Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
大規模言語モデル入門4章
Search
sugi
February 06, 2024
0
150
大規模言語モデル入門4章
sugi
February 06, 2024
Tweet
Share
Featured
See All Featured
Thoughts on Productivity
jonyablonski
75
5.1k
Why Our Code Smells
bkeepers
PRO
340
58k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
140
Joys of Absence: A Defence of Solitary Play
codingconduct
1
310
New Earth Scene 8
popppiees
1
1.7k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
231
22k
Building AI with AI
inesmontani
PRO
1
790
Site-Speed That Sticks
csswizardry
13
1.1k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
61
52k
Un-Boring Meetings
codingconduct
0
220
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
2.4k
Unsuck your backbone
ammeep
672
58k
Transcript
大規模言語モデル入門 4章
自己紹介 杉美帆 - 2017年DMM.com入社 - 2019年BASE株式会社入社 - 2022年シンプルフォーム入社 バックエンドエンジニア 好きなこと:リコメンド、検索
趣味:野球観戦、走ること
シンプルフォームのご紹介 https://www.simpleform.co.jp/
第4章のゴール - 大規模言語モデルの近年の進展について知る - プロンプトについて知る - 大規模言語モデルのアライメントの必要性を理解する
第4章 大規模言語モデルの進展 - 2023年にOpenAIが提供を開始した大規模言語モデルであるGPT-4やChatGPTは 幅広い自然言語処理のタスクを解くことができ、大きな話題となった - このGPTなどテキストを生成する能力をもつ大規模言語モデルの近年の進展につ いて知ることができる章
4.1 モデルの大規模化とその効果 - 大規模言語モデルの開発が進むにつれモデルに含まれるパラメータ数および事前 学習に使うコーパスの容量が飛躍的に増加 図4.2 大規模言語モデルの訓練コーパスの単語数の変化
4.1 モデルの大規模化とその効果 パラメータが大きくなることでモデルの規模が大きくなっていく モデルの規模を大きくすることで性能が比例して改善していくという経験的な法則が存 在する(スケール則)
4.1 モデルの大規模化とその効果 大規模言語モデルの規模を測る方法 - パラメータ数 - コーパスの容量 - 訓練時に使われた計算量 -
FLOPS - 訓練に必要な計算のほとんどは浮動小数点数の演算であるため、浮動小数点数の回数を 表す指標を使用
4.1 モデルの大規模化とその効果 Transformerを用いた大規模言語モデルでのFLOPS FLOPS ≒ 6・パラメータ数・トークン数 - 大規模言語モデルを訓練する際には計算資源の確保が必要 - 効率よく性能の高いモデルを訓練できるように比較的小規模なモデルの性能から
予測を行う研究が行われている
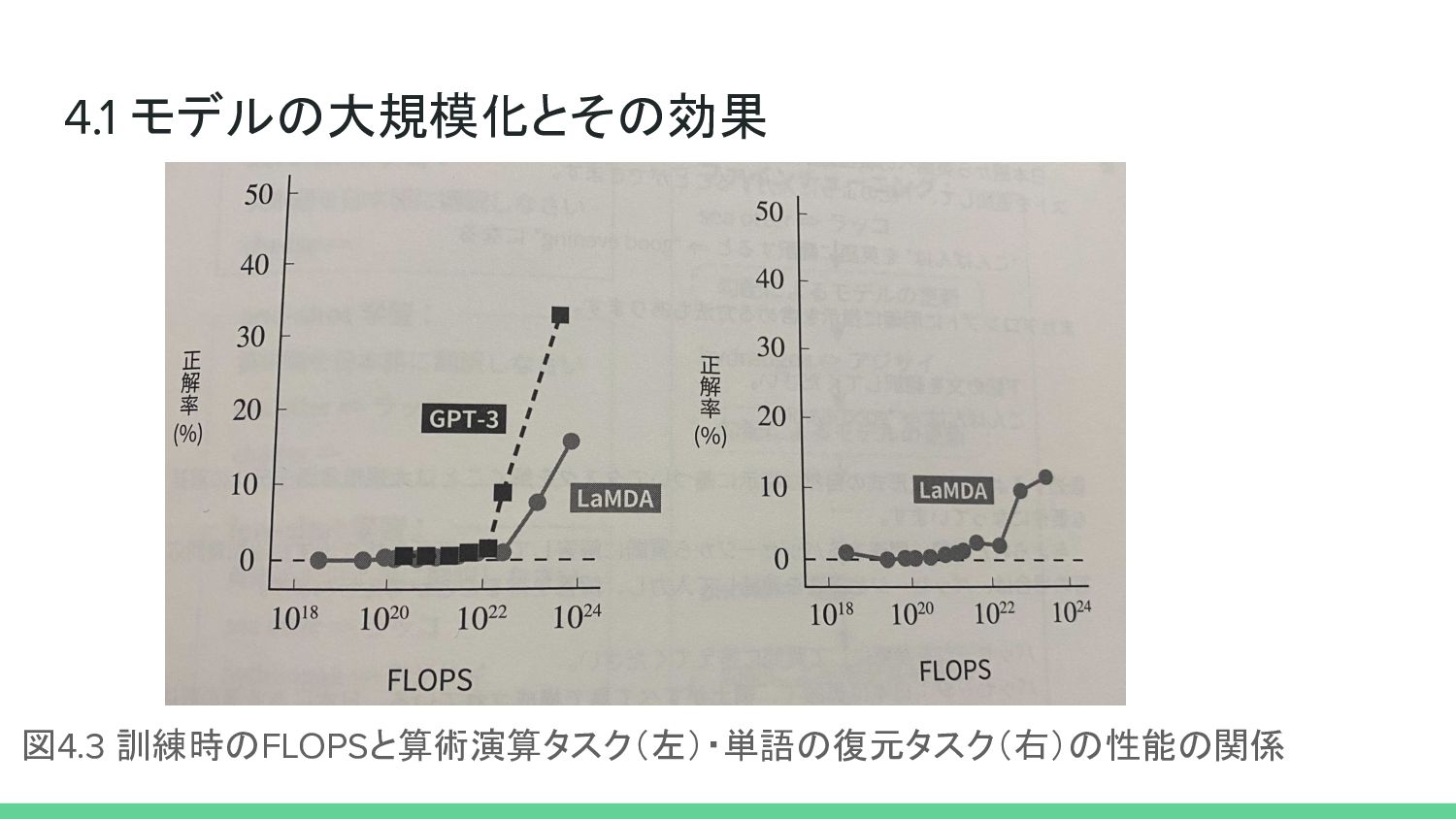
4.1 モデルの大規模化とその効果 図4.3 訓練時のFLOPSと算術演算タスク(左)・単語の復元タスク(右)の性能の関係
4.2 プロンプトによる言語モデルの制御 - モデルの大規模化によって従来はファインチューニングが必要であったタスクがプ ロンプトを調整することで解けるようになってきている - プロンプトの与え方が重要 - 普通に与えるパターン -
日本の首都は → 東京である - 機械翻訳 - “こんばんは”を英語に翻訳すると → ”good evening”になる - 明確に指示を含める方法 - 下記の文を翻訳してください。こんばんは → ”good evening”
4.2.1 文脈内学習 - プロンプトを使ってタスクを解く際の有用な方法のひとつとして「例示を与える」方法 がある - 1つ与える:one-shot学習 - 複数与える:few-shot学習(文脈内学習) -
何も与えない:zero-shot学習 - 例示を与える方法は例を与えるという意味ではファインチューニングに似た考え方 だがパラメータを更新しないという点が異なる
4.2.1 文脈内学習 図4.4 zero-shot、one-shot、few-shot学習とファインチューニングの比較
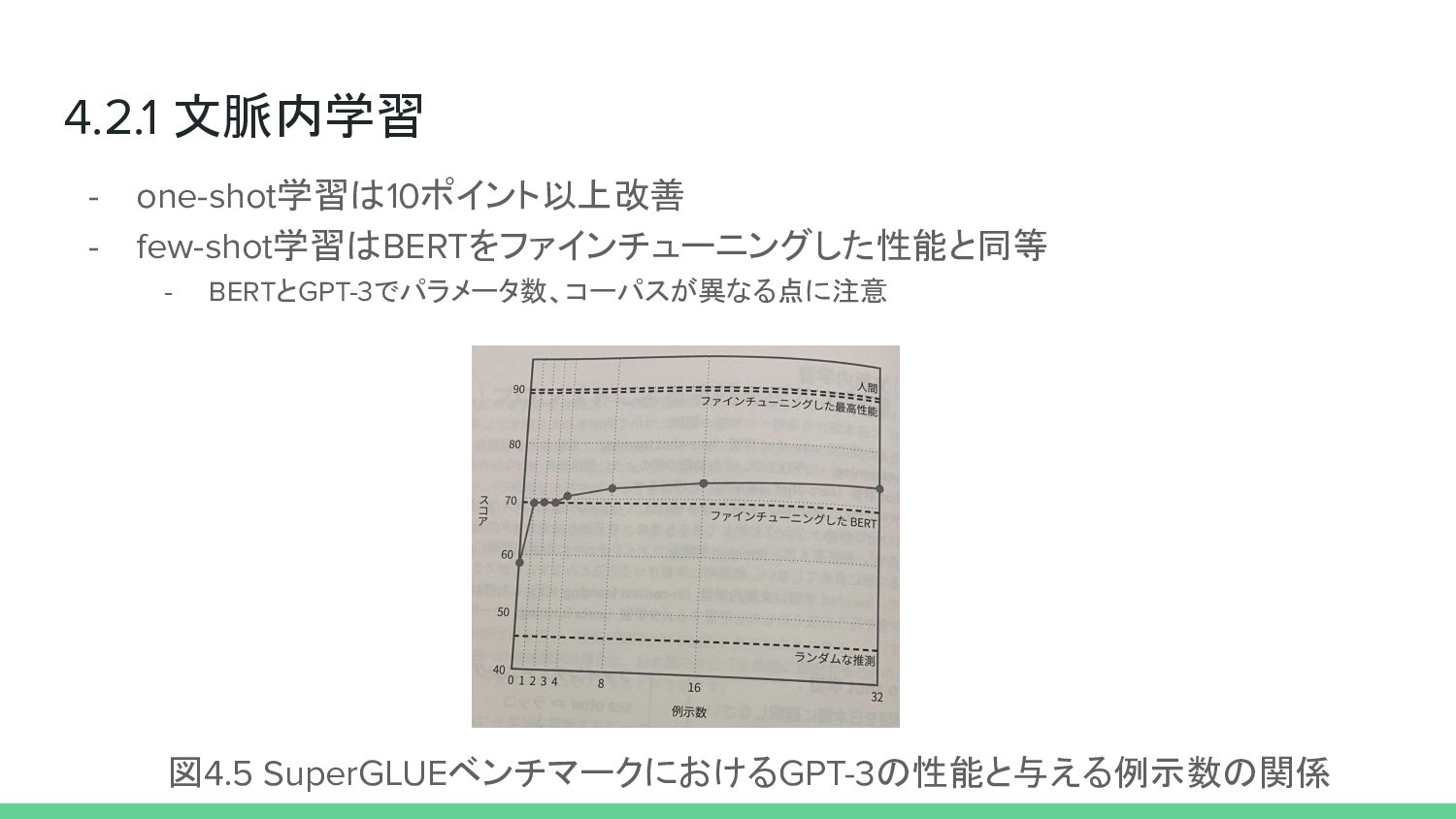
4.2.1 文脈内学習 - one-shot学習は10ポイント以上改善 - few-shot学習はBERTをファインチューニングした性能と同等 - BERTとGPT-3でパラメータ数、コーパスが異なる点に注意 図4.5 SuperGLUEベンチマークにおけるGPT-3の性能と与える例示数の関係
4.2.2 chain-of-thought 推論 マルチステップ推論 - 大規模言語モデルが苦手とされるタスクのひとつは多段階の推論が必要となるも の 例)部屋に23個のりんごがありました。料理に20個を使い、6個を買い足したとき、何個 のりんごが残りますか? 推論過程の例示を与えるChain-of-thought推論を用いると性能が改善する
4.3 アライメントの必要性 - モデルの予測結果などが人間や社会にとって理想的な挙動と一致するわけではな い - 人間や社会にとって有益で適切な挙動になるようにモデルを調整することをアライ メントと呼ぶ - 大規模現モデルの開発者による論文で3つの基準を提案
- 役に立つこと(helpful) - 正直であること(honest) - 無害であること(harmless)
4.3.1 役立つこと - 大規模言語モデルは人間にとって役に立つ必要がある - モデルは人間の指示に従うだけでなく、意図も推測する必要がある - 「6歳児に月面着陸についていくつかの文で説明する。」というプロンプト - GPT-3は類似の文を生成してしまう
- GPT-3を改善したInstructGPTでは改善されている
4.3.2 正直であること - 大規模言語モデルは虚偽の内容を生成することがある - 虚偽の生成を行う性質を幻覚(hallucination)と呼ぶ 図4.11 ChatGPTによる虚偽の内容の生成の例
4.3.3 無害であること - 大規模言語モデルの訓練コーパスはウェブから収集されたデータを用いていてい るため多くの有害な情報が含まれている - 初期のGPT-4モデルでは爆弾の生成方法を答えてしまっていた - 訓練コーパスに含まれているバイアスをそのまま反映してしまう
4.3.4 主観的な意見の扱い - 大規模言語モデルの重要な課題のひとつとして主観的な意見の扱いがある - 事前コーパスに含まれる意見の傾向を学習すると特定の属性をもつ集団への意見 のバイアスをもつことになる
4.4 指示チューニング 指示チューニング(instruction tuning) - 指示を含んだプロンプトと理想的な出力テキストの組で構成されるデータセットを 使ったファインチューニングによって大規模言語モデルのアライメントを行う方法
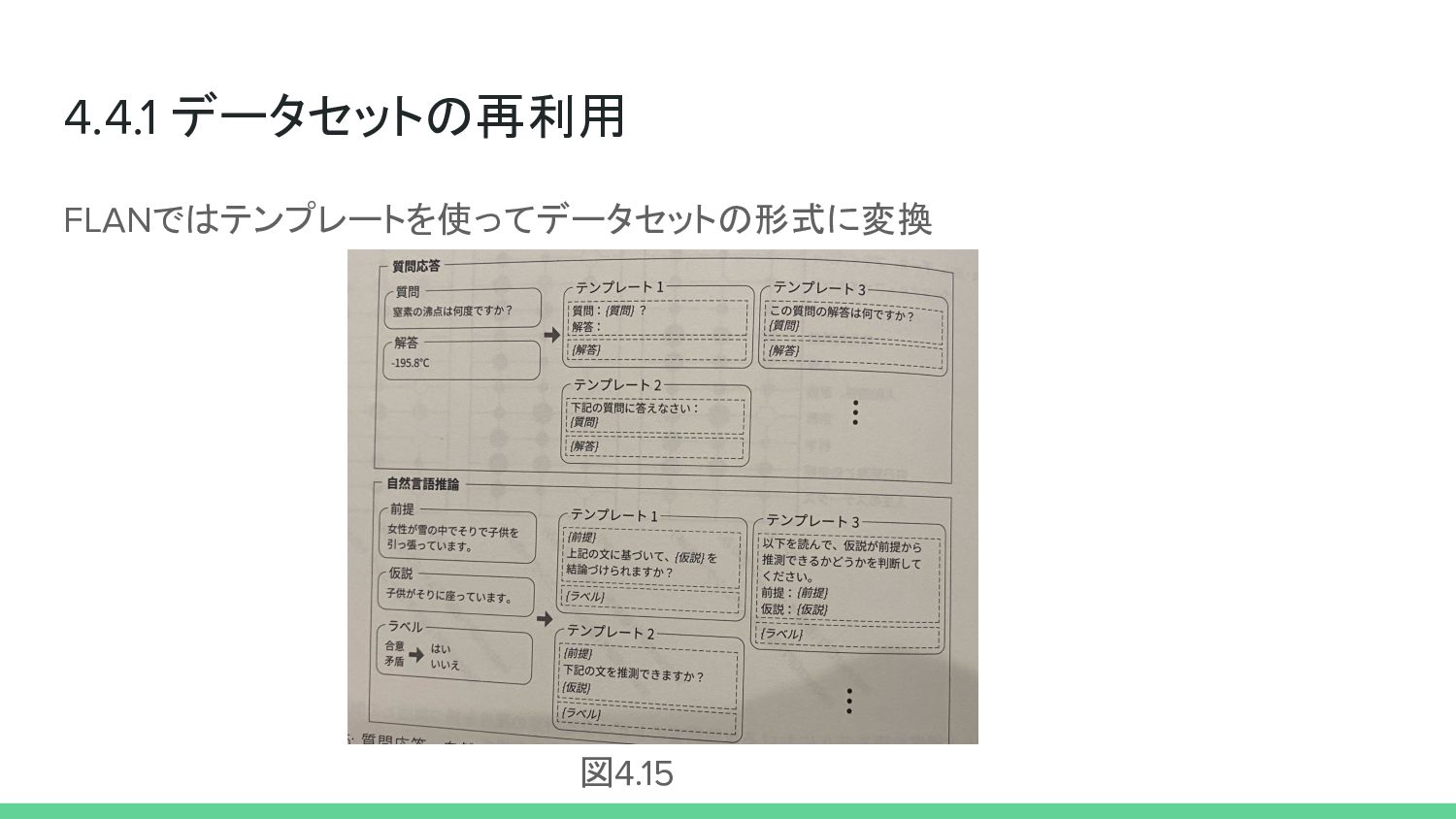
4.4.1 データセットの再利用 - 2021年にGoogleが提案したFLAN(Finetuned LAnguage Net) - GPT-3と同等規模の1370億パラメータの大規模言語モデルを62個のデータセットを 集約してファインチューニングをした結果、多数のタスクにおけるzero-shot学習の 性能がGPT-3を上回った
4.4.1 データセットの再利用 FLANではテンプレートを使ってデータセットの形式に変換 図4.15
4.4.1 データセットの再利用 - FLANと同様の方法でNatural Instructions、Super-Natural Instruction、P3 (Public Pool of Prompts)などの大規模なデータセットが構築されている
- これらのデータセットを連結して新しい大規模データセットを作成し、モデルを訓練 する試みも行われている
4.4.2 人手でデータセットを作成 - OpenAIが2022年に発表したInstructGPTはGPT-3に対して指示チューニングと強 化学習のふたつを適用してモデルを構築 - 指示チューニングでは人手で作成されたプロンプトおよび初期のInstructGPTのAPI に対して送られてきたプロンプトに対して人手で理想的な出力を付与した15,000件 程度のデータセットを作成
4.4.3 指示チューニングの問題 - 指示チューニングは単純で効果的ではあるが問題もある 1. 大規模で高品質なデータセットを作成することが難しい - 人手で大規模・高品質なデータセットを構築するのは人的コストがかかる 2. モデルの出力に対してフィードバックを行えない
- 理想的な答えを正解として与える必要があるためフィードバックを行えない - 正解が多数あることがあり定義できない
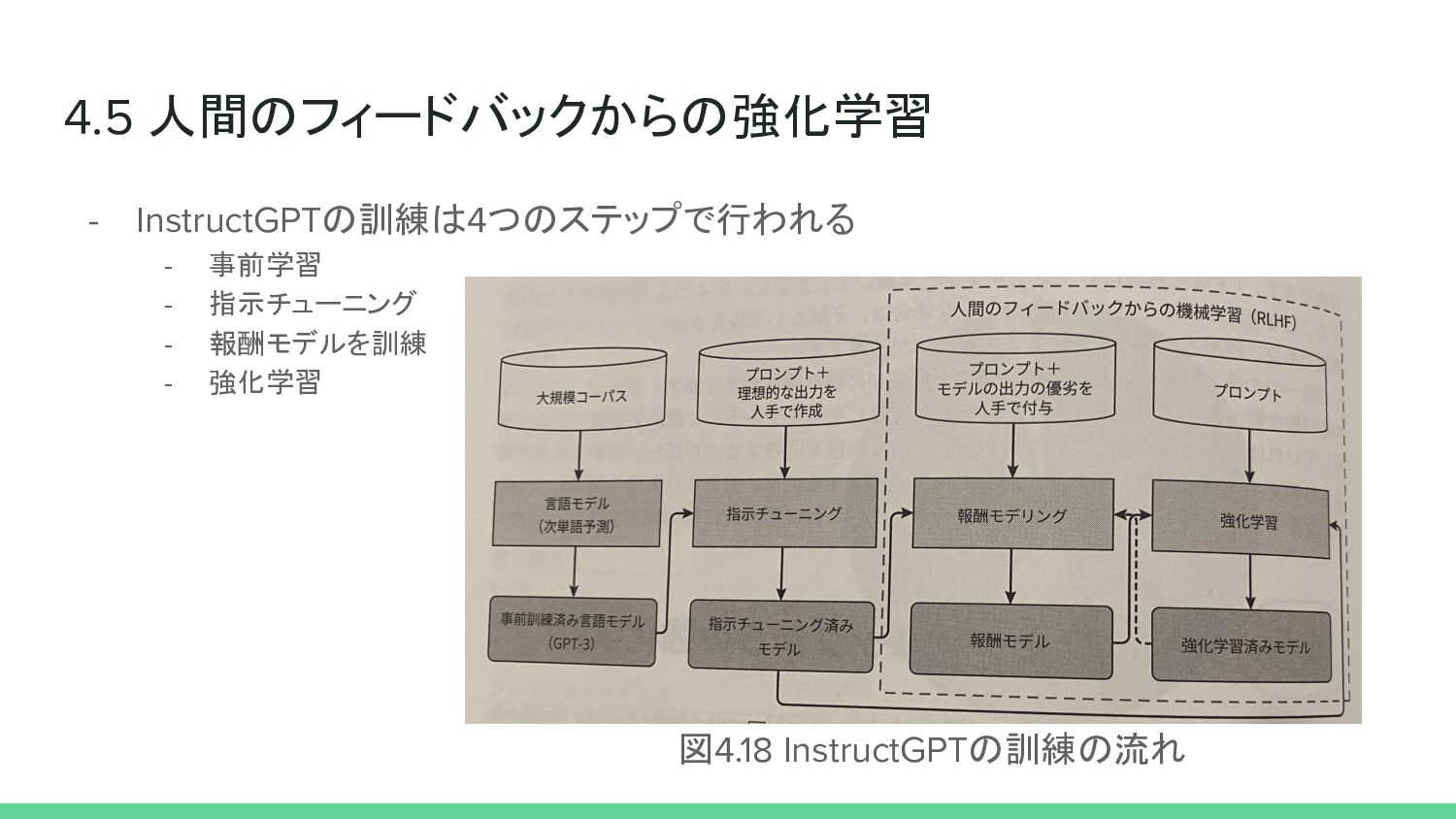
4.5 人間のフィードバックからの強化学習 - InstructGPTの訓練は4つのステップで行われる - 事前学習 - 指示チューニング - 報酬モデルを訓練
- 強化学習 図4.18 InstructGPTの訓練の流れ
4.5 人間のフィードバックからの強化学習 - 報酬モデル - 指示チューニング済みモデルが実際に生成したテキストに対して人間の好みを反映した報酬をスカ ラー値で付与 - この報酬を最大化するように指示チューニング済みモデルのファインチューニング -
強化学習 - 報酬を最大化するように指示チューニング済みモデルをファインチューニング
4.5.1 報酬モデリング 報酬モデリング - 生成されたテキストに対して報酬を予測するモデルを学習するステップ 手順 - プロンプトとテキストの組に対して人手で優劣のラベルを付与したデータセットを構 築 -
任意のプロンプトとテキストに対して報酬をスカラー値で予測する報酬モデルを学 習
4.5.1 報酬モデリング - A, B, Cが存在し、C, A, Bの順で好ましいとした場合 - C
< A、C < B、A < Bを生成 - 訓練時は上位のテキストと下位のテキストのスコア差を最大化する 損失関数 - 好ましいテキストの場合には高いスコア - そうでない場合には低いスコア
4.5.2 強化学習 強化学習 - エージェントが環境の中で試行錯誤しながら学習を行う - 現在の状態から報酬を最大化するような行動を選択するエージェントの方策を求め る問題を扱う 状態:プロンプトおよび作成済みのテキスト 行動:語彙からのトークンの選択
方策:モデルを出力するトークンの確率分布 報酬:生成されたテキストを入力した際の報酬モデルの出力
4.5.2 強化学習 エージェントは与えられたプロンプトに対して方策をもとにした行動(トークンの生成)と状 態の更新(テキストへのトークンの追加)を繰り返す 生成が完了した段階で報酬モデルによって報酬が計算され、エージェントに渡される RLHFの目的は報酬を最大化する方策のパラメータφを求めること →プロンプトxに対して生成したテキストyの報酬の期待値を最大化するパラメータを求め る問題
4.5.2 強化学習 最適化問題を解くのに強化学習が使用される 指示チューニング済みモデルのファインチューニングを行う際、指示チューニング済みモ デルのパラメータを更新しすぎると事前学習や指示チューニングで学習した内容を忘れ て報酬を得ることに特化したモデルが学習されてしまう → 防ぐために報酬には報酬モデルに加えて元々の指示チューニング済みモデルと大き く異なる出力をしないようにの正則化項を導入
4.5.2 強化学習 報酬 第1項:報酬モデリング 第2項:各トークンに対して方策が低い確率を与えるほど報酬が増え(偏りを減らすこと ができる) 第3項:指示チューニング済みモデルが出力yに含まれる各トークンに対して低い確率 を与えるほど報酬が減る
4.5.3 REINFORCE REINFORCE(またはモンテカルロ方策勾配法) - 強化学習の手法のひとつ - 詳細な数式は割愛 - 報酬が勾配によって大きさ・方向を更新する -
これによって報酬が大きいテキストが生成されやすくなる
4.5.4 指示チューニングと RLHF - テキストの優劣を判断することはテキスト生成よりもはるかに手間が少ないため データセットの作成にかかる人的コストが大きく削減される - RLHFではモデルの出力に対して直接フィードバックができる - 指示チューニングと比較をしてRLHFの学習の難易度は非常に高い
4.6 ChatGPT - ChatGPTはInstructGPTと同様に指示チューニングとRLHFを組み合わせた方法で 学習されており、学習にあたって対話形式に対応するためにデータセットが新しく追 加されている - 指示チューニングのデータセットとしてユーザとモデルの模擬的な会話データセット を人手で作成し、InstructGPTで用いたデータセットと結合をし指示チューニングを 実施
- 報酬モデルを訓練するために人間とモデルとの会話のデータセットを構築 - 報酬モデルのデータセット構築・訓練と強化学習を組み合わせて学習 9章でChatGPTを用いた質問応答システムについて紹介
さいごに 次回2/26(月)実施!担当小林さん オンライン・オフライン開催します!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}