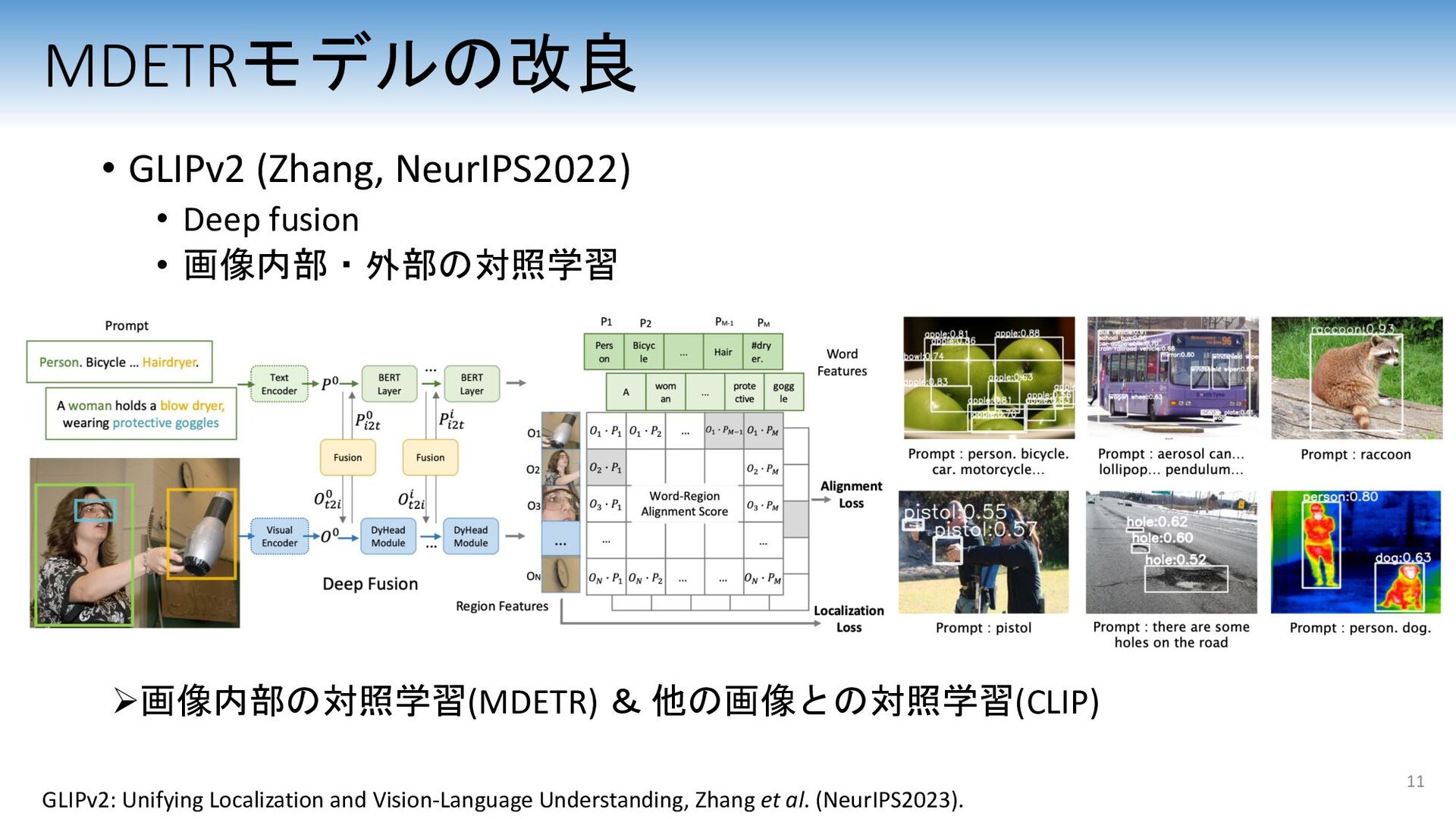
opening the faucets to a fire hydrant letting water out onto the lawn • a city worker turning on the water at a fire hydrant. • worker opening valve of fire hydrant in residential neighborhood. • a man adjusting the water flow of a fire hydrant. • the official in a yellow vest is using a wrench on a fire hydrant. Question: What color is the hydrant? red black and yellow 3 Ø 近年のMultimodal Language Modelなども,本質的にはこの2大タスクを解いているケースが多い Ø ICやVQAよりもより細かく,画像中の物体とテキストを対応付けられないか?
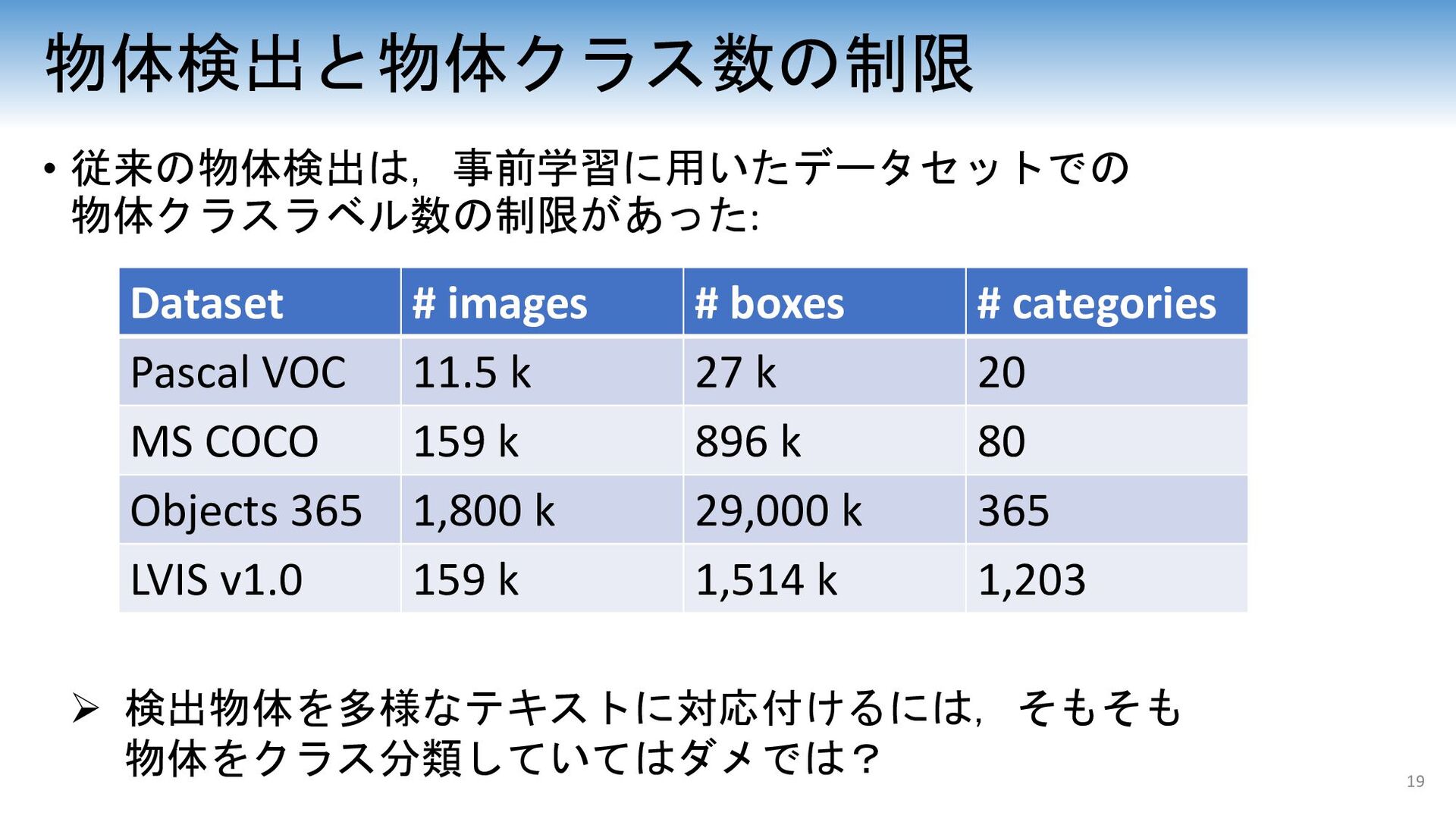
# categories Pascal VOC 11.5 k 27 k 20 MS COCO 159 k 896 k 80 Objects 365 1,800 k 29,000 k 365 LVIS v1.0 159 k 1,514 k 1,203 Ø 検出物体を多様なテキストに対応付けるには,そもそも 物体をクラス分類していてはダメでは?
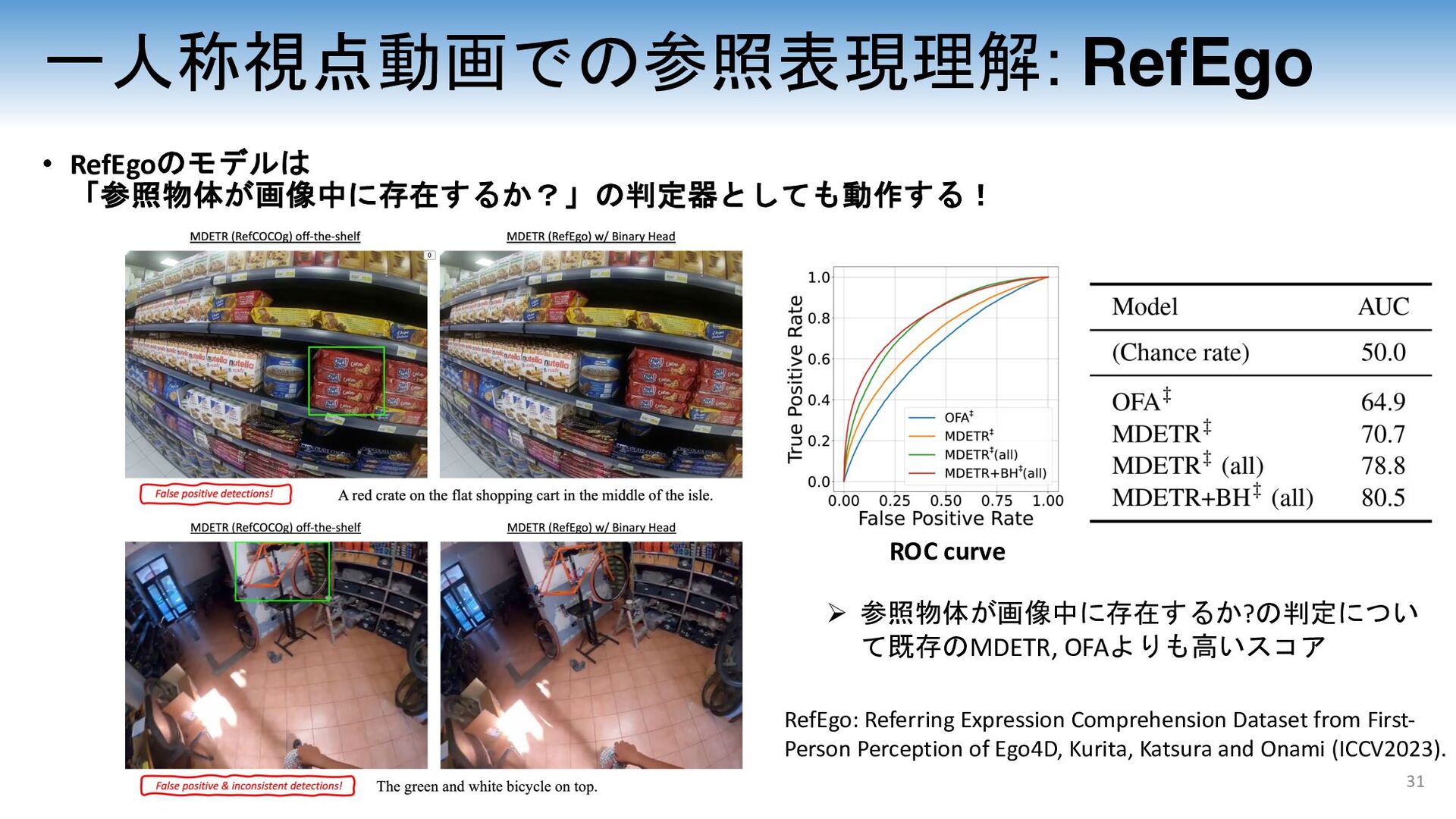
dataset A woman with a stroller. A girl riding a horse. ReferDAVIS Refer-YouTube-VOS A person showing his skate board skills on the road. A person on the right dressed in blue black walking while holding a white bottle.
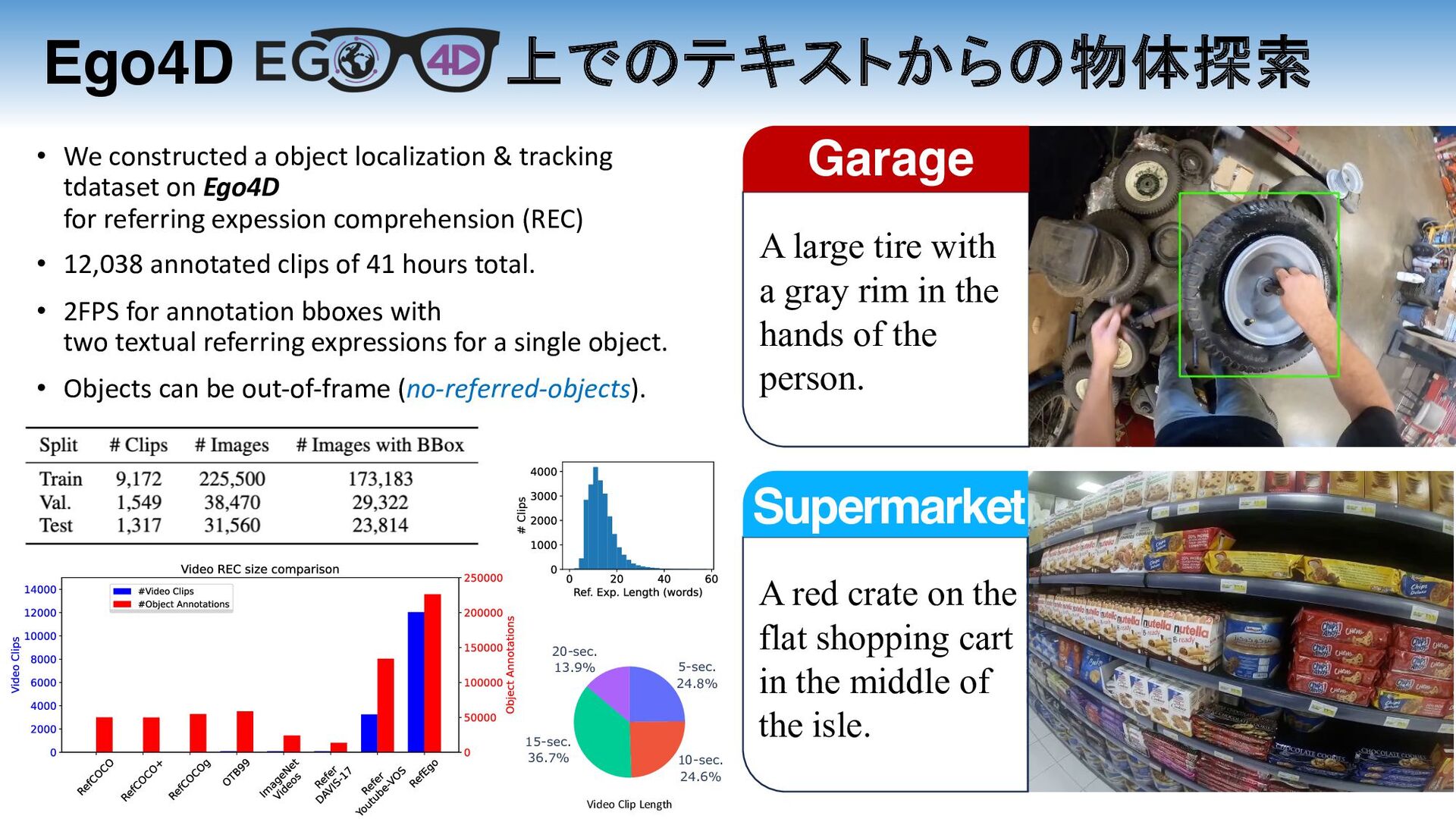
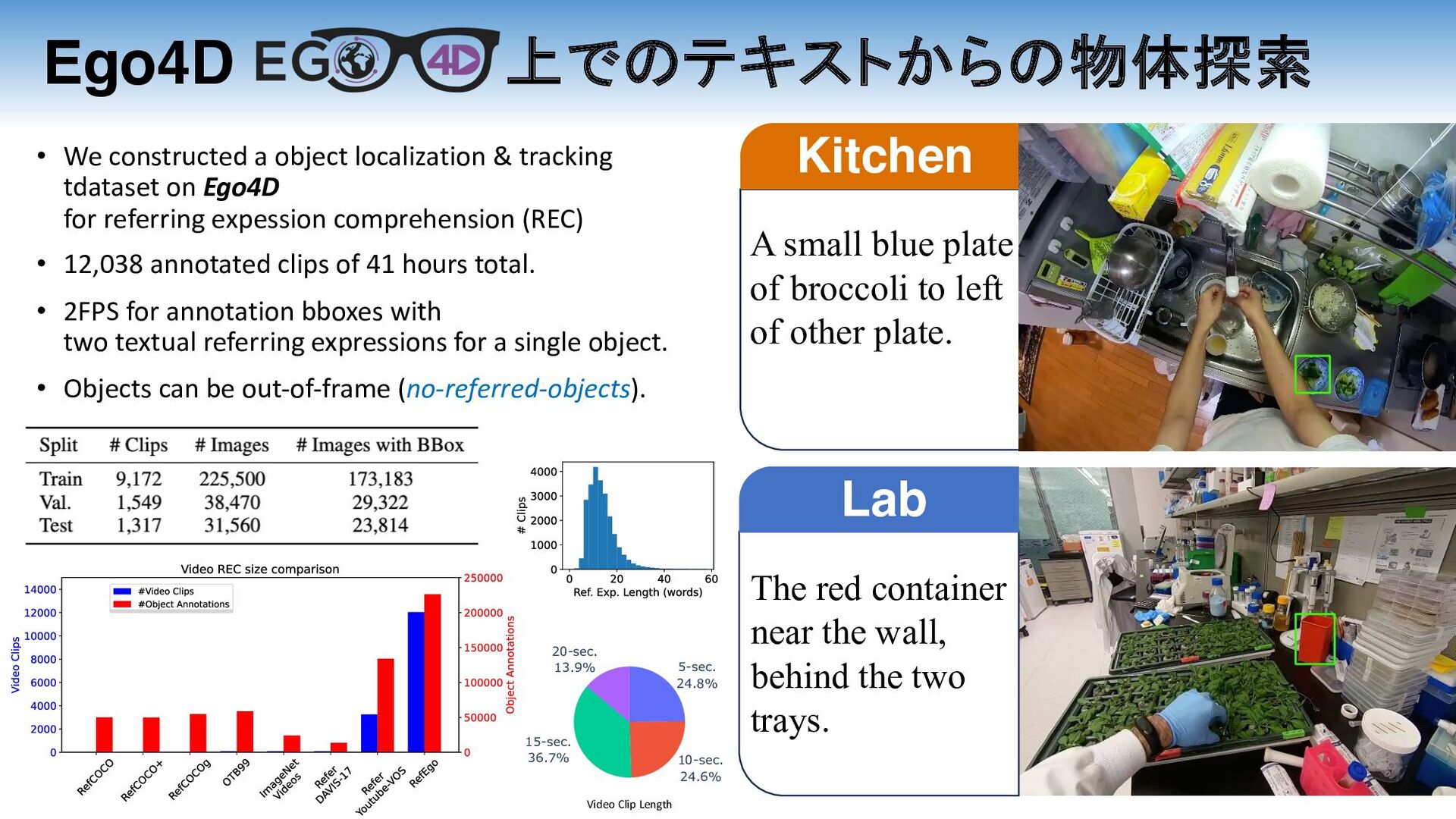
in the hands of the person. A red crate on the flat shopping cart in the middle of the isle. A small blue plate of broccoli to left of other plate. The red container near the wall, behind the two trays. Garage Kitchen Lab Supermarket
• We constructed a object localization & tracking tdataset on Ego4D for referring expession comprehension (REC) • 12,038 annotated clips of 41 hours total. • 2FPS for annotation bboxes with two textual referring expressions for a single object. • Objects can be out-of-frame (no-referred-objects). Video Clip Length A large tire with a gray rim in the hands of the person. A red crate on the flat shopping cart in the middle of the isle. Garage Supermarket
left of other plate. The red container near the wall, behind the two trays. Kitchen Lab 5-sec. 24.8% 10-sec. 24.6% 15-sec. 36.7% 20-sec. 13.9% • We constructed a object localization & tracking tdataset on Ego4D for referring expession comprehension (REC) • 12,038 annotated clips of 41 hours total. • 2FPS for annotation bboxes with two textual referring expressions for a single object. • Objects can be out-of-frame (no-referred-objects). Video Clip Length
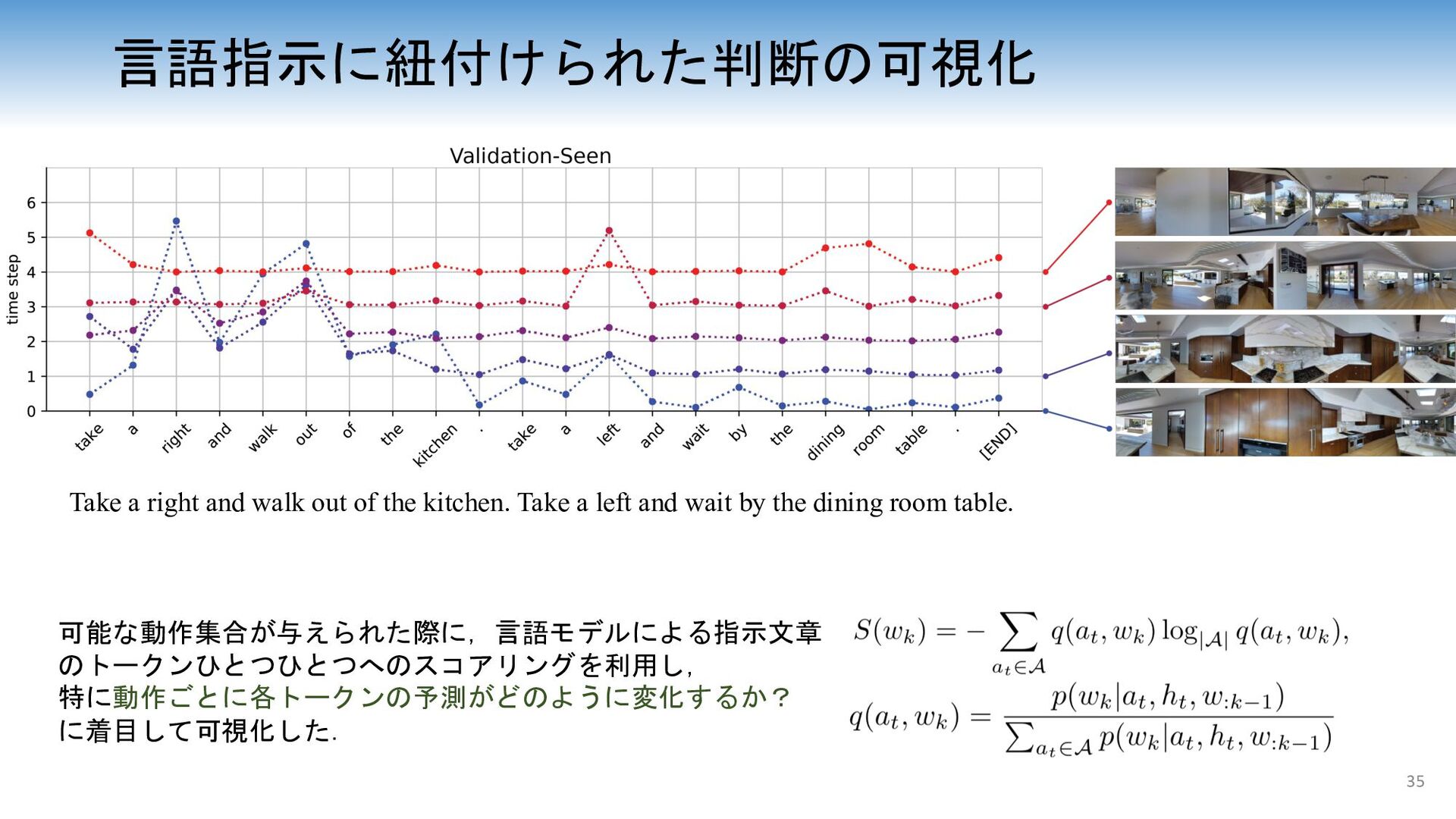
a left and wait by the dining room table. 言語指示に紐付けられた判断の可視化 可能な動作集合が与えられた際に,言語モデルによる指示文章 のトークンひとつひとつへのスコアリングを利用し, 特に動作ごとに各トークンの予測がどのように変化するか? に着目して可視化した. 35
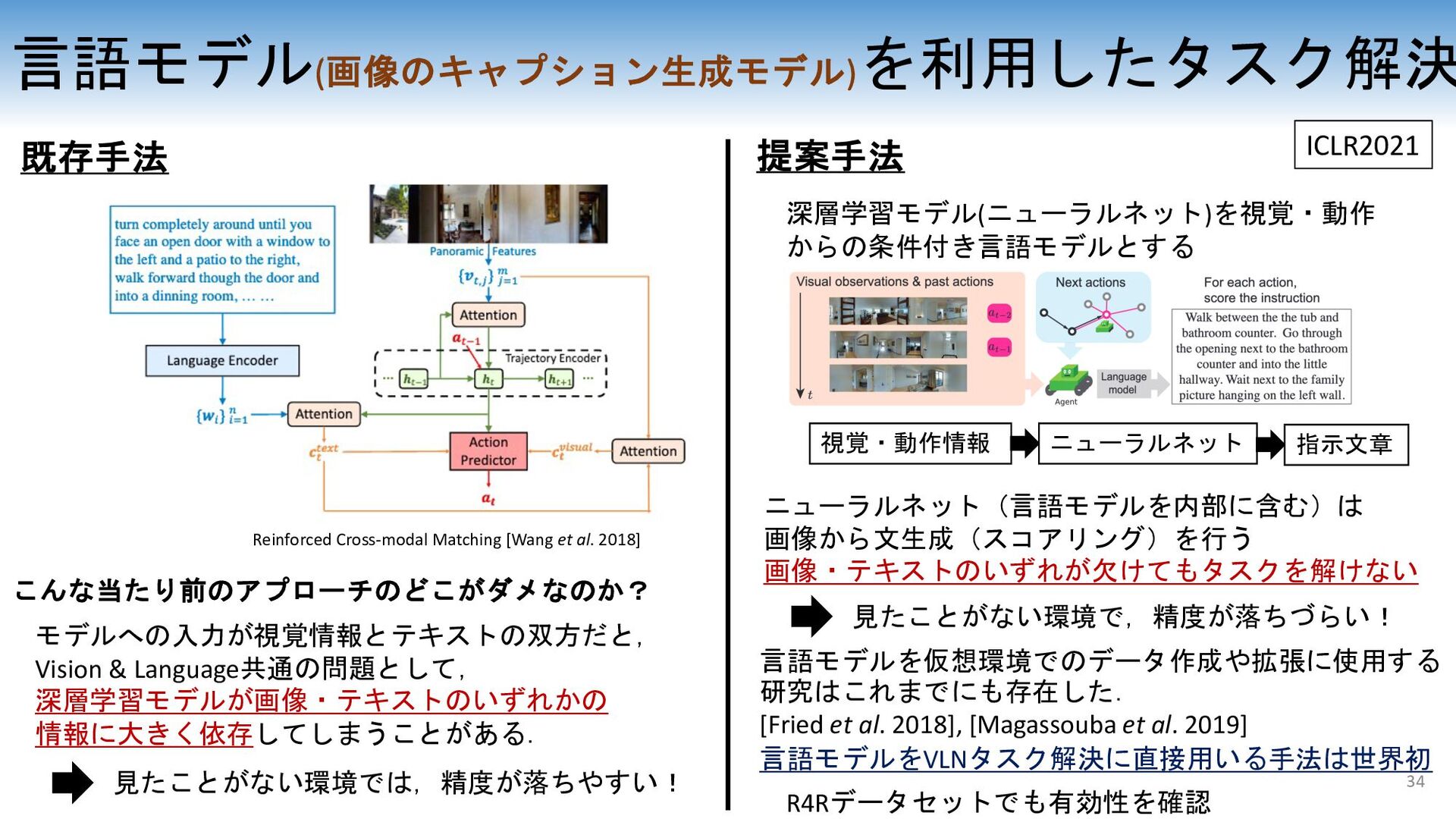
et al. (2020) – The same first author with the original VLN paper. Possible future direction: Integration of high-level machine-learning agents and low-level robotic manipulation. – Yes! 36
following datasetであるALFREDが作られている (右図) • しかし、このような環境では、環境中の物体や定義された 動作が言語的な多様性よりもはるかに少ないことが多い • 例:レタスを刻んで、殻剥きゆで卵とあえてボウルに入れ ドレッシングかけてからラップをして 冷蔵庫で冷やす :可能 :近い動作は可能だが細かい再現は不可能 :不可能 To heat a cup as well as place it in the fridge. Open the drawer Pick up a mug Open the microoven door Put the mug onto the microoven … ※最近は3Dアセットのデータセットが充実してきており 限られた物体という制限は作り込み次第で取り払われるかもしれない 37
C.f. Do as I say, not as I do: “私が教えるように行動しなさい、 私がするようにではなく” ジョン・セルデン 「茶話」 1654年 Do As I Can, Not As I Say: Grounding Language in Robotic Affordances (Google Robotics, April 2022) Google Robotics SayCan: Do As I Can, Not As I Say (2022) 私が言ったようにではなく 私ができるように動作しなさい INPUT: I spilled my coke on the table, how would you throw it away and bring me something to help clean? ROBOT: 39
C.f. Do as I say, not as I do: “私が教えるように行動しなさい、 私がするようにではなく” ジョン・セルデン 「茶話」 1654年 Do As I Can, Not As I Say: Grounding Language in Robotic Affordances (Google Robotics, April 2022) Google Robotics SayCan: Do As I Can, Not As I Say (2022) 私が言ったようにではなく 私ができるように動作しなさい INPUT: I spilled my coke on the table, how would you throw it away and bring me something to help clean? ROBOT: 40
C.f. Do as I say, not as I do: “私が教えるように行動しなさい、 私がするようにではなく” ジョン・セルデン 「茶話」 1654年 Do As I Can, Not As I Say: Grounding Language in Robotic Affordances (Google Robotics, April 2022) Robotics at Google & Everyday Robots SayCan: Do As I Can, Not As I Say (2022) 私が言ったようにではなく 私ができるように動作しなさい INPUT: I spilled my coke on the table, how would you throw it away and bring me something to help clean? ROBOT: I would 1. find a coke can 2. pick up the coke can 3. go to trasj can 4. put down the coke can 5. find a sponge 6. pick up the sponge 7. go to the table 8. put down the sponge 9. __ 41
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances (Google Robotics, April 2022) 511 preset skill-set + text-description + value function 101 task instructions in 7 classes (via MTurk) 42
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances (Google Robotics, April 2022) • 大規模言語モデル (LLM) に既存行動を promptingとして入力し、 次の行動を skill-set の中から選択する • 一方で、環境から各skill毎に計算される value関数の値と合わせることで 次の行動を決定する (あれ…GLGPとどこか似ている… 🤔 ) 43
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参照表現理解 & 言語モデル • OFA [Wang 2022] • 複数のタスク,複数のデータセットを 結合してone](https://files.speakerdeck.com/presentations/1ec61993235948109620c0c7202dea82/slide_11.jpg){kind=link}
![参照表現理解 & 言語モデル • OFA [Wang 2022] • 参照表現理解や物体検出時,bounding boxの](https://files.speakerdeck.com/presentations/1ec61993235948109620c0c7202dea82/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
![画像と言語の対照学習と基盤モデル 対照学習 Skip-gram learning in word2vec [Mikolov 2013] SimCLR [Chen](https://files.speakerdeck.com/presentations/1ec61993235948109620c0c7202dea82/slide_15.jpg){kind=link}
![画像と言語の対照学習と基盤モデル • CLIP [Radford, 2021] • (1) バッチ内部の複数枚の画像とテキストとのアライメントを対照事前学習 • 推論時に](https://files.speakerdeck.com/presentations/1ec61993235948109620c0c7202dea82/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}