Share
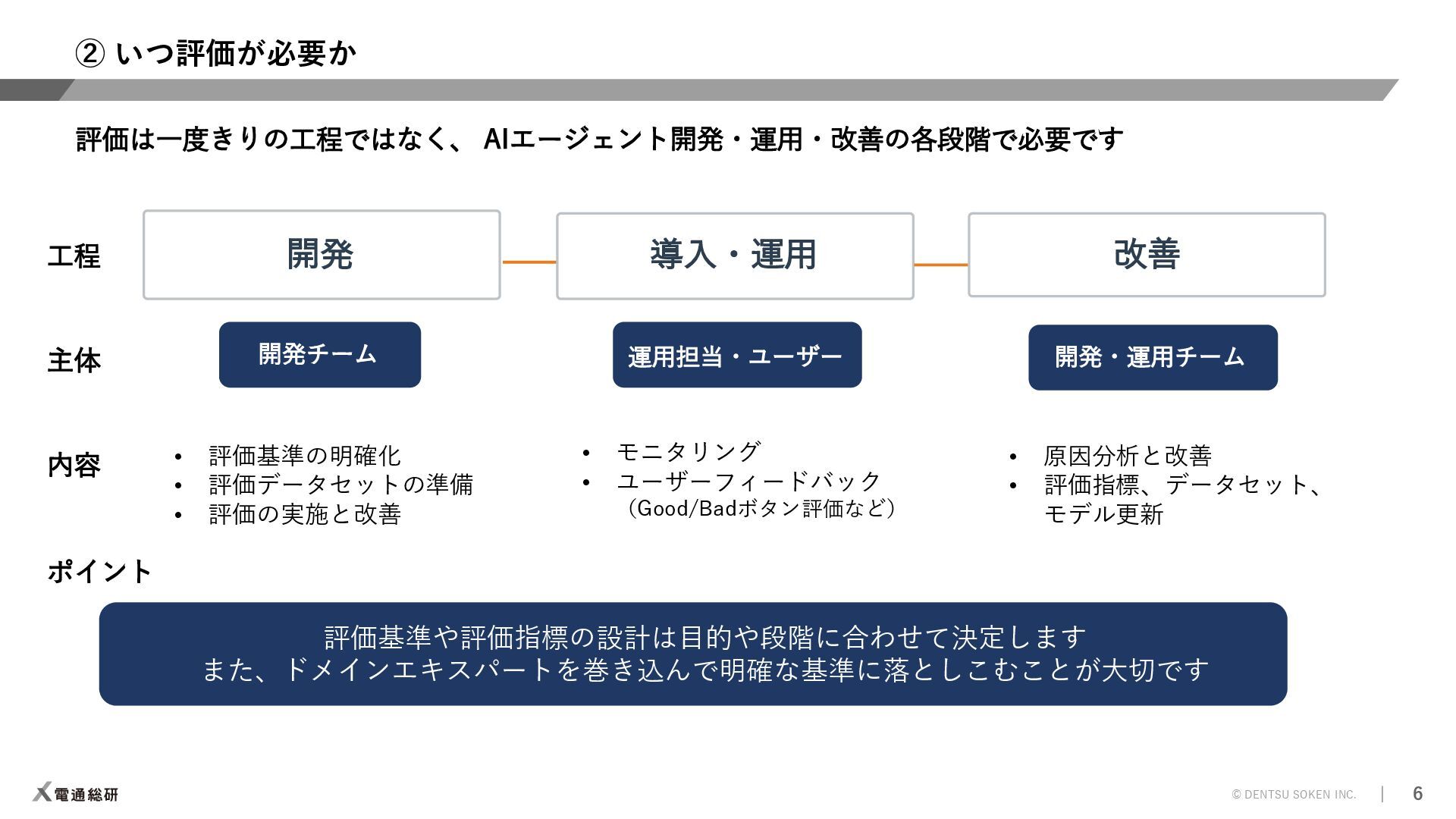
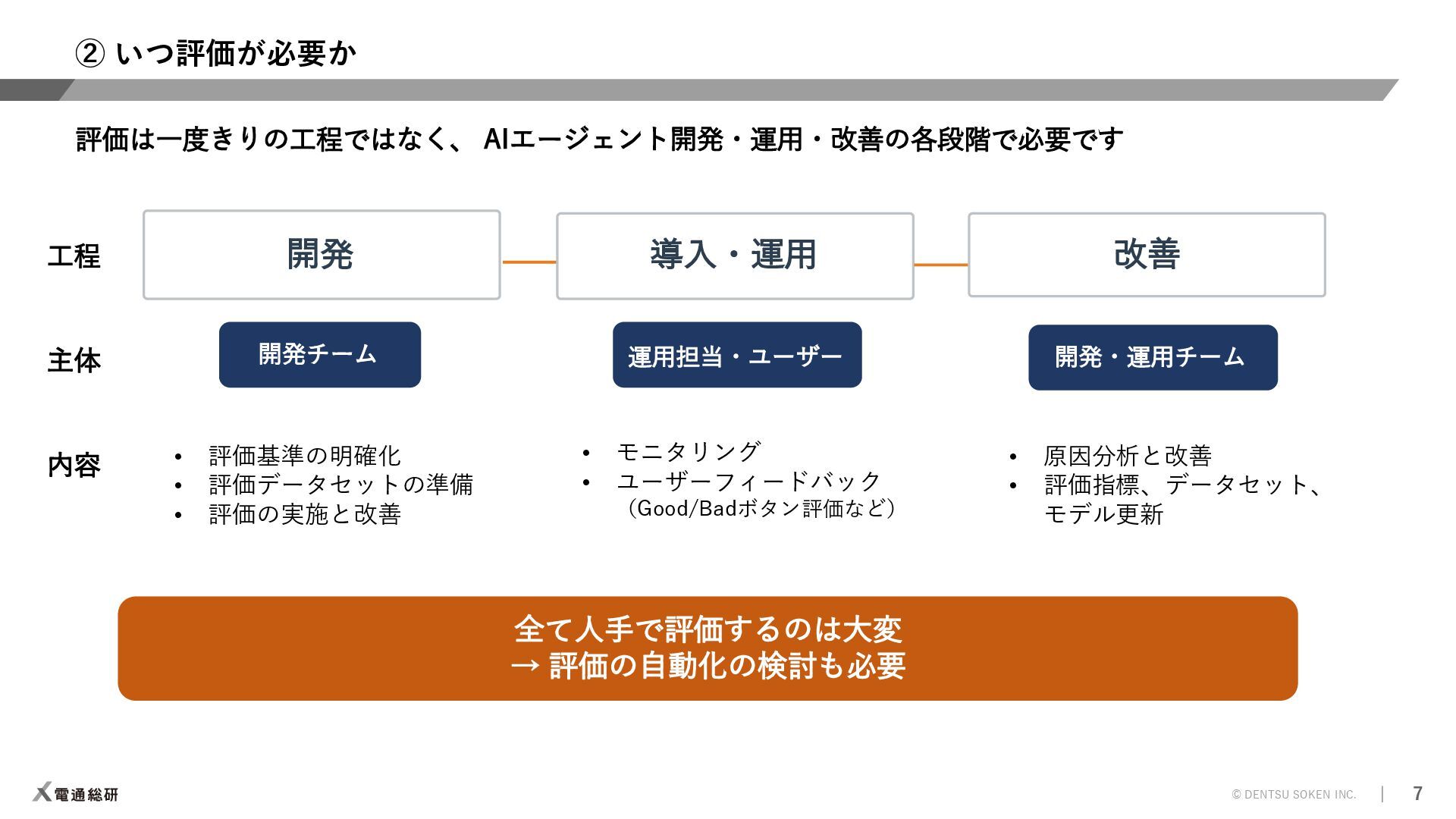
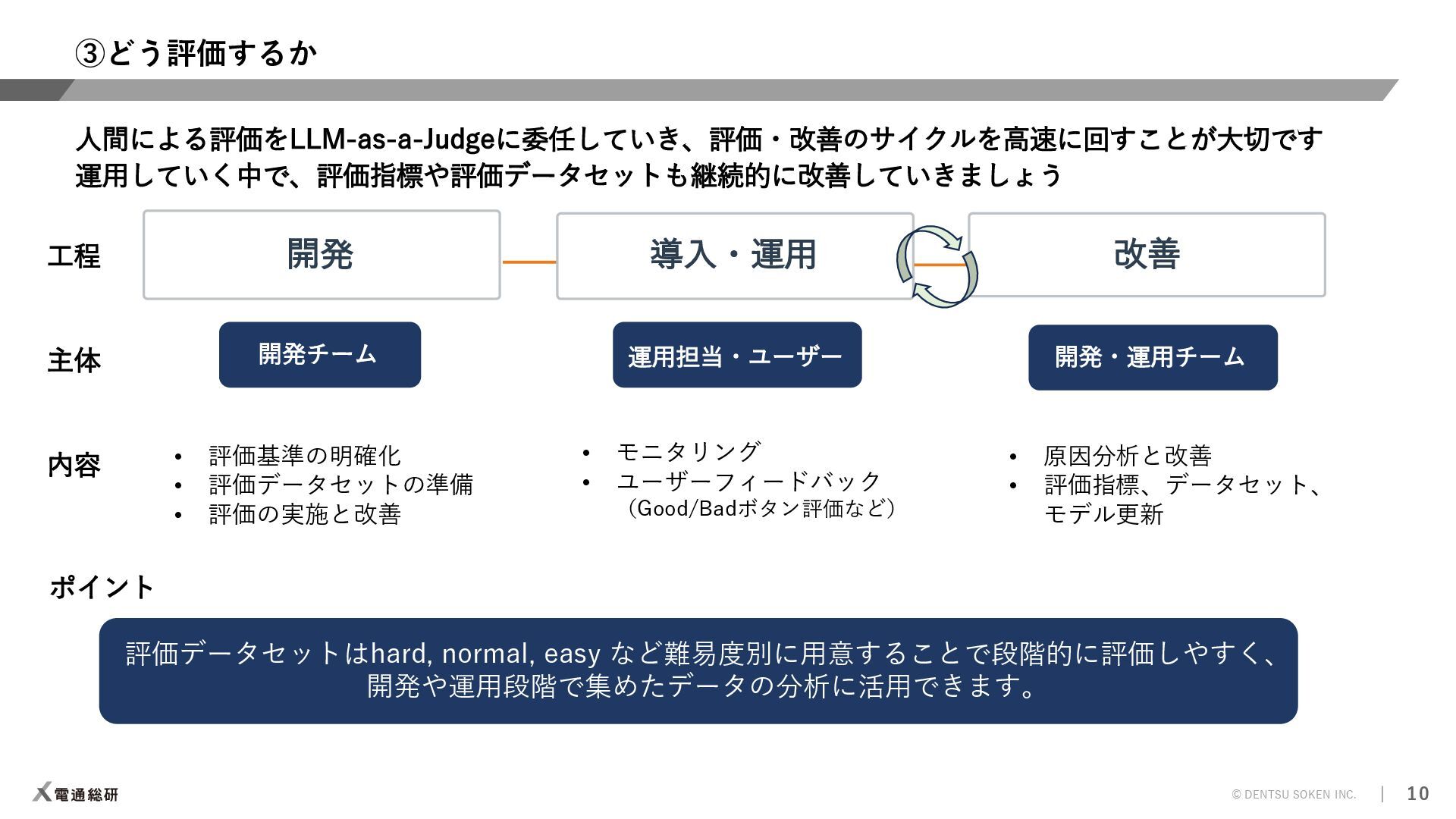
AIエージェントについて、「何を評価するか」「いつ評価するか」「どう評価するか」という観点から、ポイントを絞って解説します。 ※本資料はWeights & Biases主催のFully Connected 2025 Tokyoのワークショップで発表した資料になります。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}