graph processing,” SIGMOD 2010. – B. Shao+, “The Trinity graph engine,” Technical Report 161291, Microsoft Research 2012. – Y. Low+, “GraphLab: A New Parallel Framework for Machine Learning,” UAI 2010. • 今回は Pregel の概要 (3分) その実装 Apache Giraph についての紹介をする
(Java NIO をラップした Client/Server Socket Framework, non-blocking I/O など) Avery Ching> [snip] These were some median runs. The overall runtime improved from 167722 -> 57795 with Netty (2.9x faster). Loading the vertices improved from 51025 -> 13393 (3.8x faster). More results coming tomorrow, but for bigger runs, the improvement is likely to be even more than 3x.
• Pregel paritioning is not locality-preserving – データとアルゴリズムによりけり – RPC による communication が大量発生し非効率 になる可能性がある – Default: hash(VertexID) mod N (=# of partition)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
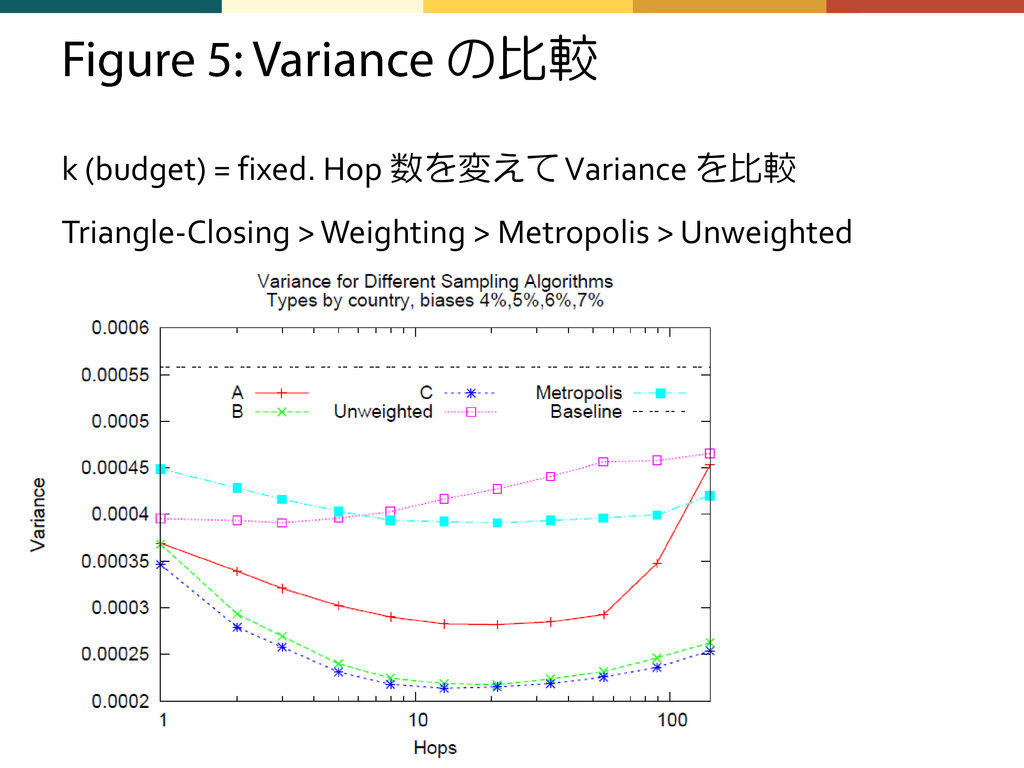
![• 結果におけるバリアンスの差をどう見るか? – チェビシェフを適用すると差小さくね? – バイアスに差が大きい場合は普通のサンプリ ングではバリアンス大きくなる? • Var[X] =](https://files.speakerdeck.com/presentations/4fd2c325d3d0d601cb00220e/slide_55.jpg){kind=link}