Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
probeの勘違いから見直した、Pod運用のアレコレ
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
j-maki
August 02, 2025
260
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
probeの勘違いから見直した、Pod運用のアレコレ
j-maki
August 02, 2025
More Decks by j-maki
See All by j-maki
fukuoka_sre_0_jmaki.pdf
jmakk0301
1
750
引いては引き直す Kubernetes運用における境界設計とその見直し
jmakk0301
0
300
おそらくAGIでも代替不可能な、 趣味としての個人コミットの話
jmakk0301
0
180
EKSシークレット管理のつらみと責務分解
jmakk0301
0
120
小さく始める障害訓練
jmakk0301
0
18
Amazon EKS MCP Serverでクラスタの職場環境のストレスチェックをして遊んでみた
jmakk0301
0
210
ギフティにおける プラットフォームエンジニアリングことはじめ
jmakk0301
2
530
Featured
See All Featured
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
Build your cross-platform service in a week with App Engine
jlugia
234
18k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
HDC tutorial
michielstock
2
750
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Visualization
eitanlees
152
17k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Odyssey Design
rkendrick25
PRO
2
730
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
310
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Transcript
probeの勘違いから見直した、Pod運用のアレコレ
自己紹介 じぇまき(@jmakingng)と言います! とあるWeb系の会社のエンジニア 最近KubeCon等のイベントで熱が高まっている そろそろK8s初学者を脱した...と信じたい
「Kubernetes Novice Tokyo #34」 でLTして以来、約10ヶ月ぶりに喋ります! 発表の場を提供してもらい感謝です! https://k8s-novice-jp.connpass.com/event/329802/
今回の発表の動機 自分が初めてk8sを勉強したときにprobe周りがあまりピンとこなかった 最近、初学者の方にprobeについて聞かれたことがあった 自分なりに調べたことについて、初学者の頃の自分に対して説明するつもりで発表し たい
ざっくりとしたprobeのイメージ Podの状態チェック(health check)のこと Liveness Probe: 「アプリが動いているか?」のチェック → 応答しなければ再起動 Readiness Probe:
「リクエストを受け取れる状態か?」のチェック → 準備できてなければトラフィックから外す Startup Probe: 「起動完了したか?」のチェック → 起動中は他のチェックを待機
公式のドキュメントを見てみる(一部表現は変更) Liveness Probe コンテナをいつ再起動するかを認識することができます。 例えば、アプリケーシ ョン自体は起動しているが、処理を継続することができないデッドロック状態を 検知することができます。 このような状態のコンテナを再起動することで、バグ がある場合でもアプリケーションの可用性を高めることができます。 Readiness
Probe コンテナがトラフィックを受け入れられる状態であるかを認識することができま す。 Podが準備ができていると見なされるのは、Pod内の全てのコンテナの準備が 整ったときです。 一例として、このシグナルはServiceのバックエンドとして使用 されるPodを制御するときに使用されます。 Podの準備ができていない場合、その PodはServiceのロードバランシングから切り離されます。
Startup Probe コンテナアプリケーションの起動が完了したかを認識することができます。 Startup Probeを使用している場合、Startup Probeが成功するまでは、Liveness Probeと Readiness Probeによるチェックを無効にし、これらがアプリケーション の起動に干渉しないようにします。
例えば、これを起動が遅いコンテナの起動チ ェックとして使用することで、起動する前にkubeletによって 強制終了されること を防ぐことができます。
probeの設定例 livenessProbe: # httpget以外にもexec、tcpSocketがある httpGet: path: /health port: 8080 initialDelaySeconds:
30 # 初回チェックまでの待機時間 periodSeconds: 10 # チェックを行う間隔 timeoutSeconds: 5 # タイムアウトまでの時間 failureThreshold: 3 # 失敗とみなす回数 successThreshold: 1 # 成功とみなす回数 ※ readinessProbeも基本的には同じフィールドを使用できる
自分の勘違い その1 Readiness probeだけあればLiveness probeいらなくね? ReadinessがOKの場合はPod内の全てのコンテナの準備が整った時という条件である ならば、それだけで良くないか?
自分の今の認識 もちろんNO Readiness probeが失敗するとpodがサービスアウトされるのみ 一方、Liveness probeでは、スレッド競合などでデッドロックが発生し、podを再起動 することで回復が見込める
簡単な例で試してみる。下記のdeploymentとserviceを作ってみる apiVersion: apps/v1 kind: Deployment metadata: name: nginx-readiness-deployment ... spec:
containers: - name: readiness image: registry.k8s.io/busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600 readinessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 10 periodSeconds: 5 livenessProbe: ...
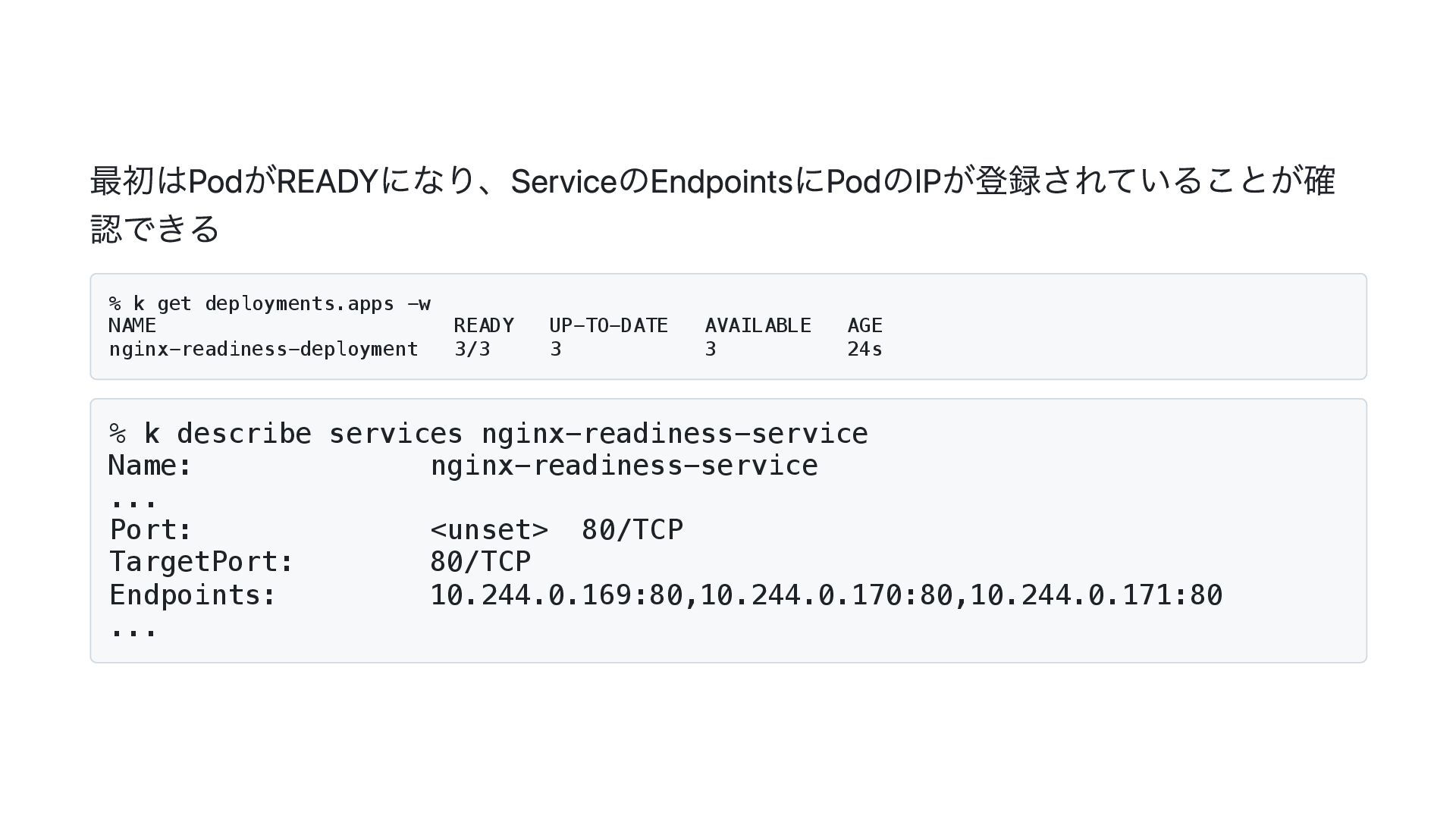
最初はPodがREADYになり、ServiceのEndpointsにPodのIPが登録されていることが確 認できる % k get deployments.apps -w NAME READY UP-TO-DATE
AVAILABLE AGE nginx-readiness-deployment 3/3 3 3 24s % k describe services nginx-readiness-service Name: nginx-readiness-service ... Port: <unset> 80/TCP TargetPort: 80/TCP Endpoints: 10.244.0.169:80,10.244.0.170:80,10.244.0.171:80 ...
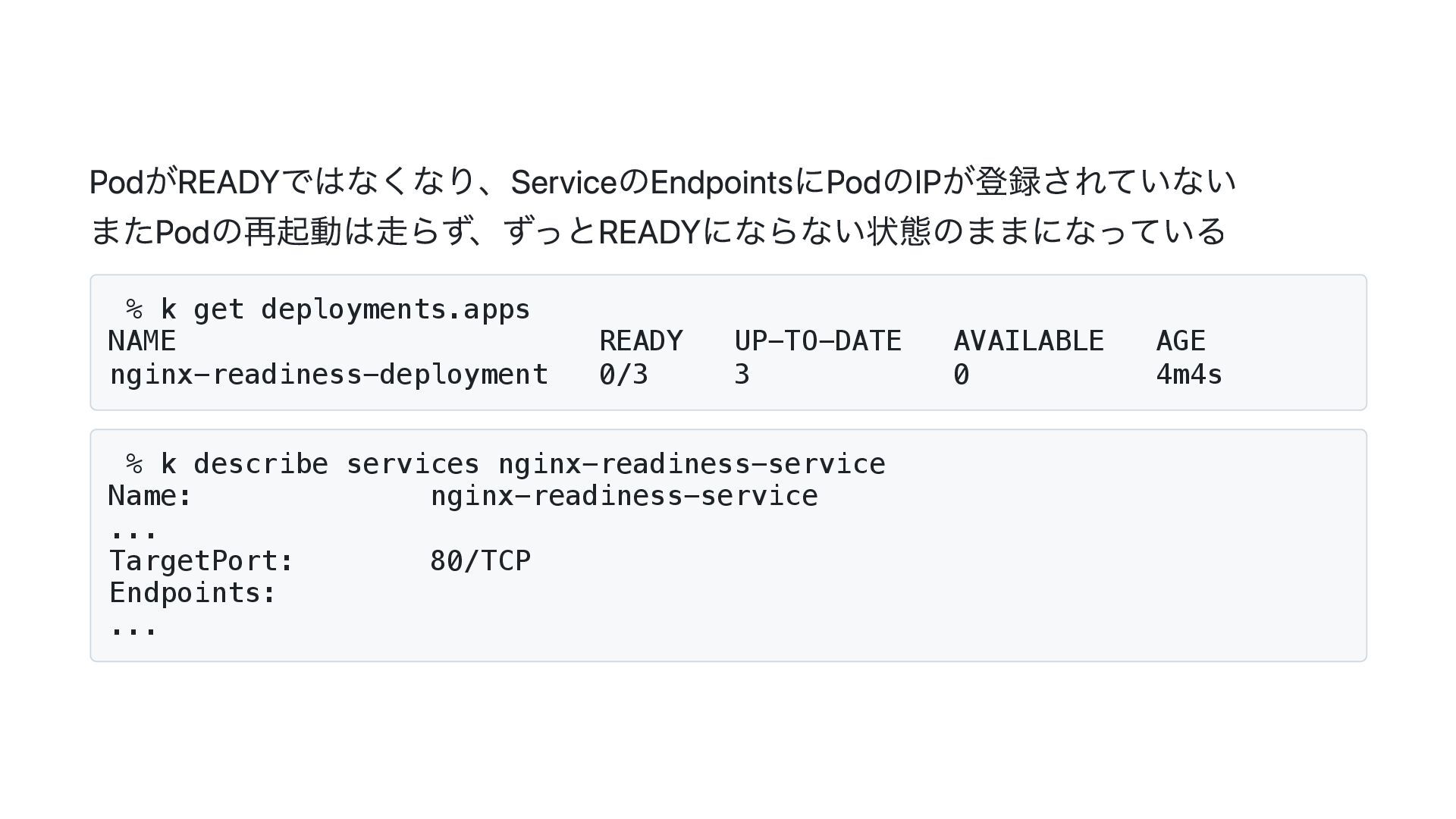
PodがREADYではなくなり、ServiceのEndpointsにPodのIPが登録されていない またPodの再起動は走らず、ずっとREADYにならない状態のままになっている % k get deployments.apps NAME READY UP-TO-DATE AVAILABLE
AGE nginx-readiness-deployment 0/3 3 0 4m4s % k describe services nginx-readiness-service Name: nginx-readiness-service ... TargetPort: 80/TCP Endpoints: ...
自分の今の認識(再掲) Readiness probeが失敗するとPodがサービスアウトされるのみ 一方、Liveness probeを設定することで、デッドロックなどアプリケーションの処理の 継続が困難な状態に陥った時、Podを再起動することで回復が見込める
自分の勘違い その2 じゃあ、Liveness probeを設定してしまえば、Readiness probeはいらない?
自分の今の認識 それもNO Podを再起動せずとも、待機させておけば状態が回復するケースも存在する (例えば、外部コンポーネントとの一時的な接続不良等) 各probe失敗時の挙動を理解し、これらを使い分けることが大切
自分の勘違い その3 じゃあ、これで設定しておけば完璧。ヨシ! Liveness probe: 200を返す簡易的なHealth Check Readiness probe: Deep
Health Check(DBや依存サービス含めたcheck
安直に指定するのは危険 例えば、ケーススタディとしてDBが高負荷になった状況を考える 問題のシナリオ例: Readiness probeにDeep Health Checkを設定している DBが高負荷によりDeep Health Checkが失敗
PodがReadyにならなず他のPodに負荷が集中 全てのpodが落ちるとユーザーはアプリケーションのエラー画面ではなくALB等の デフォルトのエラー画面を見ることになる 外部コンポーネントのトラブルは、Pod自体の再起動やサービスアウトだけでは解決 する問題ではない。
自分の今の自分の認識 全てのアプリケーションでこれを設定しておけば間違いないというような絶対解 はないはず probeのヘルスチェックは理想的には、外部コンポーネントによらずPod内部の状 況だけで決まるようにするとよいが、現実的にそうできない事情も考えられる 大切なのは、アプリケーションやフレームワークの設定、運用しているサービス の特性を考慮してこれらのprobeの設定を吟味すること、またそれを定期的に見直 して調整していくこと
ここから話を拡げるため、Readiness gateについて少し補足しておく
Readiness gateの役割 Readiness Gate(準備完了ゲート)とは、Kubernetesにおいて、Podの準備状態をより 細かく制御するための機能 主な用途: AWS Load Balancer Controllerと連携して、Podがターゲットグループに登録される
まで待機 Podの準備が完了するまで、古いPodの削除を遅延させ、ダウンタイムを削減 外部サービスとの連携を確実にするための追加の条件を設定
自分の勘違い その4 Readiness Gate を設定すれば、Pod 起動時に ALBに適切に登録してくれるから安心! ヨシ!
自分の今の認識 Readiness Gate は、Pod 起動時のトラフィック受け入れ準備を制御してくれる しかし、Pod 終了時の挙動について気を配る必要がある
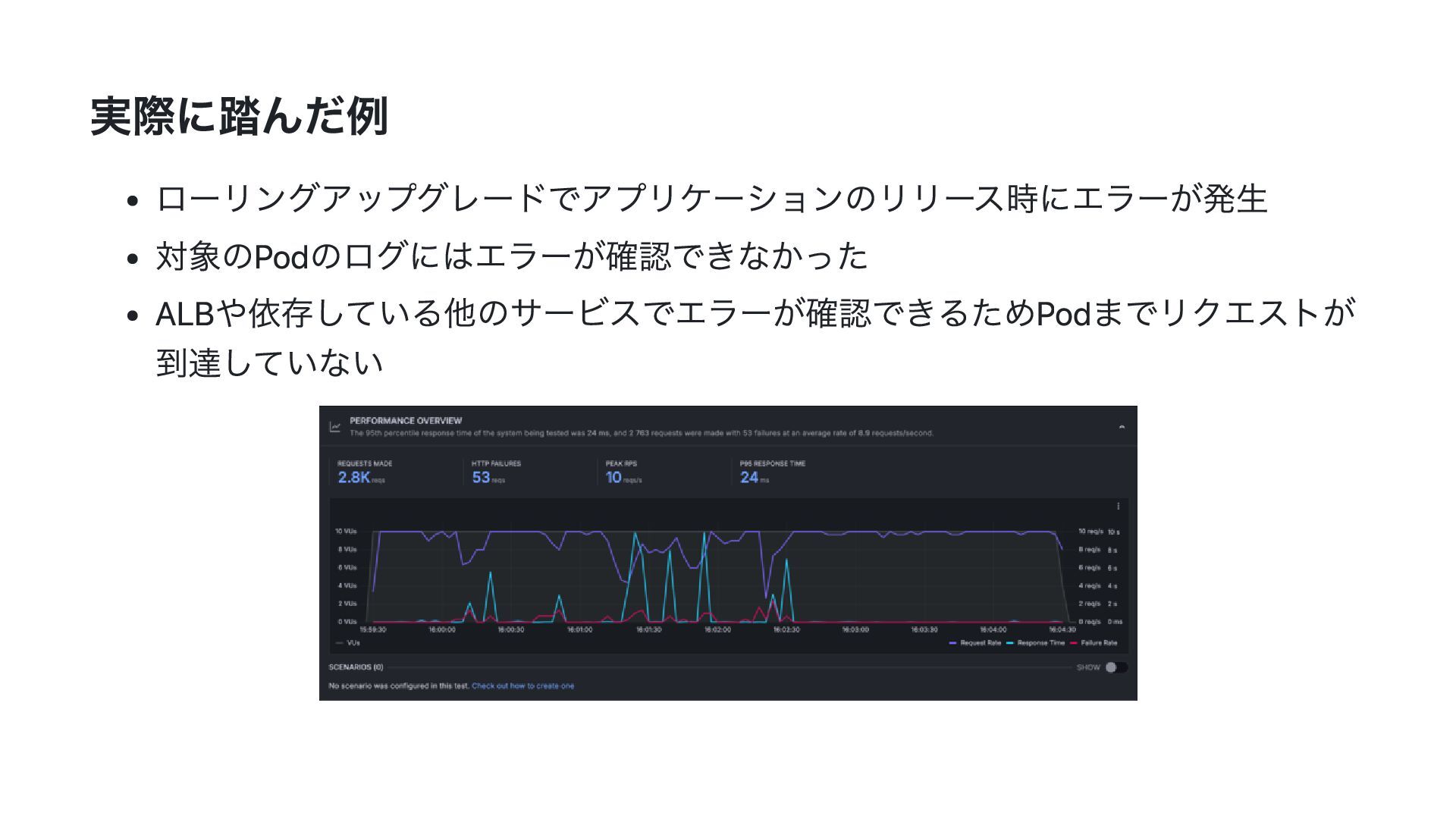
実際に踏んだ例 ローリングアップグレードでアプリケーションのリリース時にエラーが発生 対象のPodのログにはエラーが確認できなかった ALBや依存している他のサービスでエラーが確認できるためPodまでリクエストが 到達していない
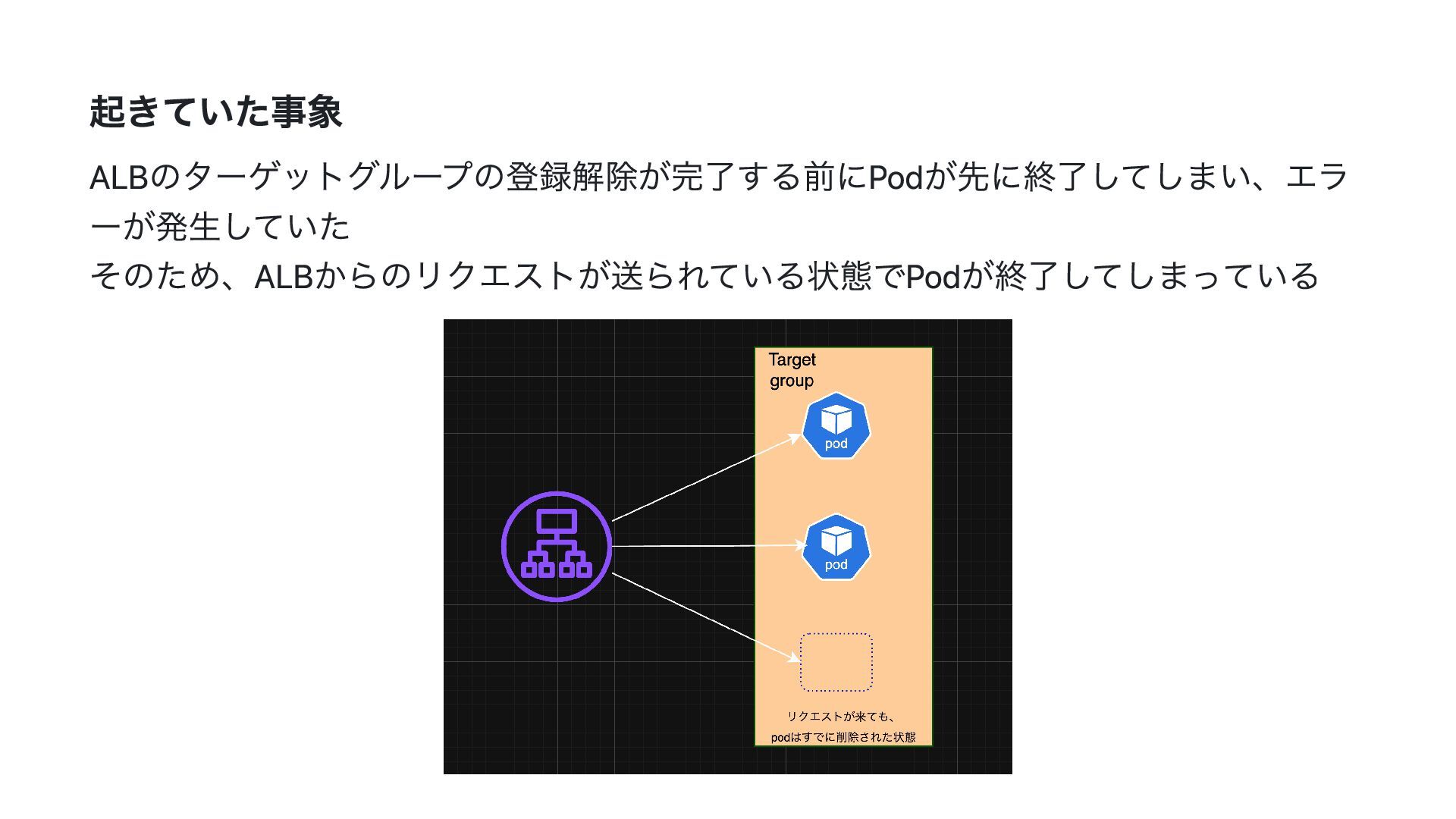
起きていた事象 ALBのターゲットグループの登録解除が完了する前にPodが先に終了してしまい、エラ ーが発生していた そのため、ALBからのリクエストが送られている状態でPodが終了してしまっている
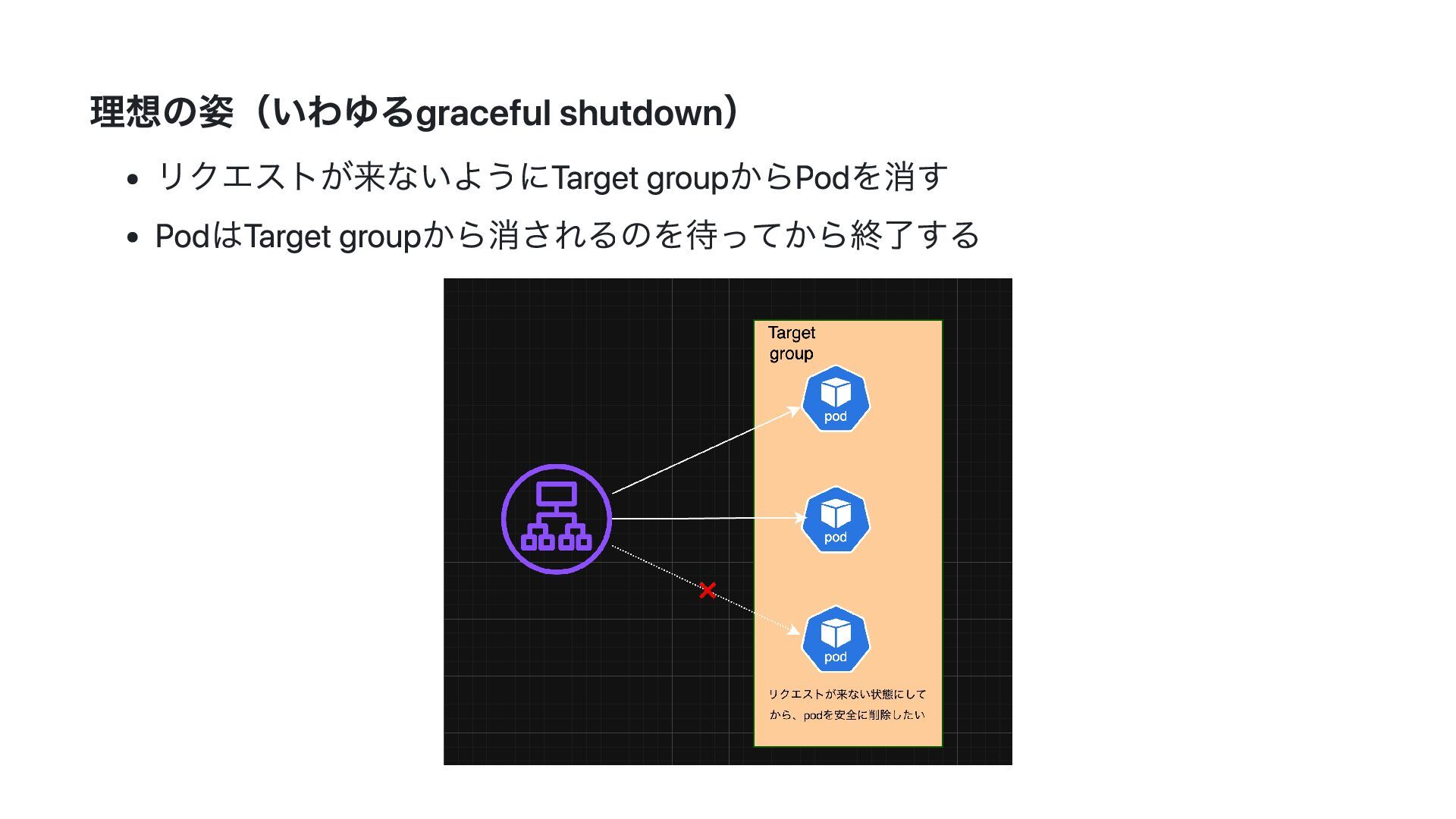
理想の姿(いわゆるgraceful shutdown) リクエストが来ないようにTarget groupからPodを消す PodはTarget groupから消されるのを待ってから終了する
やったこと その1 ALBのDeregistration delayの見直し
Deregistration delayとは? ALBがターゲットグループからターゲット(今回はPod)を外す際の待機時間 新しいリクエストの送信を停止し、処理中のリクエストが完了するのを待つ デフォルト: 300秒 対策 アプリケーション側のリクエスト処理時間やタイムアウトをもとに設定 例えば、アプリケーション側が30秒必要なら、Deregistration delayはそれ以上の
時間にする そして、Podの終了はDeregistration delayの後の時間になるように調整
Podの終了プロセスについて Podが終了する時の流れ 1. Pod削除の開始 - デプロイ等でPod削除が開始 - Podのステータスが Terminating に変更
2. PreStopフックの実行 (設定されている場合) - コンテナ内で preStop ライフサイクルフックが実行 - アプリケーションの正常終了処理を実行する時間を確保 3. SIGTERMシグナルの送信 - kubeletがコンテナのメインプロセスにSIGTERMシグナルを送信 - アプリケーションはこのシグナルを受け取って正常終了処理を開始
4. terminationGracePeriodSecondsの待機 - デフォルト30秒間、アプリケーションの正常終了を待機 - この間にアプリケーションは処理中のリクエストを完了させる 5. SIGKILLシグナルの送信 (必要に応じて) -
terminationGracePeriodSeconds経過後も終了しない場合 - kubeletがSIGKILLシグナルを送信して強制終了 6. Podの完全削除 - コンテナが完全に終了後、Podリソースが削除される
やったこと その2 Podの終了時の挙動制御 terminationGracePeriodSecondsとpreStop lifecycleの設定 preStop lifecycle hook: コンテナ終了前に70秒のsleepを実行 ALBがターゲットグループからPodを外す時間を確保 新しいリクエストが来ない状態でアプリケーションの終了処理を実行
処理中のリクエストが完了する時間を提供 terminationGracePeriodSeconds: Podの終了待機時間を90秒に延長 デフォルトの30秒では不十分 ALBのDeregistration delayと合わせて調整
apiVersion: apps/v1 kind: Deployment metadata: ... spec: template: spec: terminationGracePeriodSeconds:
90 containers: - name: example resources: ... lifecycle: preStop: exec: command: ["sh", "-c", "sleep 70"]
各設定値の考え方 アプリケーションの設定 < ALBのDeregistration delay < Pre Stop Lifecycle Hook
< terminationGracePeriodSeconds 上記に設定することで、リクエストが送られている最中にPodが終了するリスクを低減
最後に所感とまとめ Podのprobe等の設定等を勘違いを交えて紹介した この辺りの設定はK8sの知識は勿論のこと、アプリケーションのフレームワークや サービス特性などの理解も必要で難易度が高い 正しく設定することで、アプリケーションの可用性を高めることができる
参考 EKSコンテナ移行のトラブル事例:ALBの設定とPodのライフサイクル管理 https://tech-blog.monotaro.com/entry/2023/08/22/090000 Kubernetesマイクロサービス開発の実践 https://amzn.asia/d/7bRTEhG
ご清聴ありがとうございました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}