Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
OCHaCafe S10 #6 クラウドストレージ活用術
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
oracle4engineer
PRO
December 10, 2025
Video
340
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
OCHaCafe S10 #6 クラウドストレージ活用術
2025/12/10に行われた、OCHaCafe Season10 #6 で用いた資料です。
oracle4engineer
PRO
December 10, 2025
Video
More Decks by oracle4engineer
See All by oracle4engineer
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
Deep Data Security 機能解説
oracle4engineer
PRO
2
290
Oracle Cloud Infrastructure:2026年6月度サービス・アップデート
oracle4engineer
PRO
1
570
Oracle AI Databaseデータベース・サービスのメンテナンス(BaseDB/ExaDB-D/ExaDB-XS)
oracle4engineer
PRO
4
1.9k
Oracle AI Database@Google Cloud:サービス概要のご紹介
oracle4engineer
PRO
6
1.6k
Oracle AI Database@Azure:サービス概要のご紹介
oracle4engineer
PRO
6
2.1k
Oracle AI Database@AWS:サービス概要のご紹介
oracle4engineer
PRO
4
3.2k
CrossplaneによるCloud Native Control Plane
oracle4engineer
PRO
0
130
Featured
See All Featured
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Are puppies a ranking factor?
jonoalderson
1
3.7k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
210
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
180
YesSQL, Process and Tooling at Scale
rocio
174
15k
Automating Front-end Workflow
addyosmani
1370
210k
Designing for humans not robots
tammielis
254
26k
Abbi's Birthday
coloredviolet
3
8.6k
30 Presentation Tips
portentint
PRO
1
340
Transcript
クラウドストレージ活用術 Yuki Sogawa Oracle Japan
自己紹介 曽川 宥輝 日本オラクル CloudNative/AI,ML ク ラウドエンジニア バックグラウンド 大阪大学でデータセンターの省電力化の研究をしていました 趣味
ギター、バイク、ゲームなど 2 Copyright © 2025, Oracle and/or its affiliates
本日お話しすること 3 Copyright © 2025, Oracle and/or its affiliates 1
2 3 4 5 クラウドストレージとは Ceph概要 Lustre概要 ユースケースから考えるストレージ選択と技術解剖 まとめ
クラウドストレージとは
クラウドストレージの分類 クラウドストレージは大きく3つに分類される 1. ブロックストレージ 2. ファイルストレージ 3. オブジェクトストレージ 5 Copyright
© 2025, Oracle and/or its affiliates
ブロックストレージ 最も基本的なクラウドストレージ OSからはiSCSIなどで接続するので、物理的なストレージを接続したように扱える • 複数の物理ディスクを束ねてディスクプールを作成 • ディスクプールから論理的なボリュームを切り出して提供 6 Copyright ©
2025, Oracle and/or its affiliates 物理ディスク ディスクプール 論理ディスク 物理ディスク 物理ディスク 論理ディスク
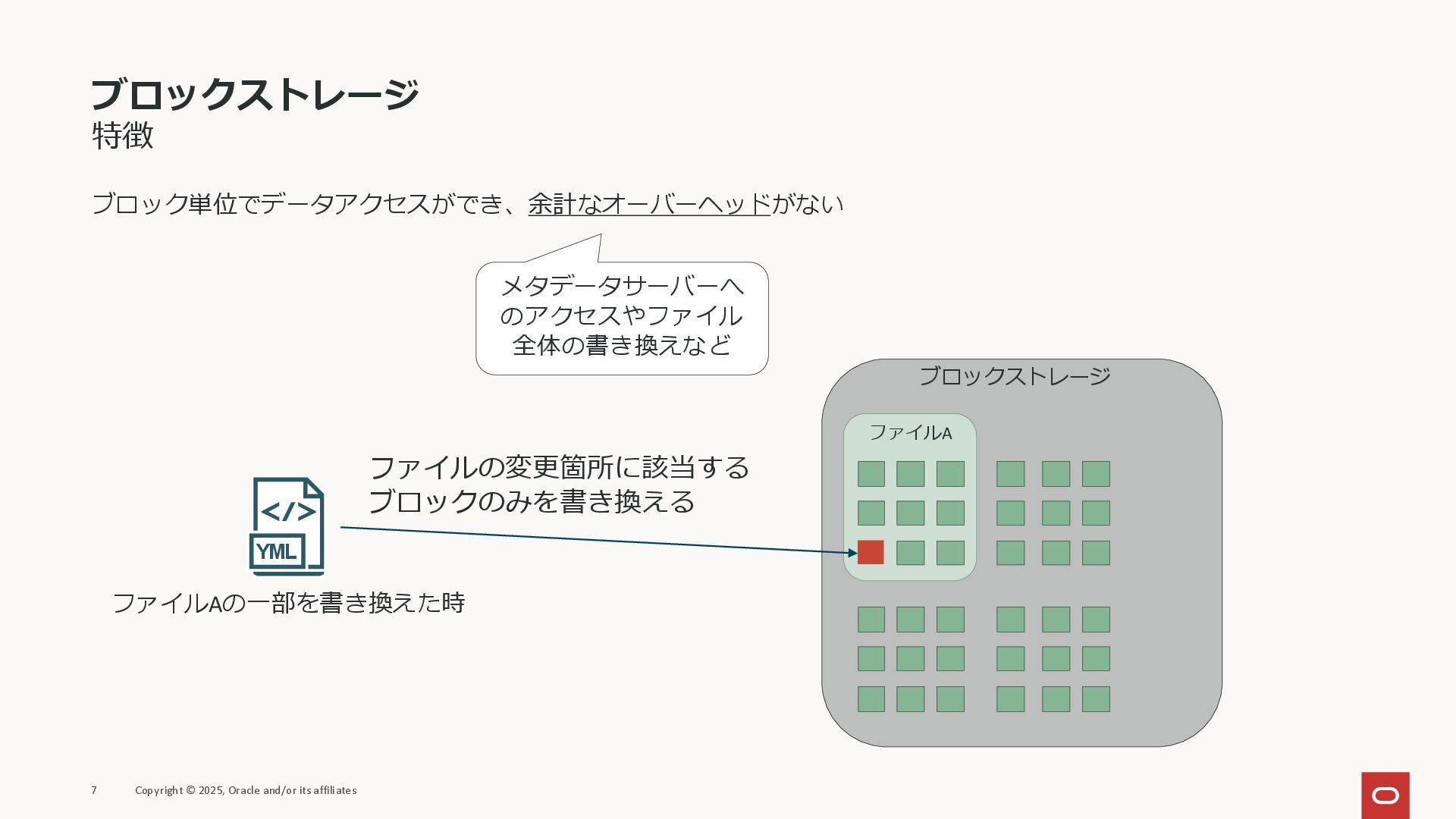
ブロックストレージ 特徴 ブロック単位でデータアクセスができ、余計なオーバーヘッドがない 7 Copyright © 2025, Oracle and/or its
affiliates ファイルの変更箇所に該当する ブロックのみを書き換える ファイルA ブロックストレージ メタデータサーバーへ のアクセスやファイル 全体の書き換えなど ファイルAの一部を書き換えた時
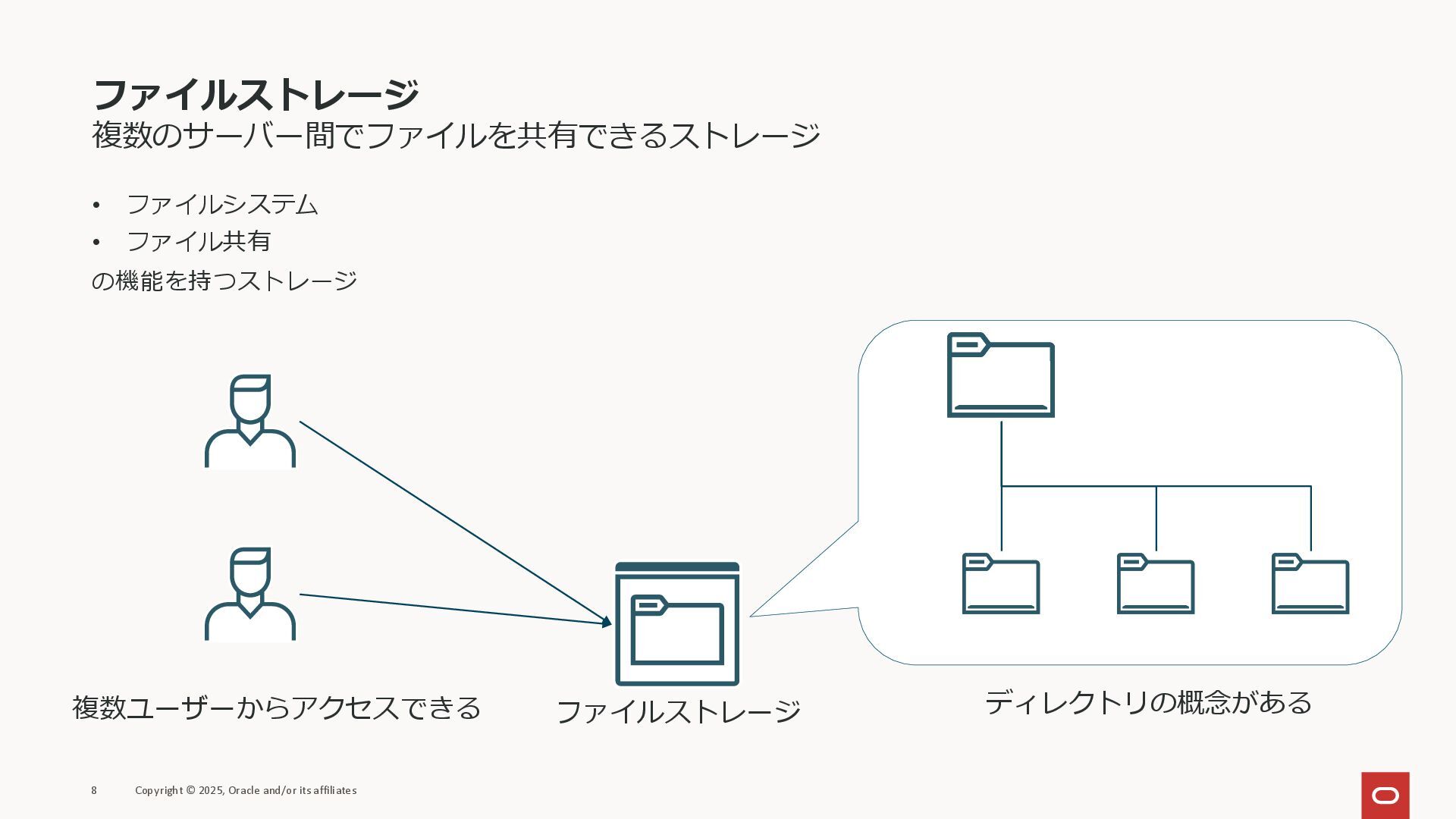
ファイルストレージ 複数のサーバー間でファイルを共有できるストレージ • ファイルシステム • ファイル共有 の機能を持つストレージ 8 Copyright ©
2025, Oracle and/or its affiliates ディレクトリの概念がある 複数ユーザーからアクセスできる ファイルストレージ
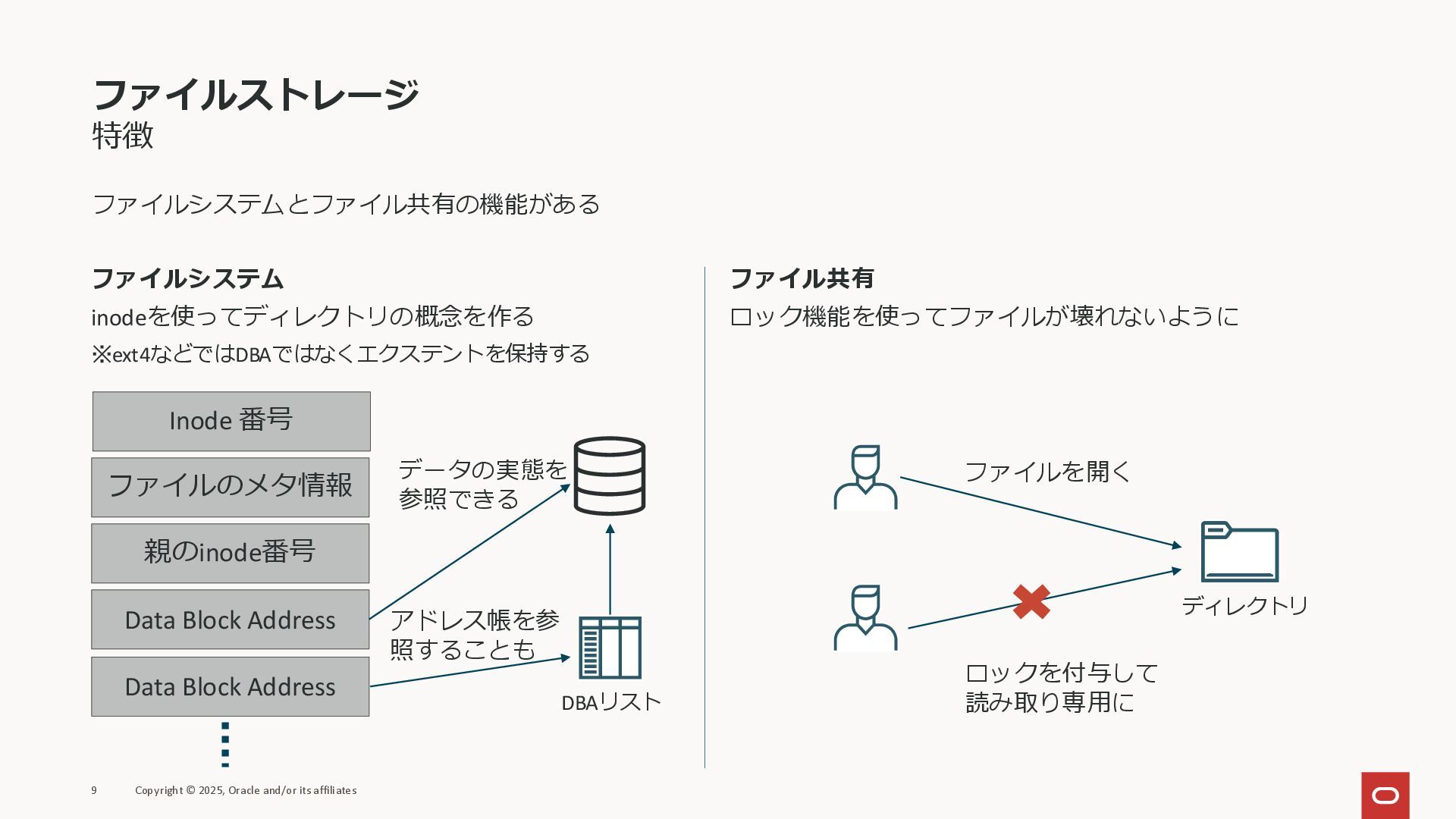
ファイルストレージ 特徴 ファイルシステムとファイル共有の機能がある 9 Copyright © 2025, Oracle and/or its
affiliates ファイルシステム inodeを使ってディレクトリの概念を作る ※ext4などではDBAではなくエクステントを保持する ファイル共有 ロック機能を使ってファイルが壊れないように Inode 番号 ファイルのメタ情報 親のinode番号 Data Block Address Data Block Address データの実態を 参照できる DBAリスト アドレス帳を参 照することも ファイルを開く ロックを付与して 読み取り専用に ディレクトリ
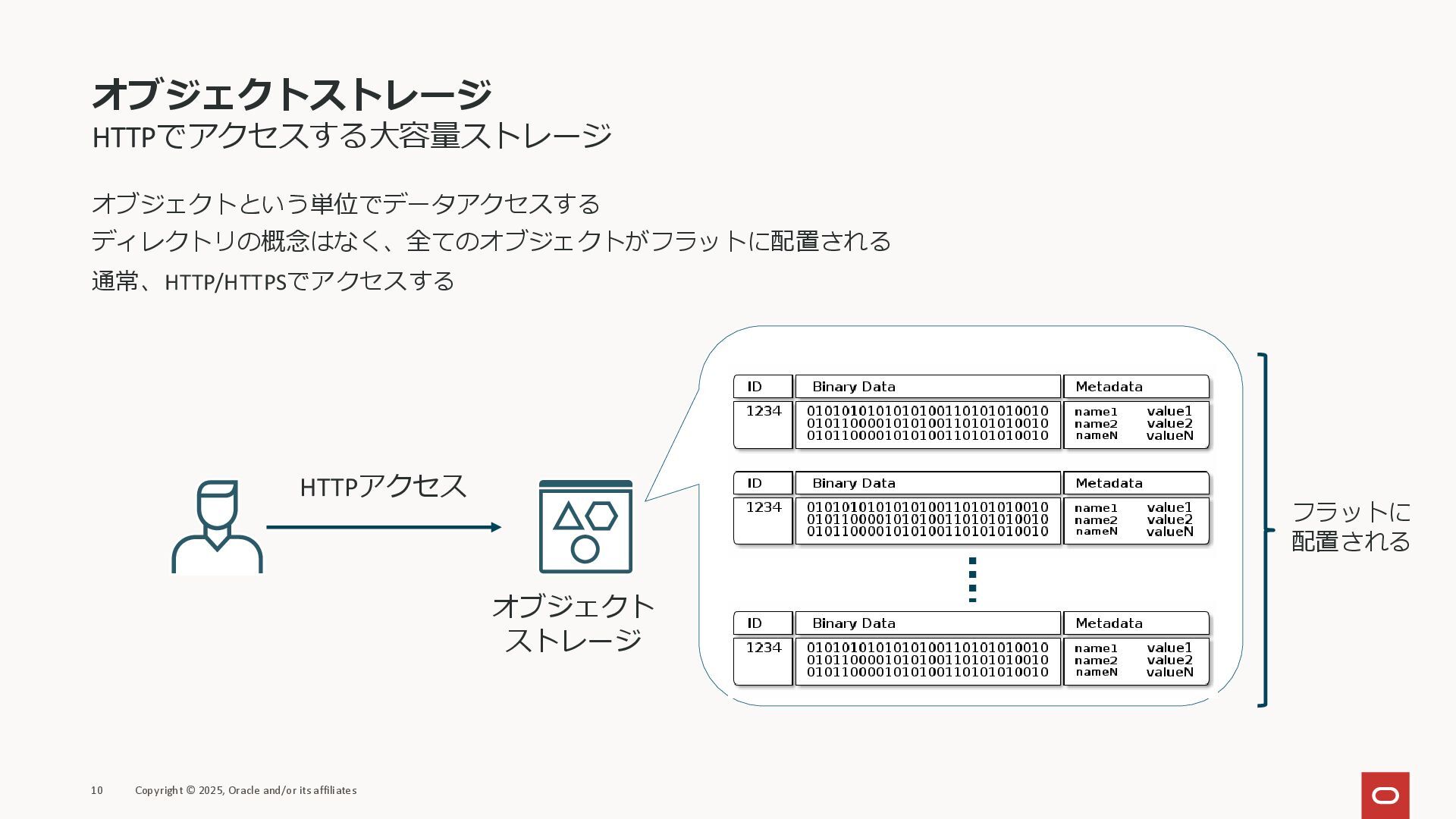
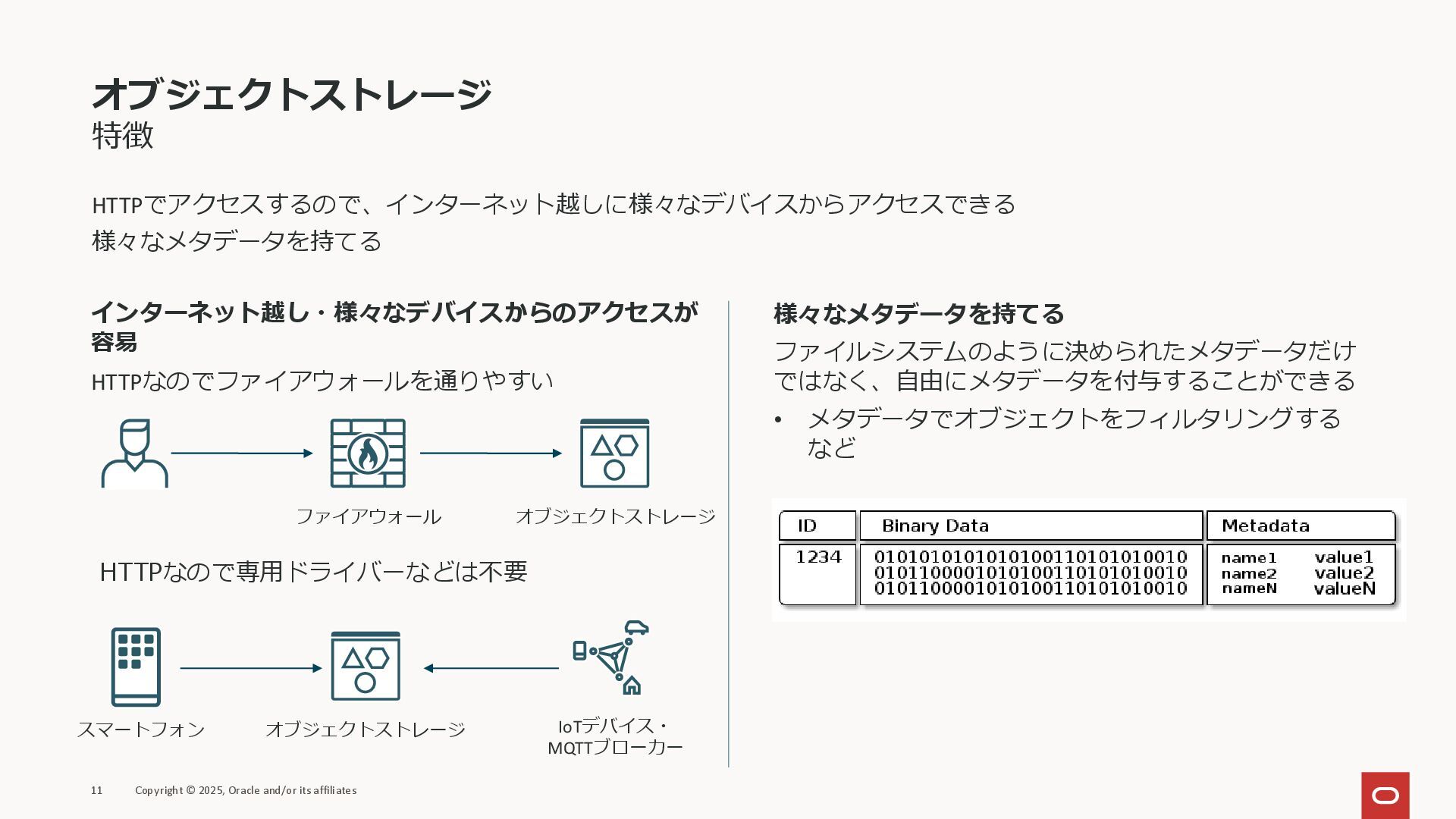
オブジェクトストレージ HTTPでアクセスする大容量ストレージ オブジェクトという単位でデータアクセスする ディレクトリの概念はなく、全てのオブジェクトがフラットに配置される 通常、HTTP/HTTPSでアクセスする 10 Copyright © 2025, Oracle
and/or its affiliates HTTPアクセス フラットに 配置される オブジェクト ストレージ
オブジェクトストレージ 特徴 HTTPでアクセスするので、インターネット越しに様々なデバイスからアクセスできる 様々なメタデータを持てる 11 Copyright © 2025, Oracle and/or
its affiliates インターネット越し・様々なデバイスからのアクセスが 容易 HTTPなのでファイアウォールを通りやすい 様々なメタデータを持てる ファイルシステムのように決められたメタデータだけ ではなく、自由にメタデータを付与することができる • メタデータでオブジェクトをフィルタリングする など ファイアウォール オブジェクトストレージ オブジェクトストレージ IoTデバイス・ MQTTブローカー スマートフォン HTTPなので専用ドライバーなどは不要
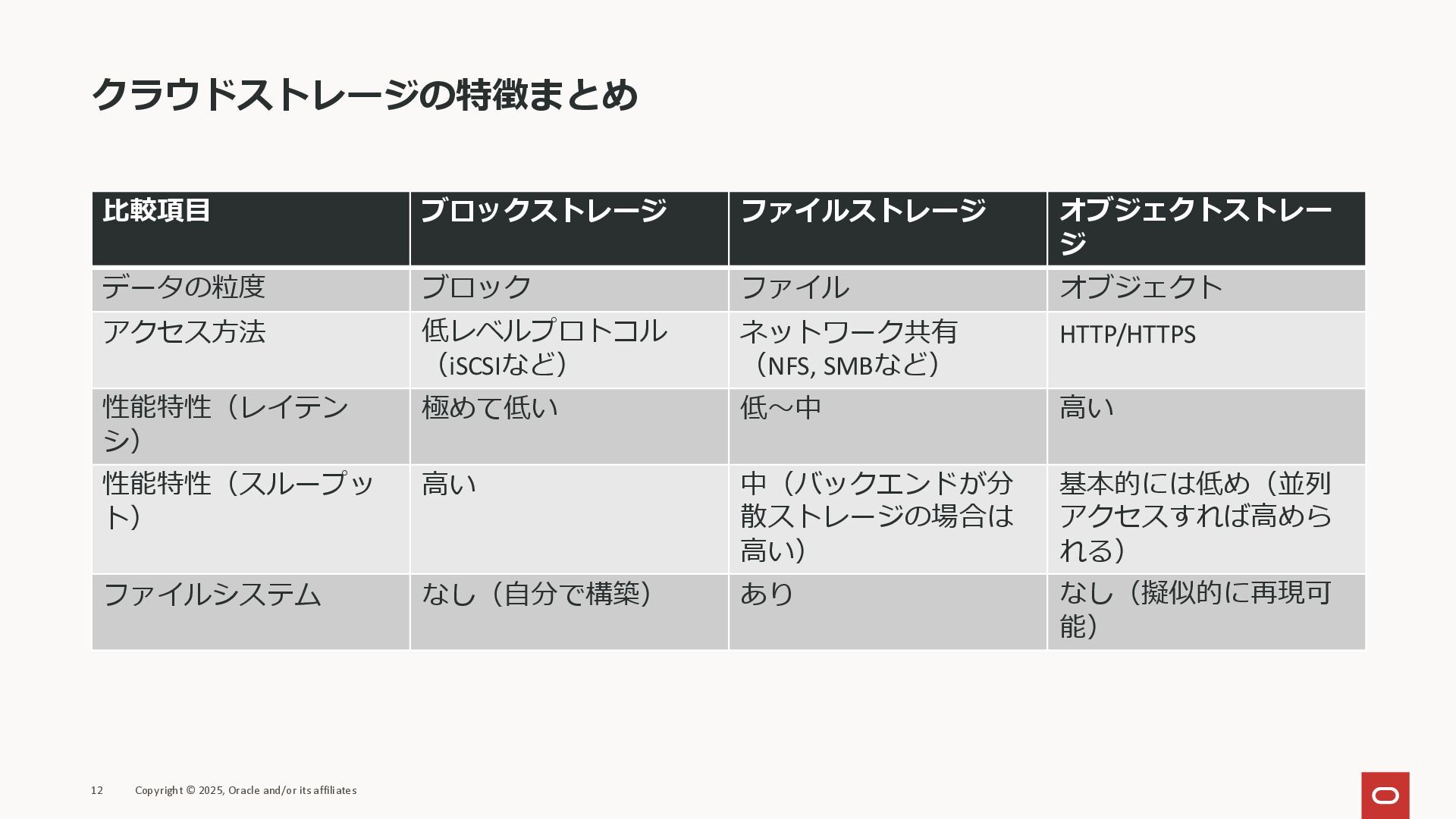
クラウドストレージの特徴まとめ 比較項目 ブロックストレージ ファイルストレージ オブジェクトストレー ジ データの粒度 ブロック ファイル オブジェクト
アクセス方法 低レベルプロトコル (iSCSIなど) ネットワーク共有 (NFS, SMBなど) HTTP/HTTPS 性能特性(レイテン シ) 極めて低い 低〜中 高い 性能特性(スループッ ト) 高い 中(バックエンドが分 散ストレージの場合は 高い) 基本的には低め(並列 アクセスすれば高めら れる) ファイルシステム なし(自分で構築) あり なし(擬似的に再現可 能) 12 Copyright © 2025, Oracle and/or its affiliates
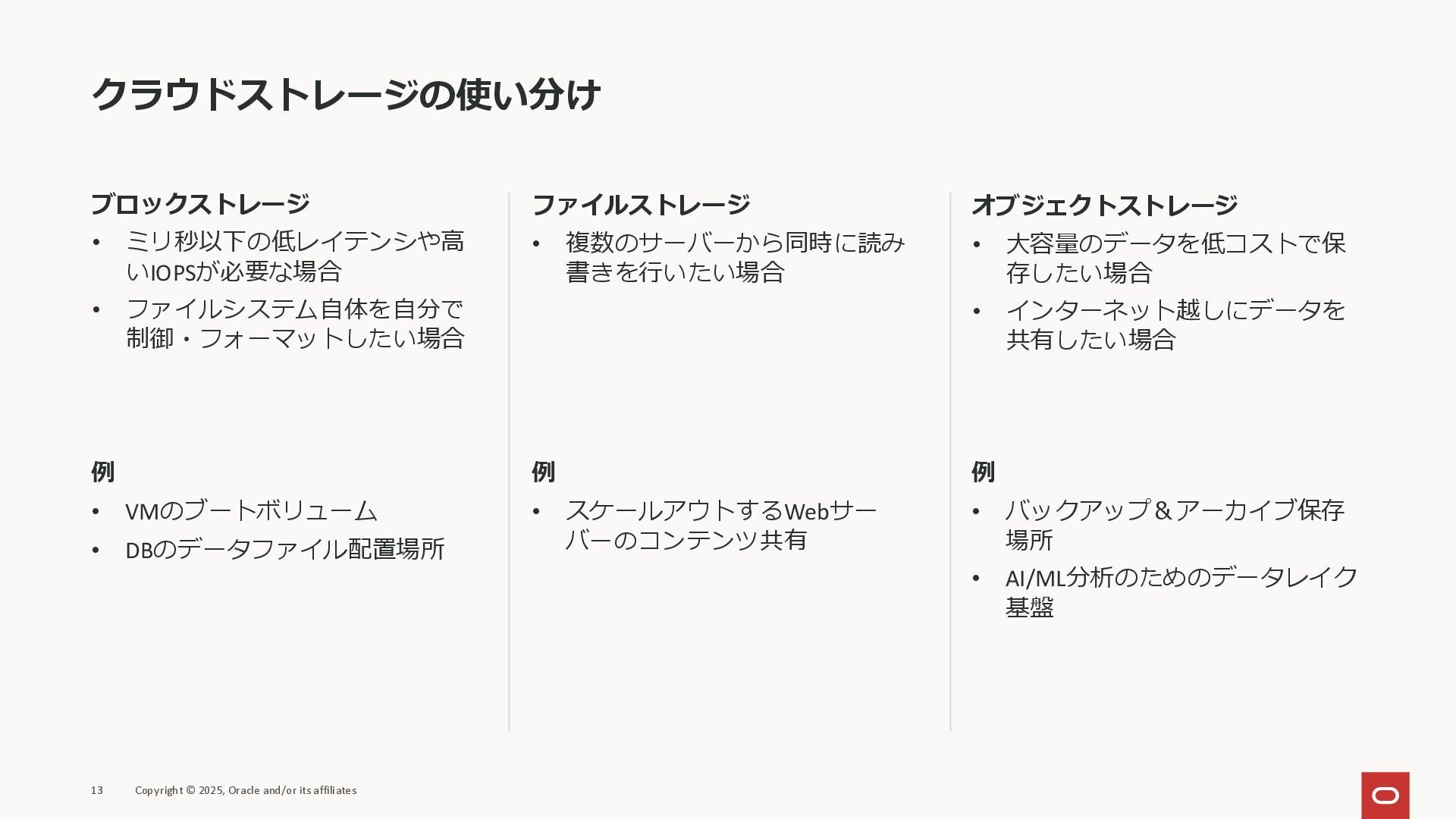
クラウドストレージの使い分け ブロックストレージ • ミリ秒以下の低レイテンシや高 いIOPSが必要な場合 • ファイルシステム自体を自分で 制御・フォーマットしたい場合 ファイルストレージ •
複数のサーバーから同時に読み 書きを行いたい場合 オブジェクトストレージ • 大容量のデータを低コストで保 存したい場合 • インターネット越しにデータを 共有したい場合 Copyright © 2025, Oracle and/or its affiliates 13 例 • VMのブートボリューム • DBのデータファイル配置場所 例 • スケールアウトするWebサー バーのコンテンツ共有 例 • バックアップ&アーカイブ保存 場所 • AI/ML分析のためのデータレイク 基盤
クラウドストレージの実装 ここまでそれぞれのクラウドストレージの特徴を説明してきましたが… プロダクトによって実装は結構異なります! なので、今回は • ブロックストレージ • ファイルストレージ • オブジェクトストレージ
の全てを提供できる、Cephを代表として説明します また、近年のAIブームに乗っかり、AIの学習データ配置場所に使われることが多いLustreも説明します(Lustreはファ イルストレージです) 14 Copyright © 2025, Oracle and/or its affiliates
Ceph概要
Cephとは • ブロックストレージ • ファイルストレージ • オブジェクトストレージ を提供する、統合ストレージ基盤 複数のノードでクラスタを構成し、データは複数のノードに複製する Kubernetes上にデプロイ・管理するためのオペレーター(Rook)もある
16 Copyright © 2025, Oracle and/or its affiliates
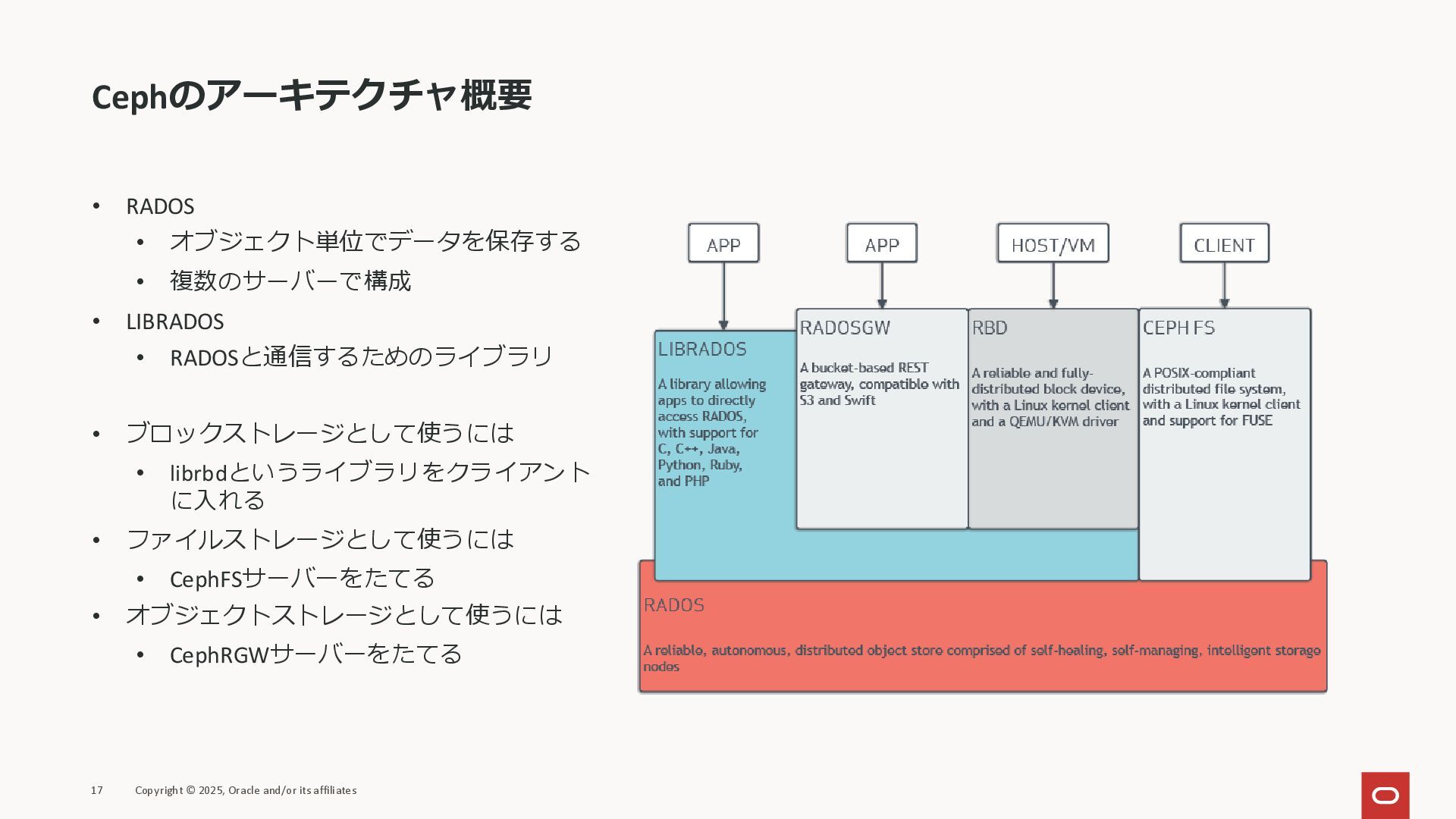
Cephのアーキテクチャ概要 • RADOS • オブジェクト単位でデータを保存する • 複数のサーバーで構成 • LIBRADOS •
RADOSと通信するためのライブラリ • ブロックストレージとして使うには • librbdというライブラリをクライアント に入れる • ファイルストレージとして使うには • CephFSサーバーをたてる • オブジェクトストレージとして使うには • CephRGWサーバーをたてる 17 Copyright © 2025, Oracle and/or its affiliates
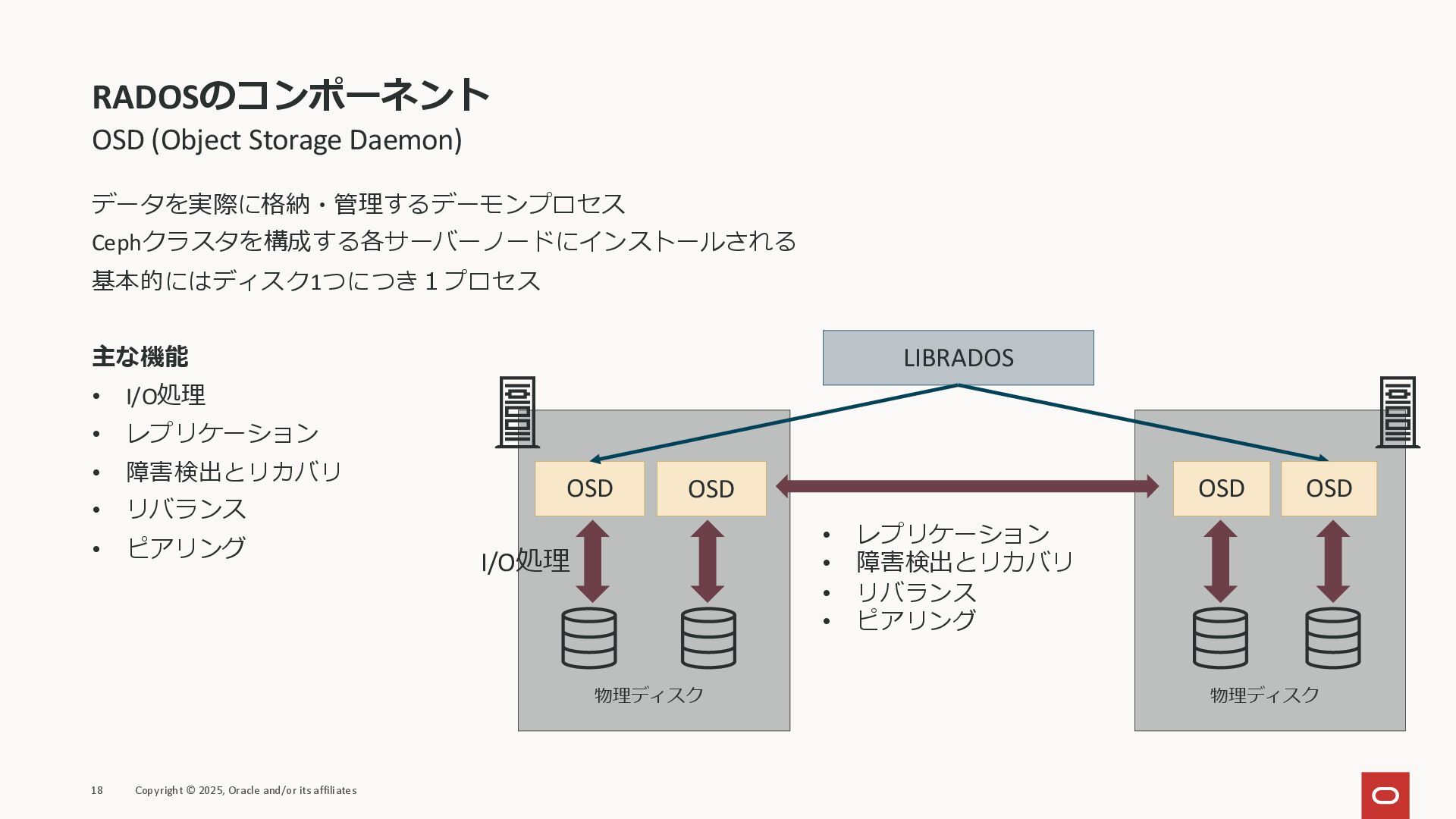
RADOSのコンポーネント OSD (Object Storage Daemon) データを実際に格納・管理するデーモンプロセス Cephクラスタを構成する各サーバーノードにインストールされる 基本的にはディスク1つにつき1プロセス 主な機能 •
I/O処理 • レプリケーション • 障害検出とリカバリ • リバランス • ピアリング 18 Copyright © 2025, Oracle and/or its affiliates LIBRADOS OSD OSD 物理ディスク 物理ディスク I/O処理 • レプリケーション • 障害検出とリカバリ • リバランス • ピアリング OSD OSD
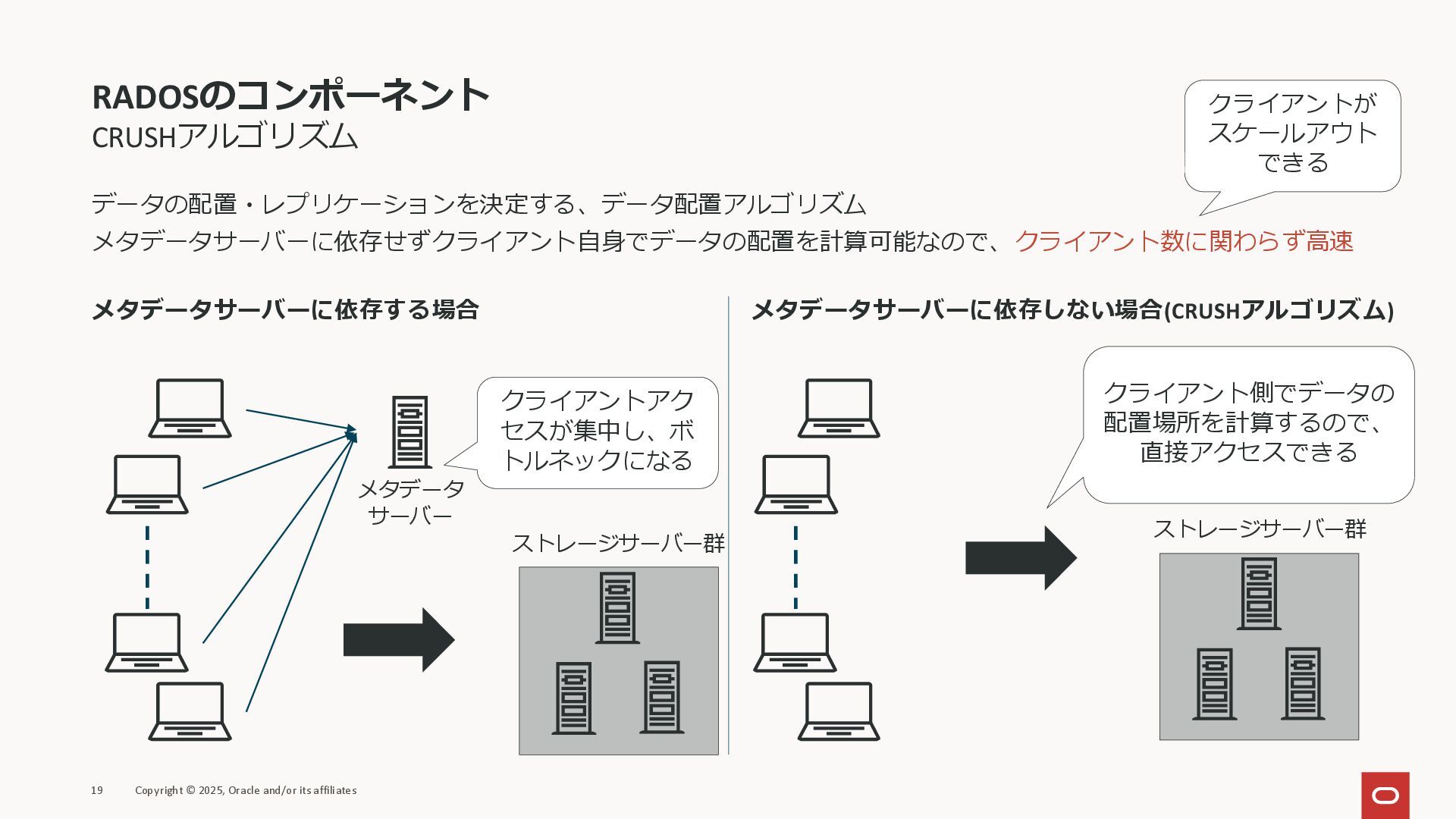
メタデータサーバーに依存する場合 RADOSのコンポーネント CRUSHアルゴリズム データの配置・レプリケーションを決定する、データ配置アルゴリズム メタデータサーバーに依存せずクライアント自身でデータの配置を計算可能なので、クライアント数に関わらず高速 19 Copyright © 2025, Oracle
and/or its affiliates メタデータサーバーに依存しない場合(CRUSHアルゴリズム) メタデータ サーバー ストレージサーバー群 クライアントアク セスが集中し、ボ トルネックになる ストレージサーバー群 クライアント側でデータの 配置場所を計算するので、 直接アクセスできる クライアントが スケールアウト できる
RADOSのコンポーネント Pool / Placement Group (PG) Pool 目的別にRADOSのストレージを分割する論理グループ SSDを使っているもの →
ssd-pool CephFS用 → cephfs-pool レプリケーション数が5のもの→ replication-5-pool など Placement Group (PG) Poolで決められたレプリケーション数を守るためのOSDのグループ レプリケーション数3の場合、[OSD#1 (Primary), OSD#2, OSD#3]など 20 Copyright © 2025, Oracle and/or its affiliates PG1 PG2 PG3 Pool
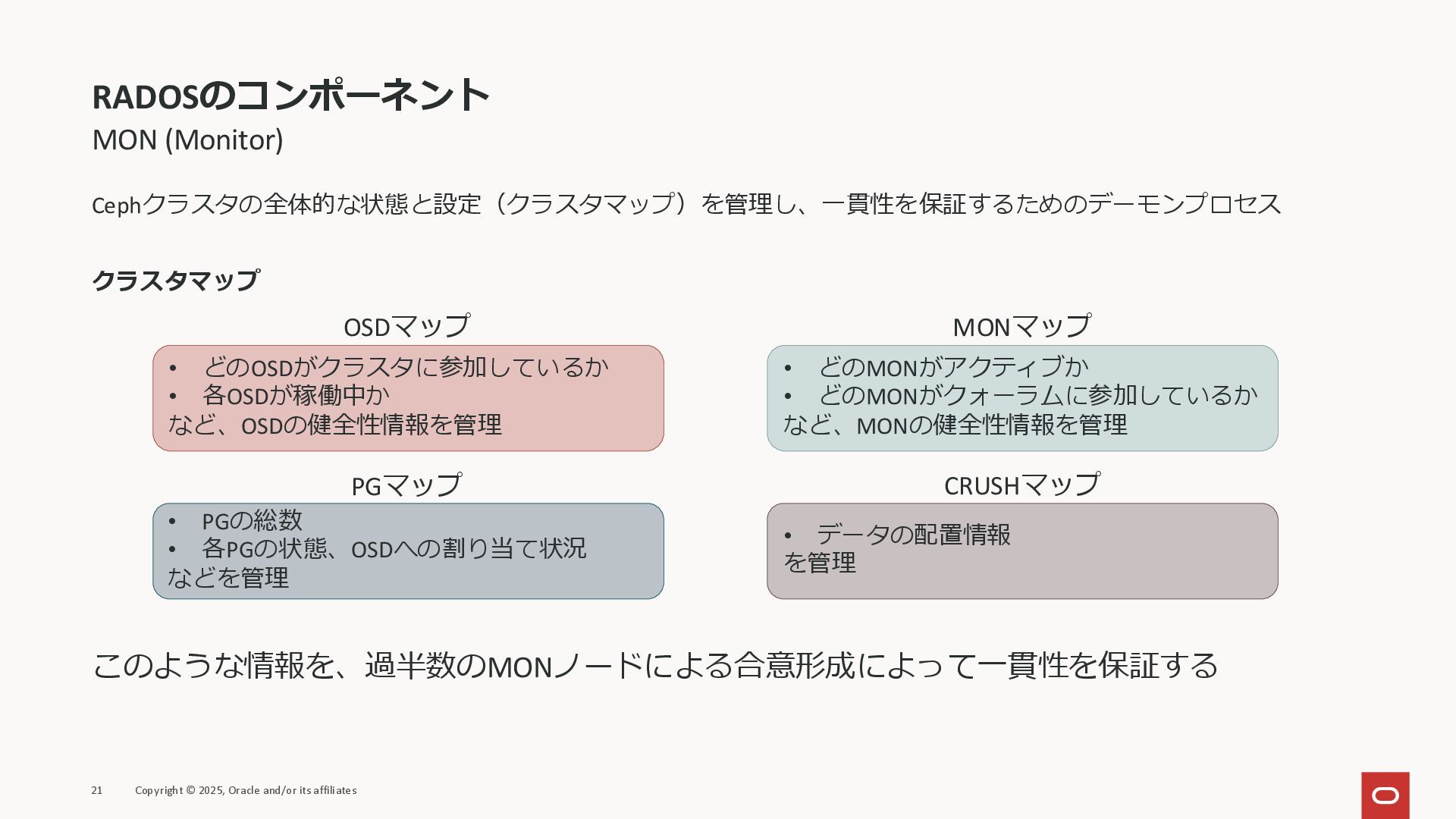
RADOSのコンポーネント MON (Monitor) Cephクラスタの全体的な状態と設定(クラスタマップ)を管理し、一貫性を保証するためのデーモンプロセス クラスタマップ 21 Copyright © 2025, Oracle
and/or its affiliates • どのOSDがクラスタに参加しているか • 各OSDが稼働中か など、OSDの健全性情報を管理 • PGの総数 • 各PGの状態、OSDへの割り当て状況 などを管理 • どのMONがアクティブか • どのMONがクォーラムに参加しているか など、MONの健全性情報を管理 • データの配置情報 を管理 OSDマップ MONマップ PGマップ CRUSHマップ このような情報を、過半数のMONノードによる合意形成によって一貫性を保証する
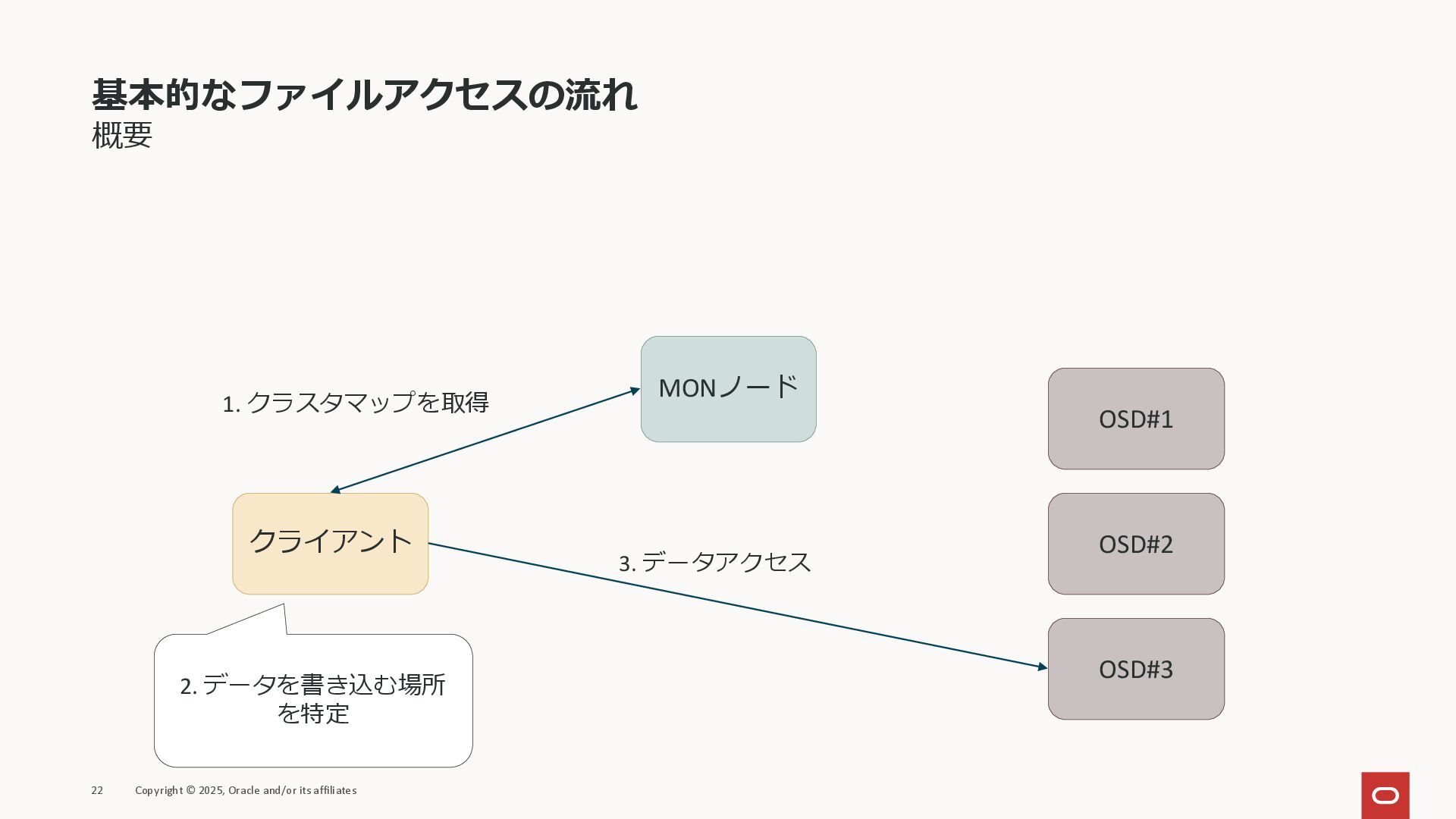
基本的なファイルアクセスの流れ 概要 22 Copyright © 2025, Oracle and/or its affiliates
クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 2. データを書き込む場所 を特定 3. データアクセス
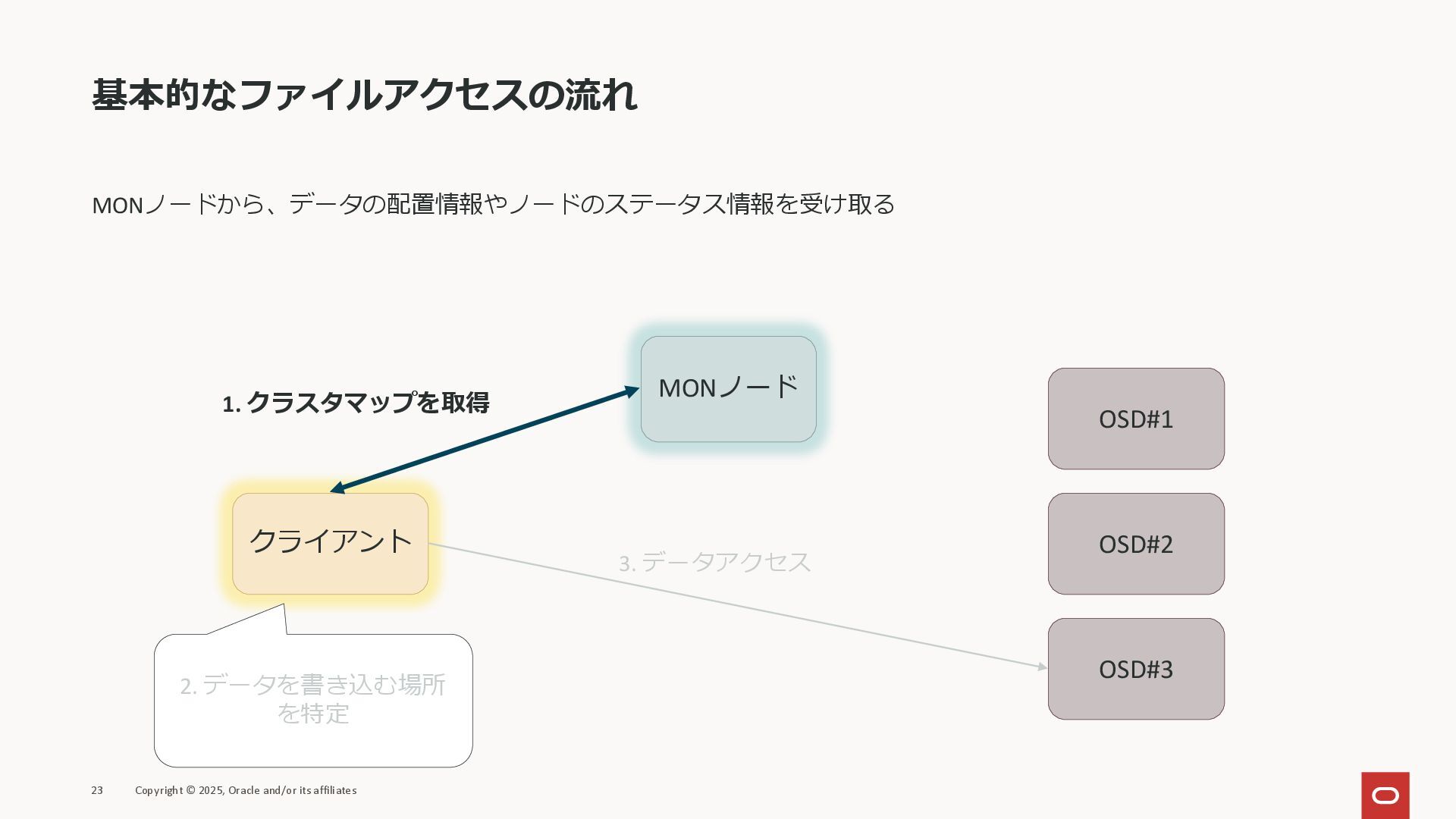
基本的なファイルアクセスの流れ MONノードから、データの配置情報やノードのステータス情報を受け取る 23 Copyright © 2025, Oracle and/or its affiliates
クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 2. データを書き込む場所 を特定 3. データアクセス
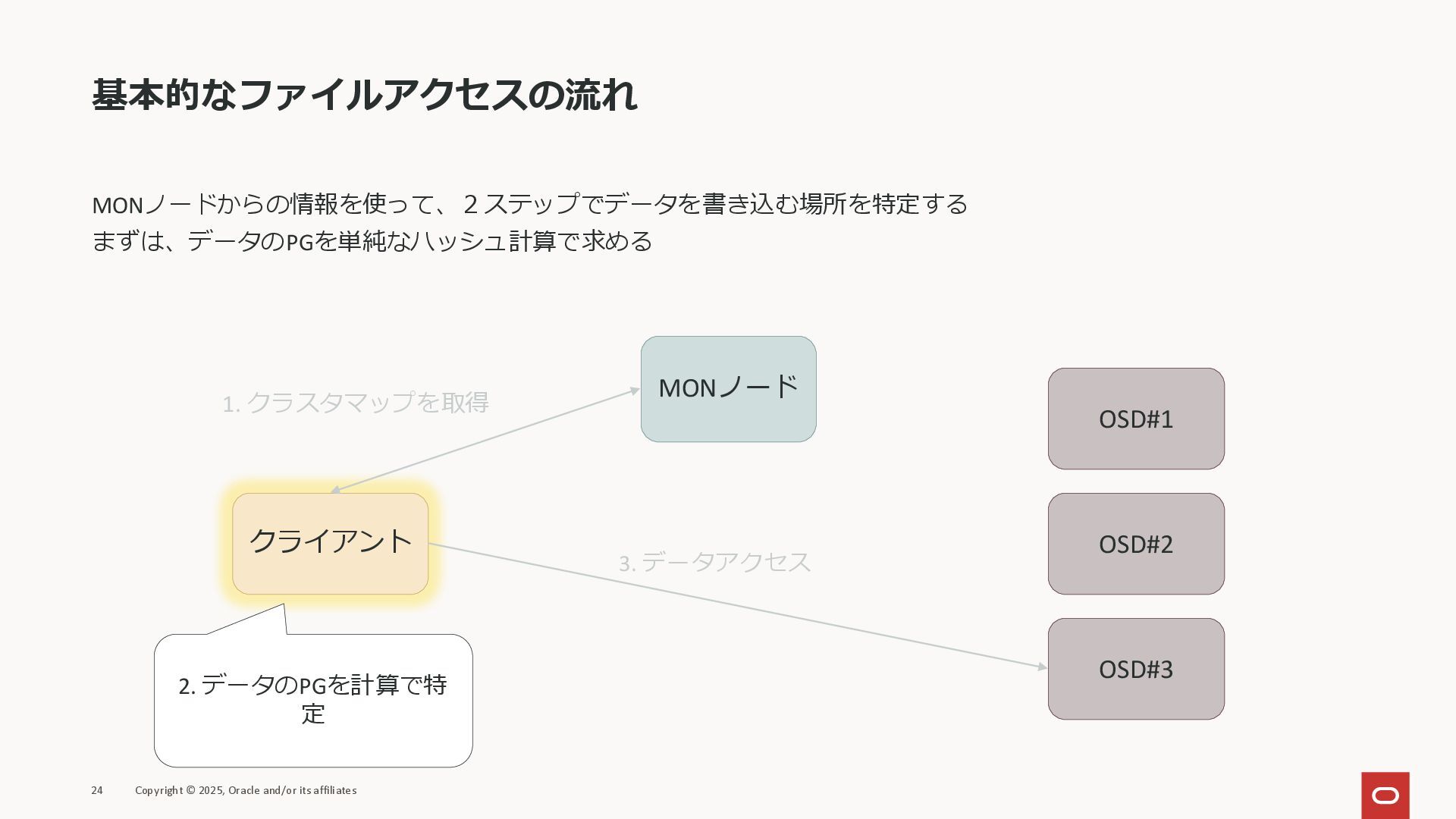
基本的なファイルアクセスの流れ MONノードからの情報を使って、2ステップでデータを書き込む場所を特定する まずは、データのPGを単純なハッシュ計算で求める 24 Copyright © 2025, Oracle and/or its
affiliates クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 2. データのPGを計算で特 定 3. データアクセス
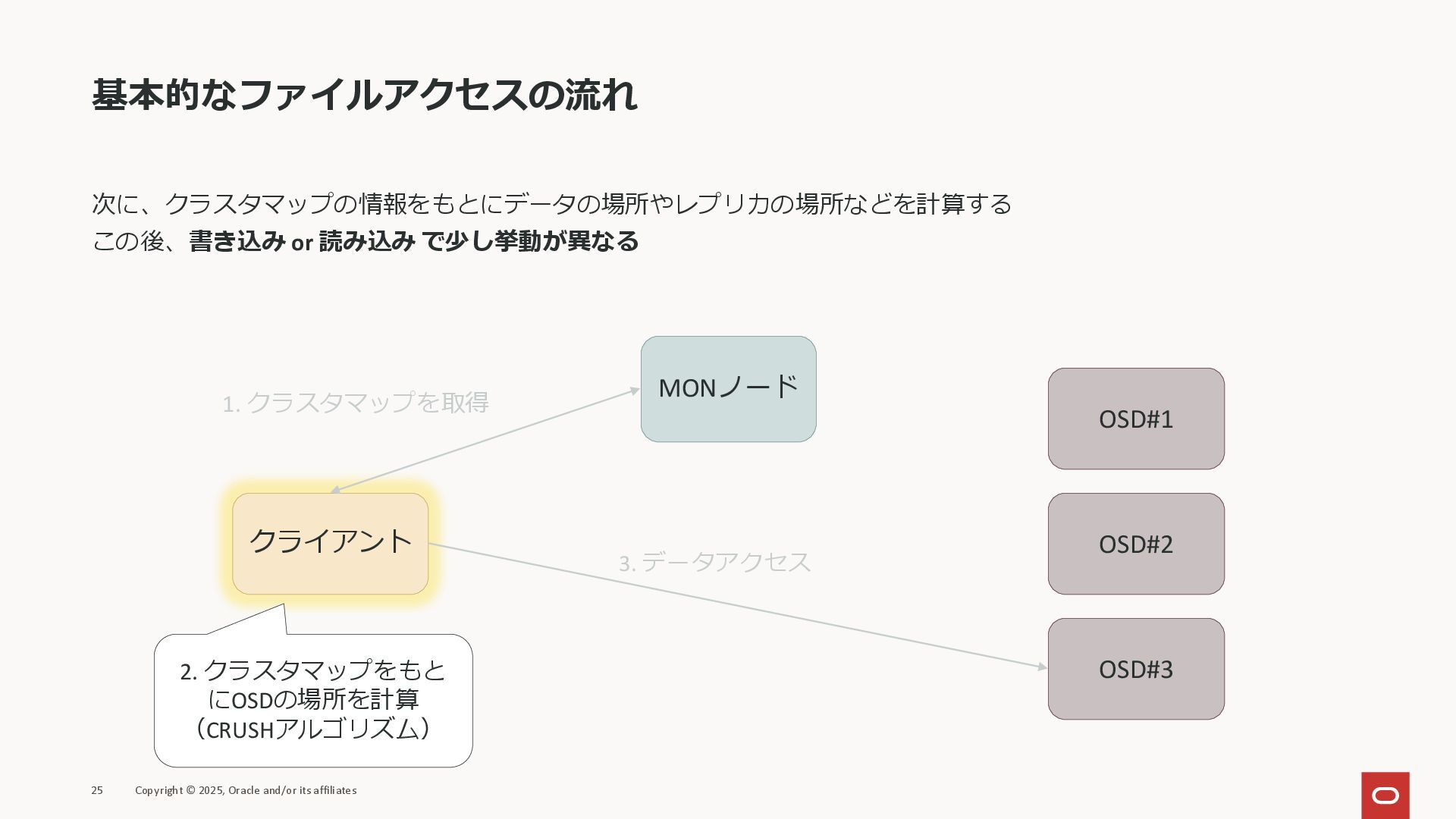
基本的なファイルアクセスの流れ 次に、クラスタマップの情報をもとにデータの場所やレプリカの場所などを計算する この後、書き込み or 読み込み で少し挙動が異なる 25 Copyright © 2025,
Oracle and/or its affiliates クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 2. クラスタマップをもと にOSDの場所を計算 (CRUSHアルゴリズム) 3. データアクセス
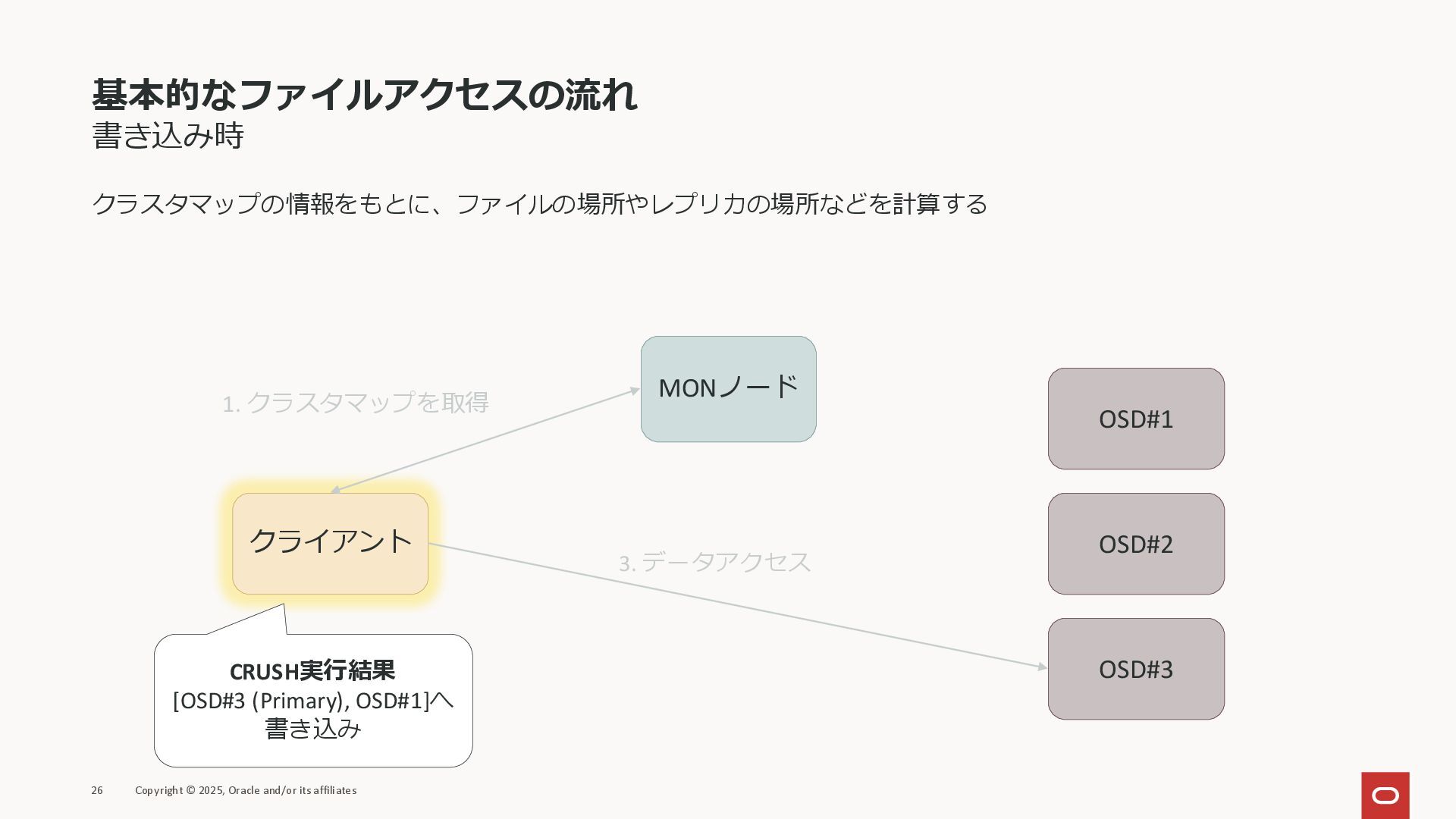
基本的なファイルアクセスの流れ 書き込み時 クラスタマップの情報をもとに、ファイルの場所やレプリカの場所などを計算する 26 Copyright © 2025, Oracle and/or its
affiliates クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 CRUSH実行結果 [OSD#3 (Primary), OSD#1]へ 書き込み 3. データアクセス
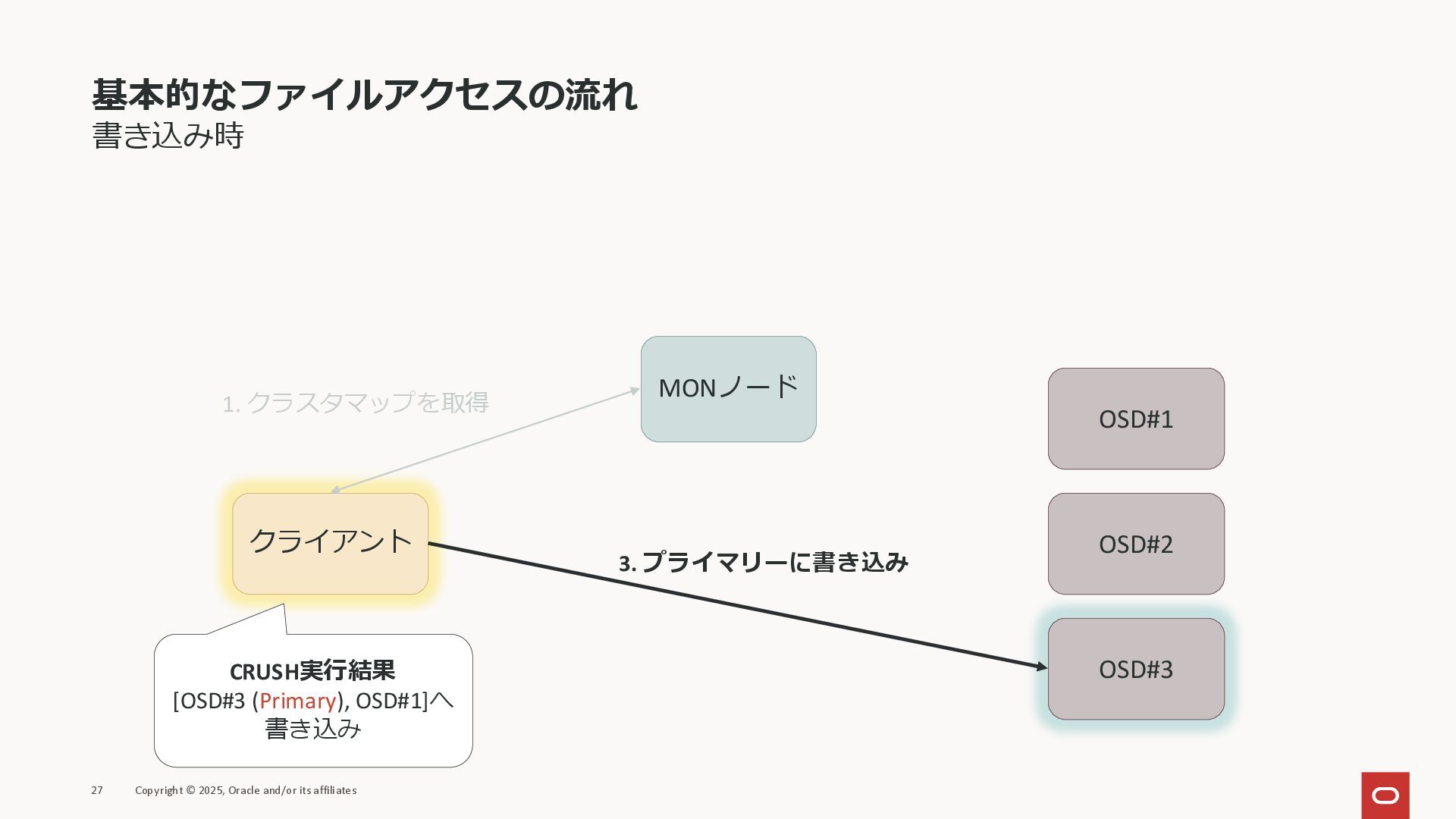
基本的なファイルアクセスの流れ 書き込み時 27 Copyright © 2025, Oracle and/or its affiliates
クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 CRUSH実行結果 [OSD#3 (Primary), OSD#1]へ 書き込み 3. プライマリーに書き込み
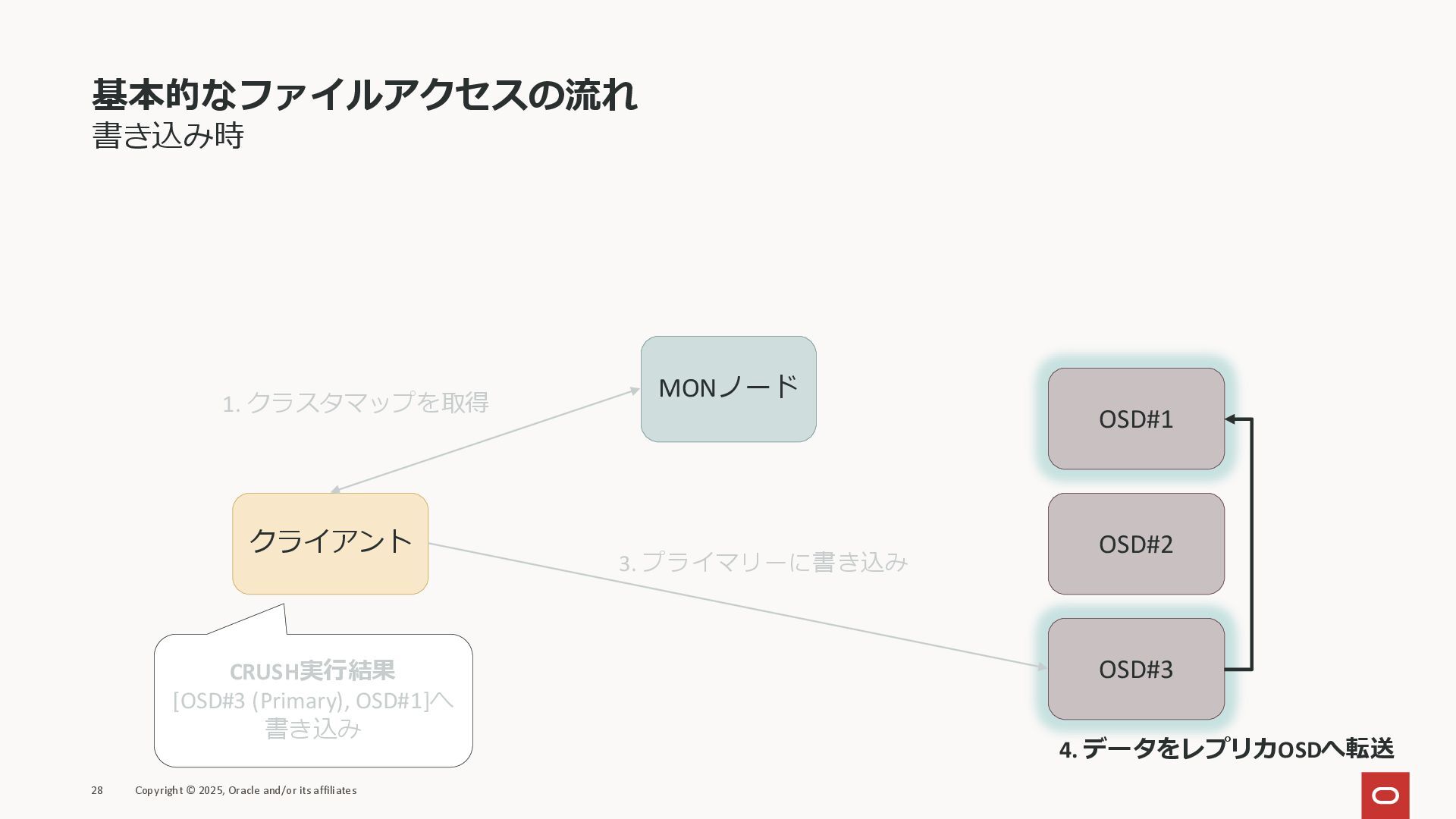
基本的なファイルアクセスの流れ 書き込み時 28 Copyright © 2025, Oracle and/or its affiliates
クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 CRUSH実行結果 [OSD#3 (Primary), OSD#1]へ 書き込み 3. プライマリーに書き込み 4. データをレプリカOSDへ転送
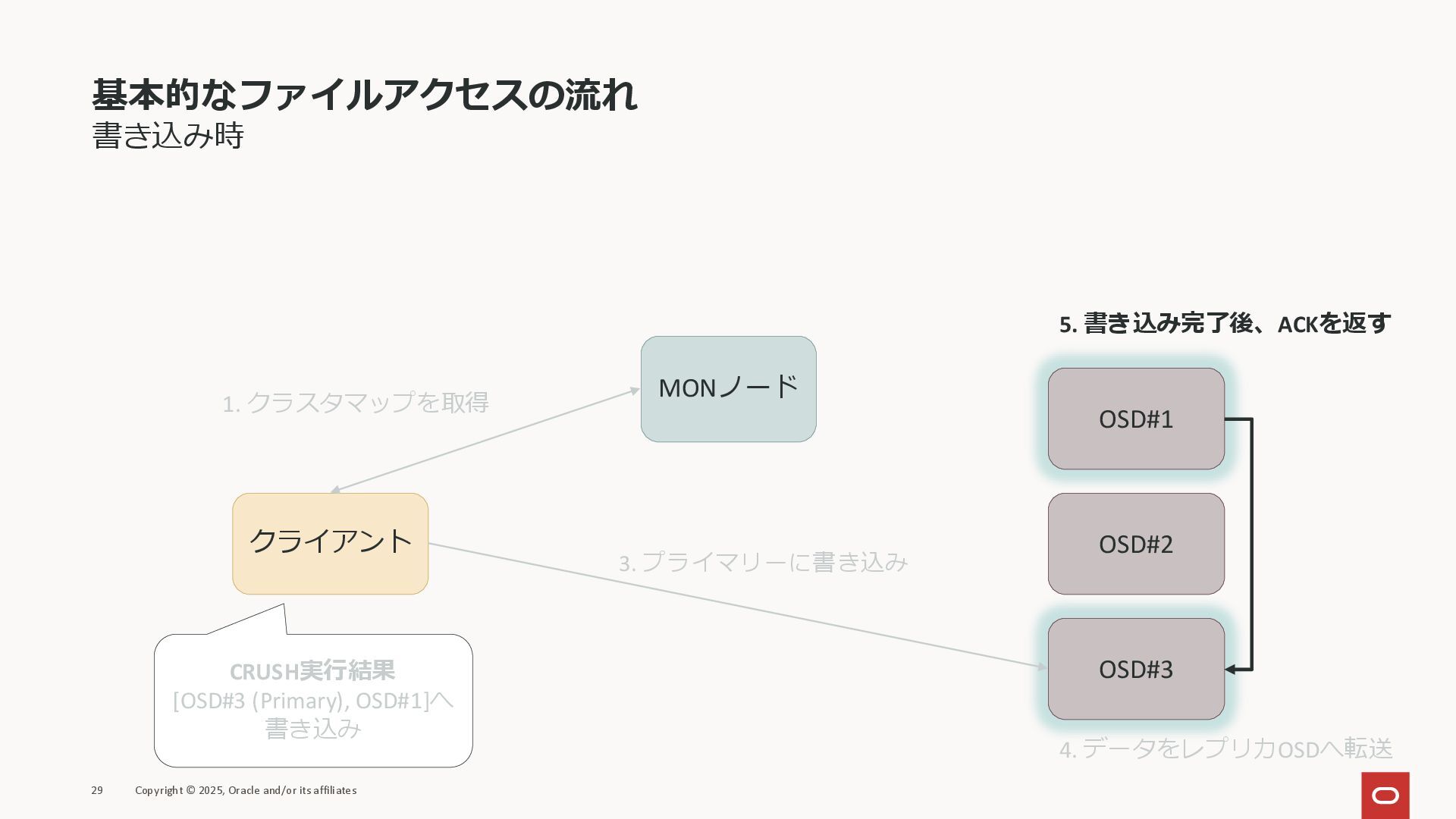
基本的なファイルアクセスの流れ 書き込み時 29 Copyright © 2025, Oracle and/or its affiliates
クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 CRUSH実行結果 [OSD#3 (Primary), OSD#1]へ 書き込み 3. プライマリーに書き込み 5. 書き込み完了後、ACKを返す 4. データをレプリカOSDへ転送
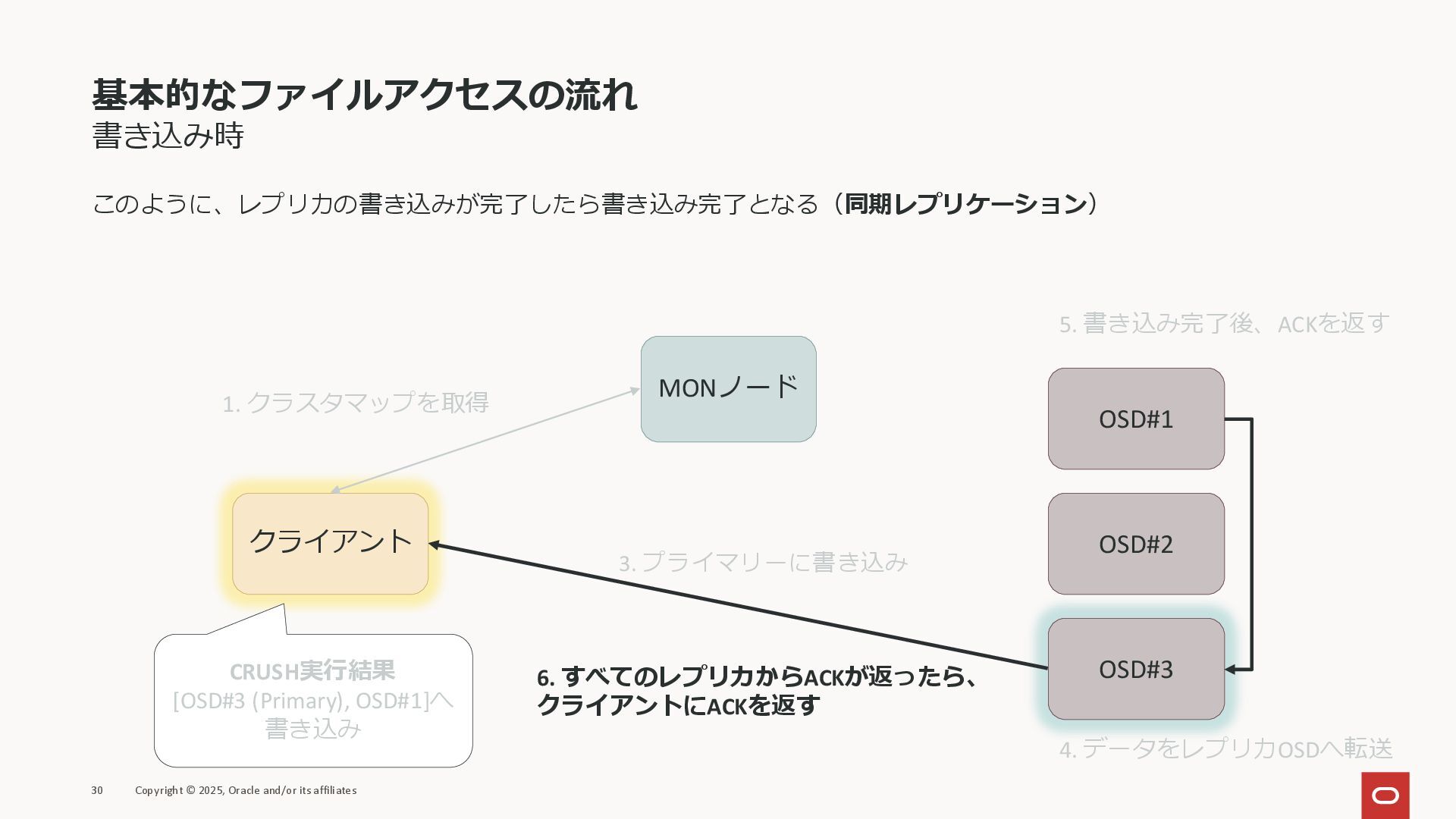
基本的なファイルアクセスの流れ 書き込み時 このように、レプリカの書き込みが完了したら書き込み完了となる(同期レプリケーション) 30 Copyright © 2025, Oracle and/or its
affiliates クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 CRUSH実行結果 [OSD#3 (Primary), OSD#1]へ 書き込み 3. プライマリーに書き込み 5. 書き込み完了後、ACKを返す 4. データをレプリカOSDへ転送 6. すべてのレプリカからACKが返ったら、 クライアントにACKを返す
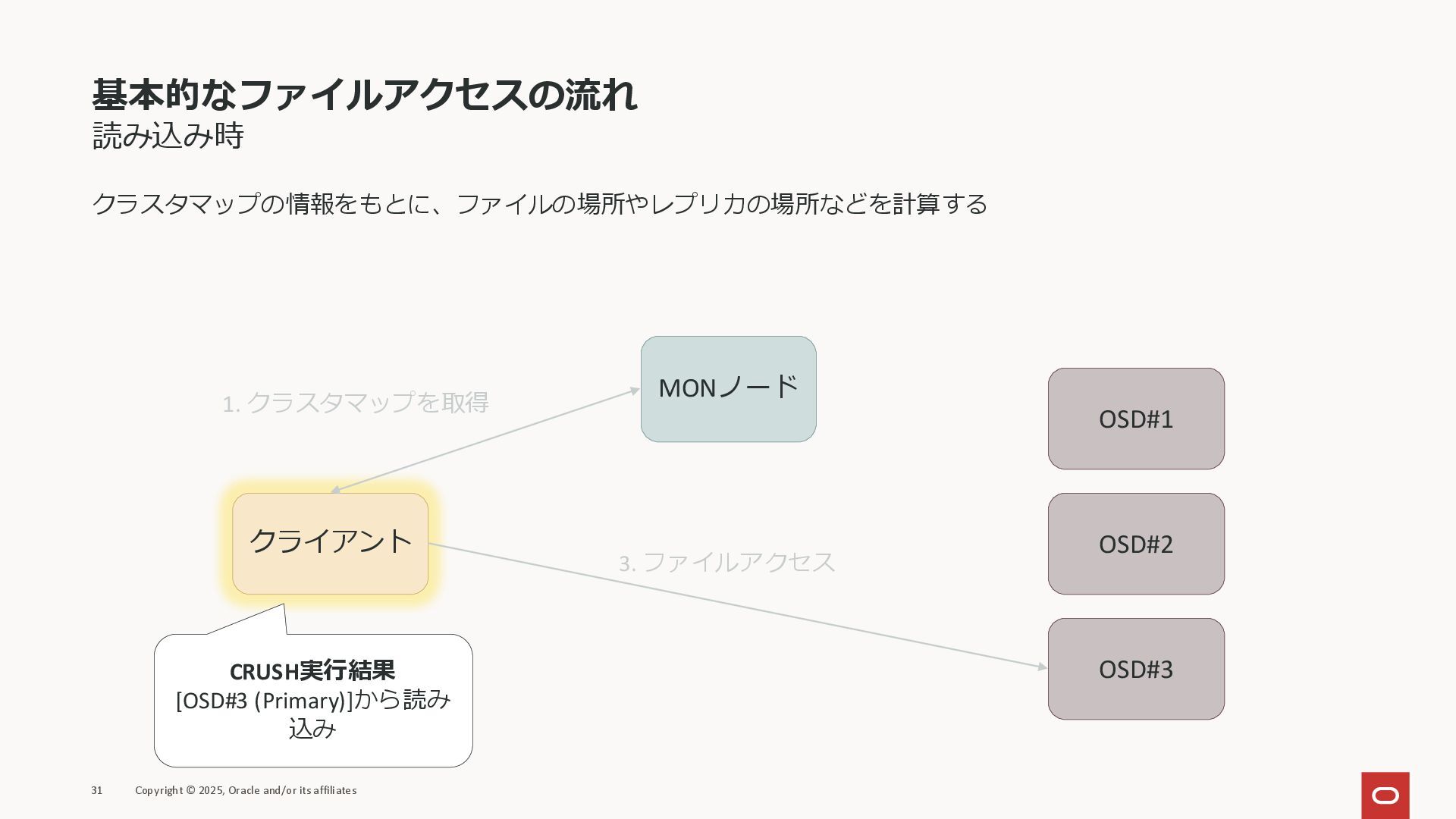
基本的なファイルアクセスの流れ 読み込み時 クラスタマップの情報をもとに、ファイルの場所やレプリカの場所などを計算する 31 Copyright © 2025, Oracle and/or its
affiliates クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 CRUSH実行結果 [OSD#3 (Primary)]から読み 込み 3. ファイルアクセス
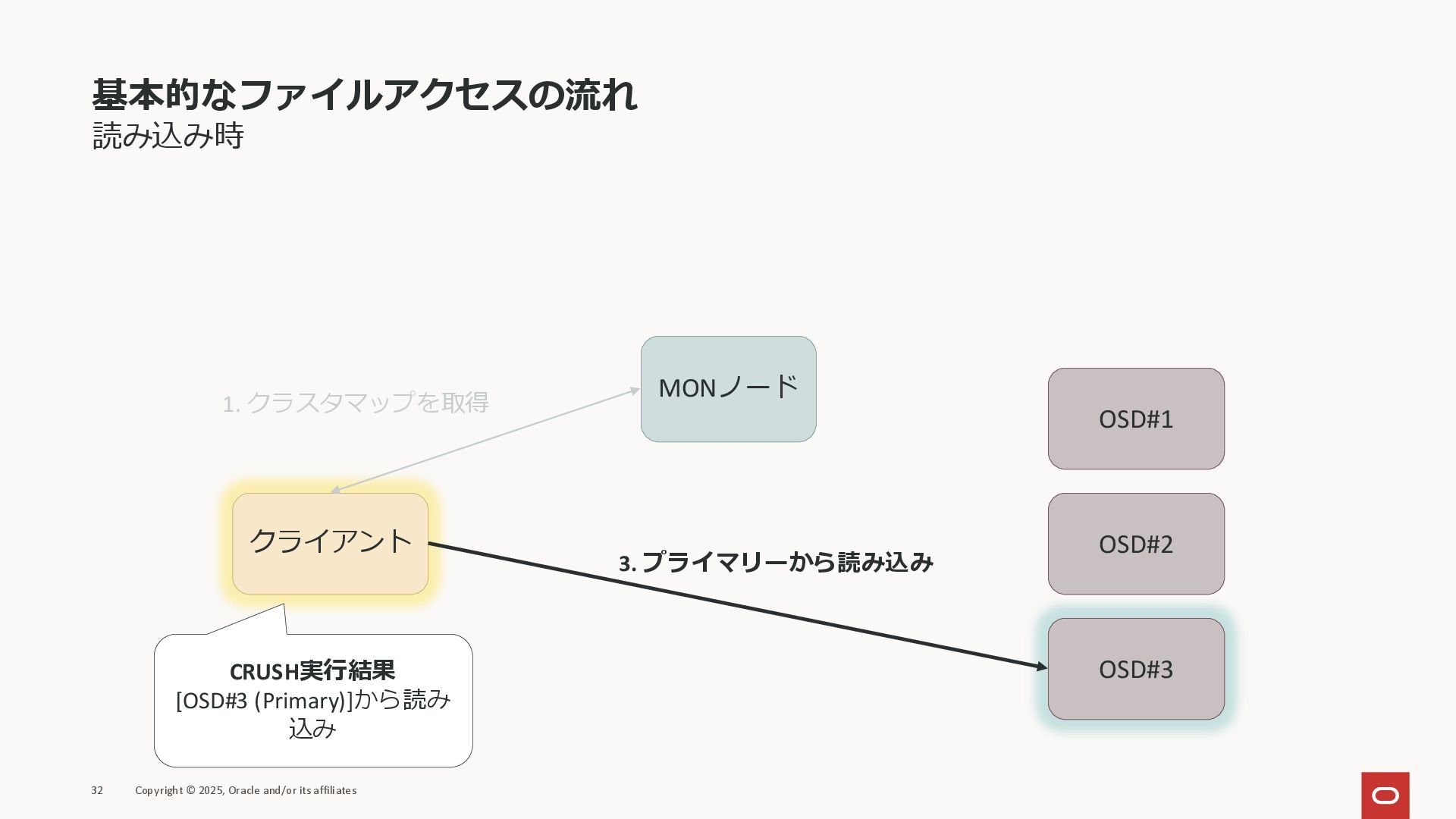
基本的なファイルアクセスの流れ 読み込み時 32 Copyright © 2025, Oracle and/or its affiliates
クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 3. プライマリーから読み込み CRUSH実行結果 [OSD#3 (Primary)]から読み 込み
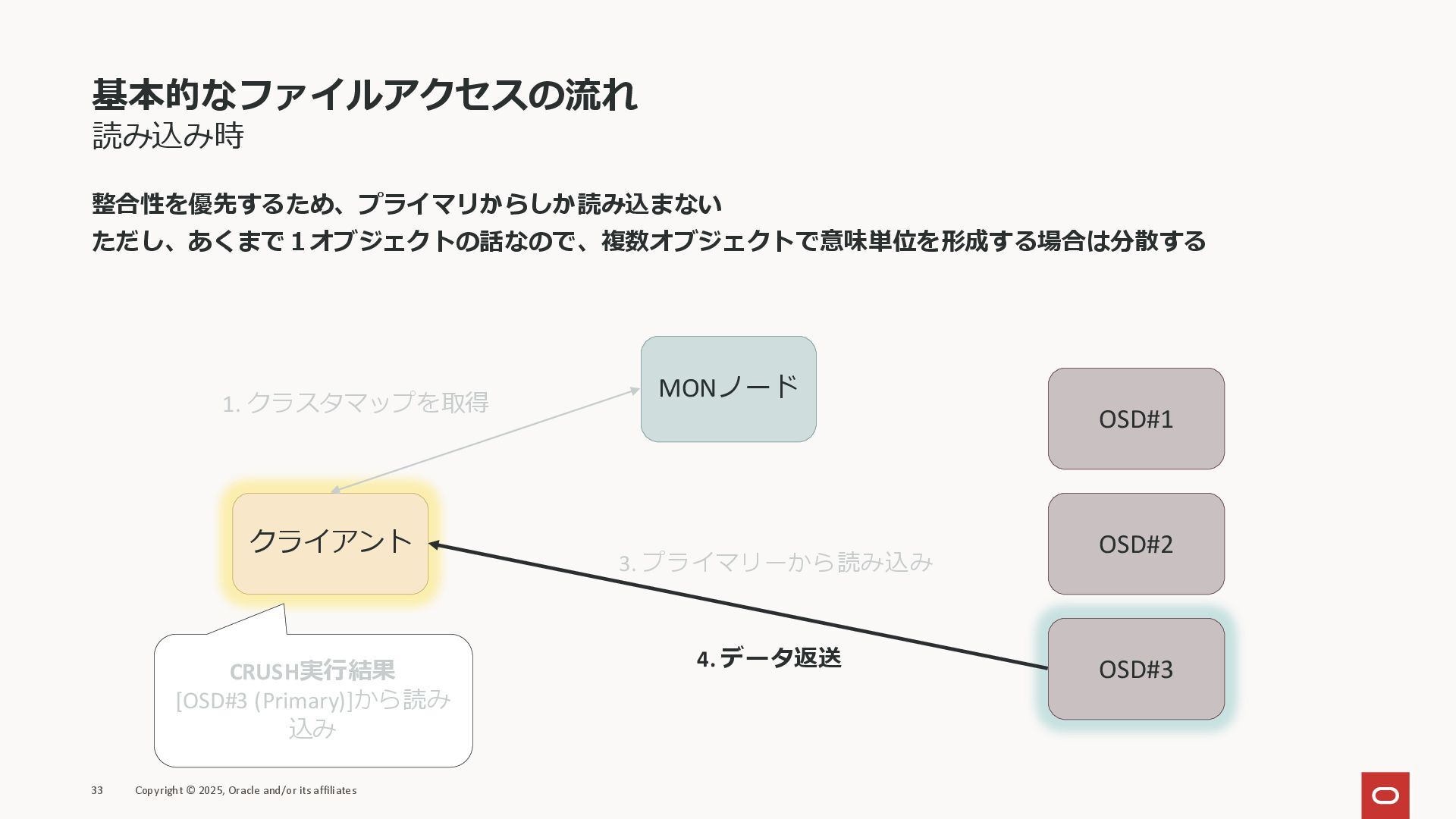
基本的なファイルアクセスの流れ 読み込み時 整合性を優先するため、プライマリからしか読み込まない ただし、あくまで1オブジェクトの話なので、複数オブジェクトで意味単位を形成する場合は分散する 33 Copyright © 2025, Oracle and/or
its affiliates クライアント MONノード OSD#1 OSD#2 OSD#3 1. クラスタマップを取得 3. プライマリーから読み込み CRUSH実行結果 [OSD#3 (Primary)]から読み 込み 4. データ返送
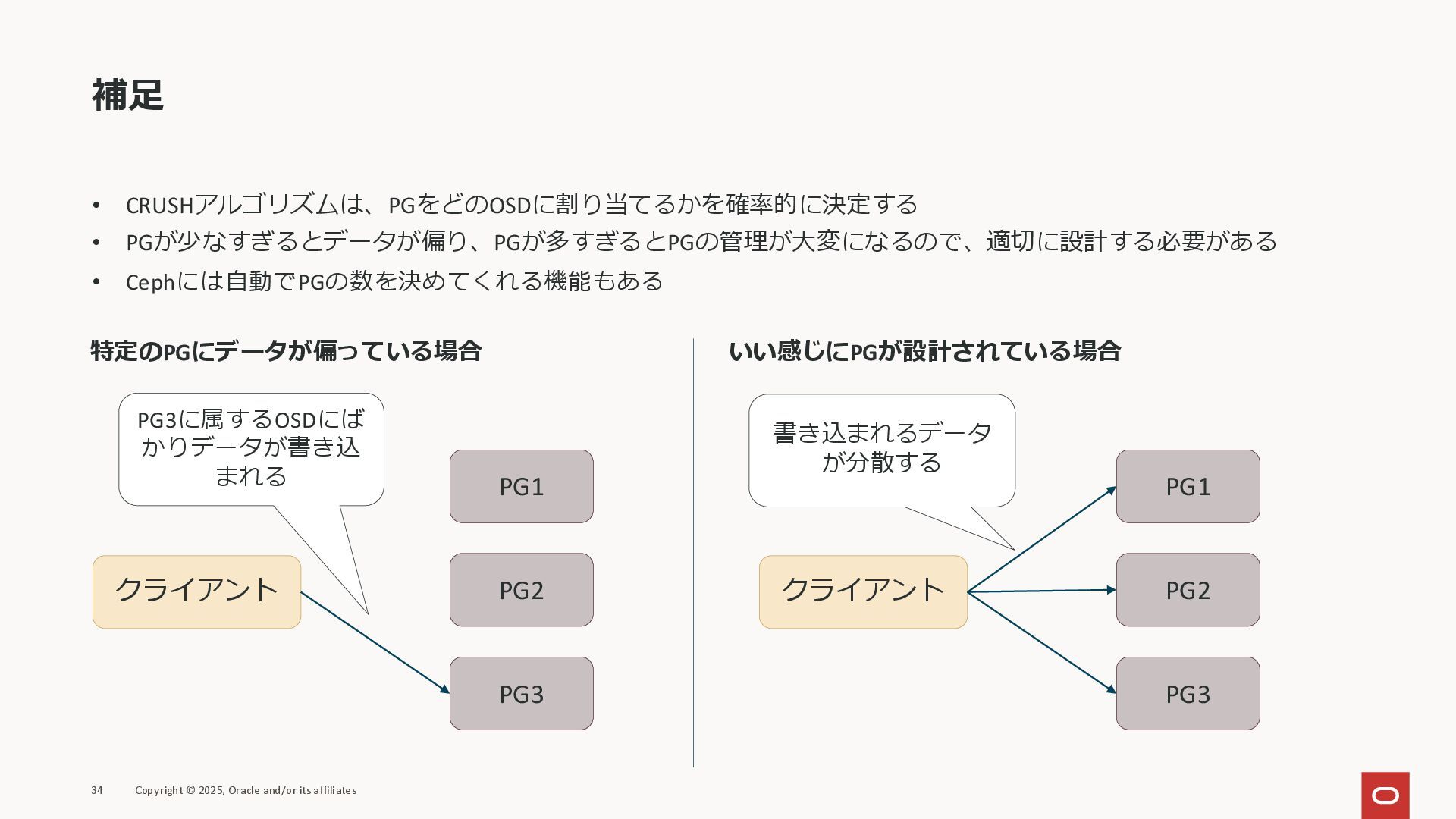
補足 • CRUSHアルゴリズムは、PGをどのOSDに割り当てるかを確率的に決定する • PGが少なすぎるとデータが偏り、PGが多すぎるとPGの管理が大変になるので、適切に設計する必要がある • Cephには自動でPGの数を決めてくれる機能もある 34 Copyright ©
2025, Oracle and/or its affiliates PG3 PG2 PG1 クライアント 特定のPGにデータが偏っている場合 PG3に属するOSDにば かりデータが書き込 まれる いい感じにPGが設計されている場合 PG3 PG2 PG1 クライアント 書き込まれるデータ が分散する
RADOSで扱うデータ あくまでオブジェクトとして保存するだけ RADOSではあくまでデータをオブジェクトとして保存するだけなので、 • ブロックストレージ • ファイルストレージ • オブジェクトストレージ のような使い方をするには
+α の機能が必要になる 35 Copyright © 2025, Oracle and/or its affiliates
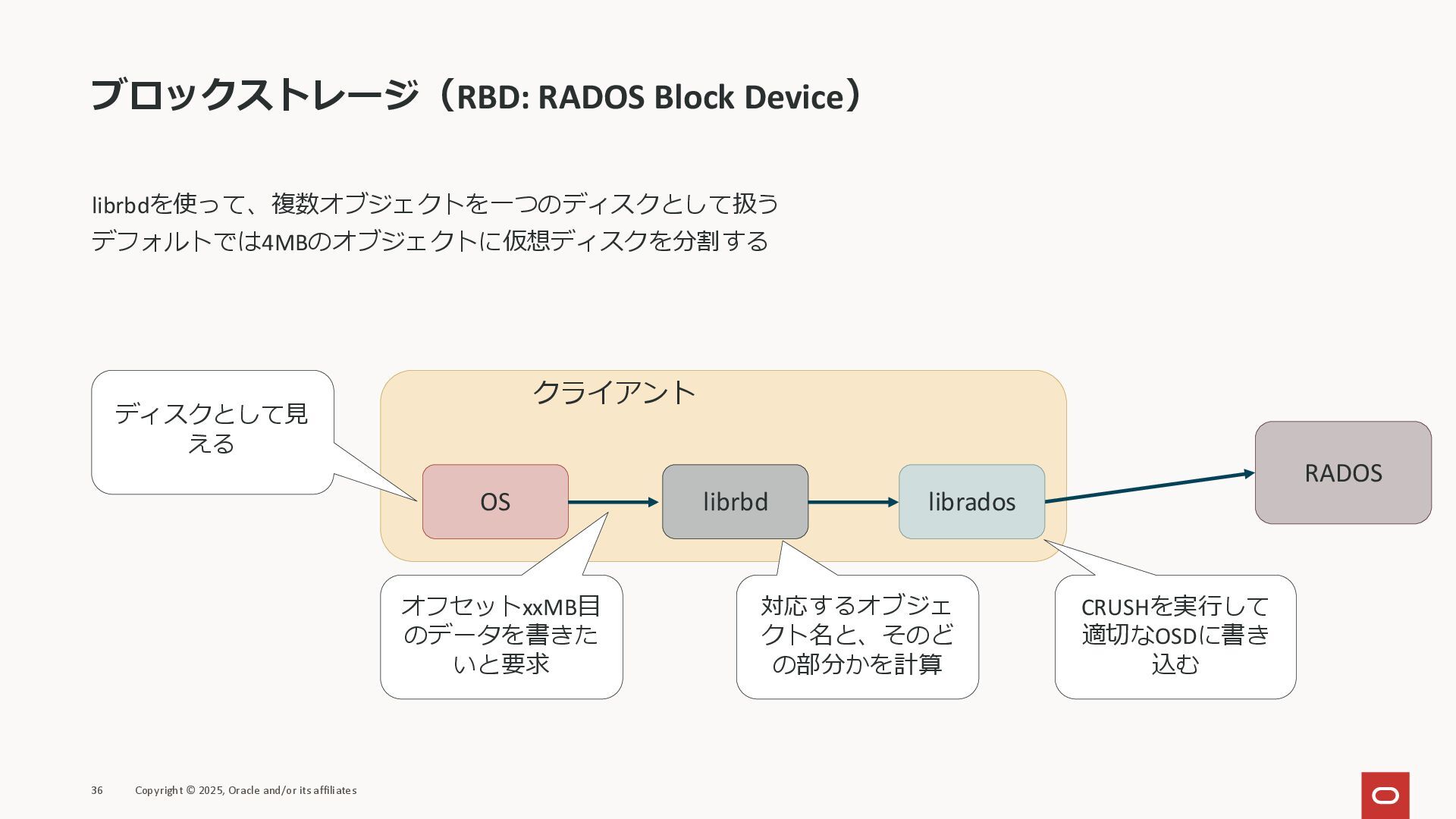
ブロックストレージ(RBD: RADOS Block Device) librbdを使って、複数オブジェクトを一つのディスクとして扱う デフォルトでは4MBのオブジェクトに仮想ディスクを分割する 36 Copyright © 2025,
Oracle and/or its affiliates OS librbd クライアント RADOS ディスクとして見 える オフセットxxMB目 のデータを書きた いと要求 対応するオブジェ クト名と、そのど の部分かを計算 librados CRUSHを実行して 適切なOSDに書き 込む
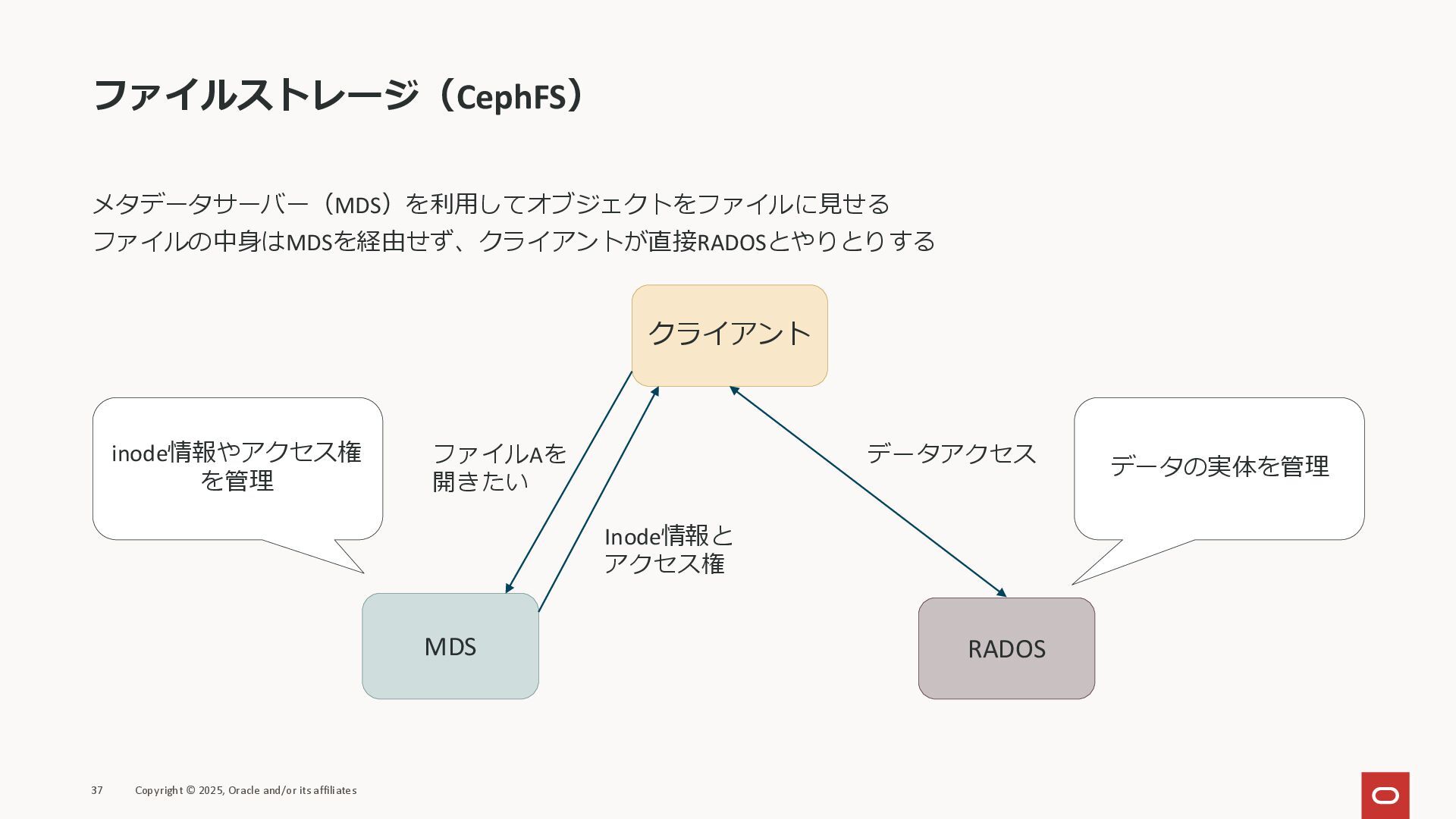
ファイルストレージ(CephFS) メタデータサーバー(MDS)を利用してオブジェクトをファイルに見せる ファイルの中身はMDSを経由せず、クライアントが直接RADOSとやりとりする 37 Copyright © 2025, Oracle and/or its
affiliates クライアント MDS RADOS inode情報やアクセス権 を管理 データの実体を管理 ファイルAを 開きたい Inode情報と アクセス権 データアクセス
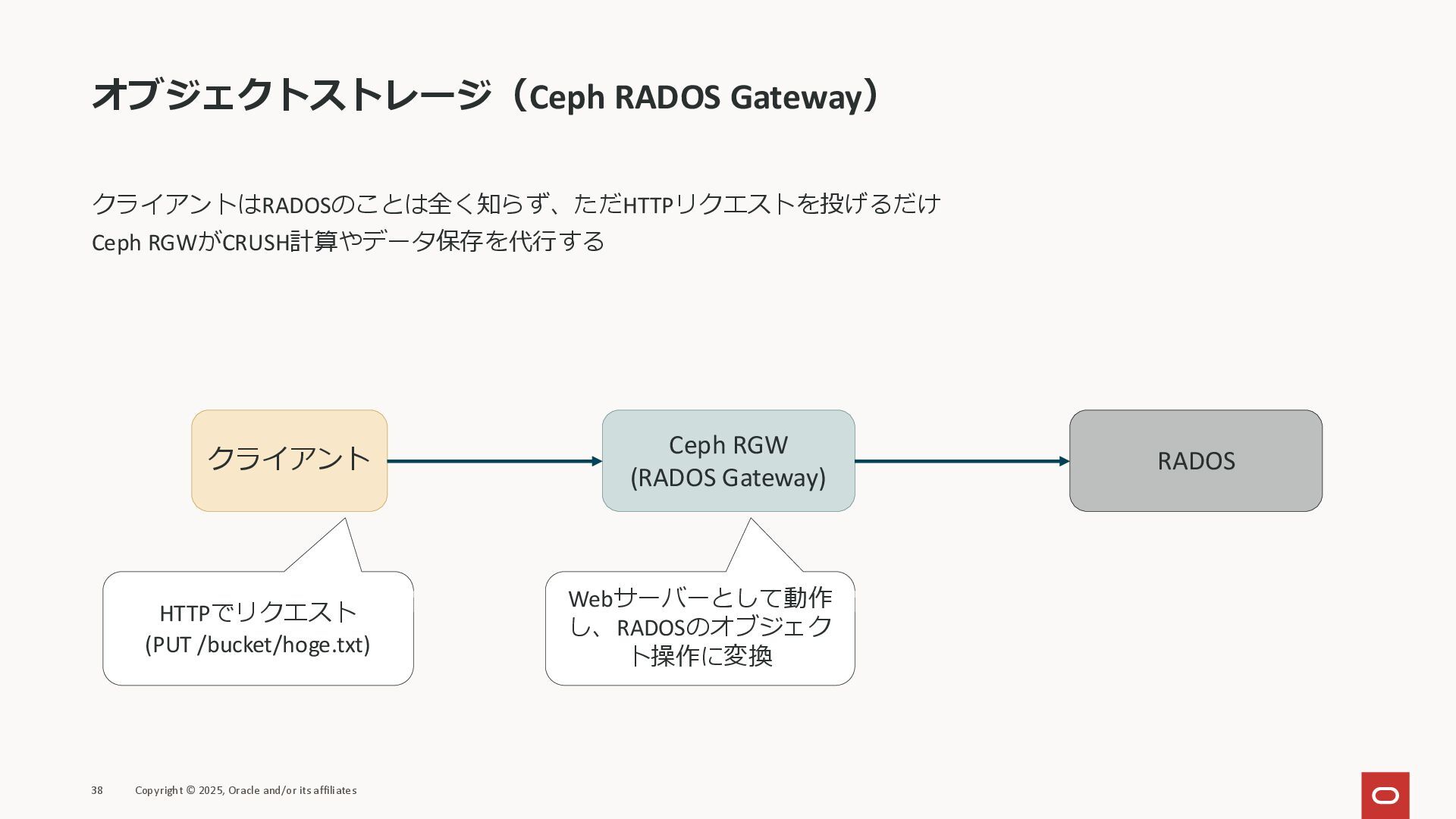
オブジェクトストレージ(Ceph RADOS Gateway) クライアントはRADOSのことは全く知らず、ただHTTPリクエストを投げるだけ Ceph RGWがCRUSH計算やデータ保存を代行する 38 Copyright © 2025,
Oracle and/or its affiliates クライアント Ceph RGW (RADOS Gateway) RADOS HTTPでリクエスト (PUT /bucket/hoge.txt) Webサーバーとして動作 し、RADOSのオブジェク ト操作に変換
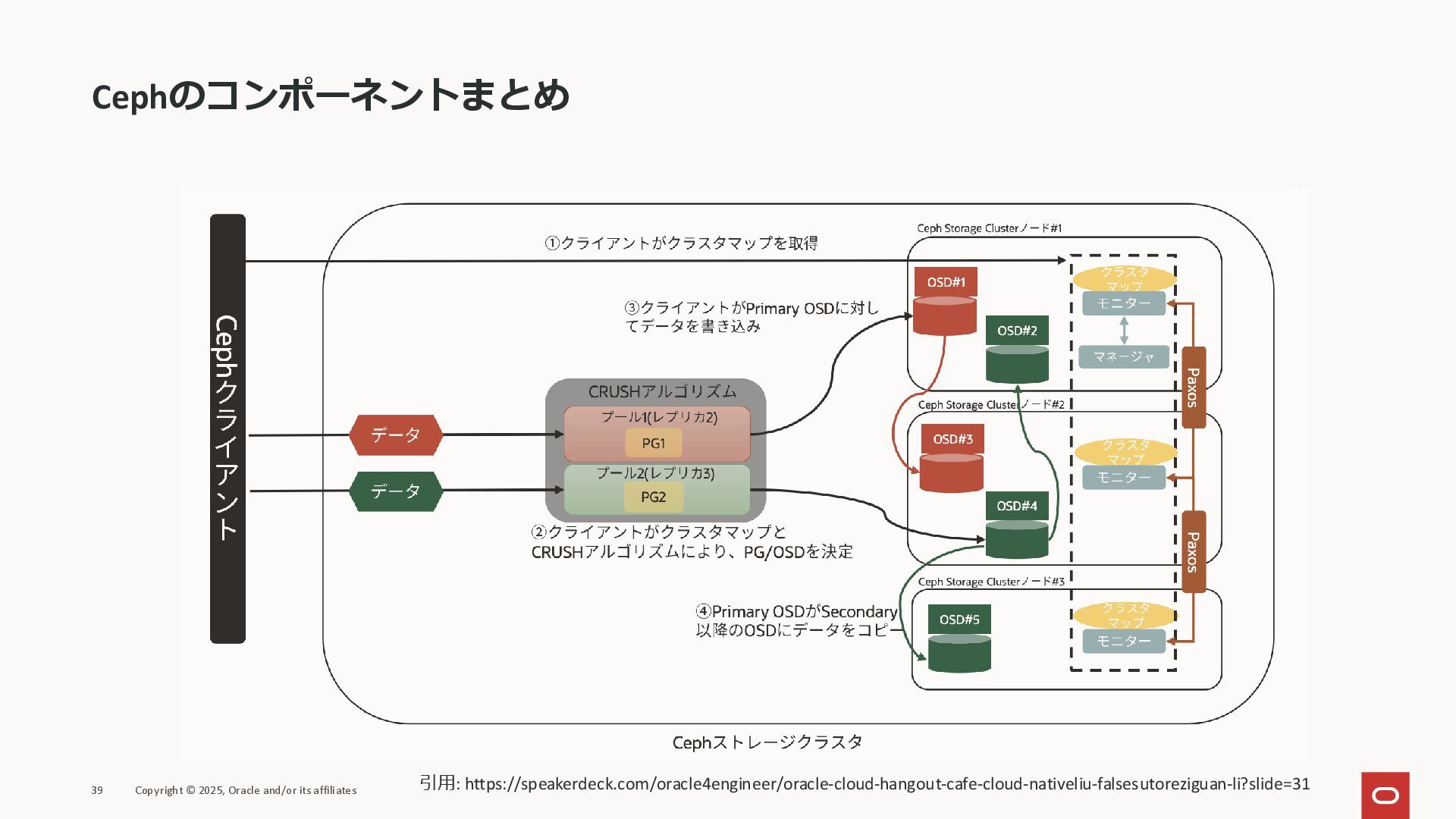
Cephのコンポーネントまとめ 39 Copyright © 2025, Oracle and/or its affiliates 引用:
https://speakerdeck.com/oracle4engineer/oracle-cloud-hangout-cafe-cloud-nativeliu-falsesutoreziguan-li?slide=31
Lustre概要
Lustreとは オープンソースの分散並列ファイルシステム 特徴 • POSIX準拠 • オンラインファイルシステムチェック • ファイルレイアウトのカスタマイズ •
異種ネットワークへの対応 • 高可用性 • セキュリティ • 容量の拡張性 ユースケース • スーパーコンピューティング分野 • AI/ML学習基盤 41 Copyright © 2025, Oracle and/or its affiliates
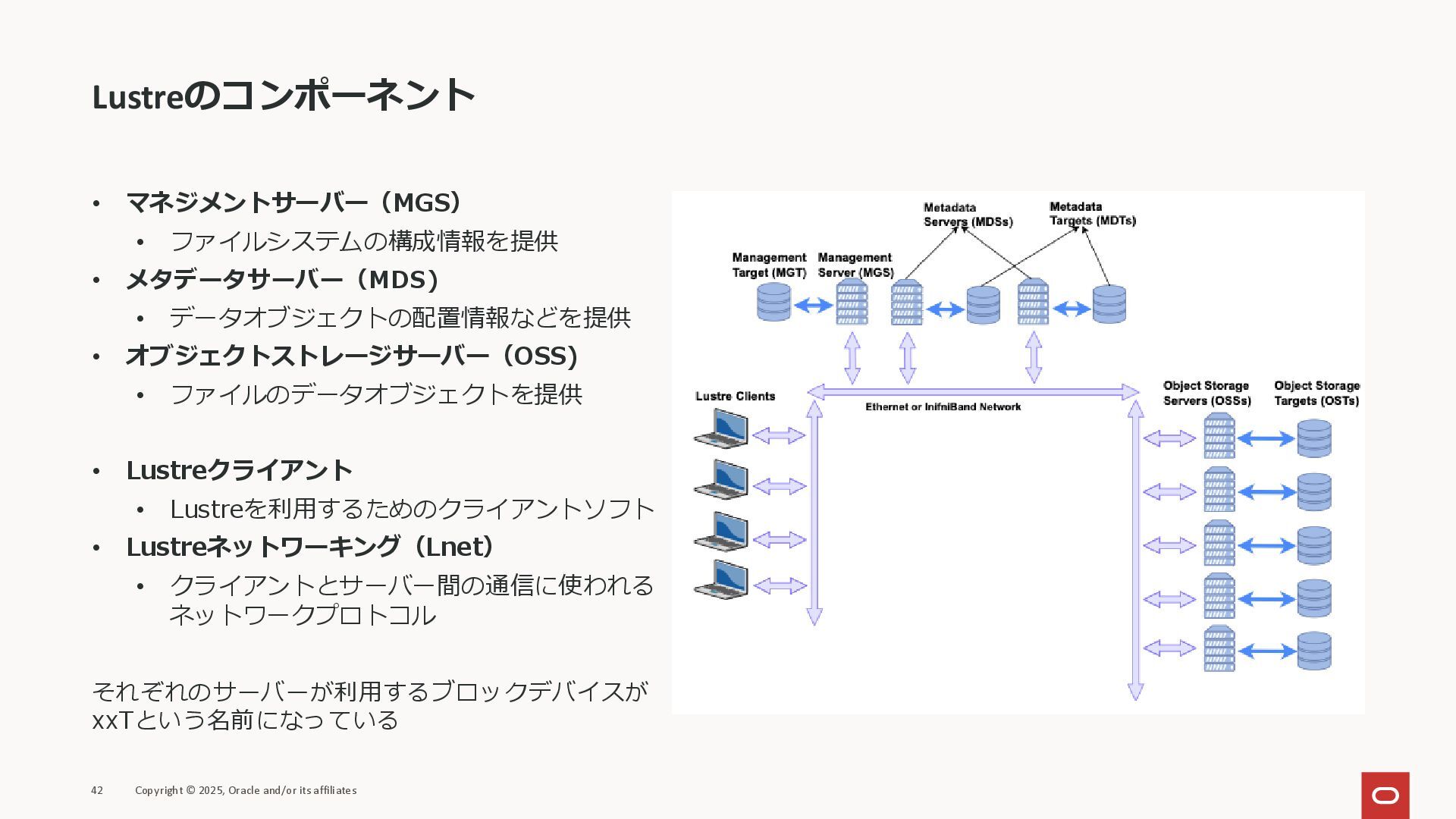
Lustreのコンポーネント • マネジメントサーバー(MGS) • ファイルシステムの構成情報を提供 • メタデータサーバー(MDS) • データオブジェクトの配置情報などを提供 •
オブジェクトストレージサーバー(OSS) • ファイルのデータオブジェクトを提供 • Lustreクライアント • Lustreを利用するためのクライアントソフト • Lustreネットワーキング(Lnet) • クライアントとサーバー間の通信に使われる ネットワークプロトコル それぞれのサーバーが利用するブロックデバイスが xxTという名前になっている 42 Copyright © 2025, Oracle and/or its affiliates
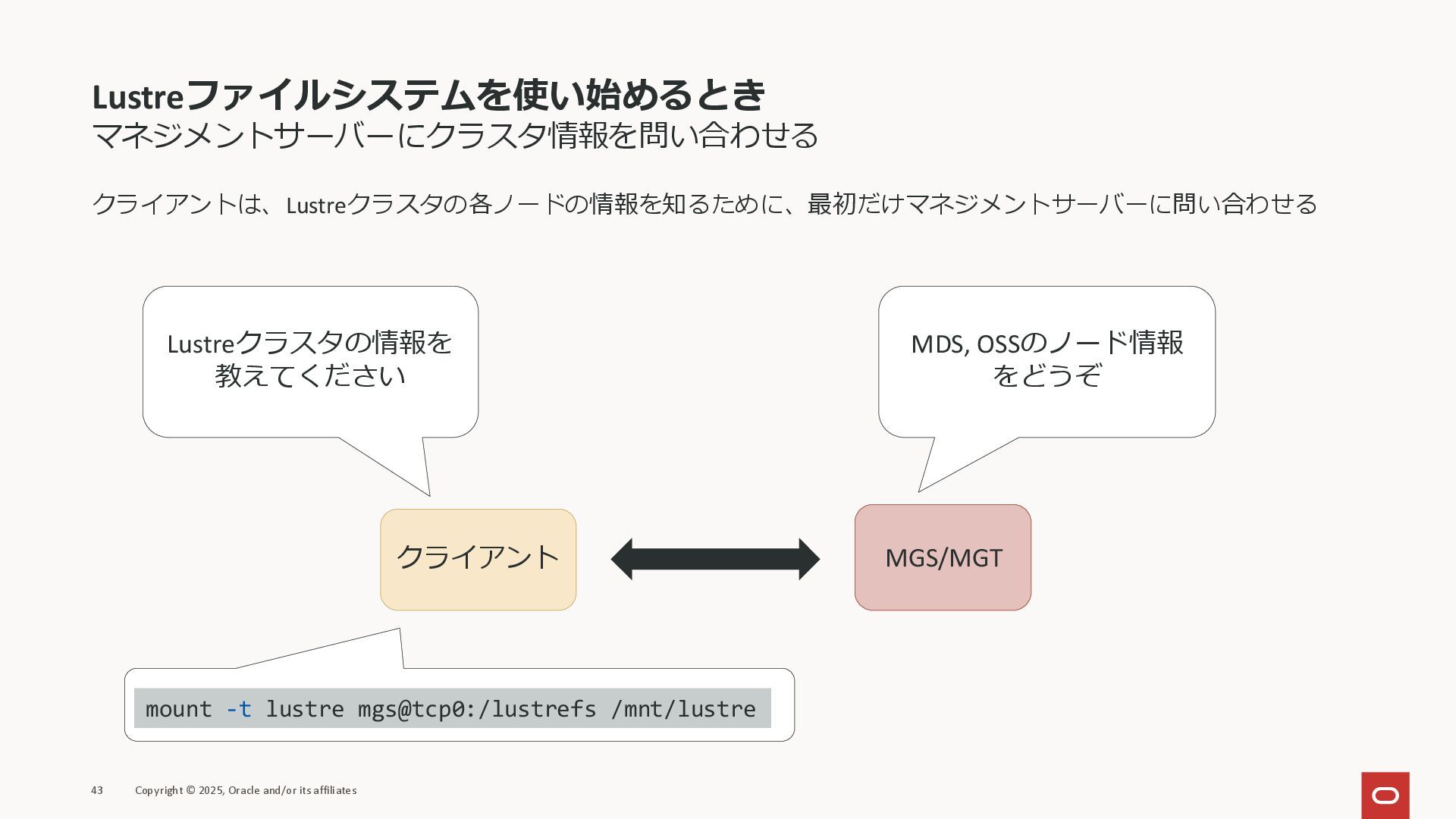
Lustreファイルシステムを使い始めるとき マネジメントサーバーにクラスタ情報を問い合わせる クライアントは、Lustreクラスタの各ノードの情報を知るために、最初だけマネジメントサーバーに問い合わせる 43 Copyright © 2025, Oracle and/or its
affiliates クライアント MGS/MGT Lustreクラスタの情報を 教えてください MDS, OSSのノード情報 をどうぞ mount -t lustre mgs@tcp0:/lustrefs /mnt/lustre
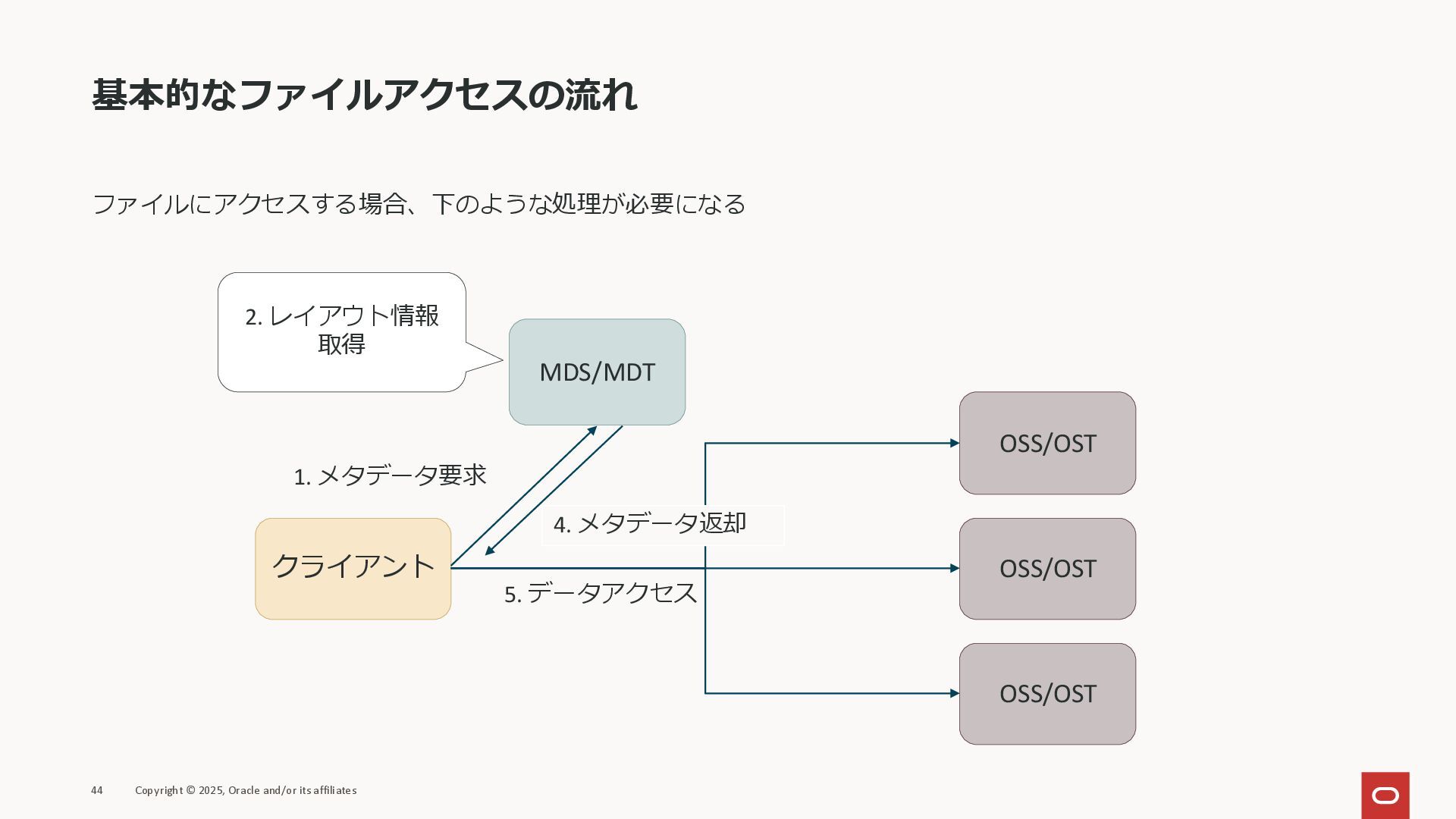
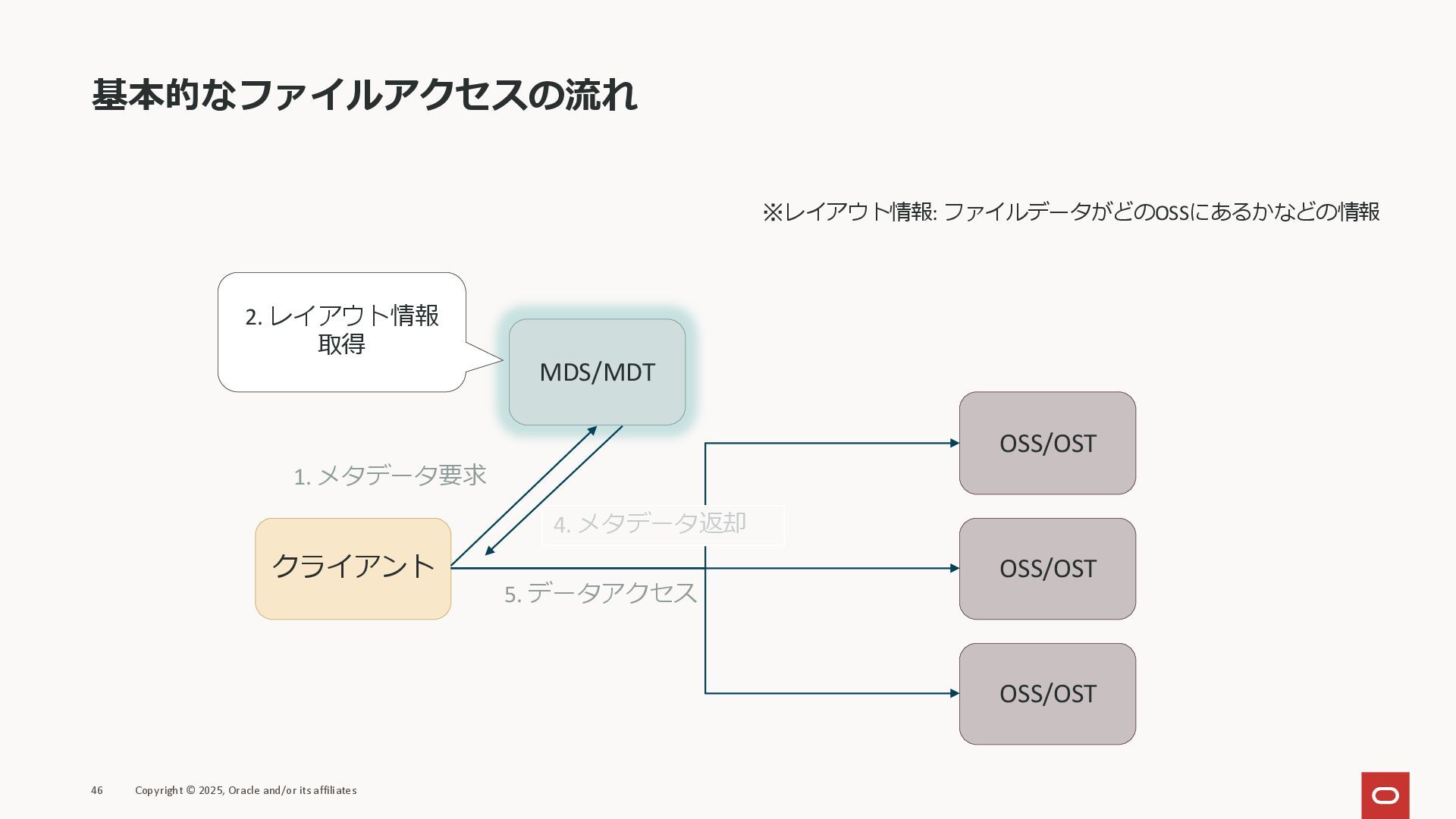
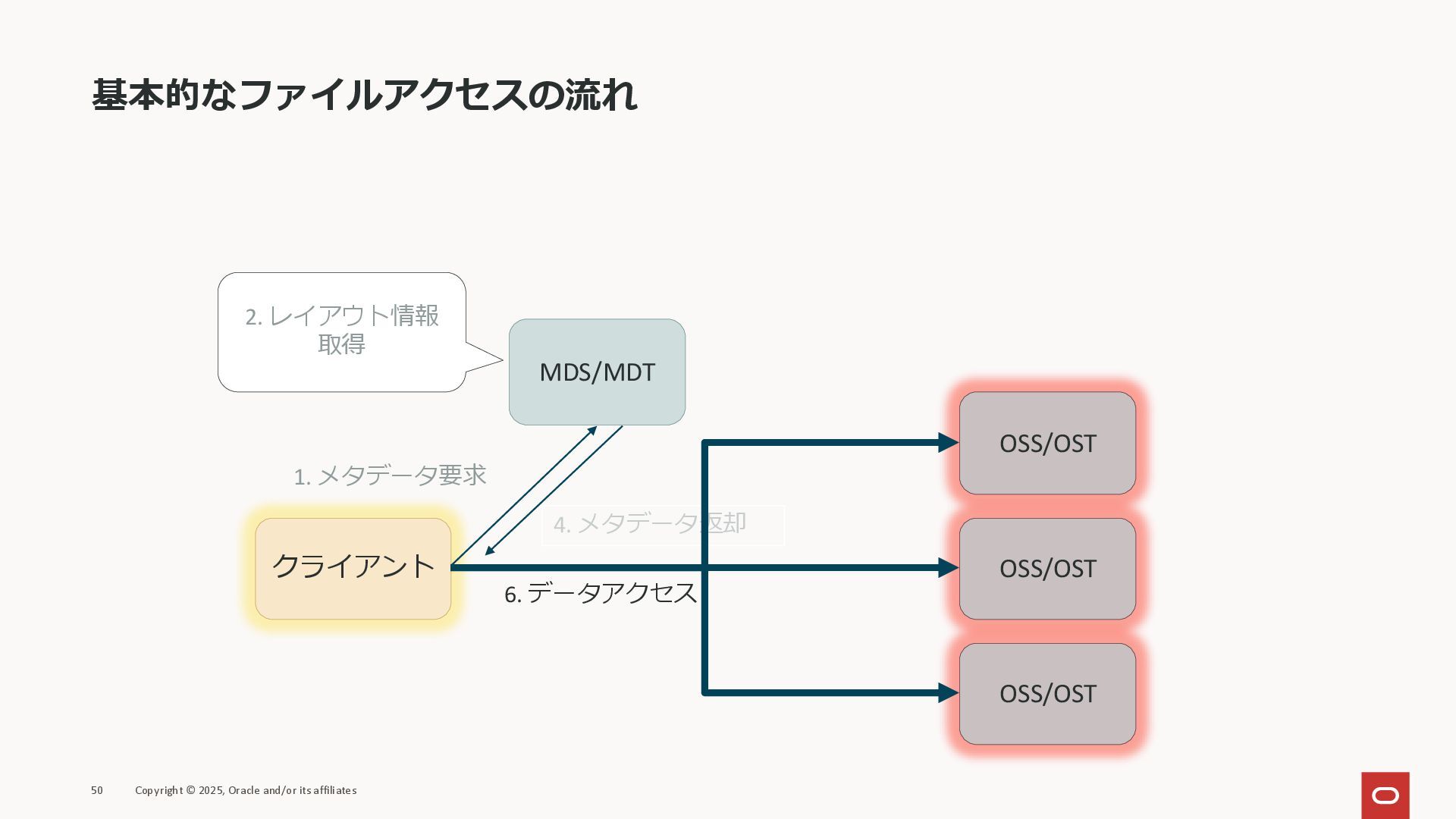
基本的なファイルアクセスの流れ ファイルにアクセスする場合、下のような処理が必要になる 44 Copyright © 2025, Oracle and/or its affiliates
クライアント MDS/MDT OSS/OST OSS/OST OSS/OST 1. メタデータ要求 2. レイアウト情報 取得 5. データアクセス 4. メタデータ返却
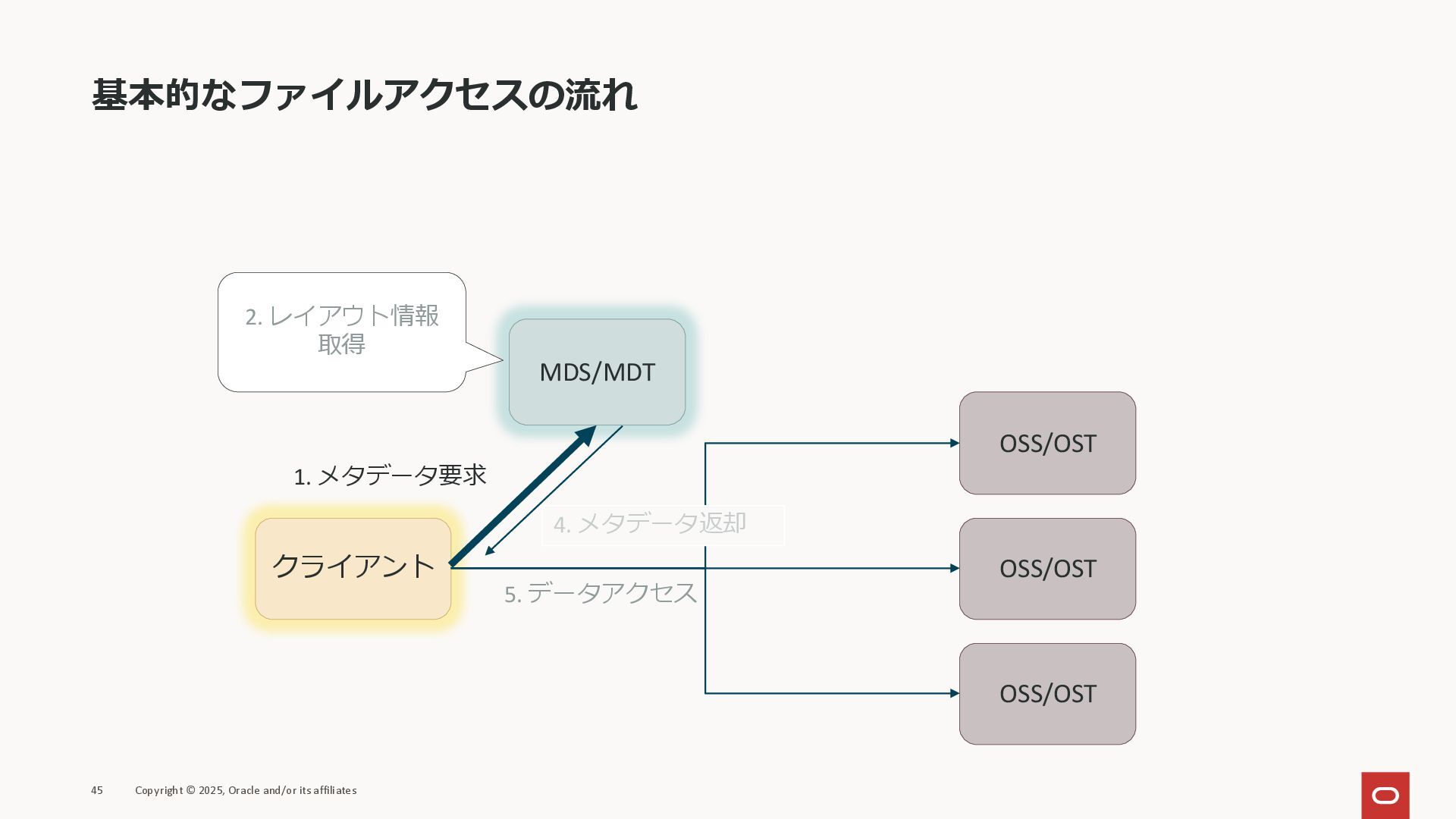
基本的なファイルアクセスの流れ 45 Copyright © 2025, Oracle and/or its affiliates クライアント
MDS/MDT OSS/OST OSS/OST OSS/OST 1. メタデータ要求 2. レイアウト情報 取得 5. データアクセス 4. メタデータ返却
基本的なファイルアクセスの流れ 46 Copyright © 2025, Oracle and/or its affiliates クライアント
MDS/MDT OSS/OST OSS/OST OSS/OST 1. メタデータ要求 2. レイアウト情報 取得 5. データアクセス 4. メタデータ返却 ※レイアウト情報: ファイルデータがどのOSSにあるかなどの情報
基本的なファイルアクセスの流れ 47 Copyright © 2025, Oracle and/or its affiliates クライアント
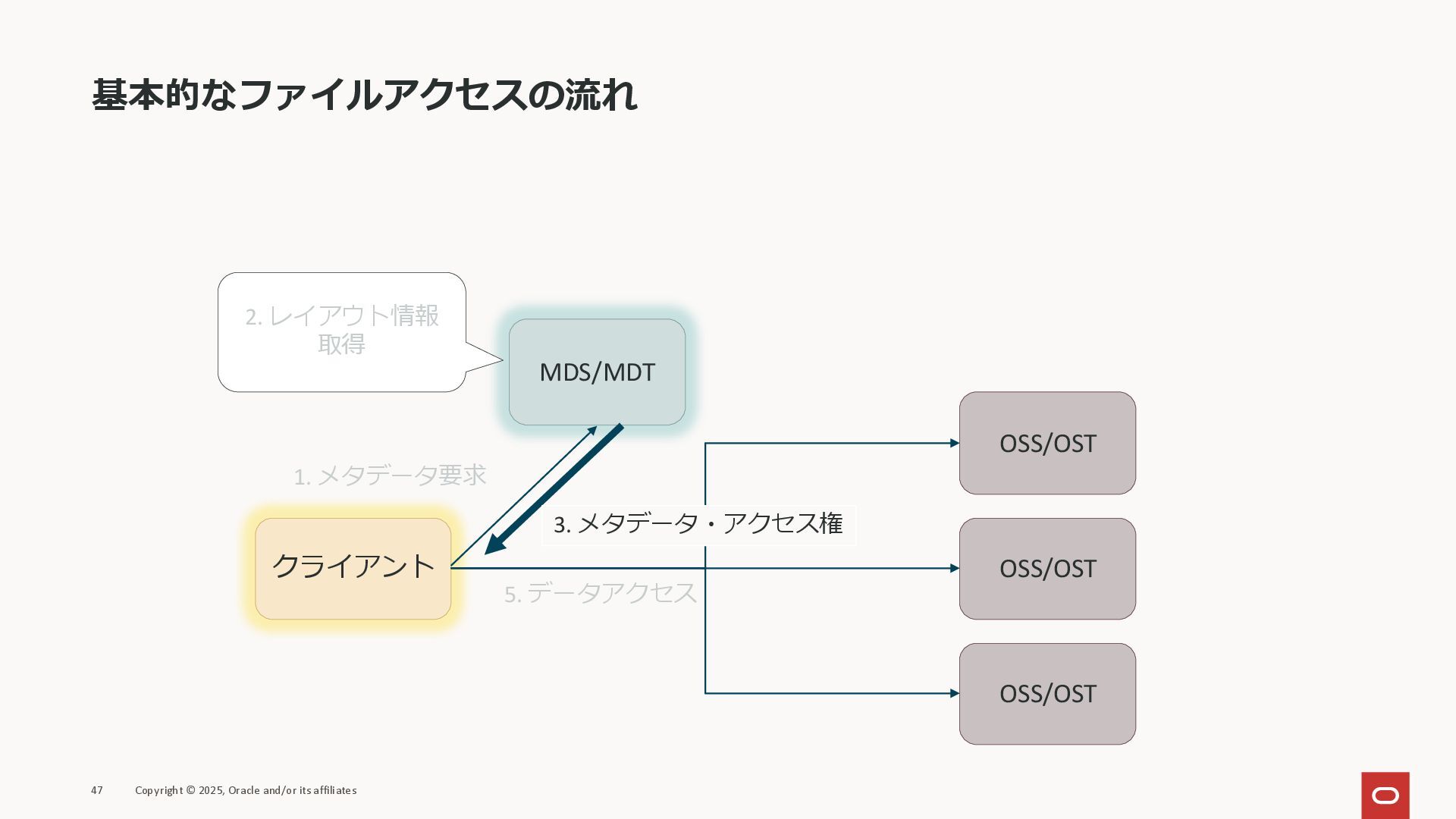
MDS/MDT OSS/OST OSS/OST OSS/OST 1. メタデータ要求 2. レイアウト情報 取得 5. データアクセス 3. メタデータ・アクセス権
基本的なファイルアクセスの流れ 48 Copyright © 2025, Oracle and/or its affiliates クライアント
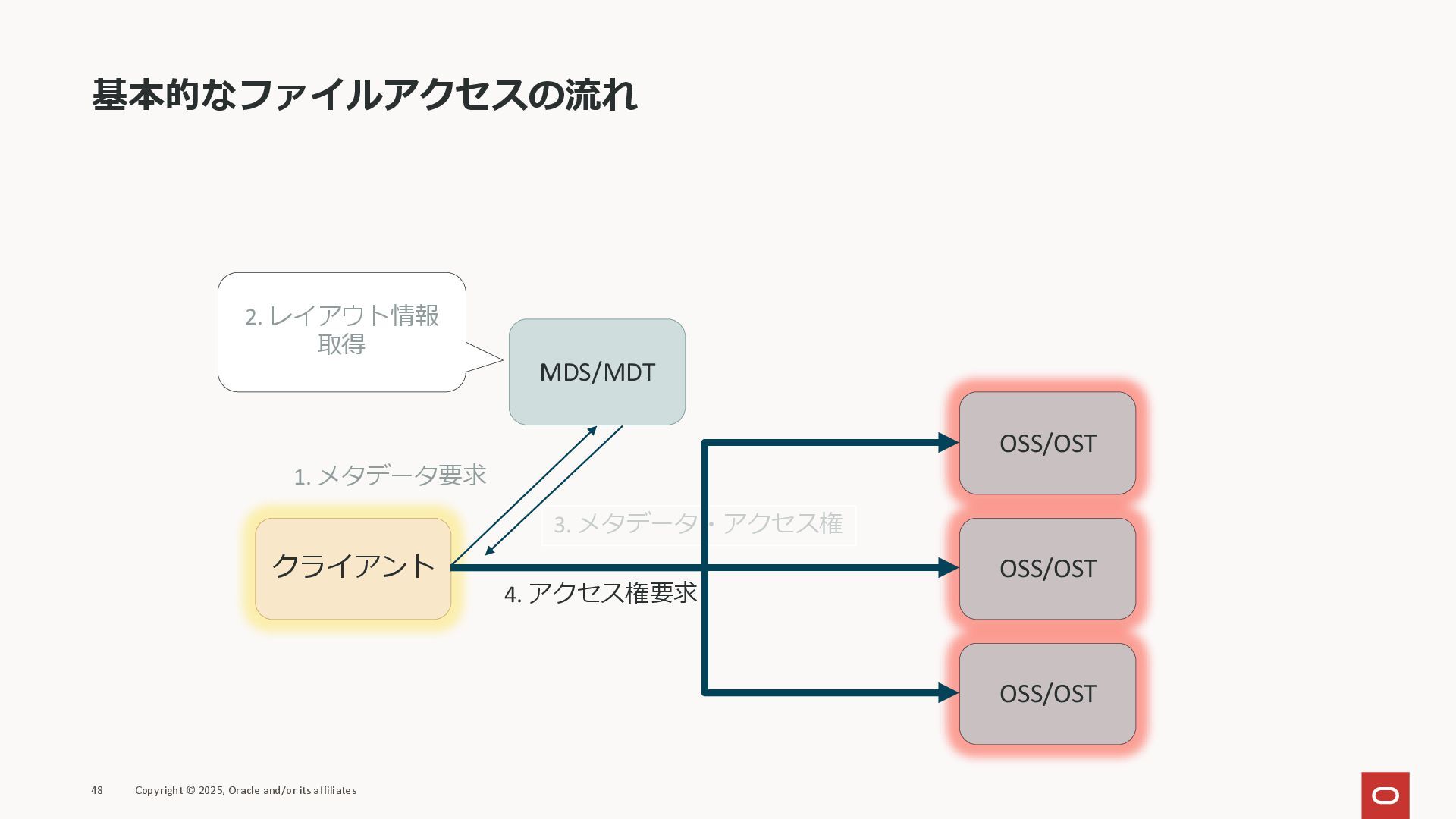
MDS/MDT OSS/OST OSS/OST OSS/OST 1. メタデータ要求 2. レイアウト情報 取得 4. アクセス権要求 3. メタデータ・アクセス権
基本的なファイルアクセスの流れ 49 Copyright © 2025, Oracle and/or its affiliates クライアント
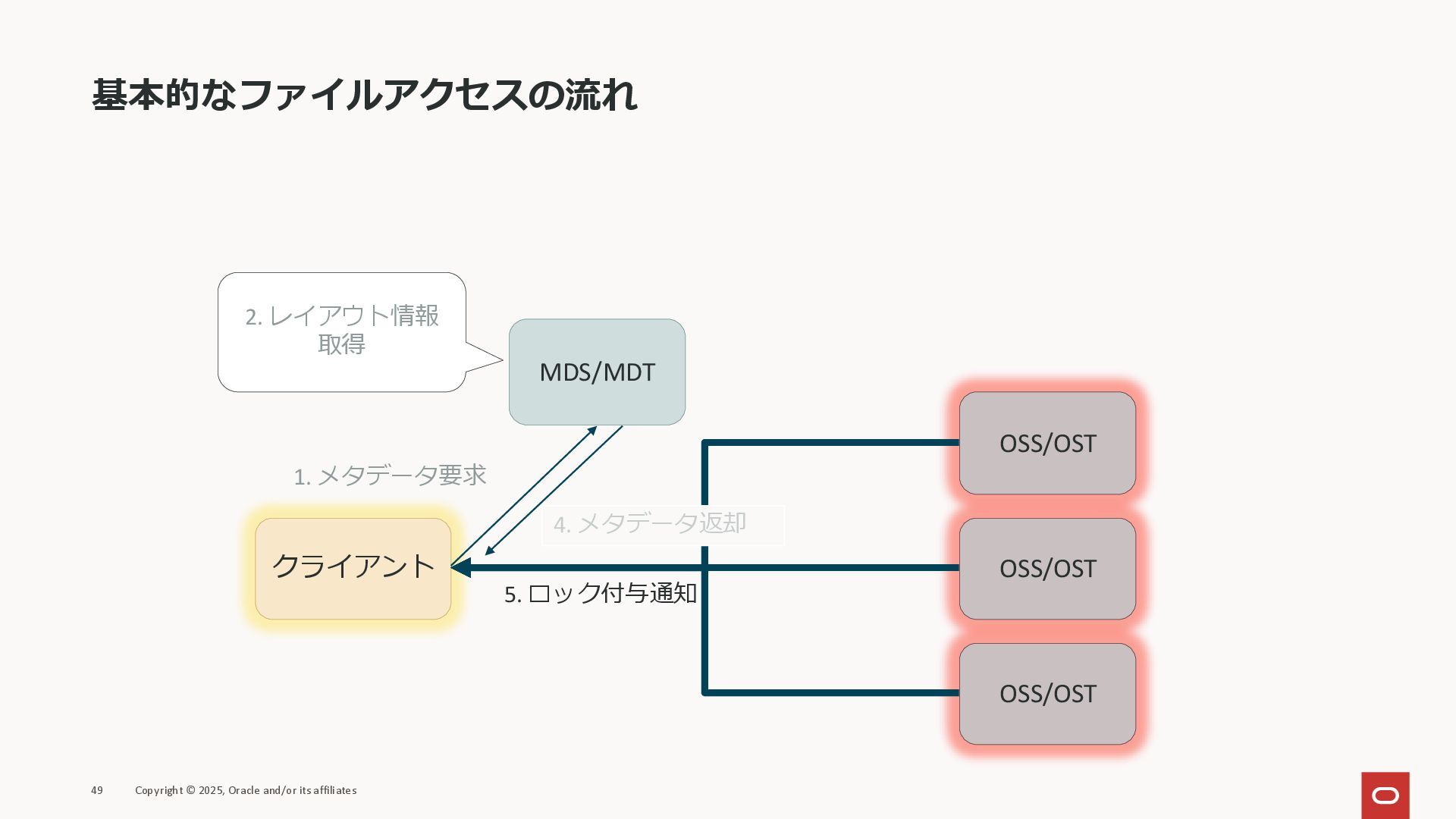
MDS/MDT OSS/OST OSS/OST OSS/OST 1. メタデータ要求 2. レイアウト情報 取得 5. ロック付与通知 4. メタデータ返却
基本的なファイルアクセスの流れ 50 Copyright © 2025, Oracle and/or its affiliates クライアント
MDS/MDT OSS/OST OSS/OST OSS/OST 1. メタデータ要求 2. レイアウト情報 取得 6. データアクセス 4. メタデータ返却
Lustreは、データの配置場所を柔軟に指定できる Lustreでは、データの配置場所を管理者が柔軟に指定することができる 1. Normal / RAID0 レイアウト • 指定したOSTに対してラウンドロビン方式でストライピング 2.
複合レイアウト • ファイルサイズの成長に応じてストライピングパターンを変更 • ストレージの利用効率を上げるデータ配置 • Etc… 51 Copyright © 2025, Oracle and/or its affiliates
Lustreのスケーラビリティとパフォーマンス 特徴 現在の実用的な範囲 実運用での使用例 クライアントのスケーラビリティ 100 ~ 100,000クライアント 50,000以上(多くは10,000 ~
20,000ク ライアント規模) クライアントのパフォーマンス クライアントあたりネットワーク帯 域幅の90% 全体:10TB/s クライアントあたり4.5GB/s メタデータ操作 1,000 ops/sec 全体:2.5TB/s OSSのスケーラビリティ OSSあたり1~32個のOST(3億オブ ジェクト、256TiB / OST) 総数:最大1,000 OSS OSSあたり32個のOST、OSTあたり8TiB (もしくは8個のOST、OSTあたり 32TiB) 総数:450 OSS OSSのパフォーマンス OSSあたり15GB/s 束ねて10TB/s OSSあたり10GB/s 束ねて2.5TB/s 52 Copyright © 2025, Oracle and/or its affiliates
Lustreのスケーラビリティとパフォーマンス 特徴 現在の実用的な範囲 実運用での使用例 MDSのスケーラビリティ MDSあたり1~4個のMDT MDTあたり40億ファイル 総数:最大256MDS MDSあたり30億ファイル(2TiB MDT×7)
MDSのパフォーマンス 50,000 ファイル作成/s 200,000メタデータ操作/s 15,000ファイル作成/s 50,000メタデータ操作/s ファイルシステムのスケーラビリ ティ 単一ファイルの最大サイズ:32PiB 全体:総容量512PiB, ファイル総数1 兆 単一ファイルの最大サイズ:数TiB 全体:総容量55PiB、ファイル総数80 億 53 Copyright © 2025, Oracle and/or its affiliates
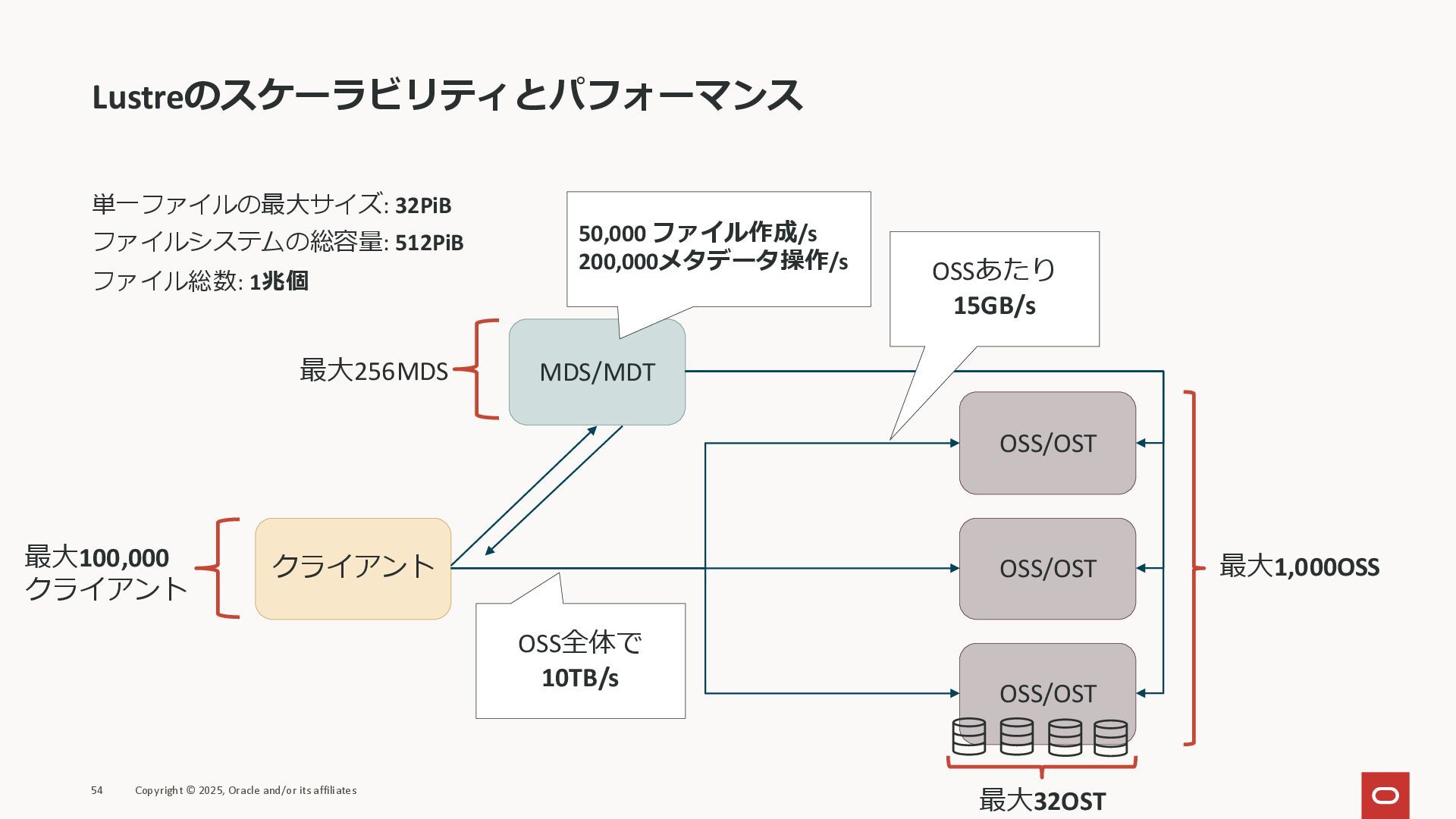
Lustreのスケーラビリティとパフォーマンス 単一ファイルの最大サイズ: 32PiB ファイルシステムの総容量: 512PiB ファイル総数: 1兆個 54 Copyright ©
2025, Oracle and/or its affiliates クライアント MDS/MDT OSS/OST OSS/OST OSS/OST 最大1,000OSS 最大32OST 最大100,000 クライアント 最大256MDS OSS全体で 10TB/s OSSあたり 15GB/s 50,000 ファイル作成/s 200,000メタデータ操作/s
ユースケースから考えるス トレージ選択と技術解剖
今回考えるユースケース 前提 クラウドストレージは、各種ベンダー・OSSごとに様々な製品がありその全てを比較することはできないので、 スケールアウトするストレージ基盤として • Ceph • ブロックストレージ • ファイルストレージ
• オブジェクトストレージ • Lustre • ファイルストレージ を代表としてユースケースにどれが合うかをみていきます 56 Copyright © 2025, Oracle and/or its affiliates
今回考えるユースケース 1. VMのブート領域としてストレージが必要な場合 2. ログのアーカイブ保存先としてストレージが必要な場合 3. LLMの学習中のチェックポイントの保存先としてストレージが必要な場合 4. 高可用性Webコンテンツ管理システムの共有ストレージが必要な場合 57
Copyright © 2025, Oracle and/or its affiliates
1. VMのブート領域としてのストレージ 求められること ファイルシステムはOSで管理するため、生のディスクが必要 小さな設定ファイル、バイナリなどをディスク上のあちこちから読み込むため、ランダムアクセス性能が重要 58 Copyright © 2025, Oracle
and/or its affiliates ブロックストレージが最適
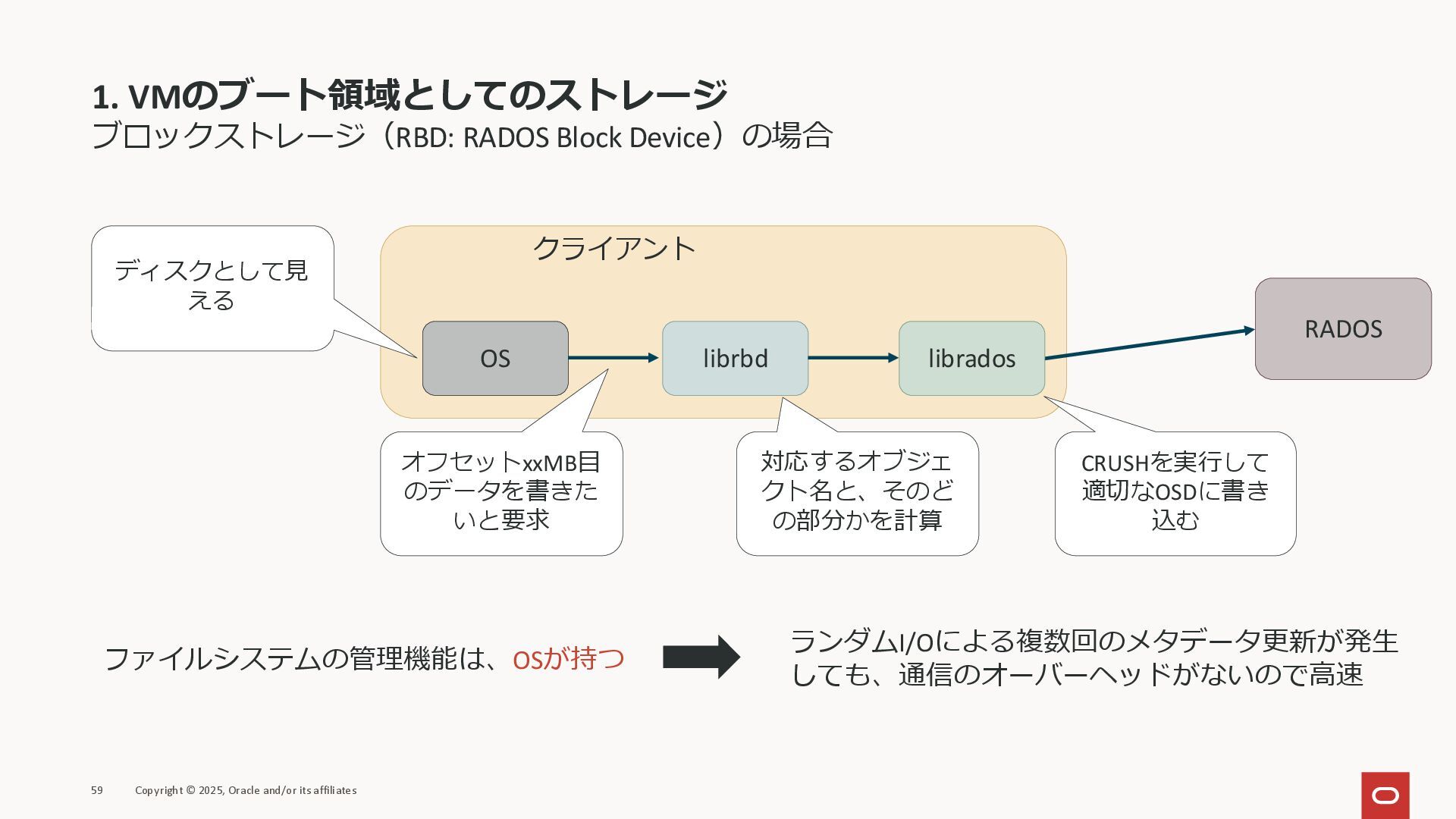
1. VMのブート領域としてのストレージ ブロックストレージ(RBD: RADOS Block Device)の場合 59 Copyright © 2025,
Oracle and/or its affiliates OS librbd クライアント RADOS ディスクとして見 える オフセットxxMB目 のデータを書きた いと要求 対応するオブジェ クト名と、そのど の部分かを計算 librados CRUSHを実行して 適切なOSDに書き 込む ファイルシステムの管理機能は、OSが持つ ランダムI/Oによる複数回のメタデータ更新が発生 しても、通信のオーバーヘッドがないので高速
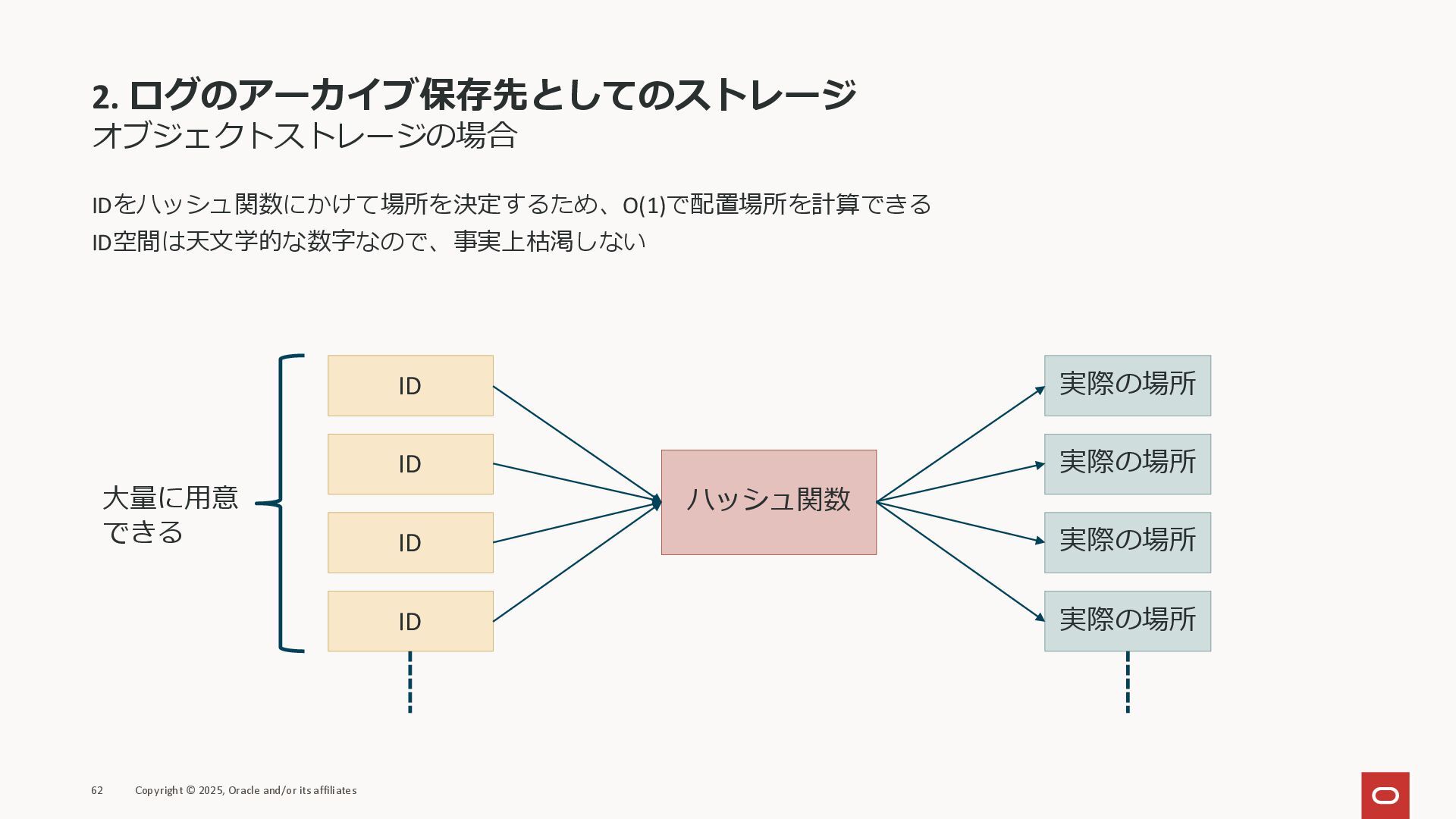
2. ログのアーカイブ保存先としてのストレージ 求められること 半永続的に保存する&サイズが増加し続けるため、スケール可能な大容量ストレージが求められる 複数のサーバーからデータが送られるため、複数クライアントから安全にアクセスできる必要がある 60 Copyright © 2025, Oracle
and/or its affiliates ファイルストレージ ファイルシステムには最大容量がある • inodeの枯渇 • 対象ファイル検索の負荷 などが原因 オブジェクトストレージ 容量に制限はない • IDをハッシュ関数にかけて場所を決定する • ID空間は天文学的な数字なので、事実上枯渇しない オブジェクトストレージが最適
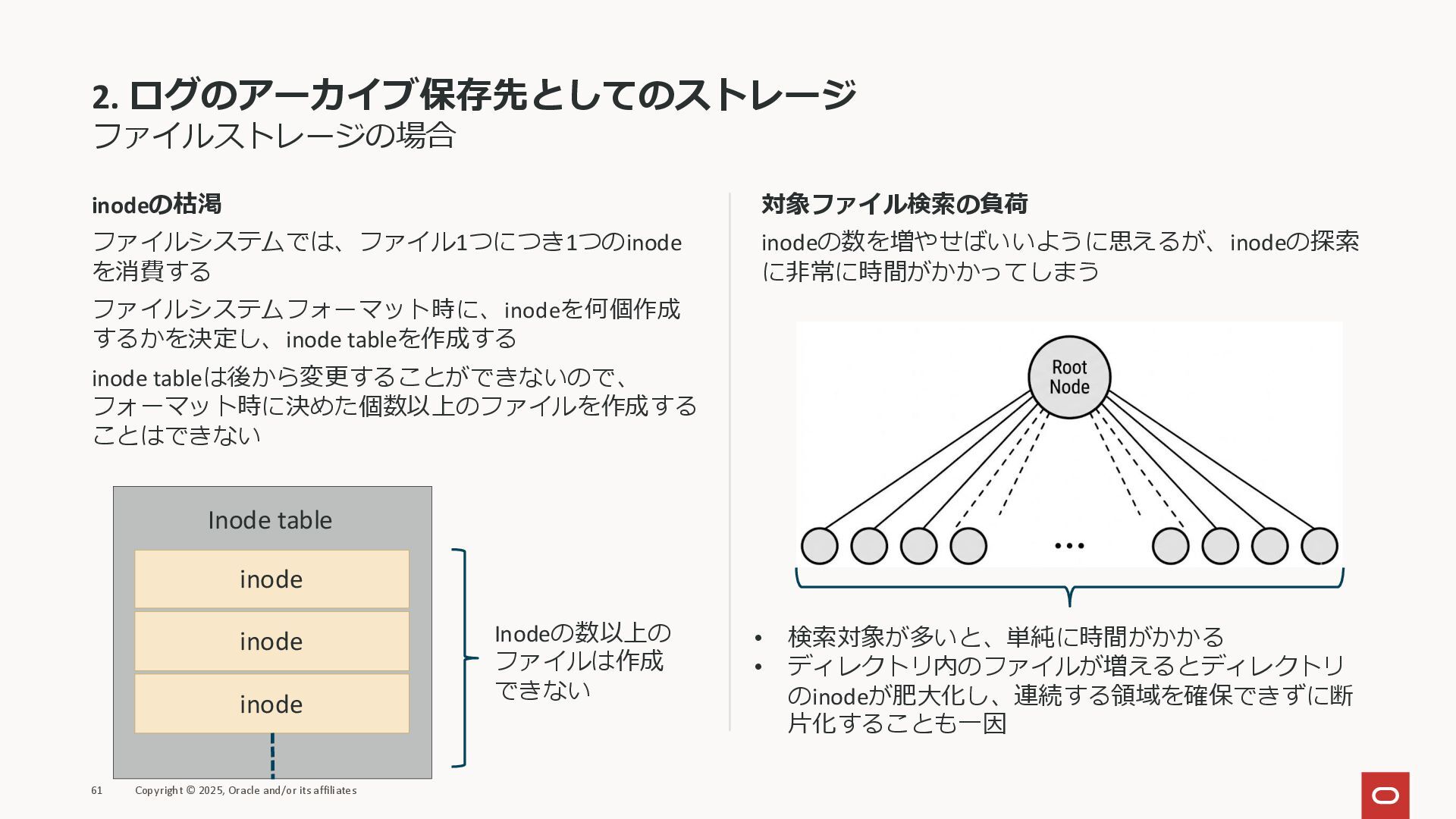
2. ログのアーカイブ保存先としてのストレージ ファイルストレージの場合 inodeの枯渇 ファイルシステムでは、ファイル1つにつき1つのinode を消費する ファイルシステムフォーマット時に、inodeを何個作成 するかを決定し、inode tableを作成する inode
tableは後から変更することができないので、 フォーマット時に決めた個数以上のファイルを作成する ことはできない 対象ファイル検索の負荷 inodeの数を増やせばいいように思えるが、inodeの探索 に非常に時間がかかってしまう 61 Copyright © 2025, Oracle and/or its affiliates inode inode inode Inodeの数以上の ファイルは作成 できない Inode table • 検索対象が多いと、単純に時間がかかる • ディレクトリ内のファイルが増えるとディレクトリ のinodeが肥大化し、連続する領域を確保できずに断 片化することも一因
2. ログのアーカイブ保存先としてのストレージ オブジェクトストレージの場合 IDをハッシュ関数にかけて場所を決定するため、O(1)で配置場所を計算できる ID空間は天文学的な数字なので、事実上枯渇しない 62 Copyright © 2025, Oracle
and/or its affiliates ID ハッシュ関数 ID ID ID 実際の場所 実際の場所 実際の場所 実際の場所 大量に用意 できる
2. ログのアーカイブ保存先としてのストレージ 補足 最近のファイルシステム(XFSなど)では、inode数は事実上無限 とはいえ、 • メタデータサーバーの負荷 • 古くなったファイルの自動削除 •
オブジェクトロック機能(指定期間は管理者でも消せないようにする) などを考えるとオブジェクトストレージが適切(コストが低い) 63 Copyright © 2025, Oracle and/or its affiliates
3. LLMの学習中のチェックポイントの保存先としてストレージが必要な場合 求められること • 書き込みが高速に行える(GPUを遊ばせないため) • POSIXに準拠している(Pythonなどから操作するため) 64 Copyright ©
2025, Oracle and/or its affiliates CephFS • 事前に定めたレプリカ数を維持するように同期レプ リケーションされるため、書き込みスループットが Lustreと比べて低い Lustre • ファイルやディレクトリのサイズに合わせて柔軟に ストライピングできるため、読み書きのスループッ トが非常に高い Lustreが最適
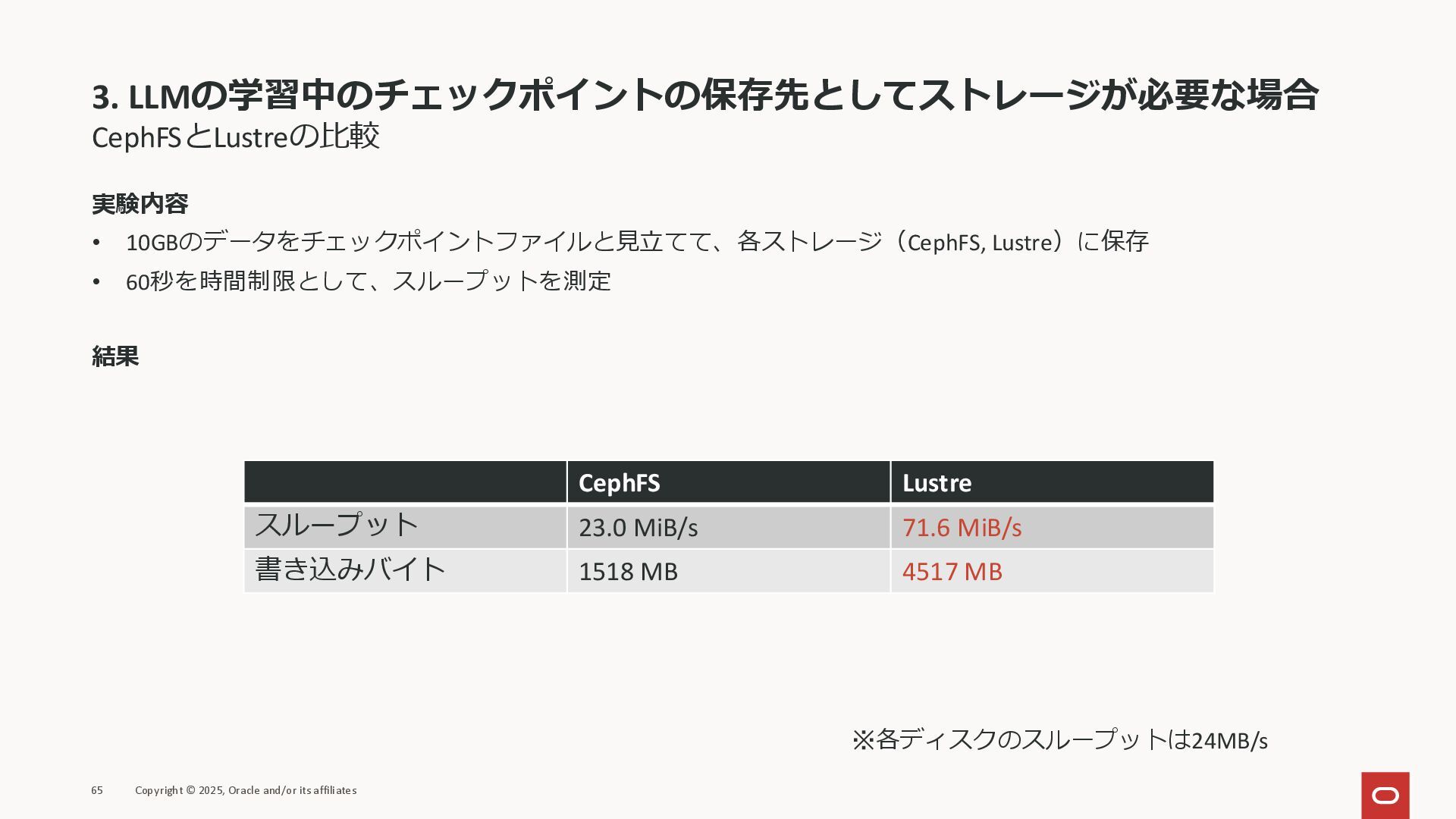
3. LLMの学習中のチェックポイントの保存先としてストレージが必要な場合 CephFSとLustreの比較 実験内容 • 10GBのデータをチェックポイントファイルと見立てて、各ストレージ(CephFS, Lustre)に保存 • 60秒を時間制限として、スループットを測定 結果
65 Copyright © 2025, Oracle and/or its affiliates CephFS Lustre スループット 23.0 MiB/s 71.6 MiB/s 書き込みバイト 1518 MB 4517 MB ※各ディスクのスループットは24MB/s
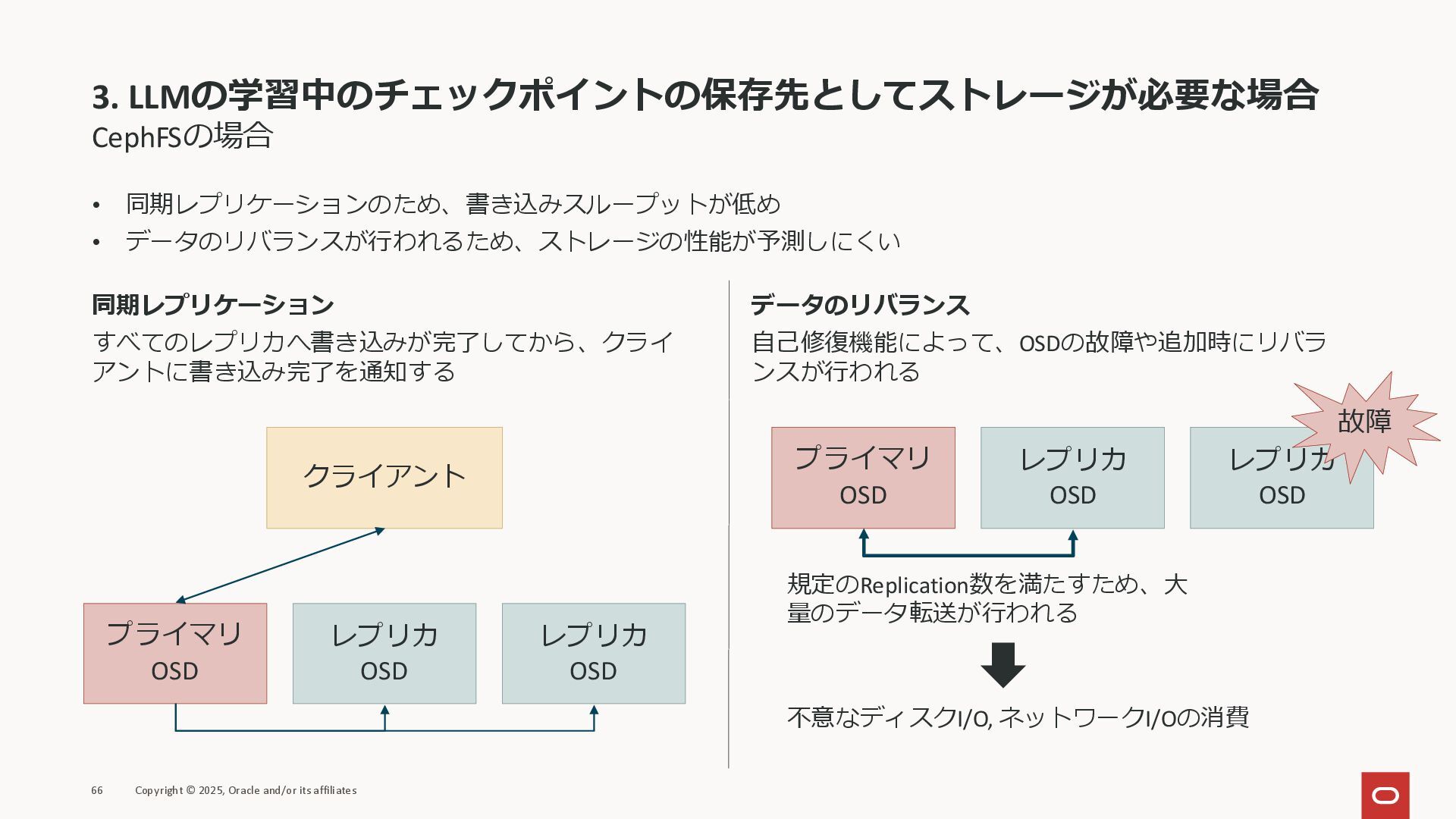
3. LLMの学習中のチェックポイントの保存先としてストレージが必要な場合 CephFSの場合 • 同期レプリケーションのため、書き込みスループットが低め • データのリバランスが行われるため、ストレージの性能が予測しにくい 66 Copyright ©
2025, Oracle and/or its affiliates クライアント プライマリ OSD レプリカ OSD レプリカ OSD 同期レプリケーション すべてのレプリカへ書き込みが完了してから、クライ アントに書き込み完了を通知する データのリバランス 自己修復機能によって、OSDの故障や追加時にリバラ ンスが行われる プライマリ OSD レプリカ OSD レプリカ OSD 故障 規定のReplication数を満たすため、大 量のデータ転送が行われる 不意なディスクI/O, ネットワークI/Oの消費
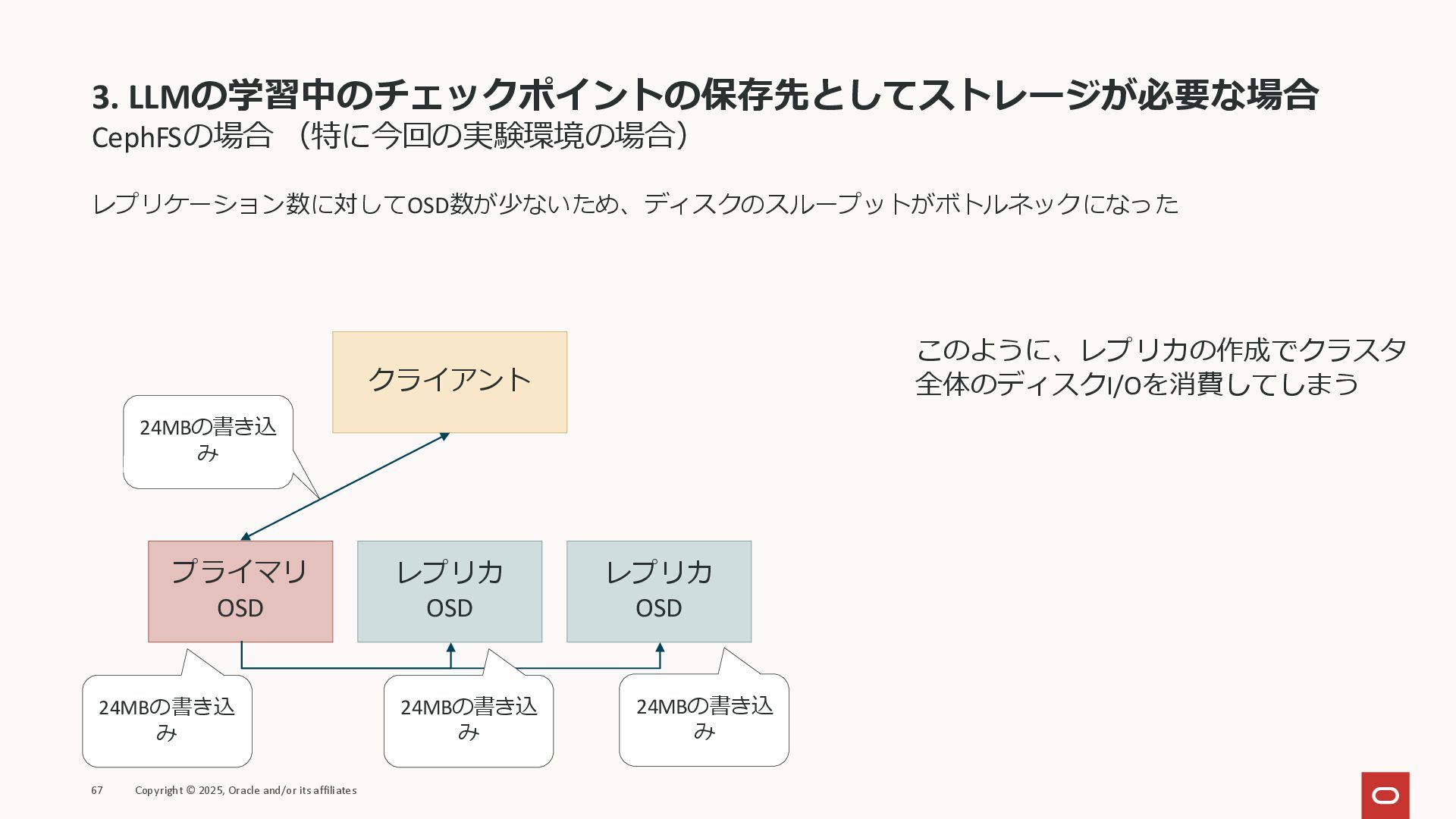
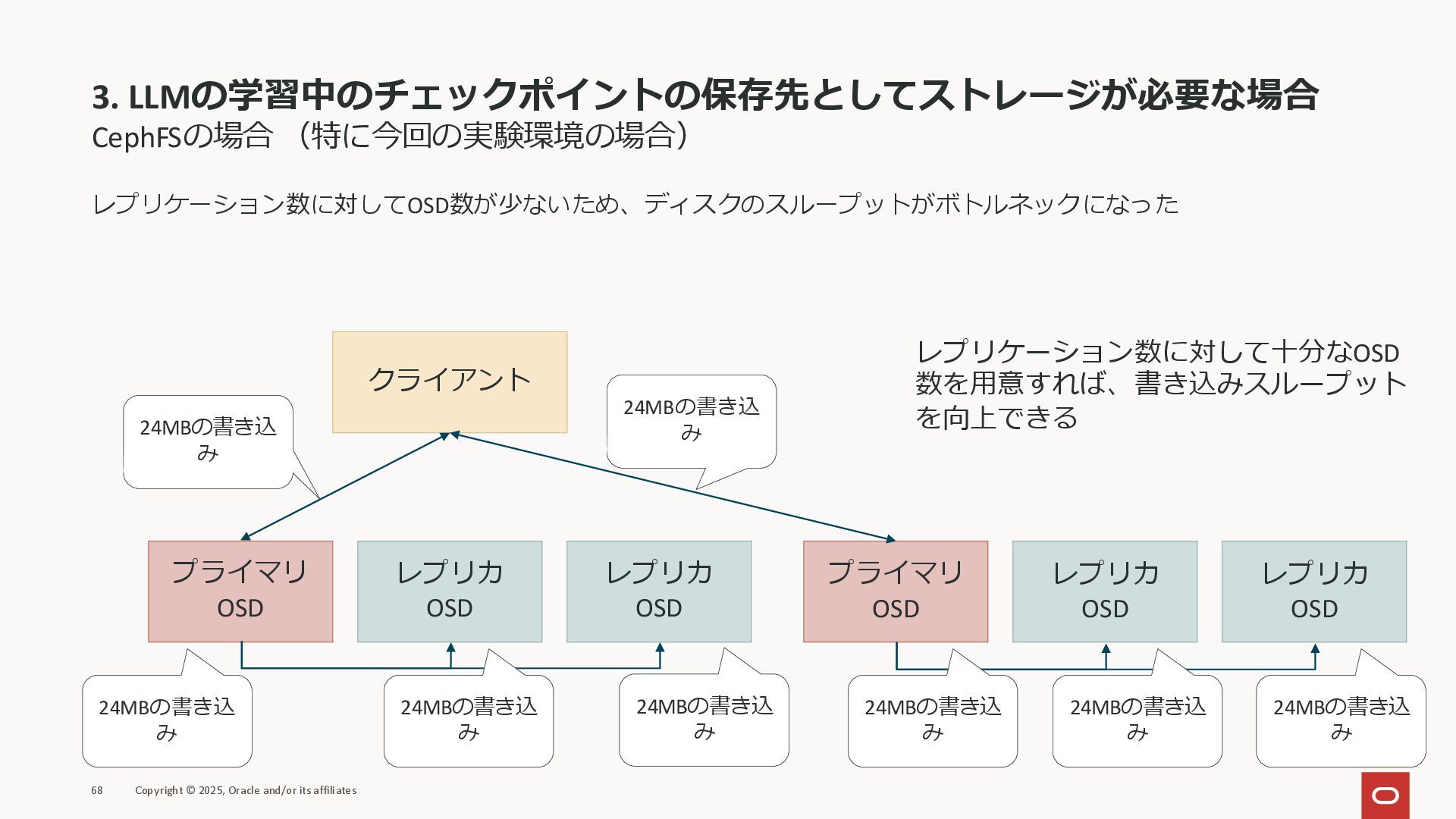
3. LLMの学習中のチェックポイントの保存先としてストレージが必要な場合 CephFSの場合 (特に今回の実験環境の場合) レプリケーション数に対してOSD数が少ないため、ディスクのスループットがボトルネックになった 67 Copyright © 2025, Oracle
and/or its affiliates クライアント プライマリ OSD レプリカ OSD レプリカ OSD 24MBの書き込 み 24MBの書き込 み 24MBの書き込 み 24MBの書き込 み このように、レプリカの作成でクラスタ 全体のディスクI/Oを消費してしまう
3. LLMの学習中のチェックポイントの保存先としてストレージが必要な場合 CephFSの場合 (特に今回の実験環境の場合) レプリケーション数に対してOSD数が少ないため、ディスクのスループットがボトルネックになった 68 Copyright © 2025, Oracle
and/or its affiliates レプリケーション数に対して十分なOSD 数を用意すれば、書き込みスループット を向上できる クライアント プライマリ OSD レプリカ OSD レプリカ OSD 24MBの書き込 み 24MBの書き込 み 24MBの書き込 み 24MBの書き込 み プライマリ OSD レプリカ OSD レプリカ OSD 24MBの書き込 み 24MBの書き込 み 24MBの書き込 み 24MBの書き込 み
3. LLMの学習中のチェックポイントの保存先としてストレージが必要な場合 Lustreの場合 Lustreはファイル・ディレクトリ作成時に柔軟にストライピングパターンを決められる ストライピングパターンのことをLustreではファイルレイアウトと呼び、さまざまなレイアウトを指定できる • Normal / RAID0 レイアウト
• 複合レイアウト • Progressive File Layout • Self Extending Layout • Metadata on MDT • File Layout Redundancy 69 Copyright © 2025, Oracle and/or its affiliates ※Lustreは基本的にレプリケーションを行わないため、書き込みスループットが高い
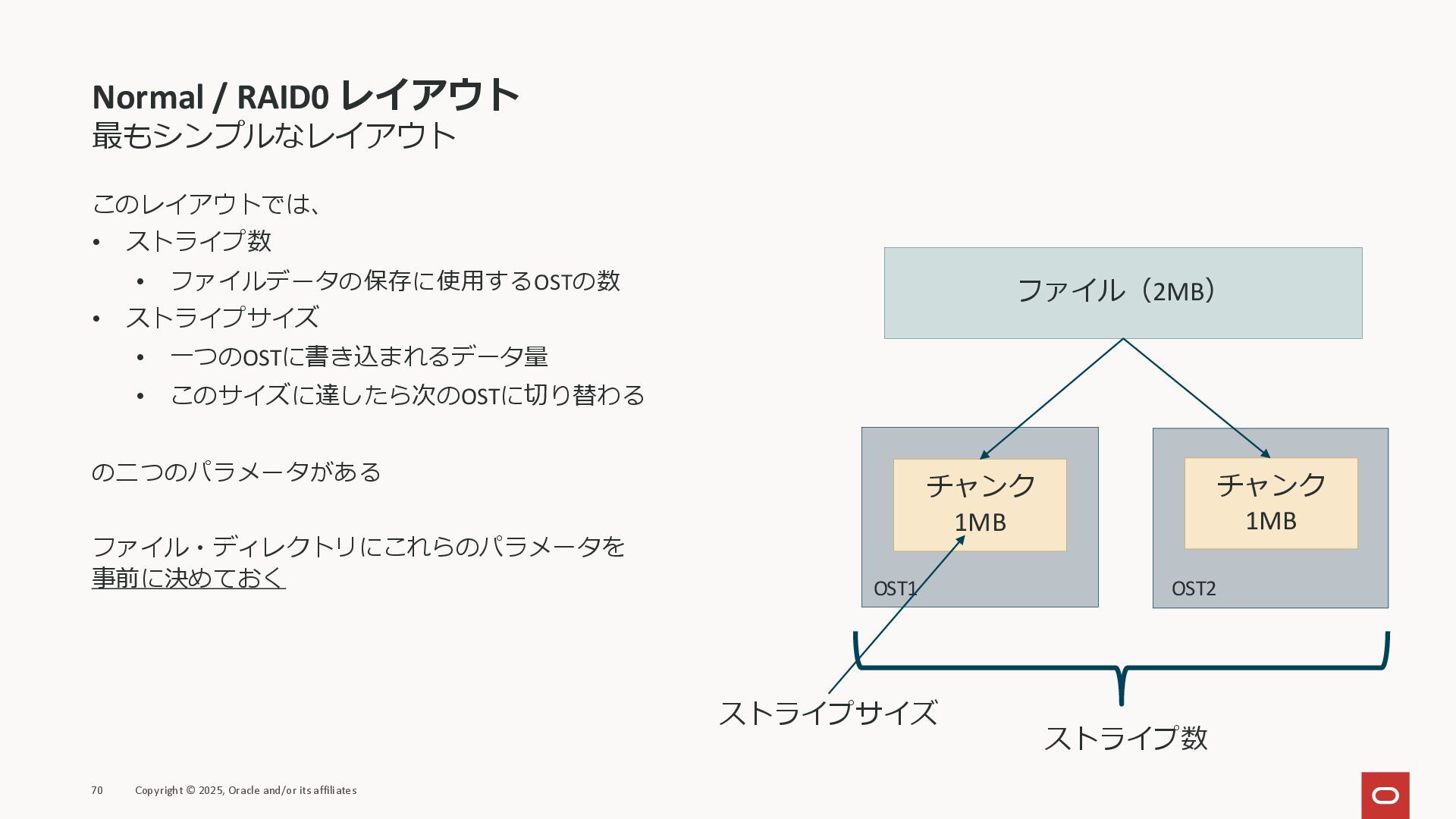
Normal / RAID0 レイアウト 最もシンプルなレイアウト このレイアウトでは、 • ストライプ数 • ファイルデータの保存に使用するOSTの数
• ストライプサイズ • 一つのOSTに書き込まれるデータ量 • このサイズに達したら次のOSTに切り替わる の二つのパラメータがある ファイル・ディレクトリにこれらのパラメータを 事前に決めておく 70 Copyright © 2025, Oracle and/or its affiliates ファイル(2MB) チャンク 1MB チャンク 1MB OST1 OST2 ストライプ数 ストライプサイズ
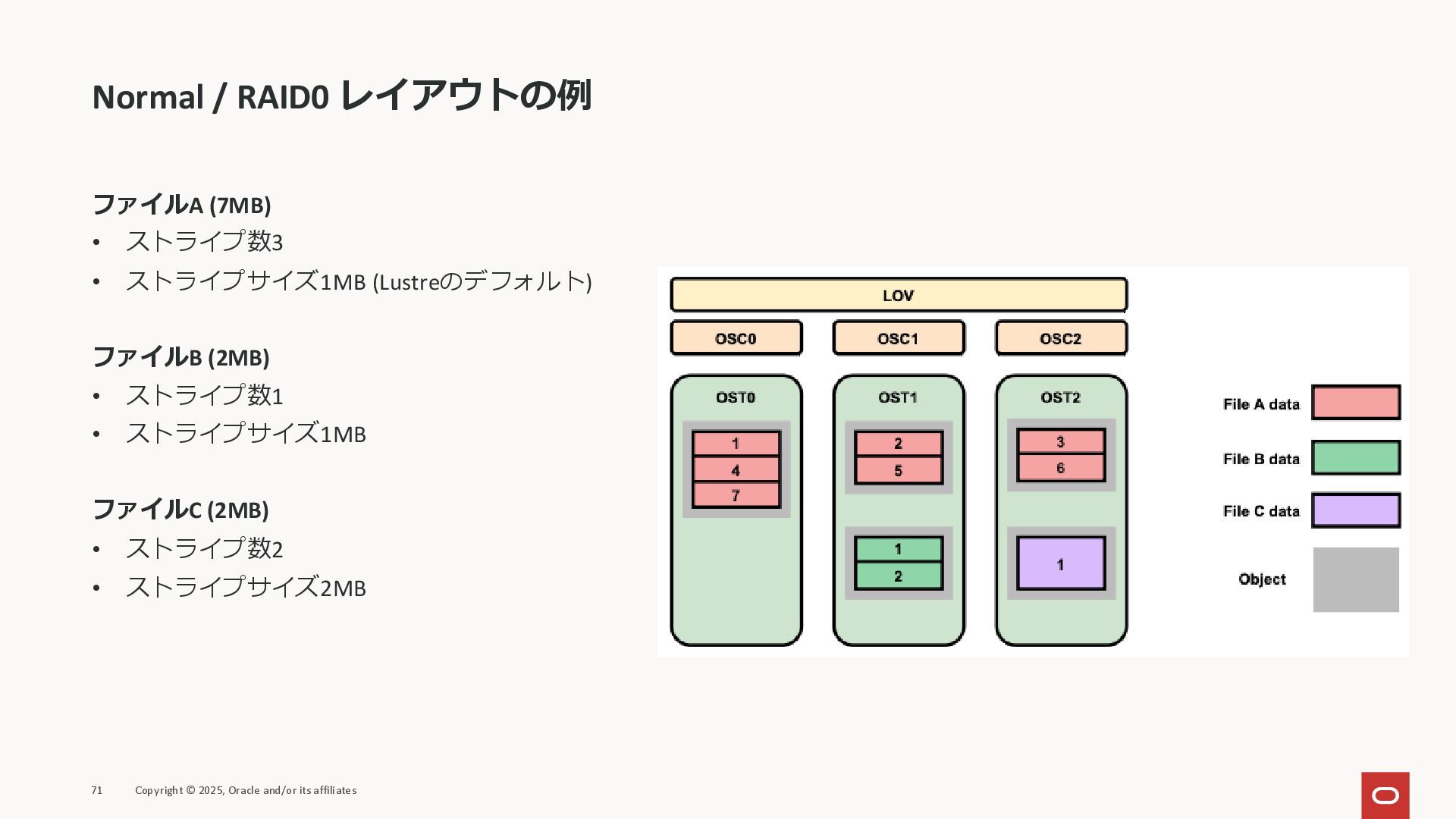
Normal / RAID0 レイアウトの例 ファイルA (7MB) • ストライプ数3 • ストライプサイズ1MB
(Lustreのデフォルト) ファイルB (2MB) • ストライプ数1 • ストライプサイズ1MB ファイルC (2MB) • ストライプ数2 • ストライプサイズ2MB 71 Copyright © 2025, Oracle and/or its affiliates
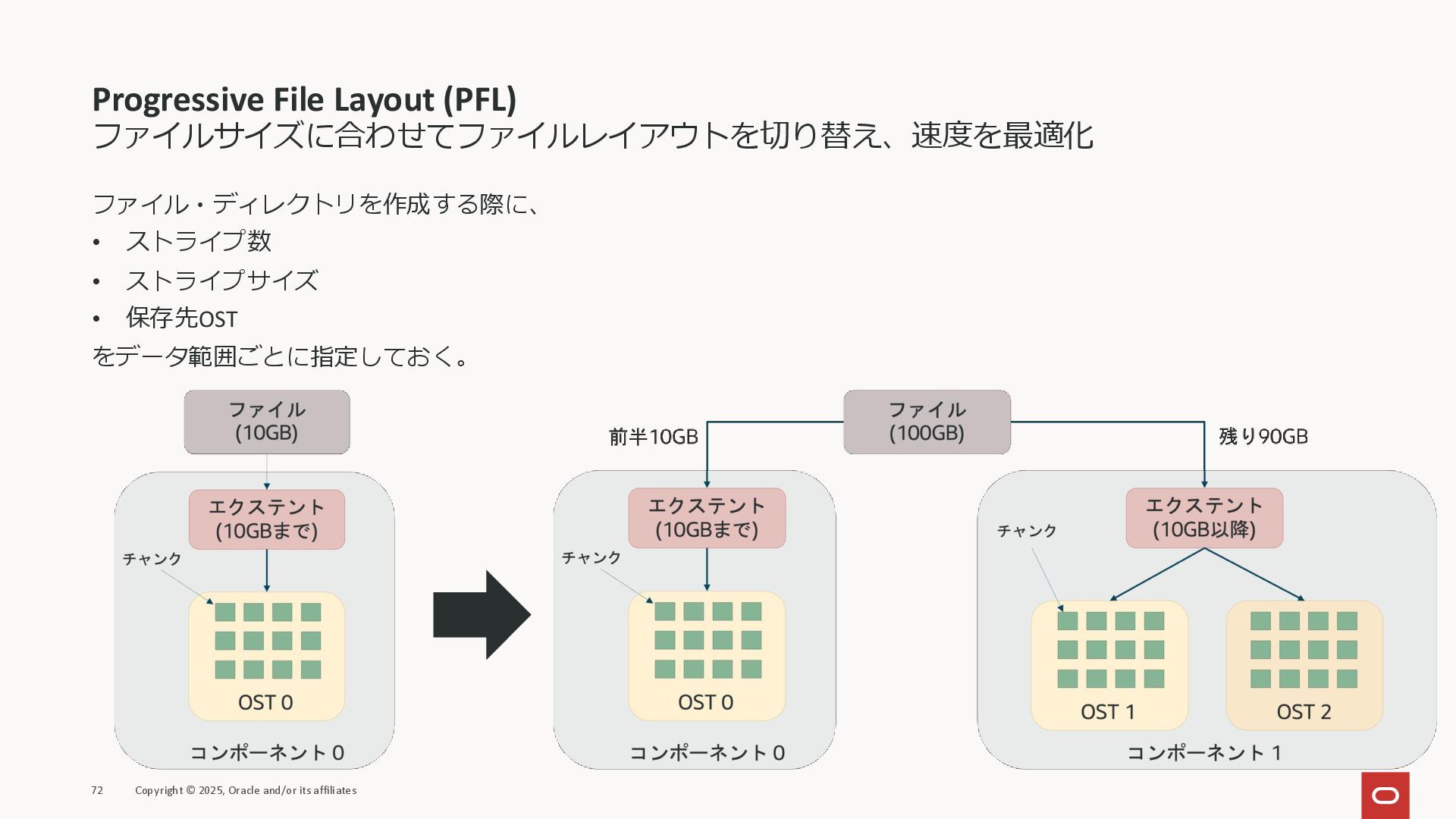
Progressive File Layout (PFL) ファイルサイズに合わせてファイルレイアウトを切り替え、速度を最適化 ファイル・ディレクトリを作成する際に、 • ストライプ数 • ストライプサイズ
• 保存先OST をデータ範囲ごとに指定しておく。 72 Copyright © 2025, Oracle and/or its affiliates
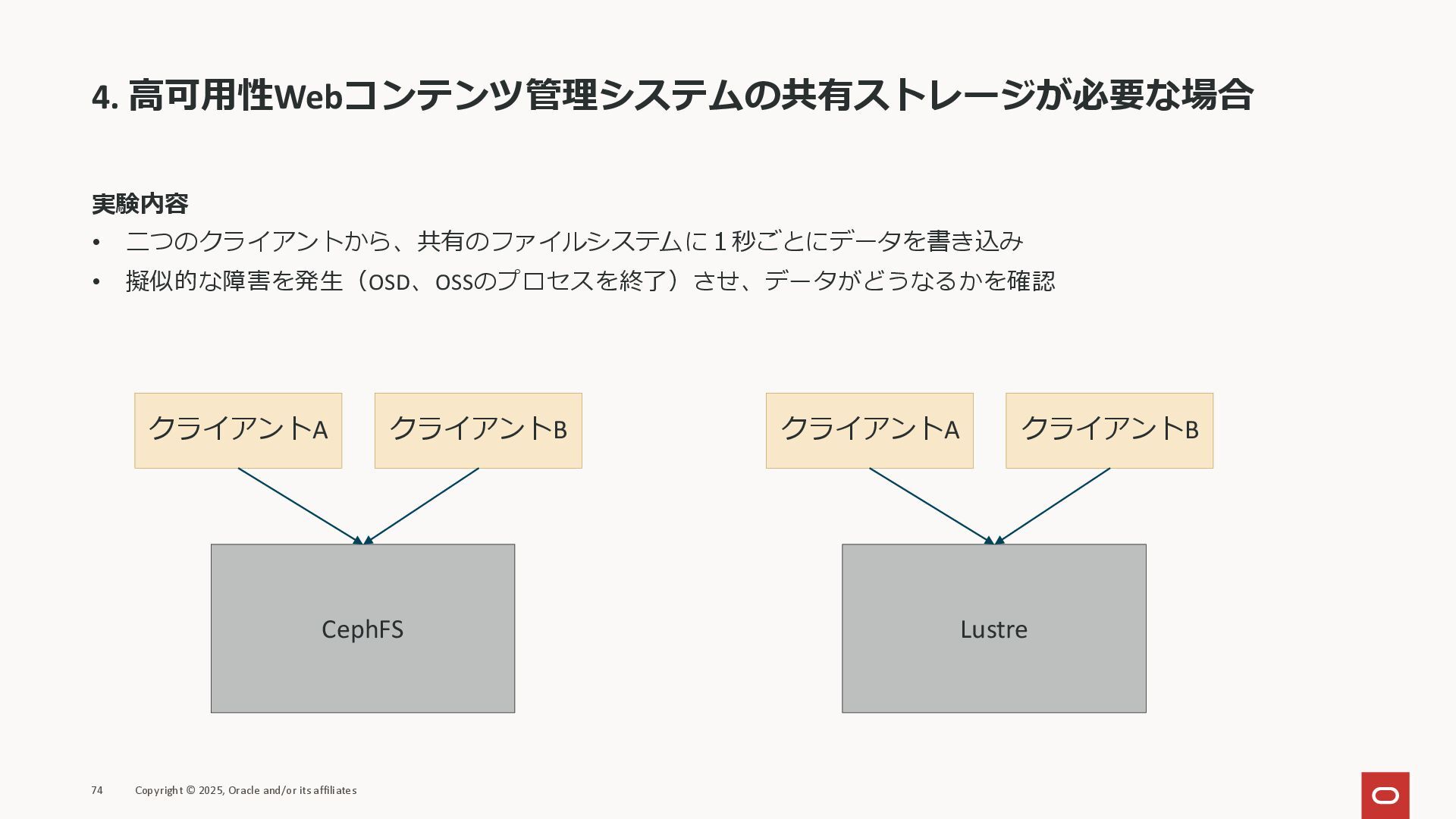
4. 高可用性Webコンテンツ管理システムの共有ストレージが必要な場合 求められること 複数のWebサーバーから同時に読み書き(ReadWriteMany)できる → ファイルストレージが最適 障害が発生してもデータが失われない 73 Copyright ©
2025, Oracle and/or its affiliates CephFS • ハードウェアRAIDに頼らず、ソフトウェアレベル でデータをレプリケーションするため、サーバー 筐体ごとの障害が起きても別のノードにあるコ ピーからデータを即座に利用できる Lustre • Lustre自体はデータの冗長性を提供しないため、ハー ドウェアRAIDなどに完全に依存する。RAIDコントロー ラー障害などでRAIDアレイ全体が破損した場合は、 データを失うことになる CephFSが最適
4. 高可用性Webコンテンツ管理システムの共有ストレージが必要な場合 実験内容 • 二つのクライアントから、共有のファイルシステムに1秒ごとにデータを書き込み • 擬似的な障害を発生(OSD、OSSのプロセスを終了)させ、データがどうなるかを確認 74 Copyright ©
2025, Oracle and/or its affiliates クライアントA クライアントB CephFS クライアントA クライアントB Lustre
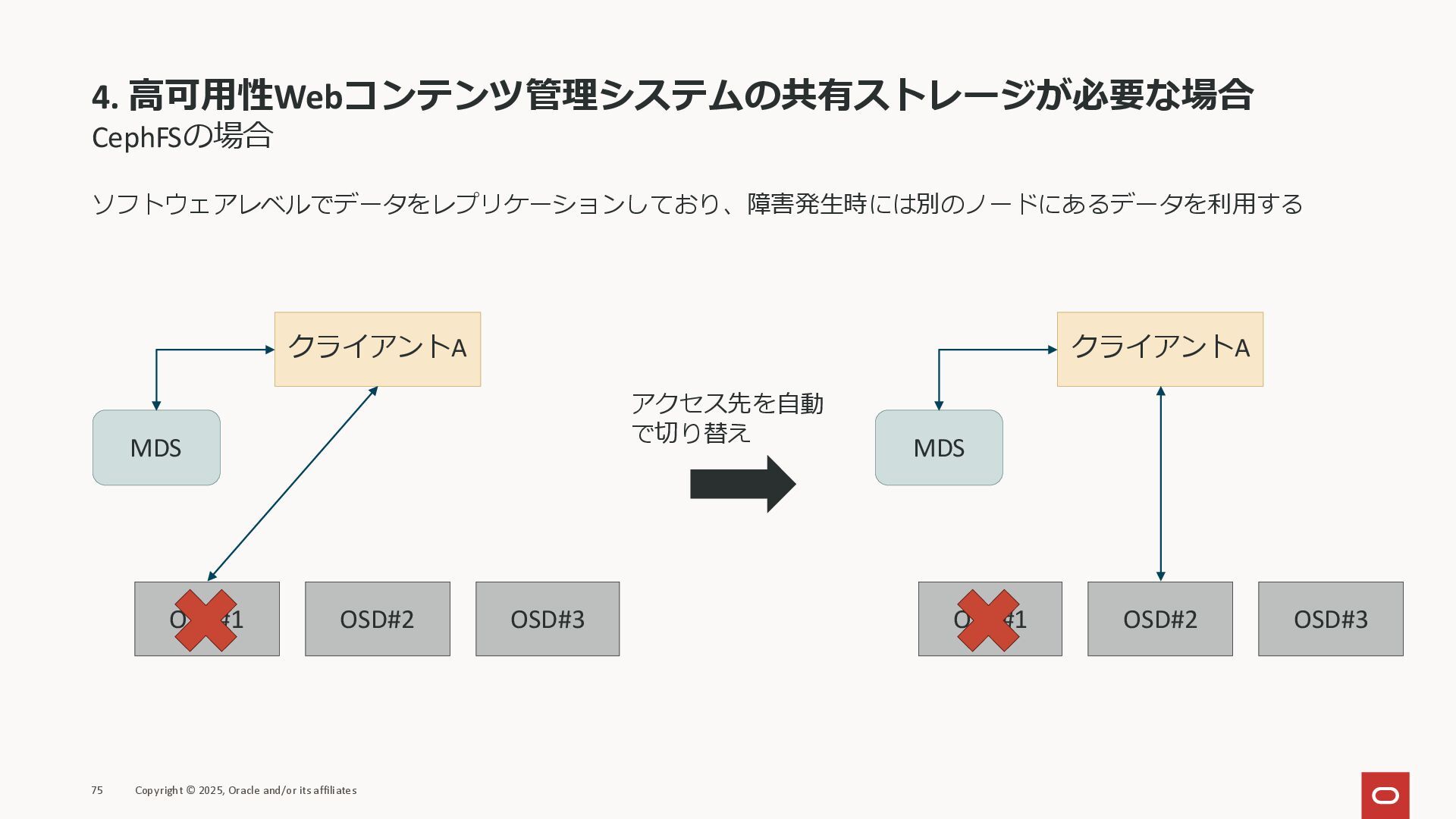
4. 高可用性Webコンテンツ管理システムの共有ストレージが必要な場合 CephFSの場合 ソフトウェアレベルでデータをレプリケーションしており、障害発生時には別のノードにあるデータを利用する 75 Copyright © 2025, Oracle and/or
its affiliates クライアントA OSD#1 OSD#2 OSD#3 MDS クライアントA OSD#1 OSD#2 OSD#3 MDS アクセス先を自動 で切り替え
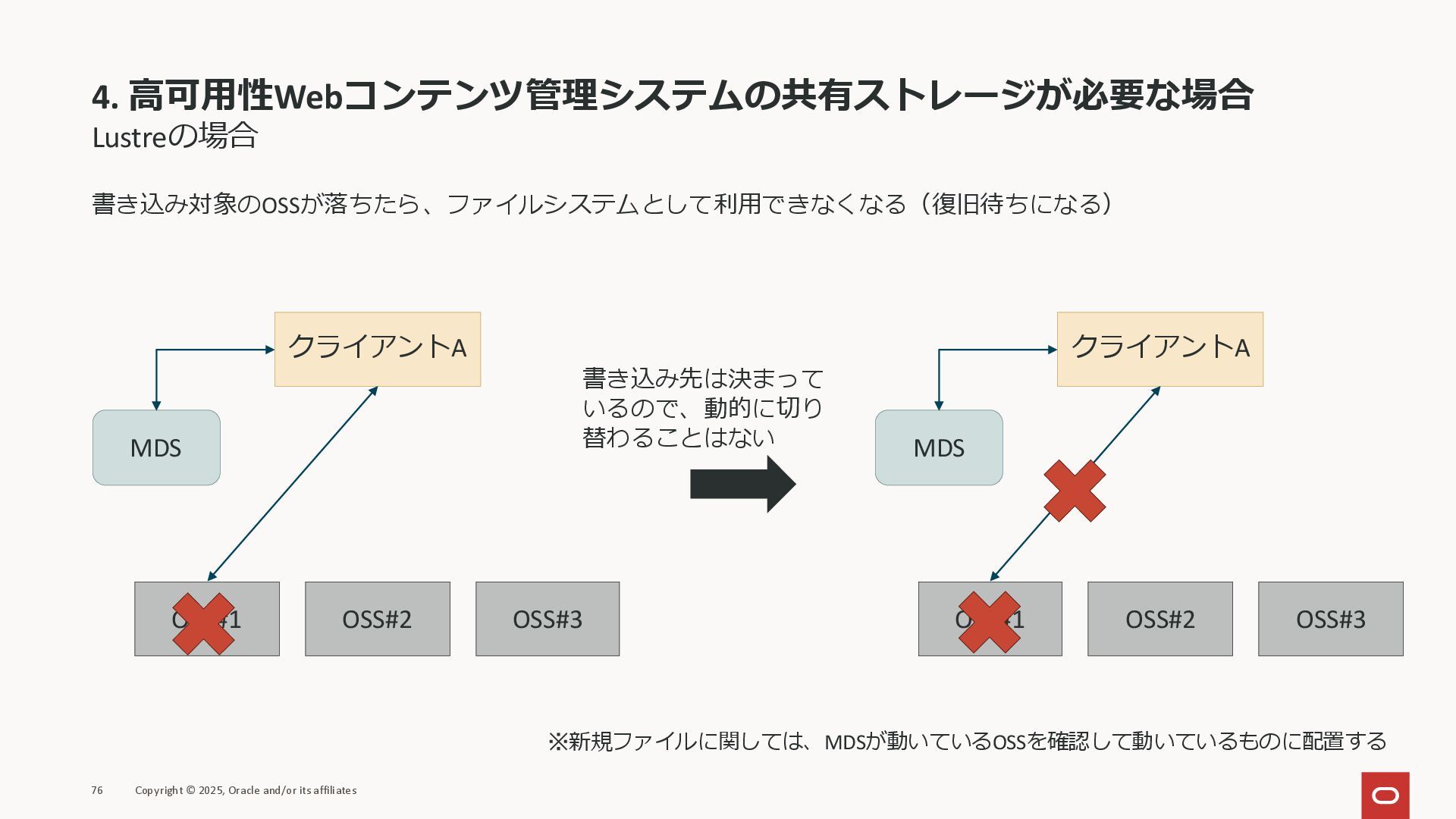
4. 高可用性Webコンテンツ管理システムの共有ストレージが必要な場合 Lustreの場合 書き込み対象のOSSが落ちたら、ファイルシステムとして利用できなくなる(復旧待ちになる) 76 Copyright © 2025, Oracle and/or
its affiliates クライアントA OSS#1 OSS#2 OSS#3 MDS クライアントA OSS#1 OSS#2 OSS#3 MDS 書き込み先は決まって いるので、動的に切り 替わることはない ※新規ファイルに関しては、MDSが動いているOSSを確認して動いているものに配置する
まとめ
まとめ クラウドストレージとは • ブロックストレージ: 生のディスクを提供 • ファイルストレージ: ファイル共有とファイルシステムの機能を提供 • オブジェクトストレージ:
HTTPでアクセスする大容量ストレージを提供 Cephとは • 上記のストレージ全てを提供できる分散ストレージ基盤で、ソフトウェア側でデータを保護している Lustreとは • ファイルストレージのみを提供し、データ保護をソフトウェア側で行わない代わりに超高スループット ユースケースからクラウドストレージを選択するには • パフォーマンス(スループット・レイテンシ)、排他制御の有無、ファイルサイズやファイル数など、多角的に評 価が必要 78 Copyright © 2025, Oracle and/or its affiliates
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}