Monitor tribe. - ~10 years experience. - Past: ThoughtWorks, SoundCloud, eBay, two small startups. - Background in programming languages/systems, type systems, human computer interaction.
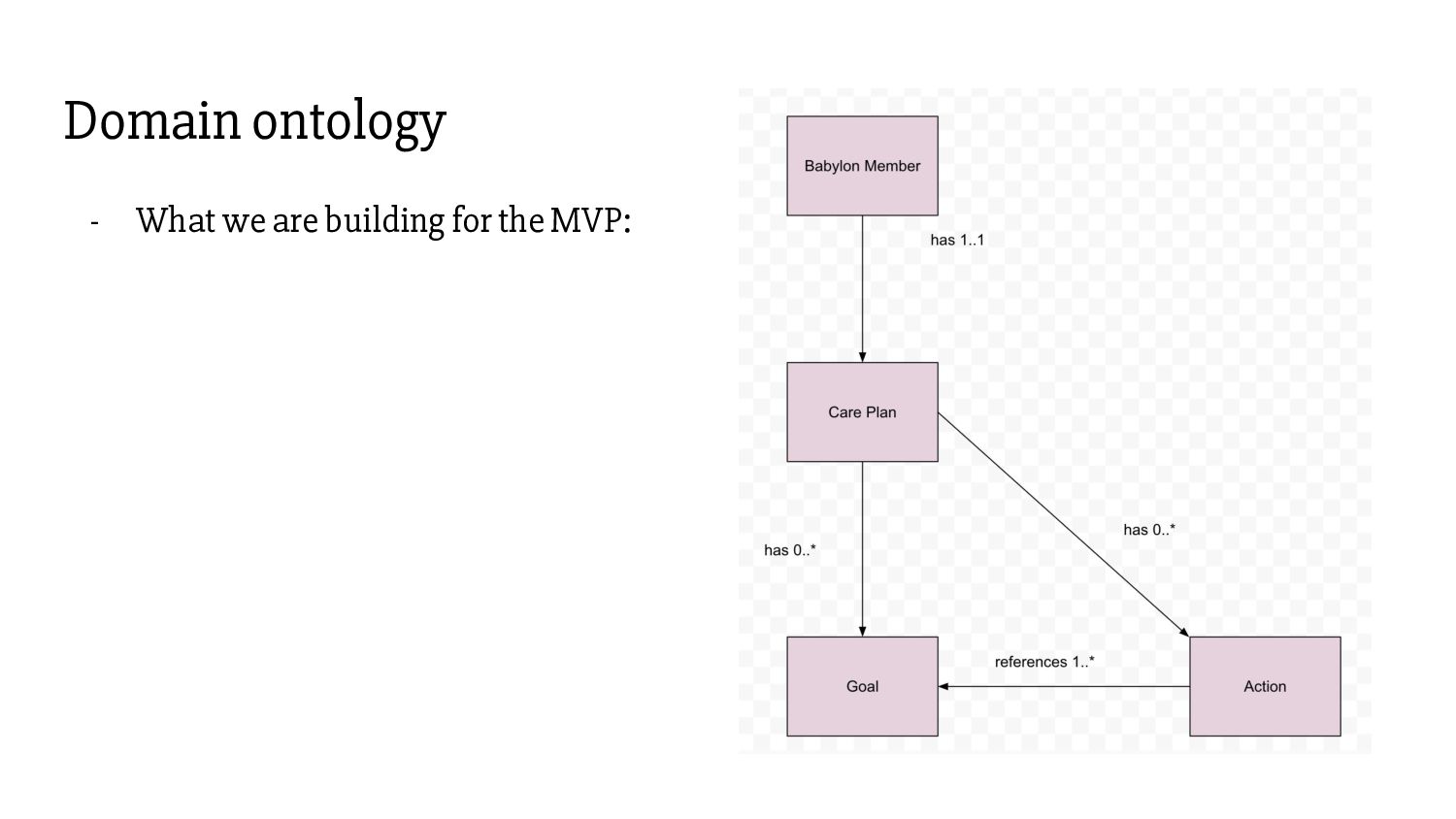
shared between a patient, their authorised family members, care teams, clinicians etc. - A care plan is co-created by and collaborated upon by several different actors. - To start with, it will contain health goals patients can achieve through self-management, and actions that will help them take there. - Hypothesis: The improved visibility/locality, improved patient participation and personalisation will lead to greater adherence from patients, and therefore to better health outcomes.
shared understanding of the domain among all stakeholders. - Balance agile development with solid deliberate design. - Build with interoperability as a first-class goal. It shouldn’t be an afterthought. - Greenfield project – Use as a vehicle for experimentation and innovation.
matter experts) and other key stakeholders. - Clinicians. - Clinical safety folks. - Product managers. - Data tribe. - Collaborate on building a shared understanding of the domain (problem space + solution space) with SMEs. - Capture the understanding as tangible evolving artefacts. - Adhere to DDD (domain-driven design) principles. - Ubiquitous Language, Aggregates, Bounded Contexts.
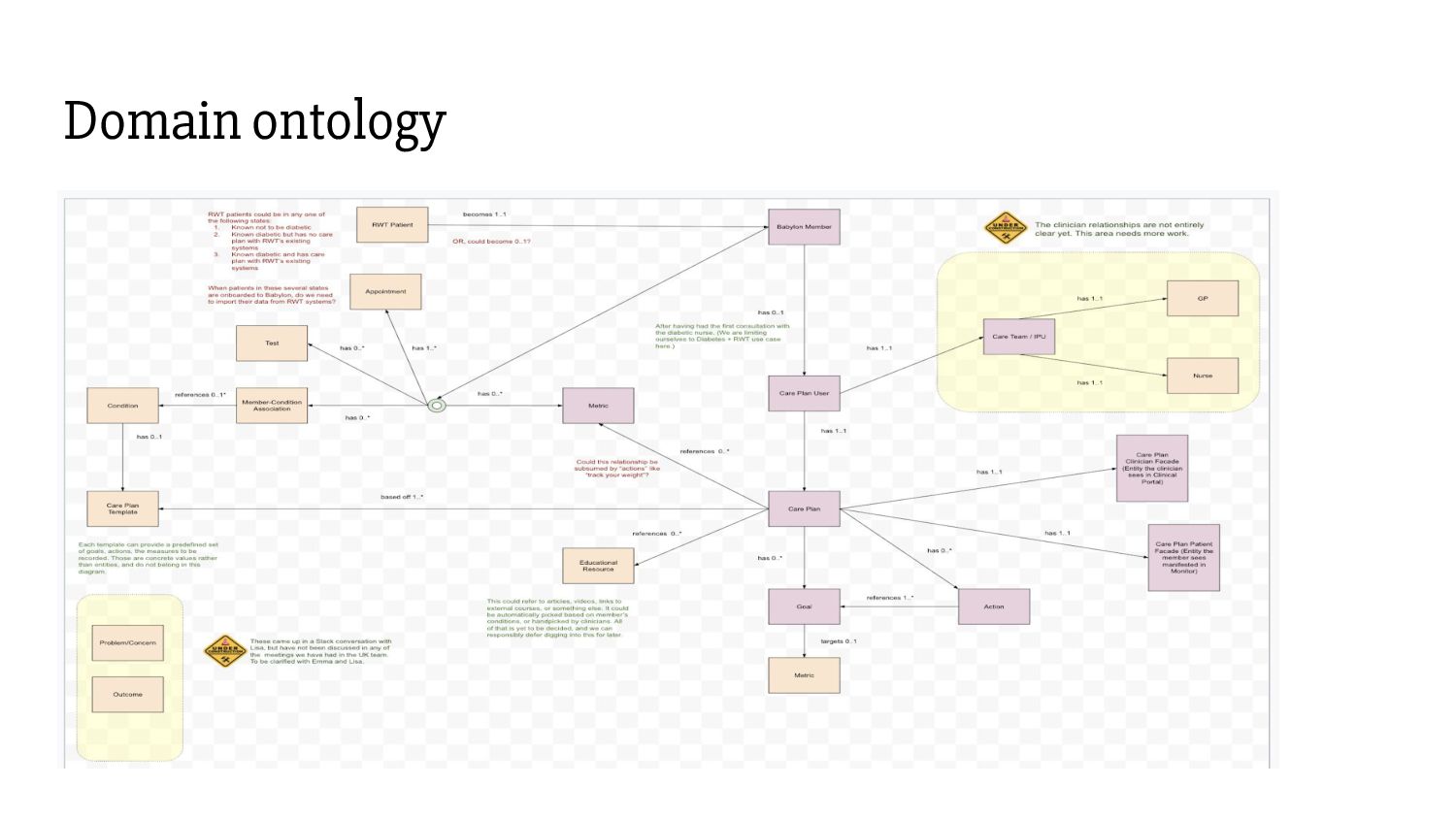
artefacts. They comprise many interconnected objects of many different entities evolving at their own pace. - Care plans are co-created and collaborated upon by patients, clinicians, care teams. - Clinicians build care plans in an interactive UI. - We need access to entire care plan graphs as of any point in time.
which scales with the domain ontology, requiring minimal work per added model? - The features that should scale up: - Retrieving the latest view of the whole of, or a subset of, the object graph. - Retrieving the state of the whole of, or a subset of, the object graph, as of any point in time. - Interactive editing. - Basic revision control. - Persistence layer mapping. - API representations.
The incidental is a part of the picture, and can distract from the essential. - With a pseudo-PL, you can focus on the essence, imagining away any incidental elements. - You could imagine a combination of syntactic constructs, abstraction mechanisms, type system features that no real PLs have. Imagination is the limit.
id: Id base, revisionId: RevisionId base, entityCreatedAt: OffsetDateTime, revisionCreatedAt: OffsetDateTime, } ++ base.map( case field when field.isRevisionable -> (field.name : Frame field.type) case field -> (field.name : field.type) )
(A limited version thereof.) - We use PostgreSQL as a “database engine”, and implement these semantics on top. - This can be thought of as us “greenspunning” databases that support such semantics natively. e.g. IrminDB, Datomic, Crux etc.
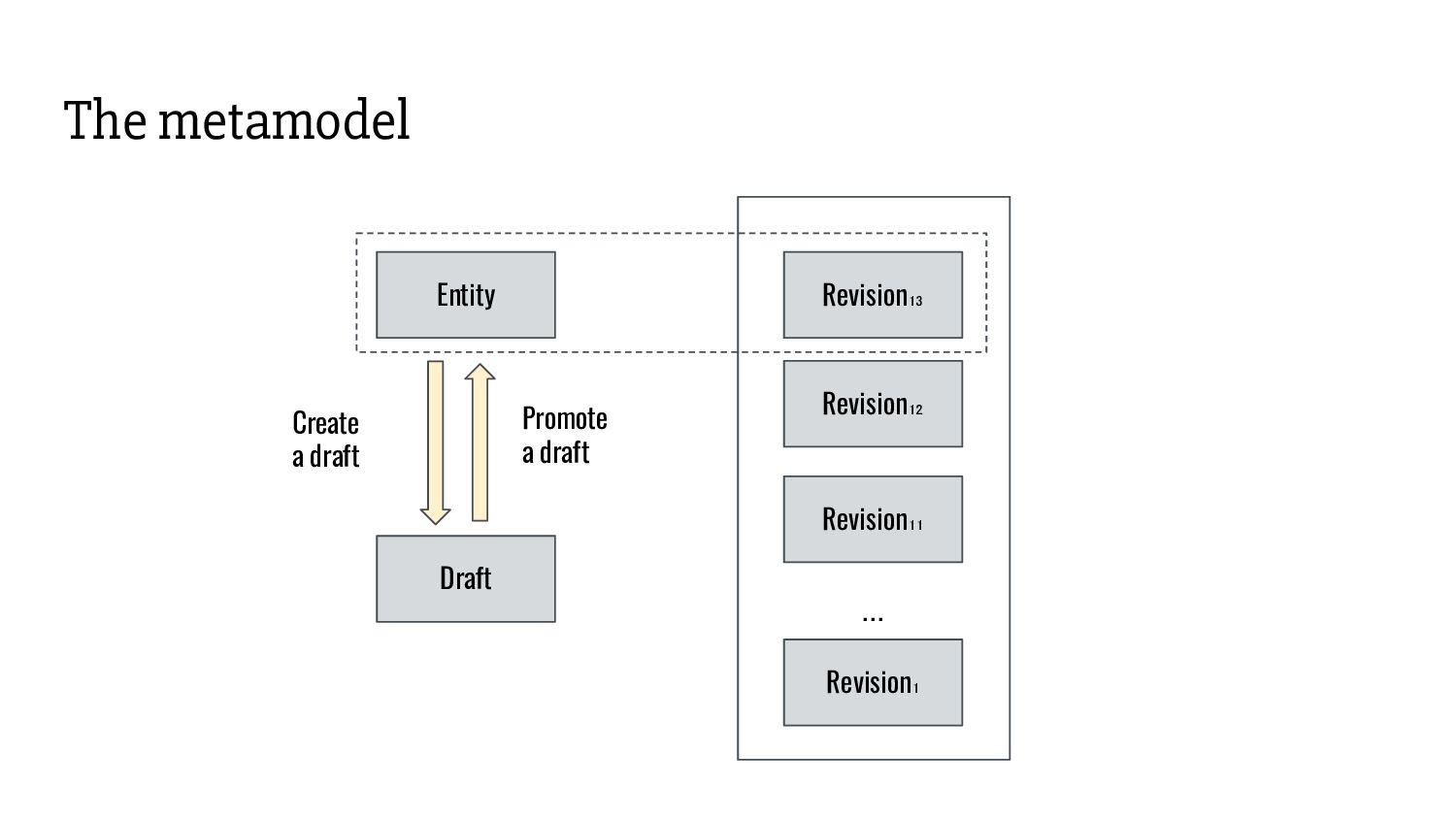
associated with it: - Entity - Revision - Together they build frames. - Revisions are immutable. Updates are made by inserting new revisions. Old revisions remain available for access. - Since different entities evolve at different paces, associations are stored in separate tables.
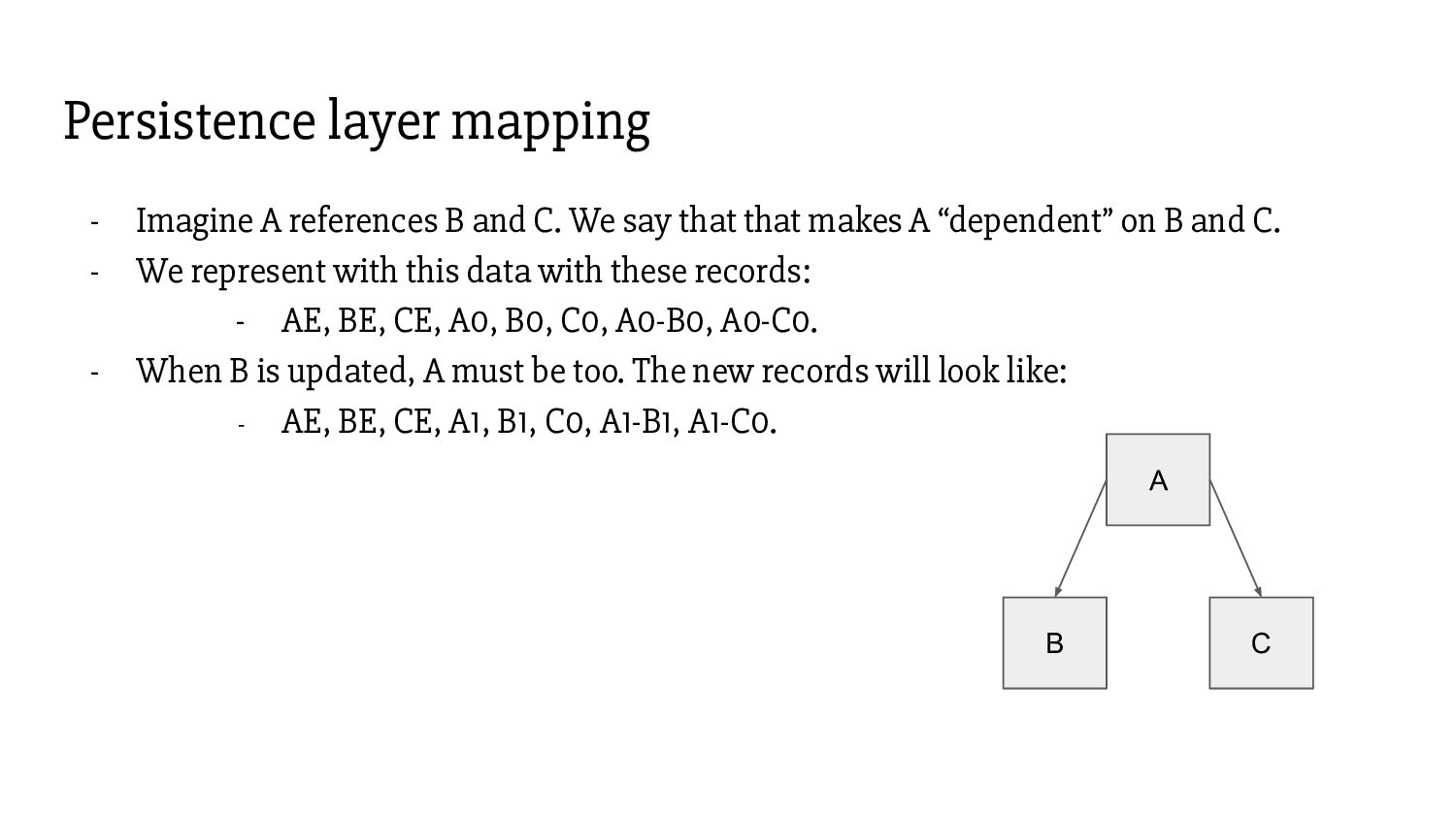
that makes A “dependent” on B and C. - We represent with this data with these records: - AE, BE, CE, A0, B0, C0, A0-B0, A0-C0. - When B is updated, A must be too. The new records will look like: - AE, BE, CE, A1, B1, C0, A1-B1, A1-C0. Persistence layer mapping A C B
substrate for exposing our semantic universe. - Typed and introspectable APIs. - Excellent tooling. - Different metamodel applications are modeled as different concrete types in the GraphQL layer. - We innovated some patterns for using GraphQL with Java which could be leveraged in other projects. API layer
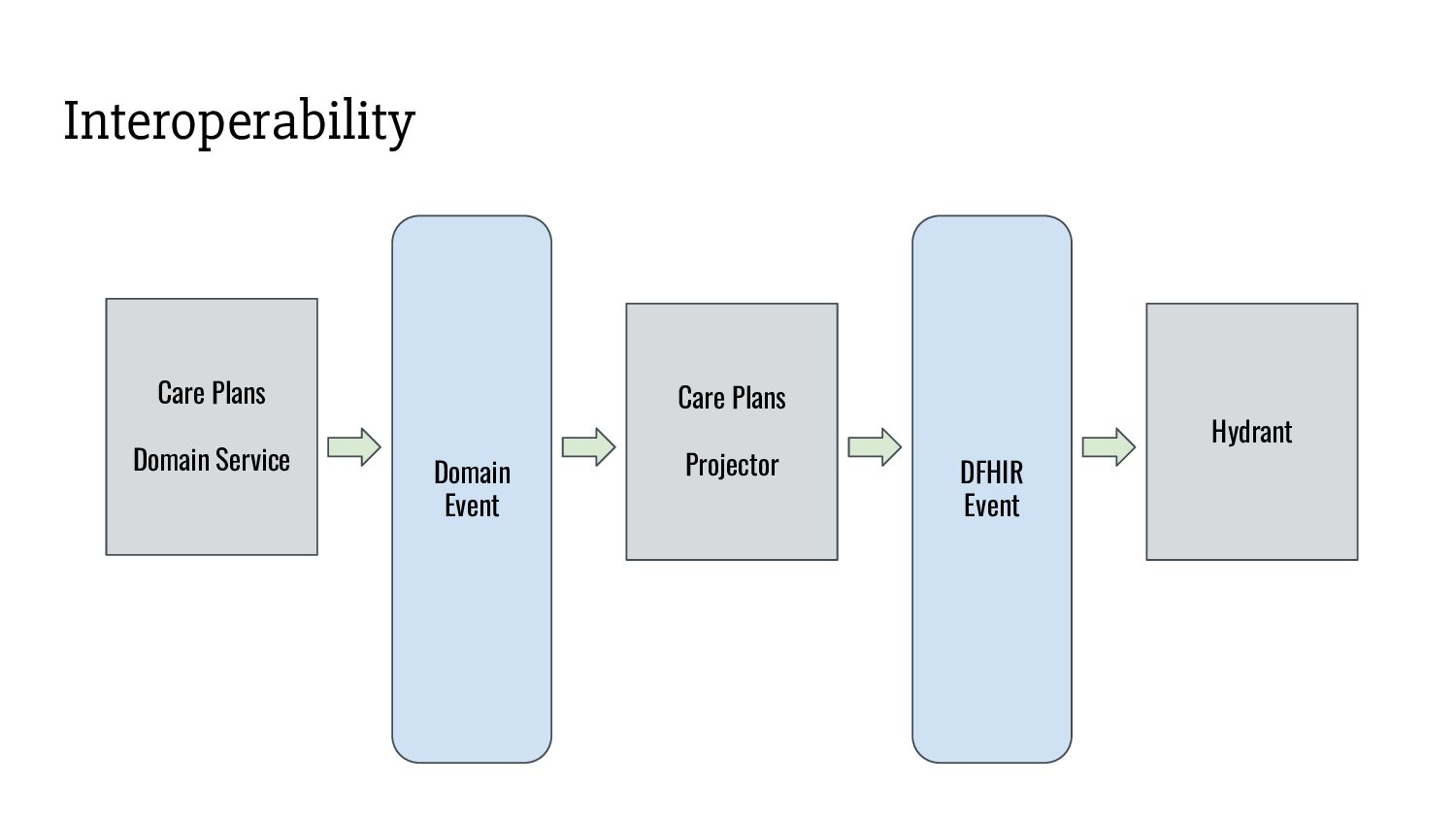
quite FHIR. - FHIR is complex. - Adopting it as a primary modelling tool is difficult. Requires extensive use of advanced techniques such as: - BasicObject refinement. - Extension points. - Profiling. - It has to be a company-wide decision with willingness to invest in education, review process, tooling. Interoperability
safe to assume that entities in the “Babylon universe” (B) and “FHIR universe” (F) are not isomorphic. - 3 levels of lossiness: - Not all B entity types map to F entity types. - For the B entity types that map to F entity types, not all B entities map to F entities. - For the B entities that map to F entities, not all B attributes map to F attributes. Interoperability
aren’t established yet. - You hit abstraction walls pretty quickly with Java and Spring. A lot of boilerplate. Not quite plug and play. - GraphQL type system has quite a few rough edges too. It’s a relatively young protocol that’s still evolving. - Sophistication comes at a price: Usually a higher initial learning curve. (But we believe the ROI justifies the cost.) Challenges
types, prescriptions, condition templates, progress tracking, and more coming. - Integration with other Monitor/Babylon features such as food swaps. - Pessimistic locking is too aggressive. We need to allow for concurrent modes of manipulation. - Improve the innards. Future Directions
and directories structure. - By making sure no line of text has multiple data, diffs can be made to work at semantically richer layers. - References will be weak, and stored in separate plain text files. - Store this in an S3 directory per patient. - S3 has versioning built into it. - You could even initialise a Git repository in the root patient directory. - Major downside: Queryability suffers. S3 or Git don’t have a semantic understanding of your data, so complex queries become impractical. Alternate persistence layer mapping with S3 + Git
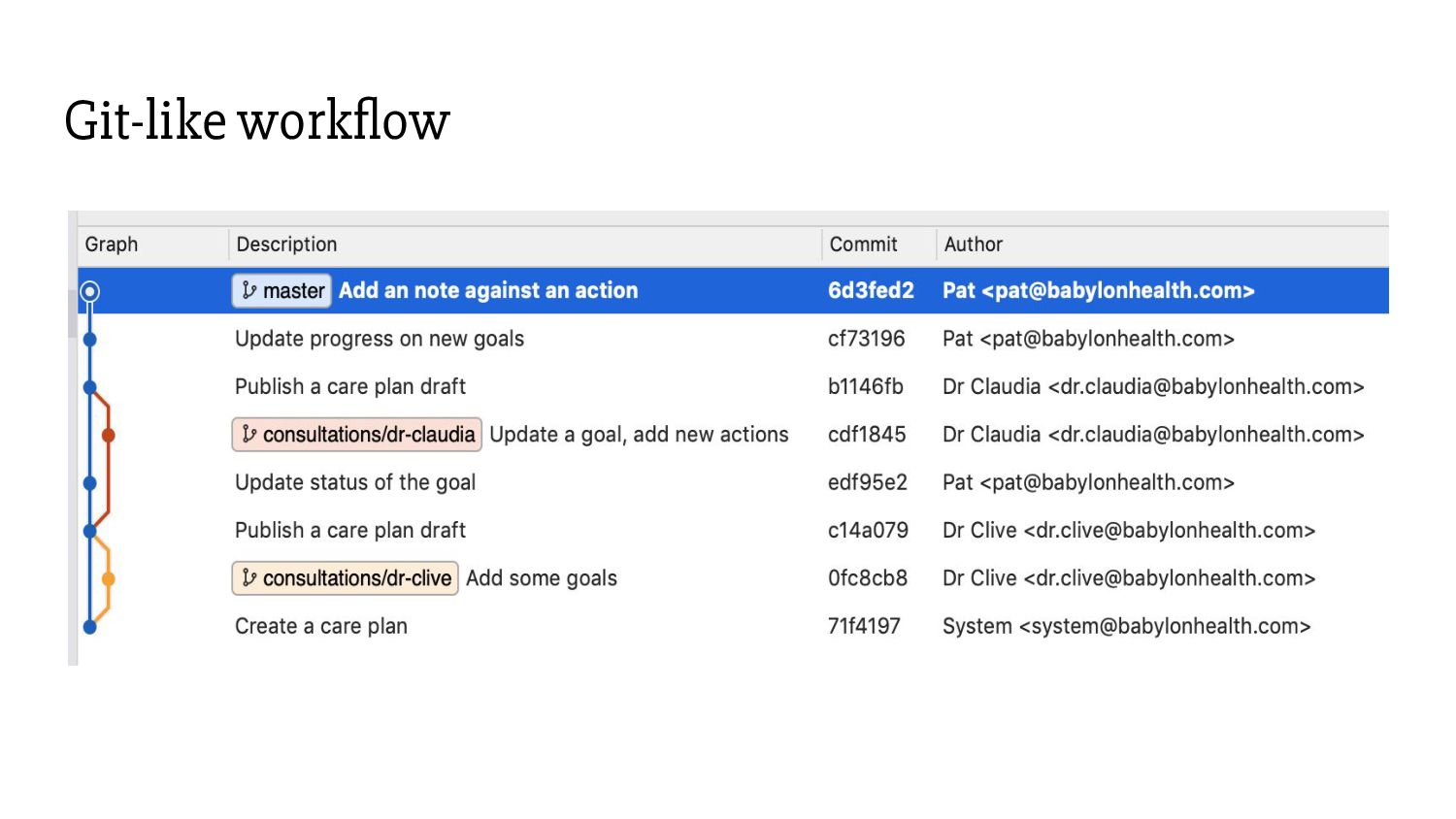
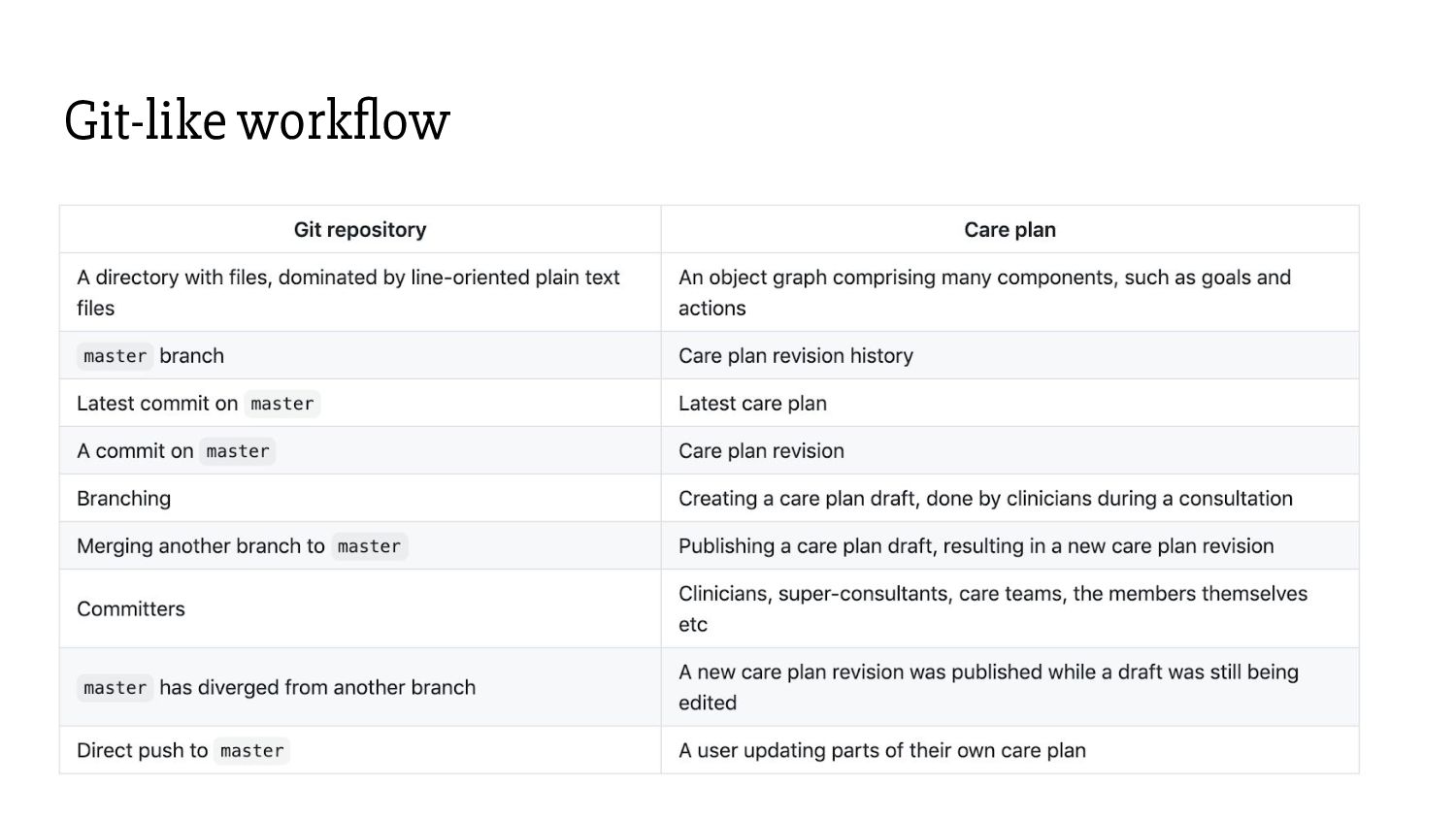
- Any one clinician can be in a “modification session” at any given time. Patients and other actors currently cannot modify care plans. - Future directions: - Keep the patient-modifiable fields (P) strictly separate from clinician-modifiable fields (C). P changes are instantaneous. C changes happen through drafts. P changes can be ported back instantly to C drafts. (Analog: rebasing master onto another branch.) - Implement rudimentary conflict resolution. Not too difficult with our metamodel. It will need a dedicated UI though. Pessimistic locking is too aggressive
API provides operations for incrementally and atomically modifying/constructing objects. - GraphQL supports batching out of the box. Needs some tweaks for supporting referring to a result of operation(N) in operation(N + 1). Interactive editing
Those storing snapshots. Patches are generated on the fly. e.g. Git, Mercurial. - Those storing patches. Concrete views are built by applying patches. e.g. Pijul, Darcs. - We chose to go with the snapshot model because we need access to full objects as of any revision much more frequently (both in contexts and time) than we need the diffs between them. Patch vs Snapshot model
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}