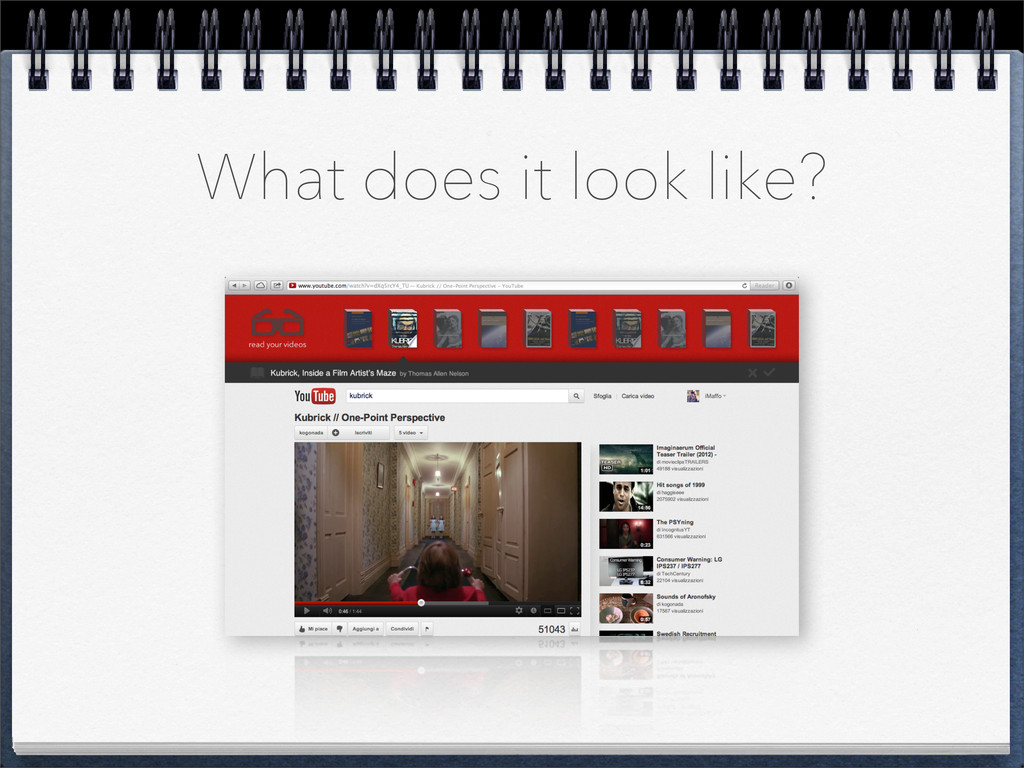
books based on the video you’re watching on YouTube • It is completely web based • Built mainly in JavaScript (client side) and PHP (server side) • It makes use of the Google Books API
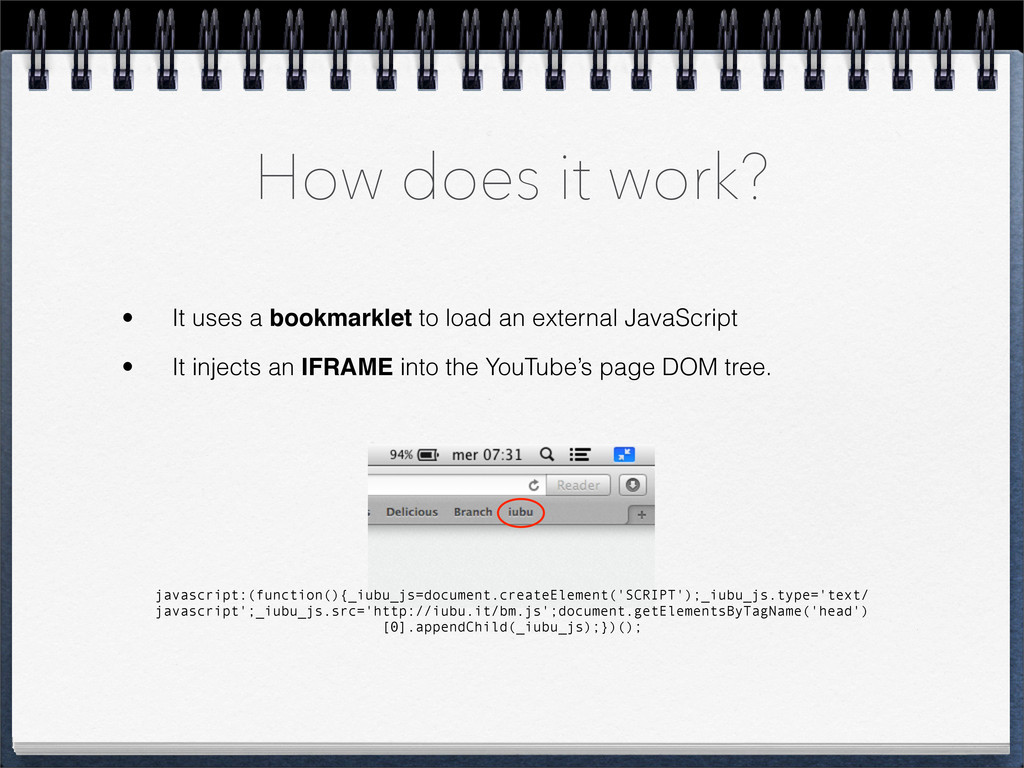
load an external JavaScript • It injects an IFRAME into the YouTube’s page DOM tree. javascript:(function(){_iubu_js=document.createElement('SCRIPT');_iubu_js.type='text/ javascript';_iubu_js.src='http://iubu.it/bm.js';document.getElementsByTagName('head') [0].appendChild(_iubu_js);})();
big N of patterns would have been impractical. • Google Books API doesn’t allow tags extraction or category filtering (!) • Data sources are quite volatile: we need to make it *in real time* • In the end: not enough time and resources to build such a system
Google Books • Categorization made to support the search process • Main principle: • Let’s be specific first (keywords search) • More “relaxed” search in case of failure. (category + 1 kw)
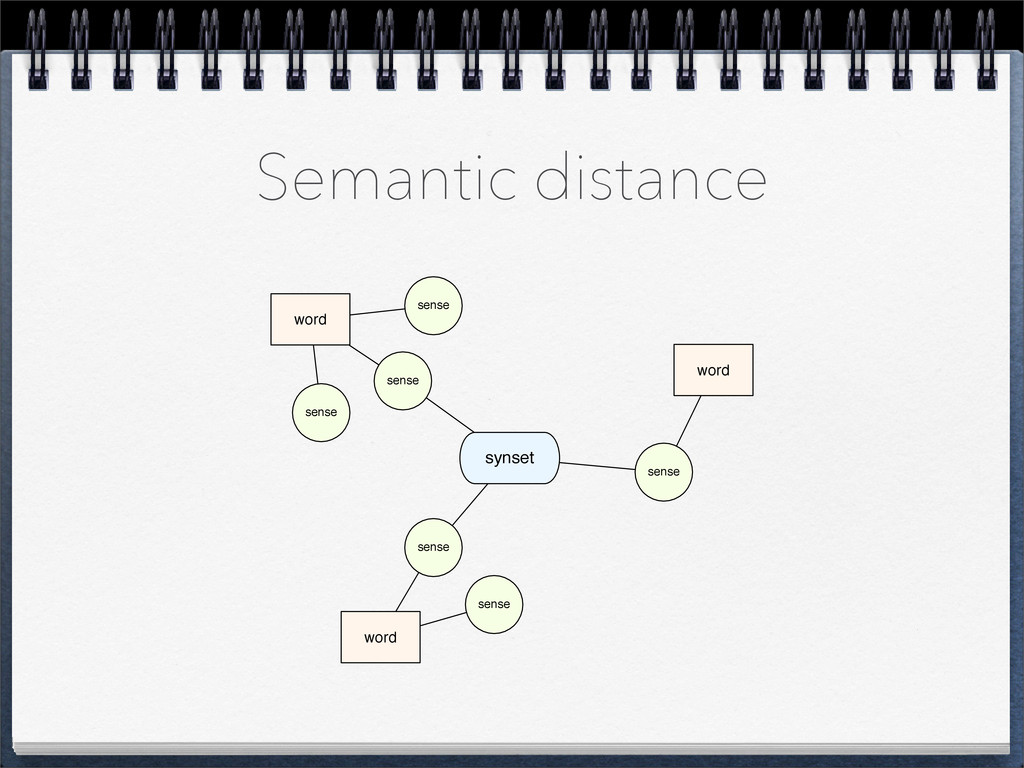
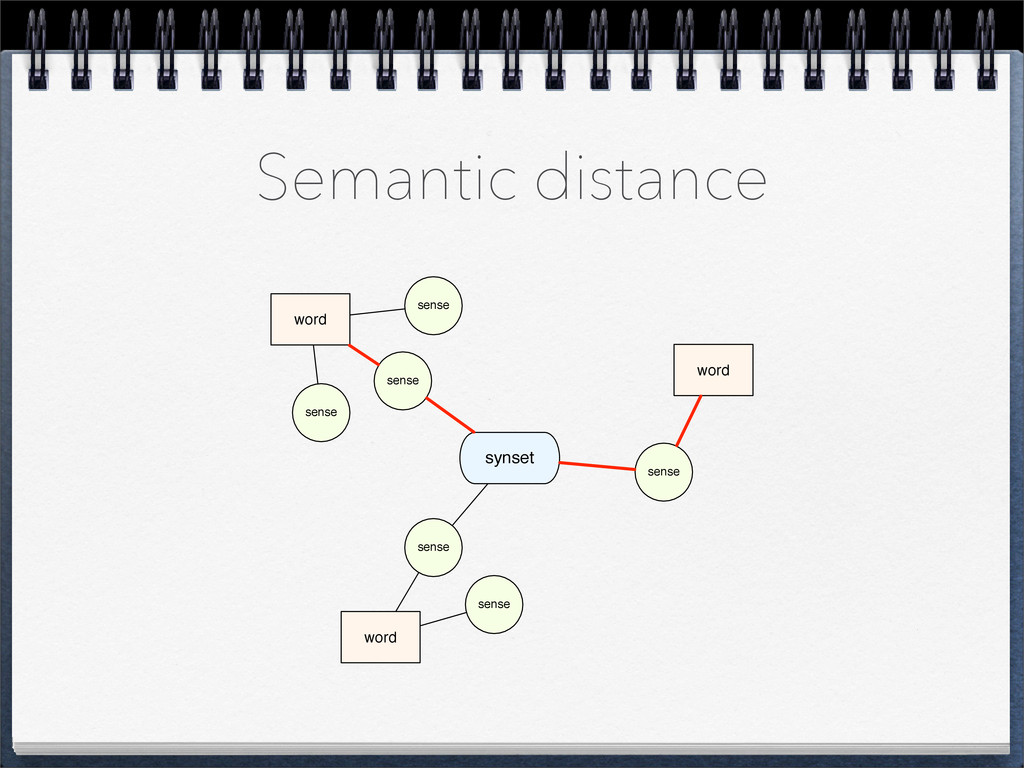
• We can use a typical shortest path algorithm • Similarity ∝ 1 / distance • Semantic similarity between category and {“stem1”:f1, “stem2”:f2, ...} pattern: ∑ similarity ( category, stemi ) * fi
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}