Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
allennlp.pdf
Search
Hitoshi Manabe
January 29, 2019
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
allennlp.pdf
Hitoshi Manabe
January 29, 2019
More Decks by Hitoshi Manabe
See All by Hitoshi Manabe
alacarte-snlp2018
manaysh
2
610
Featured
See All Featured
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
57k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Building the Perfect Custom Keyboard
takai
2
820
Marketing to machines
jonoalderson
1
5.6k
WENDY [Excerpt]
tessaabrams
11
39k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
410
Build your cross-platform service in a week with App Engine
jlugia
234
18k
New Earth Scene 8
popppiees
3
2.4k
Odyssey Design
rkendrick25
PRO
2
730
Exploring anti-patterns in Rails
aemeredith
3
450
Transcript
AllenNLPの話 真鍋 陽俊
Deep Learning for NLP - NLPでのDeep Learning用途 - テキスト生成 (machine
translation/text summarization) - 質問応答 (question answering) - 文書分類 etc... - 特にテキスト生成系では強い (言語モデルが) - どうやって実装するか
Deep Learning for NLP - NLP固有の処理 - 単語系列のpaddingとそのmask - word
-> indexの管理 - 未知語が現れたときの処理 - character -> word ...の階層的な処理 - pretrained modelの使用 - e.g) word2vec, ELMo etc… - train時とtest時の違い - e.g) teacher forcing, testだけbeam search etc… - 先行研究のモデルそのまま使うだけで良い場合もあれば、 特徴量追加(e.g character情報, tag情報)など拡張したい場合もある - 実装でちゃんとモジュールを切り分けて、使い回せる部分は再利用 - 特徴量追加してもできるだけソースの変更は最小限にしたい
AllenNLPとは - Deep Learning × NLPなライブラリ - 実装済みのモデルが多い and モデルの拡張も容易
- Pytorchベース, 裏のtokenizerとかはspaCyが使われていたり ※ https://github.com/allenai/allennlp/ より
何が良いか メジャーなTask(Dataset) / Module / Model / が既に多くカバー カバーされていなくても 容易にextendできて、
手を入れやすい 簡単なモデルは大概網羅されてる ので(ほとんど)コーディングせず実 行が可能 ※ https://github.com/allenai/allennlp/ より
AllenNLPとは その他のツール - keras - 簡単に書ける - NLPタスク特化ではない - pytext
- prototyping というより production寄りに見える - facebookが作っているのでfastText, fairseqとかと将来的に繋がる可能性 - 違いはここのissueでdiscussionされている - https://github.com/facebookresearch/pytext/issues/110
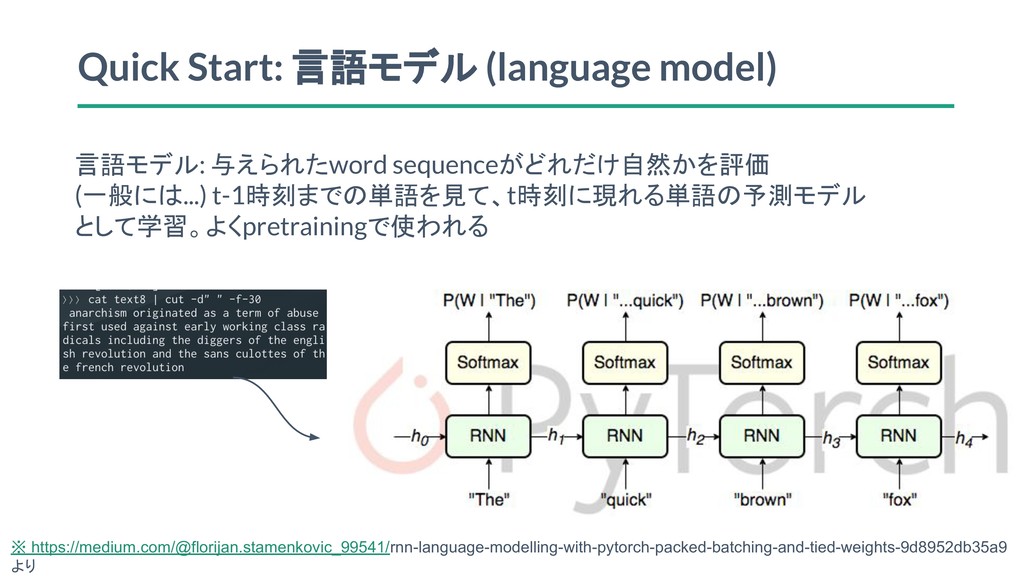
Quick Start: 言語モデル (language model) 言語モデル: 与えられたword sequenceがどれだけ自然かを評価 (一般には...) t-1時刻までの単語を見て、t時刻に現れる単語の予測モデル
として学習。よくpretrainingで使われる ※ https://medium.com/@florijan.stamenkovic_99541/rnn-language-modelling-with-pytorch-packed-batching-and-tied-weights-9d8952db35a9 より
Quick Start: 言語モデル (language model) Json記述してコマンド叩いて終わり
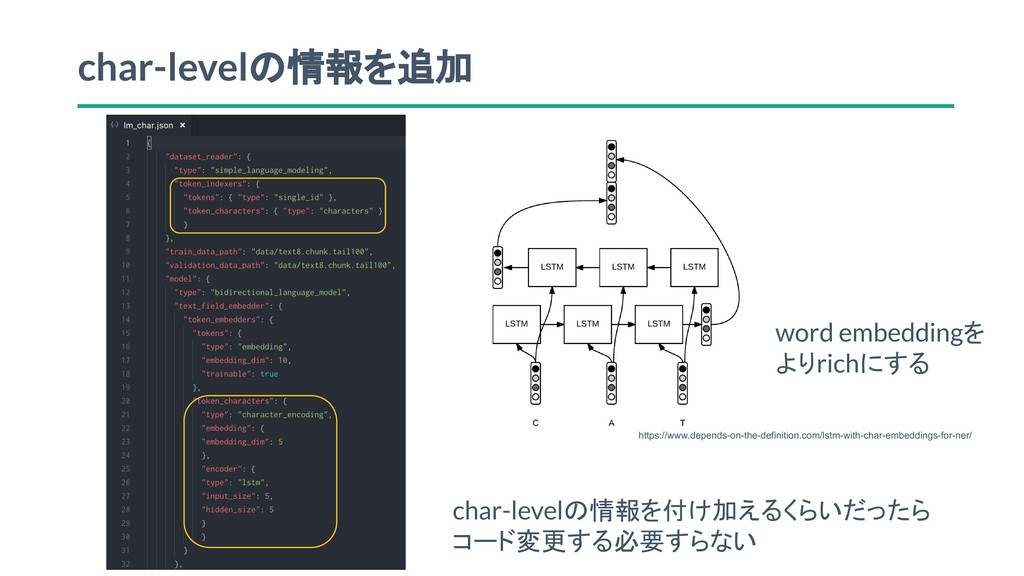
char-levelの情報を追加 char-levelの情報を付け加えるくらいだったら コード変更する必要すらない https://www.depends-on-the-definition.com/lstm-with-char-embeddings-for-ner/ word embeddingを よりrichにする
その他Jsonから記述可能なこと - ハイパーパラメータ周りの設定 - モジュールの切り替え - LSTM or GRU -
CNN or RNN - word embeddingにcharacter-levelの情報をaugment - pre-trained word embeddingの利用(とparameter freeze) - ELMo, BERTによるcontualized word embeddingの導入
Overall Architecture of Allen NLP メイン構成要素 - dataset_reader - テキストファイル読み込みから学習データのインスタンス生成
- model - Pytorchのforward計算の記述 - iterator - ミニバッチ生成とかpaddingとか - trainer - 学習ループの記述, 最適化アルゴリズム/validationのmetric指定とか 普通に使う分にはdataset_readerとmodelだけコーディングすれば良さそう
Overall Architecture of Allen NLP model moduleの組み合わせとして記述
Overall Architecture of Allen NLP dataset_reader 必要であれば前処理も記述
どのレイヤーから実装するかはcase by case Level1. AllenNLP Config - とりあえずLSTM使って文書分類したい。言語モデル作りたい。 Level2. AllenNLP
- AllenNLP内で提供されるmoduleを組み合わせて自前の構成を作る - 未対応なデータセットのフォーマット, 学習設定 (GAN等), 前処理 Level3. Pytorch - (moduleの組合せだと対応不能な)新しいモデルアーキテクチャ Level4. Numpy - 目的関数を変えたい。自前のfunctionalを使いたい。
最後に その他紹介しきれなかった機能はたくさんある - e.g) ensemble, デモのserve 未対応だと思われるところ - NLP pipelineな処理が簡単に書けると嬉しい
- e.g) 単語分割 -> 係り受け解析 -> 情報抽出 - 評価metricがmodelに内包されているので, (恐らく)正確な評価値は出せないケースが一部あるので注意 - e.g) subword分割単位の翻訳モデルのBLUEスコアとか とはいえかなり抽象化されているので中身を厳密に知る必要がある時は ちゃんと中のソースを読みましょう
参考文献 ・https://allennlp.org/papers/AllenNLP_white_paper.pdf ・https://github.com/allenai/writing-code-for-nlp-research-emnlp2018 ・https://github.com/chantera/svm2017
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}