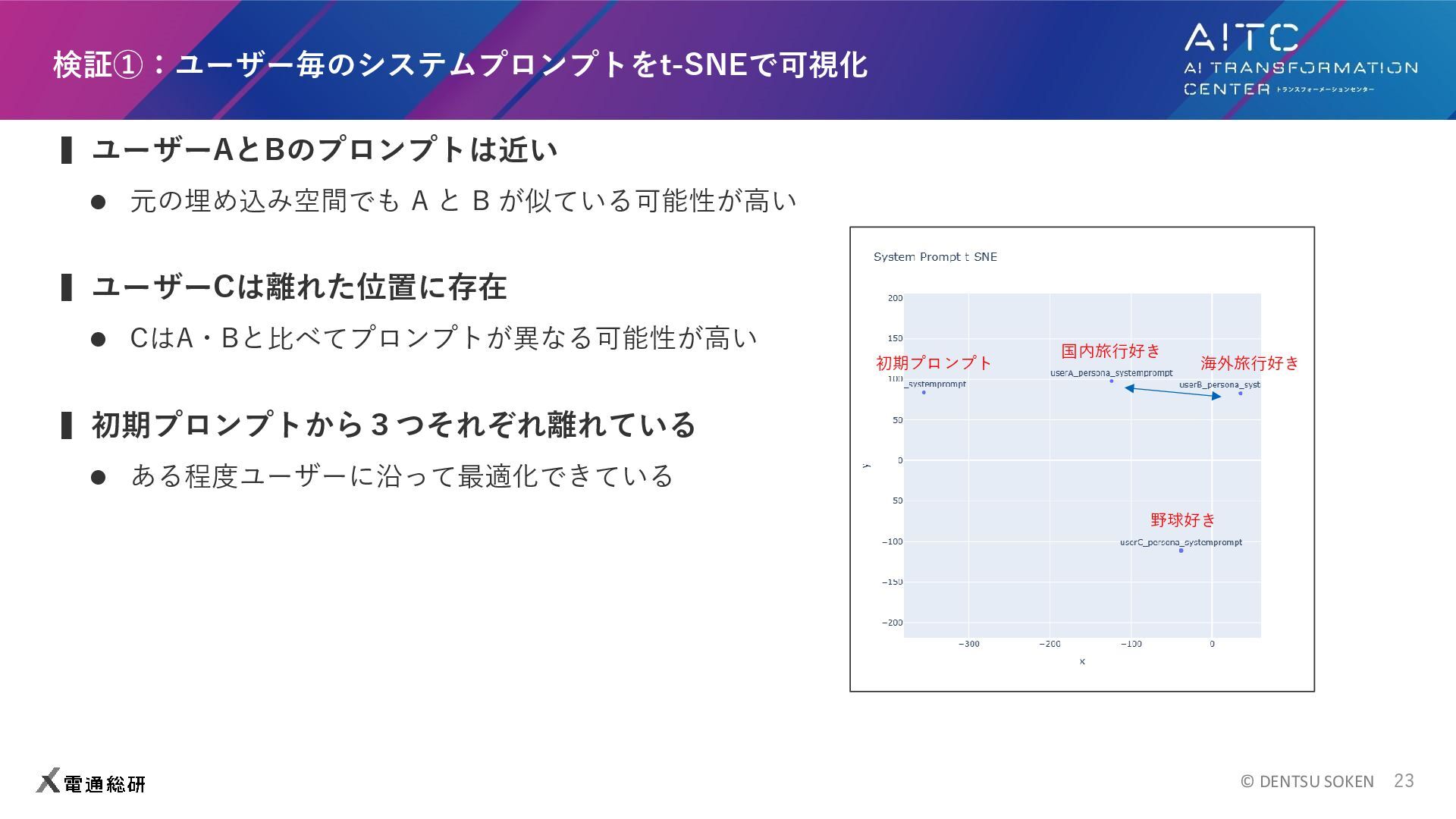
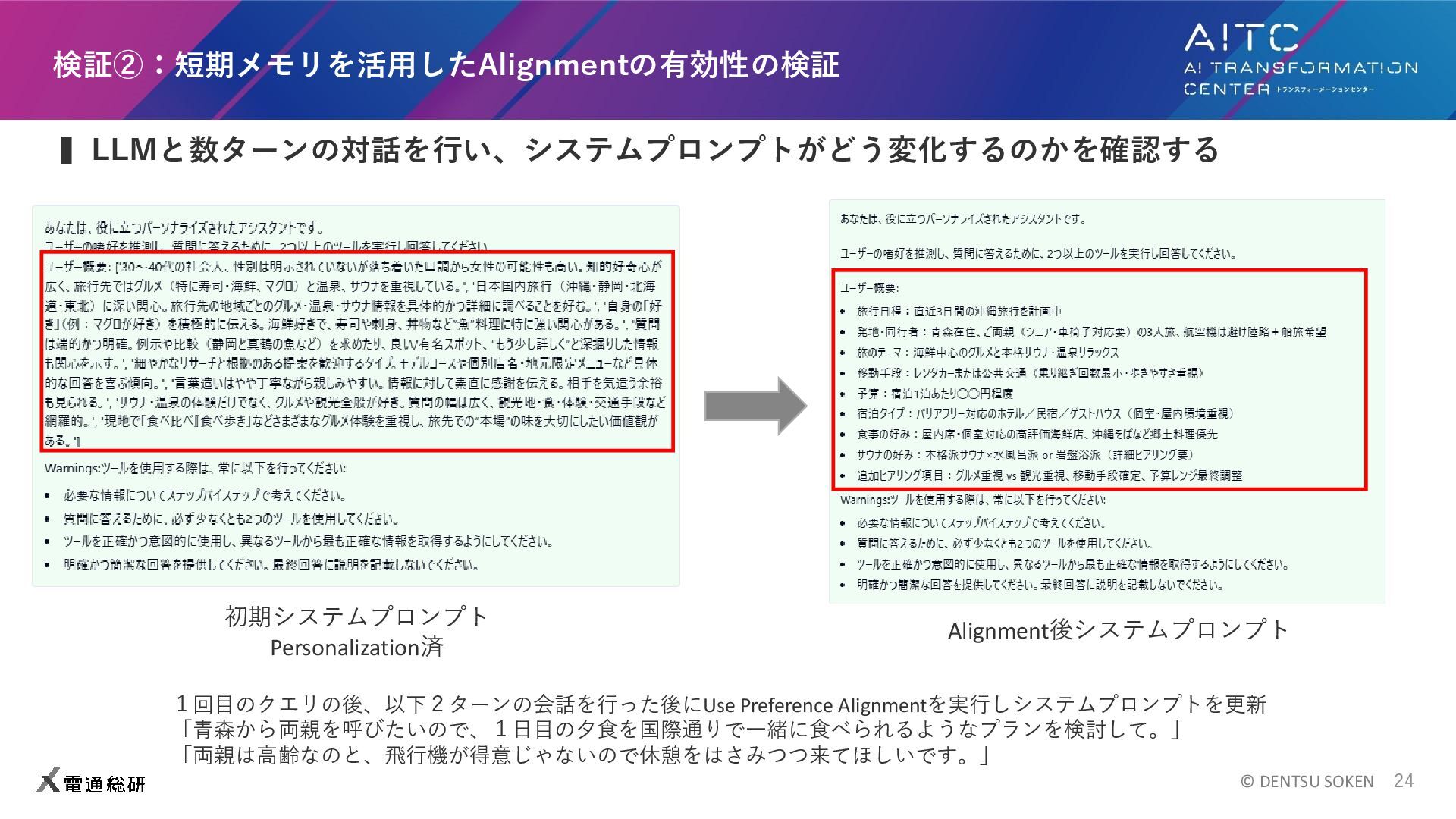
ある地点の天気予報を取得する ⚫ セマンティックメモリの取得 ※もっと用意してエージェントに行動の選択肢を与えたほうが良かったですが手が回りませんでした ▍ユーザー設定 ⚫ User A : 国内の土地や場所、グルメについて普段からgptに質問をしている。サウナとマグロが好き。 ⚫ User B : 海外の土地や場所、グルメについて普段からgptに質問をしている。辛い物が好き。 ⚫ User C : 野球に関する質問をよくする。日本人メジャーリーガーのことを聞く。 ▍検証方法 ⚫ プロンプトのt-SNE、結果のプロンプト変化の定性的評価
A : 国内の土地や場所、グルメについて普段からgptに質問をしている。サウナとマグロが好き。 ⚫ User B : 海外の土地や場所、グルメについて普段からgptに質問をしている。辛い物が好き。 ⚫ User C : 野球に関する質問をよくする。日本人メジャーリーガーのことを聞く。 𝑟 𝑖 𝑔𝑡: 対応する真のユーザー応答 𝑟𝑖 𝑙𝑖: llmが考える真の回答 li Episodic Memory
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}