We present a unified framework connecting sampling algorithms, optimal transport, and transformer architectures. The approach introduces a preconditioned, noise-free sampling method based on the regularized Wasserstein proximal operator, derived via a Cole–Hopf transformation on anisotropic heat equations. Extending this connection, we design a sparse transformer architecture that embeds an L₁ prior to enhance convexity and promote sparsity of the learning problem. Theoretical results show non-asymptotic convergence with explicit bias characterization, and experiments demonstrate improved efficiency and accuracy across Bayesian neural networks, Bayesian inverse problems, and generative modeling of image distributions.
{kind=link}
{kind=link}
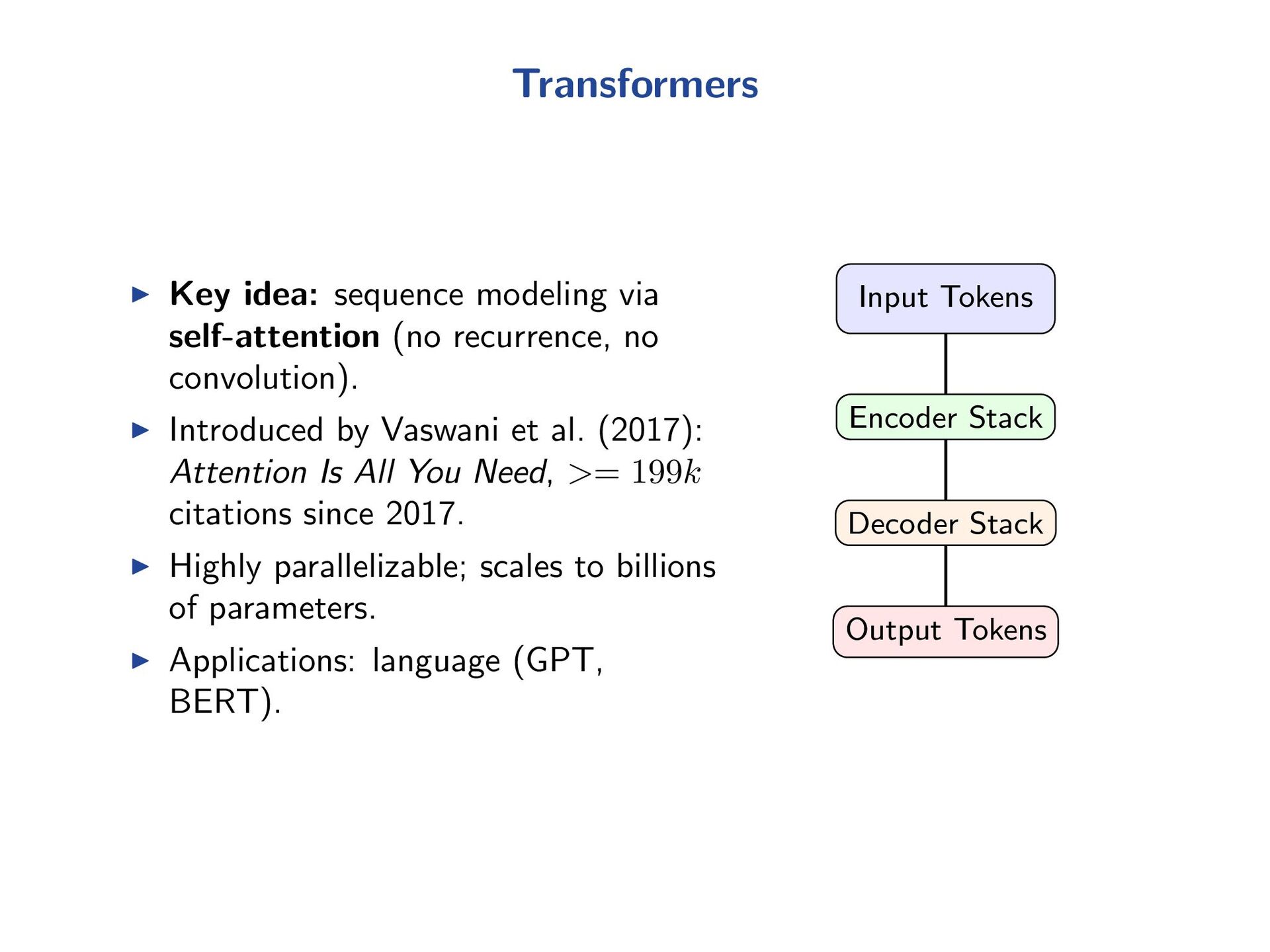{kind=link}
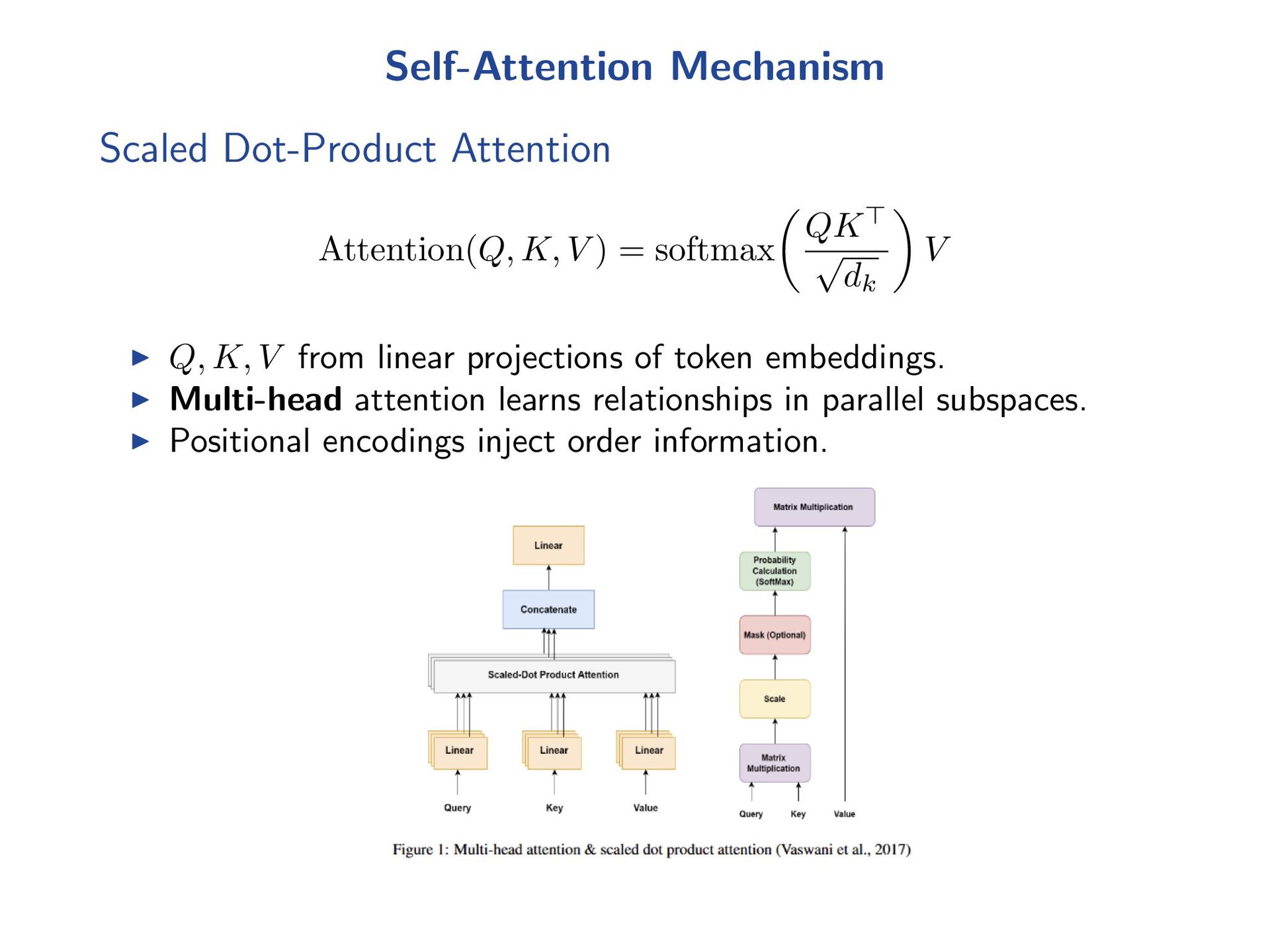{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
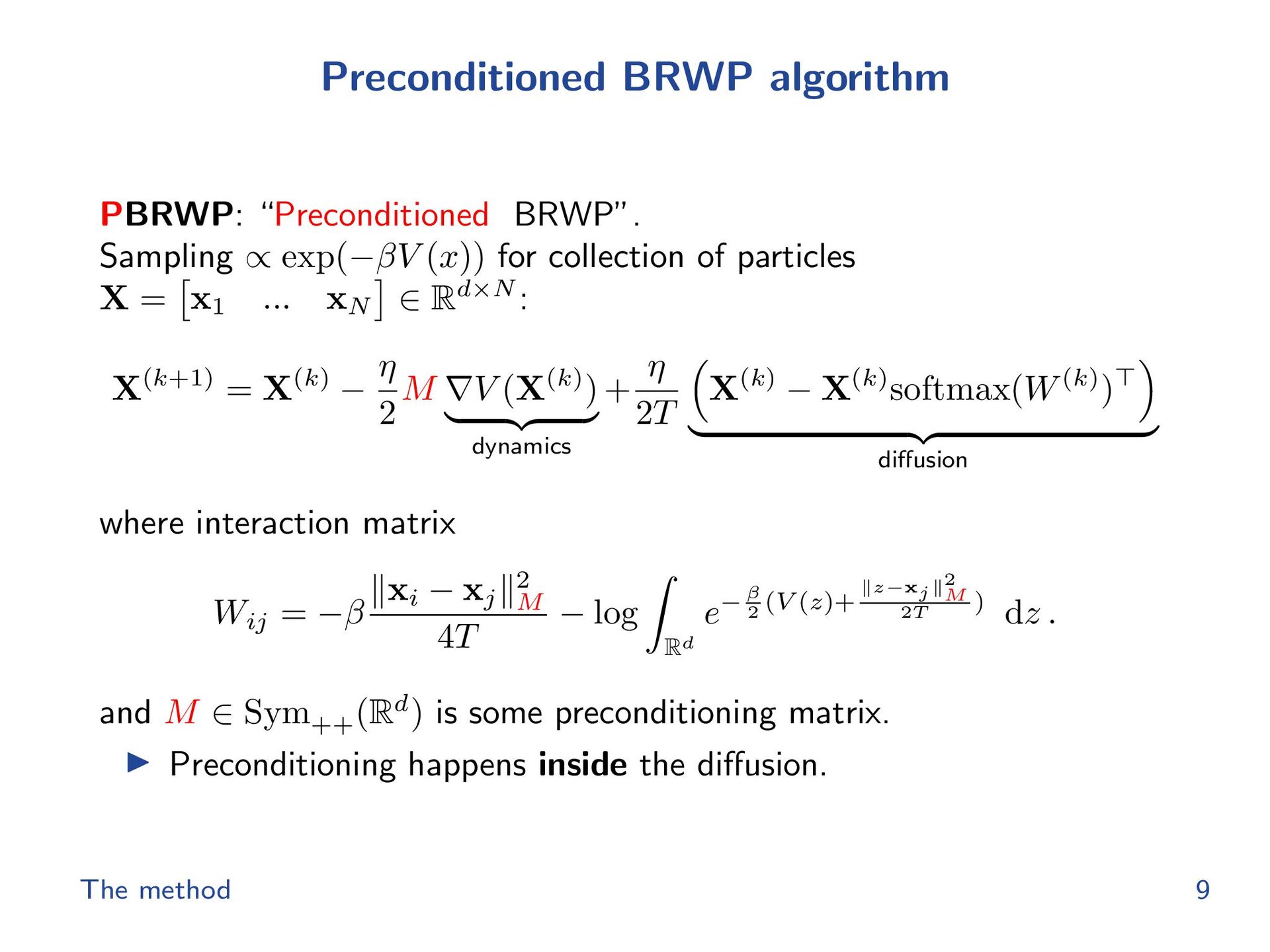{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
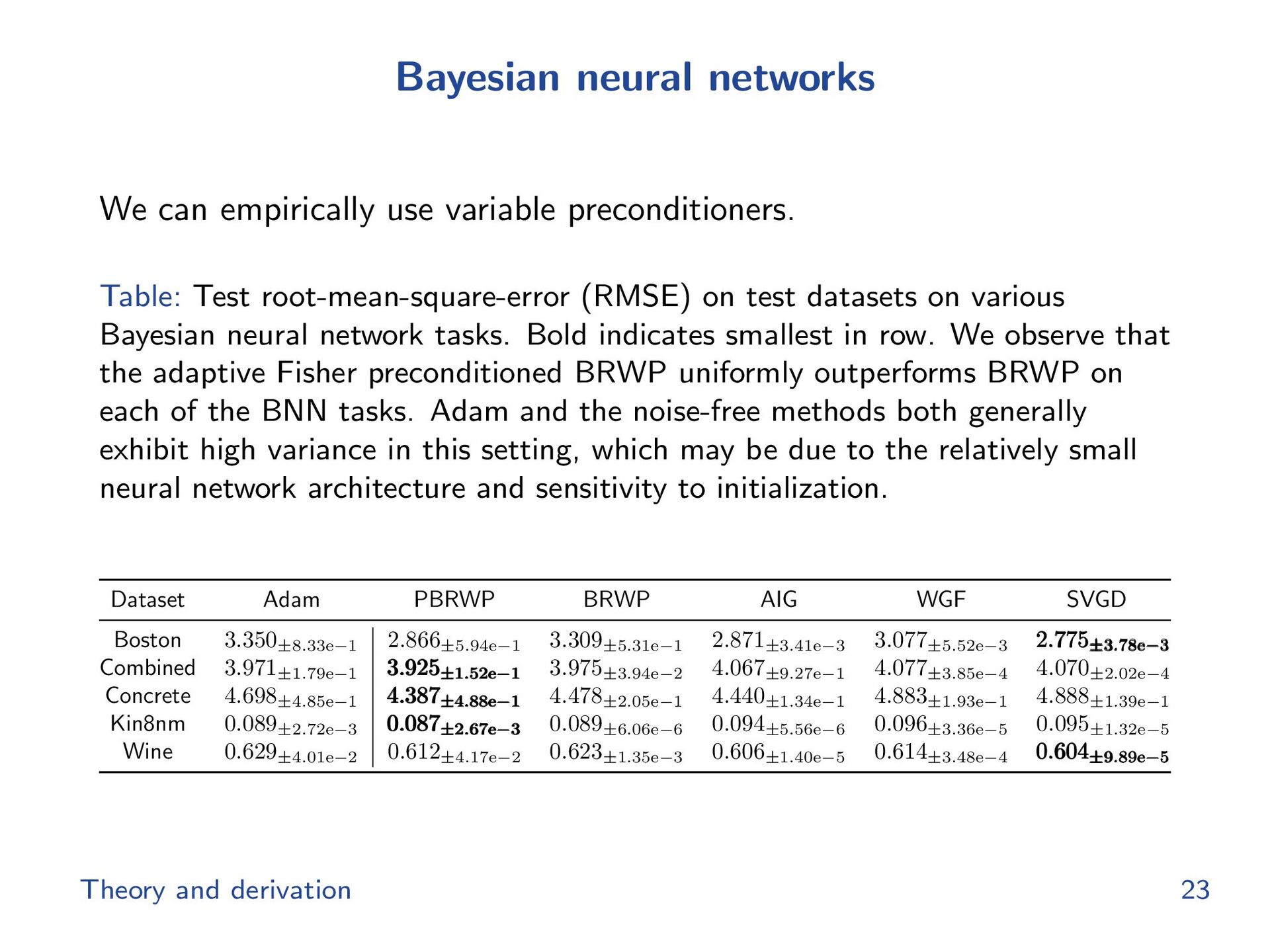{kind=link}
{kind=link}
{kind=link}
{kind=link}
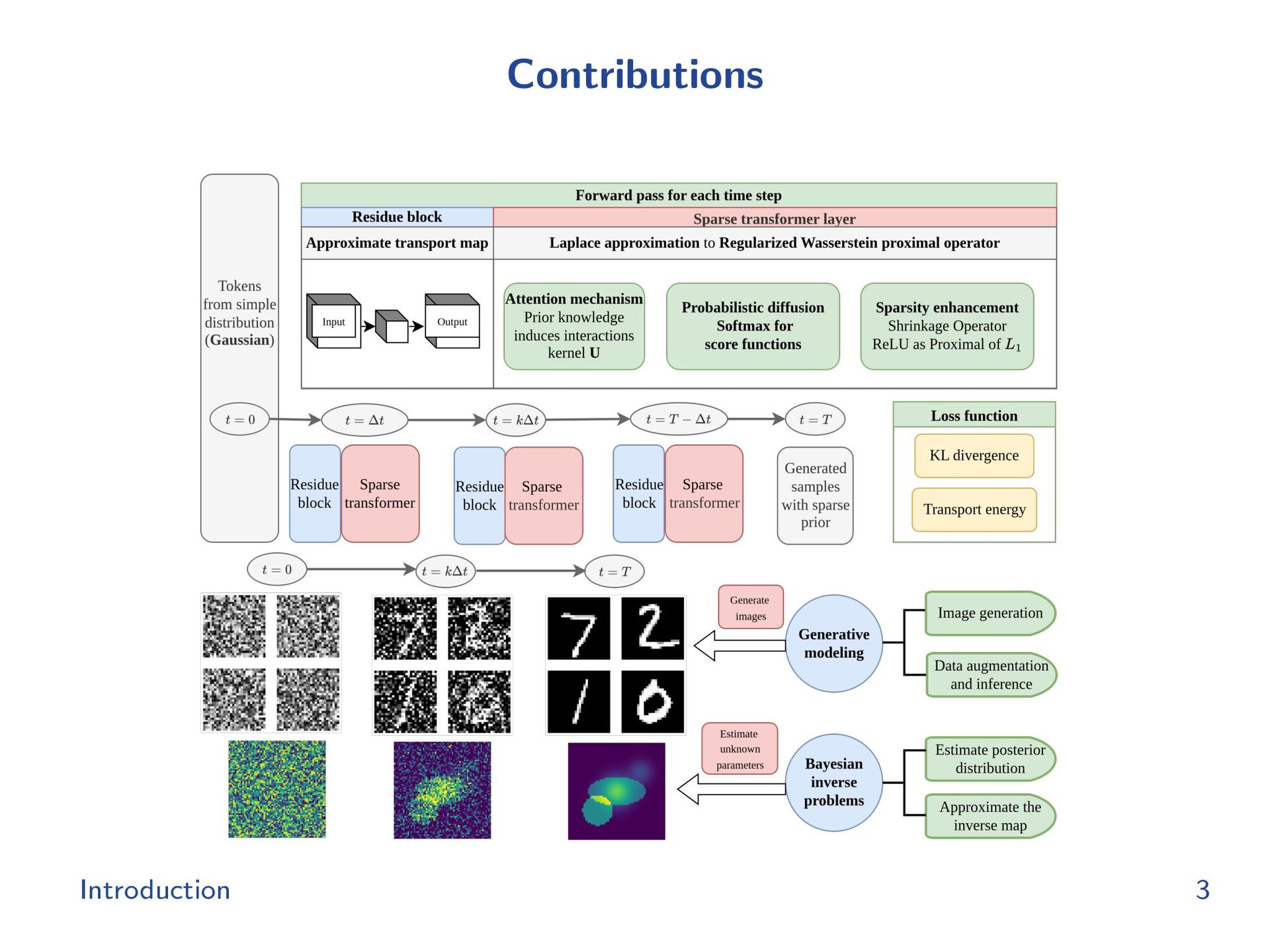{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
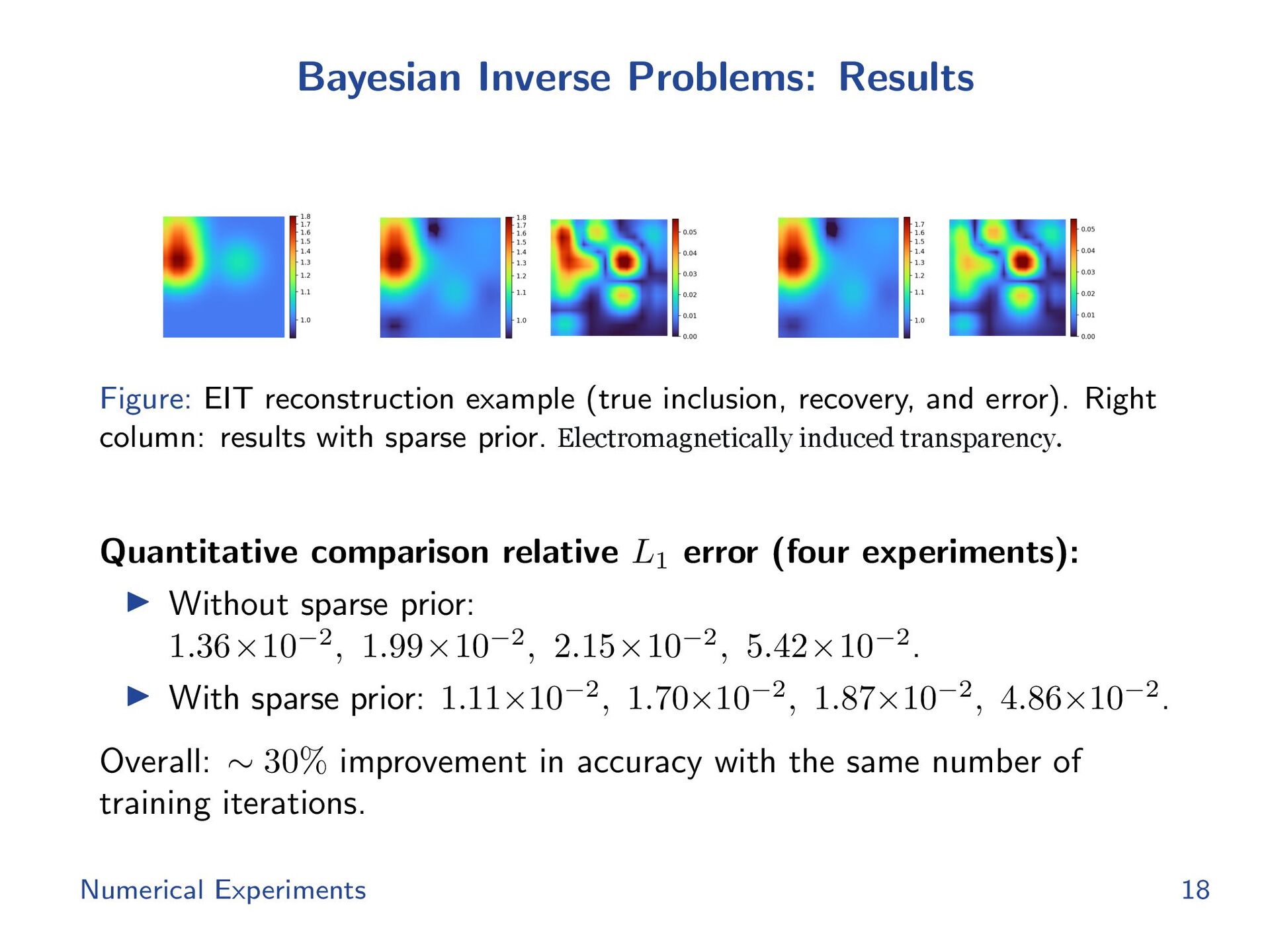{kind=link}
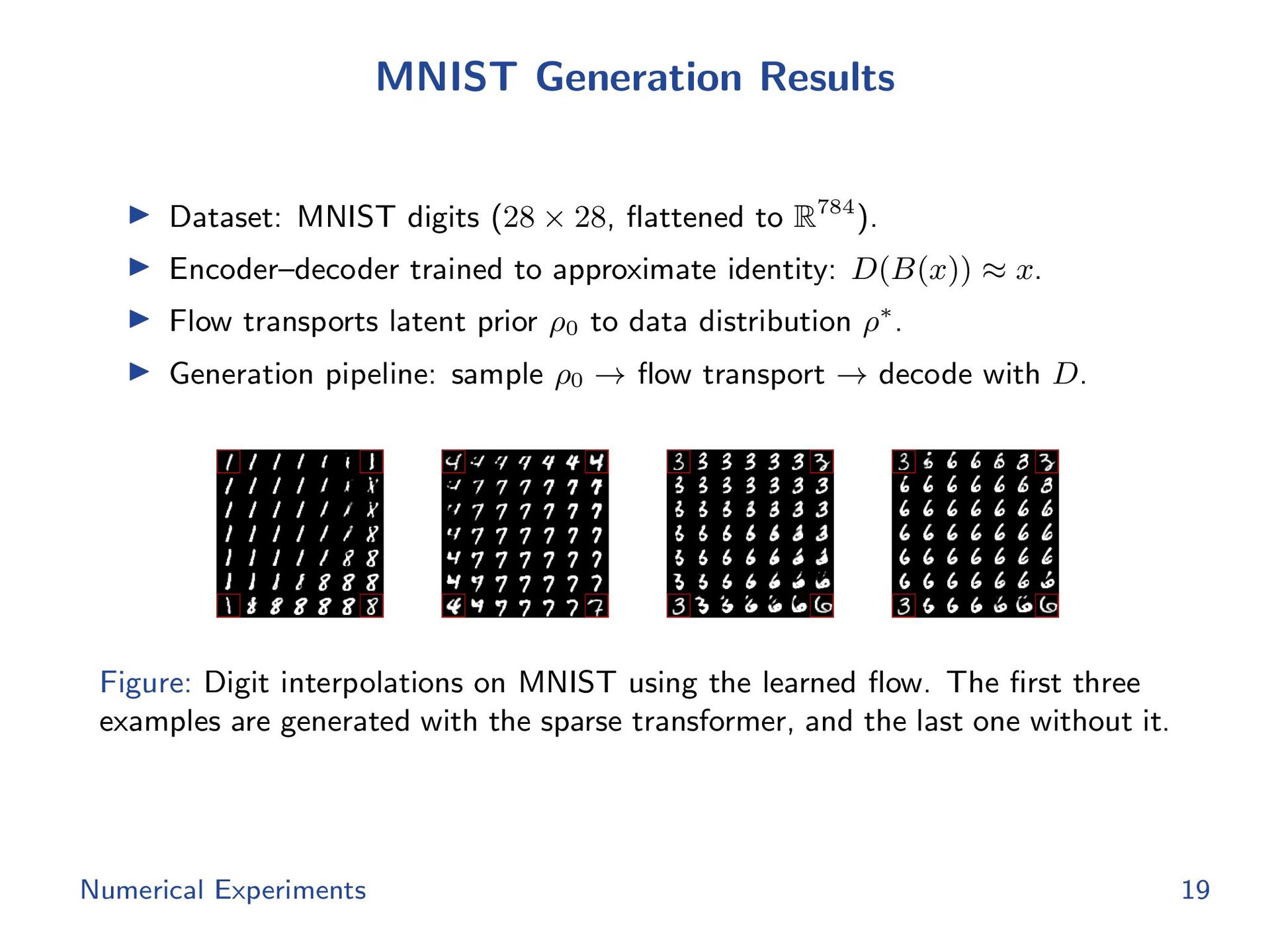{kind=link}
{kind=link}