Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
E2E自動運転の実現に向けたMLOpsの取り組み
Search
Masahiro Yasumoto
November 20, 2024
8.5k
0
Share
E2E自動運転の実現に向けたMLOpsの取り組み
第11回 Data-Centric AI勉強会 資料
https://dcai-jp.connpass.com/event/334367/
Masahiro Yasumoto
November 20, 2024
Featured
See All Featured
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.7k
Odyssey Design
rkendrick25
PRO
2
610
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
910
Side Projects
sachag
455
43k
BBQ
matthewcrist
89
10k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Become a Pro
speakerdeck
PRO
31
5.9k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Balancing Empowerment & Direction
lara
6
1.1k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
740
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
190
Transcript
E2E⾃動運転の実現に向けた MLOpsの取り組み Turing株式会社 安本 雅啓 第11回 Data-Centric AI勉強会
• 安本 雅啓 • 所属 ◦ チューリング株式会社(2024/05〜) ◦ E2E⾃動運転チーム SWE
• 経歴 ◦ メーカー研究所、AIスタートアップ (Araya)でのML開発、SaaSのbackend 開発(atama plus, Treasure Data)を経験 ⾃⼰紹介
• E2E⾃動運転実現に向けたData Centric AIの実践において、これま でに直⾯してきた課題と、それに対してどう対処してきたか。 ◦ 【E2E連載企画 第5回】20TB/dayのデータ処理を⽀えるデータ エンジンの全貌 •
また、時間の経過に伴い、別の問題も発⽣してきているので、そ れも紹介する。 今⽇話すこと
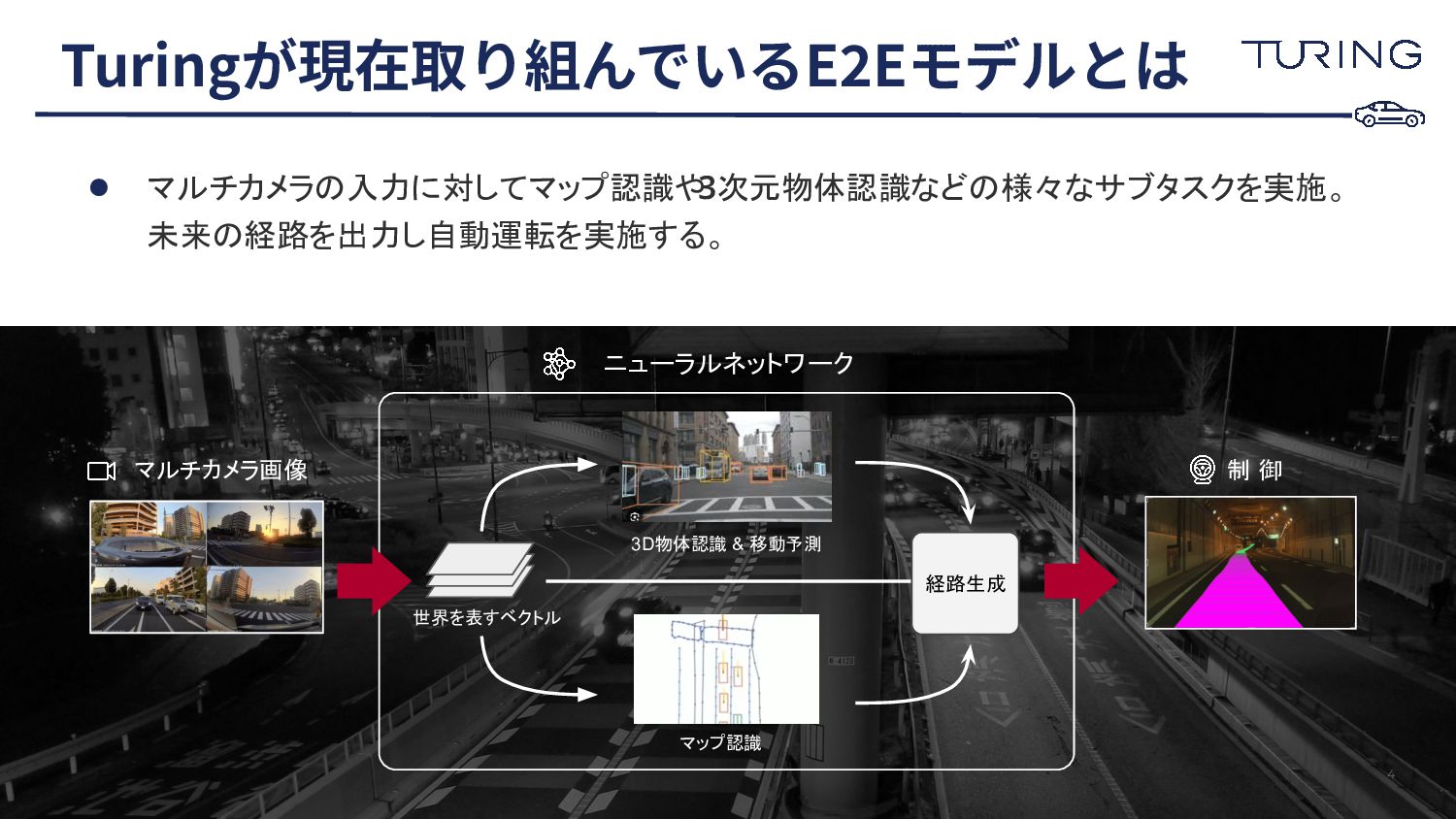
• マルチカメラの入力に対してマップ認識や 3次元物体認識などの様々なサブタスクを実施。 未来の経路を出力し自動運転を実施する。 Turingが現在取り組んでいるE2Eモデルとは 4 ニューラルネットワーク 3D物体認識 &
移動予測 マップ認識 世界を表すベクトル 経路生成 マルチカメラ画像 制 御
• End to Endモデルの学習には、「良い」データが必要。 E2Eモデルの学習には良いデータが必要 • 最近のモデル(特にTransformerベース)はData hungry。 • マルチモーダル特有の課題(センサ間の位置関係の精度)
• センサーデータ特有の課題(ノイズ、キャリブレーション) • Imitation Learningの課題(エキスパートデータの質) • 様々な交通条件のデータが必要(場所、天候、交通エージェン トの有無)。エッジケースのデータが重要。 量 質 多様 性
• ⼤量の収集データの中から、⾼品質かつ多様性に富むデータのみ を抽出してデータセットを作成。 E2Eモデルのデータパイプライン • 品質 • 右左折・直進の割合 • 天候の割合
• 走行エリアのカバレージ 収集データ データセット
1. ⼤容量のデータ
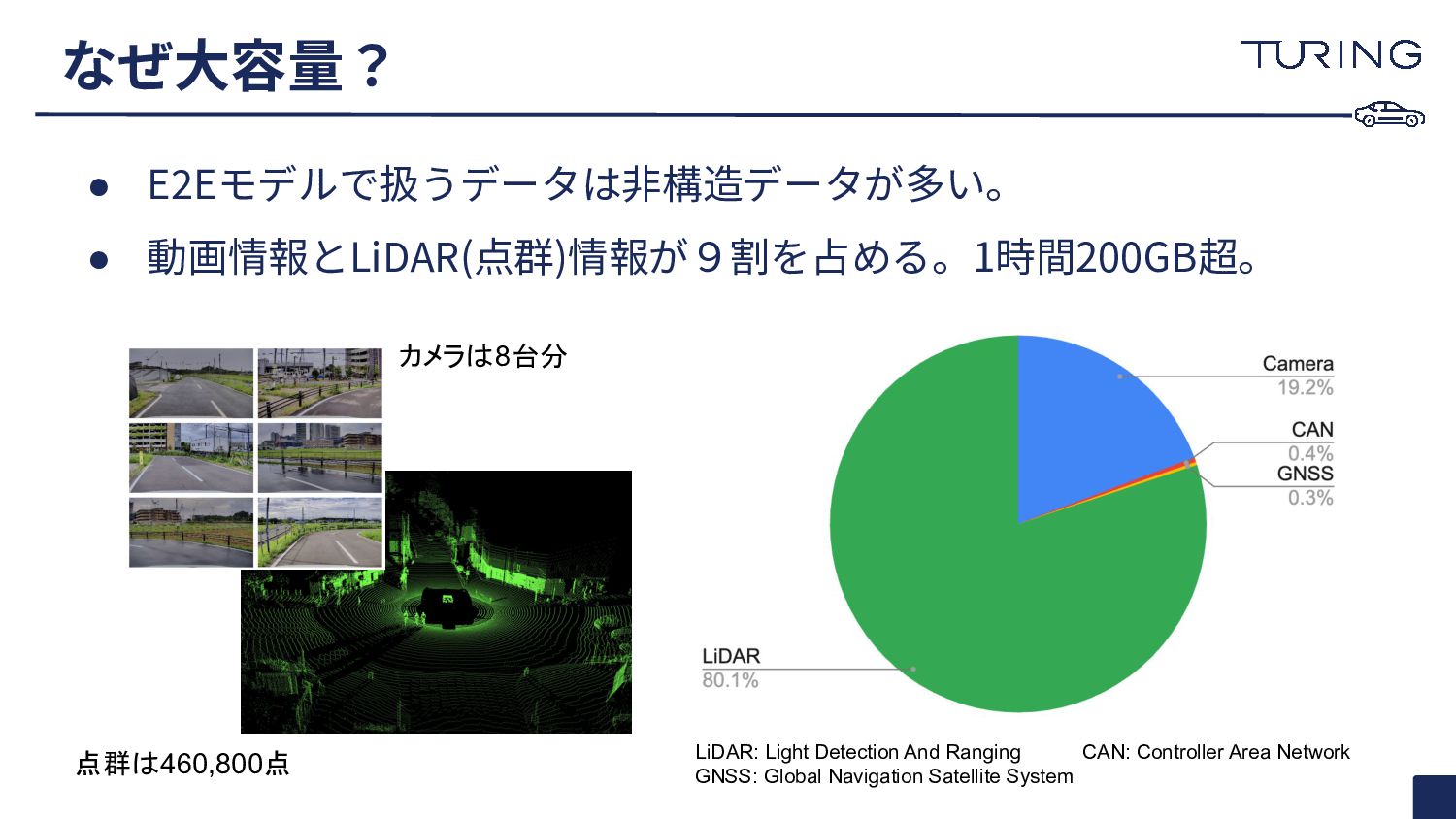
• E2Eモデルで扱うデータは⾮構造データが多い。 • 動画情報とLiDAR(点群)情報が9割を占める。1時間200GB超。 なぜ⼤容量? カメラは8台分 点群は460,800点 LiDAR: Light Detection
And Ranging CAN: Controller Area Network GNSS: Global Navigation Satellite System
• ストレージのコスト ◦ ⽣データは仕⽅ないが、加⼯済データを持つニーズがある。 ▪ 動画 → 画像→ 歪み補正済みの画像 ▪
CANのエンコードされたデータ → デコード済みデータ • アノテーションのコスト ◦ 3次元物体認識のサブタスクの学習には、教師ラベルが必要だが、⼈ ⼿でのアノテーションはコストが⾼く、全てのシーンに対して付与す ることは困難。 ⼤容量データを扱う上で直⾯する課題
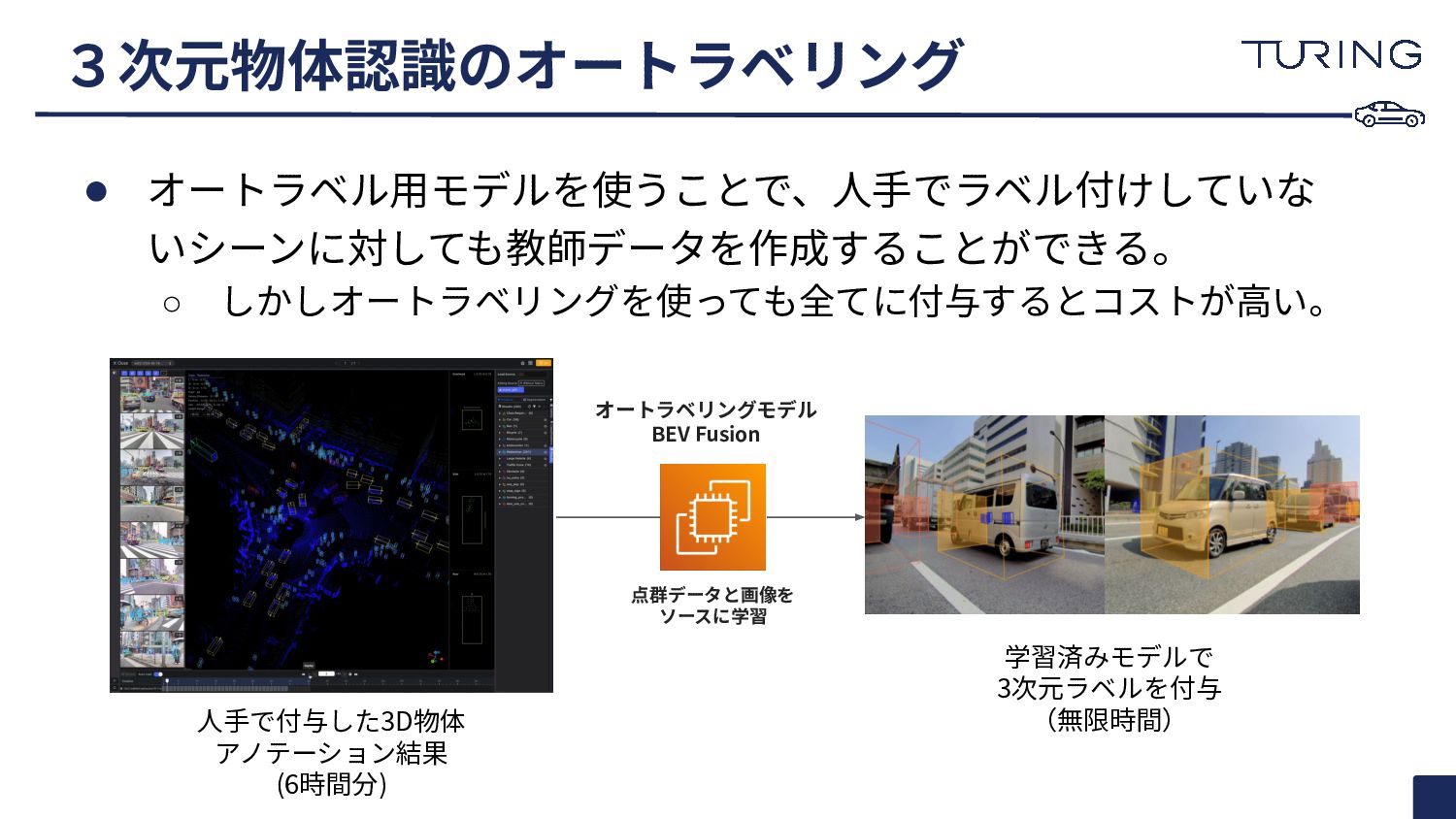
• オートラベル⽤モデルを使うことで、⼈⼿でラベル付けしていな いシーンに対しても教師データを作成することができる。 ◦ しかしオートラベリングを使っても全てに付与するとコストが⾼い。 3次元物体認識のオートラベリング ⼈⼿で付与した3D物体 アノテーション結果 (6時間分) 点群データと画像を
ソースに学習 学習済みモデルで 3次元ラベルを付与 (無限時間) オートラベリングモデル BEV Fusion
• 基本的に⽣のデータはそのままで保持。必要に応じて変換。 ◦ →ただしそうすると、必要な場⾯にすぐにデータが⼿に⼊らな いという別の課題が⽣まれる。 😞 • データ取得に時間がかかるという課題に対しては、クラウド上の 分散処理を活⽤するというパワープレイにより、リクエストが あってから短いリードタイムでデータを準備。
💪 オンデマンドに加⼯する
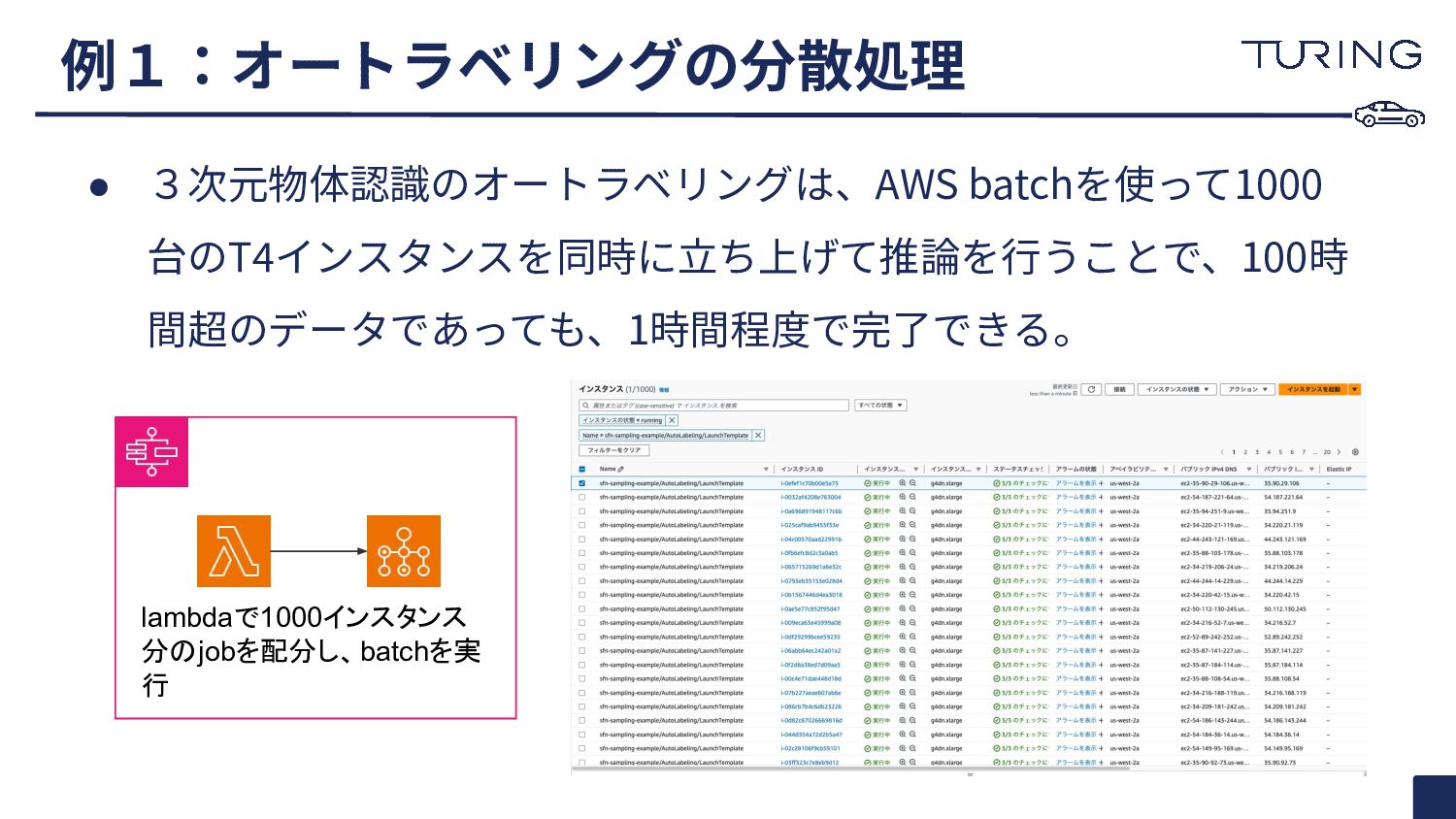
• 3次元物体認識のオートラベリングは、AWS batchを使って1000 台のT4インスタンスを同時に⽴ち上げて推論を⾏うことで、100時 間超のデータであっても、1時間程度で完了できる。 例1:オートラベリングの分散処理 lambdaで1000インスタンス 分のjobを配分し、batchを実 行
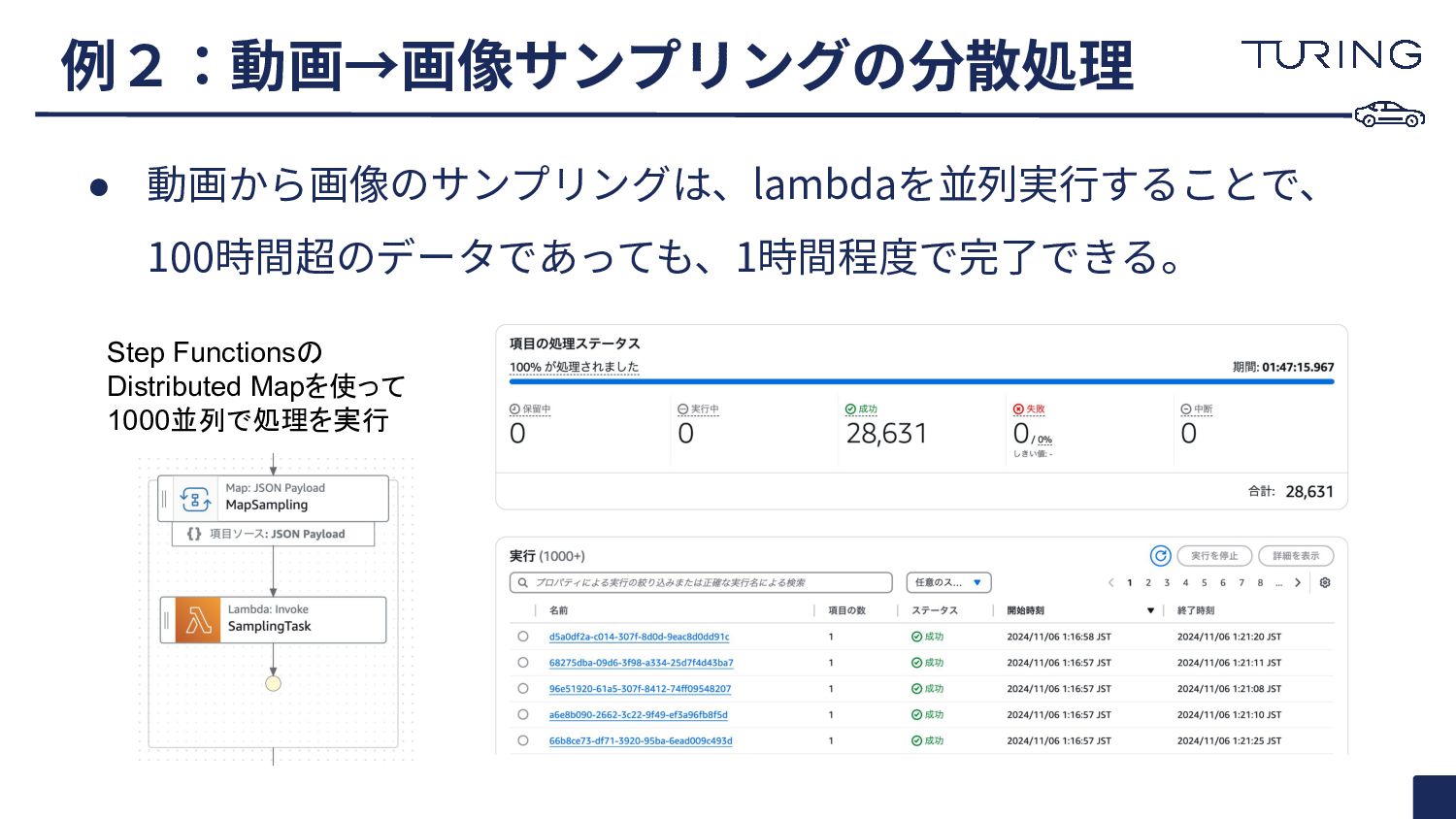
• 動画から画像のサンプリングは、lambdaを並列実⾏することで、 100時間超のデータであっても、1時間程度で完了できる。 例2:動画→画像サンプリングの分散処理 Step Functionsの Distributed Mapを使って 1000並列で処理を実行
• 最初は問題なくても、データセットのサイズが⼤きくなると、やは り計算コストや処理時間も無視できなくなってきた。 ◦ 1つのデータセットを作成するのに30万円かかる、など。 • そこで、必要性やユースケースが固まってきたデータは、あらかじ め加⼯した状態で保持するように。 ◦ 例1:動画→画像の切り出しは都度⾏うとコスト⾼なので、画像に切
り出したものを事前に⽤意しておく。 ◦ 例2:時間をキーに検索することが多いことが判明したデータは timestampをインデックスとしたテーブルに格納。 しかし、新たなる問題が発⽣
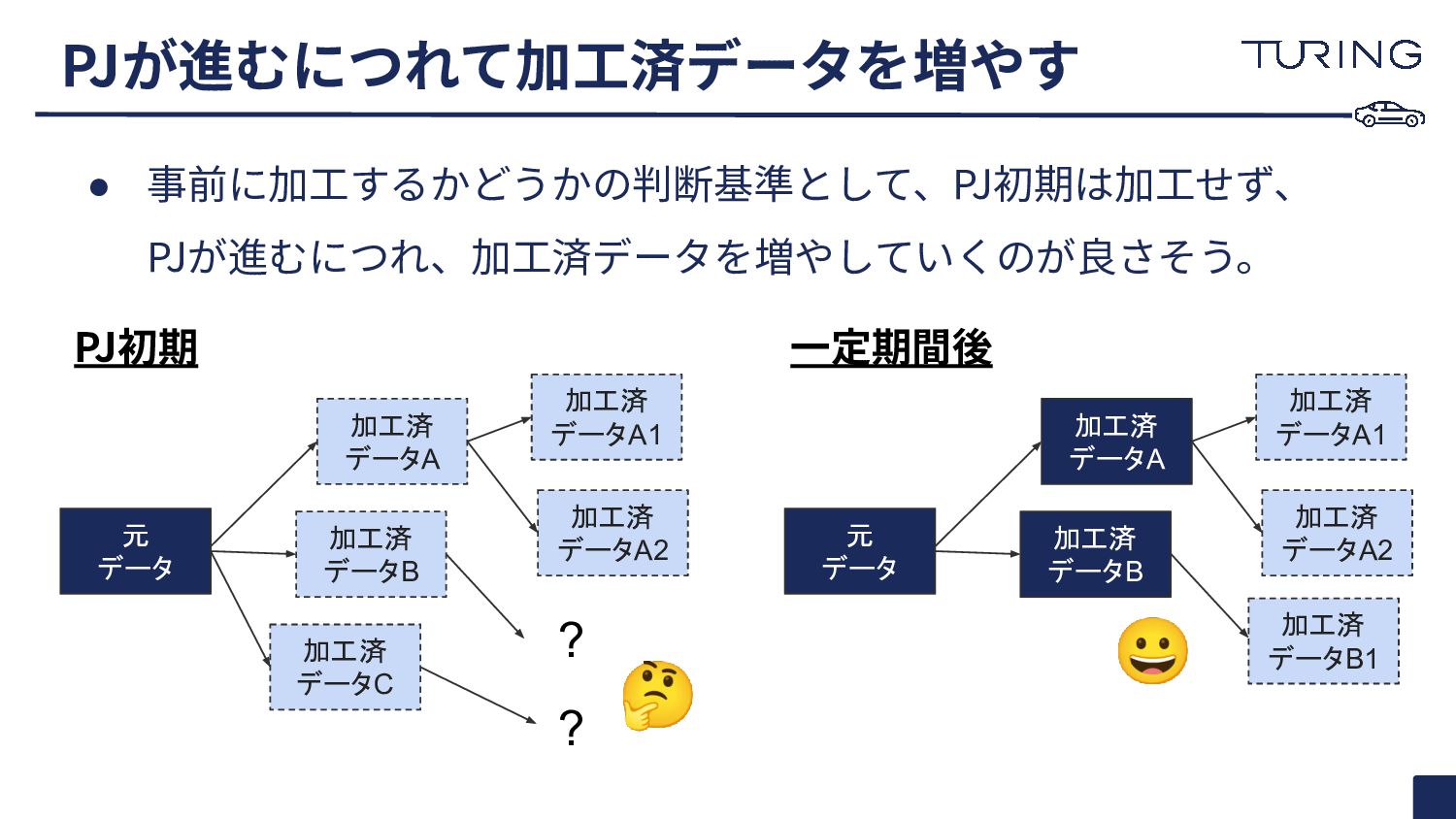
• 事前に加⼯するかどうかの判断基準として、PJ初期は加⼯せず、 PJが進むにつれ、加⼯済データを増やしていくのが良さそう。 PJが進むにつれて加⼯済データを増やす 元 データ 加工済 データA 加工済 データB
加工済 データC 加工済 データA1 加工済 データA2 ? ? 元 データ 加工済 データA 加工済 データB 加工済 データA1 加工済 データA2 加工済 データB1 PJ初期 ⼀定期間後 😀 🤔
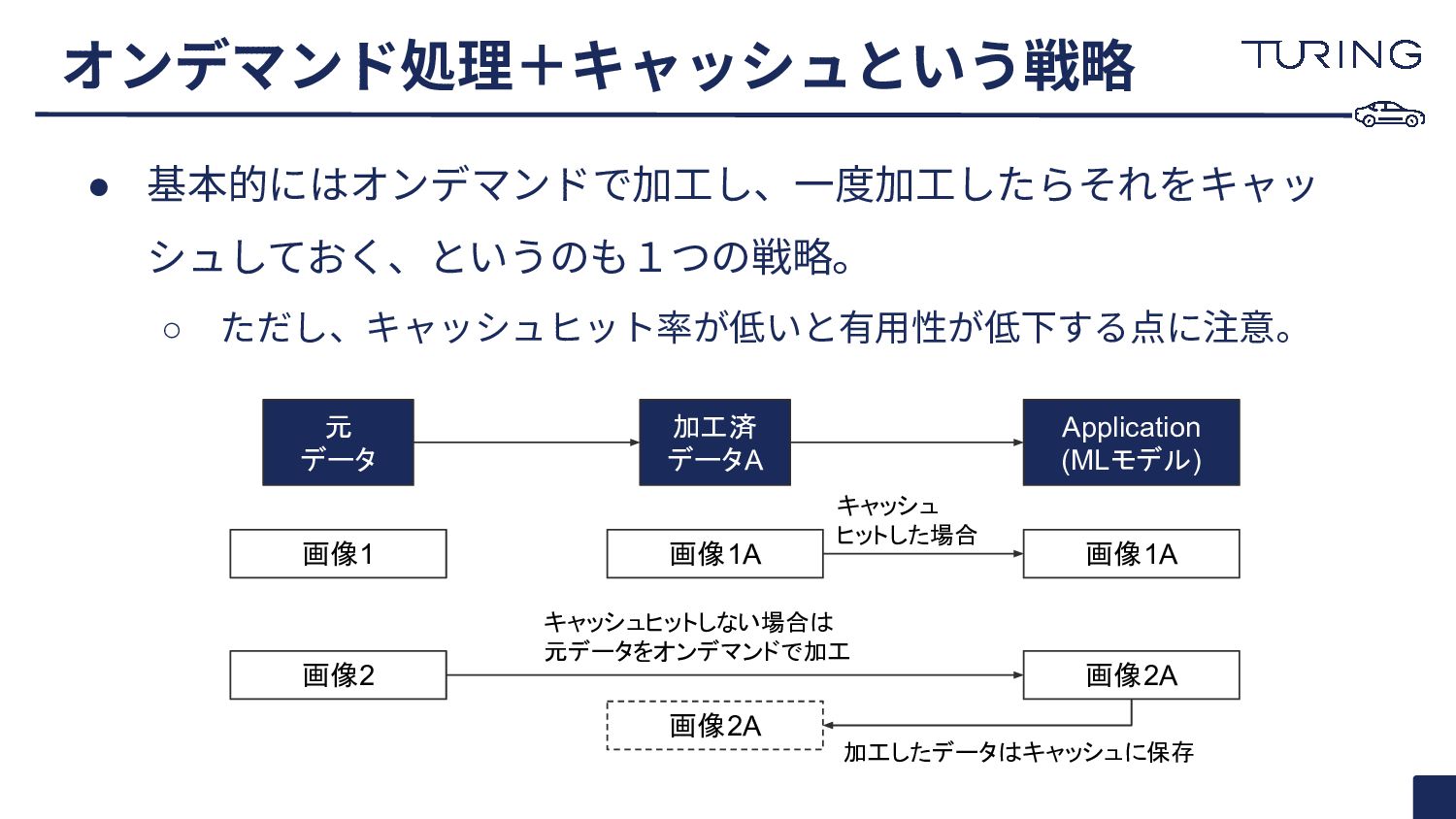
• 基本的にはオンデマンドで加⼯し、⼀度加⼯したらそれをキャッ シュしておく、というのも1つの戦略。 ◦ ただし、キャッシュヒット率が低いと有⽤性が低下する点に注意。 オンデマンド処理+キャッシュという戦略 元 データ 加工済 データA
画像1 画像2 Application (MLモデル) 画像1A 画像1A 画像2A 画像2A キャッシュ ヒットした場合 キャッシュヒットしない場合は 元データをオンデマンドで加工 加工したデータはキャッシュに保存
2. ⾼品質なデータ
• データの故障モードに対する知識が最初はほとんどなかった。 ◦ どのデータにどのようなエラーが発⽣するかは、実際にデータ の中⾝を⾒てみないとなかなか分からない。 • 実際に発⽣した問題: ◦ センサー間の時刻同期の問題(タイムスタンプのずれ) ◦
カメラ動画のコマ落ち ◦ GNSS受信機の位置情報の取得失敗 ◦ ファイルの破損 そもそも何が課題かが分からないのが課題
• 最初は、データをランダムにピックアップして、どのようなエ ラーが発⽣しているかを⾒ていった。 最初はみんなでデータを⾒る データバリデーション大会 (イメージ)
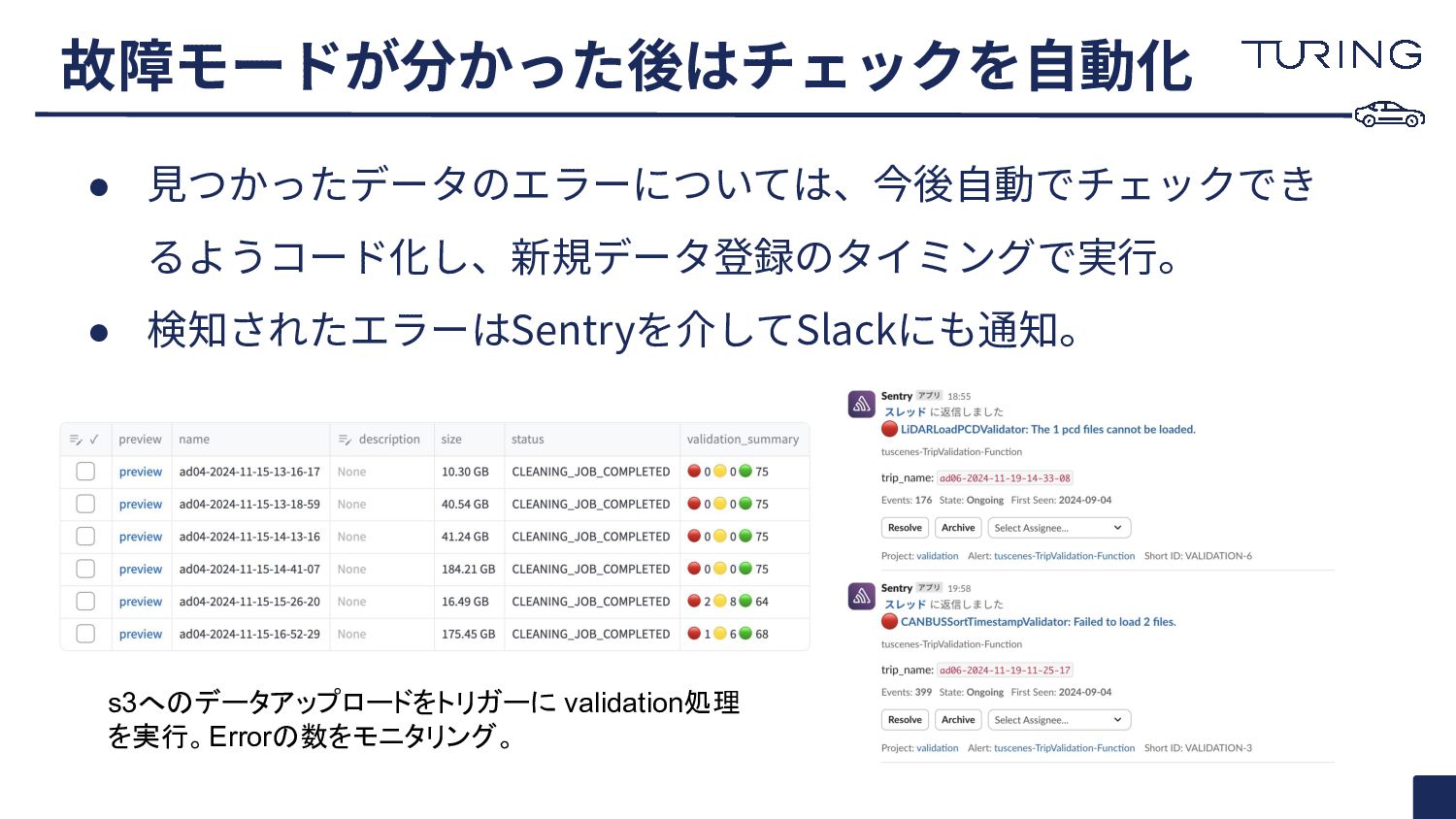
• ⾒つかったデータのエラーについては、今後⾃動でチェックでき るようコード化し、新規データ登録のタイミングで実⾏。 • 検知されたエラーはSentryを介してSlackにも通知。 故障モードが分かった後はチェックを⾃動化 s3へのデータアップロードをトリガーに validation処理 を実行。Errorの数をモニタリング。
• 画像の質については、コードでは把握が難しい(専⽤のMLモデル を作ったりする必要有)。そこで、gpt-4o miniを使って、ノイズ の有無を判定してもらうことに。 画像の質のチェックにはgpt-4oも活⽤ gpt-4o miniによってノイズが大きいと判定されたシーン(抜粋)
• 残っている問題 ◦ エキスパートデータとしての品質の改善 ◦ 位置情報の取得に失敗しているデータの改善 • データの品質の劣化は気づくのが難しい。結局は地道な⼈⼿作業 が重要と感じている。 ◦
→この⼈⼿作業を効率化するための可視化環境を準備しておく ことは⼤切。 それでもまだ問題は⼭積み
⼈⼿での確認を効率化する可視化ツール Streamlitを使って作成したwebベー スの可視化ツール Rerun (embodied AI向けのオー プンソースなツール) https://rerun.io/viewer
3. 多様性のあるデータ
• (1)多様性が確保できるようデータを取得、(2)取得したデータから 多様性に富むようデータを検索‧抽出、の2側⾯あり、両⽅⼤切。 • 場所や、右左折‧直進などの多様性は(1)で確保できるが、救急⾞ 両が出現するシーンなどは意図して取れず、むしろ(2)が重要。 • 今回は(2)について紹介。 多様性を確保するための取り組み
• どのような観点で多様性を確保すべきかは、実験をしないとなか なか分からない。 ◦ 天候、右折‧左折‧直進の割合、時間帯、季節 ◦ ⾃⾞が先頭⾞両かどうか、周辺の交通エージェントの状況、信 号機の現⽰、など • よって、どのようなキーでシーンを検索するかを事前に完全に把握
しておくことは難しい。 検索に使うキーは最初は分からない
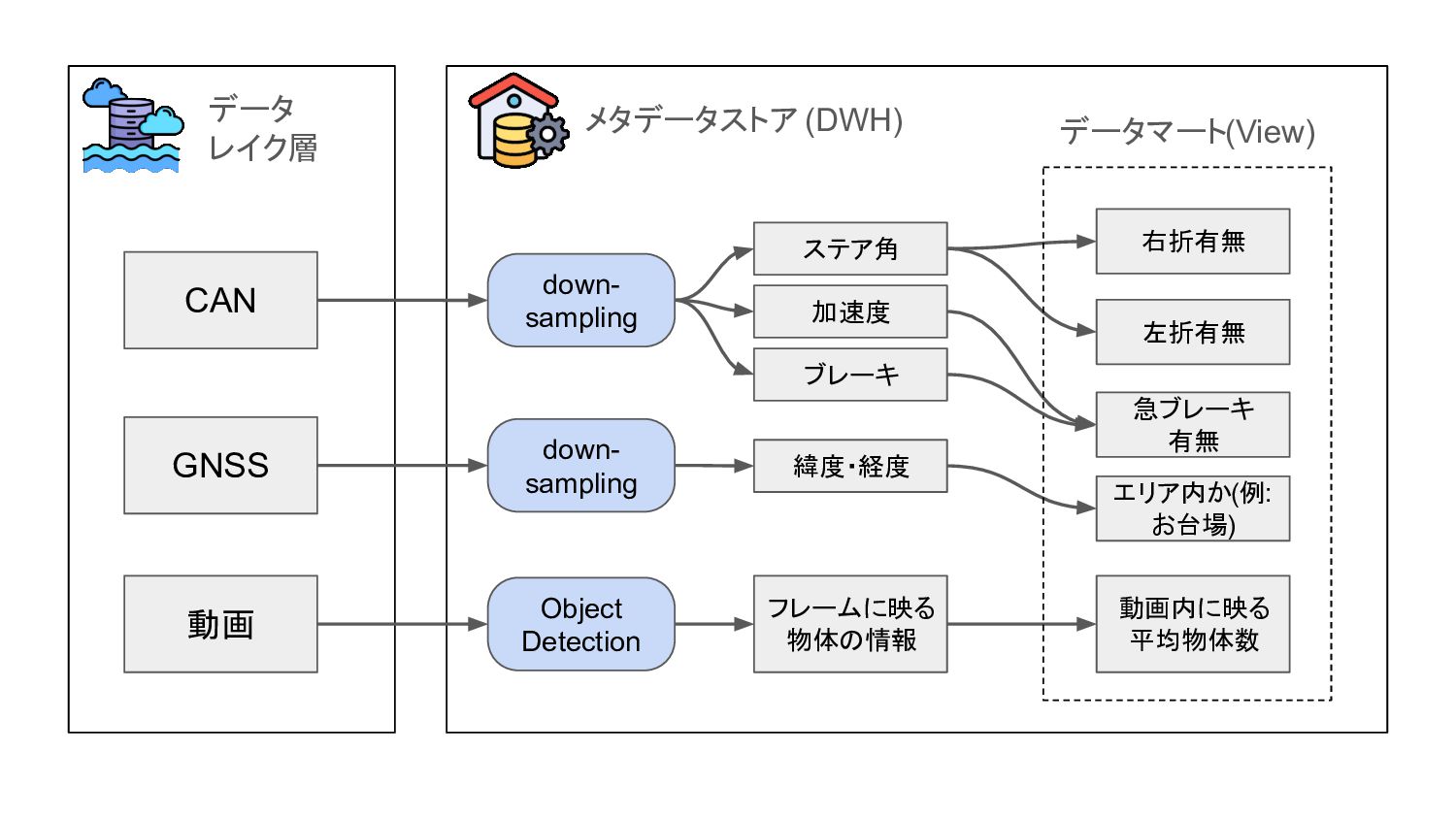
• 様々なキーでクエリする可能性がある、基本的にデータは追記だ けで更新はほぼない、という要件から、DWHを採⽤し、ここに シーンのメタデータを格納。 • センサデータは加⼯前の状態で保持し(必要に応じてダウンサン プリングする)、必要な特徴量はクエリ上のロジックで都度計算 するように設計。 データ検索のインフラとしてDWHを採⽤
データ レイク層 メタデータストア (DWH) CAN GNSS 動画 down- sampling down-
sampling Object Detection ステア角 緯度・経度 フレームに映る 物体の情報 動画内に映る 平均物体数 右折有無 左折有無 急ブレーキ 有無 エリア内か(例: お台場) データマート(View) 加速度 ブレーキ
• Open vocabularyなモデル(YOLO World)を使い、利⽤可能性が⾼ いと予想されるラベリングを事前に⾏っておく(例: ⼈、⾞など)。 • クラス名をカラムとするスキーマ設計により、スキーマを変更せ ずに新しいクラスの追加が可能。 Open
vocabulary モデルでラベリング Pivot tableとしてのView
YOLO Worldによる検出例
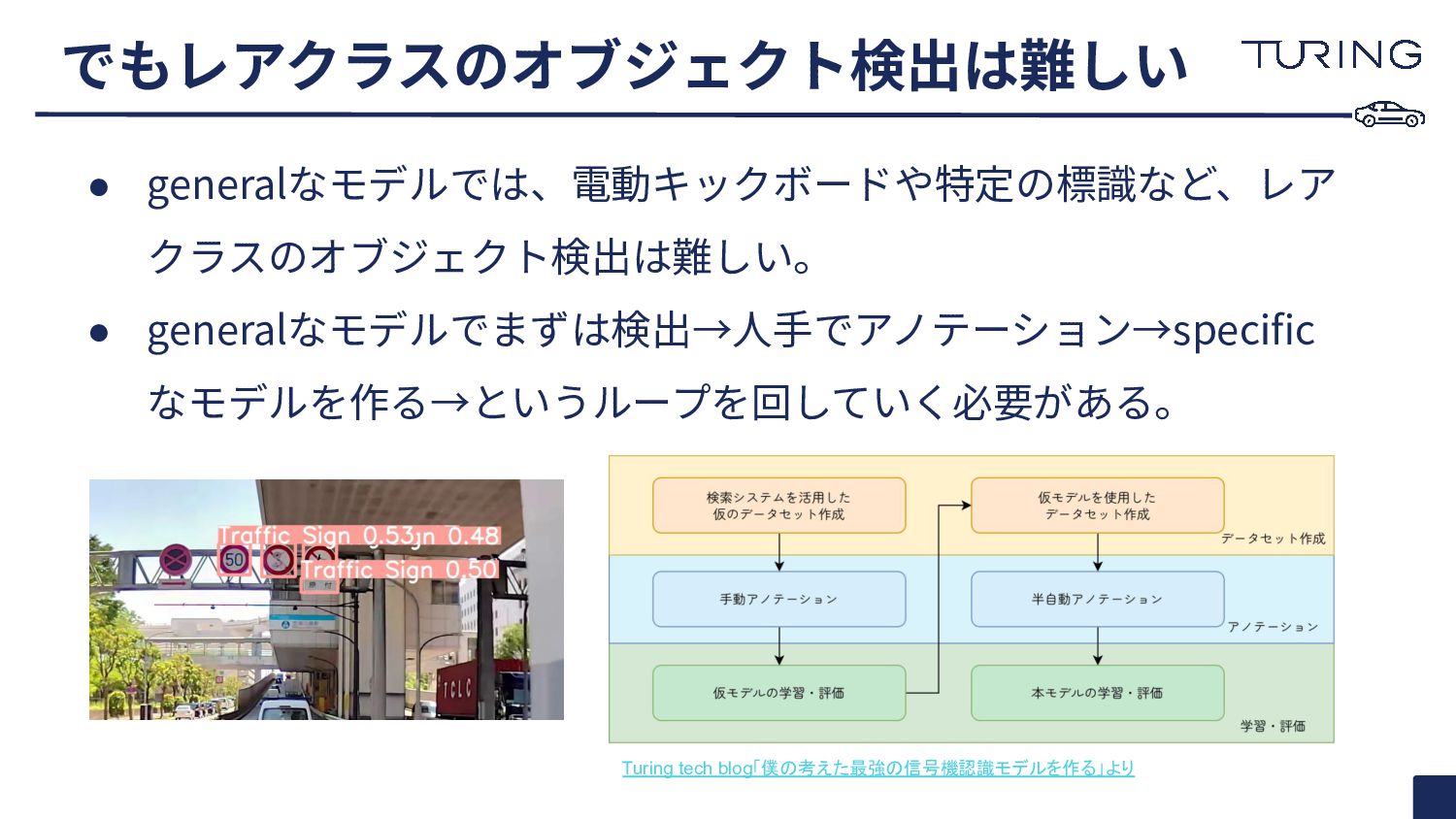
• generalなモデルでは、電動キックボードや特定の標識など、レア クラスのオブジェクト検出は難しい。 • generalなモデルでまずは検出→⼈⼿でアノテーション→specific なモデルを作る→というループを回していく必要がある。 でもレアクラスのオブジェクト検出は難しい Turing tech blog「僕の考えた最強の信号機認識モデルを作る」より
• 頻繁に更新され得るデータ(例:⼈間が付与するタグ情報)とJOIN したいニーズも今後出てくると想像。 • 実現⽅法については、今後検討が必要。 ◦ 頻繁に更新されるデータはRDBに⼊れてDWHにデータをsync ◦ Federated queryを使う
◦ そのようなデータもDWHに⼊れる 頻繁に更新するデータも⼀緒にJOINしたい
まとめ
• データの収集‧加⼯プロセスは、最初はアジリティの⾼さを⽬指 して設計した。 • フェーズが進むと、データの使⽤⽅法が明らか‧固定化されてき たため、よりコスト効率や性能を考慮した設計が必要になった。 • データの品質確保はある程度泥臭さが必要。仕組み化も良いが、 品質チェックを効率化するツールがまず⼤事。 まとめ
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}