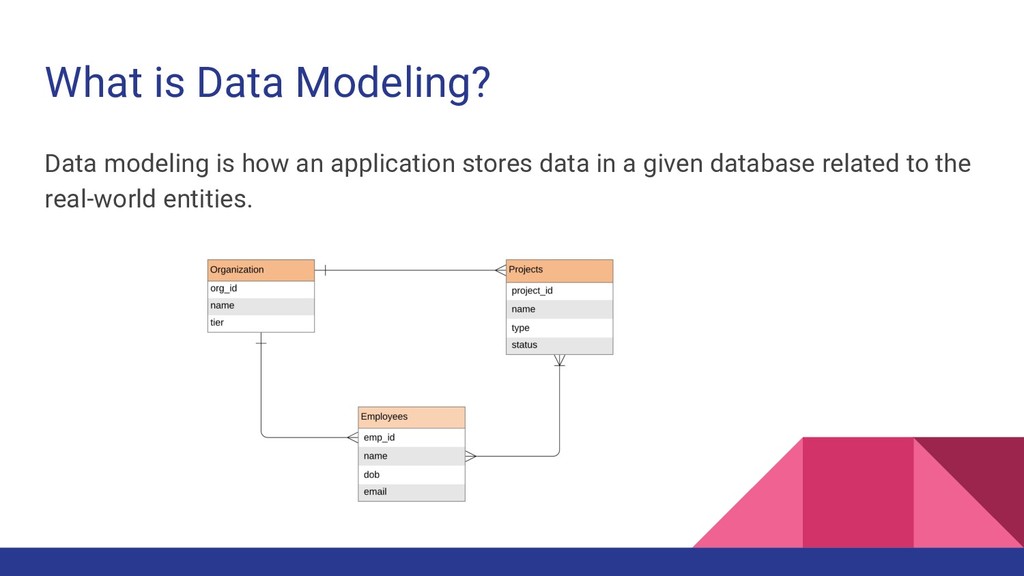
DynamoDB is the NoSQL offering from AWS. The data modeling with DynamoDB is significantly different from the relational database data modeling. This presentation is focused on the design patterns commonly used with DynamoDB.
Databases • DynamoDB - Core Concepts • DynamoDB - Relational Data Modeling • Five Step Process for Data Modeling • A Use Case • Further Reading References
with data normalization • Each table has a strict schema • Each entity has its own table • Tables are connected with relationships • Need more compute power to retrieve data from multiple tables • Performance may degrade as the database scales
in Three Availability Zones Three options for Reads • Eventual Consistency • Strong Consistency • Transactional Two options for Writes • Standard • Transactional
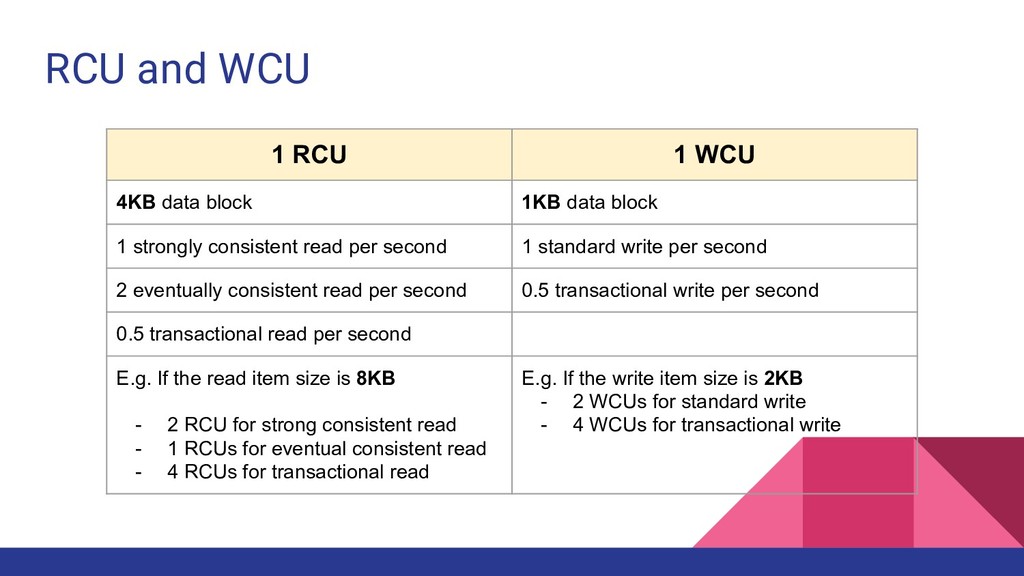
table Specify throughput in terms of capacity units 1 capacity unit can handle 1 write or 1 read DynamoDB pricing is based on capacity units and storage Two type of capacity units • Read Capacity Unit (RCU) • Write Capacity Unit (WCU)
1KB data block 1 strongly consistent read per second 1 standard write per second 2 eventually consistent read per second 0.5 transactional write per second 0.5 transactional read per second E.g. If the read item size is 8KB - 2 RCU for strong consistent read - 1 RCUs for eventual consistent read - 4 RCUs for transactional read E.g. If the write item size is 2KB - 2 WCUs for standard write - 4 WCUs for transactional write
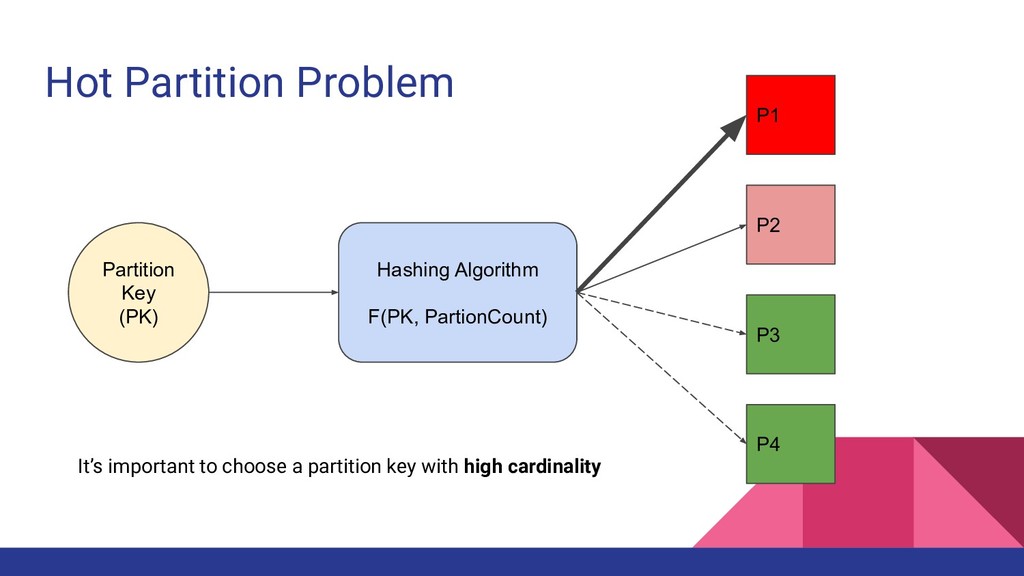
table can have one or more partitions Number of partitions for a table depends on two things • Provisioned Throughput ◦ 1 Partition => 1000 WCUs or 3000 RCUs • Table Size ◦ 1 Partition => 10 GB of data If either 10GB or capacity unit limit exceed, DynamoDB adds a NEW partition
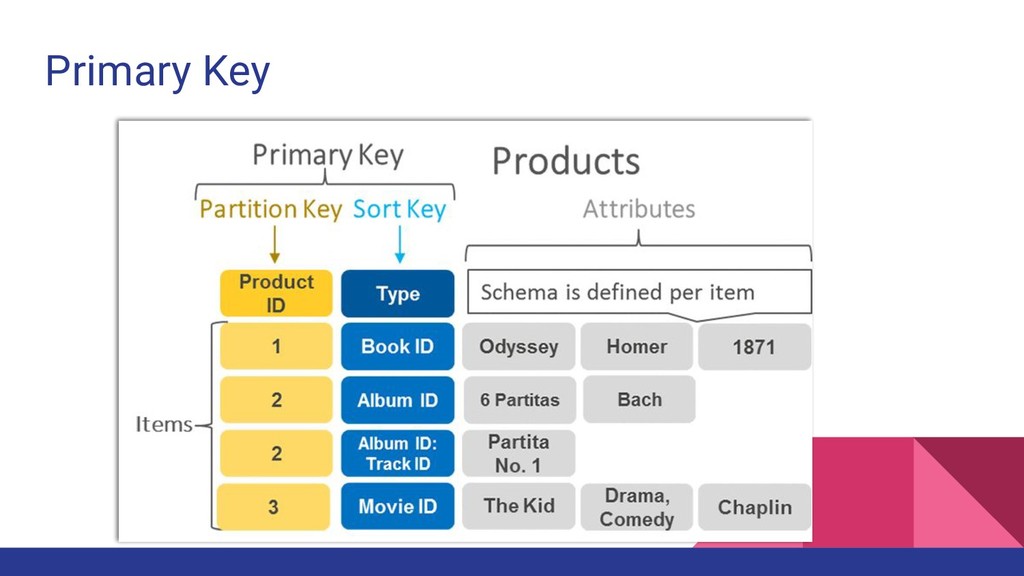
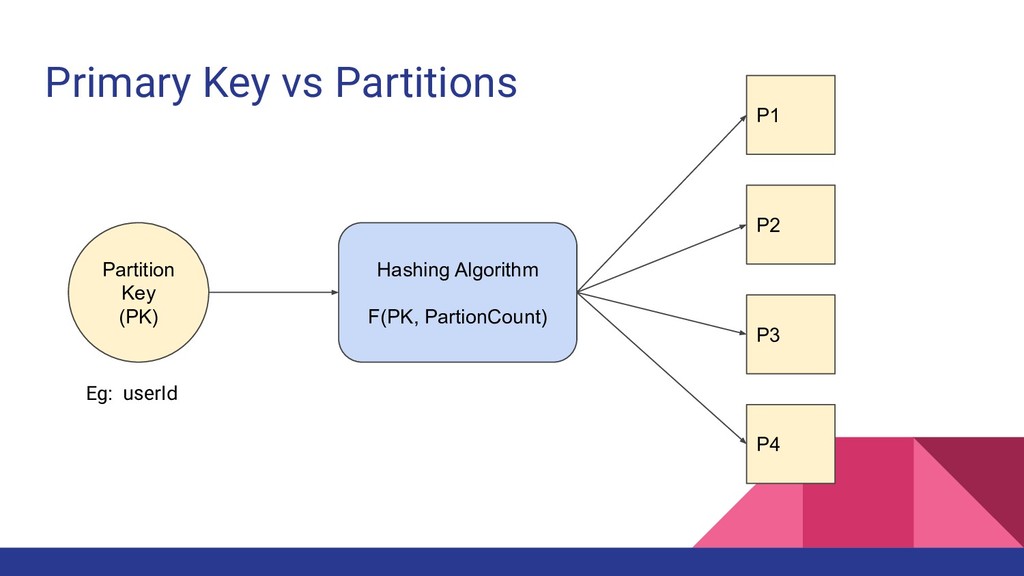
identify an item uniquely Primary key can have two forms • Only Partition key • Partition key + Sort key (Composite key) Partition Key(PK) is also known as Hash key Sort Key(SK) is also known as Range key Partition key is used to determine the partition that data is stored
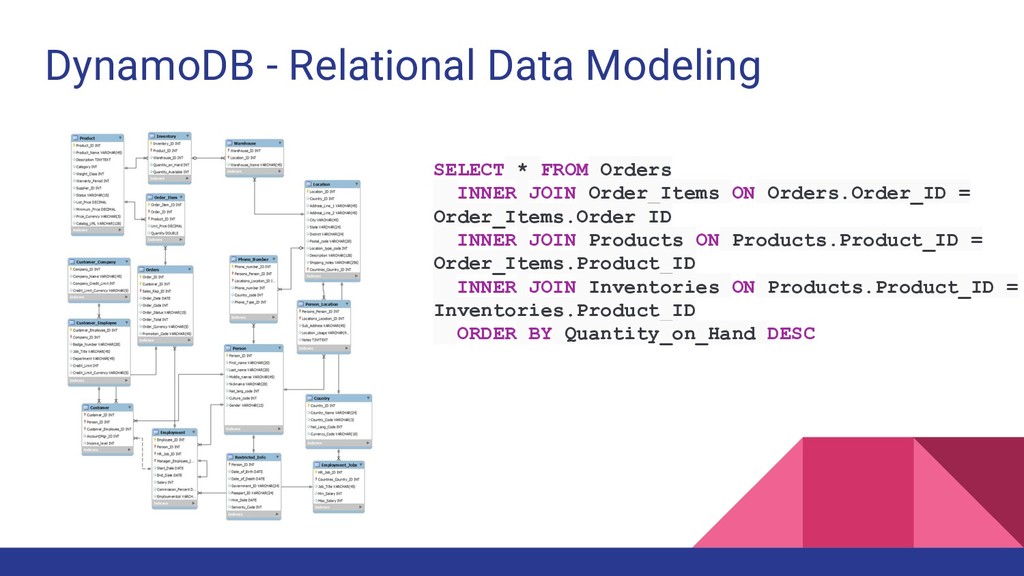
JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID ORDER BY Quantity_on_Hand DESC
for queries (As seen on previous slide) Limitations • Table joins require significant amount of processing • ACID transaction framework adds significant overhead to write process (It has to wait until all reads are completed in all the tables)
Schema Flexibility ◦ Store complex hierarchical data within a single item • Composite key design ◦ Store related items close together on the same table - (Using Sort key)
data modeling • Don’t fake a relational model • Must identify the Access Patterns before table design • Most applications need only one table • Identify primary keys and indexes to minimize the number of requests to DynamoDB to satisfy each access pattern
flexible schema to store different types of records in the same table • Identifying the most suitable Partition key and Sort key for each type of record to satisfy access patterns • Identifying secondary indexes for additional access patterns that cannot only be satisfied by the primary key (Partition and Sort keys) SELECT * FROM Table_X WHERE Attribute_Y = "somevalue" As a result - Simplified Queries
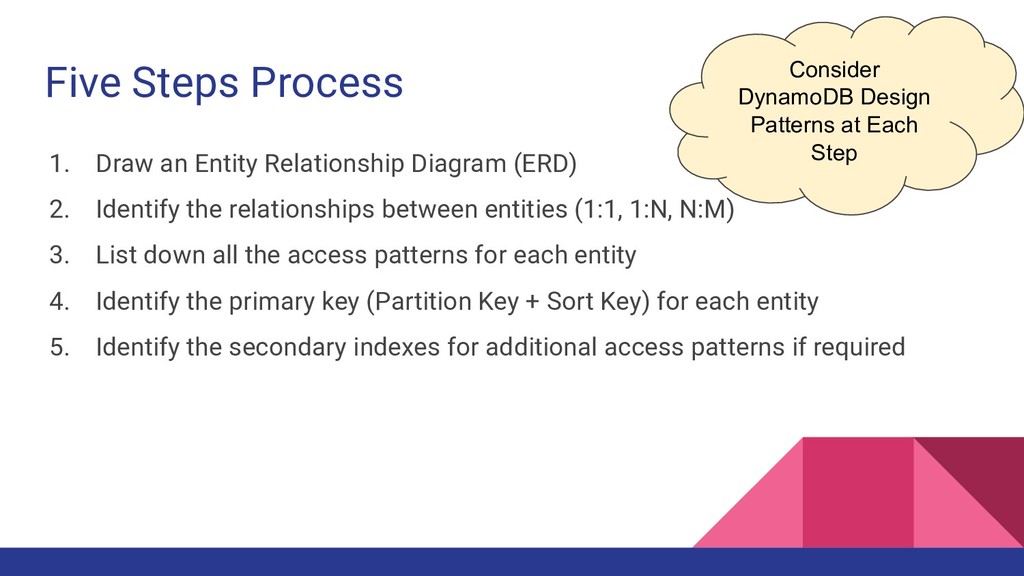
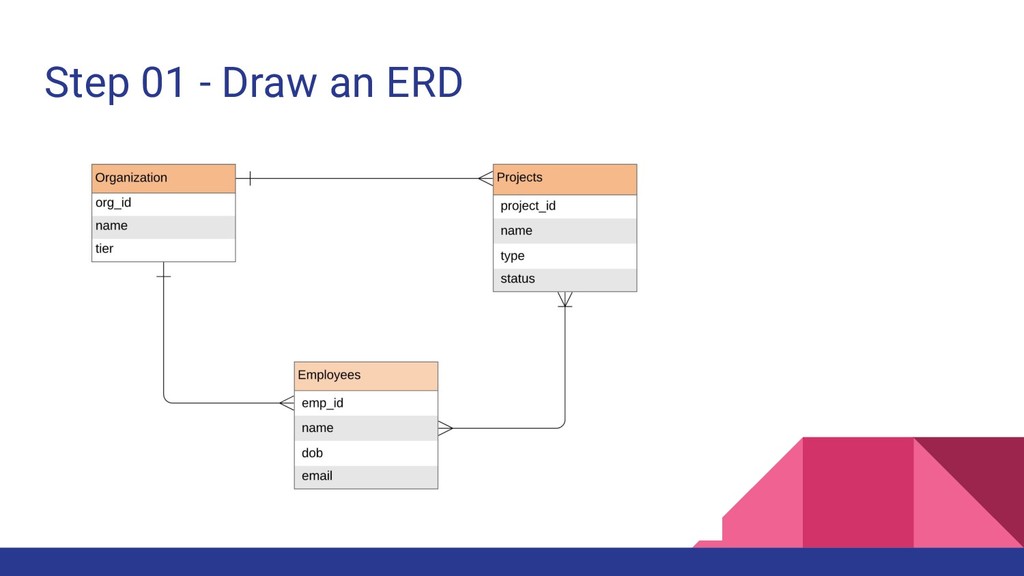
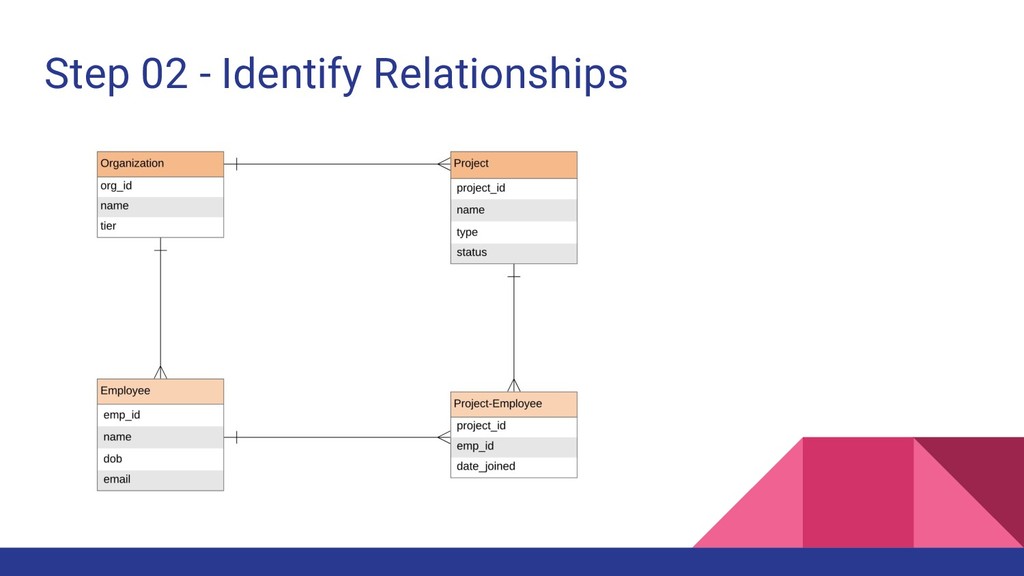
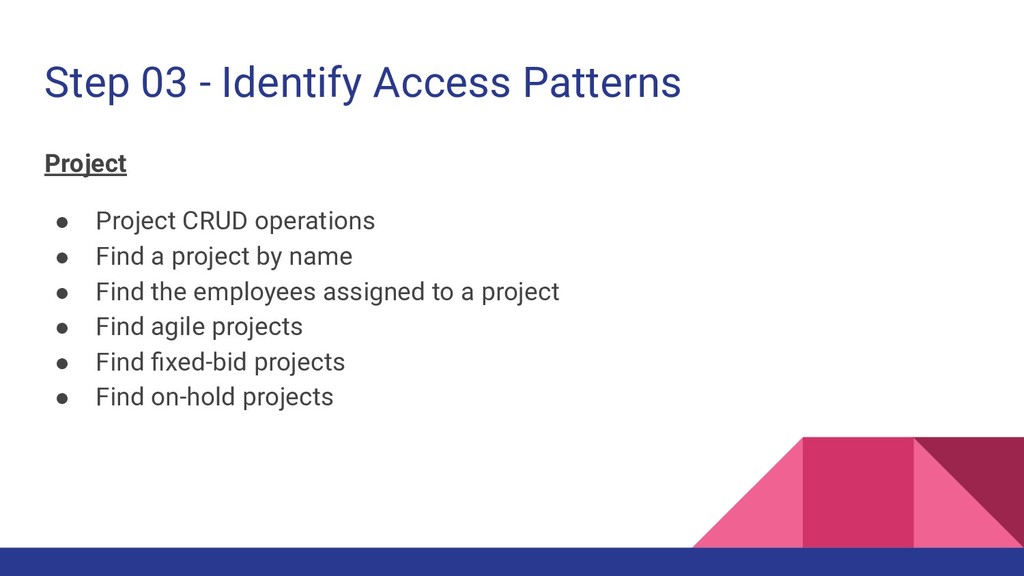
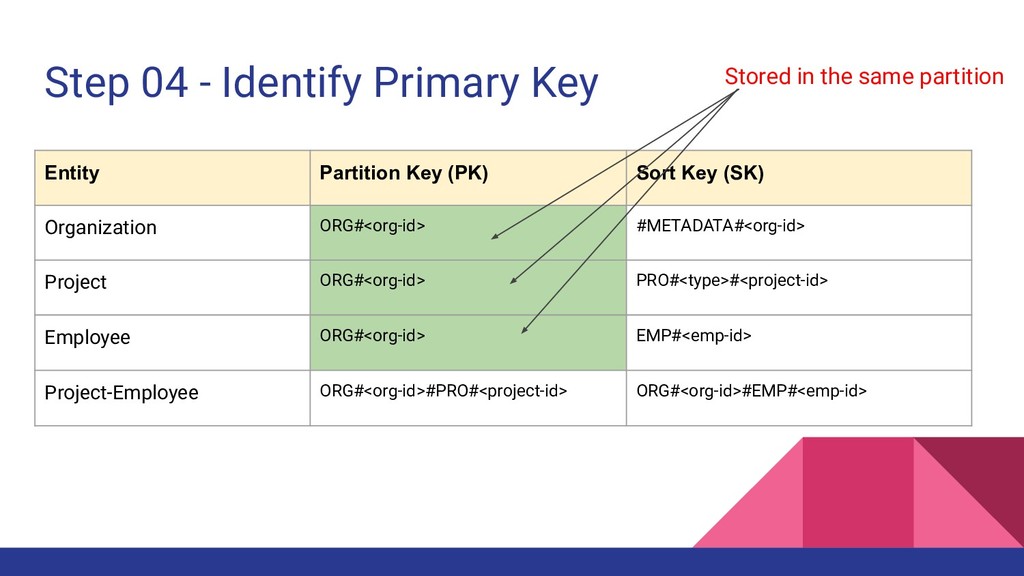
2. Identify the relationships between entities (1:1, 1:N, N:M) 3. List down all the access patterns for each entity 4. Identify the primary key (Partition Key + Sort Key) for each entity 5. Identify the secondary indexes for additional access patterns if required Consider DynamoDB Design Patterns at Each Step
operations • Find all the projects of an organization • Find all the employees of an organization • Find all projects and employees of an organization • Find an organization by name
SK=#METADATA#1234 Find all the projects of an organization - PK=ORG#1234 , SK begins_with(PRO#) Find all the employees of an organization - PK=ORG#1234 , SK begins_with(EMP#) Find both employees and projects - PK=ORG#1234 Find organization by name - Not satisfied yet.. Entity Partition Key (PK) Sort Key (SK) Organization ORG#<org-id> #METADATA#<org-id> Project ORG#<org-id> PRO#<type>#<project-id> Employee ORG#<org-id> EMP#<emp-id>
SK=EMP#300 Find all projects an employee is part of - Not yet satisfied Find all employees by name - Not yet satisfied Entity Partition Key (PK) Sort Key (SK) Employee ORG#<org-id> EMP#<emp-id>
an employee is part of - Use an inverted index Table Entity Partition Key (PK) Sort Key (SK) Project-Employee ORG#<org-id>#PRO#<project-id> ORG#<org-id>#EMP#<emp-id> GSI Name GSI Partition Key (PK) GSI Sort Key (SK) Project-Employee-Index ORG#<org-id>#EMP#<emp-id> ORG#<org-id>#PRO#<project-id> Query on GSI - PK=ORG#1234#EMP#300
projects, employees by name - GSI Overloading GSI/LSI Name GSI/LSI Partition Key (PK) GSI/LSI Sort Key (filterName) Filter-by-name-index ORG#<org-id> ORG#<org-name> Or EMP#<emp-name> Or PRO#<project-name> Find by org name - PK=ORG#1234 , filterName=ORG#HappyInc Find by emp name - PK=ORG#1234, filterName=EMP#Manoj
- Use a Sparse Index You can Query or Scan the GSI to find all the on-hold projects GSI Name GSI Partition Key (is_on_hold) On-Hold-Project-Index <any_value> eg: true
the results by non-key attributes • A filter expression is applied after a Query finishes, but before the results are returned. Therefore, a Query consumes the same amount of read capacity, regardless of whether a filter expression is present. • Use filter conditions if the secondary indexes cost more than the filter conditions due to low query velocity or frequency
Advance Design Patterns for DynamoDB - re:Invent 2018 video https://www.youtube.com/watch?v=HaEPXoXVf2k Database Design for a Mobile App with DynamoDB - (Workshop) https://aws.amazon.com/getting-started/projects/design-a-database-for-a-mobile-app-with-DynamoDB/ AWS DynamoDB Documentation https://docs.aws.amazon.com/amazonDynamoDB/latest/developerguide/Introduction.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}