[email protected] @oisin Thursday 2 February 2012 In which Oisín talks about the motivation for a web API; what makes an API Good, Right and True; an exemplary application; some useful technologies to achieve the application goals; the great mongo; the cap theorem and consistency; programming mongo through mongomapper; defensive coding for the web API; deployment to Heroku and CloudFoundry; and summarizes some realizations about mongo.
people are actually making money from web APIs - based on a freemium model, companies like UrbanAirship charge for pushing data to phones; other data companies charge subscription access to their data corpora. Next: What makes a good API?
epitomizes good coding/behavioural practice ‣ has minimal sugar ‣ has a minimum of control surfaces Thursday 2 February 2012 APIs can be a bit difficult to get right. So let’s look at the characteristics of a good API. Clarity - includes the documentation here. Good practice - adhere to naming conventions; no 40 parameter methods; Sugar implies no sugar also possible, reduces clarity. Minimum - behavioural hints in one place, minimal methods. But this all is tempered by reality.
‣ you don’t suddenly break the consumers, ever ‣ you control the API lifecycle, you control the expectations Thursday 2 February 2012 A thing that is very important for the longevity (and usefulness) of an API is evolvability. APIs have a lifecycle - you release them into the wild and people start using them. They use them in ways you never, ever, would have thought. And they start looking for new approaches, methods, access to internals and new ways to control the behaviour. If they are paying you, it’s usually a good idea in some instances to give them what they need. But you have to do this in a controlled fashion. If you break products that customers are using to make money, then there will be hell to pay. So it’s important you control the lifecycle of the API and the experience of everybody. You need to be able to say we are making changes, and we’re going to change the version, and this is what that means.
‣ latency savvy ‣ does paging where appropriate ‣ not unnecessarily fine-grained Thursday 2 February 2012 Previous characteristics apply to programming APIs, but web APIs have some extra fun things associated with them because they have the network in there, and everybody knows how that makes life difficult. Don’t try to do many fine-grained calls; make sure a typical interaction with the API doesn’t take many calls; but be bandwidth sensitive as well as latency savvy; use paging, with ranges, or iterator style URLs.
of badness ‣ traps flooding/overload ‣ adapts to surges ‣ makes good on shoddy requests, if possible ‣ authenticates, if appropriate Thursday 2 February 2012 This is the thing that will annoy people the most - if your API goes away totally. It may degrade, get slower, but shouldn’t go away. A lot of the resilience here is ops-based, so you need the right kind of scaling, but that doesn’t absolve you from doing some programming work! That’s the theory.
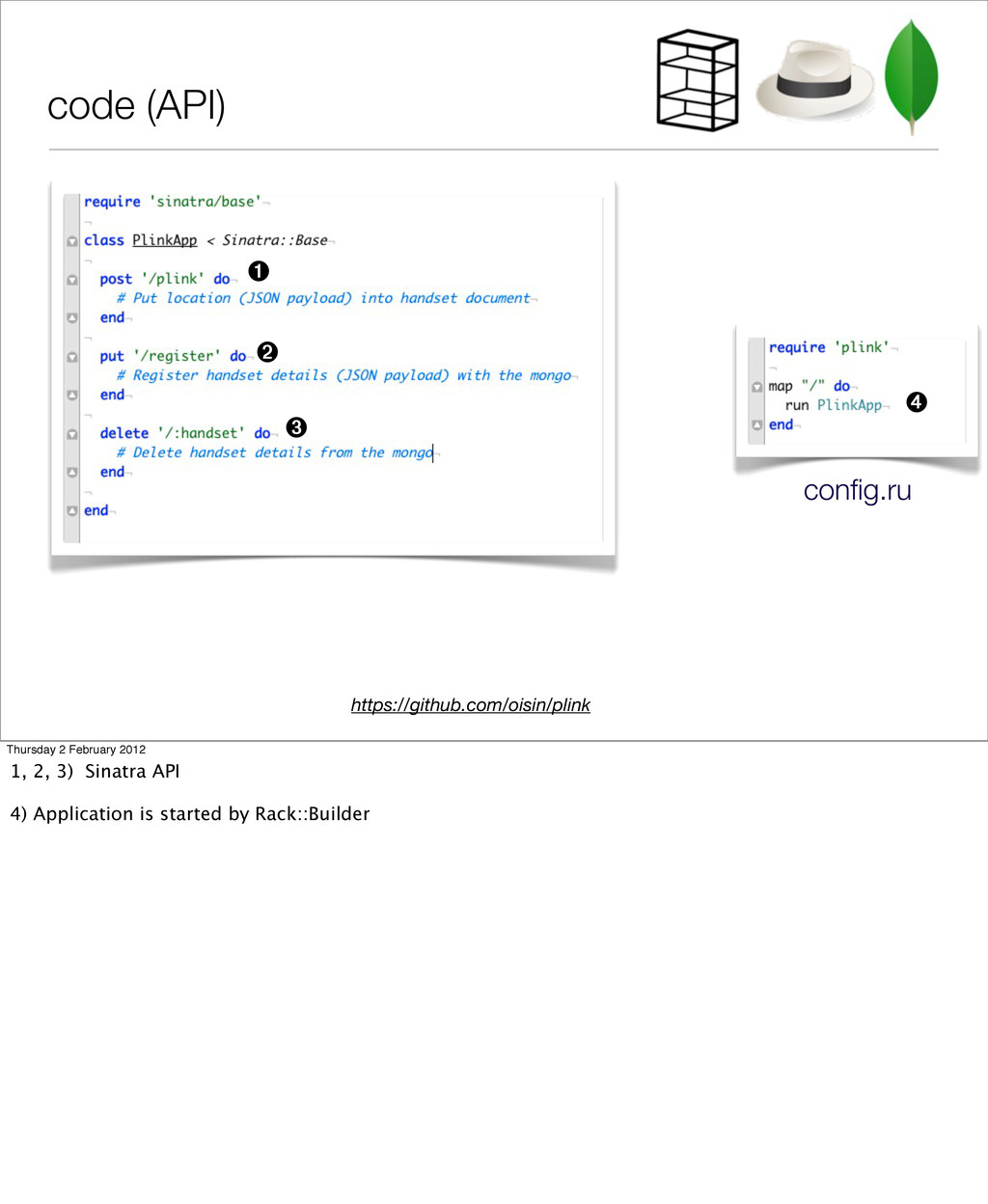
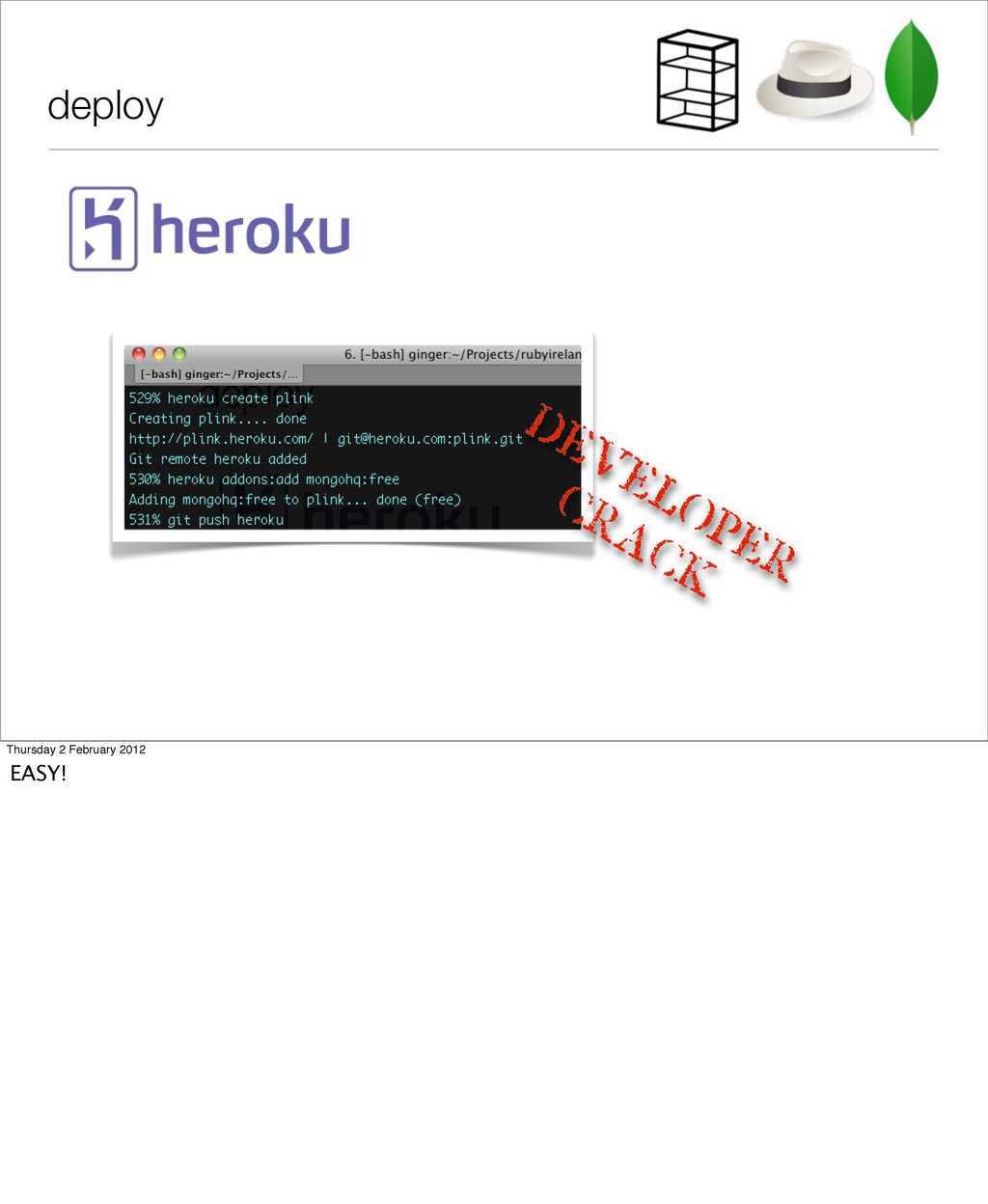
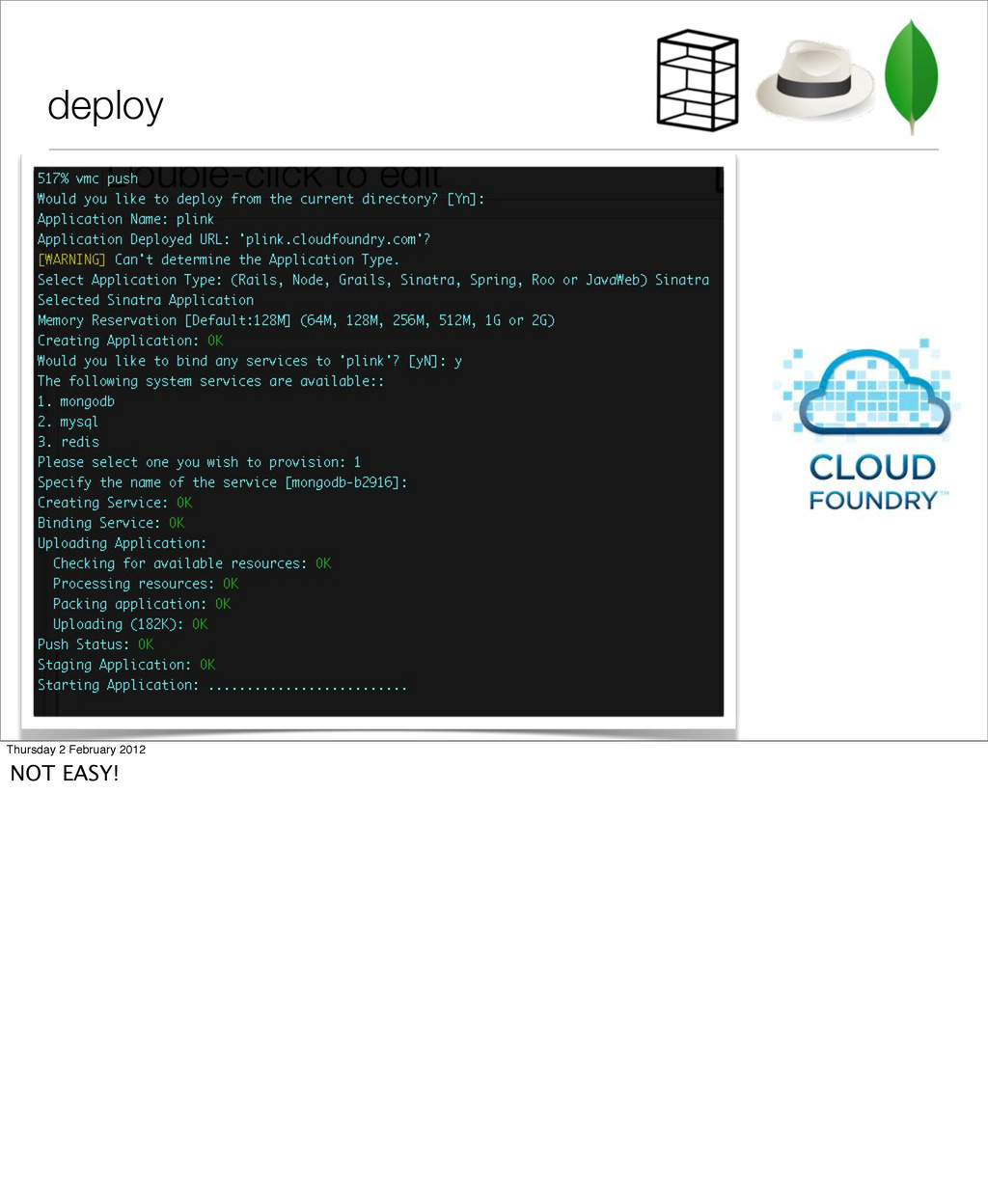
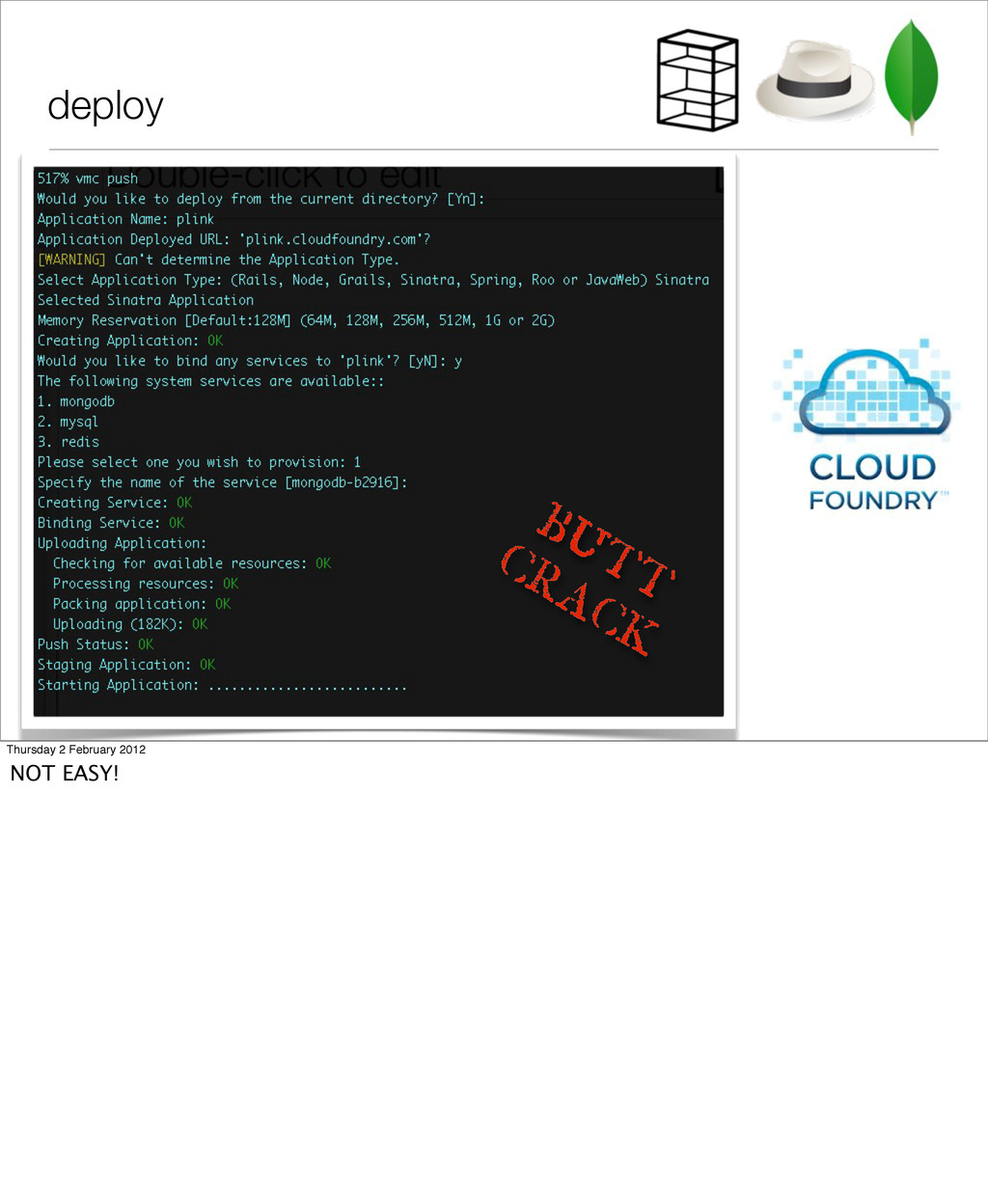
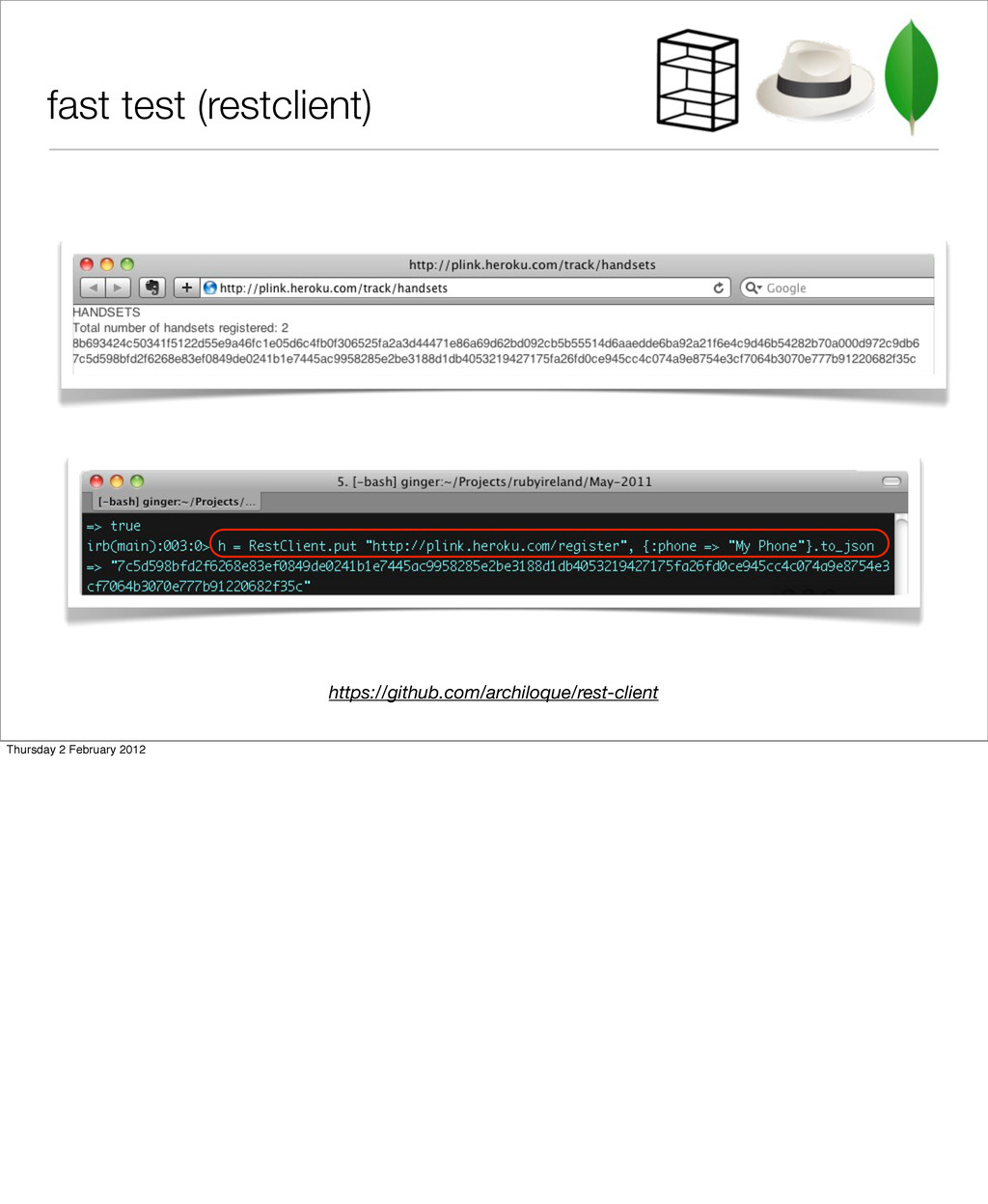
‣ now that apple/google no longer do our work for us ‣ register a handset ‣ add a location ‘ping’ signal from handset to server https://github.com/oisin/plink Thursday 2 February 2012 I did a little sample application, which I’d like to keep developing, as there is some interesting stuff from the point of view of scaling and using mongo that I’d like to get into at some point.
location details ‣ DEL a handset when not in use ‣ focussed and short Thursday 2 February 2012 From the design perspective - it’s focussed - only does three things!
a version into URL - /api/v1.3/... ‣ in good company - google, twitter ‣ produce a compatibility statement ‣ what it means to minor/major level up ‣ enforce this in code Thursday 2 February 2012 Ok to hit this with a hammer, not to be subtle and encode a version number in the URL. We can enforce compatibility rules in the code itself. A little later we can see how something like Rack can help us with this even more so, but we should keep checks in the code. Compatibility statement is something you have in the docs for your developers. But you know how that works already.
work around badness ‣ throttling of client activity with minimum call interval ‣ not using auth in this edition... Thursday 2 February 2012 I admit I’m taking a few shortcuts here! Mongo is going to do the scaling for us :) We’re going to write some defensive code. One call per 5 minutes is probably plenty for me to find out what’s going on in terms of the handset location. I left out auth to just take off one layer of stuff - it should be in later versions of the example application.
chatty ‣ we should queue to decouple POST response time from db ‣ but mongo is meant to be super-fast ‣ so maybe we get away with it in this edition :) Thursday 2 February 2012 Very small API - fine-grained is ok here. We should use queues to ensure that the synchronous HTTP returns as quickly as possible to the client. This needs an experiment - I’m playing it by ear here - mongo is meant to be fast, so maybe putting in something like a delayed_job may actually mean more overhead. This is a kind of design decision where you need to get some figures and some costs. Now lets look at some of the technologies I’ve put together for this sample app.
compatible http://www.sinatrarb.com/ whut? Thursday 2 February 2012 Sinatra is my go-to guy for small web application and web apis. Zero hassle and easy to work with and rackness gives it loads of middlewares I can use to modify the request path.
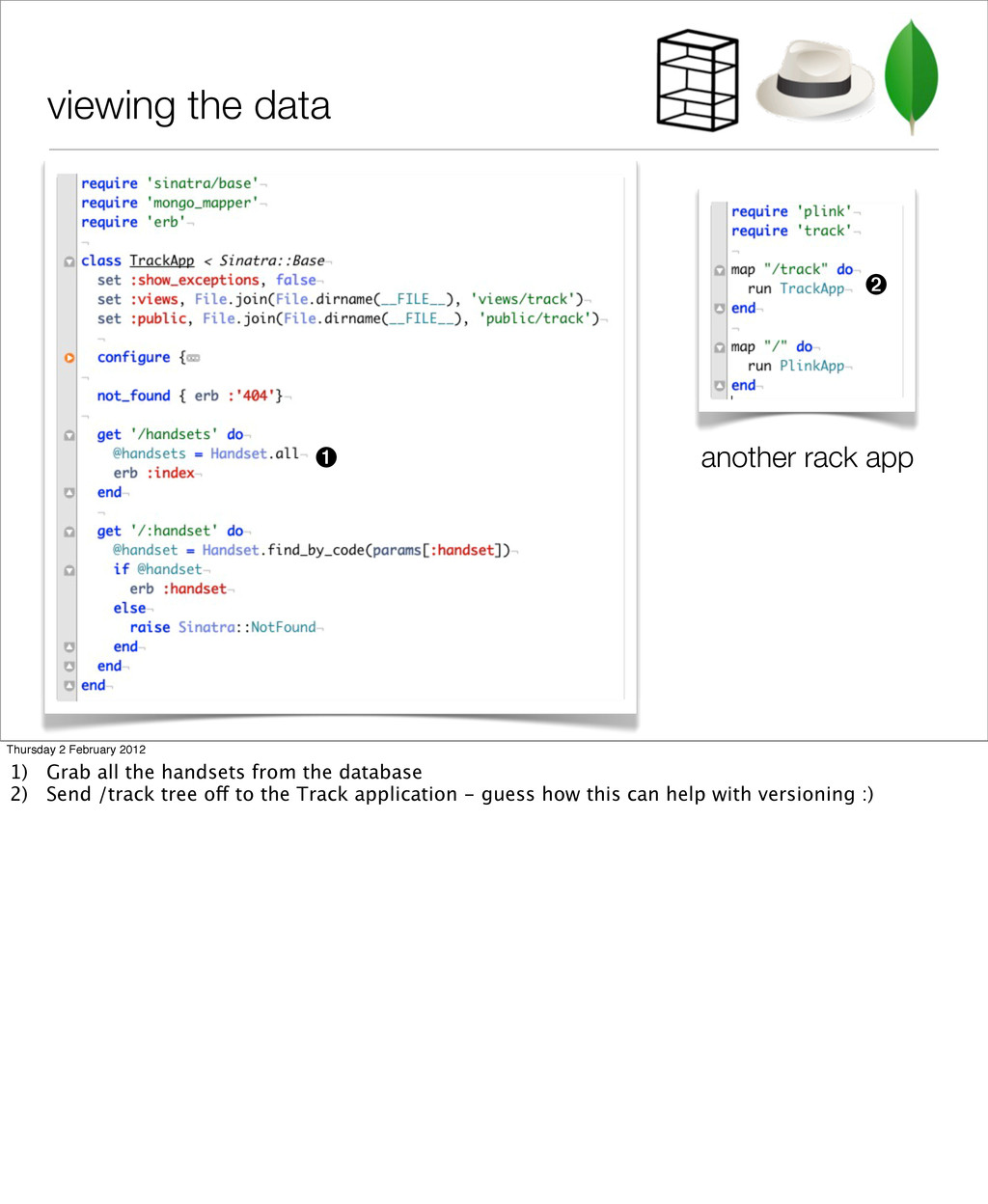
we’re going to use this for two things ‣ throttling for bad clients using a Rack middleware ‣ mounting multiple Sinatra apps with Rack::Builder (later on) http://rack.rubyforge.org/ Thursday 2 February 2012 This gives you a stack/interceptor model to run what’s called middlewares before it gets to your Sinatra application. You can also use it to start up and mount multiple applications living off the same root URL, but in different branches - I’ve added a separate tracking application which is meant to show the data gathered, which we’ll see later.
give us resilience and responsiveness ‣ also nice client on MacOS :) technologies (mongodb) http://www.mongodb.org http://mongohub.todayclose.com/ Thursday 2 February 2012 Mongo! Why did I choose it for this - high performance, horizontal scaling, non-relational, and these are all things I wanted to look at (but not so much in this talk!) It might also save my ass on the resilience and responsiveness I was talking about earlier!
of ActiveRecord : models, associations, dynamic finders ‣ embedded documents ‣ indices ‣ also, I like DataMapper and this is a little similar http://mongomapper.com/ Thursday 2 February 2012 There’s a good Ruby driver for Mongo from 10gen, but MongoMapper gives me an ORM, which is nice and lives on top of that driver. It’s a little ActiveRecord-like, with models, associations etc. At this point, it’s probably time to say a little about MongoDB.
companies using it! Lots of data. You can get all of this information from http://ww.mongodb.com/ and there are a number of really good experience blog entries and articles that are linked. Worth a read.
keys, arrays and other documents ‣ a document is like a JSON dictionary (in fact, it’s BSON) ‣ indices, yes, but no schema in the RDBMS sense - but you do plan! Thursday 2 February 2012 Well, what’s a document anyway? The main choice you need to make with Mongo is whether or not you want something to be an embedded document or a DBRef to a document on in another collection.
documents living in other collections ‣ indices - same as RDBMS - use in the same way ‣ datatypes - JSON basics plus some others including regex and code ‣ flexible querying with js, regex, kv matching ‣ but no JOINs all the same query Thursday 2 February 2012 Embedded documents instead of joins - the efficiency being that when you pull the document, you get all the embedded ones with it and you don’t need to go back to perform a JOIN.
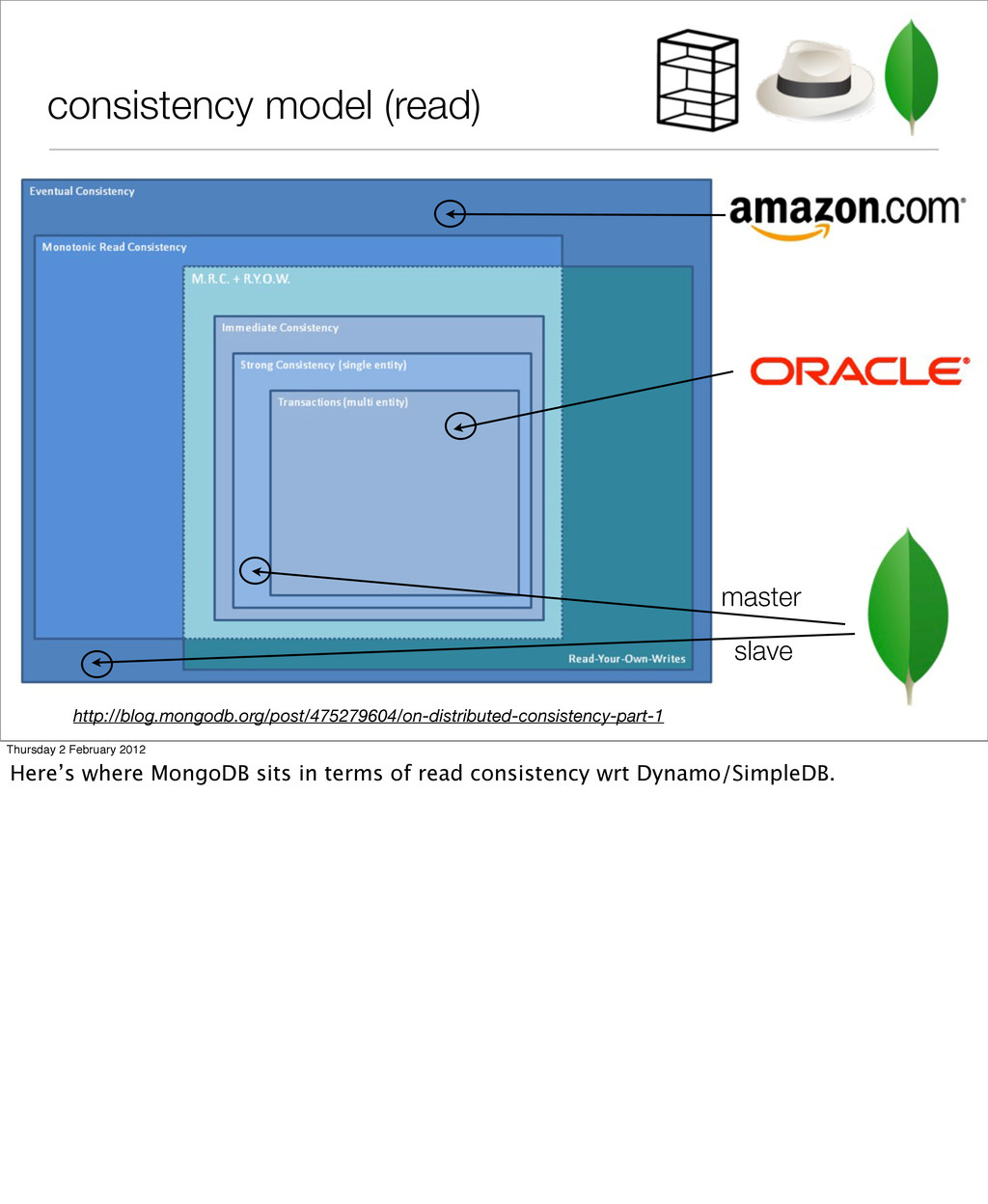
of relational DBs, better horizontal scaling can be achieved ‣ replica sets for scaling reads ‣ replica sets & sharding for scaling writes ‣ map/reduce for batch processing of data (like GROUP BY) http://www.mongodb.org/display/DOCS/Replication http://www.mongodb.org/display/DOCS/Sharding Thursday 2 February 2012 Horizontal scale and performance are the main goal of Mongo - the way to get this was to come back to some of the features and assumptions of the RDBMS and remove them: transactions, JOINs. Take these out, or soften the requirement, and the goals are more easily achieved. Replica sets involve a master and one or more slaves - you write to the master and this is pushed out to the slaves. It’s an eventual consistency model, so if you write, then immediately read from the slave, you will see stale data. If this works for you, then cool. This will scale reads.Sharding is about partitioning your collections over many replica sets. Multiple masters then means that you can scale your writes. Sharding just can be turned on at no downtime. But I haven’t tried this yet - the next talk maybe! map/reduce is an approach for processing huge datasets on certain kinds of distributable problems using a large number of computers Map: The master node takes the input, partitions it up into smaller sub-problems, and distributes those to worker nodes.The worker node processes that smaller problem, and passes the answer back to its master node. Reduce: The master node then takes the answers to all the sub-problems and combines them in some way to get the output — the answer to the problem it was originally trying to solve.
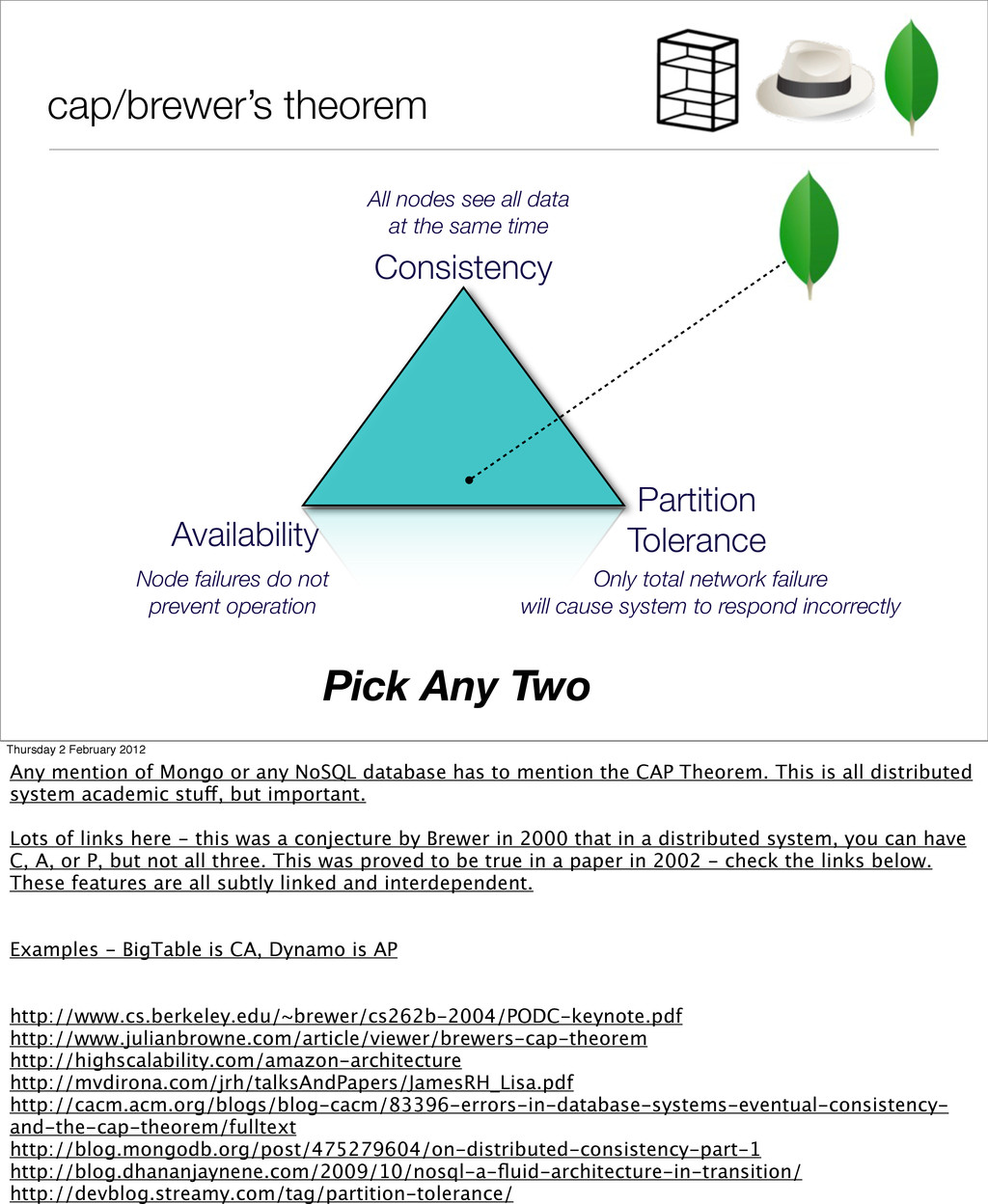
nodes see all data at the same time Node failures do not prevent operation Only total network failure will cause system to respond incorrectly Thursday 2 February 2012 Any mention of Mongo or any NoSQL database has to mention the CAP Theorem. This is all distributed system academic stuff, but important. Lots of links here - this was a conjecture by Brewer in 2000 that in a distributed system, you can have C, A, or P, but not all three. This was proved to be true in a paper in 2002 - check the links below. These features are all subtly linked and interdependent. Examples - BigTable is CA, Dynamo is AP http://www.cs.berkeley.edu/~brewer/cs262b-2004/PODC-keynote.pdf http://www.julianbrowne.com/article/viewer/brewers-cap-theorem http://highscalability.com/amazon-architecture http://mvdirona.com/jrh/talksAndPapers/JamesRH_Lisa.pdf http://cacm.acm.org/blogs/blog-cacm/83396-errors-in-database-systems-eventual-consistency- and-the-cap-theorem/fulltext http://blog.mongodb.org/post/475279604/on-distributed-consistency-part-1 http://blog.dhananjaynene.com/2009/10/nosql-a-fluid-architecture-in-transition/ http://devblog.streamy.com/tag/partition-tolerance/
‣ will not replace your SQL store ‣ good for this example app - because we want fast ‘write’ performance and scale (consistency not so much) ‣ GridFS - chunkifies and stores your files - neat! Thursday 2 February 2012
1) This the regex that will match the root of the URL path_info for a versioned call 2) The compatibility statement is implemented by this helper 3) This filter occurs before every API call and checks the version expected by the incoming request is version compatible with the server’s own
2 February 2012 1) This is a Mongo document 2) Declare the keys in the document, their type and say they are mandatory 3) This is an association - the Handset document should connect to many Location documents 4) This is an Mongo Embedded Document - it lives inside another document, not in its own collection 5) The :time key is protected from mass assignment
2012 1) Making a new connection to the database and setting the database name -- this will be very different when you are using a hosted Mongo, like the MongoHQ that’s used by Heroku. Check out the app code on GitHub for details. 2) Telling Mongo to make sure that the handsets collection (which is modeled by Handset) should be indexed on the :code key Driver too: http://api.mongodb.org/ruby/current/file.TUTORIAL.html MongoMapper: http://mongomapper.com/documentation/
Starting the Mongo shell client and using the appropriate database 2) Querying for all the handsets 3) One of the handsets has an embedded document Location
deletion https://github.com/jnunemaker/mongomapper ➊ ➋ ➌ ➍ Thursday 2 February 2012 1) Standard MongoMapper ‘where’ query 2) Creating a Handset and setting the :status and :code keys 3) Dynamic finder, ActiveRecord stylee 4) Deleting a document in the handsets collection
➎ Thursday 2 February 2012 1) Making a new Location model instance, but not saving it to databas 2) Defense Against the Dark Arts: checking for mandatory JSON payload keys 3) Defense Against the Dark Arts: checking for optional JSON payload keys 4) Adding a Location to an array of them in the Handset model 5) Saving the Handset model will write the Location array as embedded documents
Maintains insertion order - great for logs/comments/etc ‣ not in use in this example application ‣ embedded documents - no cap on arrays ‣ putting location data in another collection - not sensible ‣ hacked it in the example app Thursday 2 February 2012 Unfortunately can’t mix up those capped collections with location information here - it wouldn’t make sense to have the locations into a separate collection - there would be one for each handset and we’re limited on the number of collections on Mongo. Issues with document size - a single doc can be something like 16MB, including all of the embedded documents. Mongo is good for storing LOTS of documents, not HUGE documents. Hence the dumb hack in the code.
Thursday 2 February 2012 1) Only in production, use Throttler middleware, and program for a 300 second (5 min) interval 2) Extend the Rack Throttle interval throttler 3) Just work the choke on URLs that have ‘plink’ at the end - we don’t want to throttle everything! Throttlees get a 403 if they try to get another plink in within a 5 minute limit.
well with heroku ‣ haven’t done any work with sharding/replication ‣ complement RDBMS - e.g. for GridFS files storage, logs, profiles ‣ worthy of further study and experimentation Thursday 2 February 2012 This is my takeaways from this experiment with mongoDB
delayed_job ‣ some eye candy for the tracking data ‣ suggestions welcome :-) http://github.com/oisin/plink Thursday 2 February 2012 Improvements that could be made to the example application (hint hint).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}