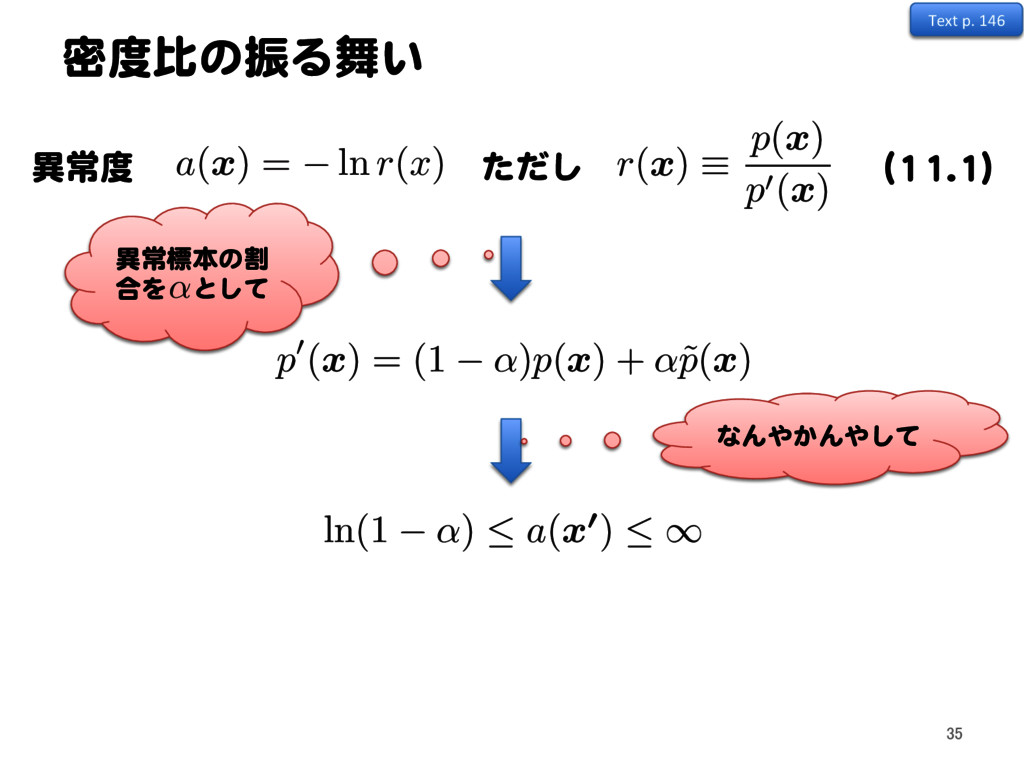
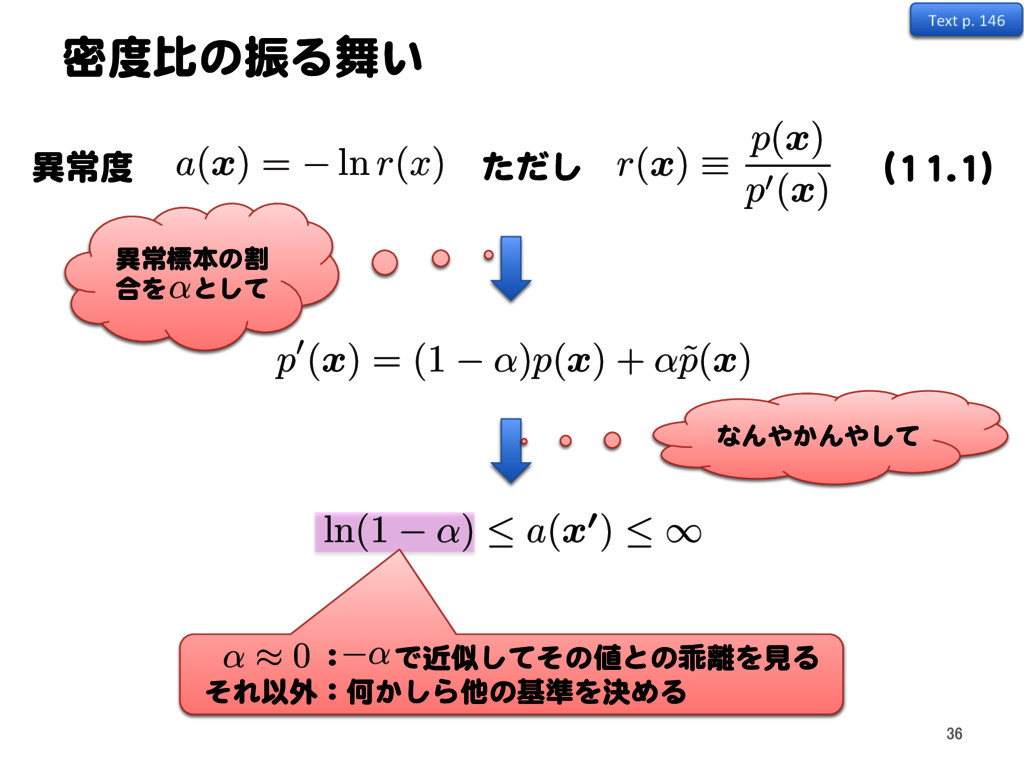
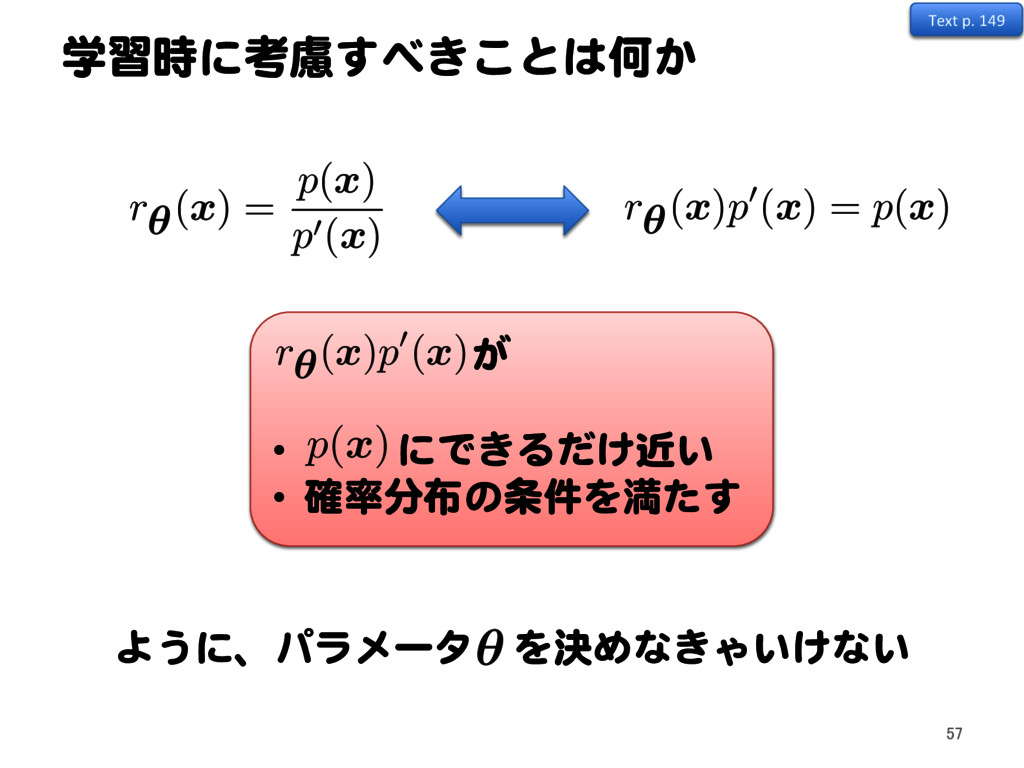
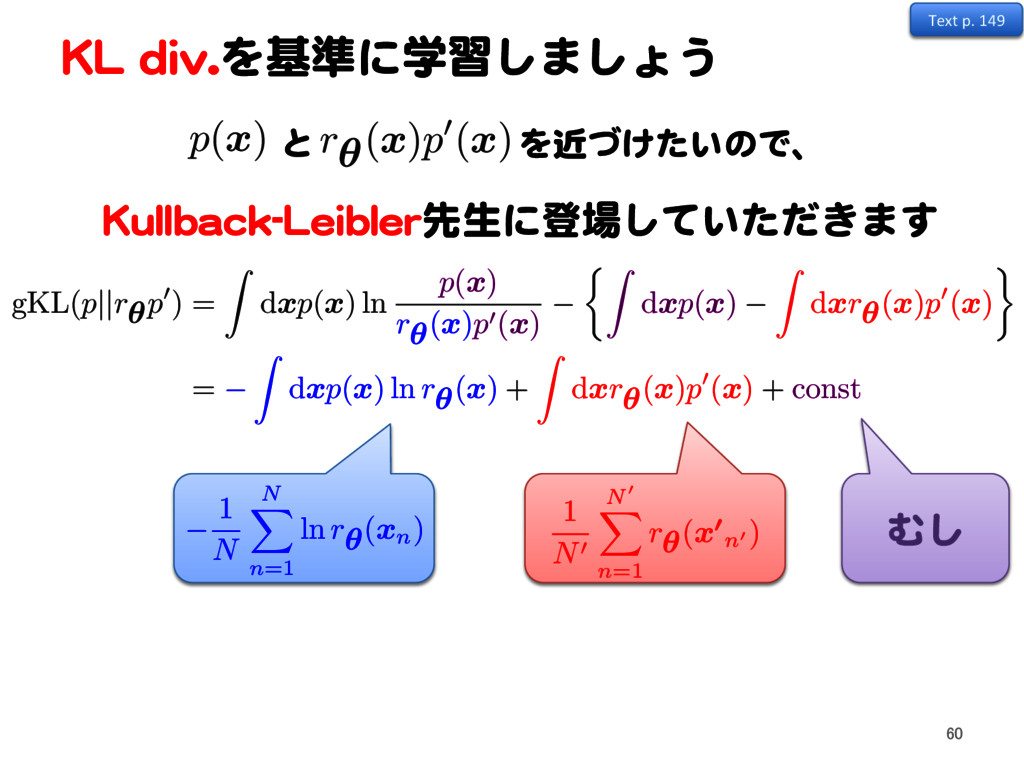
p0 ) = Z dx p (x) ln p (x) r ✓(x) p0 (x) ⇢Z dx p (x) Z dx r ✓(x) p0 (x) = Z dx p (x) ln r ✓(x) + Z dx r ✓(x) p0 (x) + const と を近づけたいので、 r ✓ ( x )p0( x ) p( x )
p0 ) = Z dx p (x) ln p (x) r ✓(x) p0 (x) ⇢Z dx p (x) Z dx r ✓(x) p0 (x) = Z dx p (x) ln r ✓(x) + Z dx r ✓(x) p0 (x) + const と を近づけたいので、 r ✓ ( x )p0( x ) p( x )
r ✓ ( xn) 1 N0 N0 X n=1 r ✓ ( x 0 n0 ) Text p. 149 60 gKL( p||r ✓ p0 ) = Z dx p (x) ln p (x) r ✓(x) p0 (x) ⇢Z dx p (x) Z dx r ✓(x) p0 (x) = Z dx p (x) ln r ✓(x) + Z dx r ✓(x) p0 (x) + const と を近づけたいので、 r ✓ ( x )p0( x ) p( x )
p( x ) Kullback-Leibler先生に登場していただきます むし = 1 N N X n=1 ln r ✓ ( xn) + 1 N0 N0 X n0=1 r ✓ ( x 0 n0 ) 1 N N X n=1 ln r ✓ ( xn) 1 N0 N0 X n=1 r ✓ ( x 0 n0 ) Text p. 149 61 gKL( p||r ✓ p0 ) = Z dx p (x) ln p (x) r ✓(x) p0 (x) ⇢Z dx p (x) Z dx r ✓(x) p0 (x) = Z dx p (x) ln r ✓(x) + Z dx r ✓(x) p0 (x) + const
X n=1 ln r ✓ ( xn) + 1 N0 N0 X n0=1 r ✓ ( x 0 n0 ) = r 1 N N X n=1 ln ✓ > ( xn) + 1 N0 N0 X n0=1 ✓ > ( x 0 n0 ) = 1 N N X n=1 ( xn) ✓ > ( xn) + 1 N0 N0 X n0=1 ( x 0 n0 ) 問題(11.5)は凸最適化問題なので、 勾配法とかで最適解が求まります 適当な初期値から収束するまで以下よろしくー ✓new ✓old ⌘rJ(✓old) Text p. 150 67
d x p( x ) ln p( x ) Z d x q( x ) ln q( x ) h p q , r'( q )i = Z d x p( x ) ln p( x ) Z d x q( x ) ln q( x ) Z d x p( x ) q( x ) ln q( x ) + 1 = Z d x p( x ) ln p( x ) q( x ) Z d x p( x ) + Z d x q( x ) gKL( p || q ) ⌘ D'( p || q ) = Z d x p( x ) ln p( x ) q( x ) Z d x p( x ) + Z d x q( x ) 一般化KLダイバージェンス 83 とおくと '( p ) = Z d x p( x ) ln p( x ) Bregmanダイバージェンスで
d x p( x ) ln p( x ) Z d x q( x ) ln q( x ) h p q , r'( q )i = Z d x p( x ) ln p( x ) Z d x q( x ) ln q( x ) Z d x p( x ) q( x ) ln q( x ) + 1 = Z d x p( x ) ln p( x ) q( x ) Z d x p( x ) + Z d x q( x ) gKL( p || q ) ⌘ D'( p || q ) = Z d x p( x ) ln p( x ) q( x ) Z d x p( x ) + Z d x q( x ) 一般化KLダイバージェンス Z d x p( x ) = 1, Z d x q( x ) = 1 を満たすなら KLダイバージェンス KL( p || q ) ⌘ Dnorm ' ( p || q ) = Z d x p( x ) ln p( x ) q( x ) 84 とおくと '( p ) = Z d x p( x ) ln p( x ) Bregmanダイバージェンスで
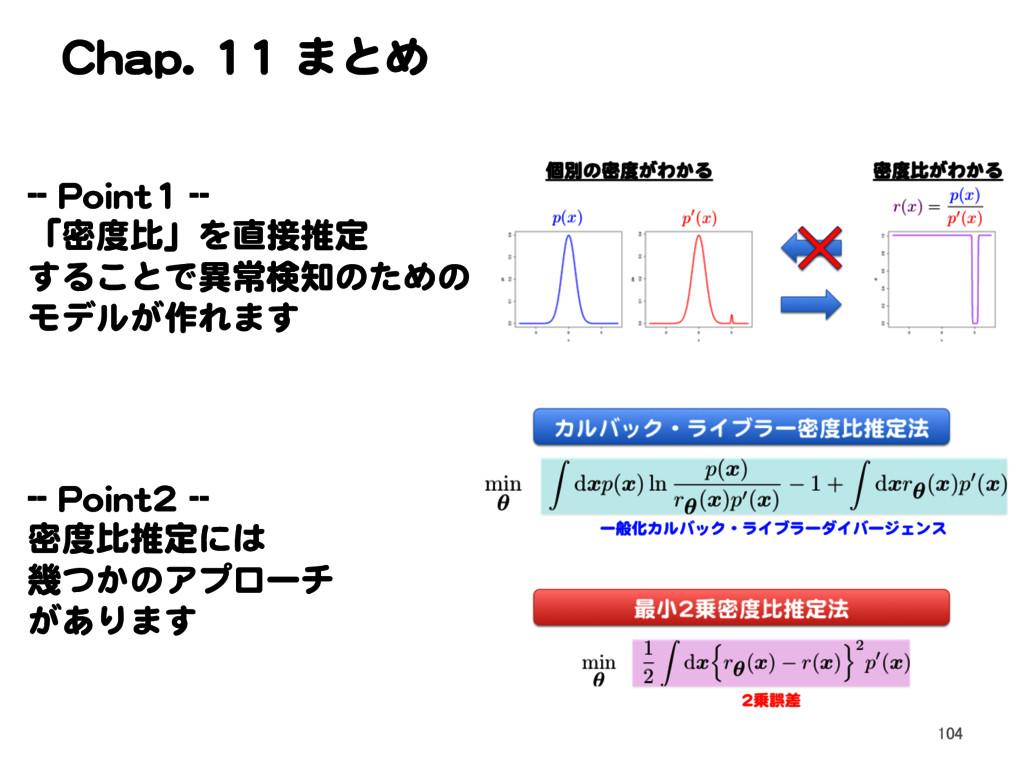
ln p( x ) r ✓ ( x )p0( x ) 1 + Z d x r ✓ ( x )p0( x ) min ✓ 1 2 Z d x nr ✓ ( x ) r( x )o2 p0( x ) カルバック・ライブラー密度比推定法 一般化カルバック・ライブラーダイバージェンス 最小2乗密度比推定法 2乗誤差 Text p. 154 89
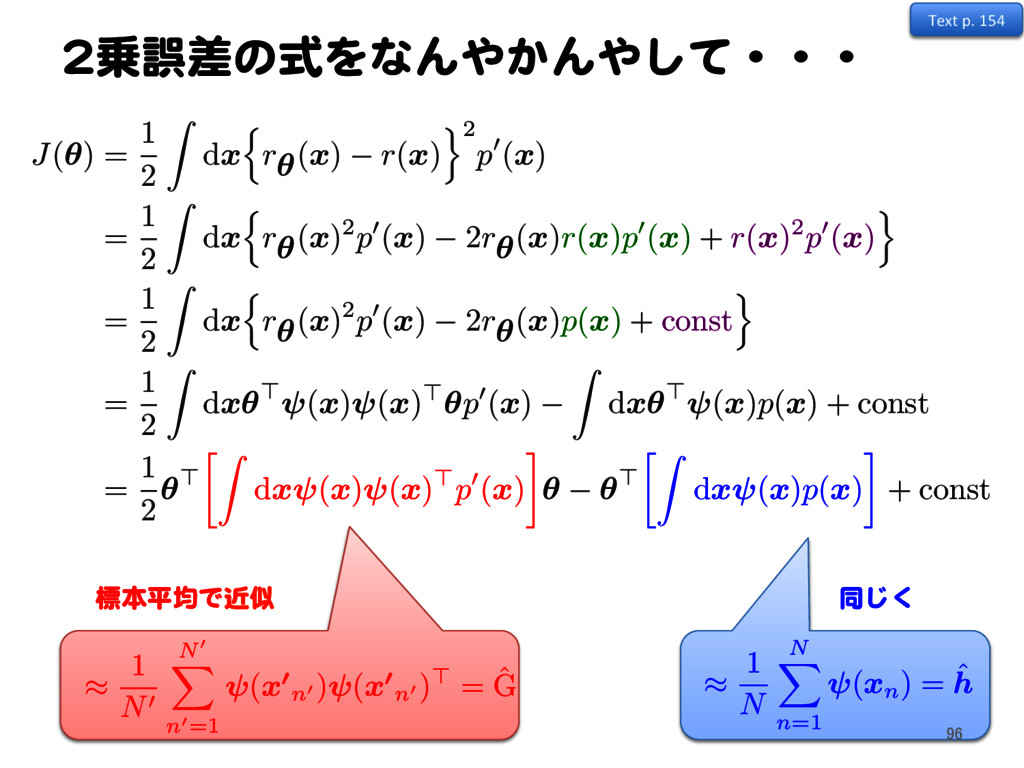
r (x) o2 p0 (x) = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) r (x) p0 (x) + r (x) 2p0 (x) o = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) p (x) + const o = 1 2 Z dx✓ > (x) (x) > ✓ p0 (x) Z dx✓ > (x) p (x) + const = 1 2 ✓ > Z dx (x) (x) >p0 (x) ✓ ✓ > Z dx (x) p (x) + const Text p. 154 91
r (x) o2 p0 (x) = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) r (x) p0 (x) + r (x) 2p0 (x) o = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) p (x) + const o = 1 2 Z dx✓ > (x) (x) > ✓ p0 (x) Z dx✓ > (x) p (x) + const = 1 2 ✓ > Z dx (x) (x) >p0 (x) ✓ ✓ > Z dx (x) p (x) + const Text p. 154 92
r (x) o2 p0 (x) = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) r (x) p0 (x) + r (x) 2p0 (x) o = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) p (x) + const o = 1 2 Z dx✓ > (x) (x) > ✓ p0 (x) Z dx✓ > (x) p (x) + const = 1 2 ✓ > Z dx (x) (x) >p0 (x) ✓ ✓ > Z dx (x) p (x) + const Text p. 154 93
r (x) o2 p0 (x) = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) r (x) p0 (x) + r (x) 2p0 (x) o = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) p (x) + const o = 1 2 Z dx✓ > (x) (x) > ✓ p0 (x) Z dx✓ > (x) p (x) + const = 1 2 ✓ > Z dx (x) (x) >p0 (x) ✓ ✓ > Z dx (x) p (x) + const Text p. 154 94
r (x) o2 p0 (x) = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) r (x) p0 (x) + r (x) 2p0 (x) o = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) p (x) + const o = 1 2 Z dx✓ > (x) (x) > ✓ p0 (x) Z dx✓ > (x) p (x) + const = 1 2 ✓ > Z dx (x) (x) >p0 (x) ✓ ✓ > Z dx (x) p (x) + const Text p. 154 95
n0 ) ( x 0 n0 )> = ˆ G ⇡ 1 N N X n=1 ( xn) = ˆ h 標本平均で近似 同じく J (✓) = 1 2 Z dx nr ✓(x) r (x) o2 p0 (x) = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) r (x) p0 (x) + r (x) 2p0 (x) o = 1 2 Z dx nr ✓(x) 2p0 (x) 2 r ✓(x) p (x) + const o = 1 2 Z dx✓ > (x) (x) > ✓ p0 (x) Z dx✓ > (x) p (x) + const = 1 2 ✓ > Z dx (x) (x) >p0 (x) ✓ ✓ > Z dx (x) p (x) + const Text p. 154 96
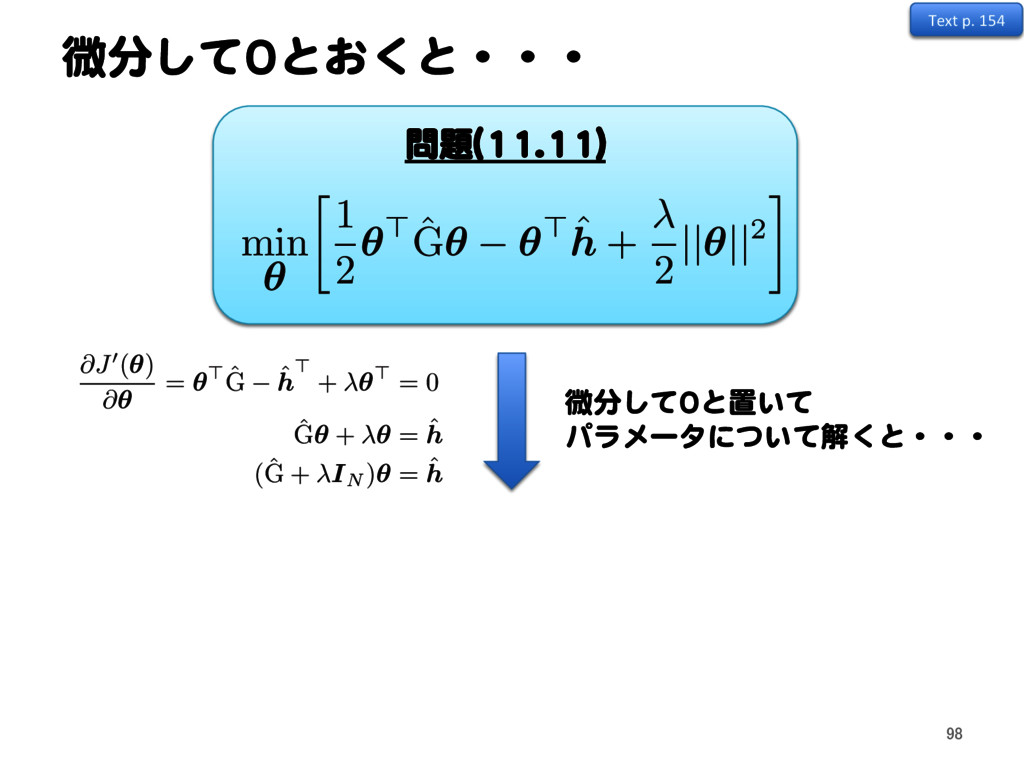
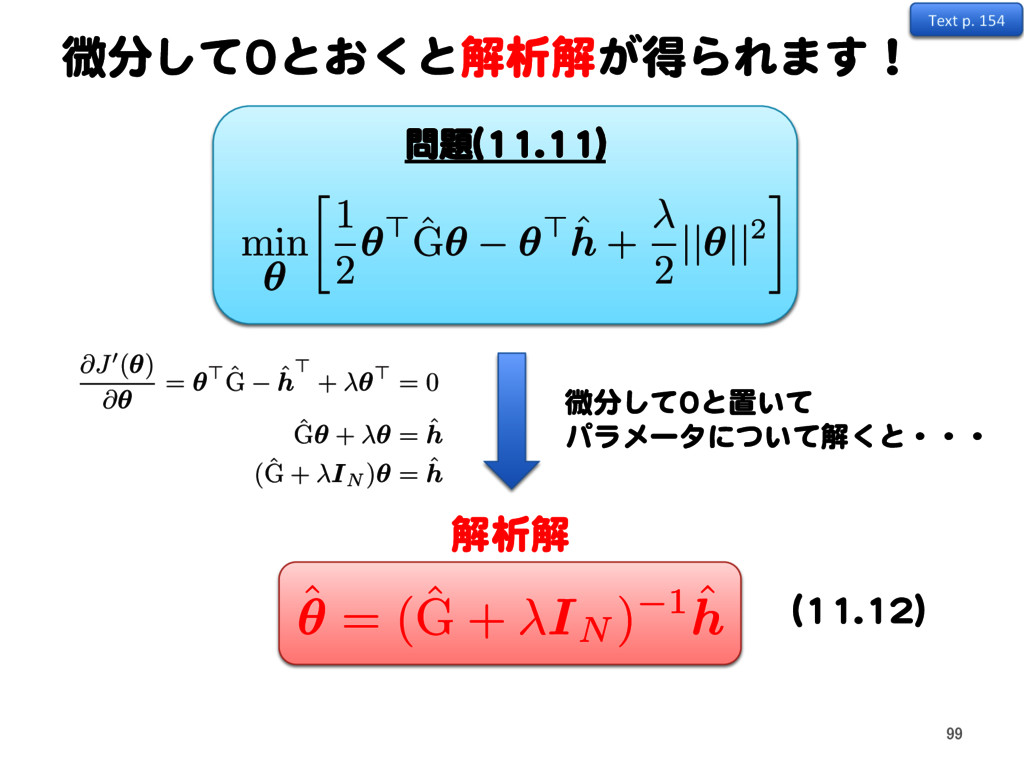
✓> ˆ h + 2 ||✓||2 @J0(✓) @✓ = ✓> ˆ G ˆ h > + ✓> = 0 ˆ G✓ + ✓ = ˆ h (ˆ G + IN )✓ = ˆ h ˆ ✓ = (ˆ G + IN ) 1 ˆ h 解析解 微分して0と置いて パラメータについて解くと・・・ Text p. 154 99 (11.12)
M. Sugiyama, T. Suzuki, and T. Kanamori. Density Ratio Estimation In Machine Learning. CAMBRIDGE UNIVERSITY PRESS. 2012. 3. M. Sugiyama, et al. Direct Importance Estimation with Model Selection and Its Application to Covariate Shift Adaptation. NIPS. 2008. 4. T. Kanamori, et al. A Least-squares Approach to Direct Importance Estimation. JMLR, 10, 1391-1445. 2009. 5. A. Banerjee, et al. Clustering with Bregman Divergences. JMLR 6, 1705-1749. 2005. 6. J. Ghosh. Bregman Divergence for Data Mining Meta-Algorithms. slide. 7. S. Boyd, and L. Vandenberghe. Convex Optimization. CAMBRIDGE UNIVERSITY PRESS. 2004. 112
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
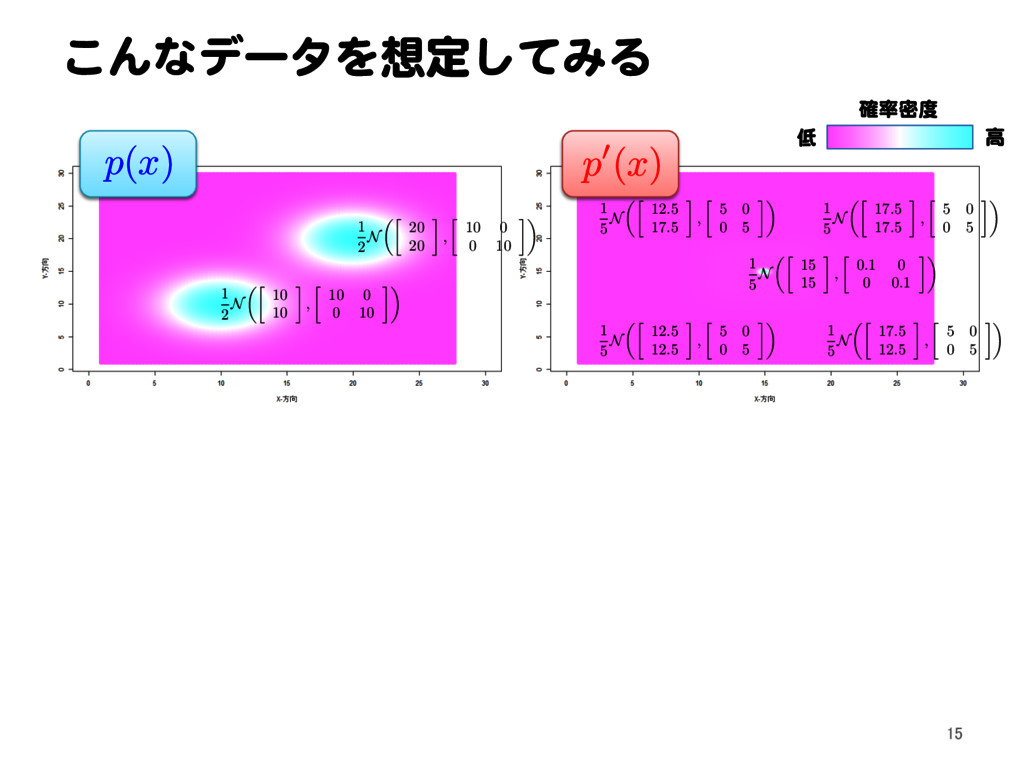
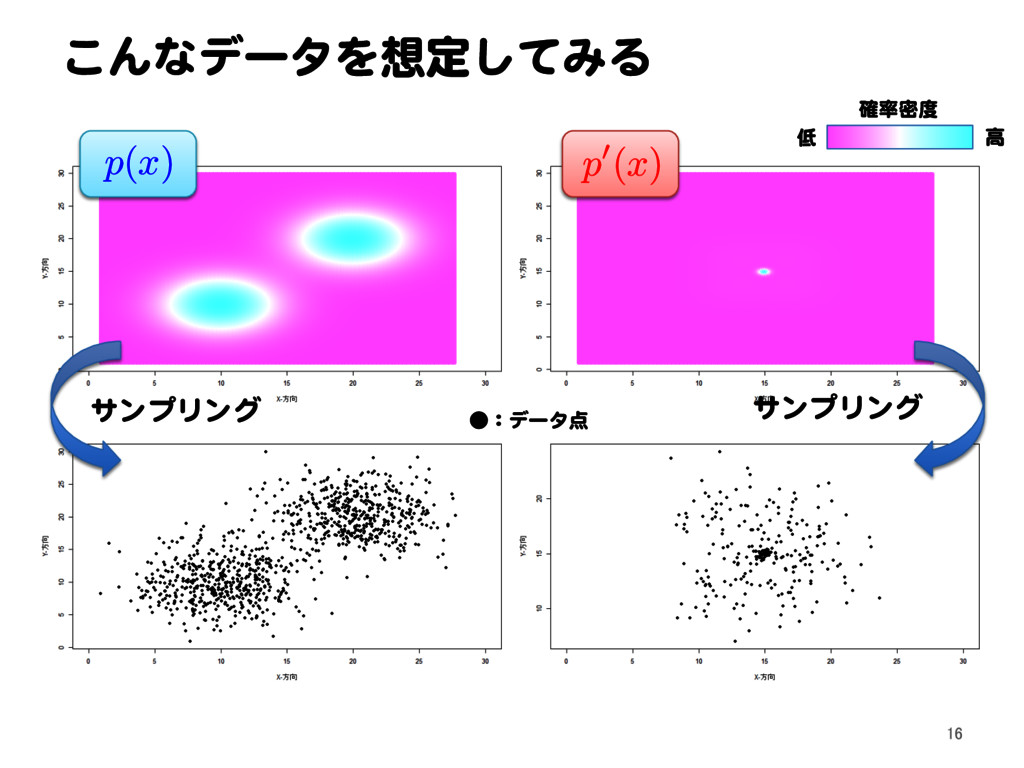
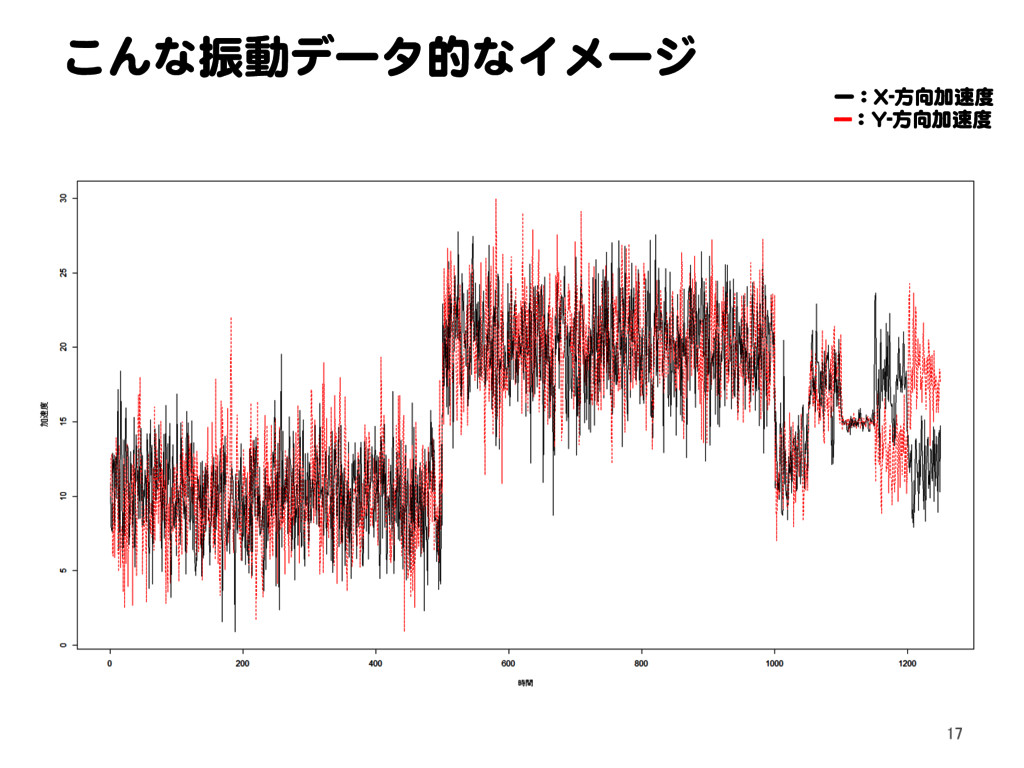
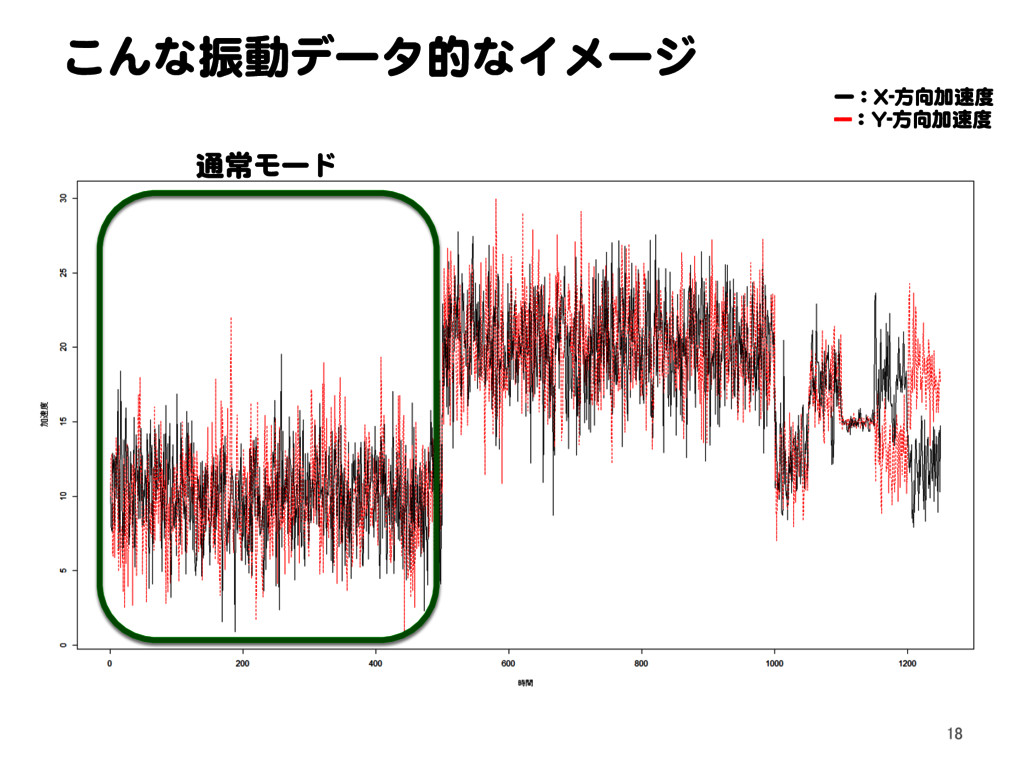
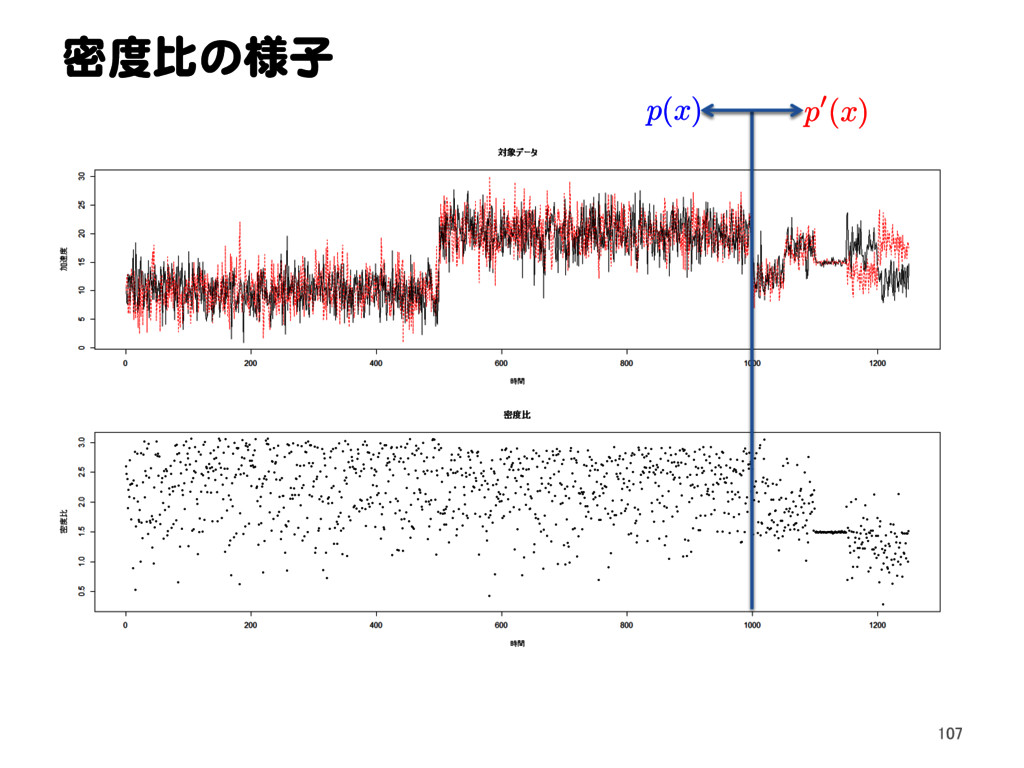
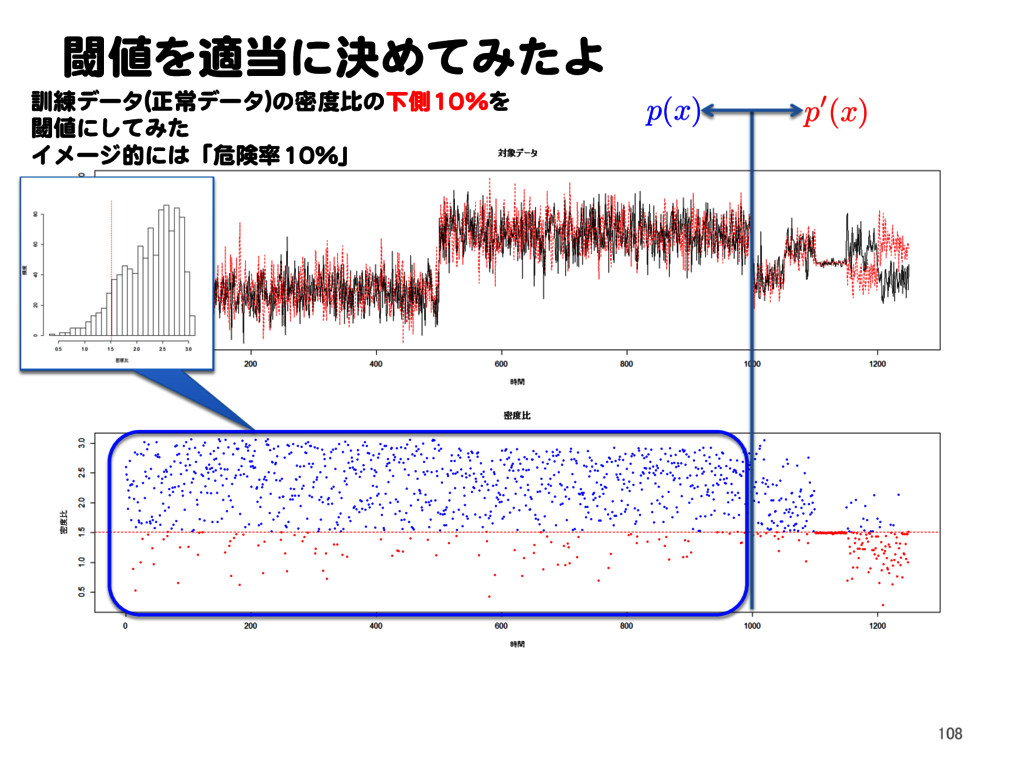
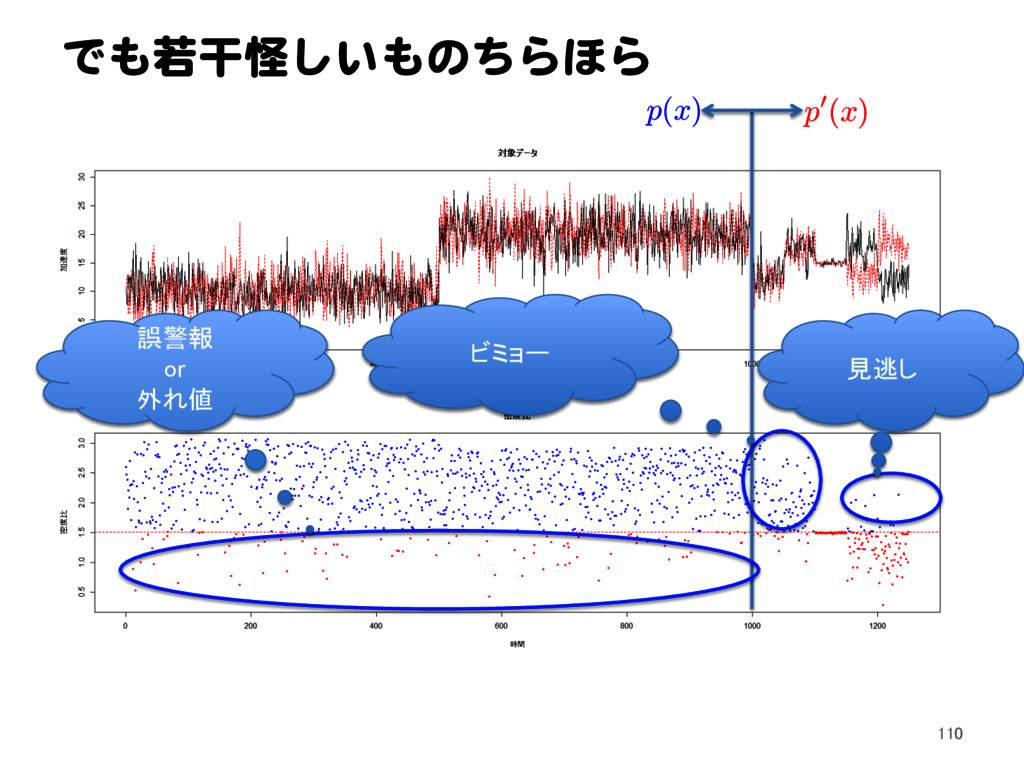
![密度比推定による異常検知 11.1 密度比による外れ値検出問題の定式化[1] Text p. 145 32](https://files.speakerdeck.com/presentations/2a15bf72f0174eca864cb2a3c5948694/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
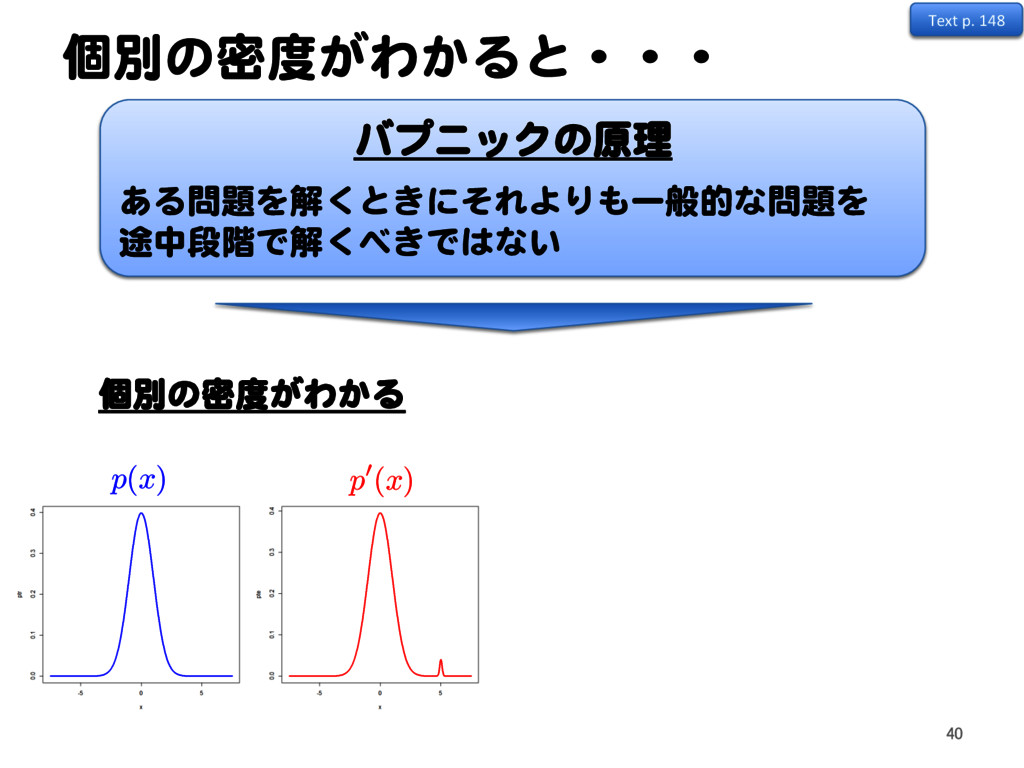
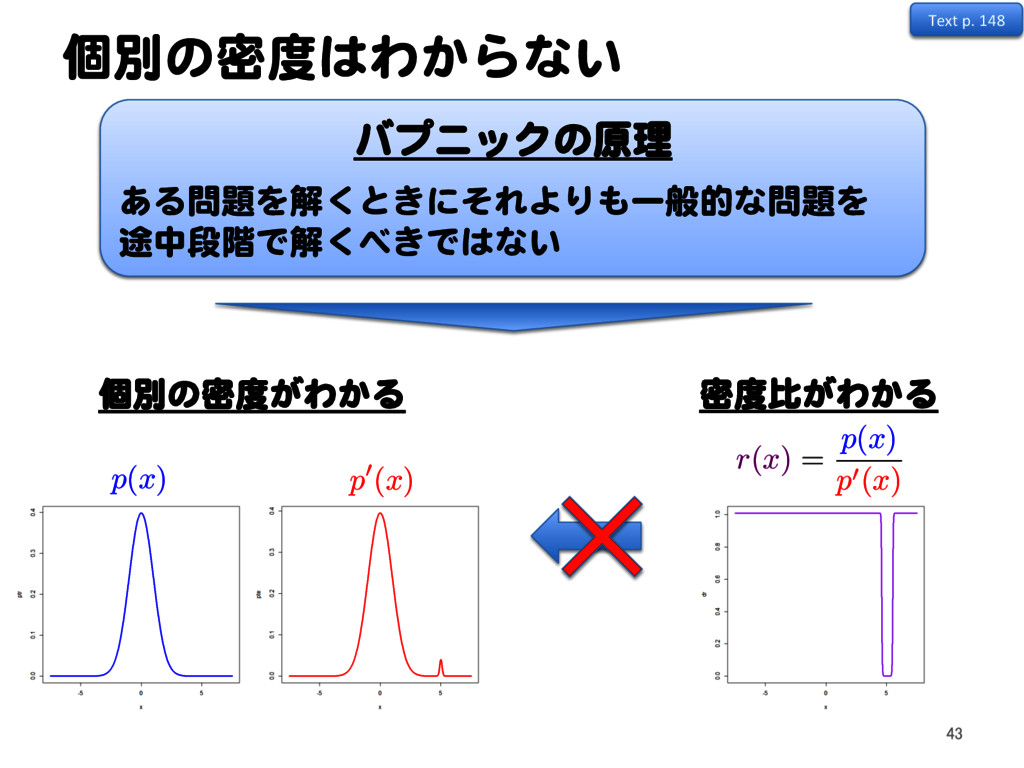
![密度比推定による異常検知 11.2 カルバック・ライブラー密度比推定法 [1, 2, 3] Text p. 148 47](https://files.speakerdeck.com/presentations/2a15bf72f0174eca864cb2a3c5948694/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
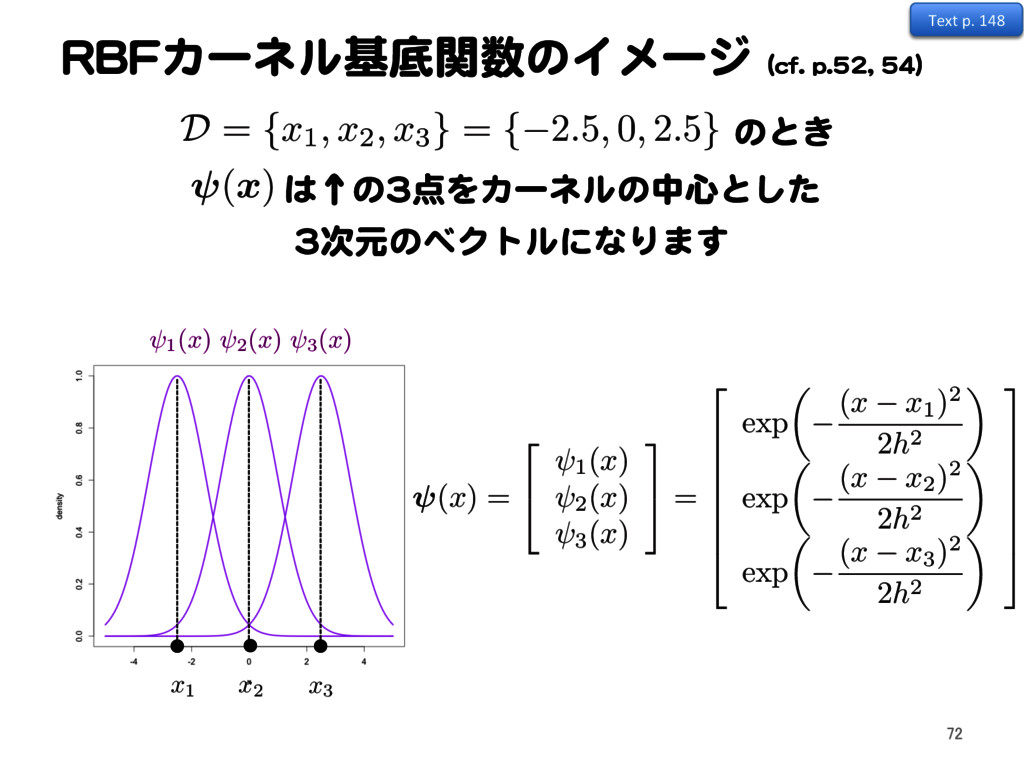{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![11.2 補足: Bregmanダイバージェンス[5, 6] '( x ) 81 D'( x](https://files.speakerdeck.com/presentations/2a15bf72f0174eca864cb2a3c5948694/slide_80.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![11.2 補足: オリジナルのKLIEP(※) 文献[2]では一般化KLダイバージェンスの最小化で はなく、通常のKLダイバージェンスの制約付き最適 化問題をProjected Gradient Descent[7]で解い てるようです ※](https://files.speakerdeck.com/presentations/2a15bf72f0174eca864cb2a3c5948694/slide_84.jpg){kind=link}
{kind=link}
![密度比推定による異常検知 11.3 最小2乗密度比推定法[1, 2, 4] Text p. 153 87](https://files.speakerdeck.com/presentations/2a15bf72f0174eca864cb2a3c5948694/slide_86.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
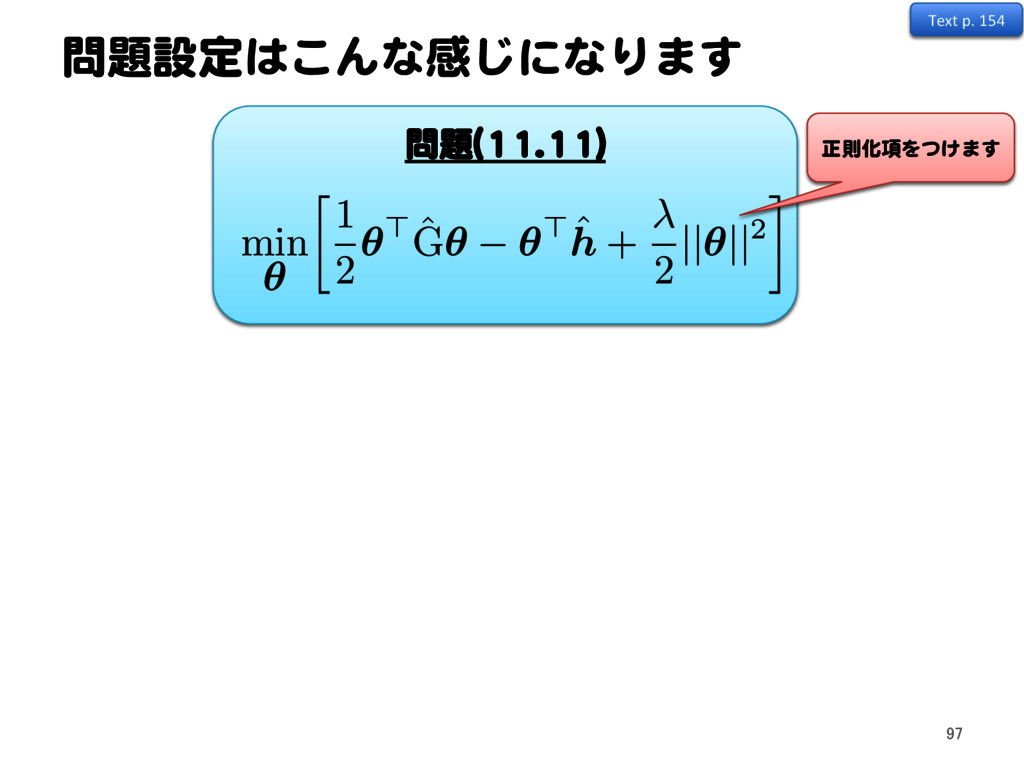
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}