Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
VideoMAE V2: Scaling Video Masked Autoencoders ...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Jundai Inoue
December 21, 2024
670
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
Jundai Inoue
December 21, 2024
More Decks by Jundai Inoue
See All by Jundai Inoue
500xCompressor: Generalized Prompt Compression for Large Language Models
jkmt
0
89
輪講資料:UNI-SIGN: TOWARD UNIFIED SIGN LANGUAGE UN- DERSTANDING AT SCALE
jkmt
0
18
T2S-GPT: Dynamic Vector Quantization for Autoregressive Sign Language Production from Text
jkmt
0
110
Featured
See All Featured
Thoughts on Productivity
jonyablonski
76
5.2k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
310
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.2k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Side Projects
sachag
455
43k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.7k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Transcript
e 井上 純大
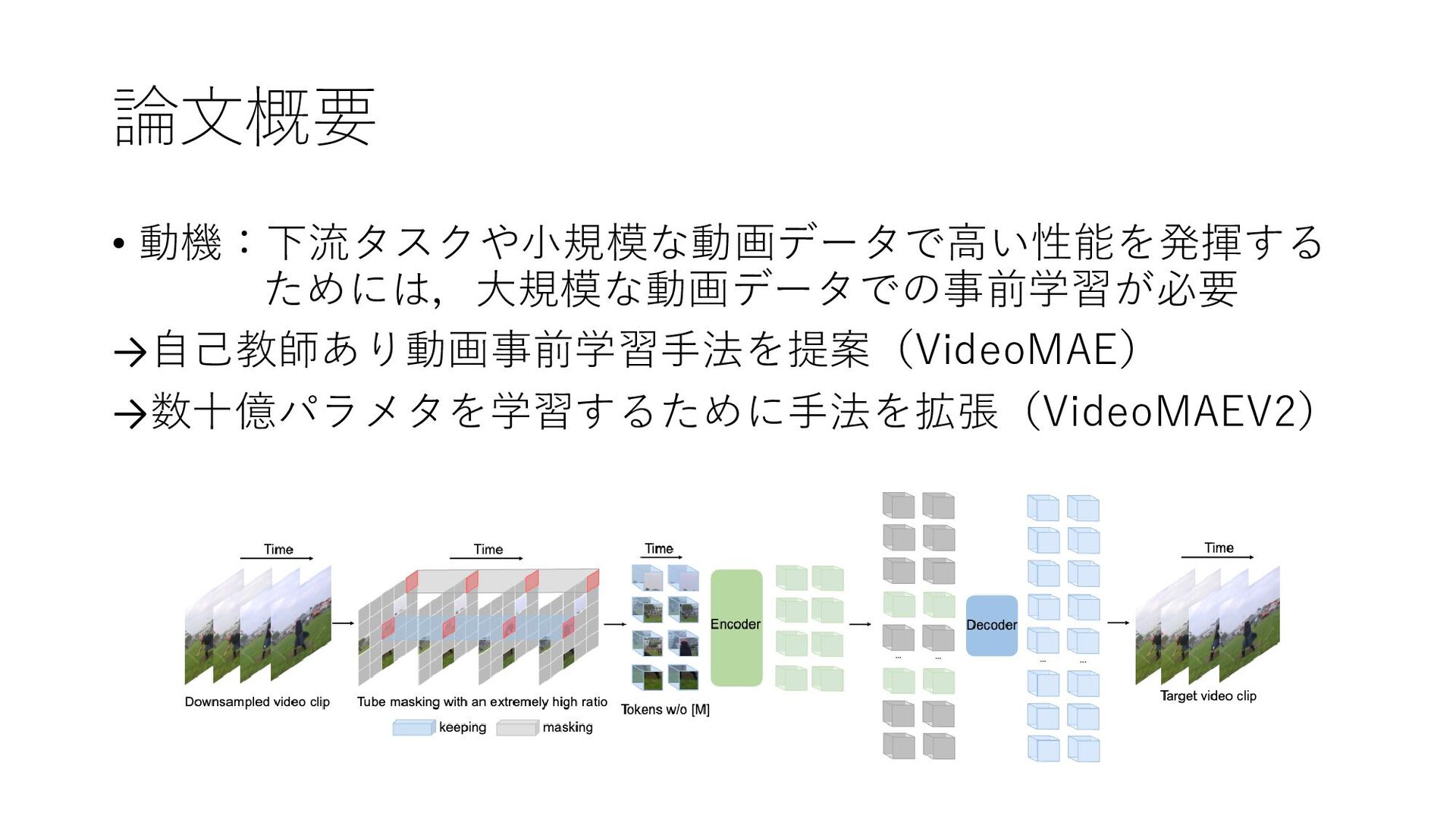
論文概要 • 動機:下流タスクや小規模な動画データで高い性能を発揮する ためには,大規模な動画データでの事前学習が必要 →自己教師あり動画事前学習手法を提案(VideoMAE) →数十億パラメタを学習するために手法を拡張(VideoMAEV2)
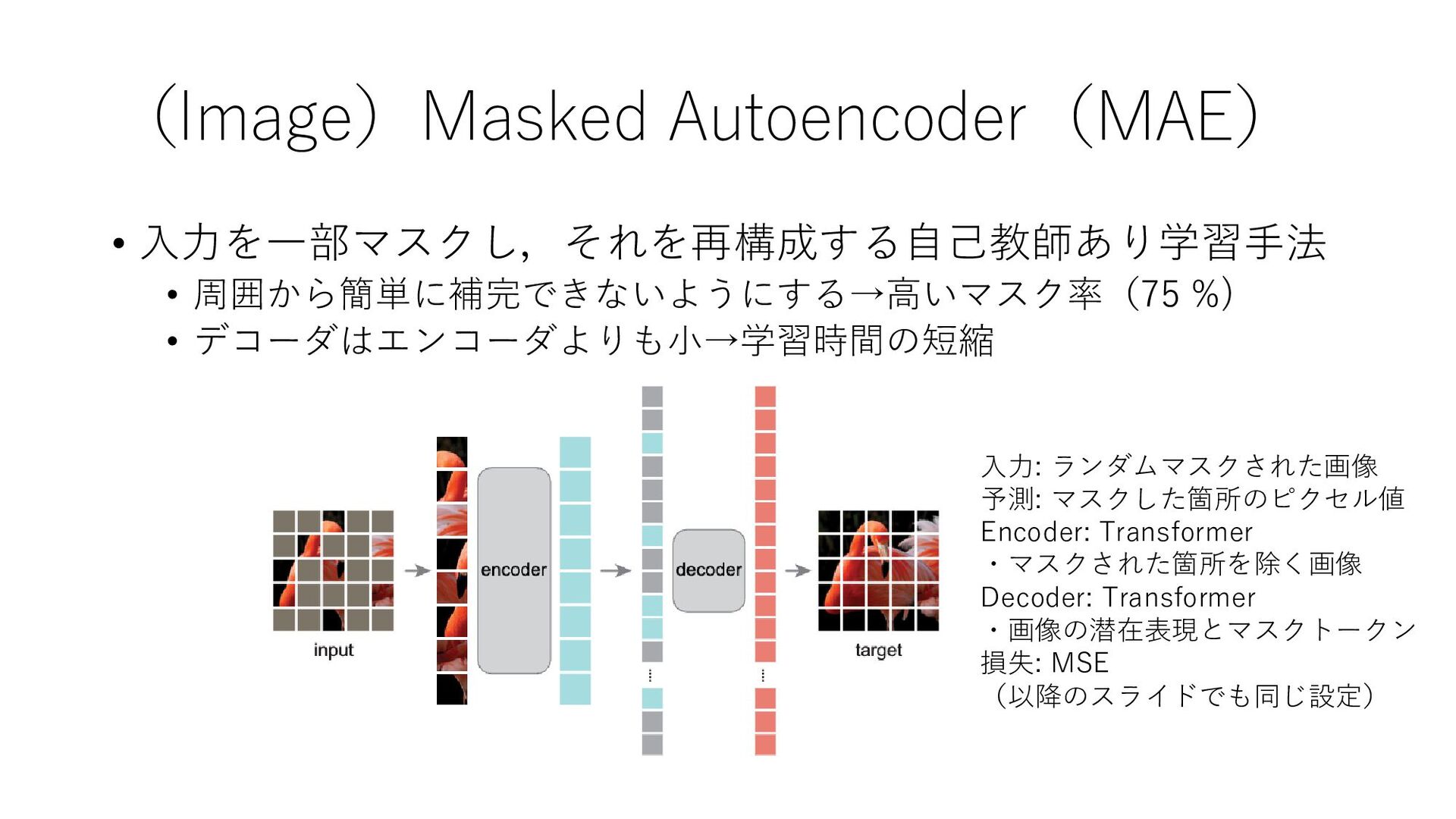
(Image)Masked Autoencoder(MAE) • 入力を一部マスクし,それを再構成する自己教師あり学習手法 • 周囲から簡単に補完できないようにする→高いマスク率(75 %) • デコーダはエンコーダよりも小→学習時間の短縮 入力:
ランダムマスクされた画像 予測: マスクした箇所のピクセル値 Encoder: Transformer ・マスクされた箇所を除く画像 Decoder: Transformer ・画像の潜在表現とマスクトークン 損失: MSE (以降のスライドでも同じ設定)
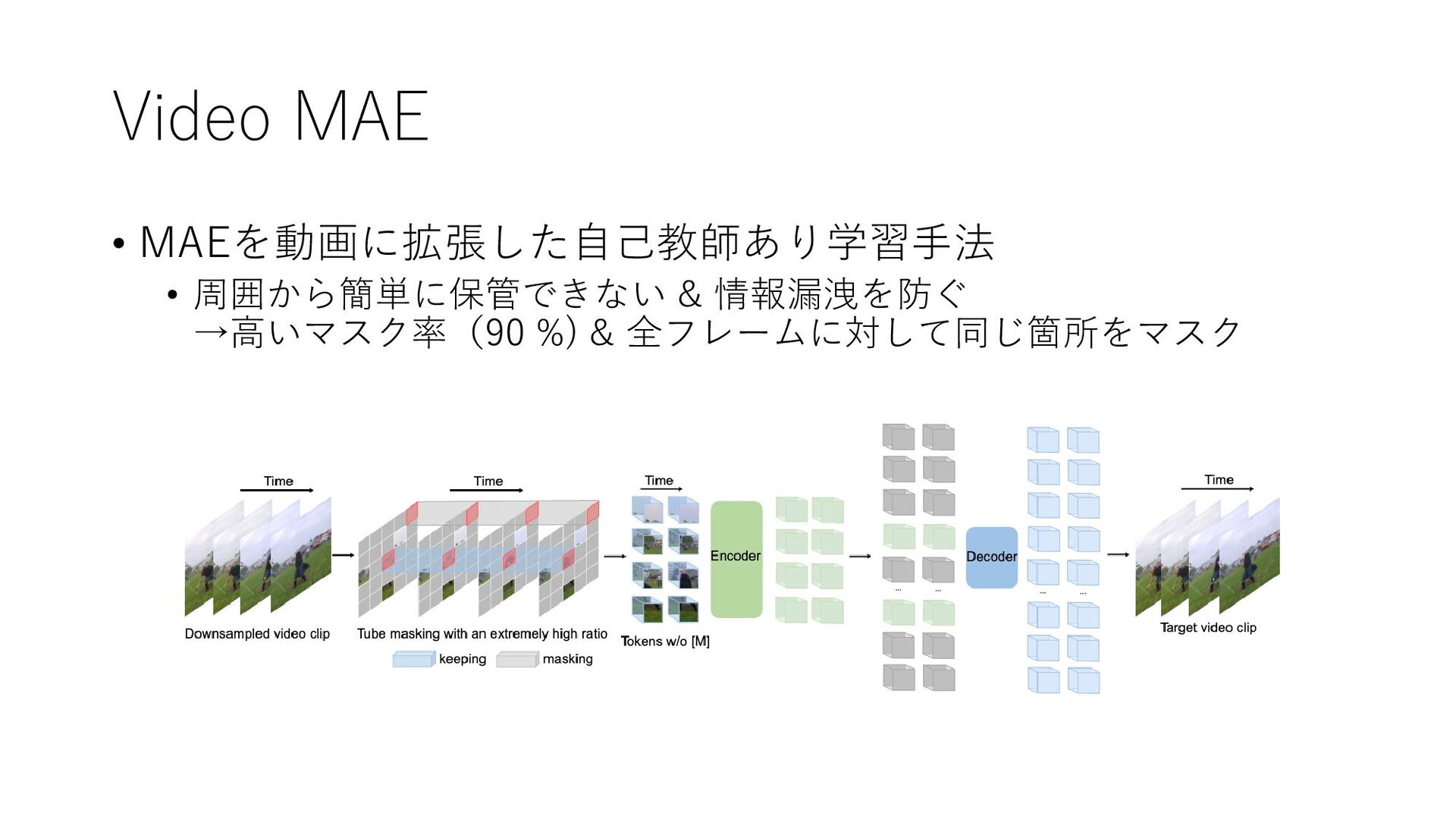
Video MAE • MAEを動画に拡張した自己教師あり学習手法 • 周囲から簡単に保管できない & 情報漏洩を防ぐ →高いマスク率(90 %)
& 全フレームに対して同じ箇所をマスク
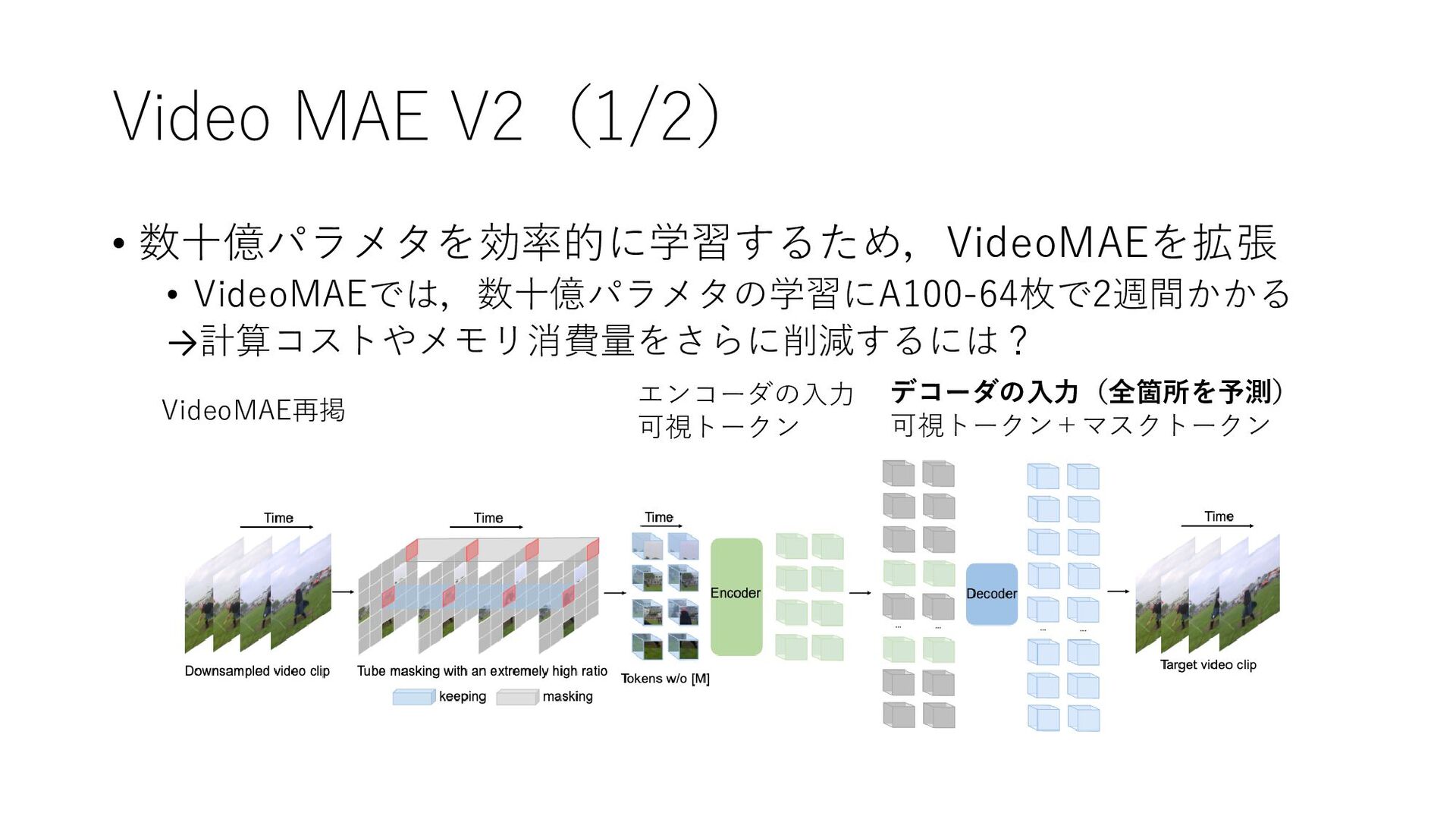
Video MAE V2(1/2) • 数十億パラメタを効率的に学習するため,VideoMAEを拡張 • VideoMAEでは,数十億パラメタの学習にA100-64枚で2週間かかる →計算コストやメモリ消費量をさらに削減するには? エンコーダの入力 可視トークン
デコーダの入力(全箇所を予測) 可視トークン+マスクトークン VideoMAE再掲
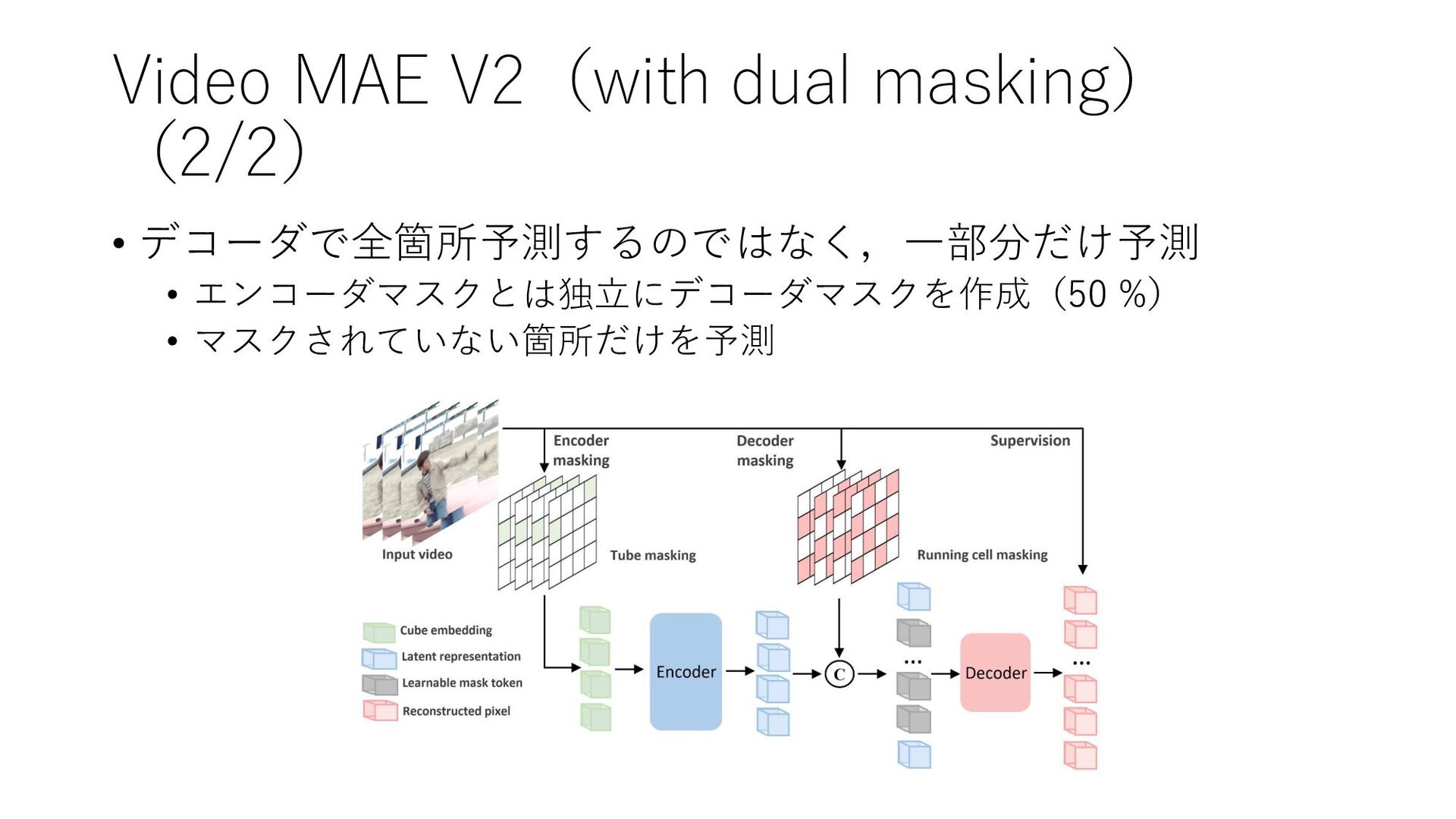
Video MAE V2(with dual masking) (2/2) • デコーダで全箇所予測するのではなく,一部分だけ予測 • エンコーダマスクとは独立にデコーダマスクを作成(50
%) • マスクされていない箇所だけを予測
実験|VideoMAE • 既存の自己教師あり学習手法よりも高い性能 データ数が少なくても学習可能(ViT-B) 下流タスクにおいても高い性能 正解率と学習スピードの向上(ViT-B)
実験|VideoMAE-V2 • VideoMAEより高速 & モデルサイズを大きくすると性能が向上 マスキング率50%が性能と計算効率の バランスが取れている
まとめ • 自己教師あり動画事前学習手法を提案(VideoMAE) • Image MAEを拡張 • 大規模なモデルで学習するために効率化(VideoMAE-V2) • デコーダで全箇所予測するのではなく,一部分だけ予測
• 結果 • 既存手法よりも高い性能 • 下流タスクでも性能を発揮
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}