Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Optunaアルゴリズムの紹介
Search
sakami
January 08, 2025
260
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Optunaアルゴリズムの紹介
sakami
January 08, 2025
More Decks by sakami
See All by sakami
Rayで分散処理
sakami
0
7
Featured
See All Featured
Mobile First: as difficult as doing things right
swwweet
225
10k
How to Ace a Technical Interview
jacobian
281
24k
Ethics towards AI in product and experience design
skipperchong
2
330
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
From π to Pie charts
rasagy
0
240
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
The Language of Interfaces
destraynor
162
27k
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
How to Talk to Developers About Accessibility
jct
2
430
Building an army of robots
kneath
306
46k
Statistics for Hackers
jakevdp
799
230k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Transcript
AI 2024.12.26 Kosuke Sakami 株式会社ディー・エヌ・エー + GO株式会社 Optunaアルゴリズムの紹介
AI 2 ▪ 『Optunaによるブラックボックス最適化』6章の内容を話します。 ▪ 本を読んだ程度の知識なので誤り等あればご指摘いただけると助かります。 ▪ 説明のために簡略化している部分があります。 ▪ Optuna
の説明は省略します。 この発表について
AI 3 項目 01|共通の枠組み 02|単目的最適化 03|多目的最適化 04|アルゴリズムの使い分け
AI 4 01 共通の枠組み
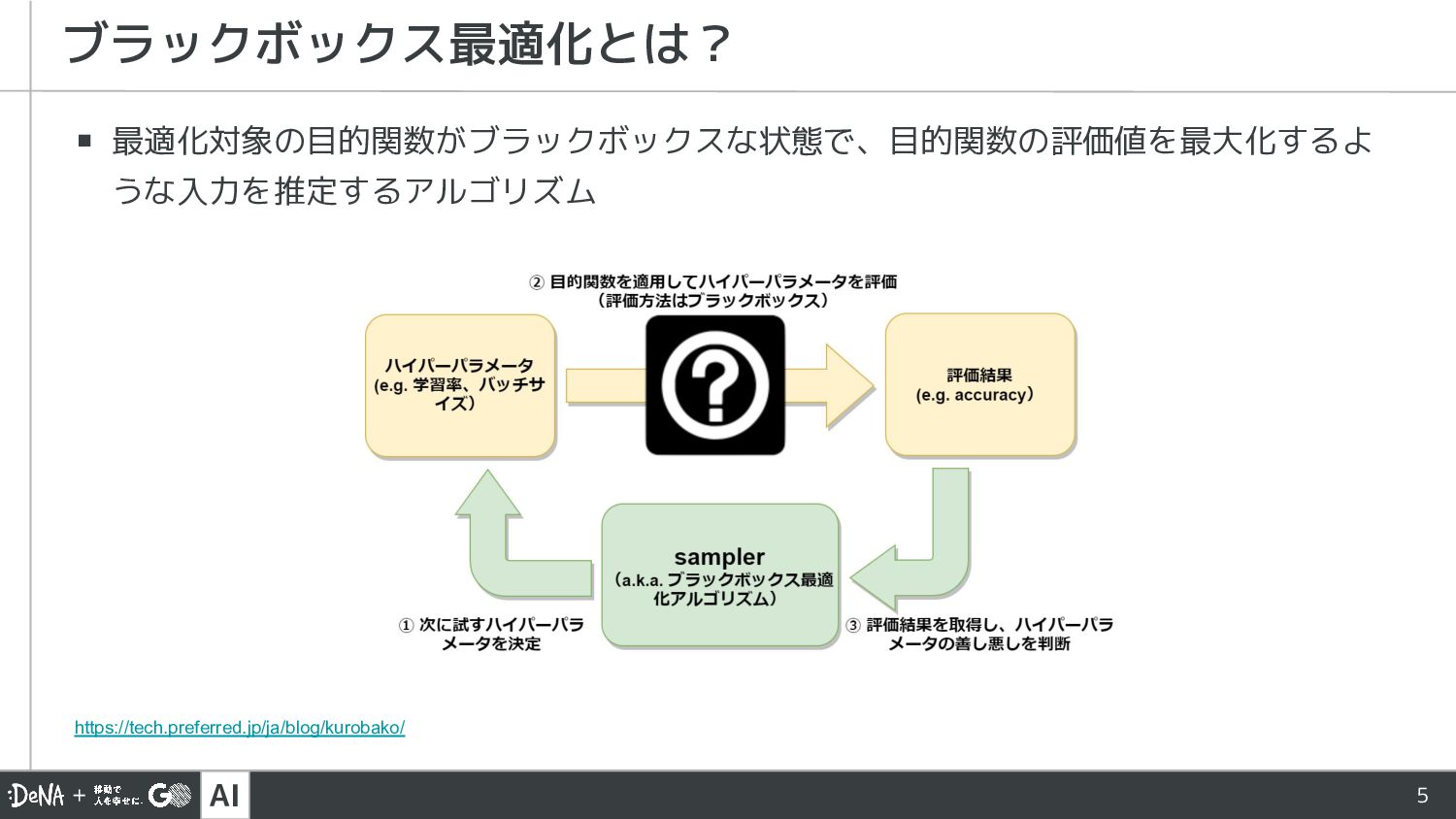
AI 5 ▪ 最適化対象の目的関数がブラックボックスな状態で、目的関数の評価値を最大化するよ うな入力を推定するアルゴリズム ブラックボックス最適化とは? https://tech.preferred.jp/ja/blog/kurobako/
AI 6 02 単目的最適化
AI 7 TPE の特徴 ▪ Optuna の単目的最適化のデフォルトアルゴリズム ▪ 入力空間にカテゴリ変数が含まれていても問題ない ▪
データ点のサンプリングに for ループ、if 分岐が含まれていても問題ない ▪ 計算量: ▪ d: 入力空間の次元数 ▪ n: これまでの探索データ数 1. TPE (Tree-structured Parzen Estimator)
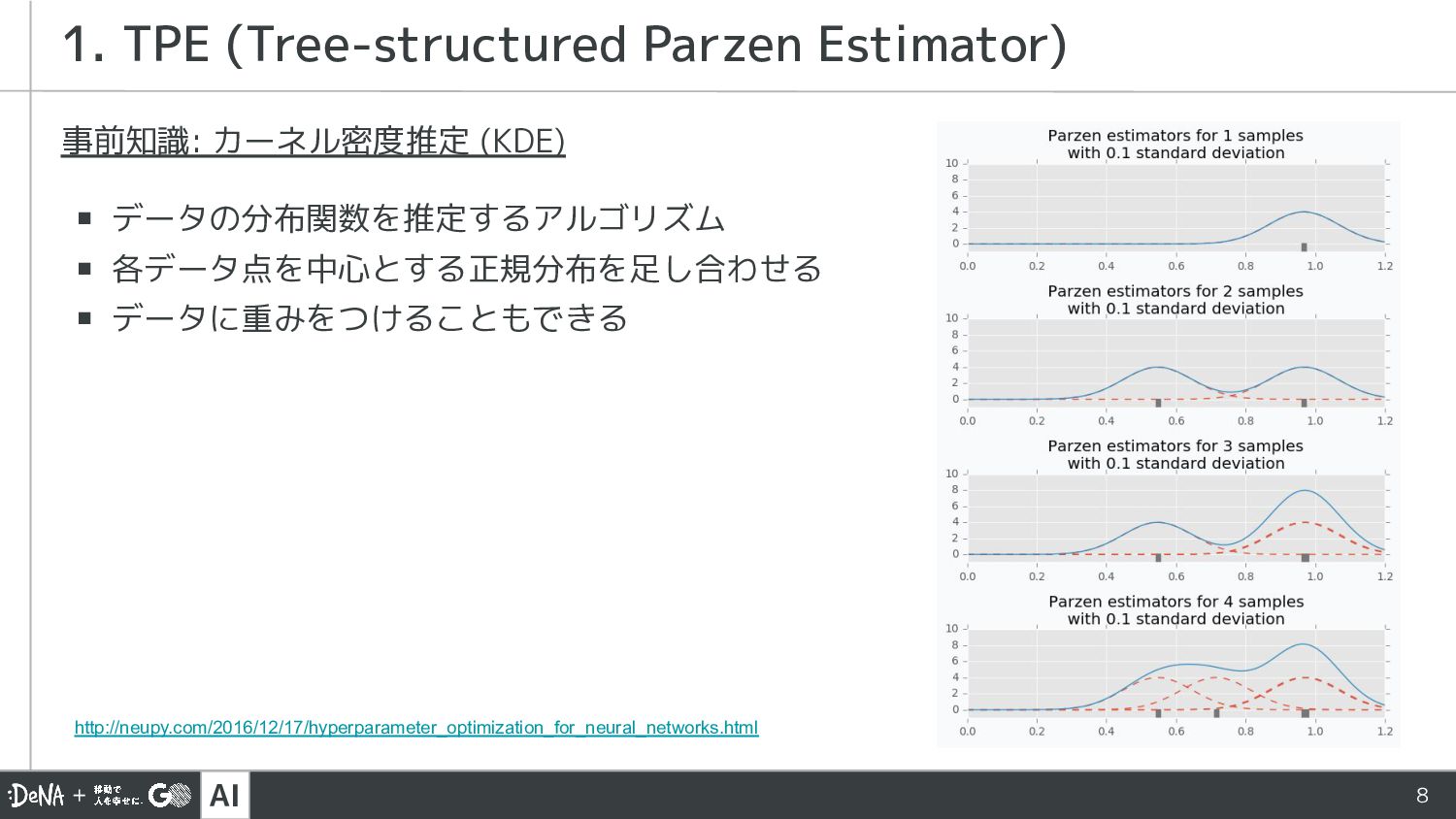
AI 8 事前知識: カーネル密度推定 (KDE) ▪ データの分布関数を推定するアルゴリズム ▪ 各データ点を中心とする正規分布を足し合わせる ▪
データに重みをつけることもできる 1. TPE (Tree-structured Parzen Estimator) http://neupy.com/2016/12/17/hyperparameter_optimization_for_neural_networks.html
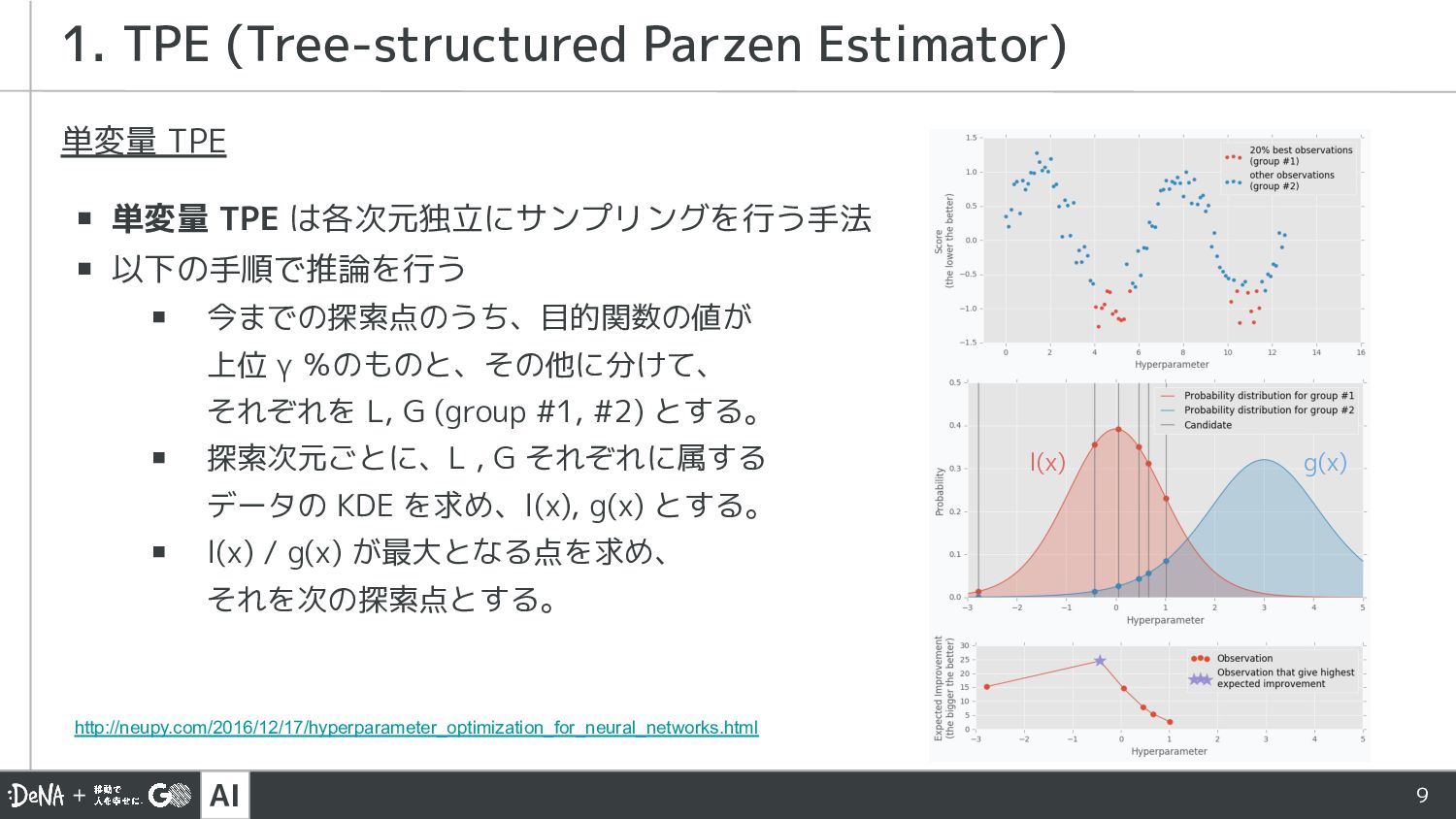
AI 9 単変量 TPE ▪ 単変量 TPE は各次元独立にサンプリングを行う手法 ▪ 以下の手順で推論を行う
▪ 今までの探索点のうち、目的関数の値が 上位 γ %のものと、その他に分けて、 それぞれを L, G (group #1, #2) とする。 ▪ 探索次元ごとに、L , G それぞれに属する データの KDE を求め、l(x), g(x) とする。 ▪ l(x) / g(x) が最大となる点を求め、 それを次の探索点とする。 1. TPE (Tree-structured Parzen Estimator) http://neupy.com/2016/12/17/hyperparameter_optimization_for_neural_networks.html l(x) g(x)
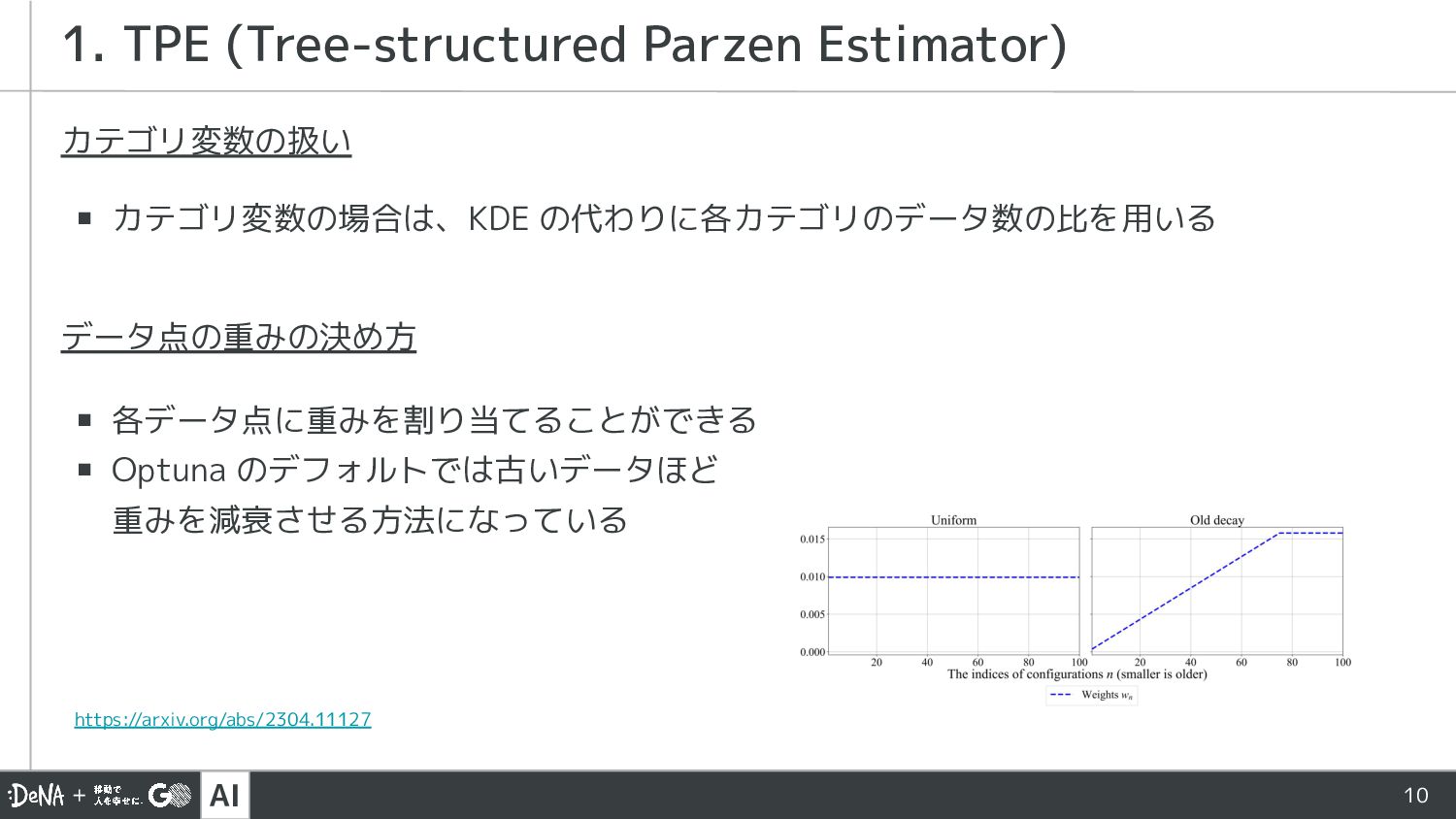
AI 10 カテゴリ変数の扱い ▪ カテゴリ変数の場合は、KDE の代わりに各カテゴリのデータ数の比を用いる データ点の重みの決め方 ▪ 各データ点に重みを割り当てることができる ▪
Optuna のデフォルトでは古いデータほど 重みを減衰させる方法になっている 1. TPE (Tree-structured Parzen Estimator) https://arxiv.org/abs/2304.11127
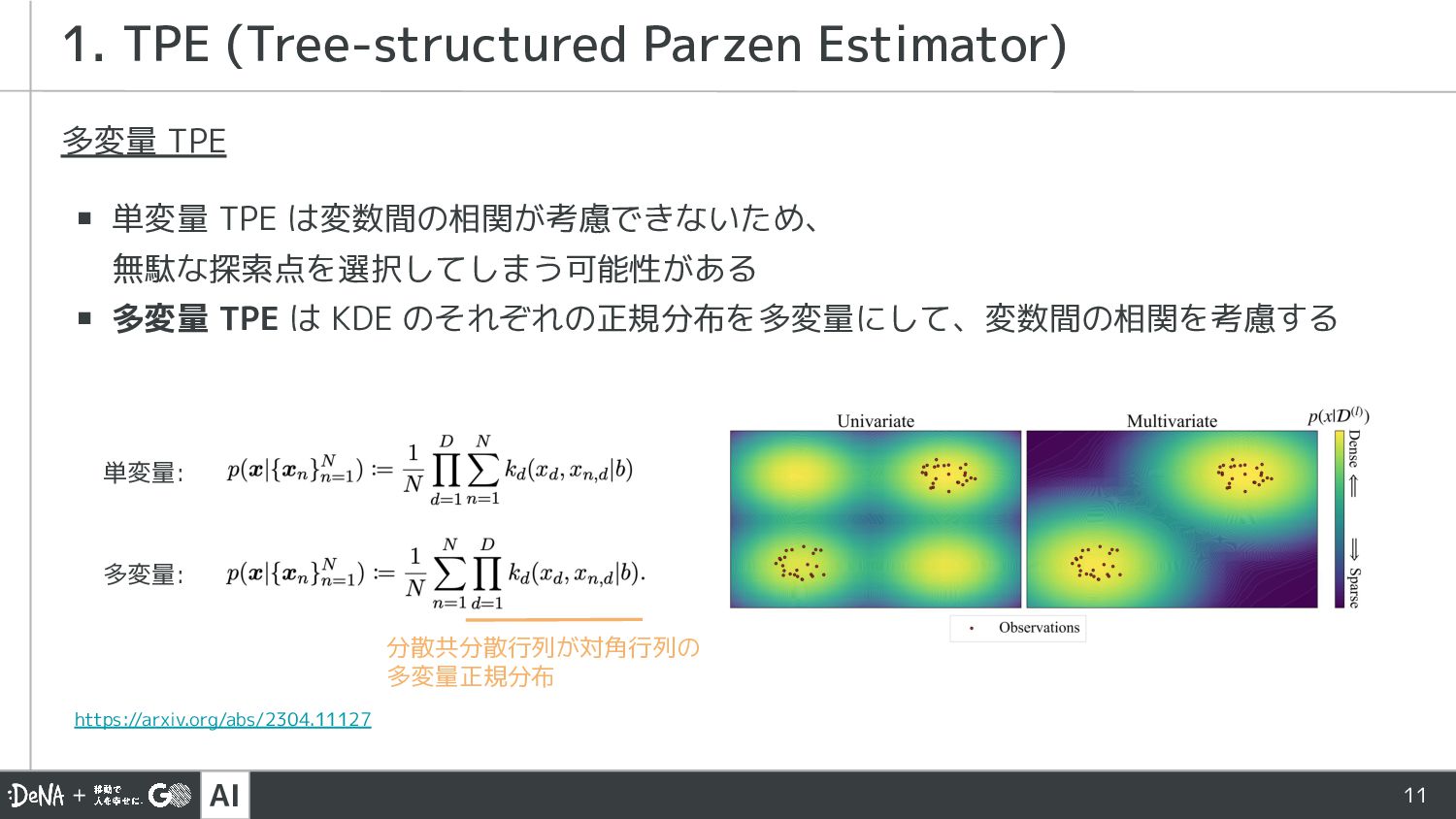
AI 分散共分散行列が対角行列の 多変量正規分布 11 多変量 TPE ▪ 単変量 TPE は変数間の相関が考慮できないため、
無駄な探索点を選択してしまう可能性がある ▪ 多変量 TPE は KDE のそれぞれの正規分布を多変量にして、変数間の相関を考慮する 1. TPE (Tree-structured Parzen Estimator) https://arxiv.org/abs/2304.11127 単変量: 多変量:
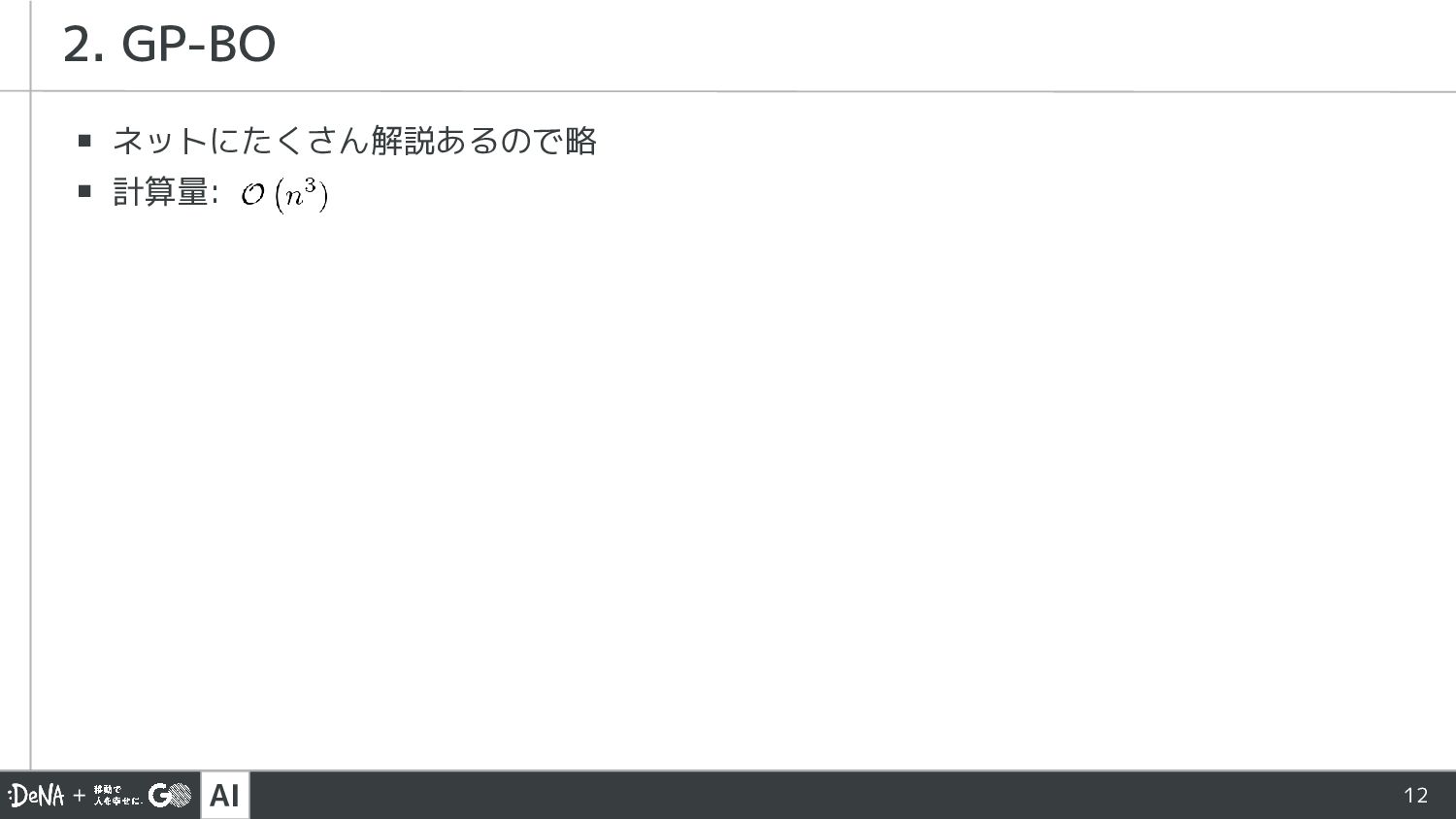
AI 12 ▪ ネットにたくさん解説あるので略 ▪ 計算量: 2. GP-BO
AI 13 CMA-ES の特徴 ▪ 進化計算アルゴリズムの一種 ▪ 各世代で正規分布に従って探索点をサンプリングする ▪ 分散を適応的に変化させて、効率的に探索を行う
▪ 計算量: 3. CMA-ES https://blog.otoro.net/2017/10/29/visual-evolution-strategies/ g+1 世代目の探索点:
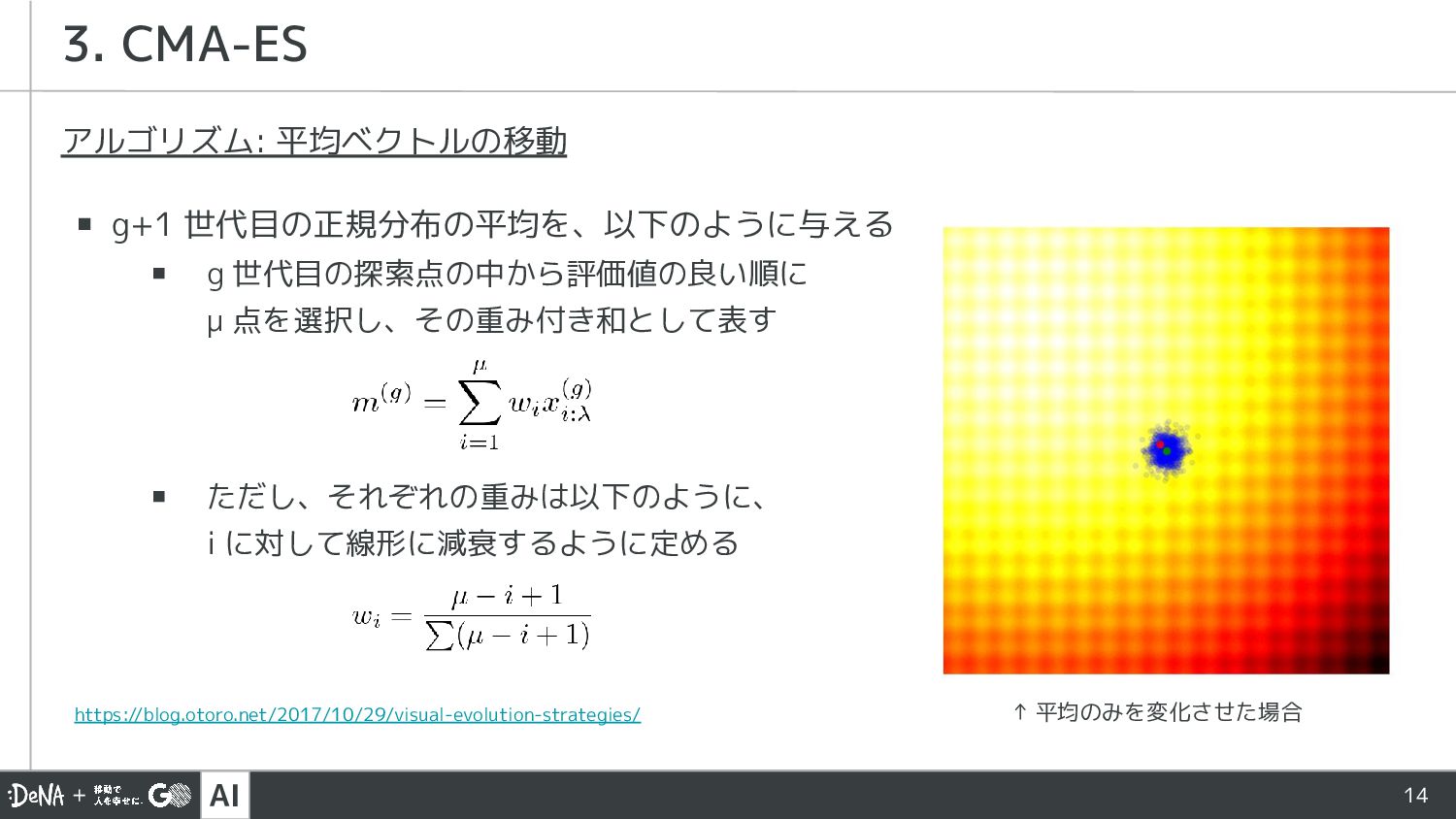
AI 14 アルゴリズム: 平均ベクトルの移動 ▪ g+1 世代目の正規分布の平均を、以下のように与える ▪ g 世代目の探索点の中から評価値の良い順に
μ 点を選択し、その重み付き和として表す ▪ ただし、それぞれの重みは以下のように、 i に対して線形に減衰するように定める 3. CMA-ES https://blog.otoro.net/2017/10/29/visual-evolution-strategies/ ↑ 平均のみを変化させた場合
AI 過去の進化パス 15 アルゴリズム: ステップサイズの調整 ▪ ステップサイズ: 正規分布の分散にかかる係数 ▪ 正規分布の平均ベクトルが指向性を持って移動しているならステップサイズを大きく、
逆に同じ場所を行ったり来たりしているならステップサイズを小さくしたい ▪ 平均ベクトルの移動量の大きさを進化パスにより見積もり、 それを用いてステップサイズを定める 3. CMA-ES http://www2.fiit.stuba.sk/~kvasnicka/Seminar_of_AI/Hansen_tutorial.pdf 今回の平均ベクトルの移動量 新しい進化パス 進化パスの大きさに応じて、ステップサイズを調整する ステップサイズ:
AI 16 アルゴリズム: 分散共分散行列の適応 ▪ 分散共分散行列は、Rank-One Update と Rank-μ Update
の2種類の更新を行う ▪ Rank-One Update: 平均ベクトルの移動方向に 探索幅を伸ばすように分散共分散行列を適応させる ▪ Rank-μ Update: 有望個体群から C を最尤推定する 3. CMA-ES http://www2.fiit.stuba.sk/~kvasnicka/Seminar_of_AI/Hansen_tutorial.pdf C の最尤推定量
AI 17 03 多目的最適化
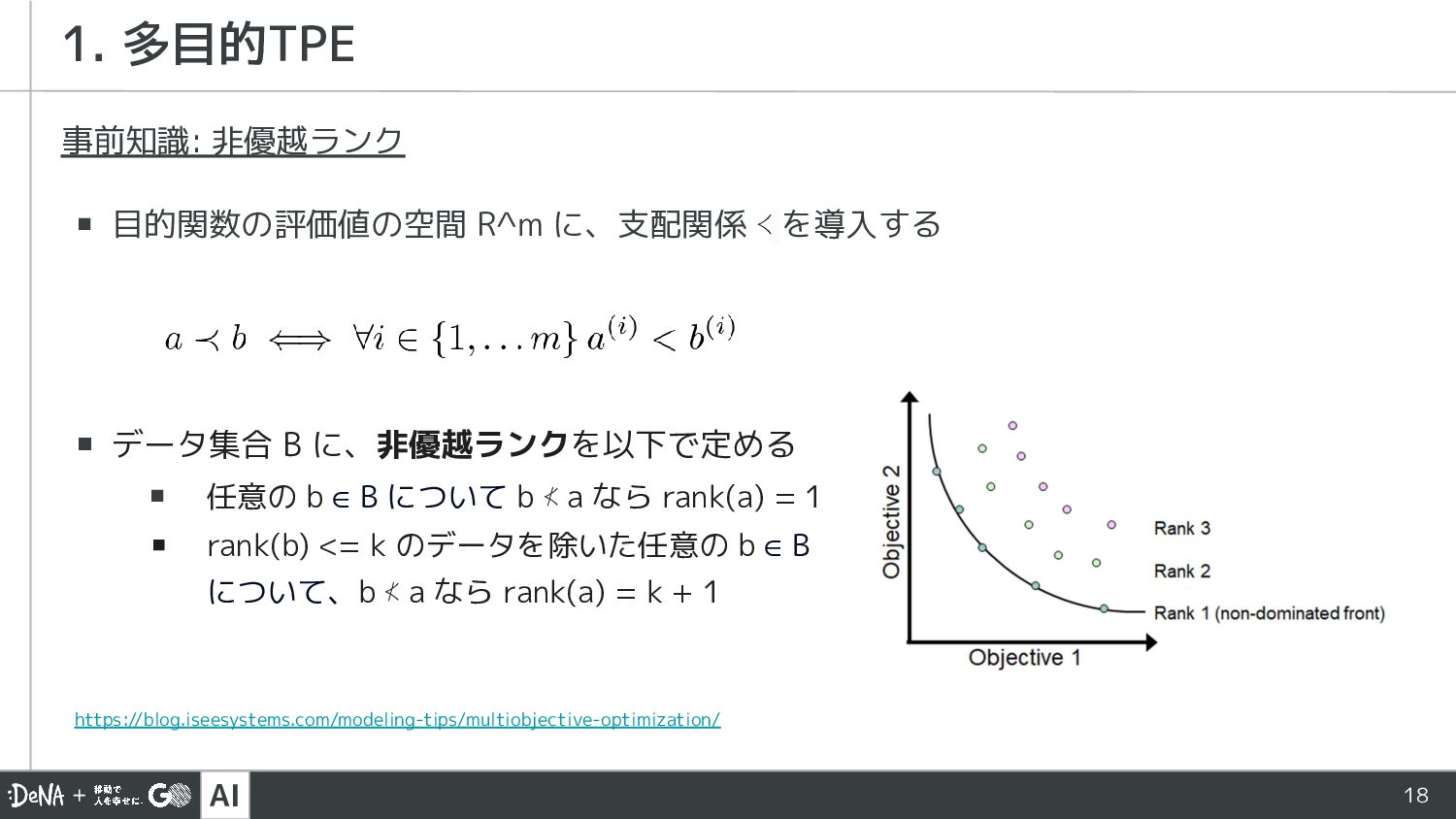
AI 18 事前知識: 非優越ランク ▪ 目的関数の評価値の空間 R^m に、支配関係 ≺ を導入する
▪ データ集合 B に、非優越ランクを以下で定める ▪ 任意の b ∈ B について b ⊀ a なら rank(a) = 1 ▪ rank(b) <= k のデータを除いた任意の b ∈ B について、b ⊀ a なら rank(a) = k + 1 1. 多目的TPE https://blog.iseesystems.com/modeling-tips/multiobjective-optimization/
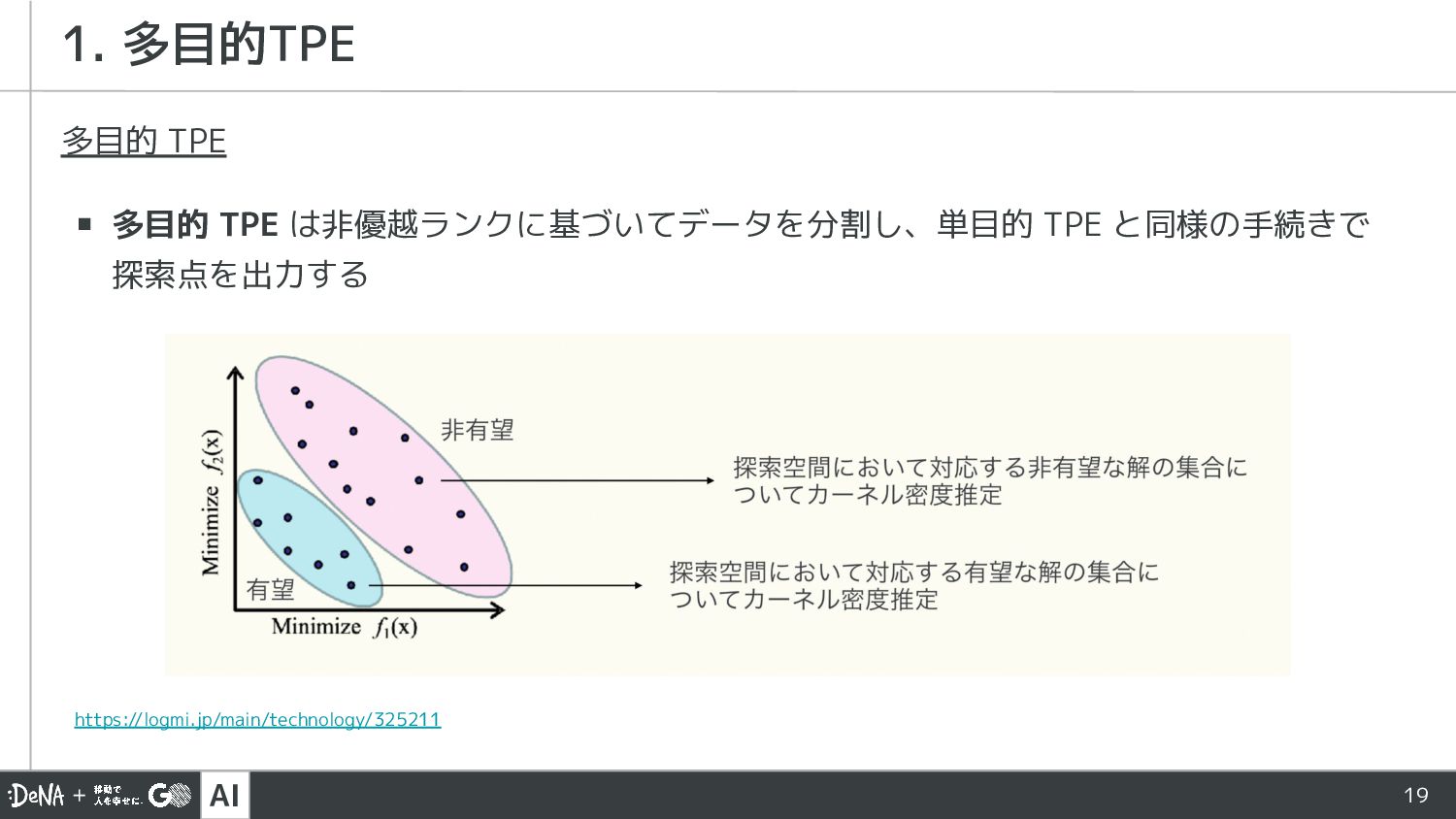
AI 19 多目的 TPE ▪ 多目的 TPE は非優越ランクに基づいてデータを分割し、単目的 TPE と同様の手続きで
探索点を出力する 1. 多目的TPE https://logmi.jp/main/technology/325211
AI 20 L の選び方 ▪ データ分割時、同一ランク内でどのデータ点を選択するかに任意性がある ▪ Optuna のデフォルトでは、超体積指示関数を最大化するようにデータ点が選択される ▪
超体積指示関数: データ点集合が支配する体積を返す関数。 値を有限にするため、適当な参照点 r を固定し、その間の体積を測る。 ▪ 貪欲法により最大化する 1. 多目的TPE https://logmi.jp/main/technology/325211
AI 21 NSGA-Ⅱ ▪ NSGA-Ⅱ は Optuna の多目的最適化のデフォルトで、進化計算アルゴリズムの一種 ▪ 以下の手順で推論を行う
▪ 前の世代の集団から、非優越ランクおよび混雑距離に基づいて親集団を選択する ▪ 親集団から、交叉と突然変異によって作成した子集団を探索点の集合とする ▪ 前の世代の集団としては、親集団と子集団の和集合を用いる ▪ 計算量: ▪ m: 目的関数の出力空間の次元数 ▪ p: 各世代の個体数 2. NSGA-Ⅱ https://logmi.jp/main/technology/325211
AI 22 混雑距離 ▪ 非優越ランクだけでは親集団が一意に定まらないので、混雑距離を導入する。 ▪ 混雑距離: その個体に隣接する2つの個体のマンハッタン距離 ▪ 目的関数の出力空間の混雑距離が大きいものから順に個体を選択することで、多様性を
確保できる 交叉と突然変異 ▪ Optuna では、交叉ののち突然変異を行う ▪ 定義域に実数値変数が多く含まれる場合は、 デフォルトの一様交叉のままでは性能が悪い 2. NSGA-Ⅱ https://tech-oh.com/2022/05/17/multi_objective_opt_5/
AI 23 04 アルゴリズムの使い分け
AI 24 TPE ▪ カテゴリ変数や if / for ループなどに柔軟に対応できる GP-BO
▪ 探索回数が数十回程度の、重い計算の探索に適している CMA-ES ▪ 目的関数の計算が高速で、探索を多く回せる場合に適している ▪ カテゴリ変数や制約付き最適化に対応していない 1. 単目的最適化
AI 25 多目的 TPE ▪ 探索回数が限定されている場合に、NSGA-Ⅱ よりも性能が良い ▪ Optuna v4.0.0
で大幅に高速化されている NSGA-Ⅱ ▪ 実行時間が探索回数によらず一定なので、 多く探索する場合に適している 2. 多目的最適化 https://logmi.jp/main/technology/325211
AI 26 AI
AI 27 Appendix
AI 28 l(x) / g(x) が期待改善量を最大化していることの説明 1. TPE (Tree-structured Parzen
Estimator) x^(i) に関係ないので 無視して OK y*: L, G の境界の y の値 y が小さい方がよいとする
AI 29 l(x) / g(x) が期待改善量を最大化していることの説明 1. TPE (Tree-structured Parzen
Estimator) これを最小化すれば OK
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}