Current technology innovations rely on information (entropy), transportation
(differential equations), and their algorithms (AI). This talk reviews the
research update of the project: transport information geometric computations
(TIGC). The project designs and analyzes numerical algorithms for statistical
physics and generative AI, including normalization flows, generative adversary
networks, and transformers. Through algorithms and numerical examples, the
TIGC project builds on concrete and solid mathematical foundations of AI with
various applications in uncertainty quantification, sampling algorithms, and statistical
physics-related simulations.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
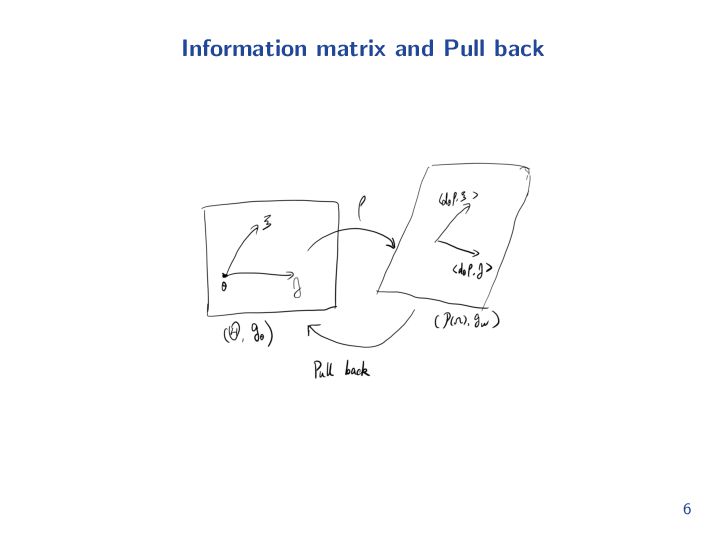{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
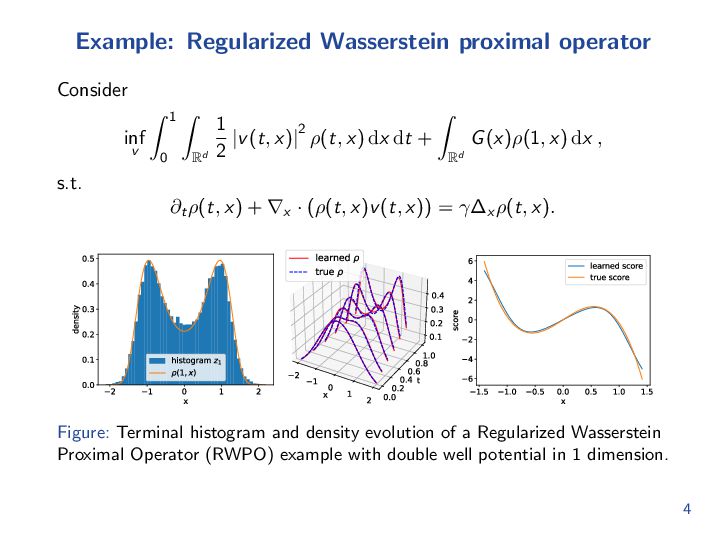{kind=link}
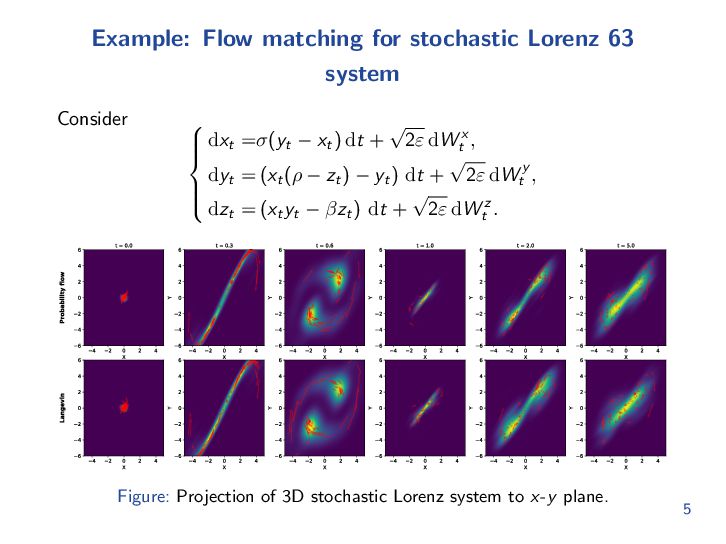{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
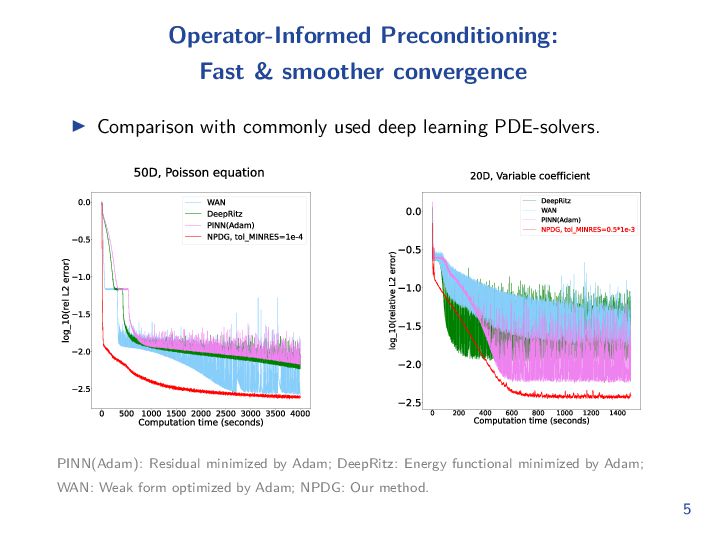{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}