Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MCPサーバー連携をLLMに学ばせる強化学習フレームワークARTを使ってみる (CyberAg...
Search
Keisuke Kamata
December 02, 2025
530
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MCPサーバー連携をLLMに学ばせる強化学習フレームワークARTを使ってみる (CyberAgent 三橋 亮太)
Keisuke Kamata
December 02, 2025
More Decks by Keisuke Kamata
See All by Keisuke Kamata
Physical AIを支えるWeights & Biases
olachinkei
1
410
W_Bハッカソン説明会202602.pdf
olachinkei
0
510
W&Bが新しくリリースしたServerless RLの紹介 (W&B 鎌田啓輔)
olachinkei
0
370
WeaveでMCPを記録する & W&BのMCP
olachinkei
1
340
LLMアプリケーションの品質担保に向けた プラクティスと LLMオブザーバビリティツール
olachinkei
1
330
生成AI開発を加速するNVIDIA NIMとNVIDIA NeMo
olachinkei
2
1.4k
Weaveを用いた生成AIアプリケーションの評価_モニタリンングと実践例.pdf
olachinkei
2
630
20240917_wandb_Monthly_meetup_TIS
olachinkei
0
640
Nejumi Leaderboard release 20240702
olachinkei
1
430
Featured
See All Featured
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Site-Speed That Sticks
csswizardry
13
1.3k
WENDY [Excerpt]
tessaabrams
11
38k
Become a Pro
speakerdeck
PRO
31
6k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
BBQ
matthewcrist
89
10k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.5k
Transcript
MCPサーバー連携をLLMに学ばせる 強化学習フレームワークARTの知見共有 株式会社サイバーエージェント AI 事業本部 AI Lab Reinforcement Learningチーム 三橋
亮太 W&B meetup #26
2 ARTの知見共有 01 自己紹介 • 氏名 ◦ 三橋 亮太 •
所属 ◦ 2024/11~ 株式会社サイバーエージェント ▪ AI事業本部 AI Lab Reinforcement Learningチーム リサーチエンジニア • 業務/軸 ◦ 研究成果のプロダクト提供に向けた エンジニアリング技術の獲得と実践 • 直近の業務 ◦ 軽量な日本語報酬モデルの公開 (HF) ◦ 言語モデルを含むパイプラインの構築と評価 • 趣味:SAKE DIPLOMA(2022)
3 ARTの知見共有 01 • なぜMCPサーバー連携を(オープンウェイト) LLMに学ばせるのか ◦ APIモデルを使えば良いのではないか? ▪ API利用で解決する規模
/速度であればYes ▪ 数百万件規模のデータをエージェントで処理したいようなケースでは 推論コスト/速度が無視できない (社内ノウハウを蓄積する機会の損失) ◦ オープンウェイトモデルにMCPを繋ぎこめば解決ではないのか? ▪ No ▪ LLMにツールを渡しても最初から 100%使いこなせるわけではない • 提供されたツールを適切に使いこなす能力を身に付ける ことが必要になると考えている • この能力を獲得するために活用できるライブラリとして ARTを紹介、使用した知見を共有 今日の目的
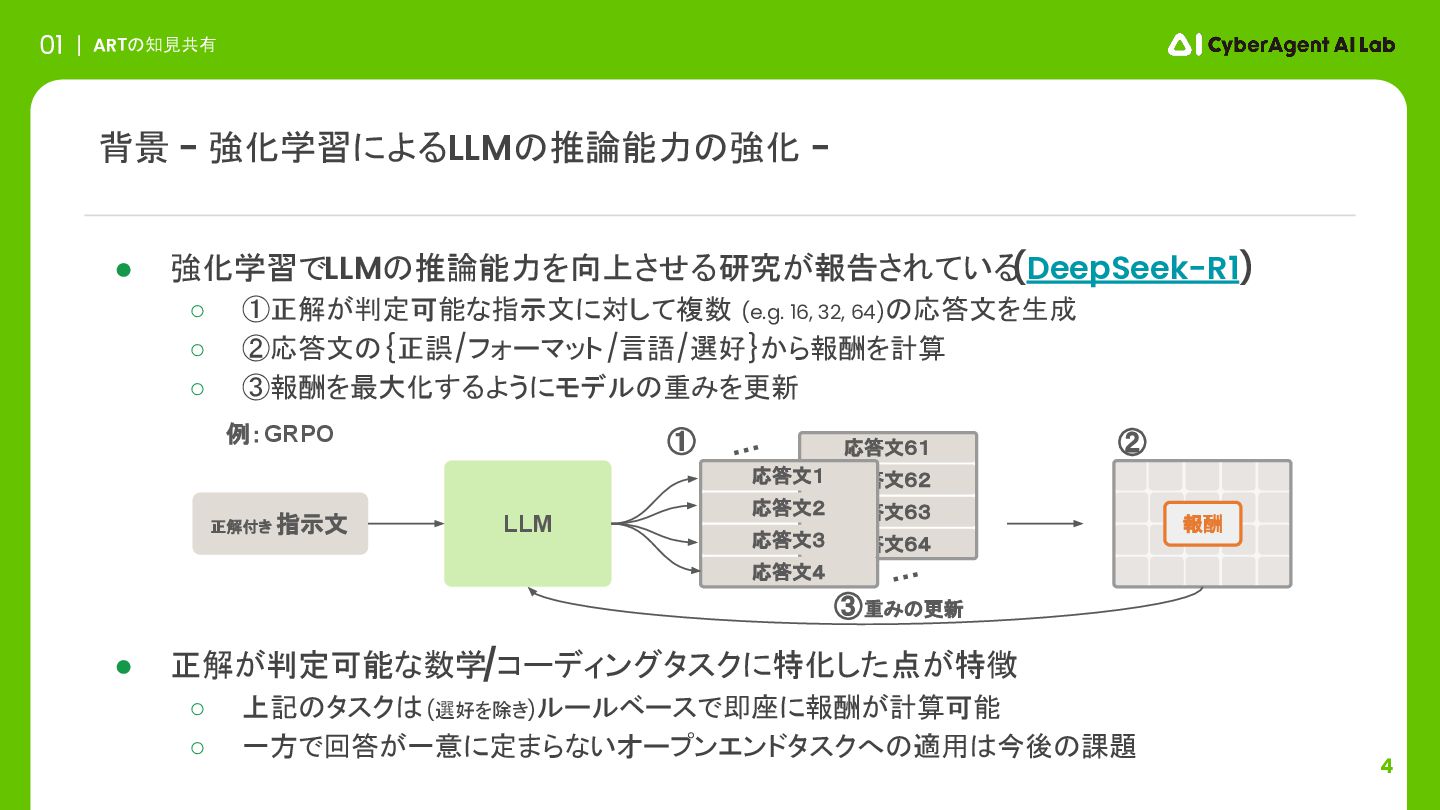
4 ARTの知見共有 01 • 強化学習でLLMの推論能力を向上させる研究が報告されている (DeepSeek-R1) ◦ ①正解が判定可能な指示文に対して複数 (e.g. 16,
32, 64)の応答文を生成 ◦ ②応答文の{正誤/フォーマット/言語/選好}から報酬を計算 ◦ ③報酬を最大化するようにモデルの重みを更新 • 正解が判定可能な数学/コーディングタスクに特化した点が特徴 ◦ 上記のタスクは(選好を除き)ルールベースで即座に報酬が計算可能 ◦ 一方で回答が一意に定まらないオープンエンドタスクへの適用は今後の課題 背景 - 強化学習によるLLMの推論能力の強化 - 正解付き 指示文 LLM ・・・ ・・・ 応答文61 応答文62 応答文63 応答文64 応答文1 応答文2 応答文3 応答文4 報酬 ③重みの更新 ① ② 例:GRPO
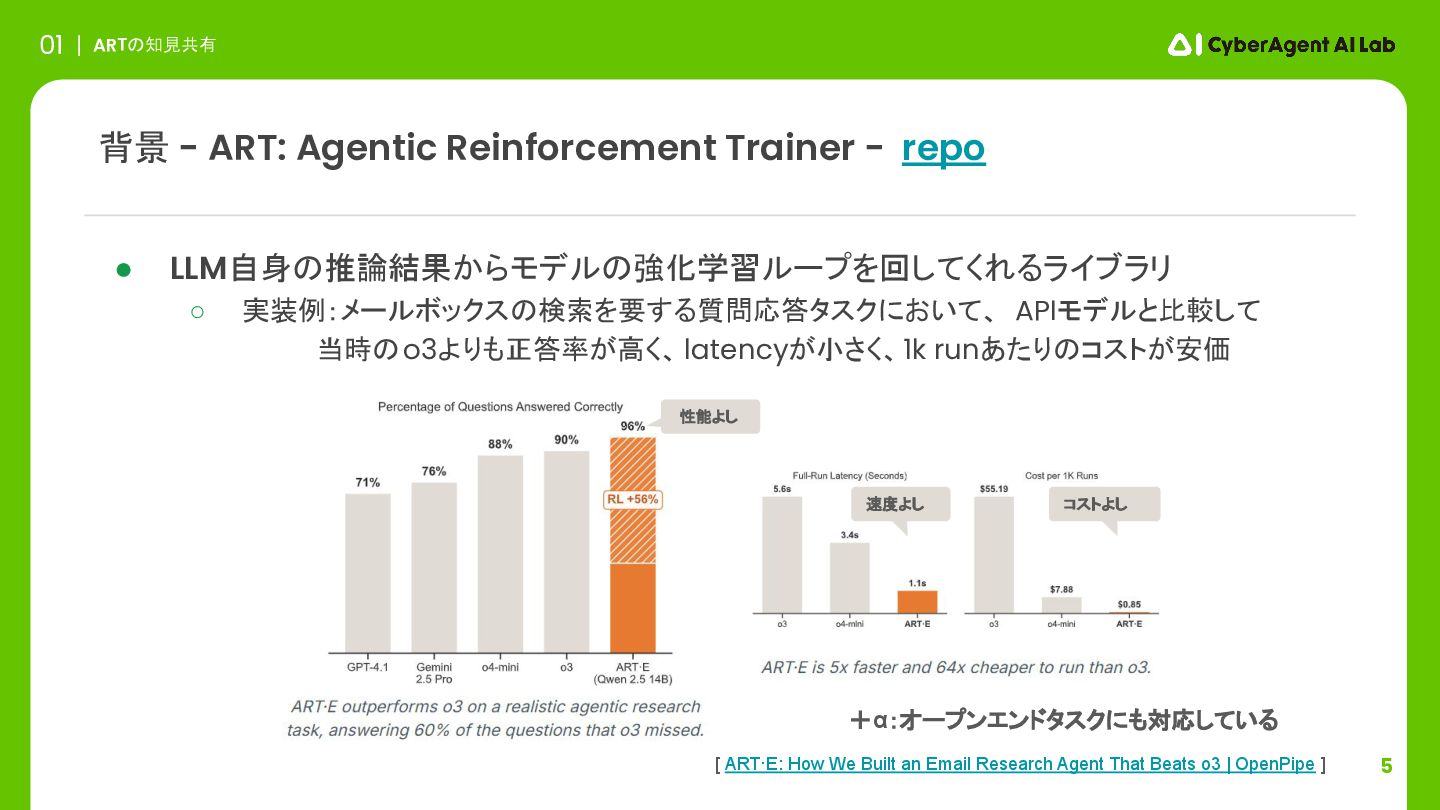
5 ARTの知見共有 01 • LLM自身の推論結果からモデルの強化学習ループを回してくれるライブラリ ◦ 実装例:メールボックスの検索を要する質問応答タスクにおいて、 APIモデルと比較して 当時のo3よりも正答率が高く、 latencyが小さく、1k
runあたりのコストが安価 背景 - ART: Agentic Reinforcement Trainer - repo [ ART·E: How We Built an Email Research Agent That Beats o3 | OpenPipe ] 性能よし 速度よし コストよし +α:オープンエンドタスクにも対応している
6 ARTの知見共有 01 • 背景 • ARTの仕組み • MCPサーバー連携を学ばせるモデルの学習 •
ARTの使い道 目次
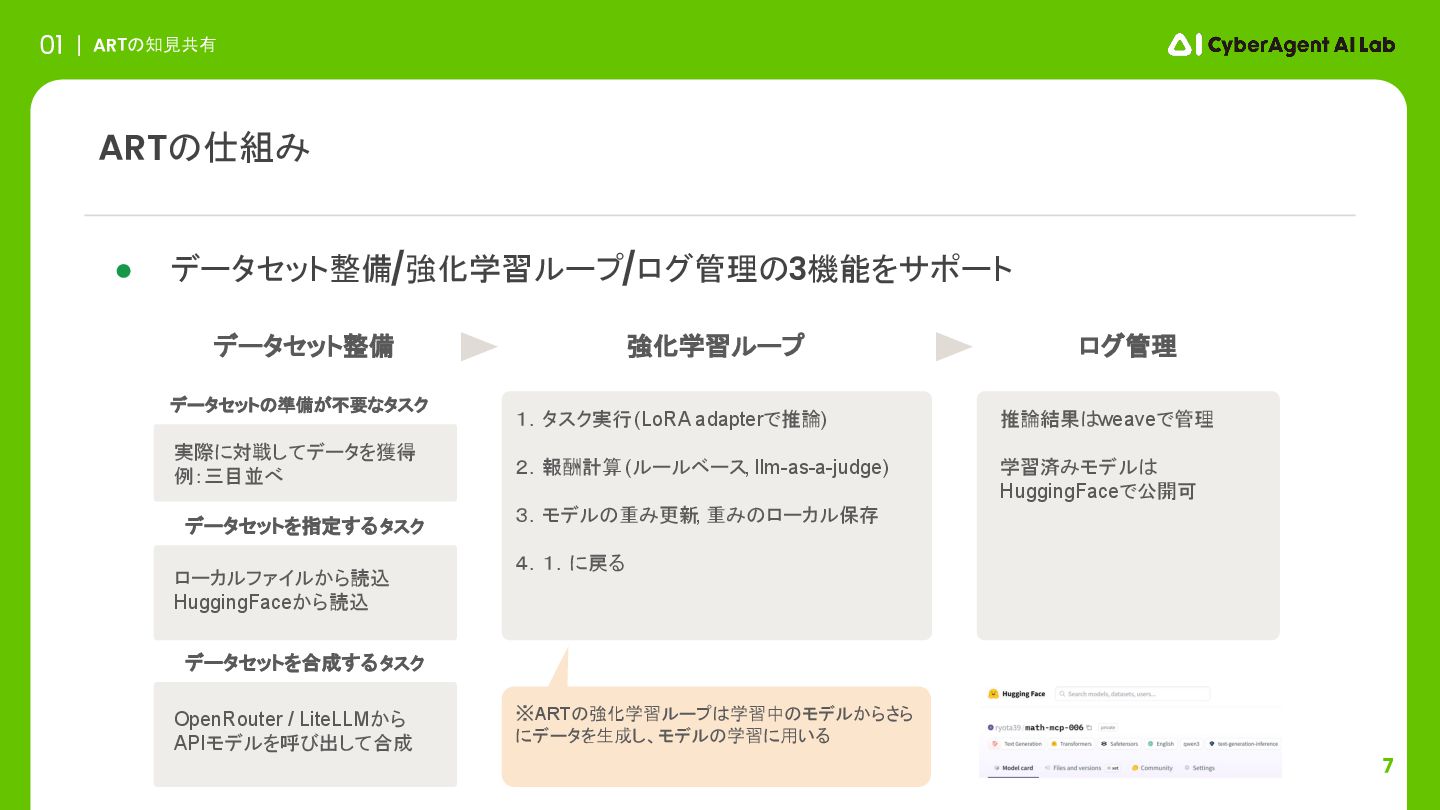
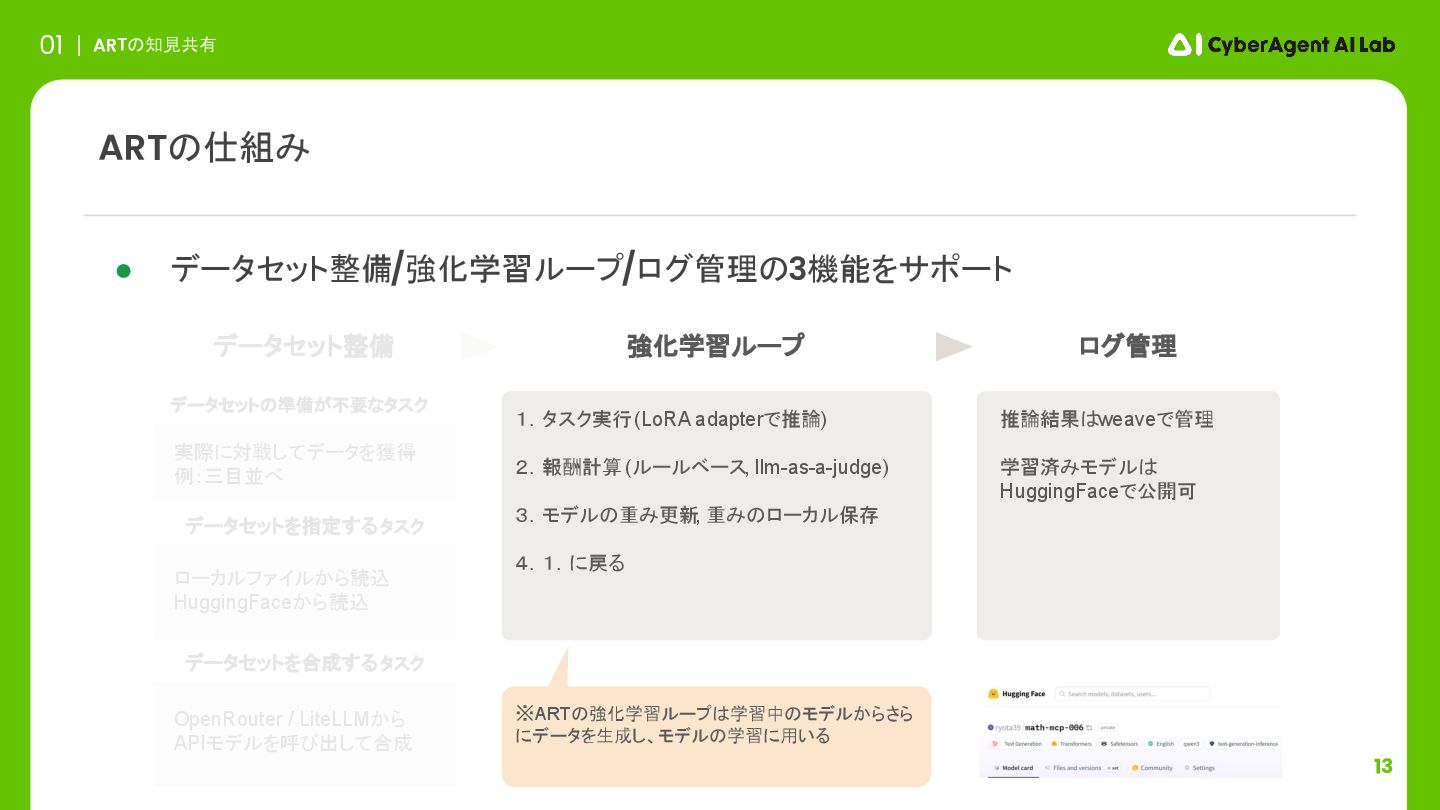
7 ARTの知見共有 01 ARTの仕組み 実際に対戦してデータを獲得 例:三目並べ データセットの準備が不要なタスク 強化学習ループ ログ管理 推論結果はweaveで管理
学習済みモデルは HuggingFaceで公開可 ローカルファイルから読込 HuggingFaceから読込 データセットを指定するタスク データセットを合成するタスク • データセット整備/強化学習ループ/ログ管理の3機能をサポート OpenRouter / LiteLLMから APIモデルを呼び出して合成 ※ARTの強化学習ループは学習中のモデルからさら にデータを生成し、モデルの学習に用いる 1.タスク実行 (LoRA adapterで推論) 2.報酬計算 (ルールベース, llm-as-a-judge) 3.モデルの重み更新 , 重みのローカル保存 4.1.に戻る データセット整備
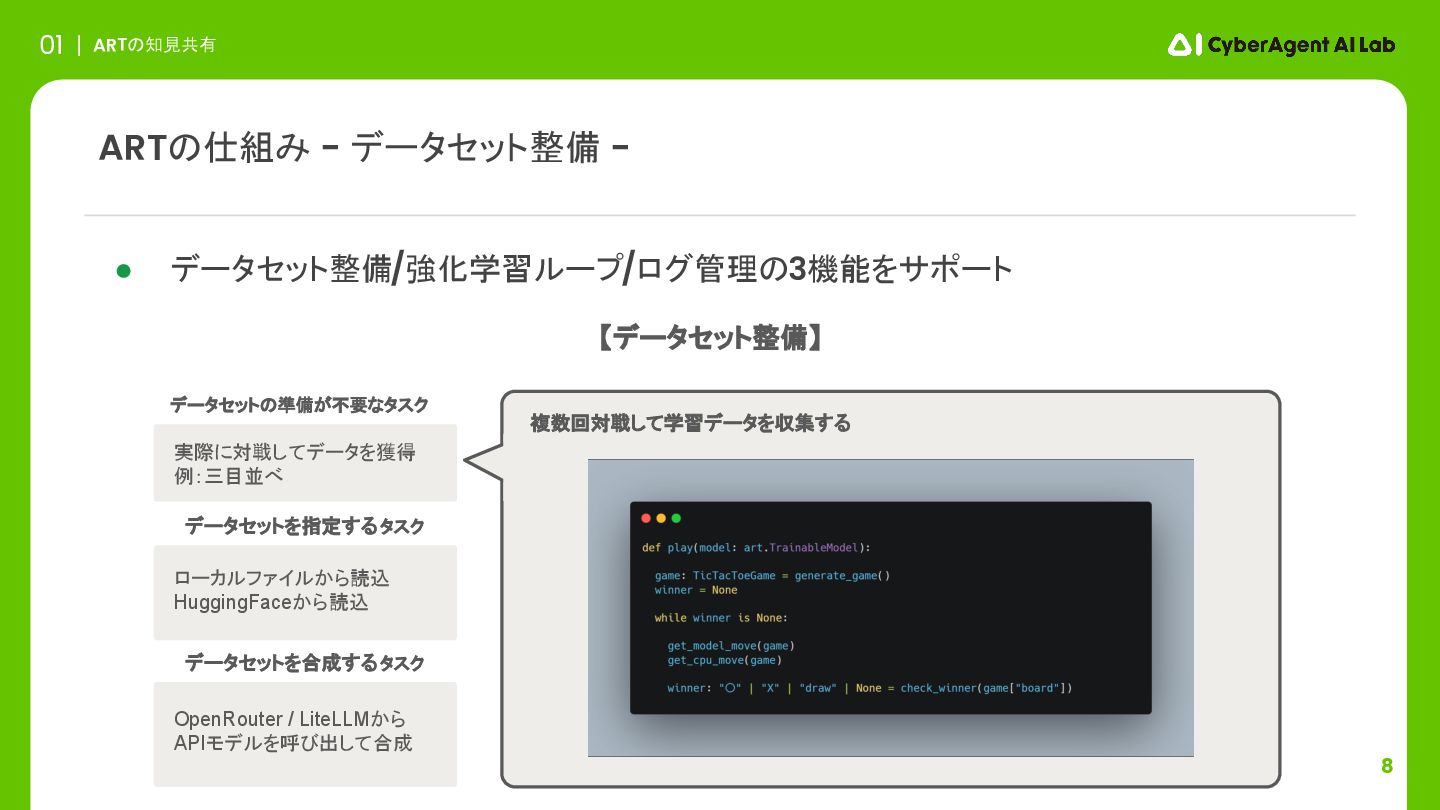
8 ARTの知見共有 01 ARTの仕組み - データセット整備 - 実際に対戦してデータを獲得 例:三目並べ ローカルファイルから読込
HuggingFaceから読込 データセットを指定するタスク データセットを合成するタスク • データセット整備/強化学習ループ/ログ管理の3機能をサポート OpenRouter / LiteLLMから APIモデルを呼び出して合成 【データセット整備】 複数回対戦して学習データを収集する データセットの準備が不要なタスク
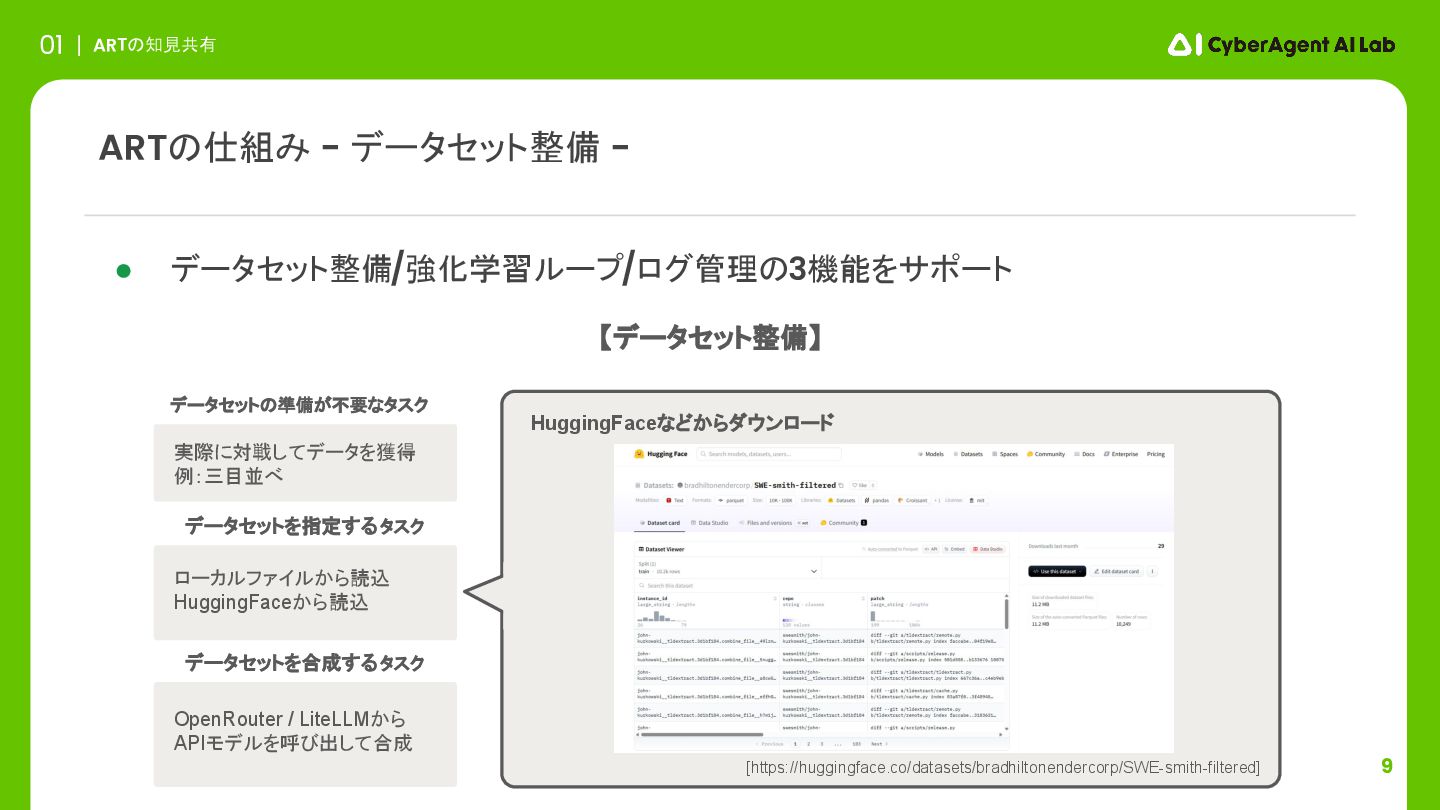
9 ARTの知見共有 01 ARTの仕組み - データセット整備 - 実際に対戦してデータを獲得 例:三目並べ ローカルファイルから読込
HuggingFaceから読込 データセットを指定するタスク データセットを合成するタスク • データセット整備/強化学習ループ/ログ管理の3機能をサポート OpenRouter / LiteLLMから APIモデルを呼び出して合成 HuggingFaceなどからダウンロード [https://huggingface.co/datasets/bradhiltonendercorp/SWE-smith-filtered] データセットの準備が不要なタスク 【データセット整備】
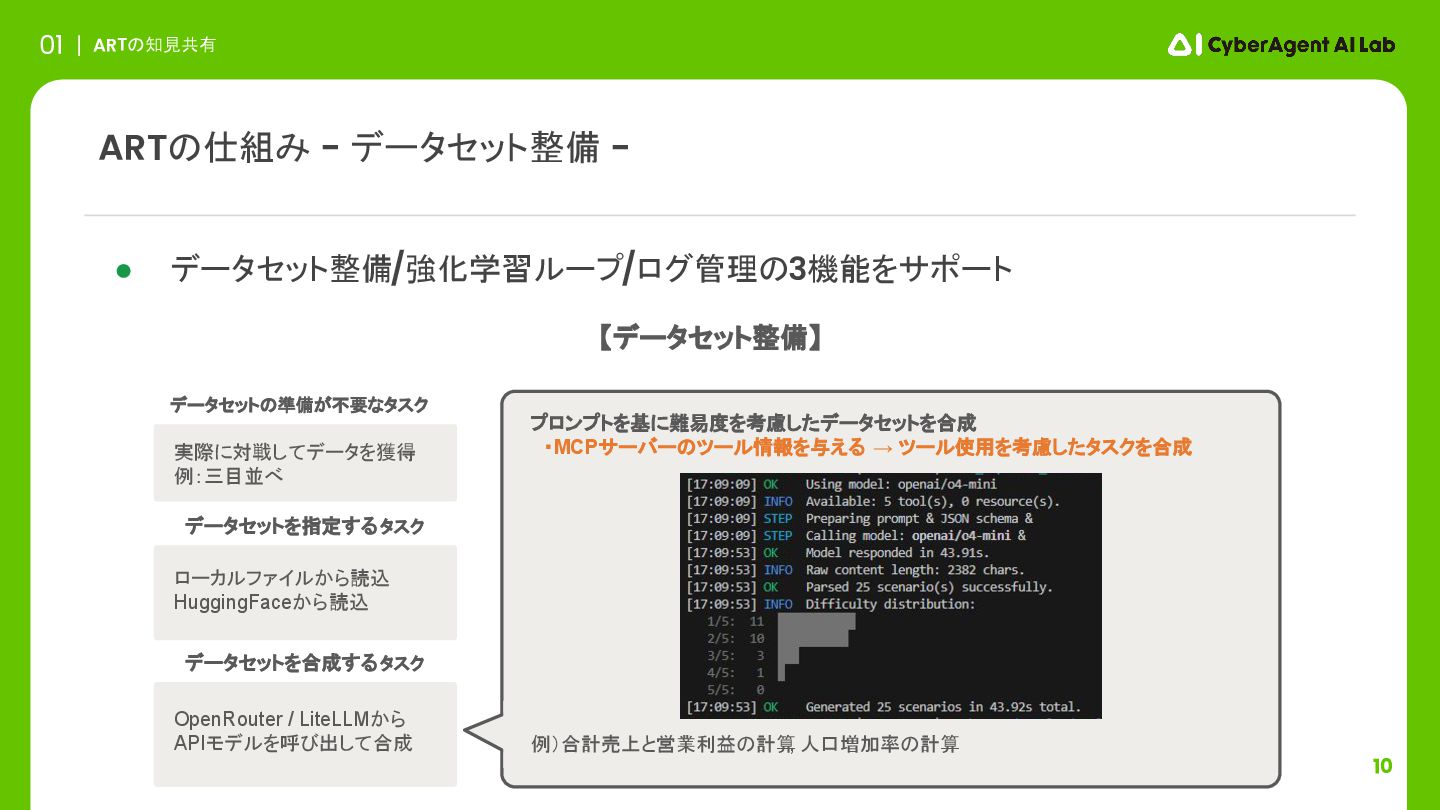
10 ARTの知見共有 01 ARTの仕組み - データセット整備 - 実際に対戦してデータを獲得 例:三目並べ ローカルファイルから読込
HuggingFaceから読込 データセットを指定するタスク データセットを合成するタスク • データセット整備/強化学習ループ/ログ管理の3機能をサポート OpenRouter / LiteLLMから APIモデルを呼び出して合成 プロンプトを基に難易度を考慮したデータセットを合成 ・MCPサーバーのツール情報を与える → ツール使用を考慮したタスクを合成 例)合計売上と営業利益の計算 , 人口増加率の計算 データセットの準備が不要なタスク 【データセット整備】
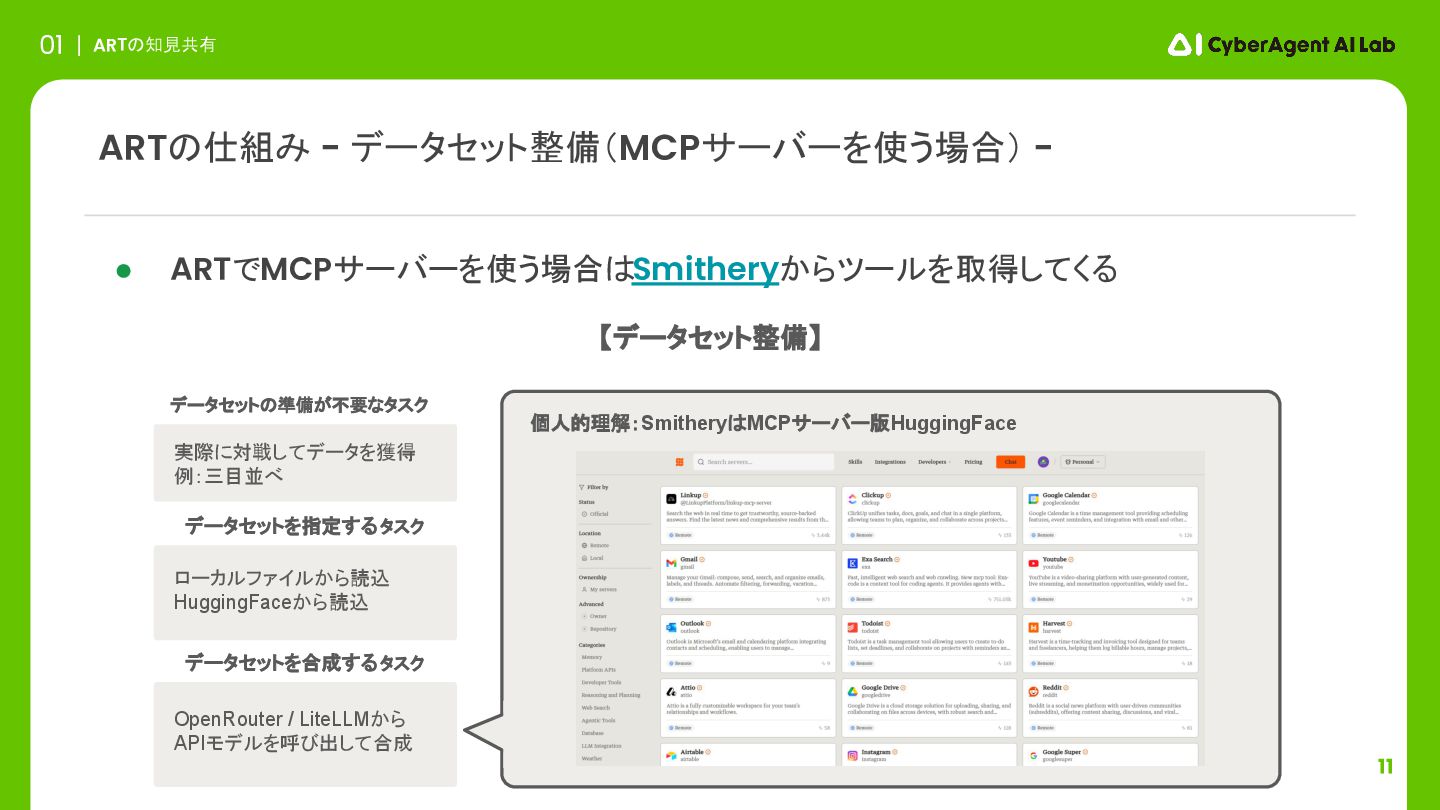
11 ARTの知見共有 01 ARTの仕組み - データセット整備(MCPサーバーを使う場合) - 実際に対戦してデータを獲得 例:三目並べ ローカルファイルから読込
HuggingFaceから読込 データセットを指定するタスク データセットを合成するタスク • ARTでMCPサーバーを使う場合はSmitheryからツールを取得してくる OpenRouter / LiteLLMから APIモデルを呼び出して合成 個人的理解:SmitheryはMCPサーバー版HuggingFace データセットの準備が不要なタスク 【データセット整備】
12 ARTの知見共有 01 ARTの仕組み - データセット整備(MCPサーバーを使う場合) - 実際に対戦してデータを獲得 例:三目並べ ローカルファイルから読込
HuggingFaceから読込 データセットを指定するタスク データセットを合成するタスク • ARTでMCPサーバーを使う場合はSmitheryからツールを取得してくる OpenRouter / LiteLLMから APIモデルを呼び出して合成 チュートリアルとしてMath-MCPを使用(四則演算と三角関数他を計算する機能) ・実装ではMCPサーバー固有のURLを指定してツールとリソースを取得する データセットの準備が不要なタスク 【データセット整備】
13 ARTの知見共有 01 ARTの仕組み 実際に対戦してデータを獲得 例:三目並べ データセットの準備が不要なタスク 強化学習ループ ログ管理 推論結果はweaveで管理
学習済みモデルは HuggingFaceで公開可 ローカルファイルから読込 HuggingFaceから読込 データセットを指定するタスク データセットを合成するタスク • データセット整備/強化学習ループ/ログ管理の3機能をサポート OpenRouter / LiteLLMから APIモデルを呼び出して合成 1.タスク実行 (LoRA adapterで推論) 2.報酬計算 (ルールベース, llm-as-a-judge) 3.モデルの重み更新 , 重みのローカル保存 4.1.に戻る データセット整備 ※ARTの強化学習ループは学習中のモデルからさら にデータを生成し、モデルの学習に用いる
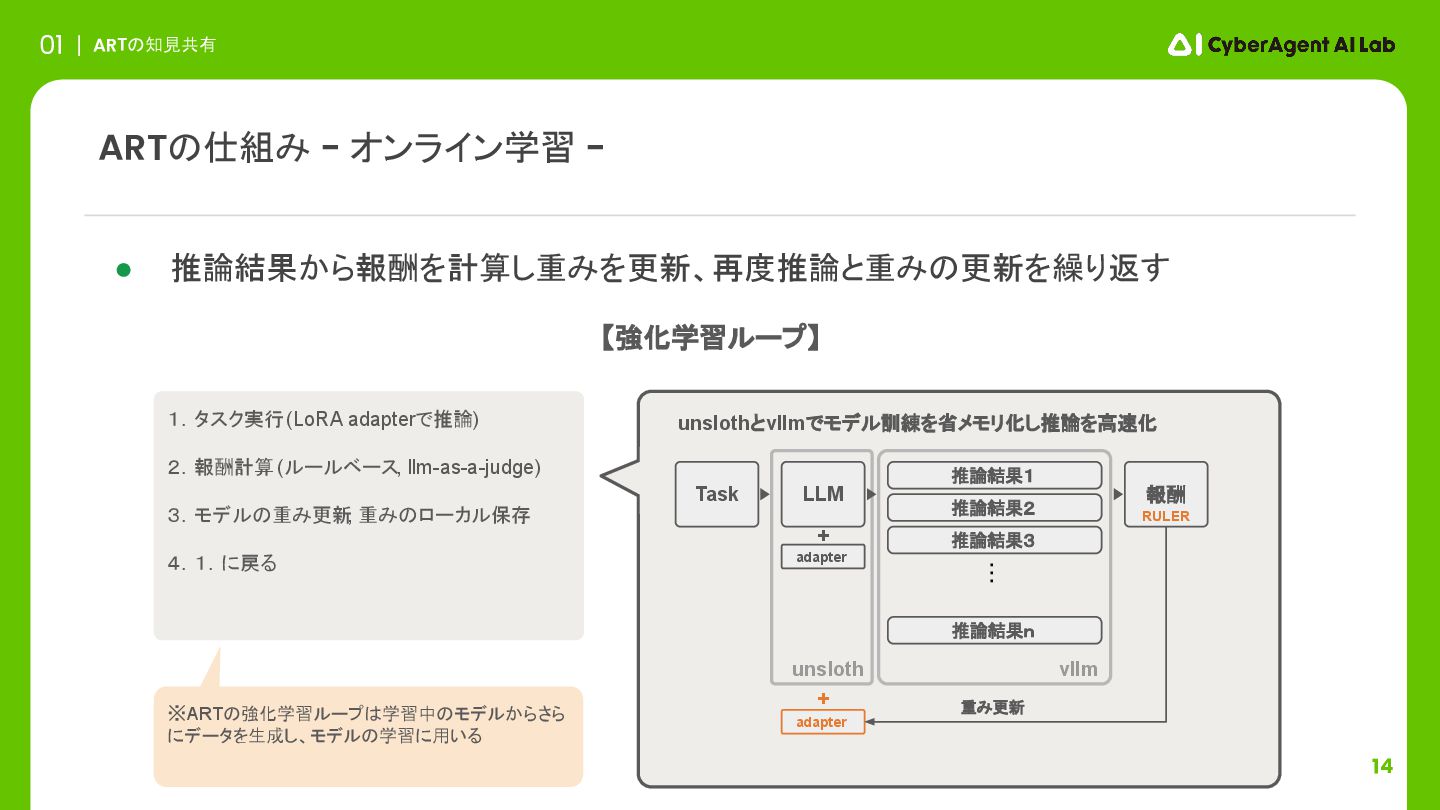
14 ARTの知見共有 01 • 推論結果から報酬を計算し重みを更新、再度推論と重みの更新を繰り返す ARTの仕組み - オンライン学習 - ※ARTの強化学習ループは学習中のモデルからさら
にデータを生成し、モデルの学習に用いる 1.タスク実行 (LoRA adapterで推論) 2.報酬計算 (ルールベース, llm-as-a-judge) 3.モデルの重み更新 , 重みのローカル保存 4.1.に戻る unslothとvllmでモデル訓練を省メモリ化し推論を高速化 Task LLM 推論結果1 推論結果2 推論結果3 推論結果n ・・・ 報酬 adapter + vllm unsloth adapter 重み更新 + 【強化学習ループ】 RULER
15 ARTの知見共有 01 • 推論結果から報酬を計算し重みを更新、再度推論と重みの更新を繰り返す ARTの仕組み - オンライン学習(RULER評価) - ※ARTの強化学習ループは学習中のモデルからさら
にデータを生成し、モデルの学習に用いる 1.タスク実行 (LoRA adapterで推論) 2.報酬計算 (ルールベース, llm-as-a-judge) 3.モデルの重み更新 , 重みのローカル保存 4.1.に戻る RULER(Relative Universal LLM-Elicited Rewards) ・エージェントの推論結果を基に相対的にスコアを付与する 【強化学習ループ】 推論結果1 推論結果2 推論結果3 推論結果n ・・・ 推論結果1:0.25 推論結果2:0.6 推論結果n:0.85 ・・・ 目標が同じn個の推論結果(=軌跡)をスコア付けしなさい rubric1: 目標を達成した軌跡 >> 目標を達成できない軌跡 rubric2: 目標を効率的に達成した軌跡 > 非効率な軌跡 rubric3: 軌跡間の優劣の差をスコアに反映する rubric4: 目標に向けて進捗があれば部分点を与える LLM-as-a-judge
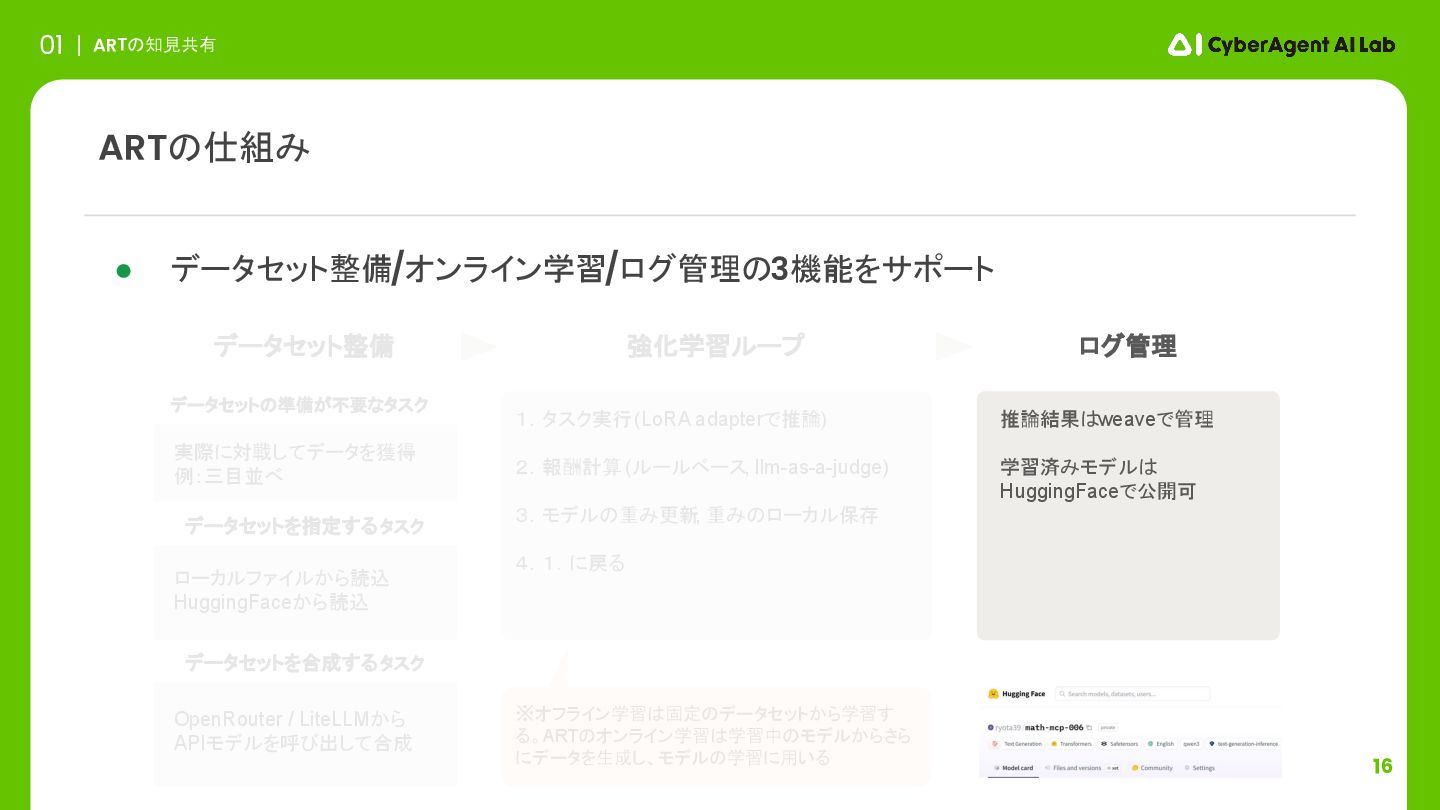
16 ARTの知見共有 01 ARTの仕組み 実際に対戦してデータを獲得 例:三目並べ データセットの準備が不要なタスク 強化学習ループ ログ管理 推論結果はweaveで管理
学習済みモデルは HuggingFaceで公開可 ローカルファイルから読込 HuggingFaceから読込 データセットを指定するタスク データセットを合成するタスク • データセット整備/オンライン学習/ログ管理の3機能をサポート OpenRouter / LiteLLMから APIモデルを呼び出して合成 ※オフライン学習は固定のデータセットから学習す る。ARTのオンライン学習は学習中のモデルからさら にデータを生成し、モデルの学習に用いる 1.タスク実行 (LoRA adapterで推論) 2.報酬計算 (ルールベース, llm-as-a-judge) 3.モデルの重み更新 , 重みのローカル保存 4.1.に戻る データセット整備
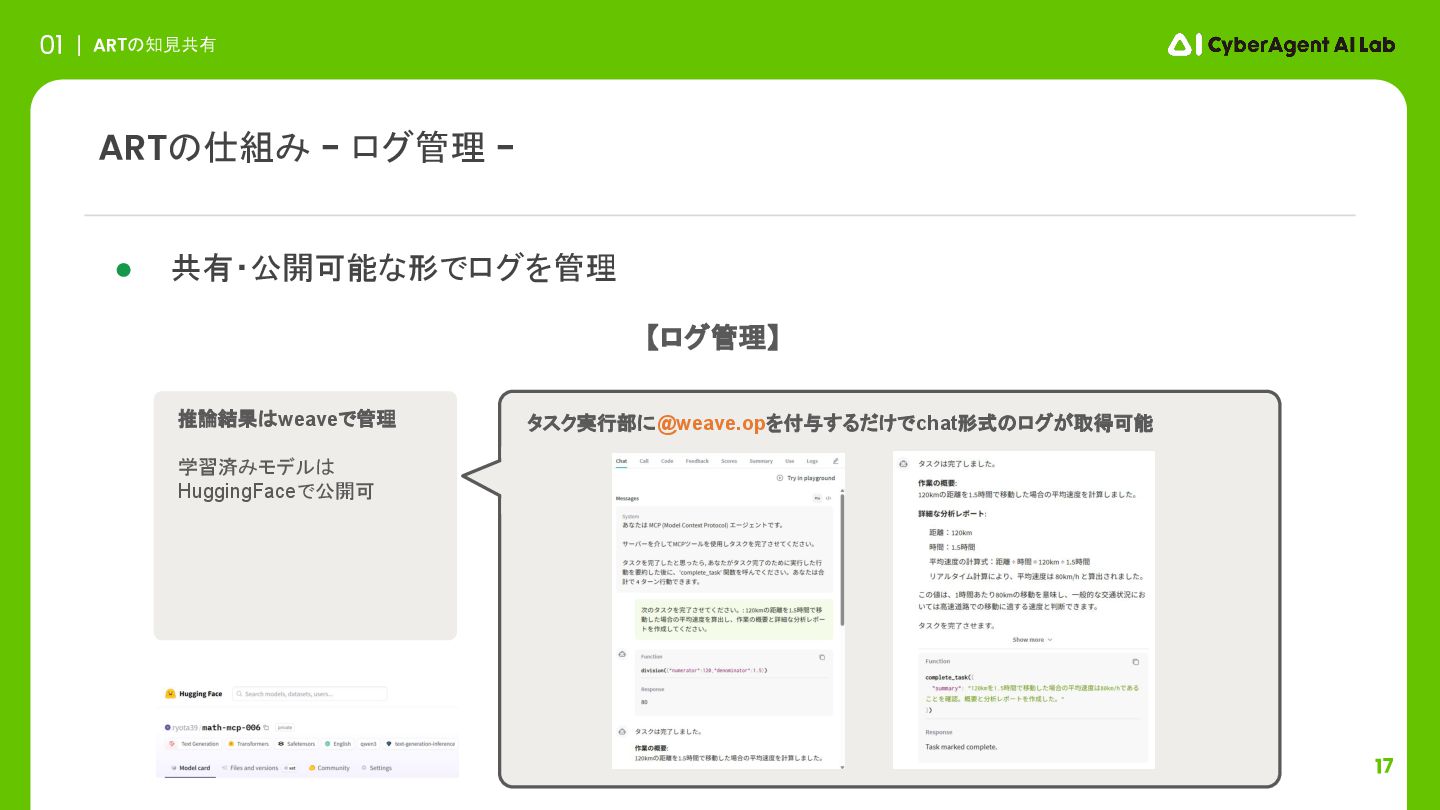
17 ARTの知見共有 01 • 共有・公開可能な形でログを管理 ARTの仕組み - ログ管理 - タスク実行部に@weave.opを付与するだけでchat形式のログが取得可能
推論結果はweaveで管理 学習済みモデルは HuggingFaceで公開可 【ログ管理】
18 ARTの知見共有 01 • 背景 • ARTの仕組み • MCPサーバー連携を学ばせるモデルの学習 •
ARTの使い道 目次
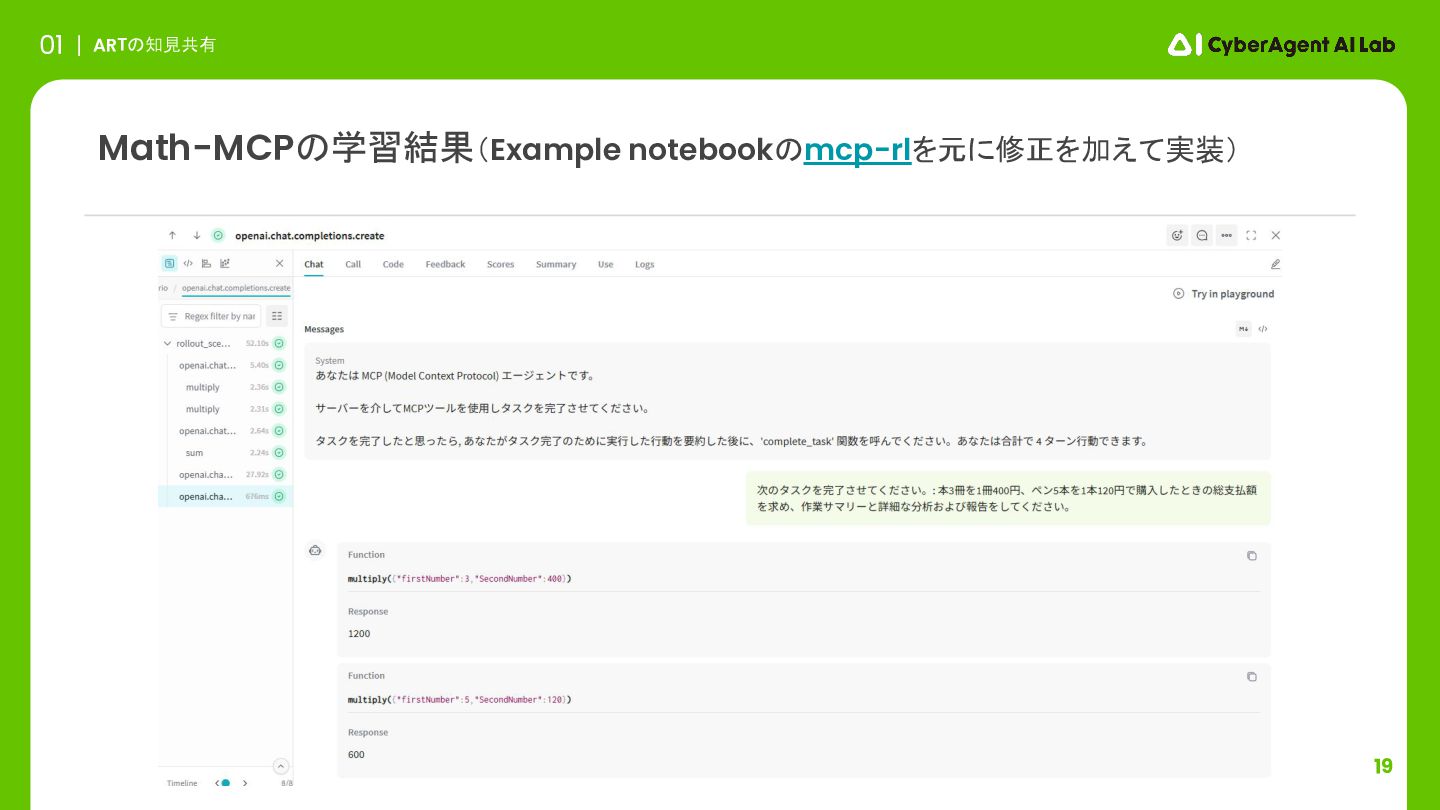
19 ARTの知見共有 01 Math-MCPの学習結果(Example notebookのmcp-rlを元に修正を加えて実装)
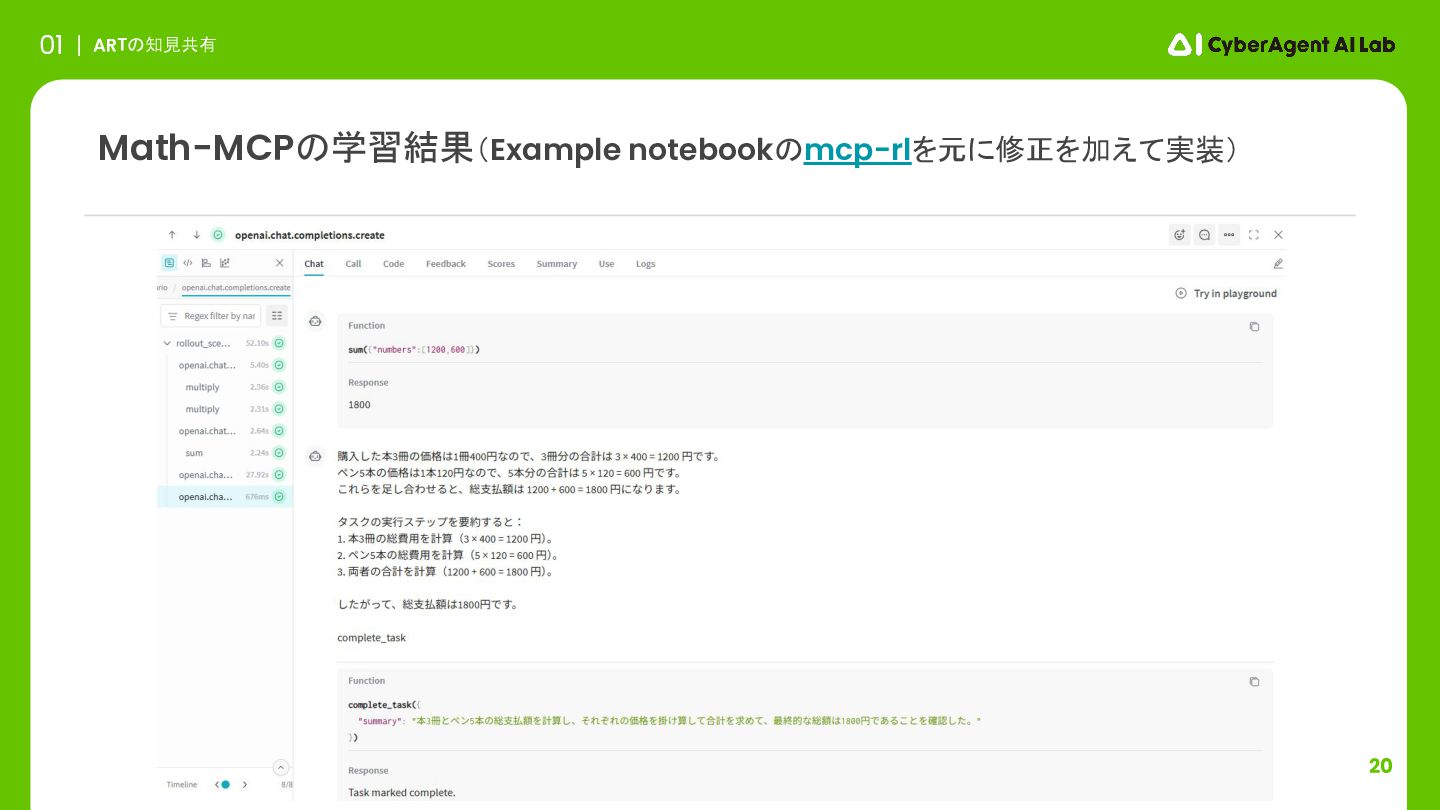
20 ARTの知見共有 01 Math-MCPの学習結果(Example notebookのmcp-rlを元に修正を加えて実装)
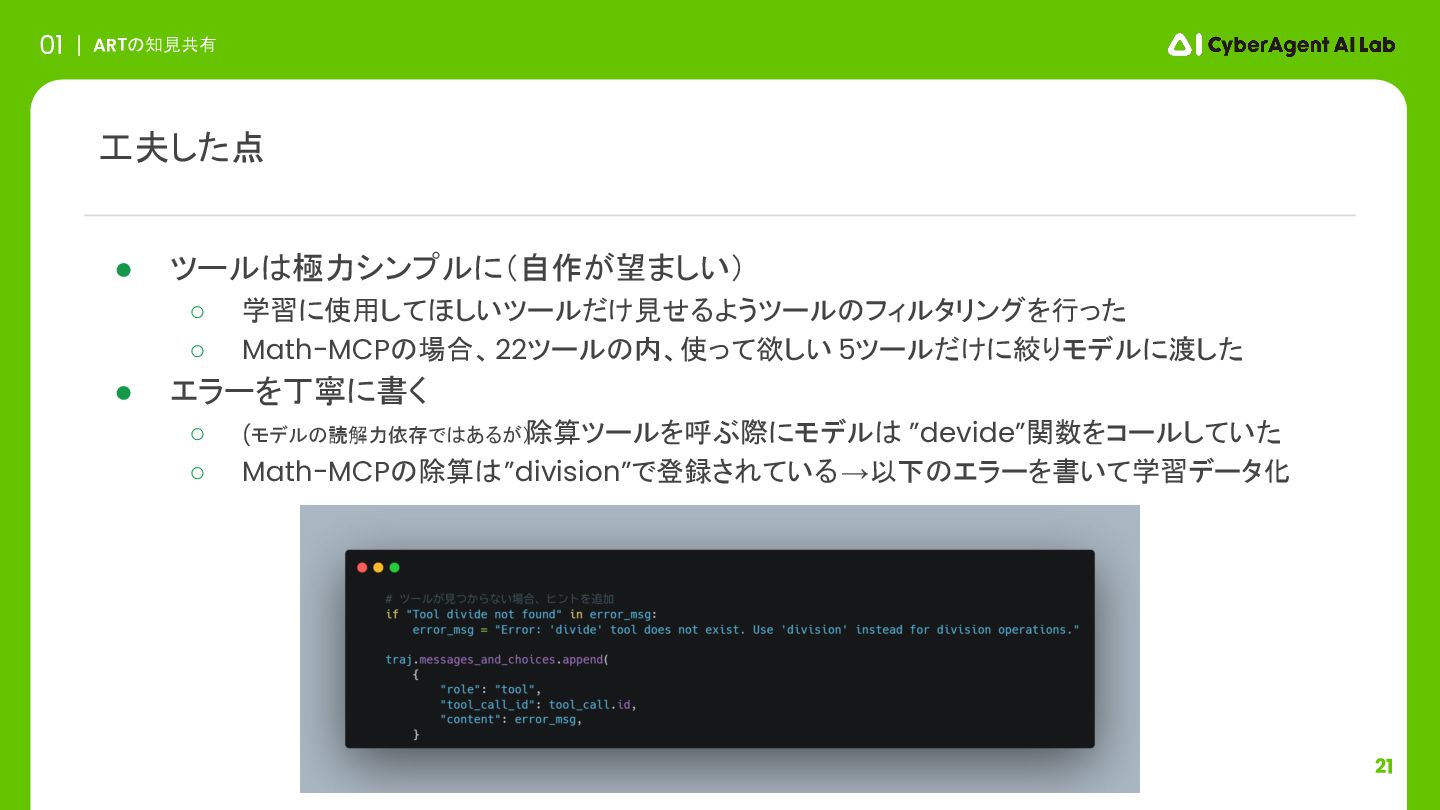
21 ARTの知見共有 01 • ツールは極力シンプルに(自作が望ましい) ◦ 学習に使用してほしいツールだけ見せるようツールのフィルタリングを行った ◦ Math-MCPの場合、22ツールの内、使って欲しい 5ツールだけに絞りモデルに渡した
• エラーを丁寧に書く ◦ (モデルの読解力依存ではあるが) 除算ツールを呼ぶ際にモデルは ”devide”関数をコールしていた ◦ Math-MCPの除算は”division”で登録されている→以下のエラーを書いて学習データ化 工夫した点
22 ARTの知見共有 01 • 背景 • ARTの仕組み • MCPサーバー連携を学ばせるモデルの学習 •
ARTの使い道 目次
23 ARTの知見共有 01 • ドメイン特化文書の読解と生成 ◦ Few-shot プロンプトで対応しきれない、エッジケースが大量にある場合の文書に 対して、読解タスクの正答率 等を報酬としたオンライン学習を行う
◦ プロンプトに書き切れない複雑なルールを、自身の失敗した推論結果から学習すると (最終的に)複雑なルールの組み合わせを守った生成ができるかも • カスタマーサポートの人間へのエスカレーション判断と継続改善 ◦ 定型質問やマニュアルで対応可能な回答はチャットボットで自動回答させたいが、 上記の対応を超えた質問が来た場合は即座に人間に判断を仰ぎたい場面を想定 ◦ 製品によって異なるエスカレーション基準を、エスカレーション後の人間による 対応データを学習しながら、エスカレーション基準と応答品質の向上を図る ARTの使い道 ※ 個人的な見解です
24 ARTの知見共有 01 • MCPサーバー連携をLLMに学ばせる強化学習フレームワーク ARTを紹介 ◦ ツール使用を含むタスク実行能力を身に付ける方法を学習できるライブラリ ◦ ツール使用を考慮したタスクの合成とオンライン学習とログ管理をサポート
• Math-MCPを例に実装結果を共有 ◦ 与えたツールを適切に使うことを確認 ◦ モデルに渡すツールは極力シンプルに、エラーを丁寧に記載して次の学習データに変換 • 特定のユースケースに対してARTでアプローチできそうなことを共有 ◦ ドメイン特化文書の読解や生成の案 ◦ カスタマーサポートにおけるエスカレーション性能の改善案 まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}