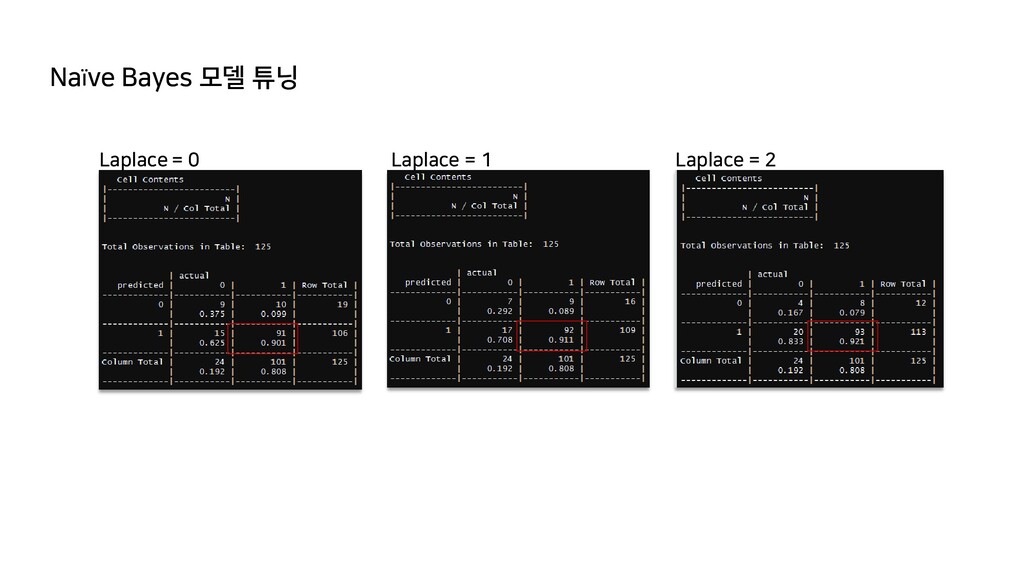
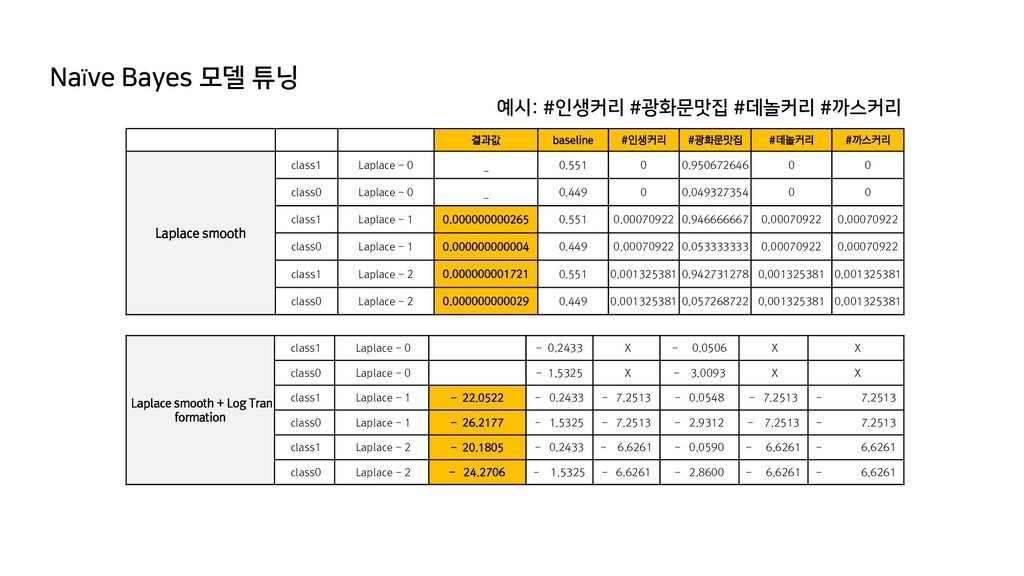
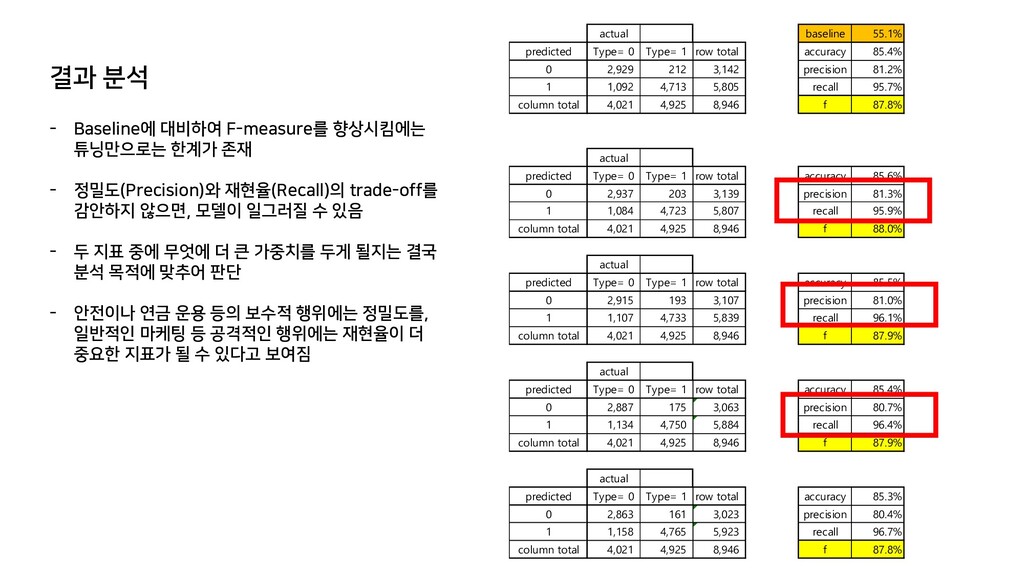
row total accuracy 85.4% 0 2,929 212 3,142 precision 81.2% 1 1,092 4,713 5,805 recall 95.7% column total 4,021 4,925 8,946 f 87.8% actual predicted Type= 0 Type= 1 row total accuracy 85.6% 0 2,937 203 3,139 precision 81.3% 1 1,084 4,723 5,807 recall 95.9% column total 4,021 4,925 8,946 f 88.0% actual predicted Type= 0 Type= 1 row total accuracy 85.5% 0 2,915 193 3,107 precision 81.0% 1 1,107 4,733 5,839 recall 96.1% column total 4,021 4,925 8,946 f 87.9% actual predicted Type= 0 Type= 1 row total accuracy 85.4% 0 2,887 175 3,063 precision 80.7% 1 1,134 4,750 5,884 recall 96.4% column total 4,021 4,925 8,946 f 87.9% actual predicted Type= 0 Type= 1 row total accuracy 85.3% 0 2,863 161 3,023 precision 80.4% 1 1,158 4,765 5,923 recall 96.7% column total 4,021 4,925 8,946 f 87.8% - Baseline에 대비하여 F-measure를 향상시킴에는 튜닝만으로는 한계가 존재 - 정밀도(Precision)와 재현율(Recall)의 trade-off를 감안하지 않으면, 모델이 일그러질 수 있음 - 두 지표 중에 무엇에 더 큰 가중치를 두게 될지는 결국 분석 목적에 맞추어 판단 - 안전이나 연금 운용 등의 보수적 행위에는 정밀도를, 일반적인 마케팅 등 공격적인 행위에는 재현율이 더 중요한 지표가 될 수 있다고 보여짐
{kind=link}
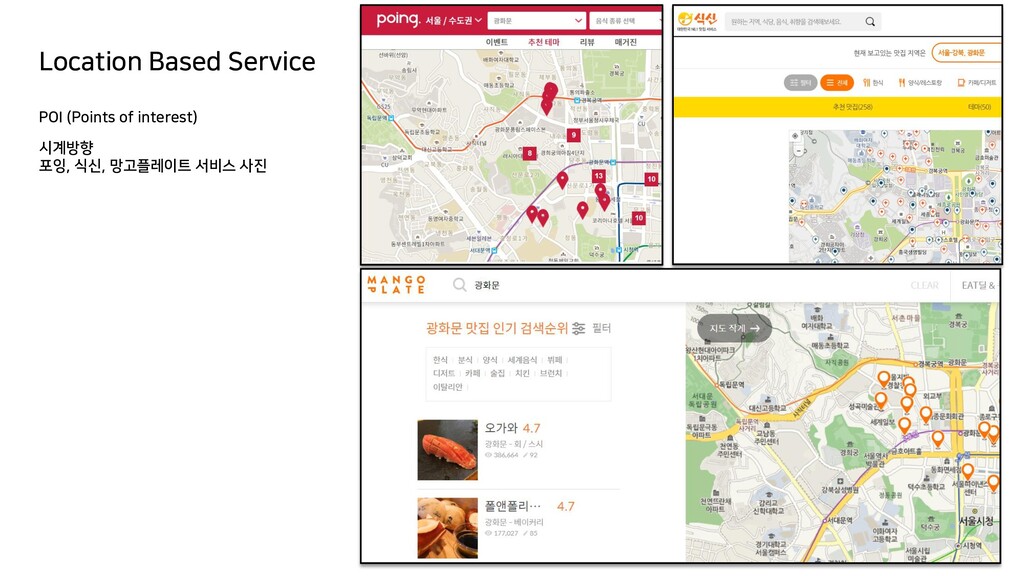
{kind=link}
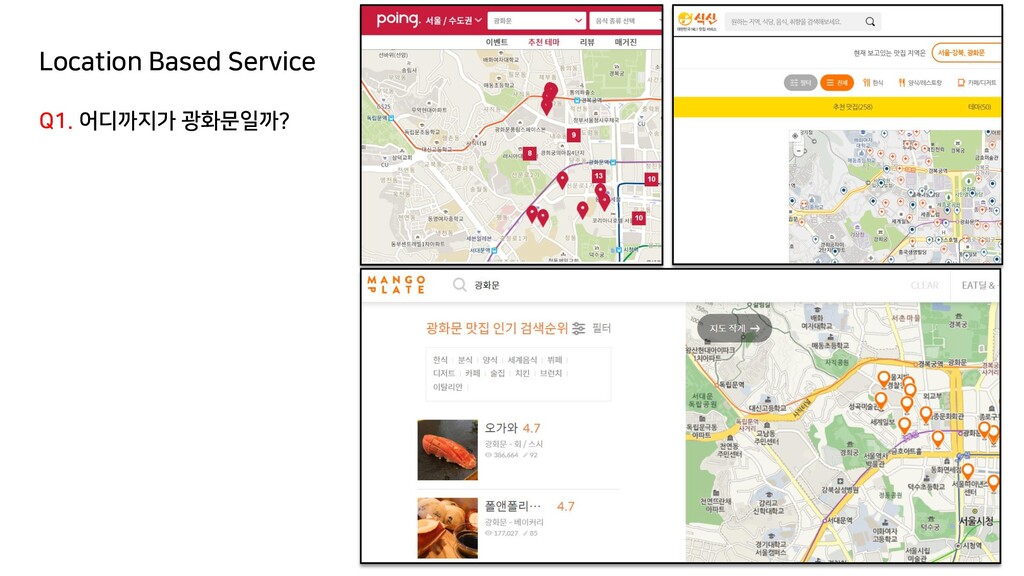
{kind=link}
{kind=link}
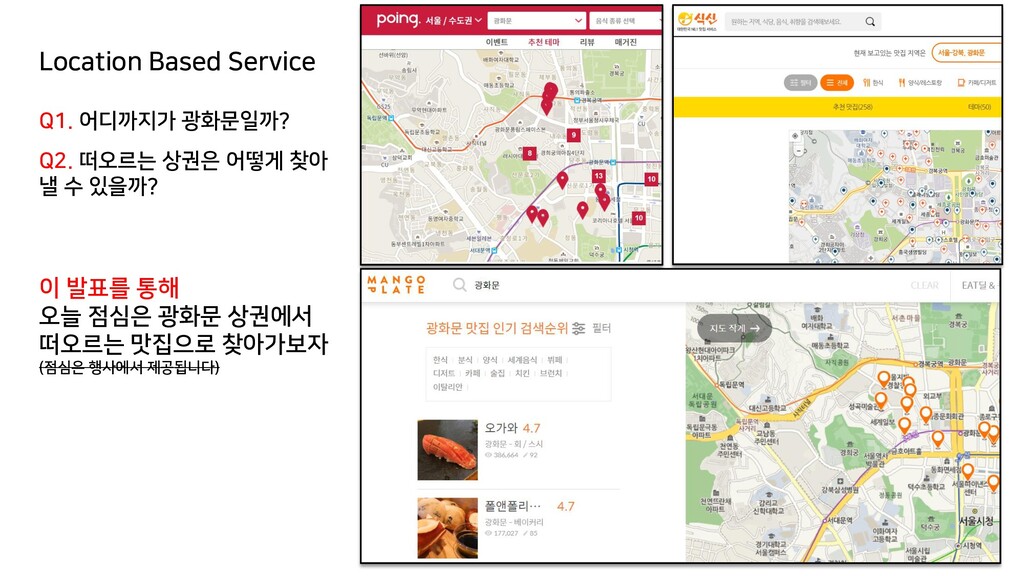{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[정부나 경제지표가 말하는 상권은 체감이 잘 안된다] 실제 고객들의 데이터로](https://files.speakerdeck.com/presentations/a46bae65a0fe43a58f2730accef22b01/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
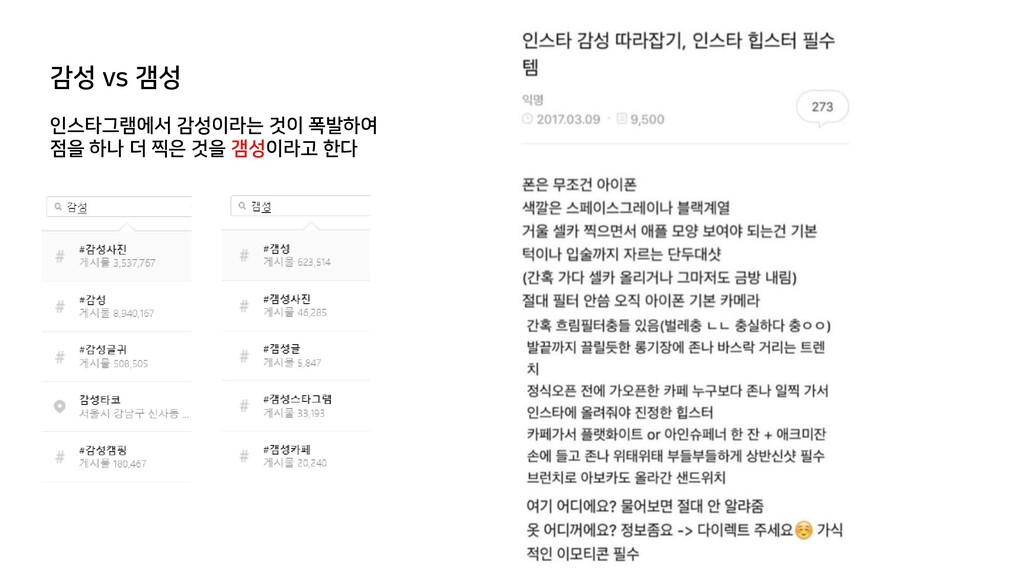{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
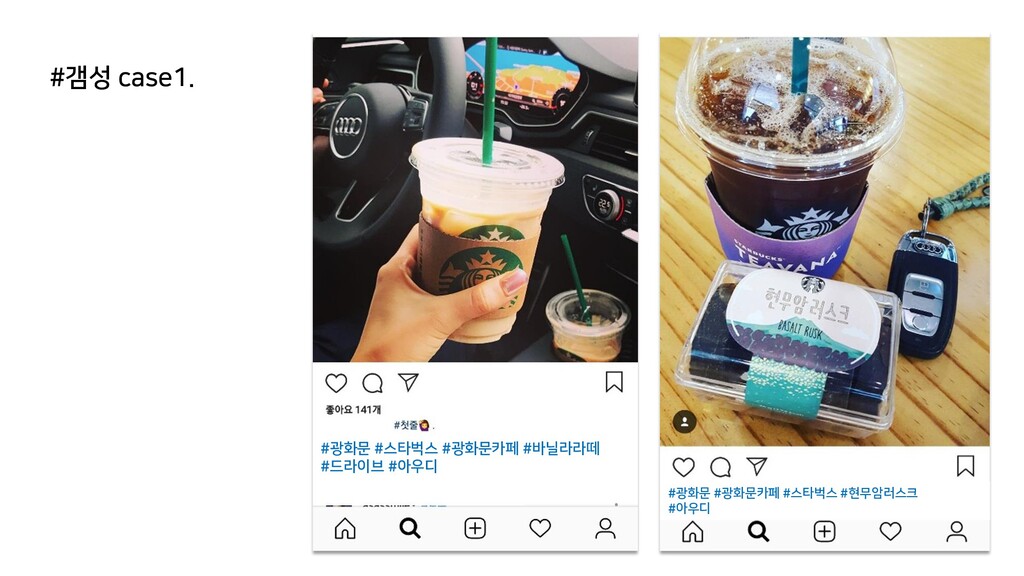{kind=link}
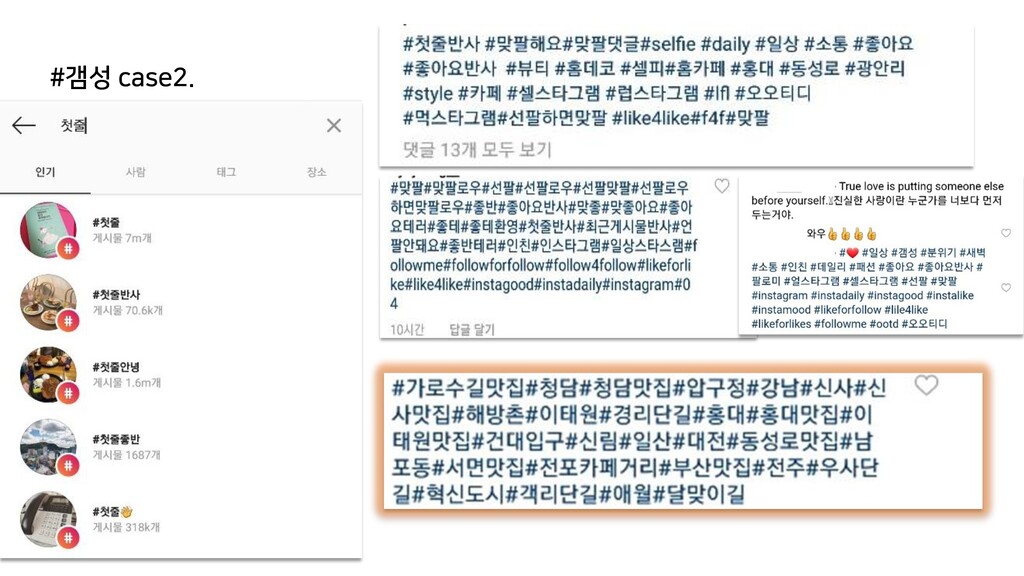{kind=link}
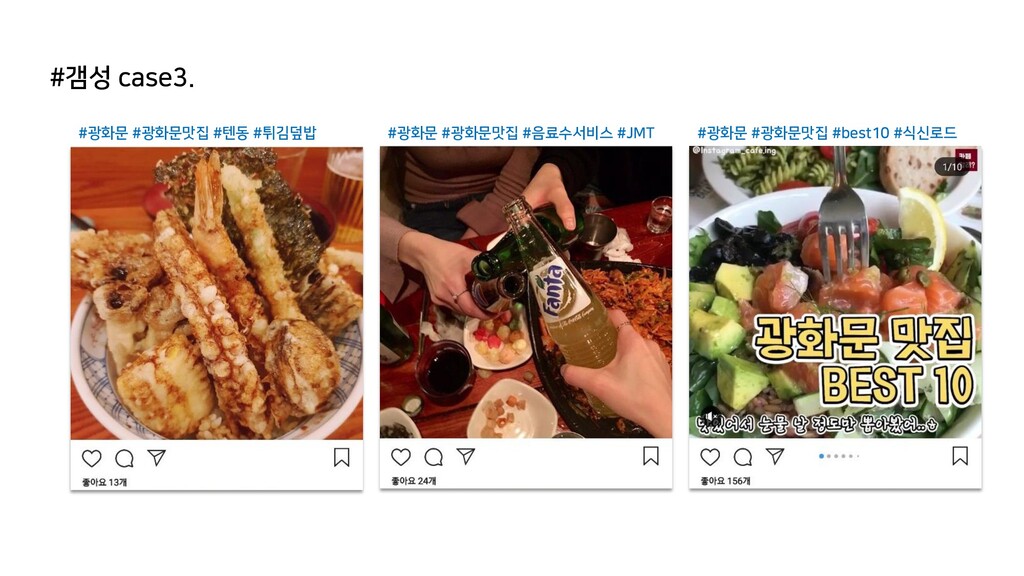{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}