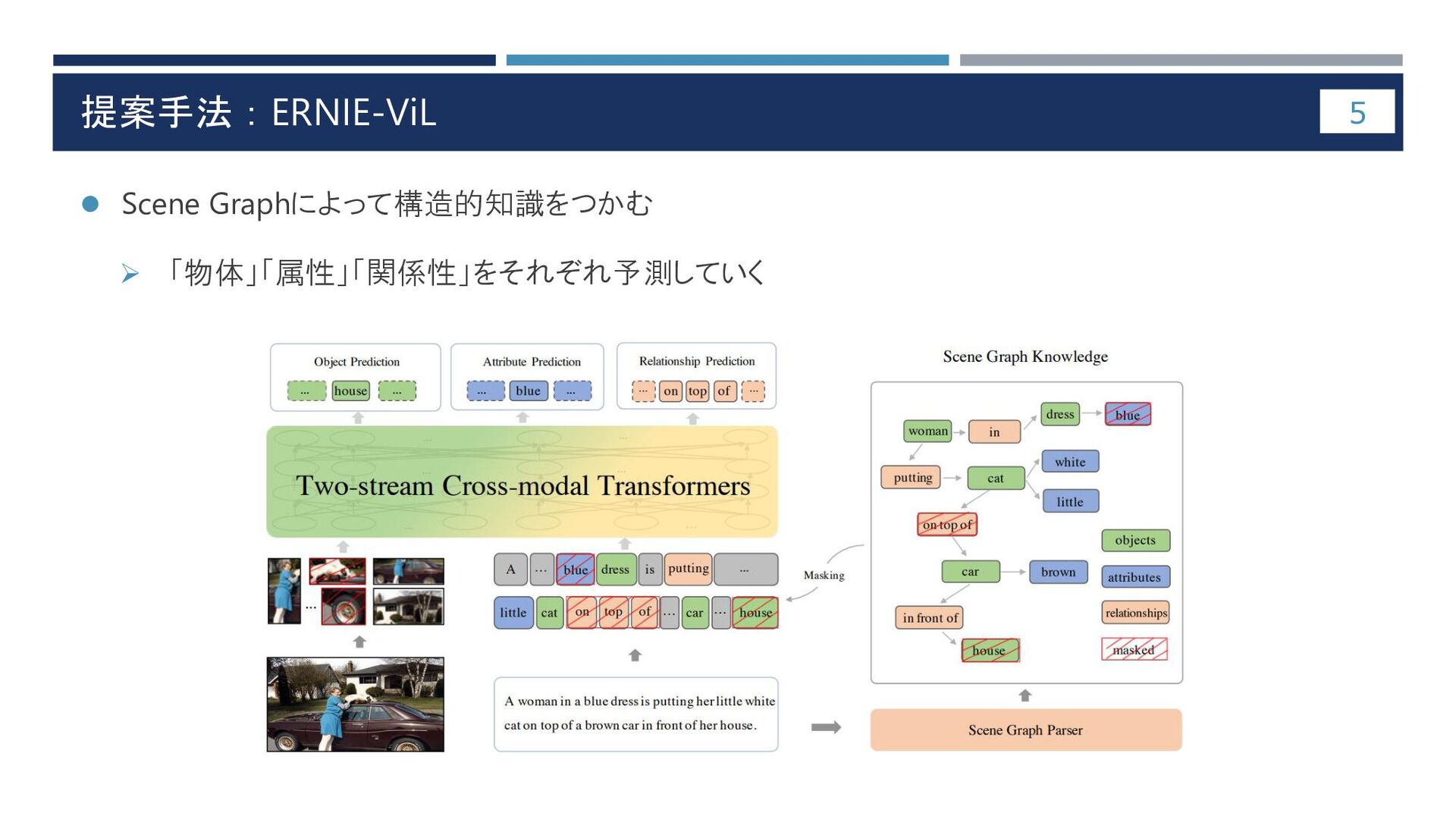
Textual Descriptions for Improved Image Retrieval [Sebastian+ ACL2015]で用いられたScene Graph Parser 1. Quantificational modifiers ⇒ “a lot of”の”lot”のような何かに依存する名詞をつなげる 2. Pronoun resolution ⇒ 代名詞が何を指しているのか 3. Plural nouns ⇒ 複数形はそれぞれに分割 4. Rule-Based Parser ⇒ ルールに従って属性と関係性を抽出 5. Classifier-Based Parser a. Object and Attribute Extraction ⇒ 他の単語でも属性を表現できているか e.g. “the person beside me” = “the person next to me” b. Relation Prediction ⇒ 物体同士の関係性を見ていく 14 https://aclanthology.org/W15-2812.pdf
{kind=link}
{kind=link}
{kind=link}
![関連研究:より詳細な情報を獲得しきれていない ViLBERT LXMERT model detail ViLBERT [Lu+ NIPS2019] ◦two-streamのtransformerを利用 △画像の詳細がうまくつかめない](https://files.speakerdeck.com/presentations/0e4045a8bb9141ec820a89f758ef36ae/slide_3.jpg){kind=link}
{kind=link}
![構成:SentenceとImageのEmbedding ⚫ SentenceのEmbeddingはBERTと同様 ➢ [CLS] “Sugiura” “Komei” “Lab” “is” “much”](https://files.speakerdeck.com/presentations/0e4045a8bb9141ec820a89f758ef36ae/slide_5.jpg){kind=link}
{kind=link}
![構成:② Object Prediction ➢ 物体の単語の30%を選択 ⇒ 情報量を少し残す • 8割の確率で[MASK]に •](https://files.speakerdeck.com/presentations/0e4045a8bb9141ec820a89f758ef36ae/slide_7.jpg){kind=link}
![構成:③ Attribute Prediction ④ Relationships Prediction ➢ 単語やフレーズの30%を[MASK]に ➢ かかわってくるオブジェクトの情報も前提条件に含まれる](https://files.speakerdeck.com/presentations/0e4045a8bb9141ec820a89f758ef36ae/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}