Share
2023/04/03に行われた第12回ザッピングセミナーでの発表資料です https://zappingseminar.connpass.com/event/279383/?utm_campaign=event_publish_to_follower&utm_source=notifications&utm_medium=twitter
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ガウス埋め込みに基づく文表現生成 18 18 ▪ 紹介理由 ・ガウス分布/ガウス過程は意味変化の研究でもよく使用される [3][4][5] (全てNLP2022の研究) ・〇〇の研究において,単語の意味をベクトルで表現→分布で表現 は王道でわかりやすい](https://files.speakerdeck.com/presentations/9492594324734502ab2e396188f0e17a/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
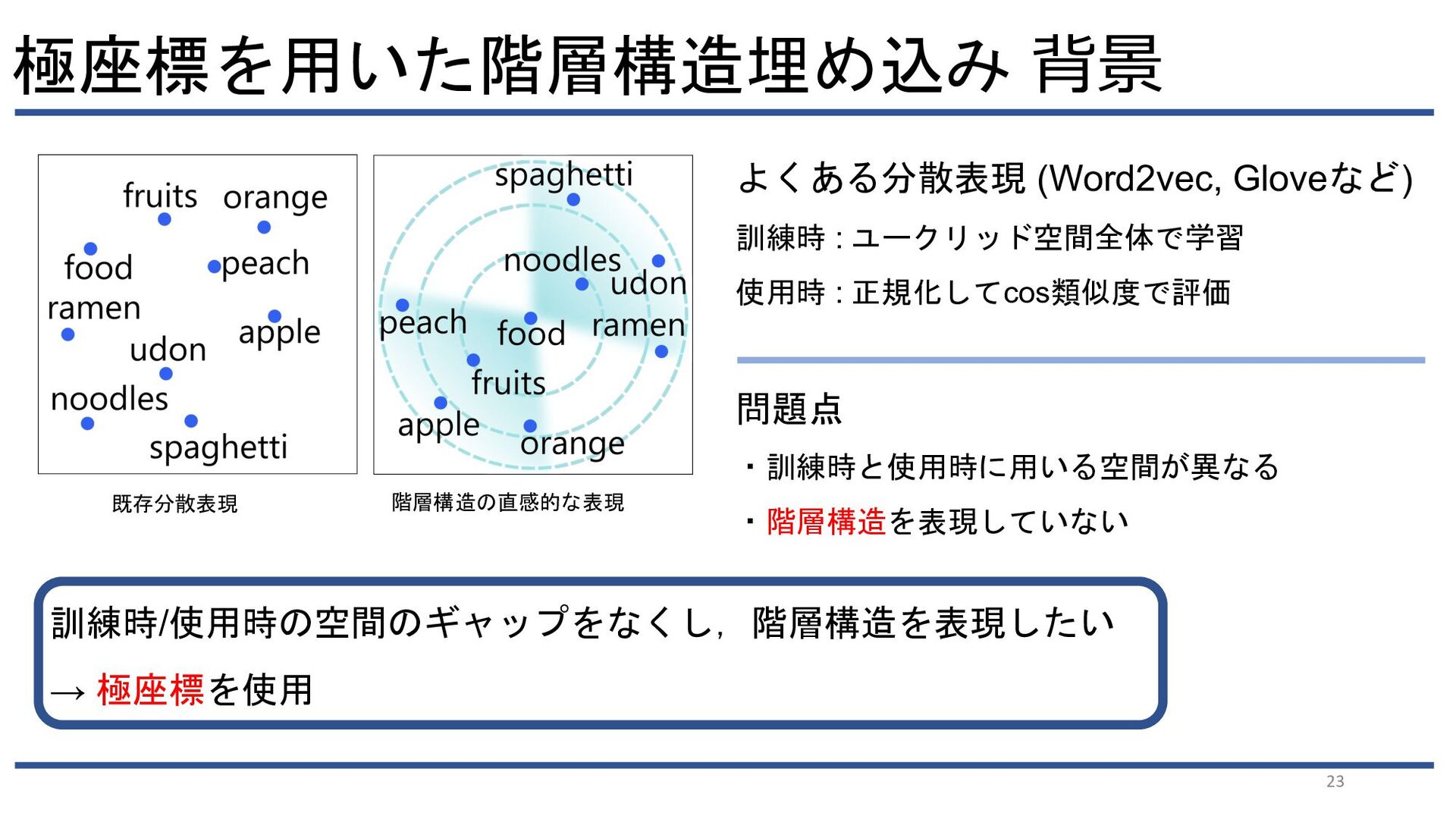{kind=link}
{kind=link}
{kind=link}
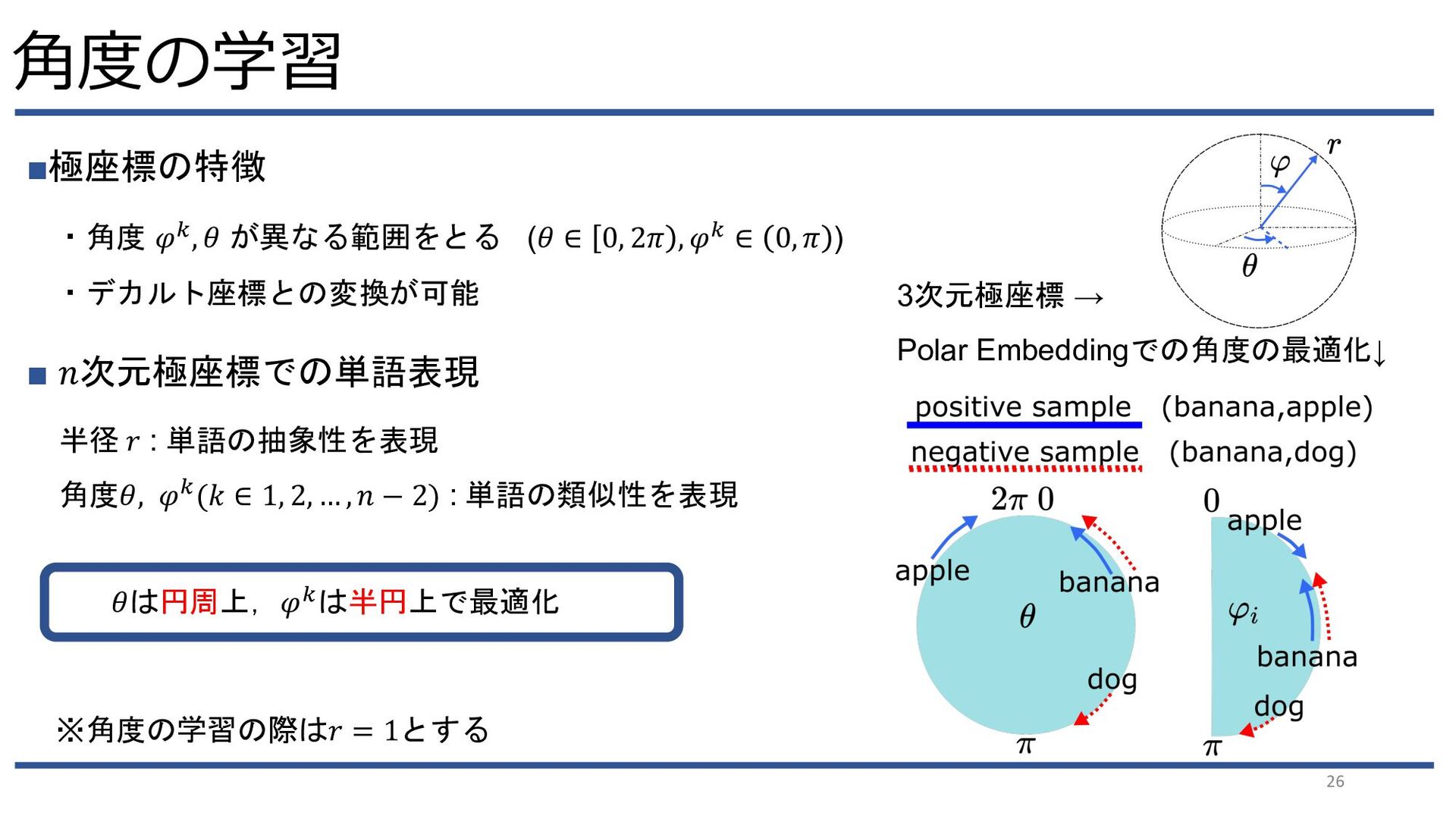{kind=link}
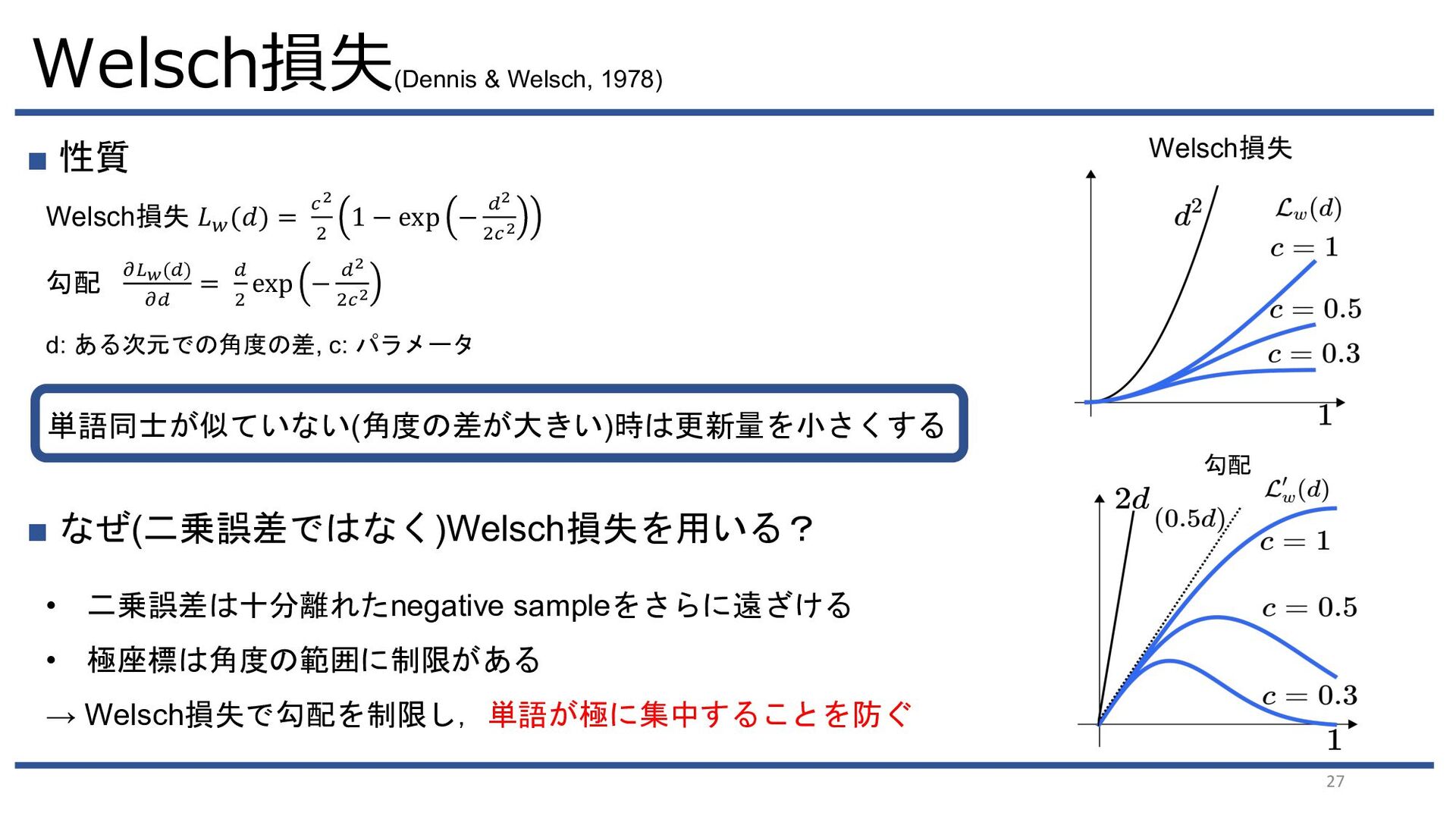{kind=link}
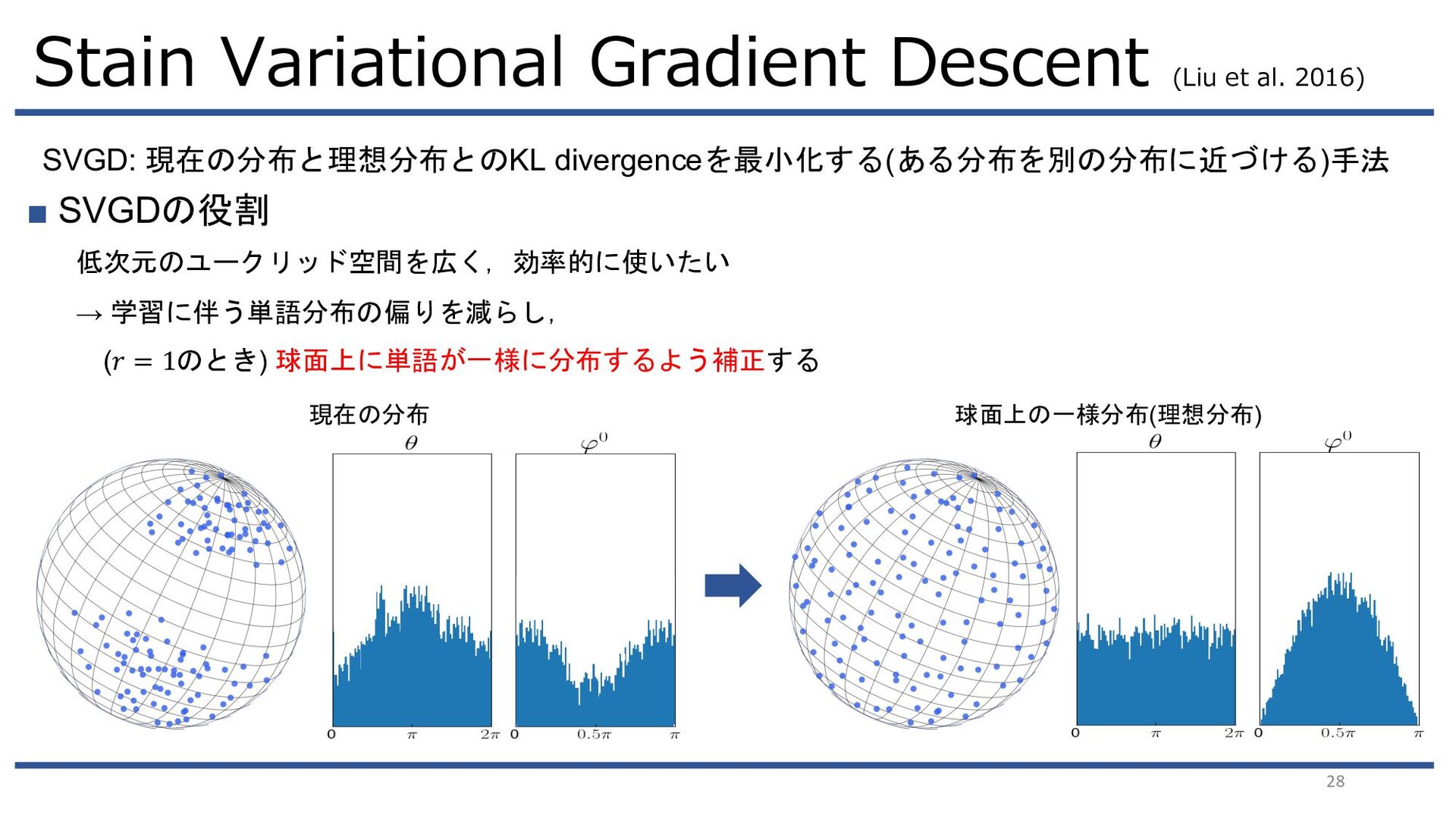{kind=link}
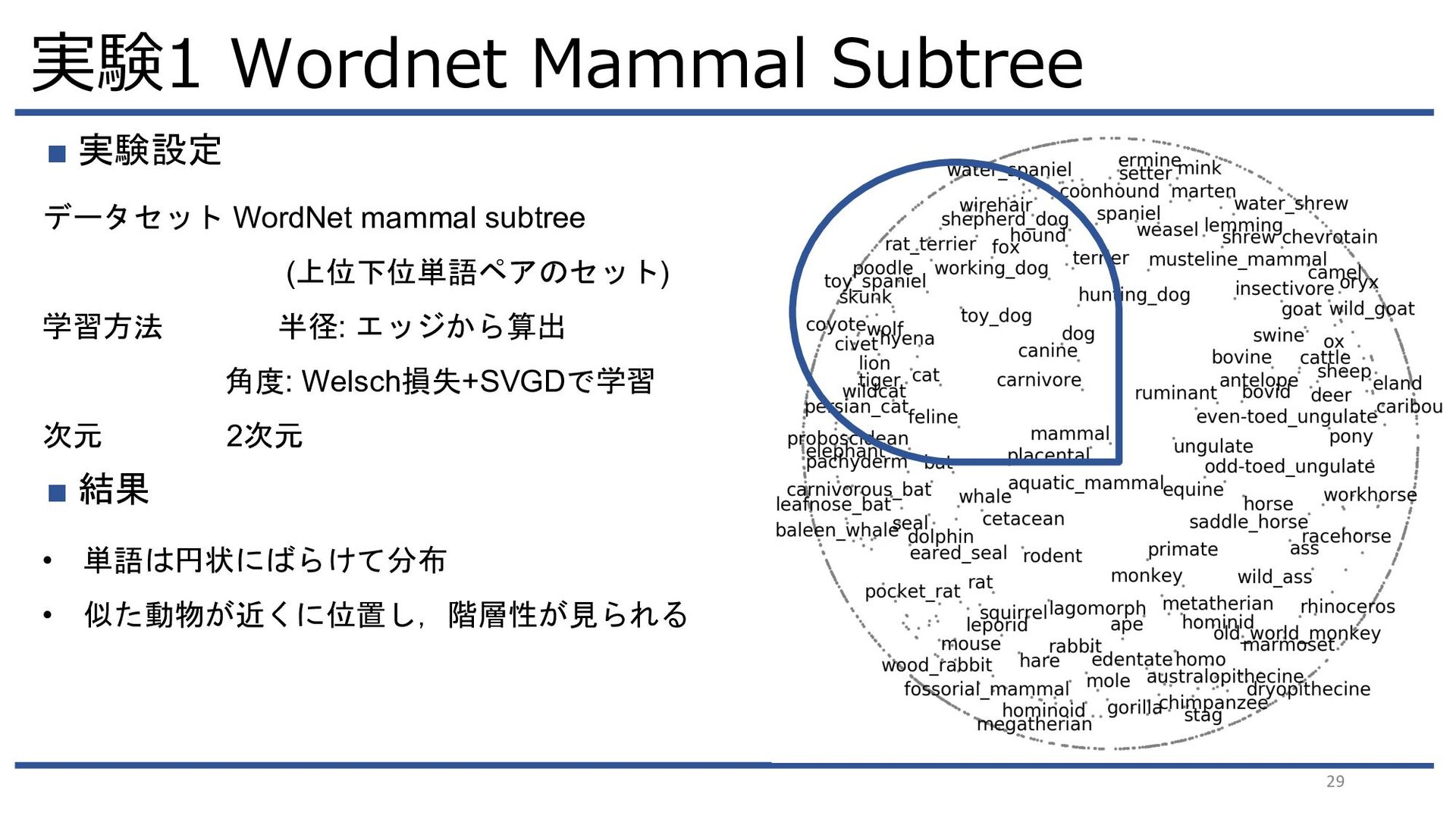{kind=link}
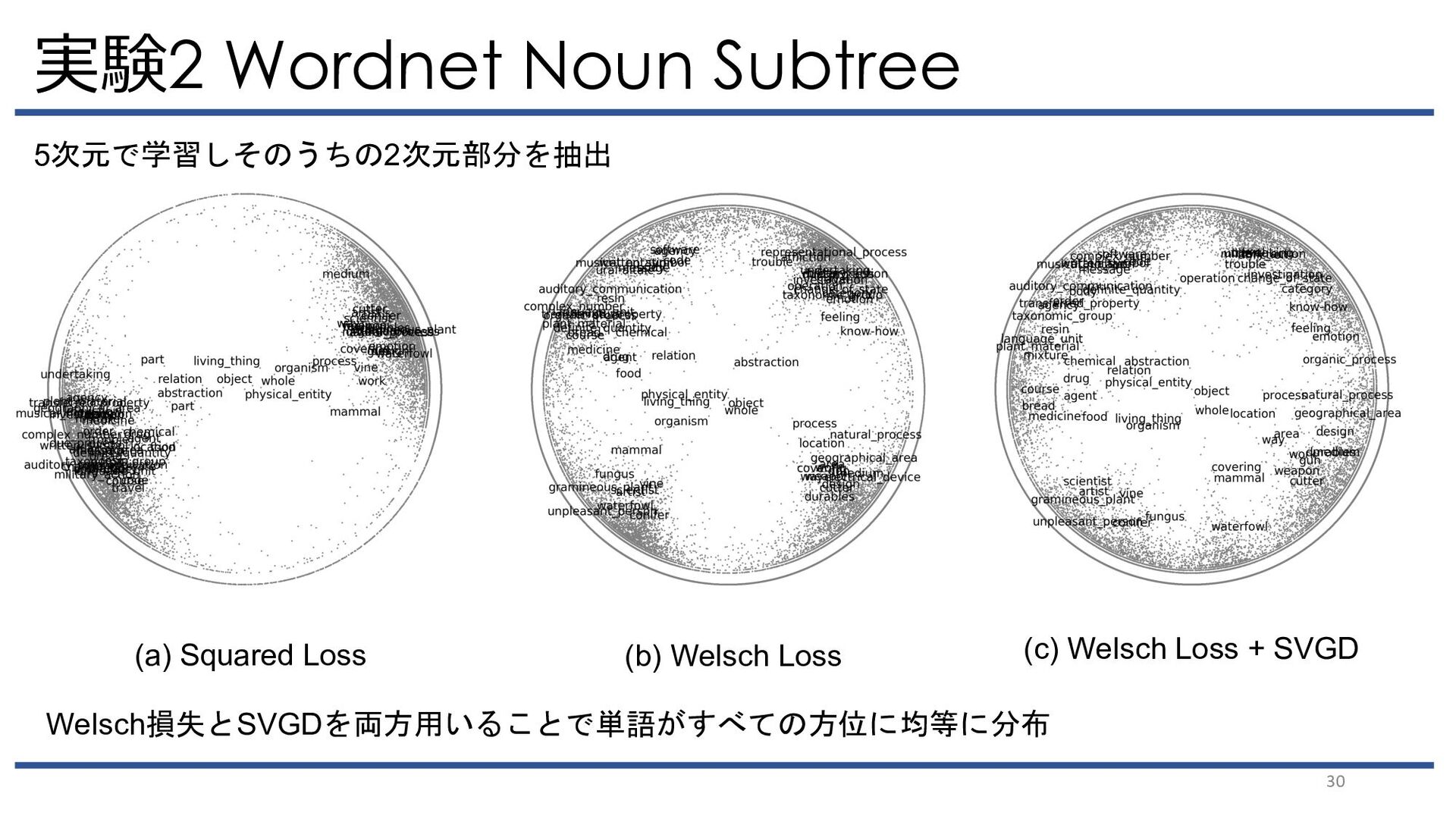{kind=link}
{kind=link}
{kind=link}
{kind=link}
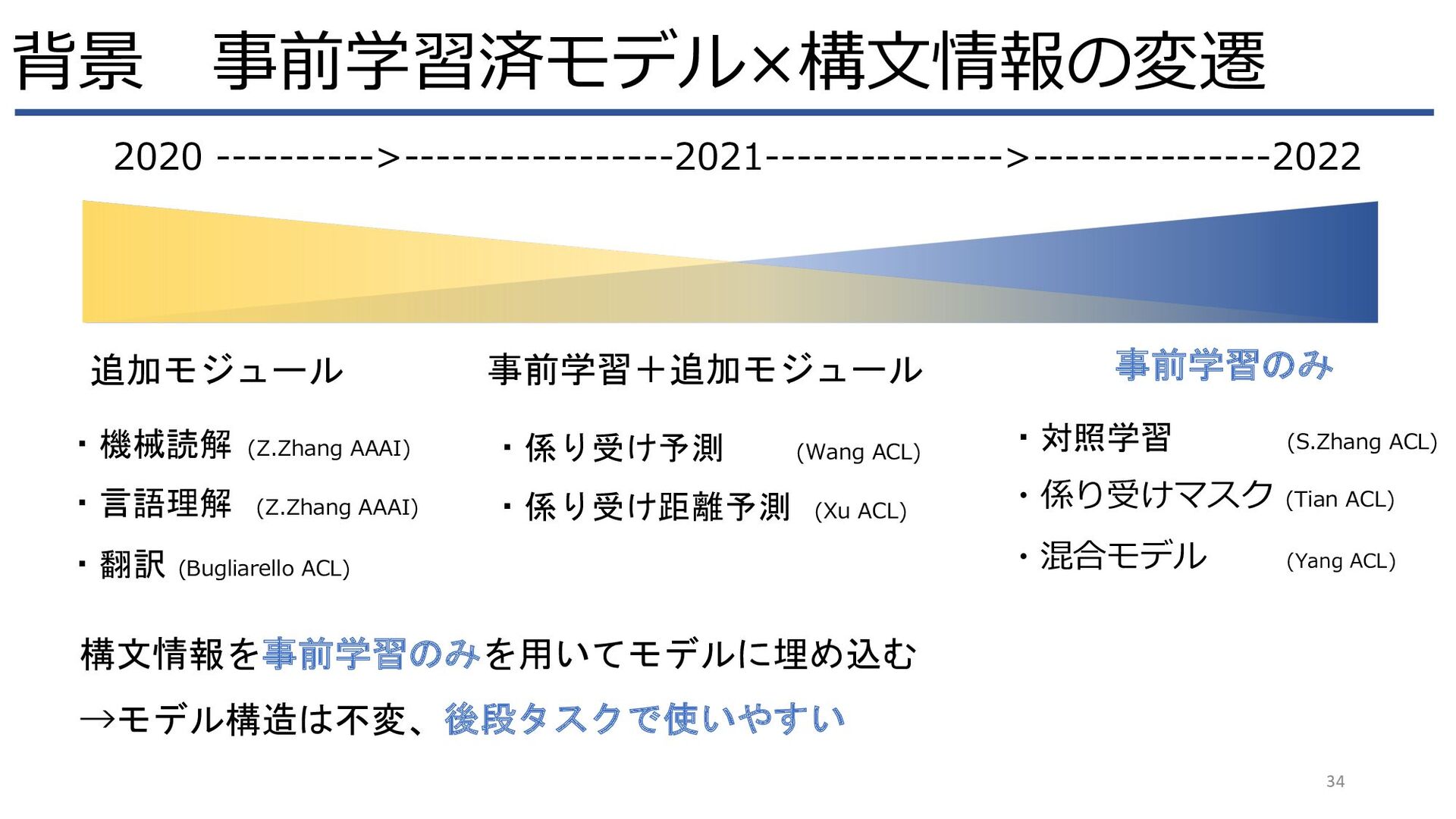{kind=link}
{kind=link}
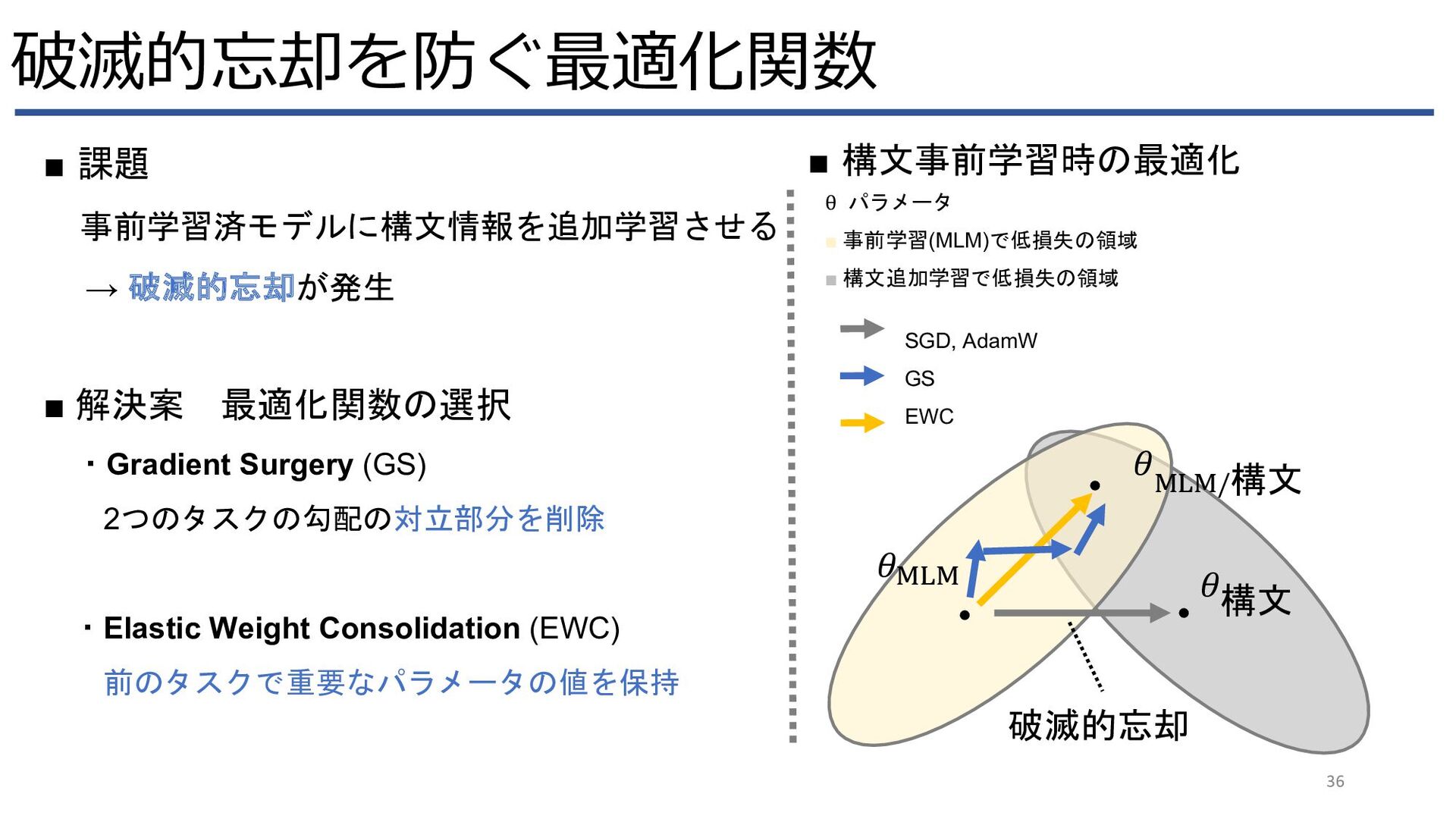{kind=link}
{kind=link}
{kind=link}
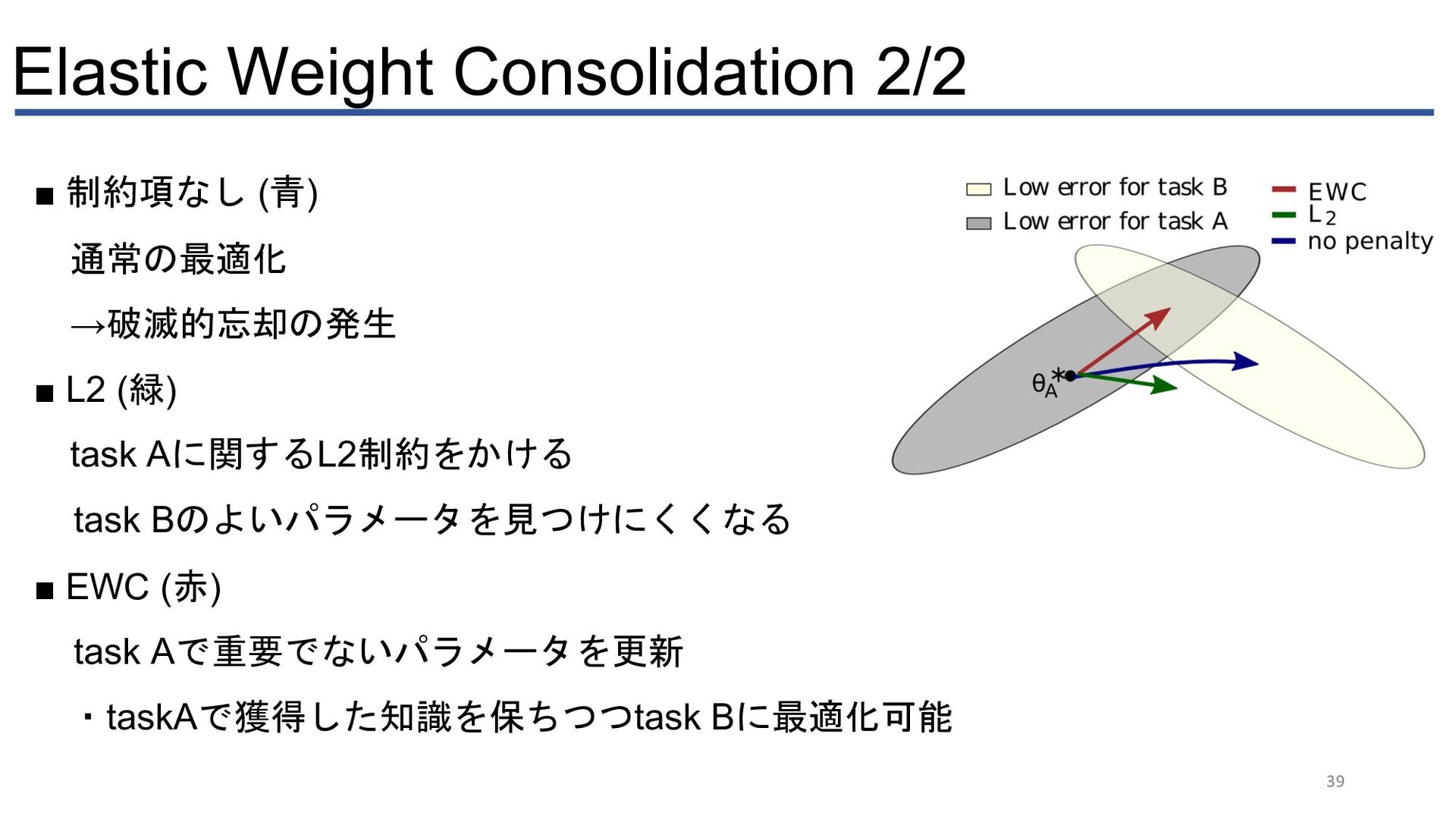{kind=link}
{kind=link}
{kind=link}
{kind=link}