Equipe : 10 personnes Trois enjeux majeurs : Construire une plateforme Hadoop opérationnelle Montée en compétence de l’équipe Préconisations pour une plateforme industrielle Contexte
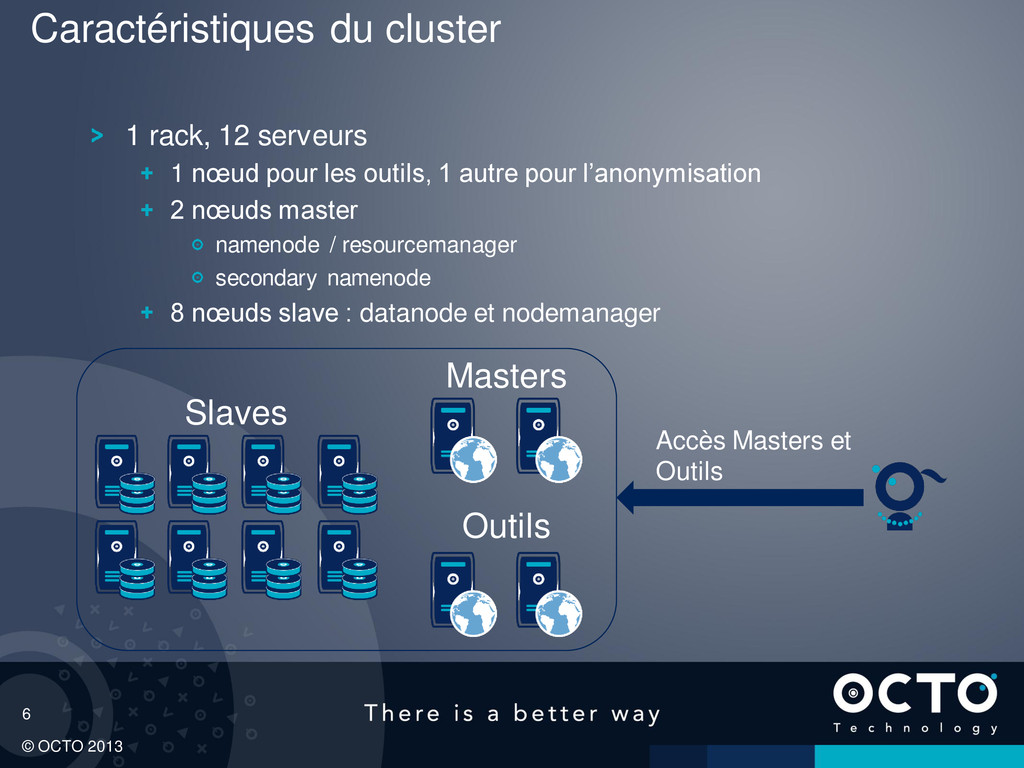
pour les outils, 1 autre pour l’anonymisation 2 nœuds master namenode / resourcemanager secondary namenode 8 nœuds slave : datanode et nodemanager Caractéristiques du cluster Slaves Masters Outils Accès Masters et Outils
Pourquoi ? Temps limité Projet dense Infra : Mise en place et configuration du cluster Exploration des possibilités des outils d’Hadoop Transfert de compétences Comment ? Co-localisation de l’équipe opérationnelle Mise au point et priorisation d’un backlog Réunion d’avancement hebdomadaire On y aborde les réussites et les points bloquants On y valide le travail réalisé On y ajuste le backlog pour la semaine suivante Objectifs Favoriser un bon suivi de l’avancement Favoriser les échanges en direct Eviter les blocages, les non dits
matérielle « imposée » Taille de certaines partitions inadaptées Pas d’accès internet Firewalls Résultat Partitions : des adaptations « crades » à base de liens symboliques Repartitionnement en GPT des disques de stockage Accès internet : création d’un mirroir local Firewalls : demandes d’ouvertures de ports Coût : Un peu plus d’une semaine Mise en place du cluster Déploiement d’Hadoop
Kernel : swapiness, overcommit, hugepages, … Ext4 : pas de blocs réservés, noatime, nodiratime, … Hadoop : taille des blocs HDFS, réplication, mémoire par composant ? Résultat Pour le transfert de compétences : très positif Pour le projet : démarrage très lent. Impact négatif Un SCM au démarrage peut faire gagner beaucoup de temps ! Mise en place du cluster Déploiement d’Hadoop
à tout maintenir Configuration parfois complexe Des IHM globalement trop basiques La ligne de commande reste le plus complet Mise en place du cluster Déploiement des outils
cluster s’optimise au contact de la réalité Limites des outils Ajustement de l’ordonnanceur Configuration mémoire Configuration d’HDFS Python est ici un bon allié L’analyse des données
requêtes SQL utilisées Points négatifs Bug surprenant sur les dates Trop lent Après 1 mois de CREATE TABLE, beaucoup de blocs sous remplis L’analyse des données Hive
un « SAS like » Points négatifs Trop lent Pas d’intégration Hcatalog dans la CDH à l’époque Son utilisation a tourné court rapidement. L’analyse des données Pig
bêta Au moment de la sortie d’Impala Points négatifs Lent Plantages du shell Impala Certaines requêtes retournaient des résultats invalides Problèmes corrigés depuis mais une leçon de cela : Qu’un éditeur communique sur un produit ne signifie pas que ce produit est utilisable ! L’analyse des données Impala
utilisés Naive bayes, random forest, regression logistique, k-means, arbres de décision Des points positifs Ligne de commande, facile à utiliser Déjà installé dans la CDH Des douleurs Documentation inadaptée Besoin du code source pour comprendre comment ça marche Sorties textuelles grep sur la sortie standard Manque d’homogénéité Formats d’entrée, docs Le passage de 0.6 à 0.7 (migration de mineure CDH) a cassé nos jobs Format d’entrée textuel supprimé au profit du vectoriel Produit nettement moins mature que scikit ou R mais en amélioration. L’analyse des données Mahout
de guerre » Pour superviser, mes outils actuels suffisent ! Un SCM ? Pas le temps, SSH fera l’affaire ! Les logs c’est important, il faut tous les collecter Conserver les paramètres mémoire par défaut Conserver la configuration par défaut de HDFS Conserver la configuration par défaut de MapReduce Utiliser les formats de fichier par défaut Benchmarker son cluster avec TeraSort Les pièges
niveau de parallélisme insuffisant Un surcoût aux performances non garanties Comment l’éviter ? Penser parallélisme Notion de conteneur : 1 coeur / xGo de RAM / 1 Disque dur HDFS Dimensionner pour du temps de traitement La tentation des machines « monstres de guerre »
seuls ne donne pas de détails sur les métriques internes d’Hadoop Lectures / écritures de HDFS par nœud I/O et mémoire pendant l’exécution d’un job Stop-the-world GC Comment l’éviter ? Hadoop embarque un connecteur Ganglia Ambari permet d’avoir un vue cohérente de toutes ces métriques Pensez aux développeurs ! Ils sont les mieux placé pour optimiser leurs jobs Pour superviser, mes outils actuels suffisent !
c’est 10 machines Configuration et maintenance à la main difficile Perte de temps Comment l’éviter ? Utiliser un SCM, Cloudera Manager ou Ambari Un SCM ? Pas le temps, SSH fera l’affaire !
reducers > 520 fichiers de logs à collecter sur tout le cluster Peu d’informations utiles à long terme Comment l’éviter ? Sur les slaves : collecte uniquement des logs des Applications Master Collecte sur les masters Les logs c’est important, il faut tous les collecter
optimisés pour votre cluster Sous utilisation des ressources Échecs possibles de certains jobs Comment l’éviter ? 2Go pour les démons nodemanager et datanode 4Go pour le démon resourcemanager 4Go + 1Go par million de bloc HDFS pour le namenode Secondary namenode configuré comme le namenode Utiliser 4Go voire 8Go par container Superviser Conserver les paramètres mémoire par défaut
cluster Les paramètres dépendent de vos données, de votre réseau, … Comment l’éviter ? Blocs d’au moins 128Mo Utiliser la compression BLOCK par défaut RECORD est pertinent pour pour des vidéos par exemple Utiliser Gzip pour de la donnée archivée, Snappy pour des données de travail Ajuster les buffers d’I/O, le nombre de threads serveur, la bande passante dédiée à la réplication des blocs, … Superviser Conserver la configuration par défaut de HDFS
cluster Les paramètres dépendent de votre utilisation Comment l’éviter ? Compresser les résultats intermédiaires avec Snappy Utiliser le CapacityScheduler ou le FairScheduler Indiquer à YARN des valeurs mémoire minimales et maximales larges Configurer avec des règles de calcul Container / serveur : nb cores * 1,5 – 1 Mémoire : 8Go / core Auditer l’usage réel pour optimiser les configurations Conserver la configuration par défaut de MapReduce
à un stockage inefficace Plus d’espace utilisé que nécessaire Comment l’éviter ? Format de stockage : distinguer les usages Base de données : Parquet / ORC Données binaires : SeqFile Compression : quelle fréquence d’accès ? Donnée utilisée : Snappy Archivage : GZip Utiliser les formats de fichier par défaut
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}