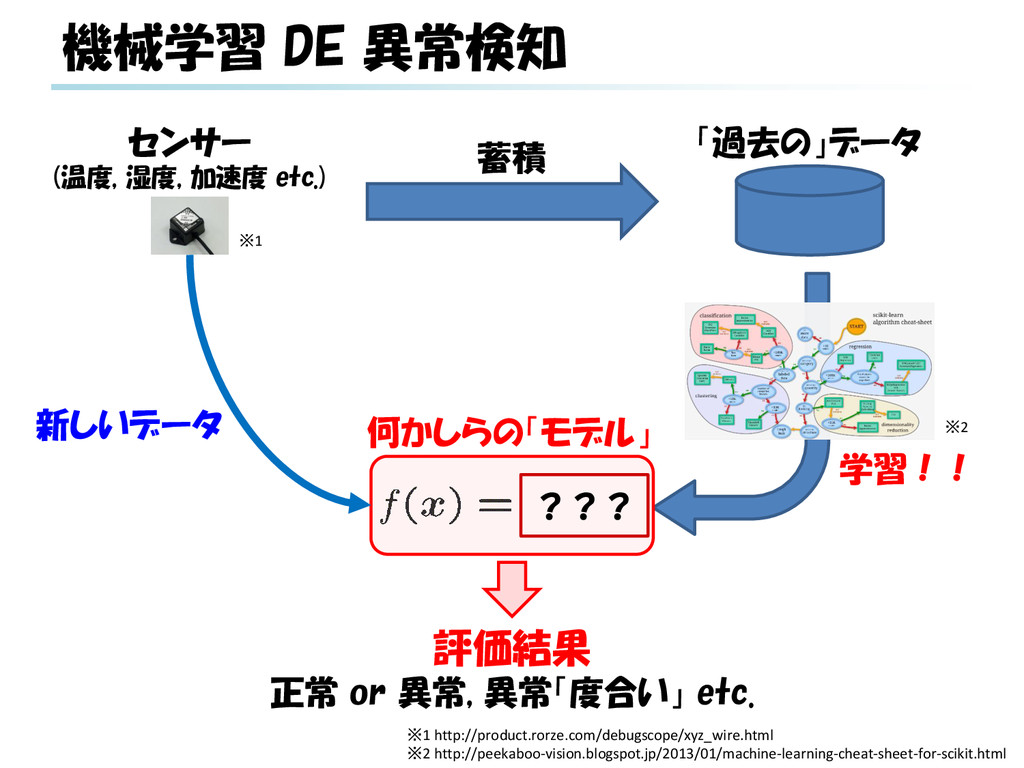
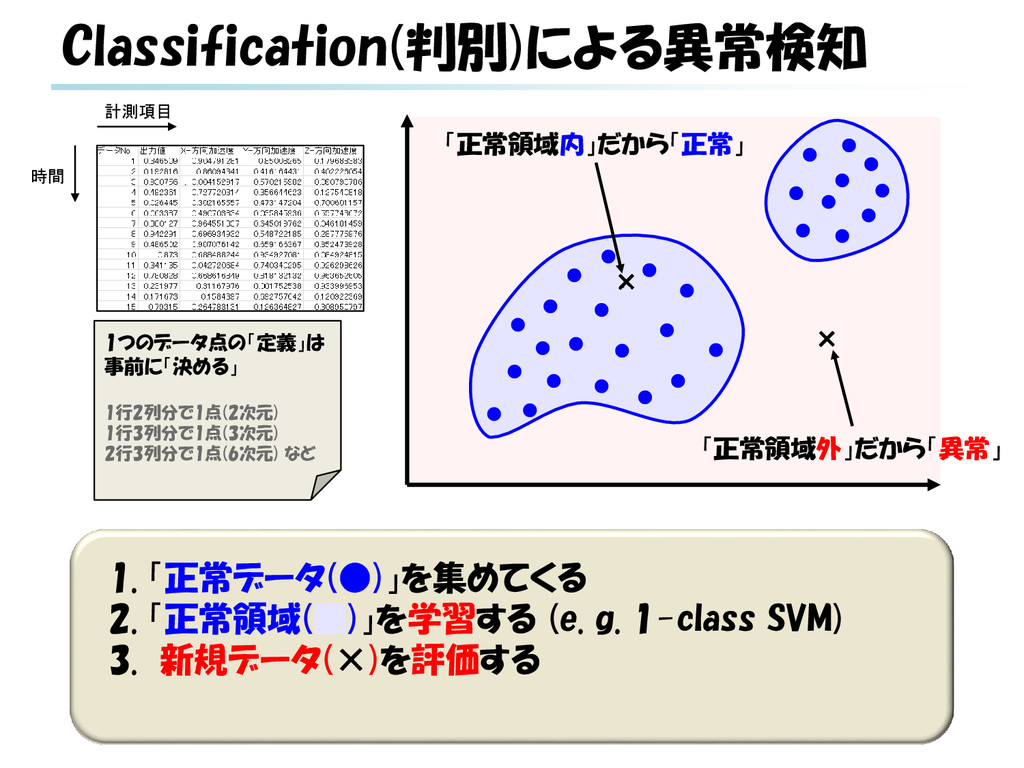
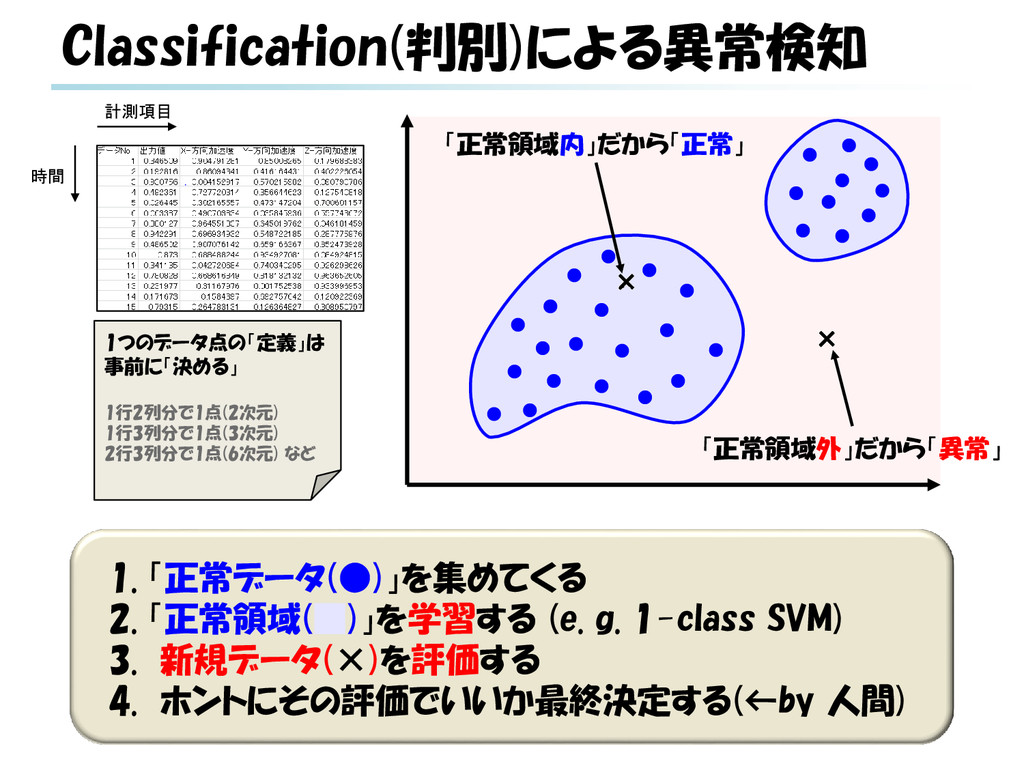
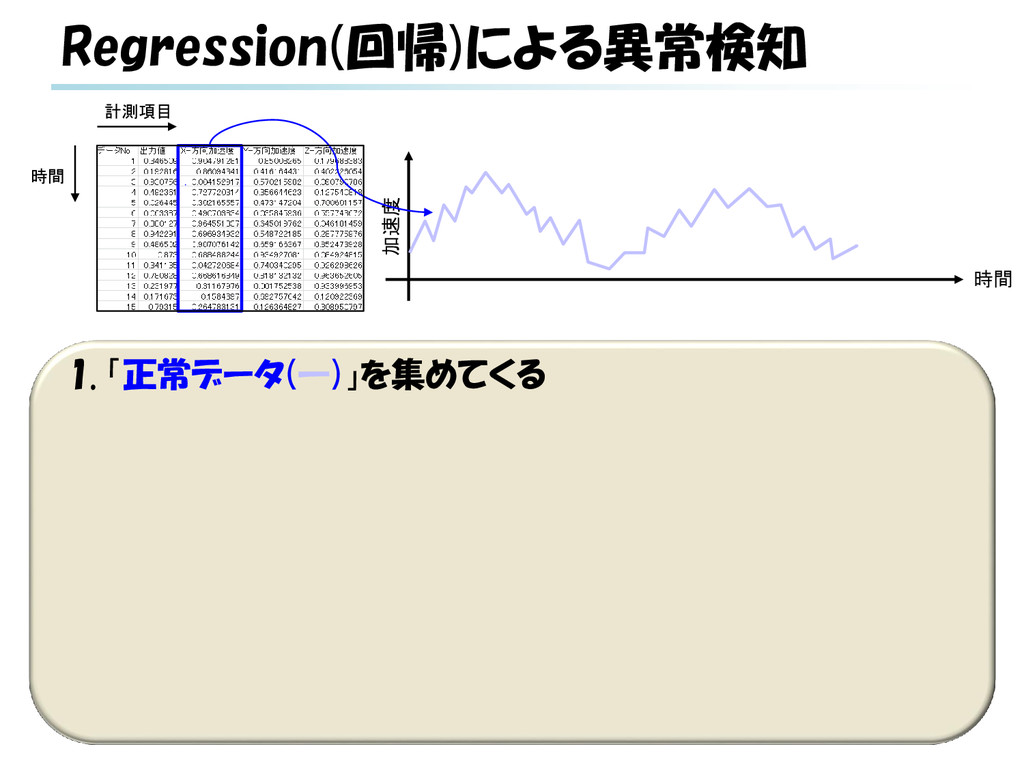
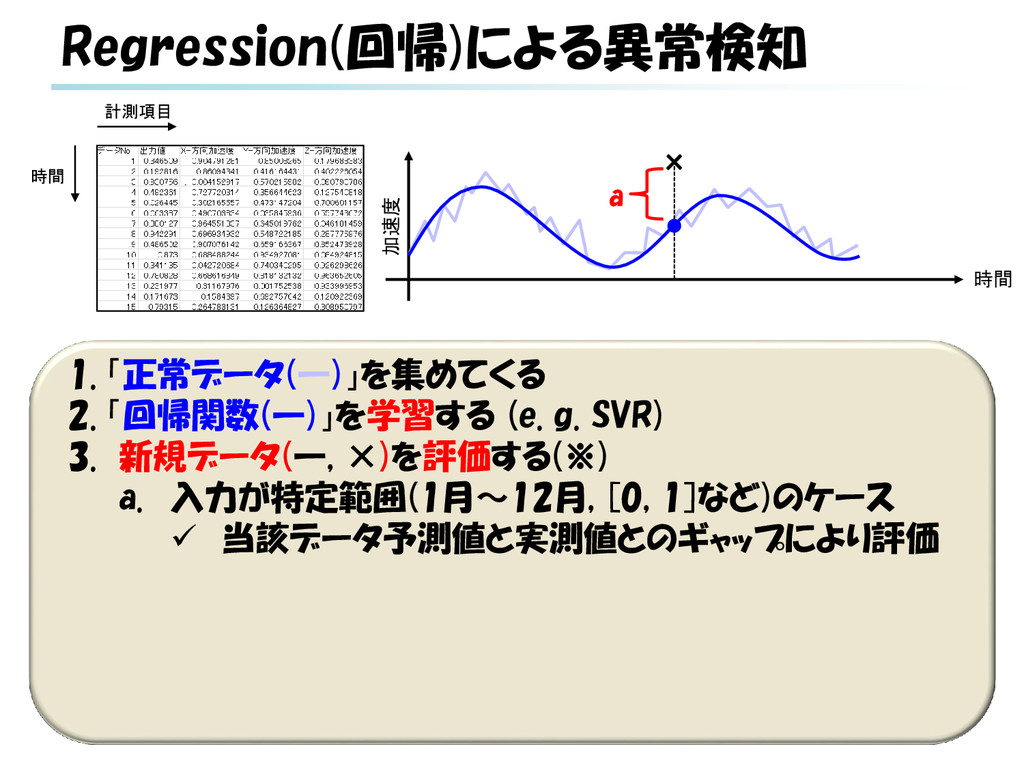
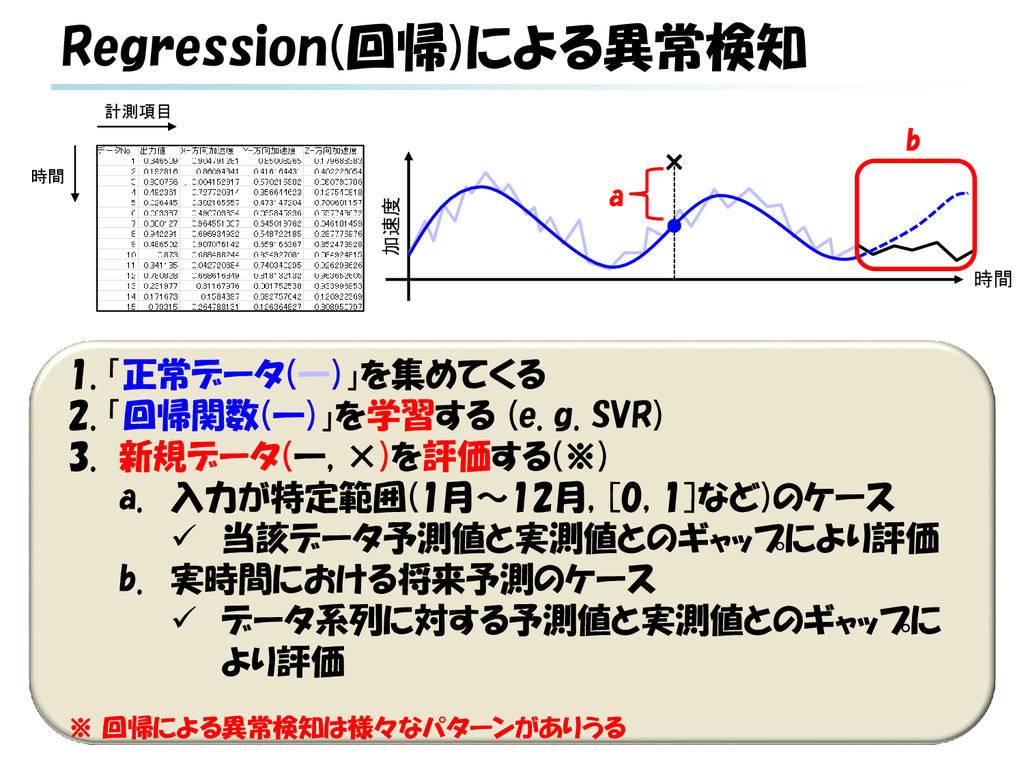
g. SVR) 3. 新規データ(―, ×)を評価する(※) a. 入力が特定範囲(1月~12月, [0, 1]など)のケース 当該データ予測値と実測値とのギャップにより評価 b. 実時間における将来予測のケース データ系列に対する予測値と実測値とのギャップに より評価 ※ 回帰による異常検知は様々なパターンがありうる b × a
C. M. Bishop. Pattern Recognition And Machine Learning. Springer. 2006. (日本語版有) 3. K. P. Murphy. Machine Learning. The MIT Press. 2012. 4. T. Hastie, R. Tibshirani, and J. Friedman. The Elements of Statistical Learning. Springer. 2009. (日本語版有) 5. 赤穂昭太郎. カーネル多変量解析. 岩波書店. 2008. 6. 杉山 将. イラストで学ぶ機械学習. 講談社. 2013. 7. 平井有三. はじめてのパターン認識. 森北出版. 2012. 8. 山西健司. データマイニングによる異常検知. 共立出版. 2009.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ご清聴あじゃじゃしたー 何かあればこちら↓まで! [email protected] @oshokawa(Twitter)](https://files.speakerdeck.com/presentations/5e865810f2a90131312c5a3c5b87e874/slide_42.jpg){kind=link}