Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ゼロつく2_輪読.pdf
Search
Pirotyyy
February 21, 2024
0
68
ゼロつく2_輪読.pdf
Pirotyyy
February 21, 2024
Tweet
Share
More Decks by Pirotyyy
See All by Pirotyyy
ゼロつく2輪読会 資料 2.1 - 2.4
pirotyyy
0
67
IDEA 2月度 LT資料
pirotyyy
0
52
Featured
See All Featured
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
330
WENDY [Excerpt]
tessaabrams
9
36k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.3k
Between Models and Reality
mayunak
2
210
Google's AI Overviews - The New Search
badams
0
930
What’s in a name? Adding method to the madness
productmarketing
PRO
24
3.9k
Optimizing for Happiness
mojombo
378
71k
Tell your own story through comics
letsgokoyo
1
830
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
750
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
1.8k
The World Runs on Bad Software
bkeepers
PRO
72
12k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
122
21k
Transcript
ゼロつく2 輪読 第2章4節 〜 千葉大学工学部情報工学コース3年 @pirotyyy 輪読くらぶ
概要 前回の復習 (自己)相互情報量の導入 SVDによる次元削減 まとめ
前回の復習
前回の復習 自然言語処理について、代表的な2つの手法について学んだ 例)シソーラスの手法・カウントベースの手法 シソーラスの手法 ある単語の類語辞典を作成し、それを元に単語の関連付けを行う 課題点①:時代によって単語が増えるので、それに対応していく必要がある 課題点②:シンプルに単語の量が多くて大変 カウントベースの手法 ある単語の周囲にある単語の出現回数を数え、それを元に関連付けを行う コサイン類似度を用いて、数え上げによって得られた共起行列の各要素間の類似度を求め、単語間
の関連づけを行った 課題点:関連付けにコサイン類似度を用いると、「冠詞 + 名詞」の組み合わせに弱い
(自己)相互情報量の導入
(自己)相互情報量の導入 自己相互情報量(PMI):2つの値x, yの依存度を表す指標 相互情報量(MI):2つの確率変数X, Yの依存度を表す指標(PMIの平均) PMIの定義(式) PMIが正のとき P(x, y) >
P(x)P(y) xとyが一緒に出現しやすい(共起しやすい) PMIが負のとき P(x, y) < P(x)P(y) xとyが一緒に出現しにくい(共起しにくい) PMIが0のとき P(x, y) = P(x)P(y) xとyは独立である(依存関係なし)
(自己)相互情報量の導入 PMIの値を用いて、単語の関連付けを行う 例)単語数がN個であるコーパスを考える。コーパス中のある単語「the」「car」「drive」につい て以下の様であったとする。 N = 10000 「the」出現回数 = 1000
「car」出現回数 = 20 「drive」出現回数 = 10 「the」と「car」の共起回数 = 10 「car」と「drive」の共起回数 = 5
(自己)相互情報量の導入 PMI(“the”, “car”) ≒ 2.32 PMI(“car”, “drive”) ≒ 7.97 以下のように計算できる。
結果より、人間の感覚に近いことがわかる。 したがって、単語の関連付けを行う方法についてはこれでいいかもしれない しかし、コーパス中の単語の種類が増えていくにつれて、共起行列であったり、PMIの行列の次 元数はとんでもない数になる。 どうにかして、扱う行列の次元を減らしたい!!
SVDによる次元削減
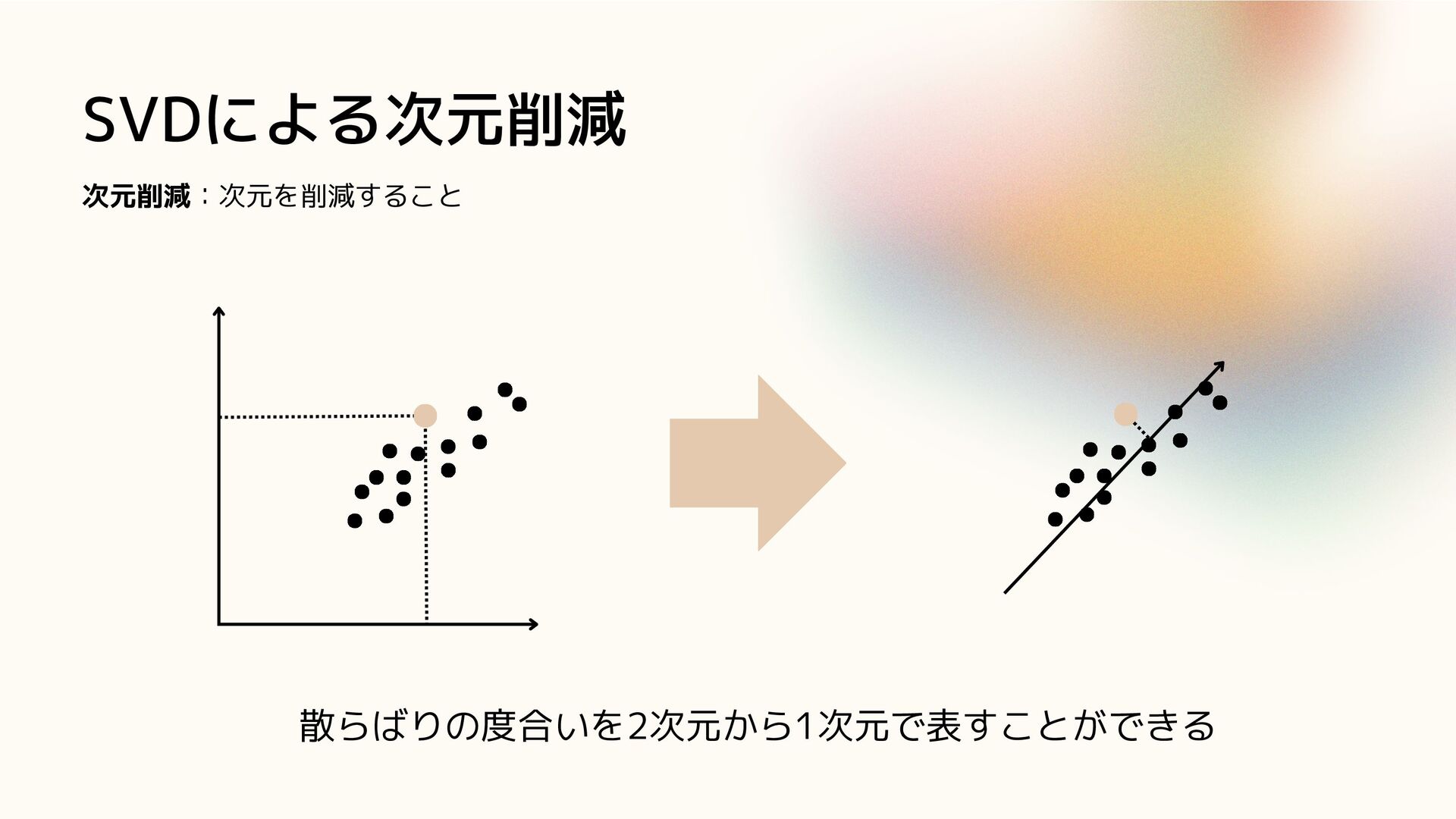
SVDによる次元削減 次元削減:次元を削減すること 散らばりの度合いを2次元から1次元で表すことができる
SVDによる次元削減 カウントベースの手法における次元削減のモチベーション 扱う行列データの次元が小さくすることで計算量が減る 1. ほとんどの要素が0であるベクトルを減らすことができる 2. ベクトルの全ての要素が意味のある値を持つ a. 0ばかりで、無駄な値が多い
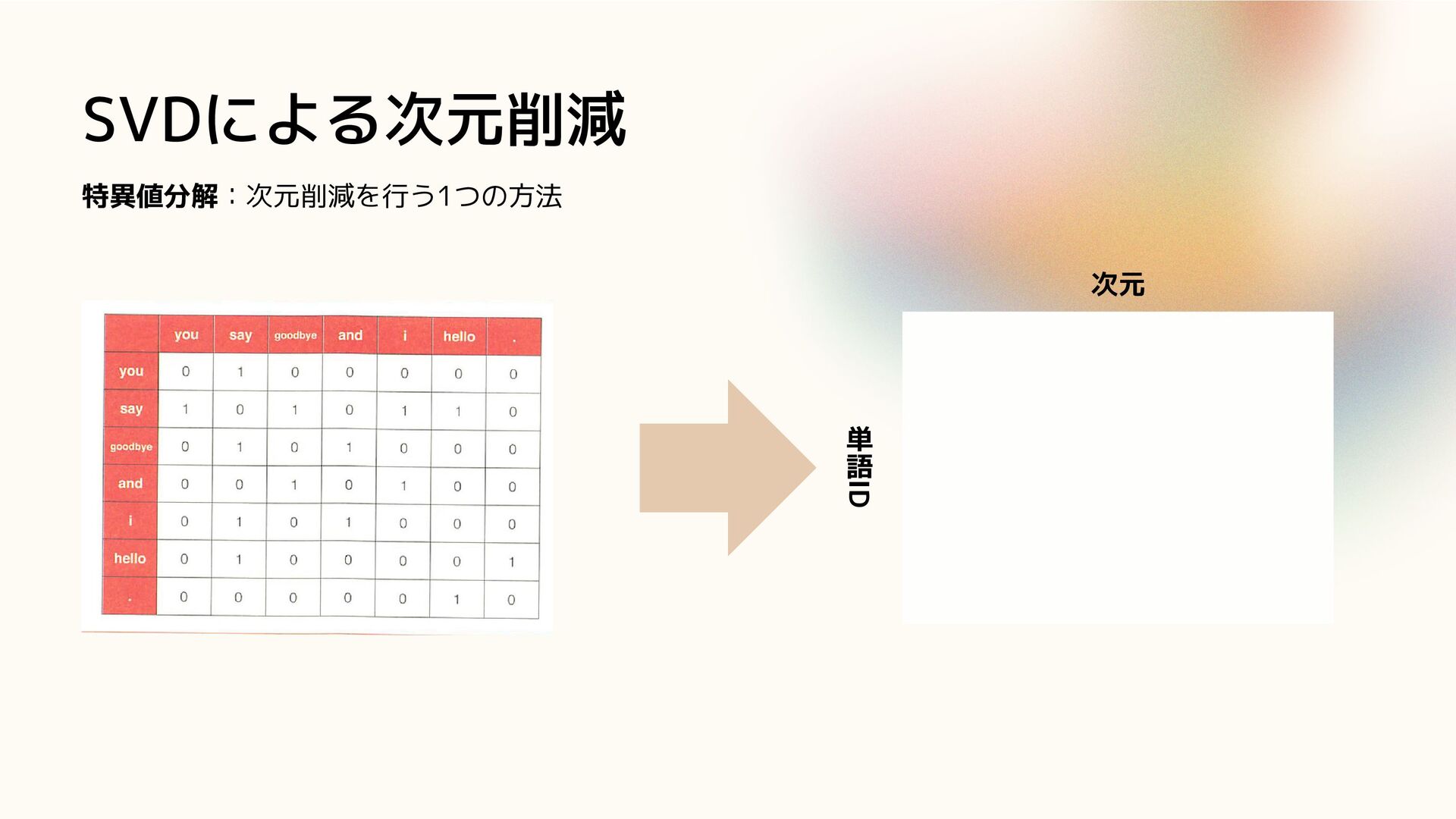
SVDによる次元削減 特異値分解:次元削減を行う1つの方法 単 語 ID 次元
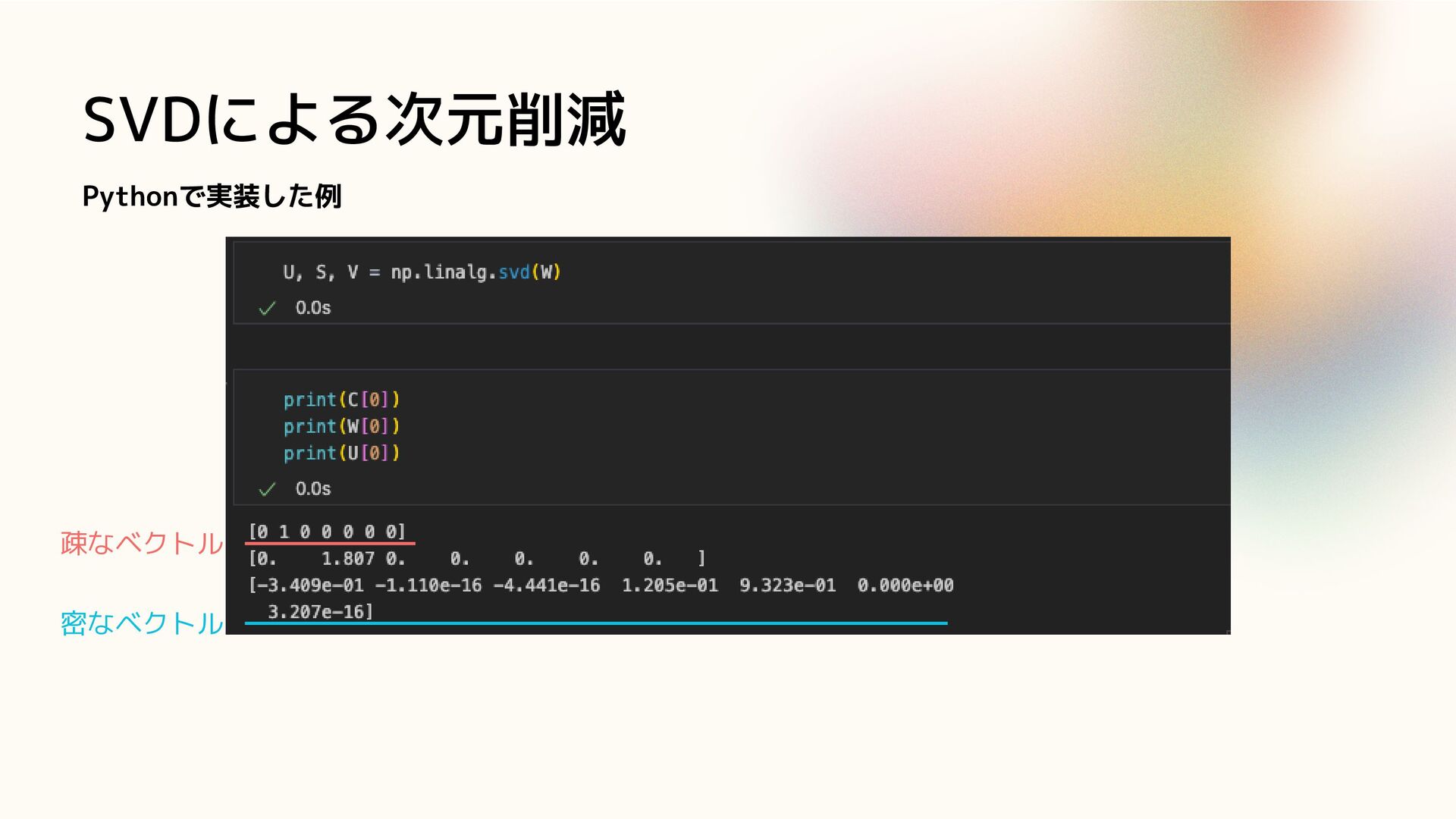
SVDによる次元削減 Pythonで実装した例 疎なベクトル 密なベクトル
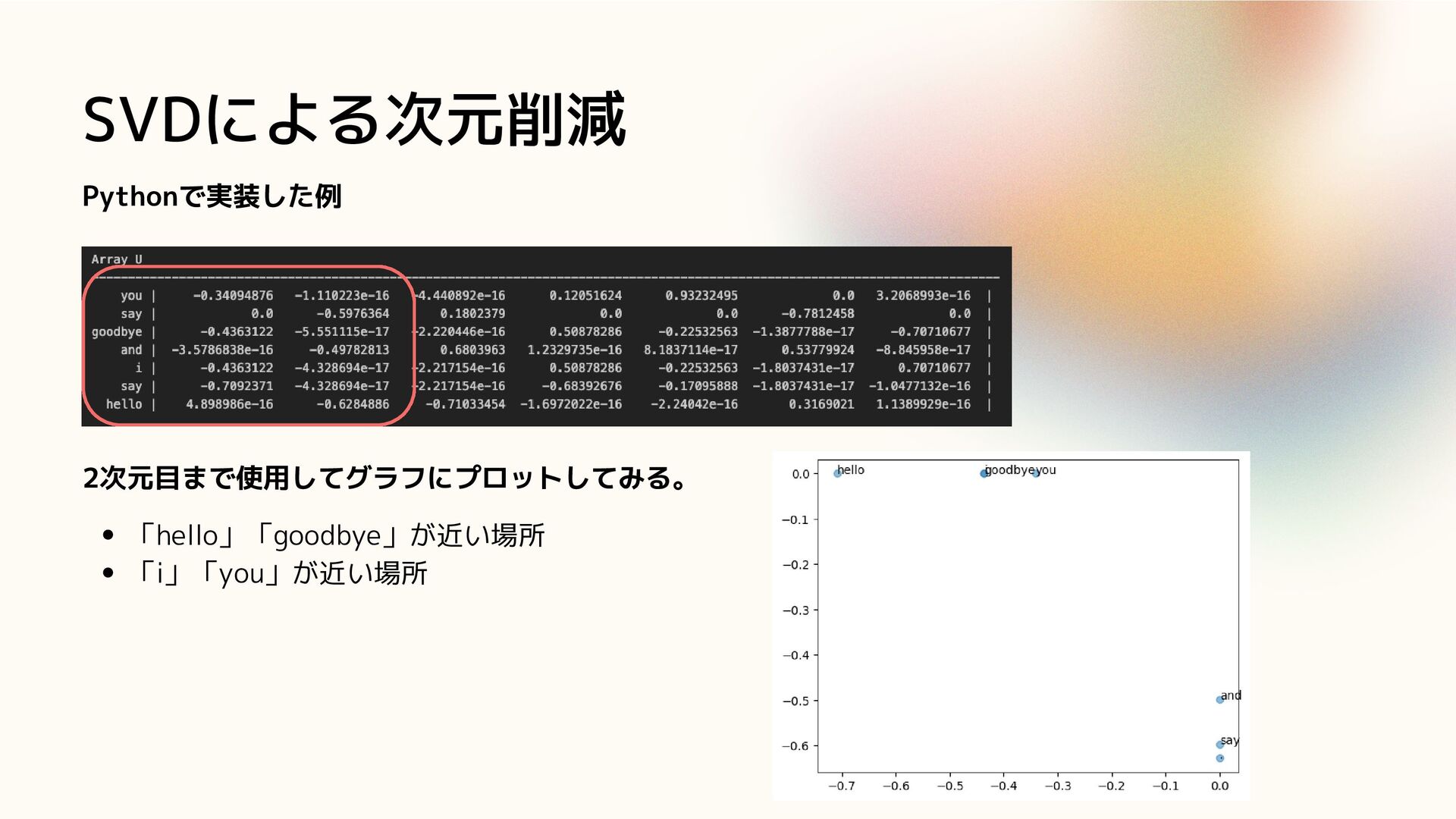
SVDによる次元削減 Pythonで実装した例 2次元目まで使用してグラフにプロットしてみる。 「hello」「goodbye」が近い場所 「i」「you」が近い場所
まとめ SVDによって、正確にコーパス中の単語の関連付けを行うことができた
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}