evening, 1st on-call of a new team member • Incident started Friday night • 5 people took turns over 36h • 20 people involved total • Source of the outage identified Sunday at 1am
evening, 1st on-call of a new team member • Incident started Friday night • 5 people took turns over 36h • 20 people involved total • Source of the outage identified Sunday at 1am
Namenodes • Mitigate heap consumption at startup • Adjust heap, start NN one by one • Enable RPCs, services ones first, then client ones • Investigate and delete superfluous data How did we fix it?
many exceptions to achieve quorum size 2/3. 3 exceptions thrown: 8485: at org.apache.hadoop.hdfs.serverAsked for firstTxId 71030619500 which is in the middle of file /var/cache/hadoop/jn/root/current/edits_00000000710280706 81- 0000000071034147476.namenode.FileJournalManager.getRem oteEditLogs(FileJournalManager.java:195) at org.apache.hadoop.hdfs.qjournal.server.Journal.getEditLogMani fest(Journal.java:638) at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer. getEditLogManifest(JournalNodeRpcServer.java:178)Add Comment
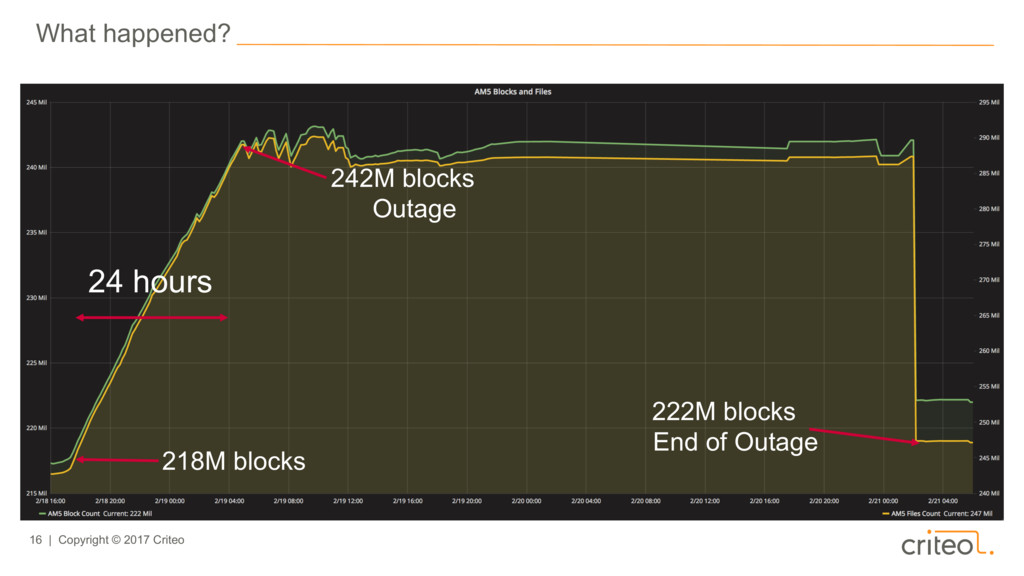
22:10:51,743 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 47515ms#012GC pool 'PS MarkSweep' had collection(s): count=1 time=47729ms 2016-02-20 22:11:53,331 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 47585ms#012GC pool 'PS MarkSweep' had collection(s): count=1 time=47845ms 2016-02-20 22:12:53,750 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 47916ms#012GC pool 'PS MarkSweep' had collection(s): count=1 time=48286ms 2016-02-20 22:13:57,209 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 49450ms#012GC pool 'PS MarkSweep' had collection(s): count=1 time=49701ms 2016-02-20 22:14:57,535 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 49324ms#012GC pool ...
major design issue • 2 very different roles: DB (metadata) and Servicing (RPC) • Scalability issue comes from In-Memory DB • Namenode later proved to have a lot of single threaded code (in our version of CDH) • We shared the Namenode and ResourceManager on the same machine Adjust Hardware - Problem
Deal with large FSImage: • RAM: 192GB à 512GB • JVM: 150GB à 332GB • Faster write time of both edits and fsimage/checkpoint: SSD Storage • Mitigate single threaded code impact: 2.0Ghz à 3.4Ghz • Specialize Namenode machines Adjust Hardware - Mitigation
files • Along with a file creation, a lease (lock) is created • In case of failure, the lease is not released but cleaned up later by the Namenode • What happens when you have a very large amount of unreleased leases? àThe Namenode clean up all leases at once and becomes unresponsive àA failover happens, but the newly active Namenode also becomes unresponsive… HDFS-10220 gave us more control to fine tune the duty cycle with which the Namenode recovers old leases • dfs.namenode.lease-recheck-interval-ms • dfs.namenode.max-lock-hold-to-release-lease-ms Improve Stability - HDFS-10220
too long • Mono threaded code – run after replaying edits • With ~300 million files – takes very long • What happens when you have ~300 million files? àIt takes a very long time àIt triggers a failover as the Namenode becomes unresponsive HDFS-8865/HDFS-9003 uses the Fork-Join framework to improve the performances of that operation Improve Stability - HDFS-8865/HDFS-9003
with our datanodes (bad controllers) • Need to change RAID controllers of 700 machines • Decommission/Recommission cycle rack / rack (20 machines), several racks per week, during 4 months • Double the size of the cluster at the same time: 700 à 1353 datanodes • Generates a lot of datanode incremental block reports • One IBR per block movement • We estimated between 2.5 - 11 Million movement per datanode • Plus the normal cluster life, plus the usual HDFS rebalance • What happened? • Namenode became irresponsive at some point causing major outages HDFS-9198/HDFS-6841 - Coalesce IBR processing in the NN and limit IBR treatment to 4ms Complex and risky patch as it changed some protobuf interfaces but hopefully optional fields Improve Stability - HDFS-9198/HDFS-6841
10GB heap size datanodes to give preprod the ability to deal with as many blocks as prod • Create 180 millions of files/block – 1 block/file • Multiple get/set of metadata files informations • Delete the millions of files/block created Improve performances – Load testing
defective raid card – Replace all of them • Scale HDFS from ~700 datanodes to ~3000 datanodes • Scale the backup Hadoop cluster to at least ½ the capacity of the main one • Address the Namenode scalability issue • Scaling the team ;-) Scaling
of actual cluster usage – Application Performance Management and metrology • Support our users in their transition to Spark and their experimentation with other frameworks • Increase the use of Mesos rather than bare metal machines for cluster access, probes,… • Upgrade the CDH4 cluster to the same level as the main CDH5 one • Address the Active/Passive Hadoop cluster issue Better cluster usage
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}