Powerful DOM search utilities • Various page types • Forever changing version → Flexible architecture → Robust development ▪ More search utilities, more options
task results in a union of both input model. ◦ Or… leads to two pieces of scrapers with many shared functions. • Parameters carried all over the scraping logic. ◦ If-else jungles. ◦ Many subroutines with longAndSubtlyDifferentNamesLikeThis.
b • Child Combinator ◦ a > b • Adjacent Sibling Combinator ◦ a + b • General Sibling Combinator ◦ a ~ b See: https://www.w3.org/TR/css3-selectors/#grammar
buried in text... <p>Text in certain date format...</p> // can’t anchor text nodes... <p>Some text <a>link</a> some text</p> // only takes simple selector... :not(div.some-class)
◦ Iterate by DFS (depth first search), filtered by Match Function • Match Function: Selector Group, Node → boolean ◦ Disjunction (OR) over selectors in selector group ◦ = match(selector1, node) || match(selector2, node) || ... Selector Group ::= Selector [, Selector]* • div#id, div.class, a[attr]
id selector ◦ Optimize on simple selector sequence conjunction order ◦ Optimize on selector group disjunction order ◦ DFS pruning • Can we do more? ◦ element.querySelectorAll(“+ .some-class”) ◦ Younger-sibling-first DFS ◦ Child-first DFS ▪ Beware of time cost
<div>...</div> // body </div> <div> <footer>...</footer> </div> • How to express the position constraints of header/footer to target body? ◦ Body is [after] header AND [before] footer
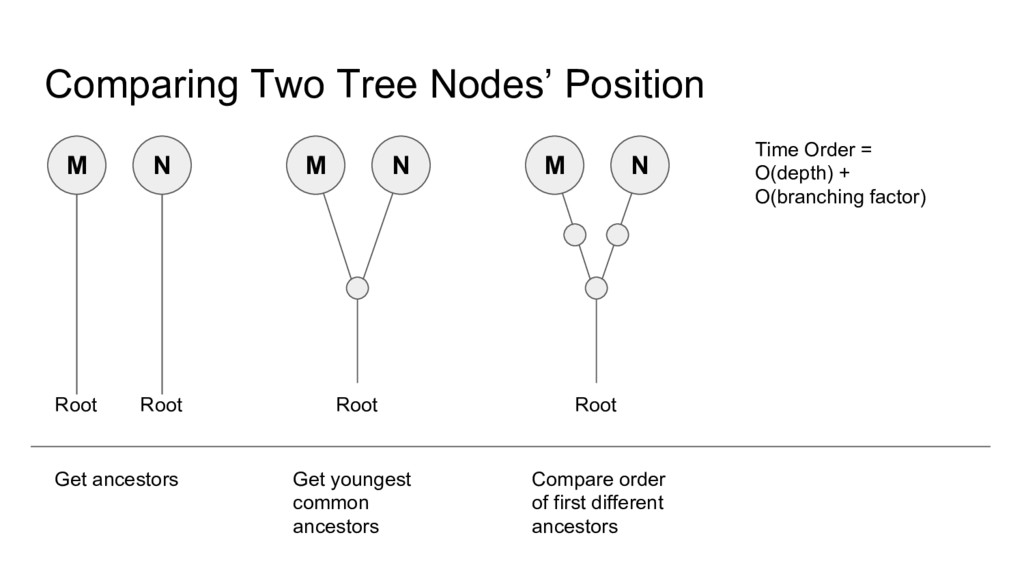
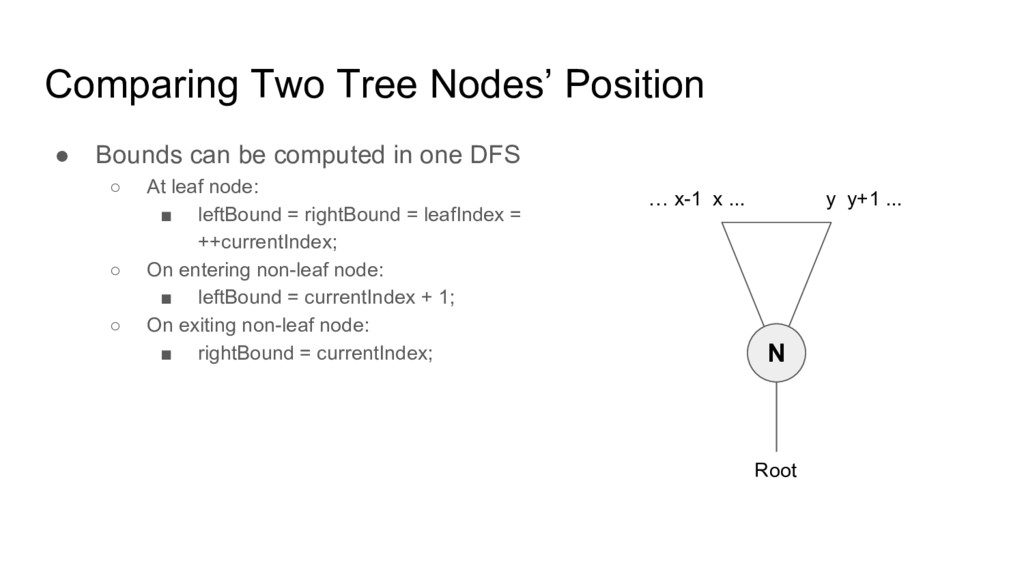
• In case of immutable tree, with O(n) indexing, node position comparison is O(1) • Key: ◦ Define leaf index, L(N) = index of leaf node in DFS order, for any leaf node N. ◦ Define left bound, LB(N) = leaf index of oldest leaf descendant of N (including itself) ◦ Define right bound, RB(N) = leaf index of youngest leaf descendant of N (including itself)
Root A: before M.rightBound < N.leftBound B: after M.leftBound > N.rightBound C: descendant not (A or B), M.depth > N.depth D: ancestor not (A or B), M.depth < N.depth E: equal otherwise
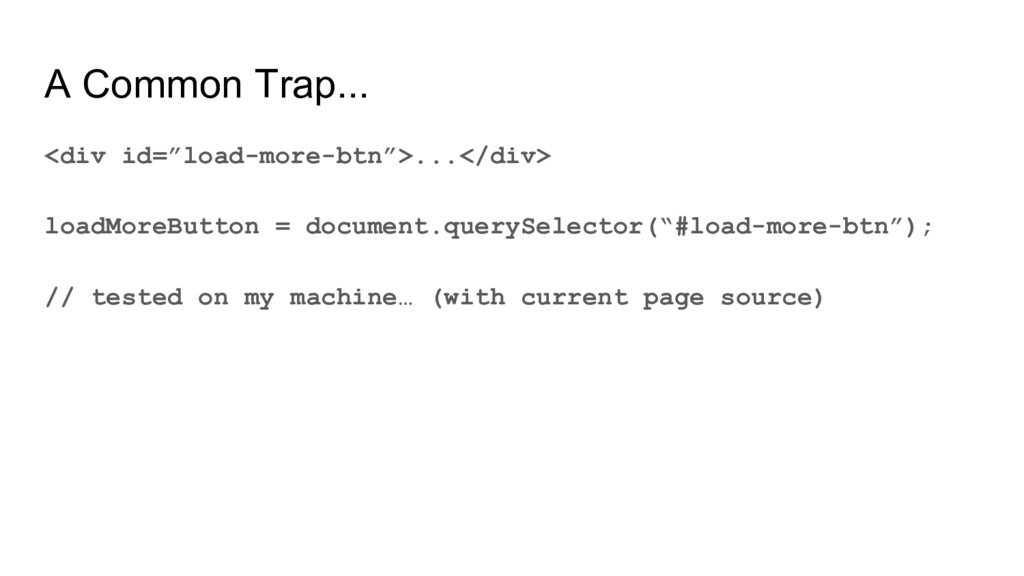
◦ Presence of login form ◦ Permalink • Try to follow their code structure ◦ Conway’s Law • Scrape based on robust hypotheses ◦ Need to collect documents ◦ Need the ability to do experiment over a document set // hypothesis: #load-more-btn is unique and always present loadMoreButton = document.querySelector(“#load-more-btn”);
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Document Query Language SELECT * FROM [Doc_1, Doc_2] WHERE *](https://files.speakerdeck.com/presentations/2aa52122efcf48ceb7f3c058d5c03b93/slide_45.jpg){kind=link}
![Document Query Language SELECT * FROM [Doc_1, Doc_2] WHERE .c](https://files.speakerdeck.com/presentations/2aa52122efcf48ceb7f3c058d5c03b93/slide_46.jpg){kind=link}
![Document Query Language SELECT tag FROM [Doc_1, Doc_2] WHERE .c](https://files.speakerdeck.com/presentations/2aa52122efcf48ceb7f3c058d5c03b93/slide_47.jpg){kind=link}
![Document Query Language SELECT COUNT(*) FROM [Doc_1, Doc_2] WHERE .c](https://files.speakerdeck.com/presentations/2aa52122efcf48ceb7f3c058d5c03b93/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}