Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
輪講資料:UNI-SIGN: TOWARD UNIFIED SIGN LANGUAGE UN-...
Search
Jundai Inoue
May 24, 2025
18
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
輪講資料:UNI-SIGN: TOWARD UNIFIED SIGN LANGUAGE UN- DERSTANDING AT SCALE
5分で論文紹介
Jundai Inoue
May 24, 2025
More Decks by Jundai Inoue
See All by Jundai Inoue
500xCompressor: Generalized Prompt Compression for Large Language Models
jkmt
0
89
VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
jkmt
0
670
T2S-GPT: Dynamic Vector Quantization for Autoregressive Sign Language Production from Text
jkmt
0
110
Featured
See All Featured
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Navigating Weather and Climate Data
rabernat
0
280
Balancing Empowerment & Direction
lara
6
1.2k
Rails Girls Zürich Keynote
gr2m
96
14k
GraphQLとの向き合い方2022年版
quramy
50
15k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
180
Between Models and Reality
mayunak
4
360
My Coaching Mixtape
mlcsv
0
170
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Test your architecture with Archunit
thirion
1
2.3k
Transcript
井上 純大(豊田工業大学 知識データ工学研究室 M2) @ICLR2025 図表は論文,[1]より引用
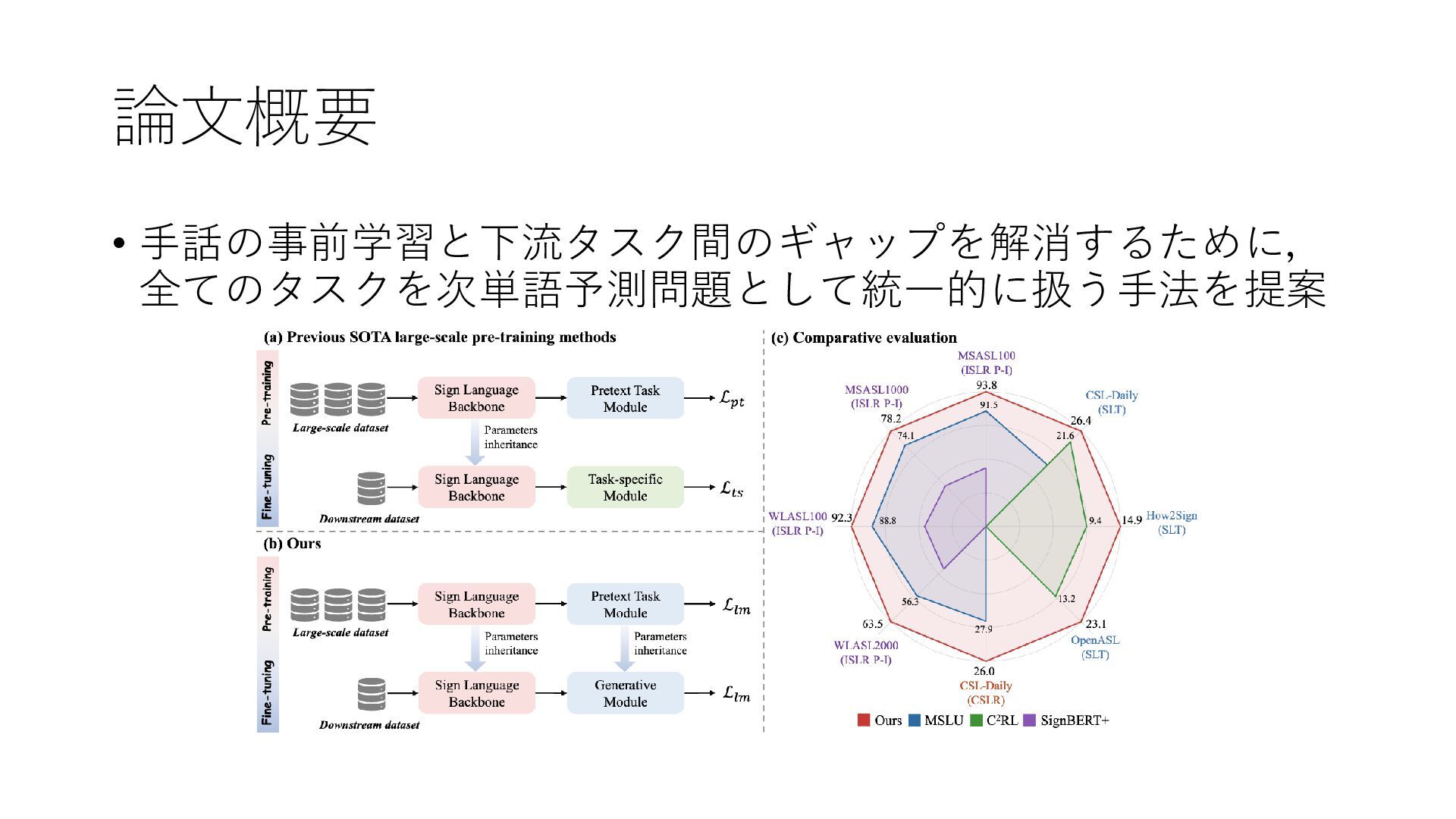
論文概要 • 手話の事前学習と下流タスク間のギャップを解消するために, 全てのタスクを次単語予測問題として統一的に扱う手法を提案
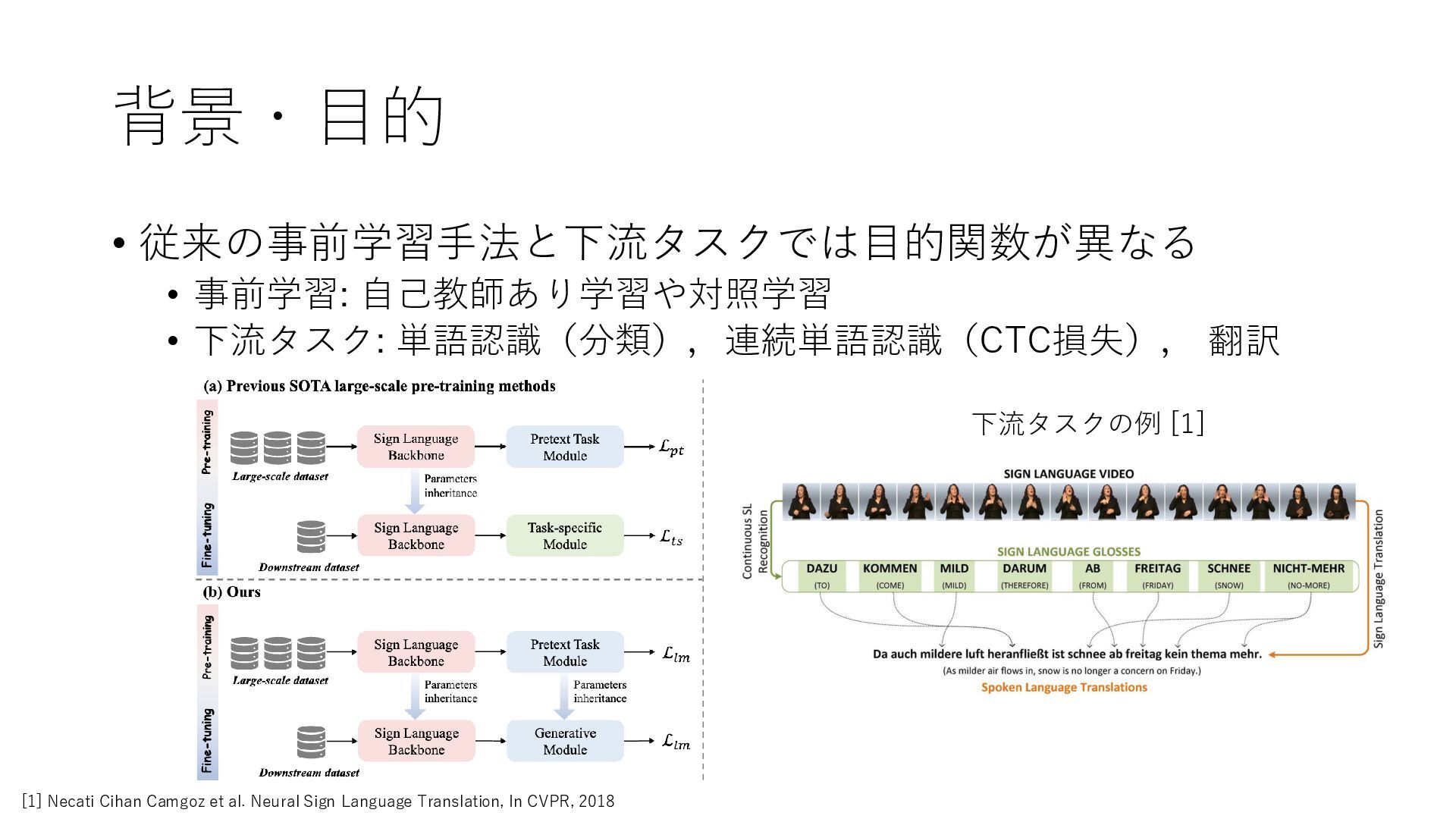
背景・目的 • 従来の事前学習手法と下流タスクでは目的関数が異なる • 事前学習: 自己教師あり学習や対照学習 • 下流タスク: 単語認識(分類),連続単語認識(CTC損失), 翻訳
下流タスクの例 [1] [1] Necati Cihan Camgoz et al. Neural Sign Language Translation, In CVPR, 2018
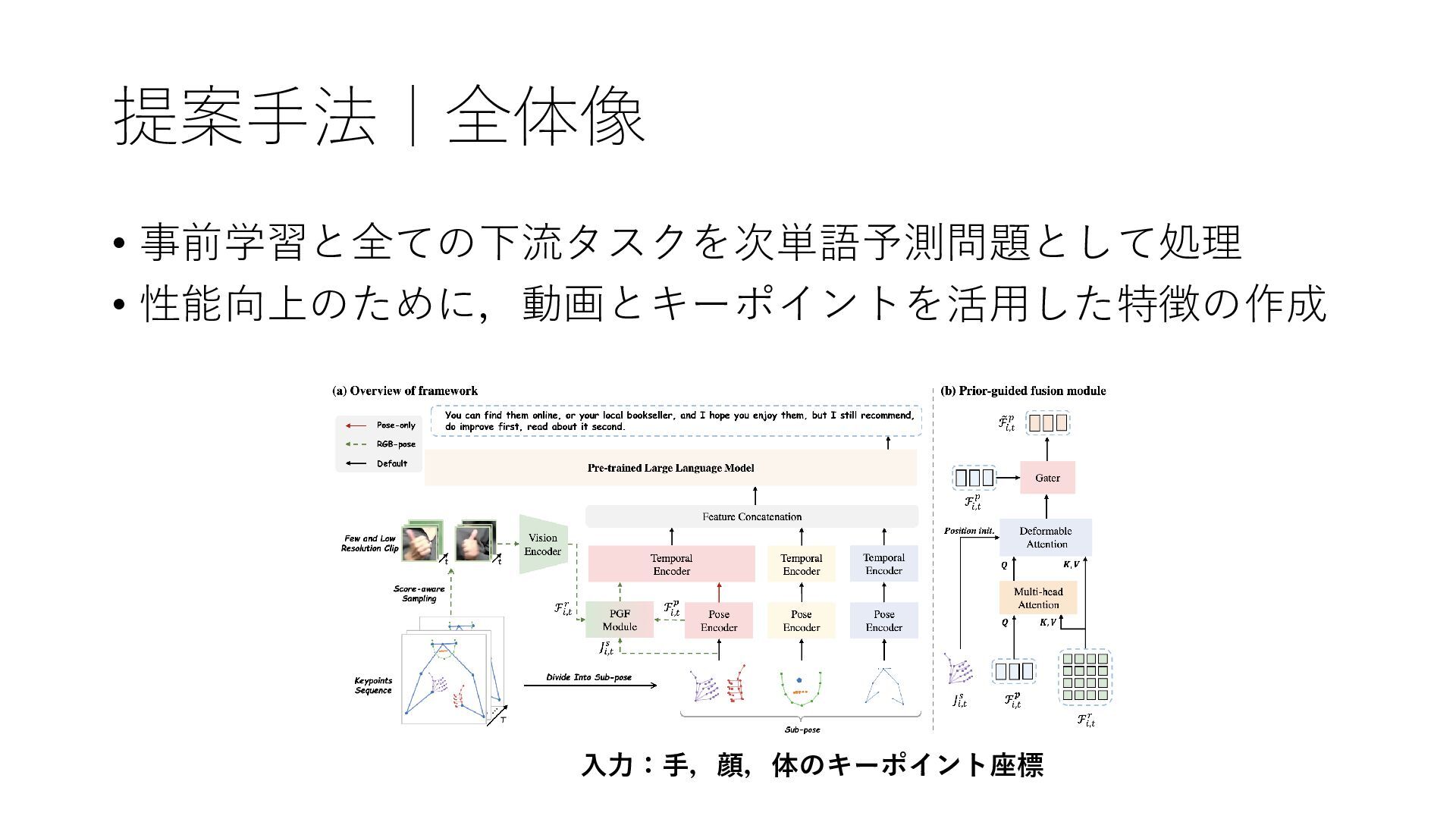
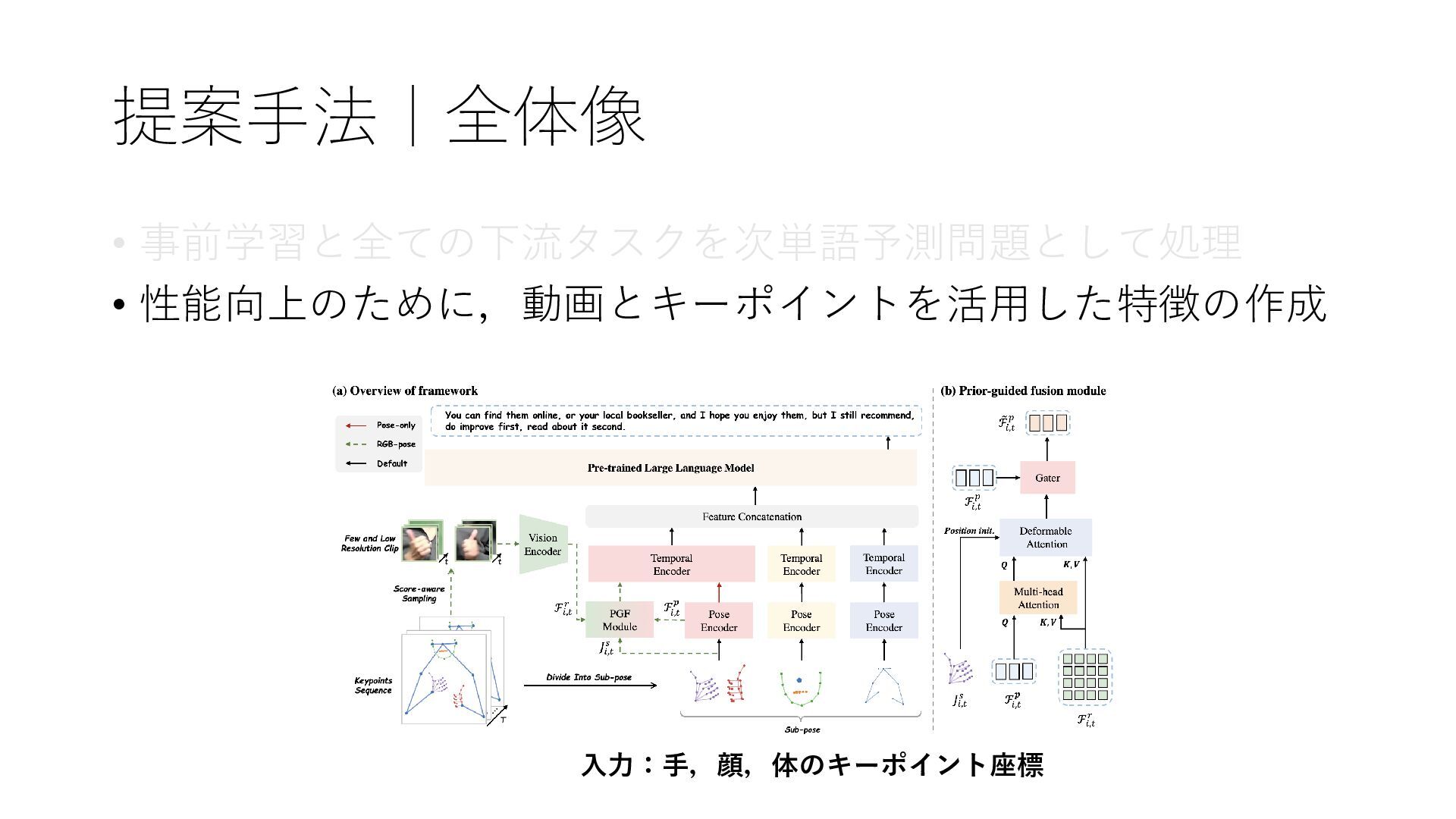
提案手法|全体像 • 事前学習と全ての下流タスクを次単語予測問題として処理 • 性能向上のために,動画とキーポイントを活用した特徴の作成 入力:手,顔,体のキーポイント座標
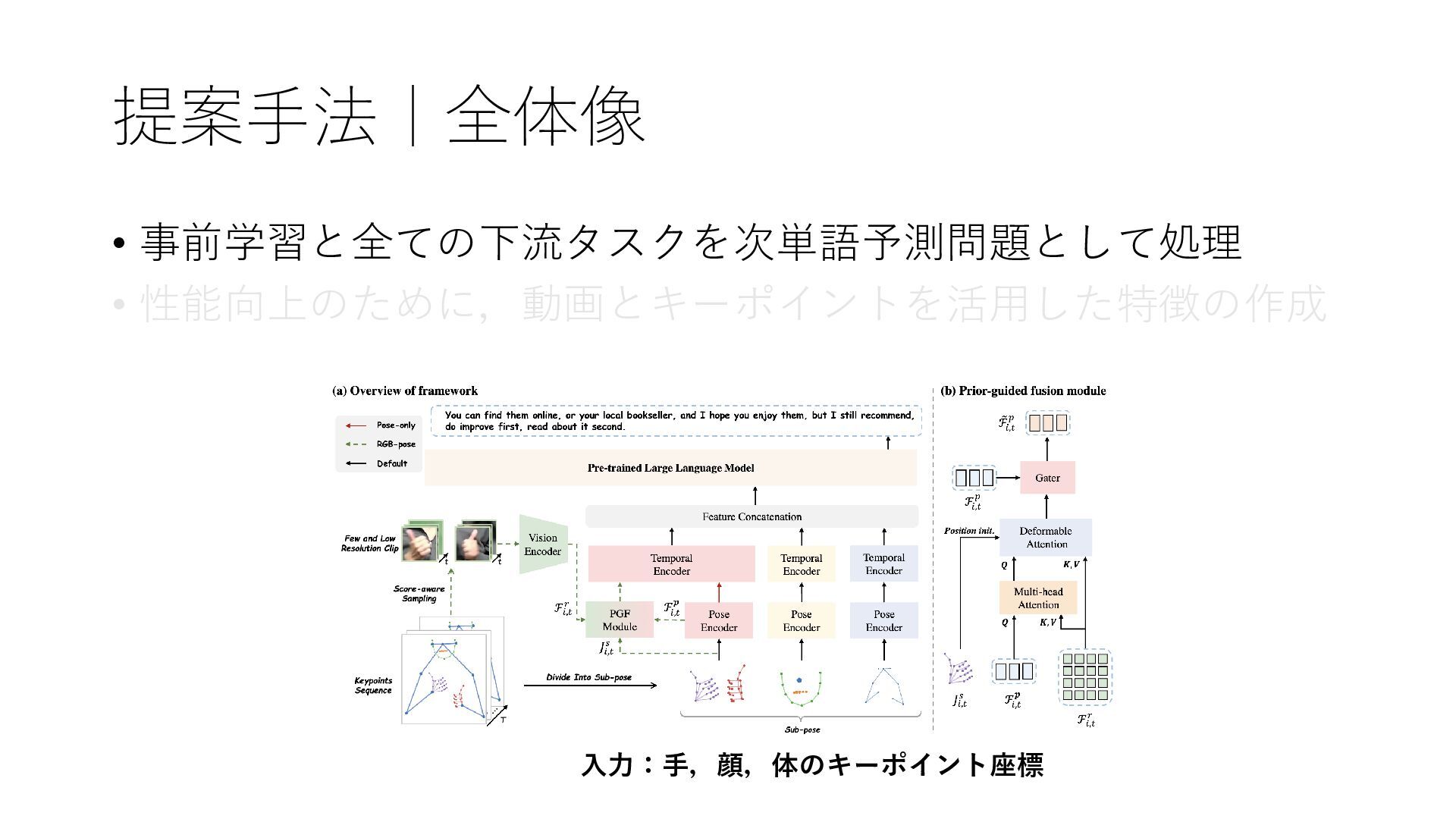
提案手法|全体像 • 事前学習と全ての下流タスクを次単語予測問題として処理 • 性能向上のために,動画とキーポイントを活用した特徴の作成 入力:手,顔,体のキーポイント座標
提案手法|次単語予測問題として定式化 • 事前学習と下流タスクで同じ目的関数で学習 →タスク間のギャップを解消 • 手話の特徴を言語モデル(mT5-base)に入力し,次単語を予測 • 損失関数: Fsign: キーポイントや動画から
得られる手話の特徴 s u : u番目のトークン
提案手法|全体像 • 事前学習と全ての下流タスクを次単語予測問題として処理 • 性能向上のために,動画とキーポイントを活用した特徴の作成 入力:手,顔,体のキーポイント座標
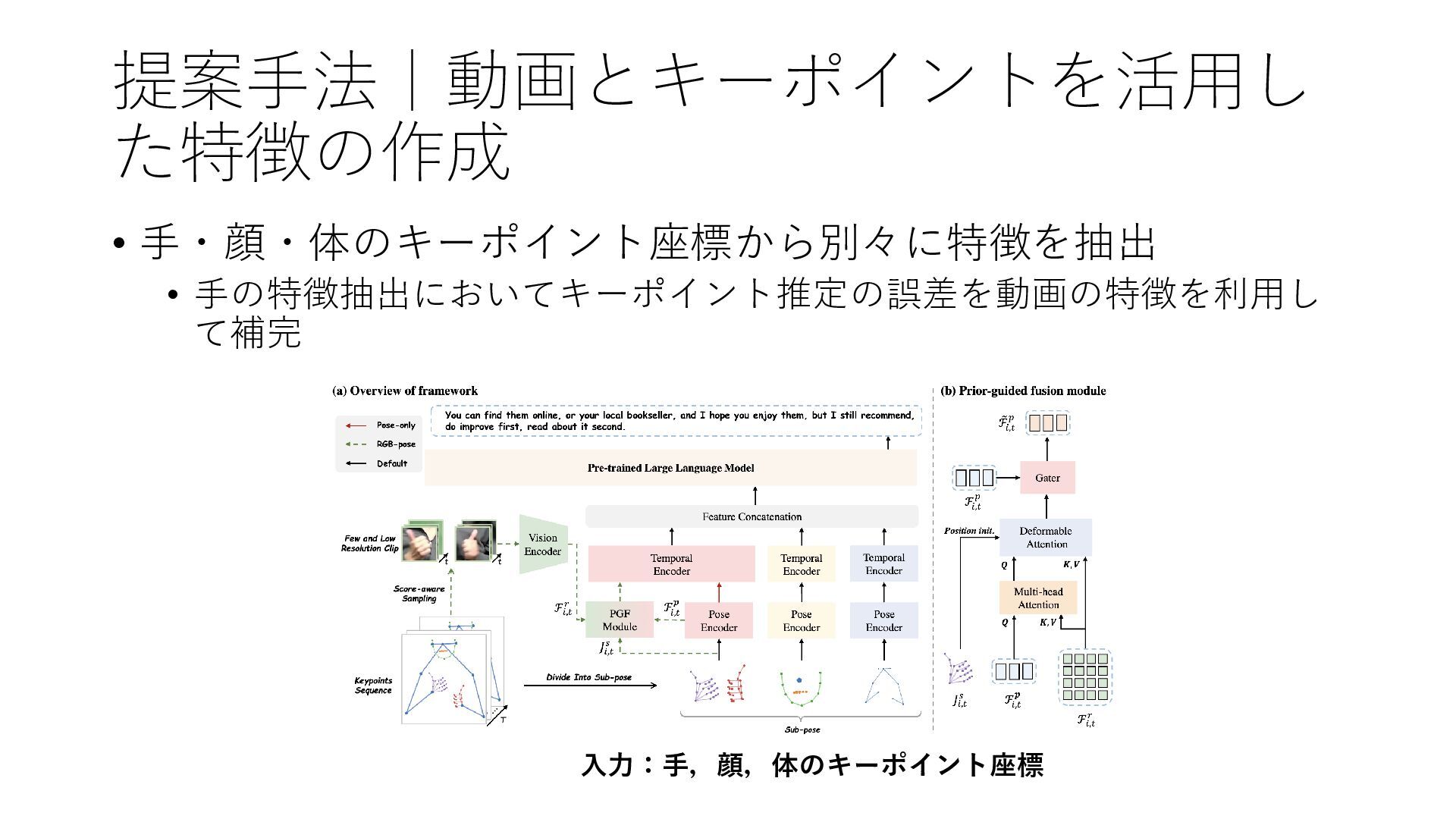
提案手法|動画とキーポイントを活用し た特徴の作成 入力:手,顔,体のキーポイント座標 • 手・顔・体のキーポイント座標から別々に特徴を抽出 • 手の特徴抽出においてキーポイント推定の誤差を動画の特徴を利用し て補完
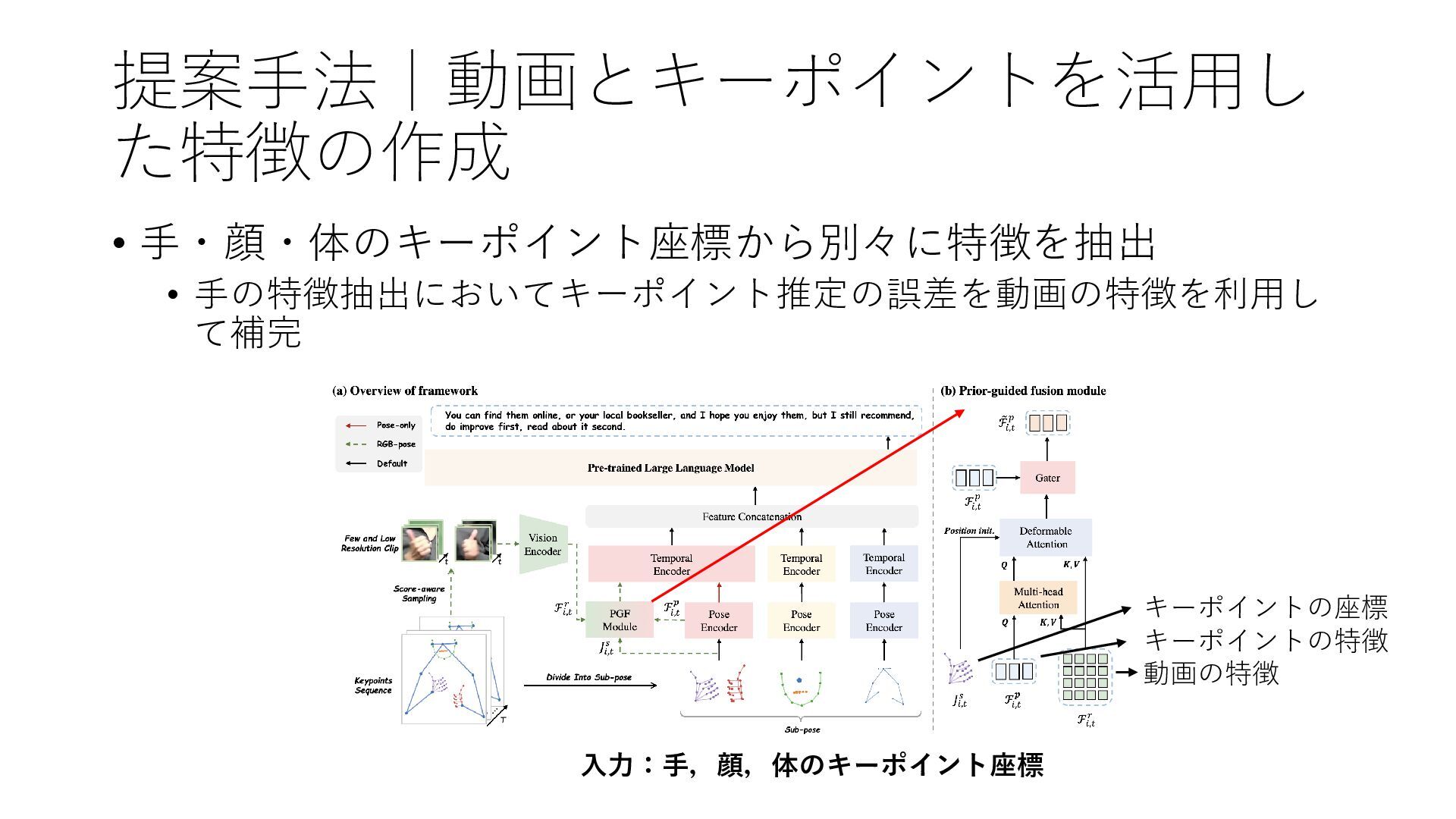
提案手法|動画とキーポイントを活用し た特徴の作成 入力:手,顔,体のキーポイント座標 • 手・顔・体のキーポイント座標から別々に特徴を抽出 • 手の特徴抽出においてキーポイント推定の誤差を動画の特徴を利用し て補完 キーポイントの座標 キーポイントの特徴
動画の特徴
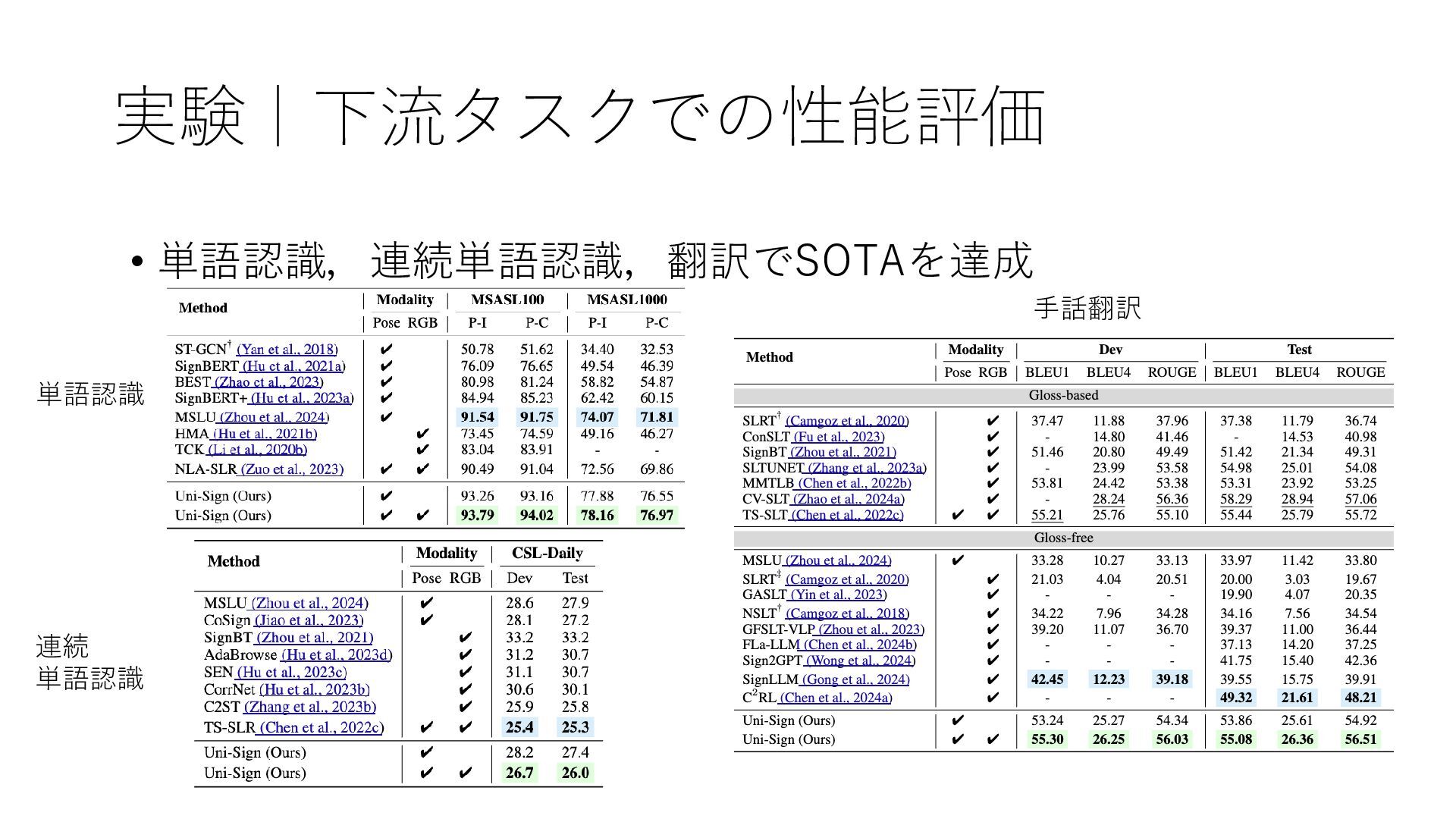
実験|下流タスクでの性能評価 • 単語認識,連続単語認識,翻訳でSOTAを達成 単語認識 連続 単語認識 手話翻訳
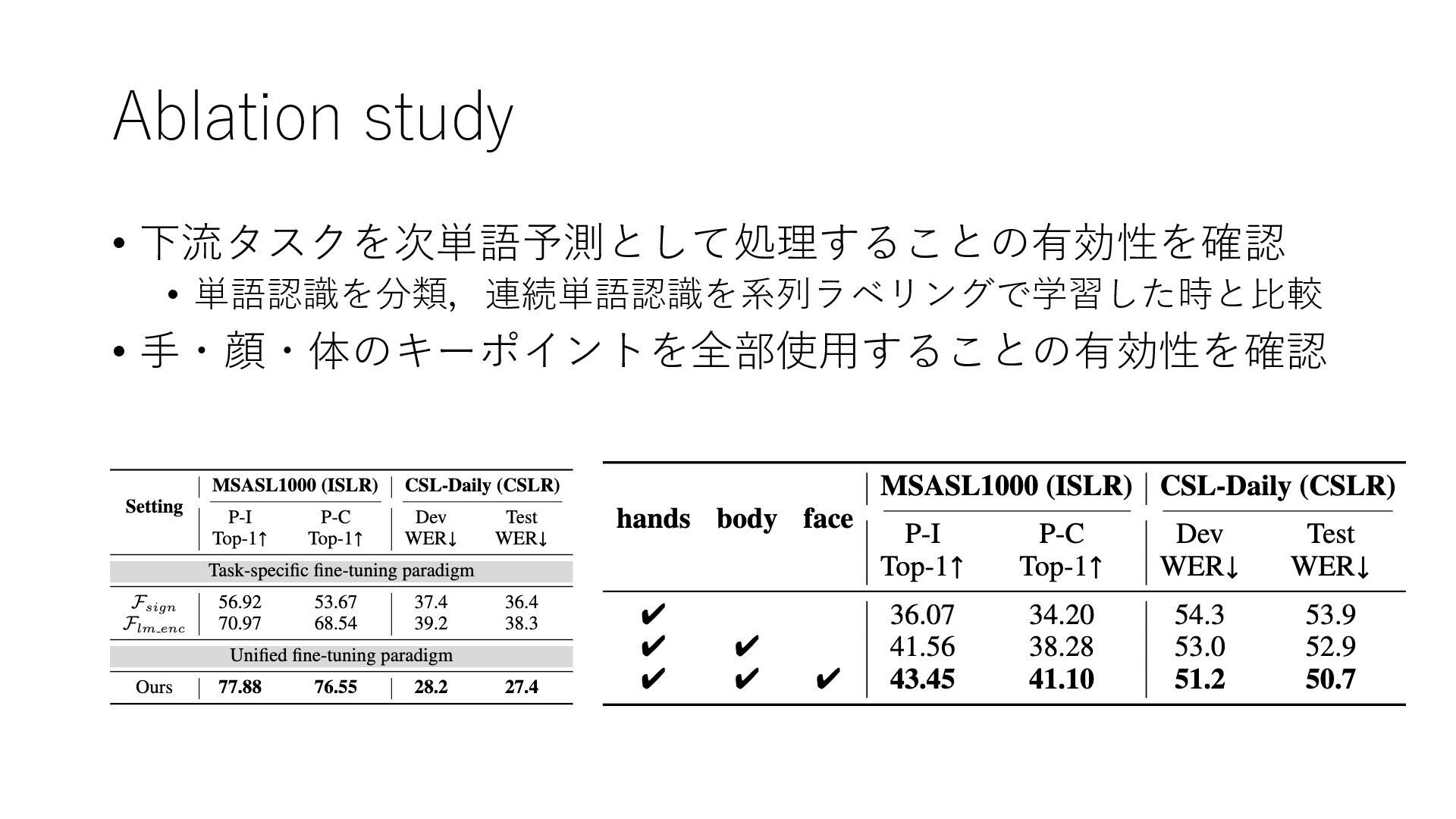
Ablation study • 下流タスクを次単語予測として処理することの有効性を確認 • 単語認識を分類,連続単語認識を系列ラベリングで学習した時と比較 • 手・顔・体のキーポイントを全部使用することの有効性を確認
![井上 純大(豊田工業大学 知識データ工学研究室 M2) @ICLR2025 図表は論文,[1]より引用](https://files.speakerdeck.com/presentations/56b8a029b2d645908419646392d9e102/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}