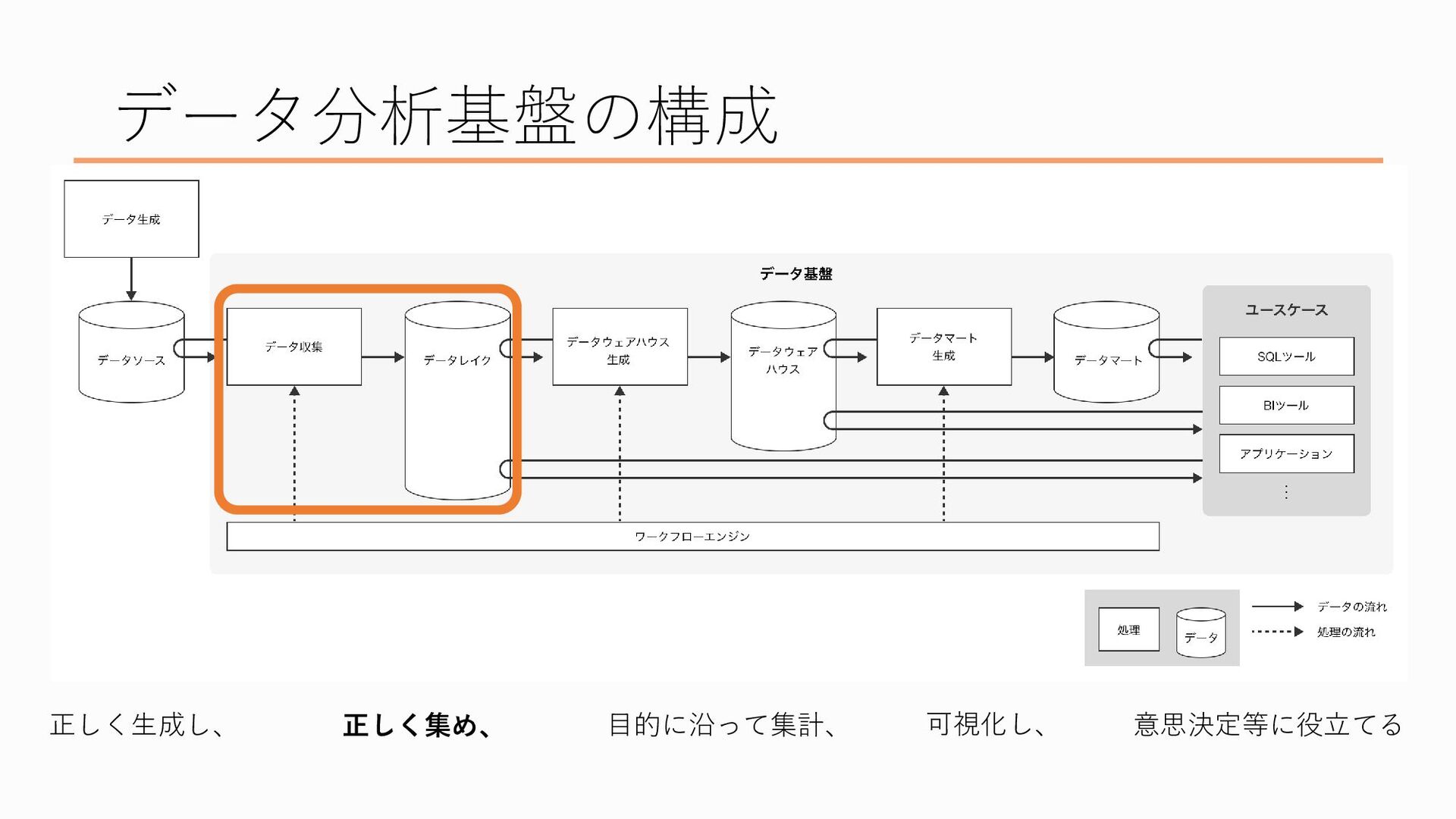
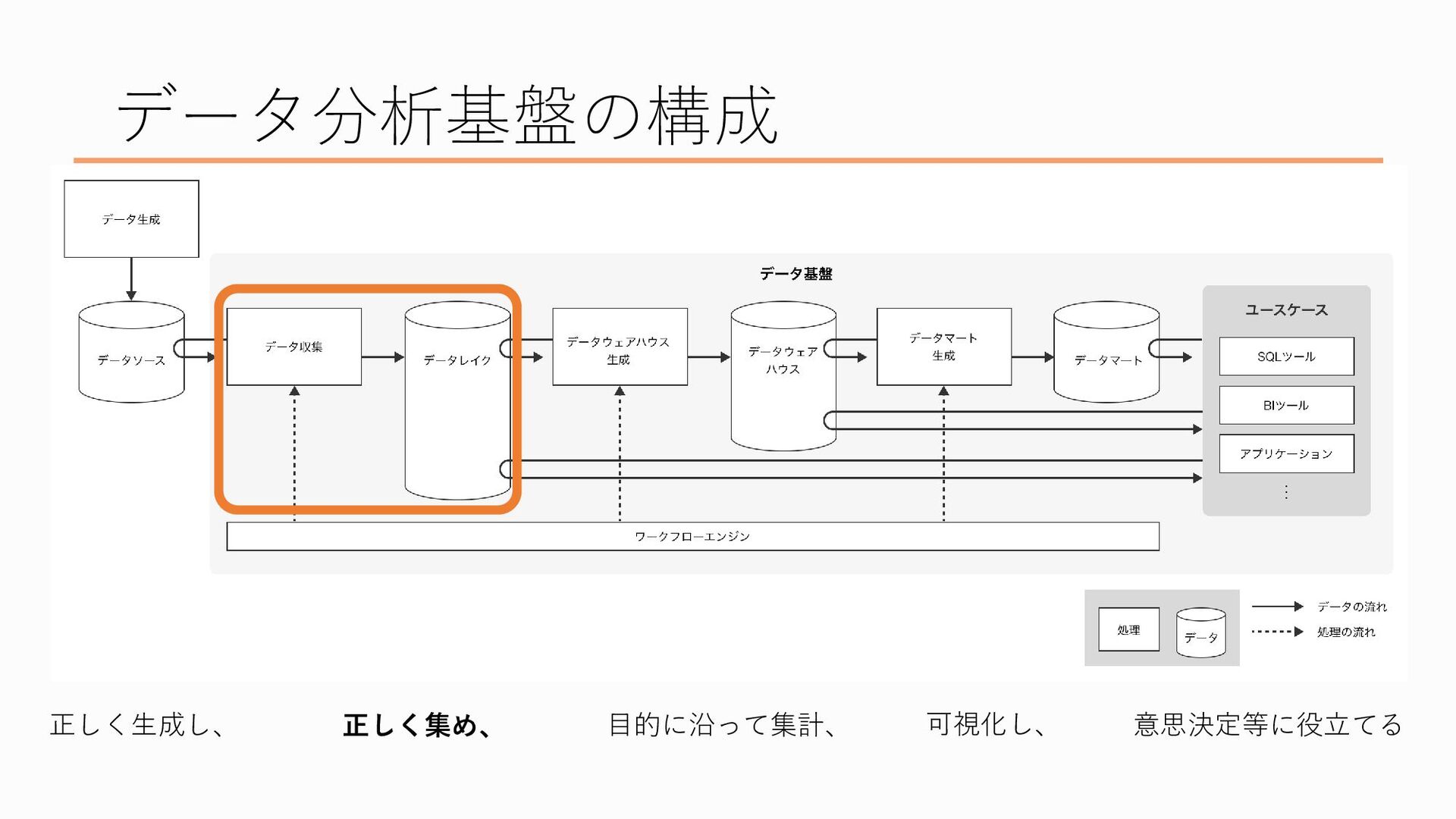
データ分析基盤といってもいくつかの段階を踏んでおり、具体的にはこんな構成になっています 先ほどのデータ分析基盤の説明を当てはめると、
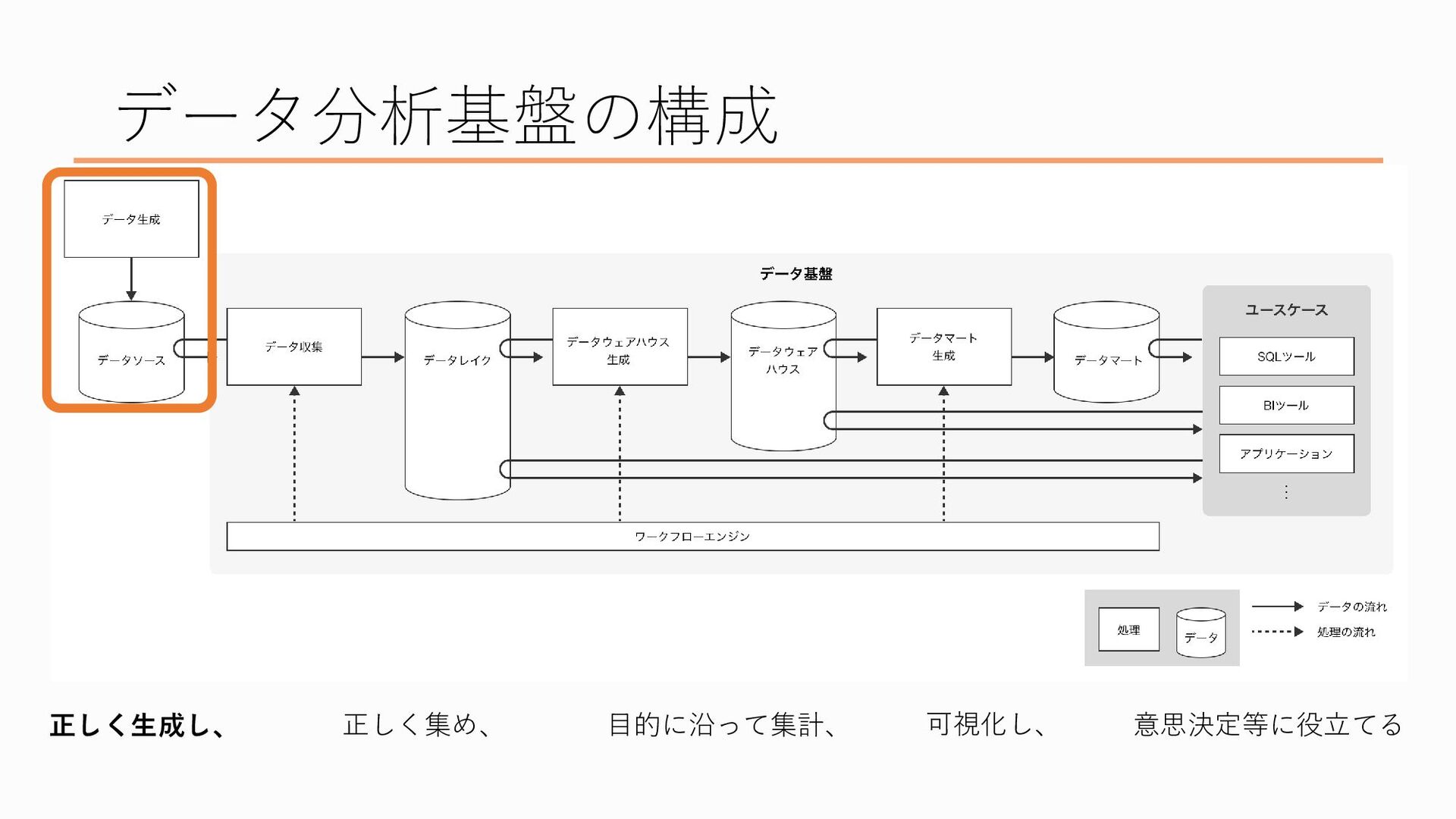
最初、一番左にあるのが「データを正しく生成する」ところ、
次にデータを「正しく集める」ところ、
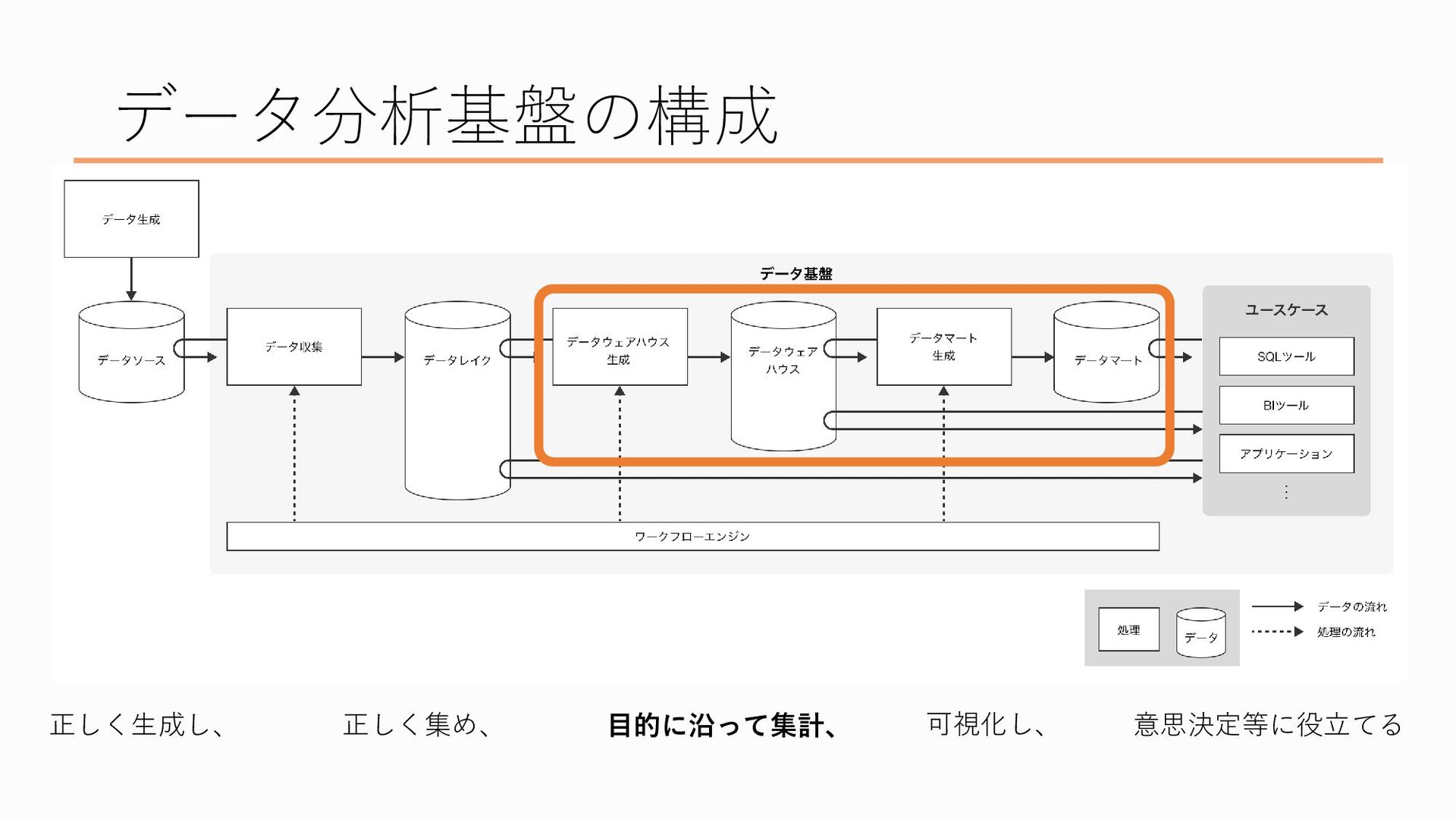
ここがデータを「目的に沿って集計」するところ、
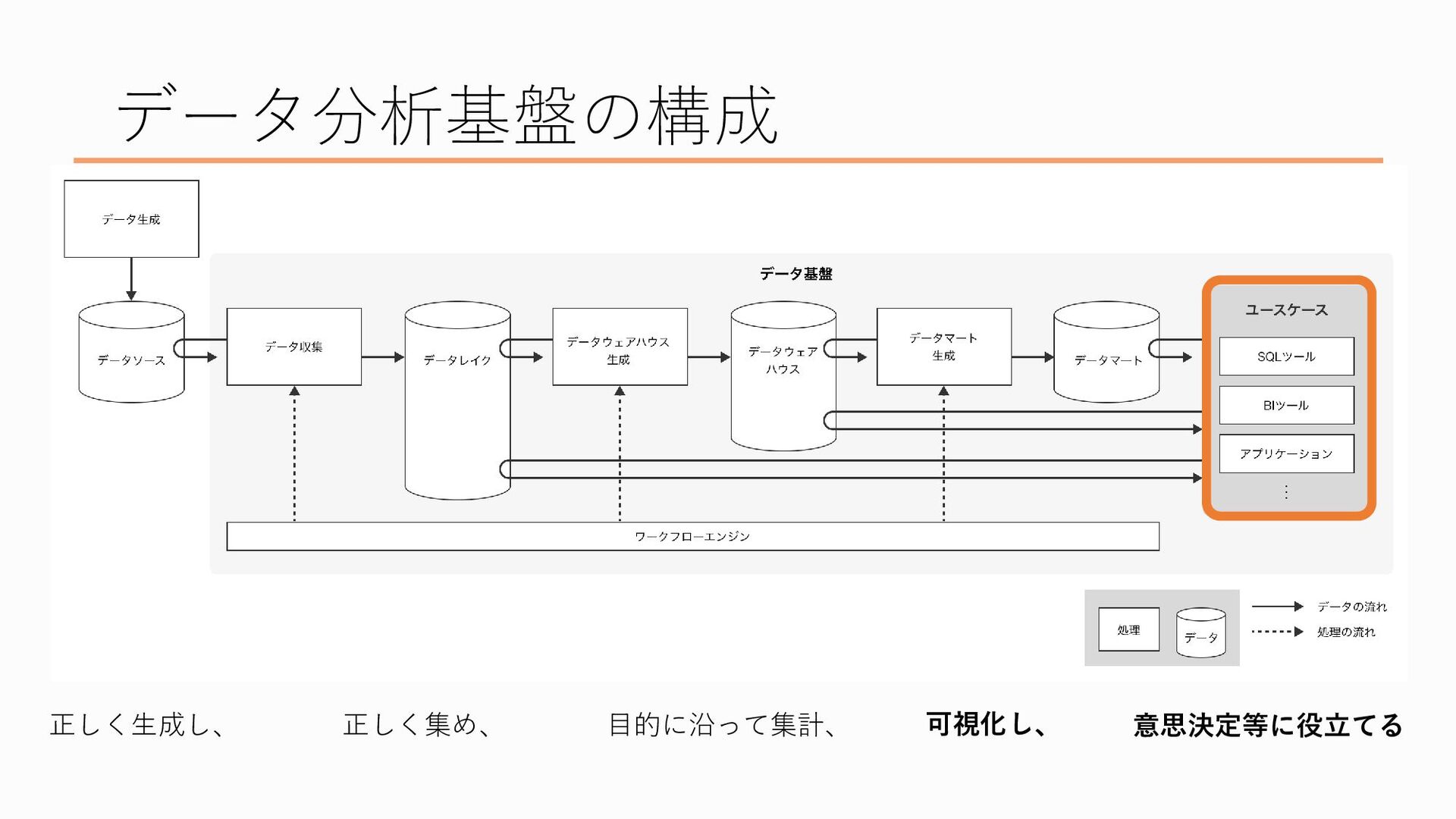
そして最後にデータを「可視化し、意思決定に役立てる」フェーズがあり、ここにいるのがデータを利用する皆さん、という感じになってます、でこの流れを一つずつ説明したいと思います
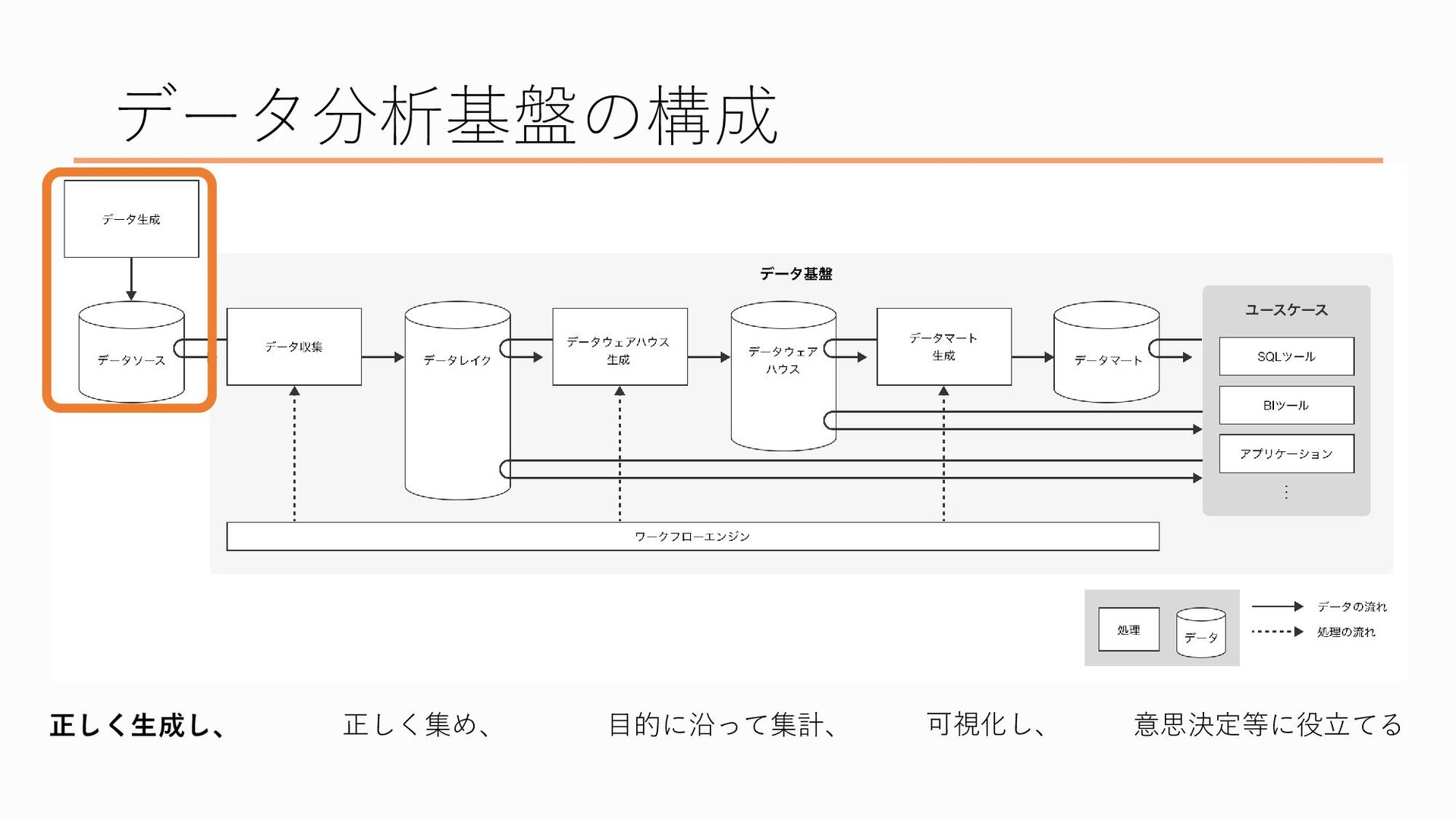
まずはデータの生成から、ここは厳密にはデータ分析基盤の外側の部分なのですが、、、
データというのは放っておいても勝手に生まれてくる、といったものではありません たとえば会員情報というのはユーザーがサイトで会員登録を行うと業務システムのDBに登録情報が記録されるようにしていますし、 ユーザーの行動ログを取得するにはwebページにユーザーの行動を取得するための処理を埋め込む必要がありますし、営業のデータだったら営業担当が営業の管理ツールに情報を入力することでデータが生まれます このように、人間の活動によってデータは生み出されています なぜ集めるところではなくデータを生成する段階から話を始めるかというと、当然データが無いことには分析ができないからです 今回はここに関しては詳しくは触れませんが、正しく分析を行うためにというのはもちろん、データソースに問題があるということはデータ分析だけでなく業務そのものに問題がある可能性が高いのでそれを直してもらうためにも、データが取れていなかったり欠けていたりする場合にはデータを正しい状態に直してもらえるよう、データを生成している側の方々に働きかけるのもデータエンジニア、というかデータ系の職種の仕事の一つです
次はそれらのデータを正しく集めるという部分です
これは先ほど述べた通りですが、データソースとその在りかにも色々あります
なので、それに合わせてデータソースの集め方も異なります、 たとえばもともとExcelファイルやcsvファイルになっているものであればそれをコピー等で持ってくれば良いですし、業務システムのデータベースにあるデータはSQLを使って抽出したり、ファイル等に出力したりすることで持ってきます アクセス解析ツールのデータも、ファイルにエクスポートして持ってきます このあたりどういうデータに対してどういった方法を取るかは、データのサイズやシステムの構成など、様々な要因を考慮して決定します
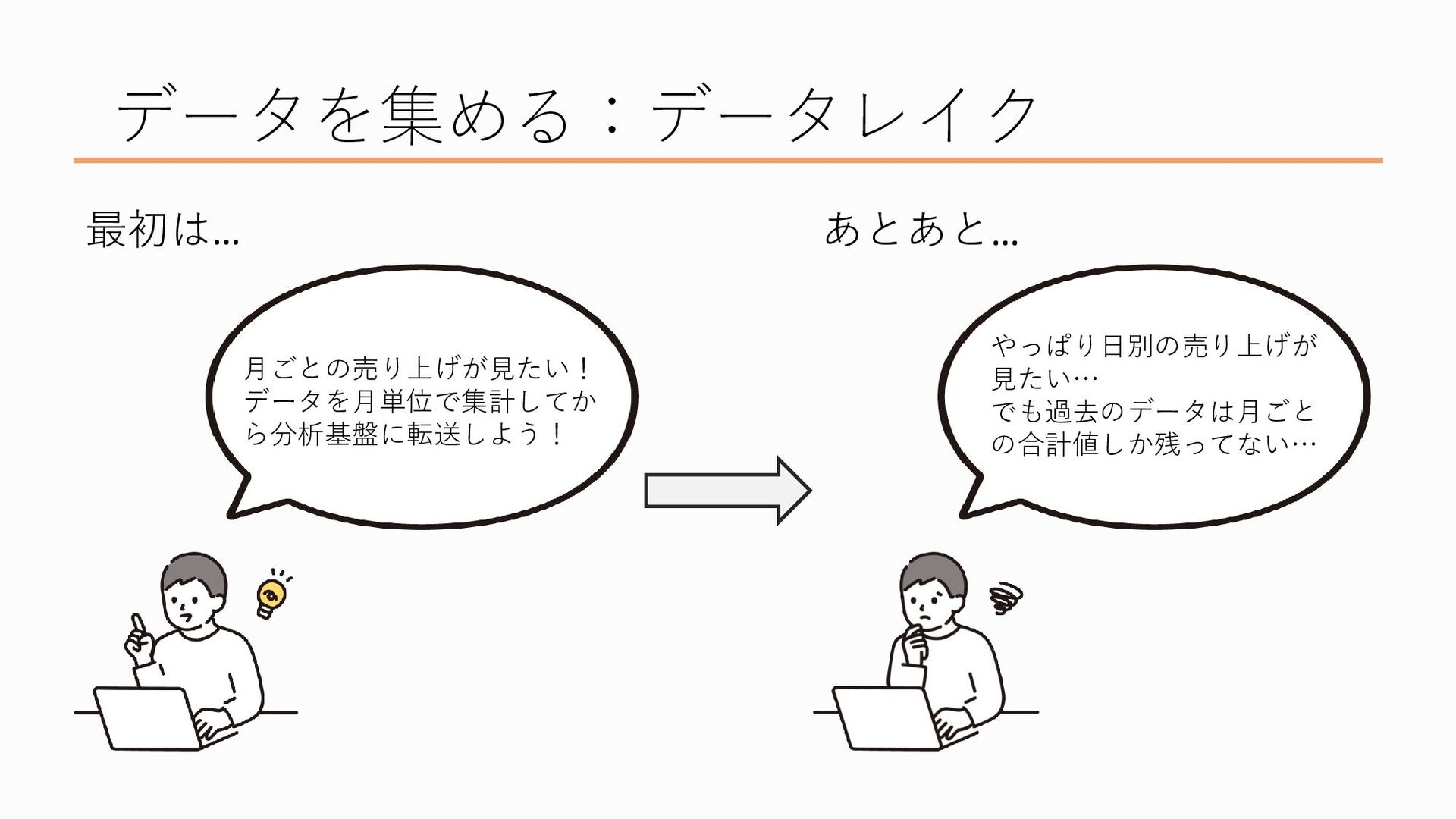
で、そのデータを集める場所が「データレイク」と呼ばれます。データソースを水源とみなしたときに、そこから流れてきた大量のデータを蓄える場所なので湖といったイメージでデータレイクと名付けられた、という説があります
このデータレイクには各所から集めたデータを「そのまま」置いておくことが重要とされています。なぜかというと、 そもそも企業にとってデータとは大切な資産の一つという考え方があります 資産なのでできる限り失いたくないんですけど、その一方で加工してしまったデータはもとに戻すのが難しいんですね、
たとえば、最初は「月ごとの売上を見たい!」という目的で売り上げを月単位に集計してからに転送してしまうと、後から「やっぱり日ごとに見たいわ~」となっても過去のデータはもう合計値しか残ってないので一日一日の売り上げがわからない…ということが起こり得るんですね、なので、データを加工する前にまずはデータが生成されたときのままの形で蓄積しておきたいんです
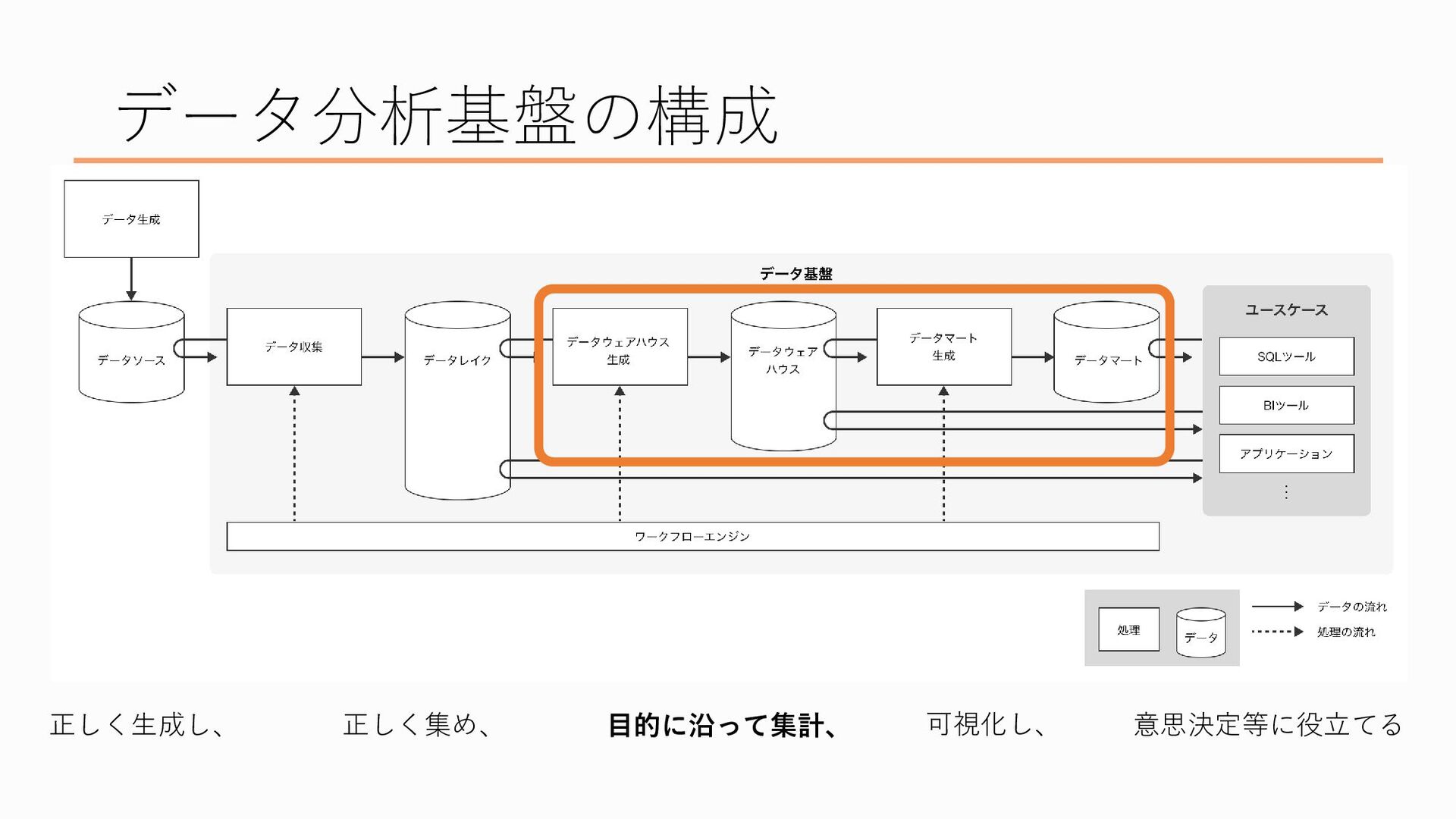
次に、目的に沿って集計する部分について説明します
データレイクにある、取得した状態そのままのデータを集計・加工したものがデータウェアハウスと呼ばれます データウェアハウスというのは、「大量のデータを意味のある形で置いておく」ということから倉庫のイメージと結びつけてそう呼ばれています
やはり先ほどのデータレイクにあるような収集しただけのデータはどうしても扱いづらいので、データの形式を整えたり、数値や日付の表記を整えたり、個人情報を取り除いたり、部署を横断した「共通指標」に沿った集計を行ったりして、分析に使いやすい形にしたデータをデータウェアハウスに置いておきます
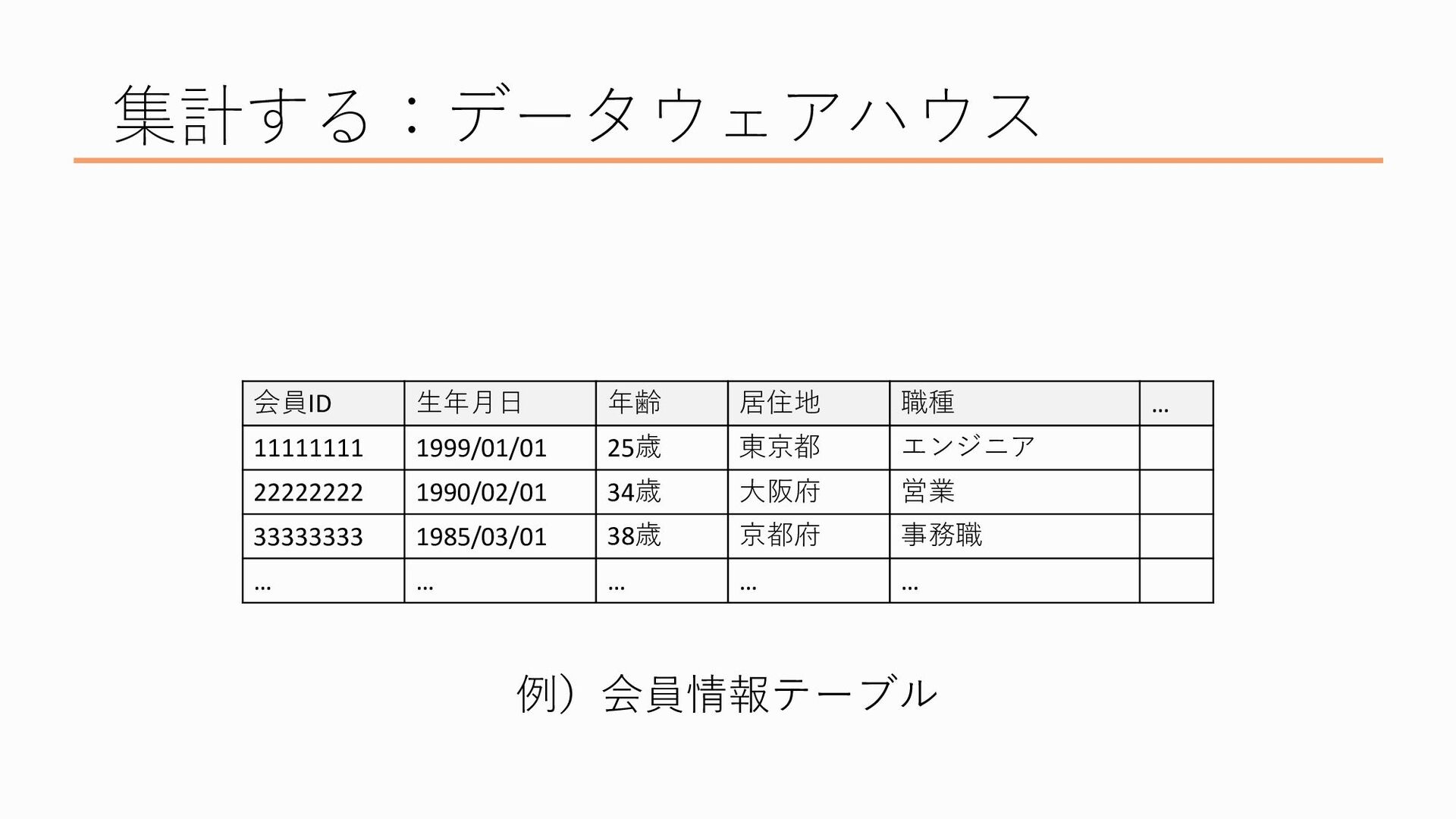
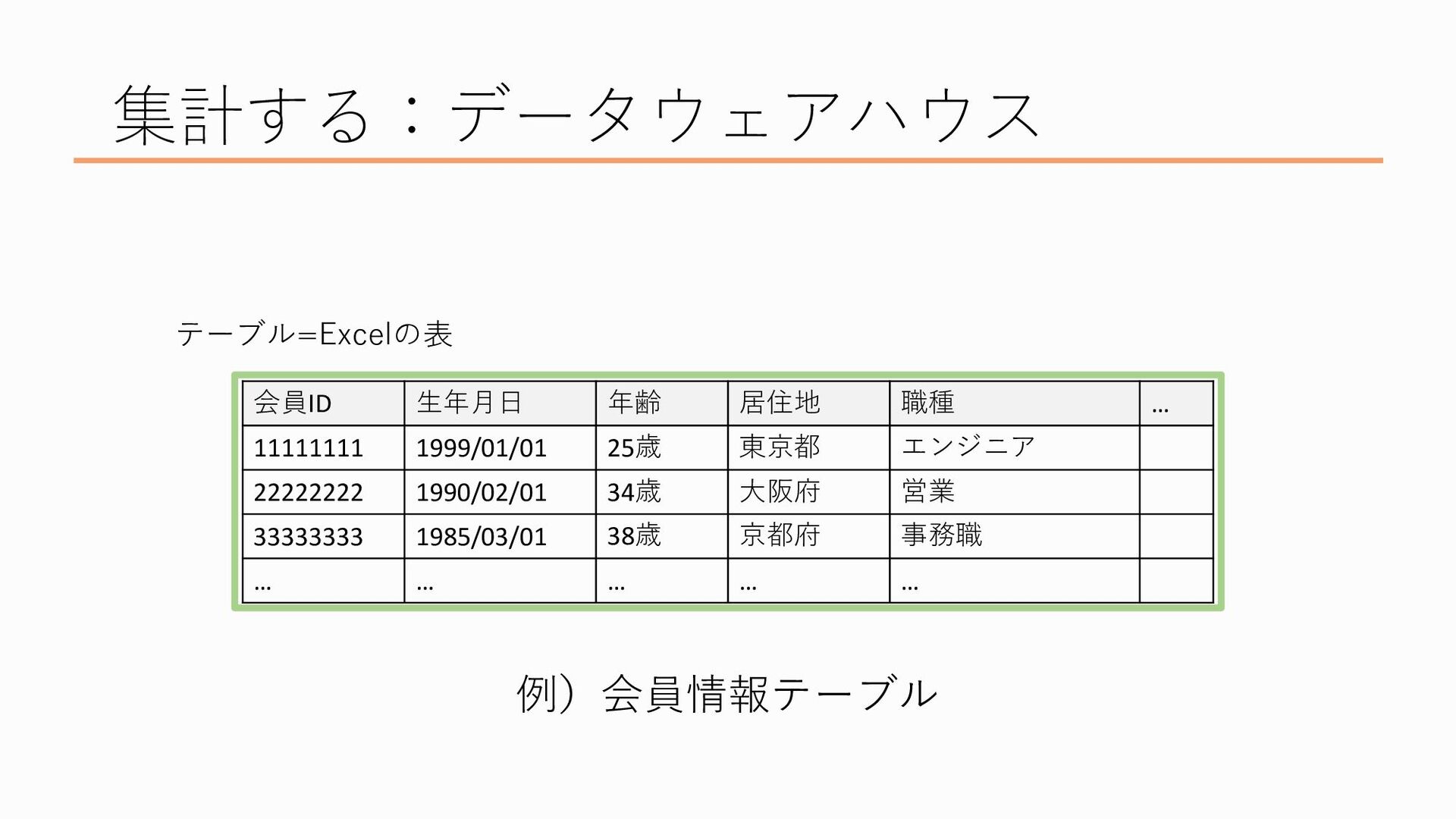
まず「形式を整える」というのに関して、データウェアハウスでは分析をしやすくするためにデータの形式をきちんと定めて(いわゆる構造化データ)データを保管します ここではテーブルの形で保管されるのが一般的で、じゃあテーブルってどんなものなの?というと、Excelの表をイメージしてもらえると良いかなと思います
Excelにある表が一つのテーブル、つまり一つのデータの塊です
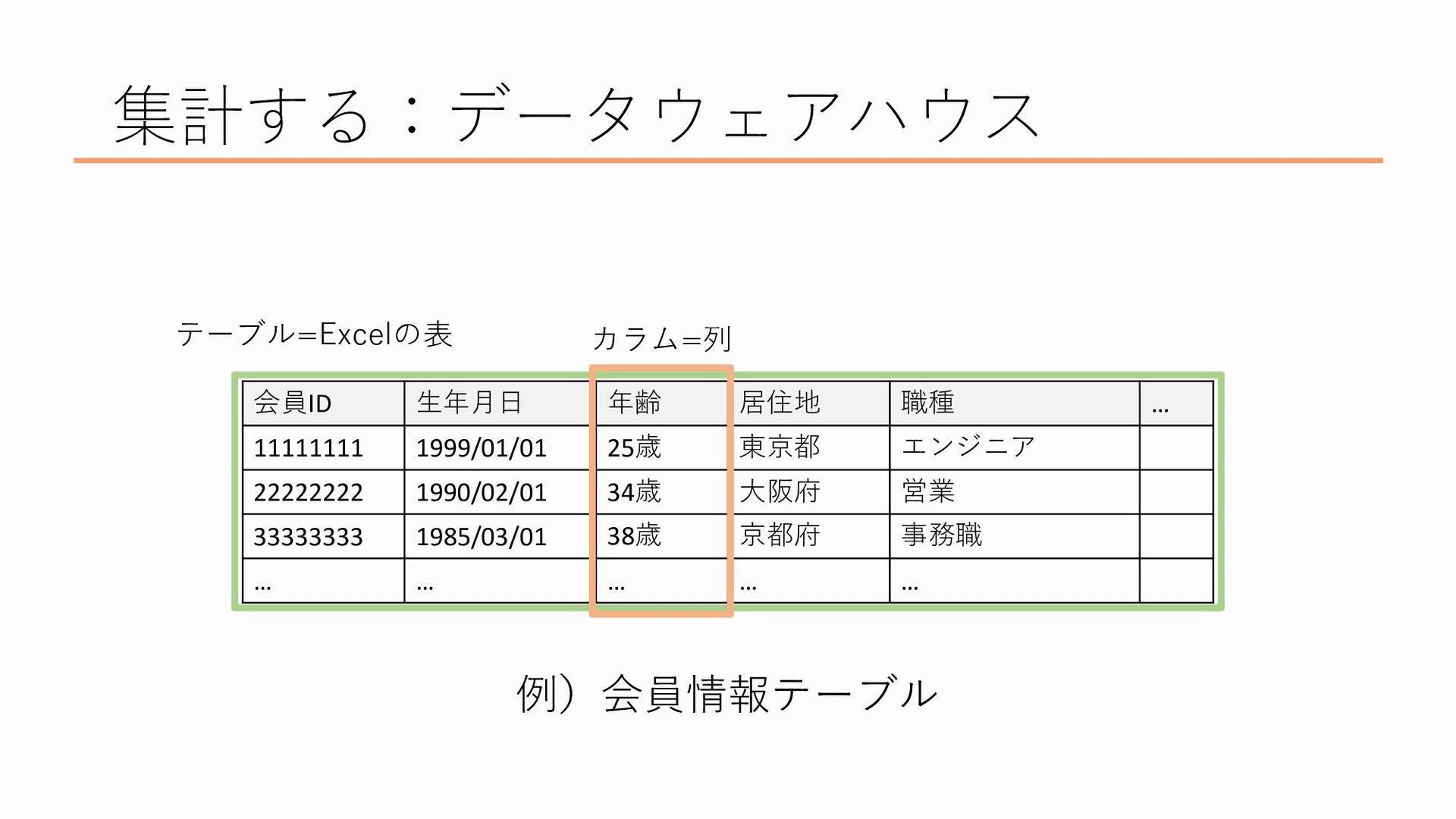
Excelでいう列にあたるのが「カラム」と呼ばれるもので、データの項目ですね、たとえばここでいうと「会員ID」とか「生年月日」とか「年齢」などのそれぞれの列がカラムにあたります
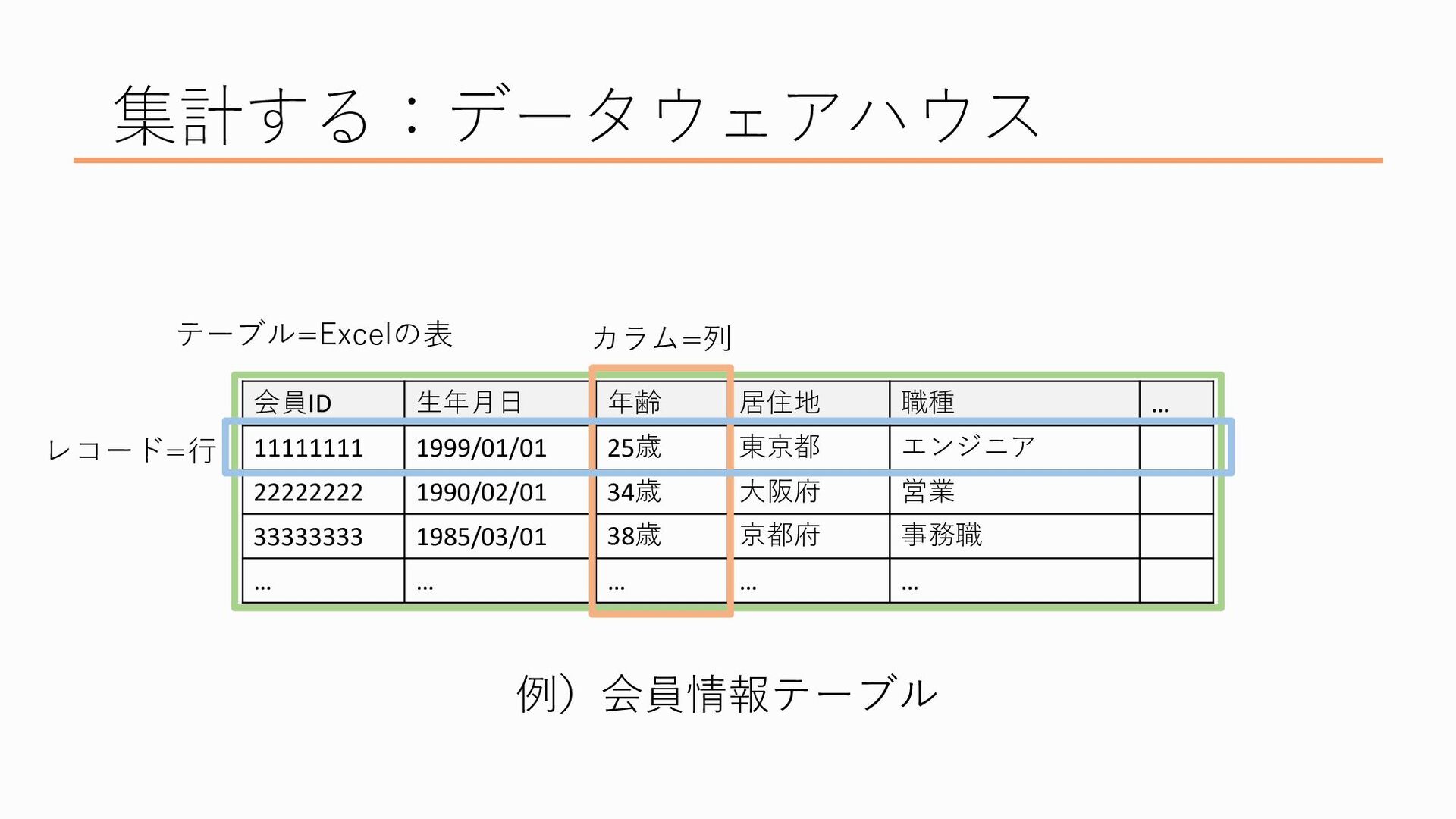
Excelでいう行にあたるのが「レコード」というもので、1レコード、要は一行が一つのデータのまとまり、ここでいうと、会員ID11111111の会員は生年月日が1999/01/01で、25歳で、東京都に住んでいて…という感じです このような形式にデータを揃えるのがデータウェアハウスでの処理の一つです
また、部署を横断した「共通指標」に沿った集計を行ったりもします たとえば、「売上」の定義には消費税を含むのか否か、さらにはクーポンでの割引前の金額なのか割引後の金額なのか… 商品の純粋な本体価格がわからないと困る!という部署と、最終的にユーザーが支払った金額が知りたいんや!という部署とがあったら、それぞれの部署で「売上」の定義が変わってきそうですよね こういった部署によって認識が変わってきそうなデータについては、「売上というのはこういう定義です!」みたいな共通の指標を部署を横断して決めておき、一旦はその定義に沿って数値を集計した方が、その企業の中で横断的にデータを利用しやすくなります もし共通指標とは違う定義で売り上げが見たい!というのであれば、あとあと説明するデータマートを作る時点で、それぞれが見たい数値に集計し直す形になります
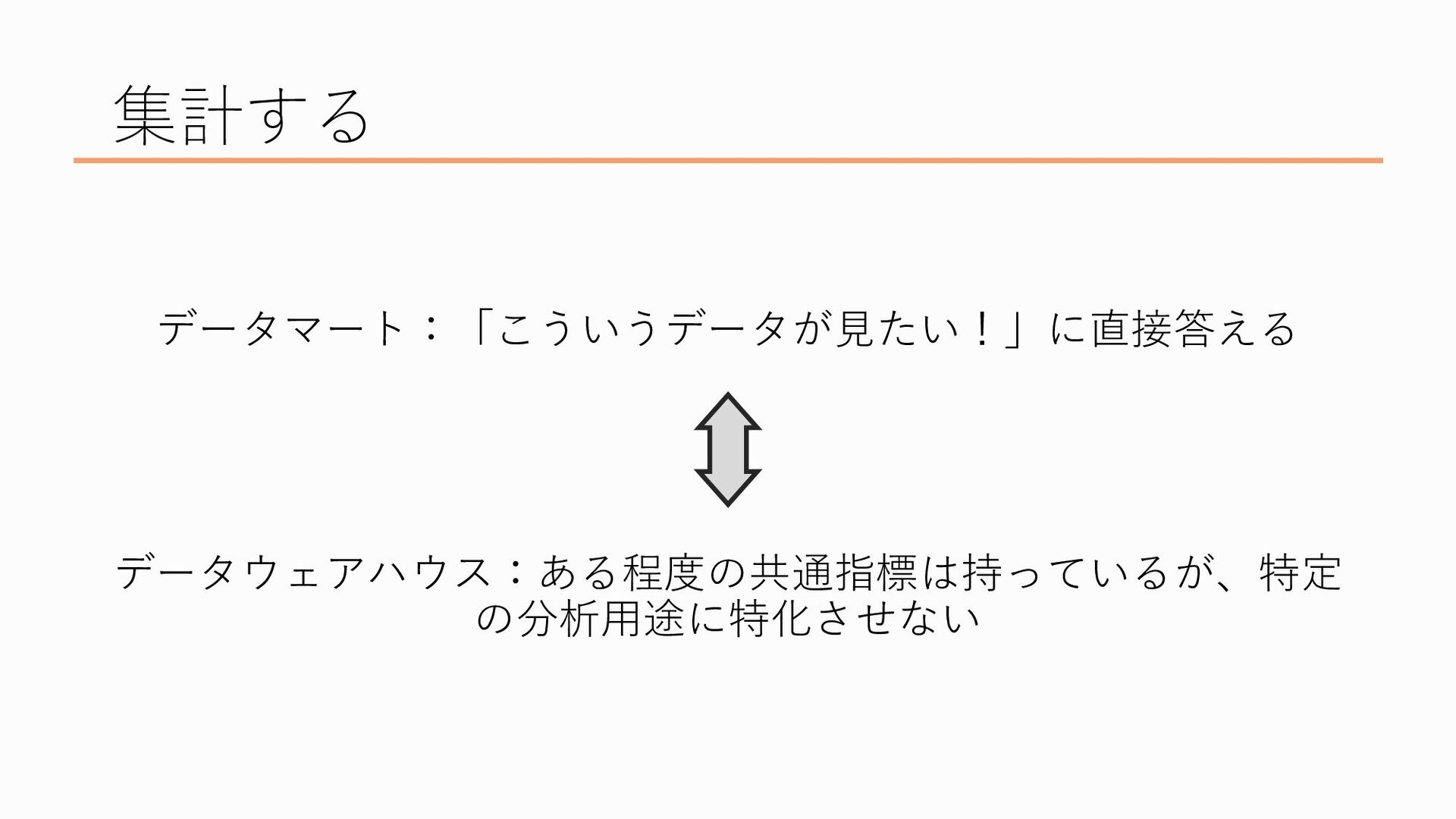
データウェアハウスの次の段階にあたるのがデータマートです、これはすぐに分析に使える、いわば完成品のデータを置いている「市場」のイメージです
データウェアハウスでもある程度のデータの整理や集計は行いましたが、データウェアハウスにあるデータは色々な部署や立場の人が分析に使えるよう、あえて汎用的なデータにしているので、データがぼんやりしていますし、データ量も膨大です。そこから特定の分析用途に向けて集計・加工されたものがデータマートです なんでデータマートを作るのかというと、もちろんデータウェアハウスのデータから直接それぞれが分析をしても良いのですが、定期的にモニタリングしたい数値などは特に、毎回いちいちSQLを書いてデータを抽出して…とやるのは面倒ですし、データ量が多く処理に時間がかかるので分析のたびに毎度毎度待ち時間が発生してしまいます。なので、「この条件のこういうデータが見たい!」というのを先に自動的に集計しておいて、見たいときにいつでもパッと見れる方が楽だよね、っていうので、データマートを作成します
さらに、データウェアハウスから各々がデータを分析するとなると、人によって集計方法が異なって結果が矛盾してしまう可能性があります たとえば、ユーザーが会員登録から30日以内に求人に応募した数を知りたい…といった時に、登録当日を0日目とするのか、それとも当日を1日目とするのか、で当然集計結果は変わってきます 事前にデータマートでデータを集計しておきそれを共有しておくことで、集計する人によって集計結果が変わってしまうことを防ぐ、という目的もあります
このように、「こういうデータが見たい!」に直接答えるのがデータマートで、その手前にある、特定の分析用途に特化させず、かつある程度の共通指標を持っているのがデータウェアハウスなのですが、どこまでが汎用的なテーブルでどこからが特定の目的に特化したテーブルなのか、というのは正直業界や企業、あとは分析基盤を作る人の設計思想によるかなと思うので、とりあえず集計の段階にはデータウェアハウスとデータマートっていう2つの段階・概念があるよ、ということだけ知ってもらえたらと思います
最後、可視化から意思決定等に役立てる、という部分についてです
データマートを作ったのちは、そのデータをBIツールで可視化したり、直接SQLでデータを抽出したりしてデータを分析・活用します データの可視化やデータを利用した機械学習など、データの活用例については後ほど登壇される皆さんが詳しくお話ししてくださるらしいので乞うご期待です
以上がデータ分析基盤の一連の流れになります。 本当はデータの収集から集計までの処理を自動でやってくれるワークフローエンジンのお話やメタデータのお話しもしたかったのですが、時間の都合で泣く泣く(?)カットしました。またどこかの機会でお話しできたらと思います。そんな機会があるかは不明ですが。
さて、改めてこの図を見てみると、データが生成されてからデータ分析者に届くまでの過程、この四角の中でどのようなことが行われているのか、というのが理解いただけたのではないでしょうか
話をまとめると、データ分析基盤とは必要なデータを「正しく生成し」、「正しく集め」、 「目的に沿って集計・可視化し」、「意思決定等に役立てる」ためのシステムです、 ということと、 データ分析基盤の一連の処理がスムーズに行われるよう運用・管理したり、データウェアハウス・データマートを開発したりしているのがデータエンジニアです、 ということ、この2つを知ってもらえたら嬉しいなと思いますし、この後に登壇される方々のお話も理解しやすくなるんじゃないかなと思います
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}