, Ram Pasunuru , Pedro Rodriguez , John Nguyen , Benjamin Muller, Margaret Li , Chunting Zhou⋄, Lili Yu, Jason Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman , Srinivasan Iyer FAIR at Meta, Paul G. Allen School of Computer Science & Engineering, University of Washington,University of Chicago 読み手:佐藤蒼馬(名大 笹野研 M2)
{kind=link}
{kind=link}
{kind=link}
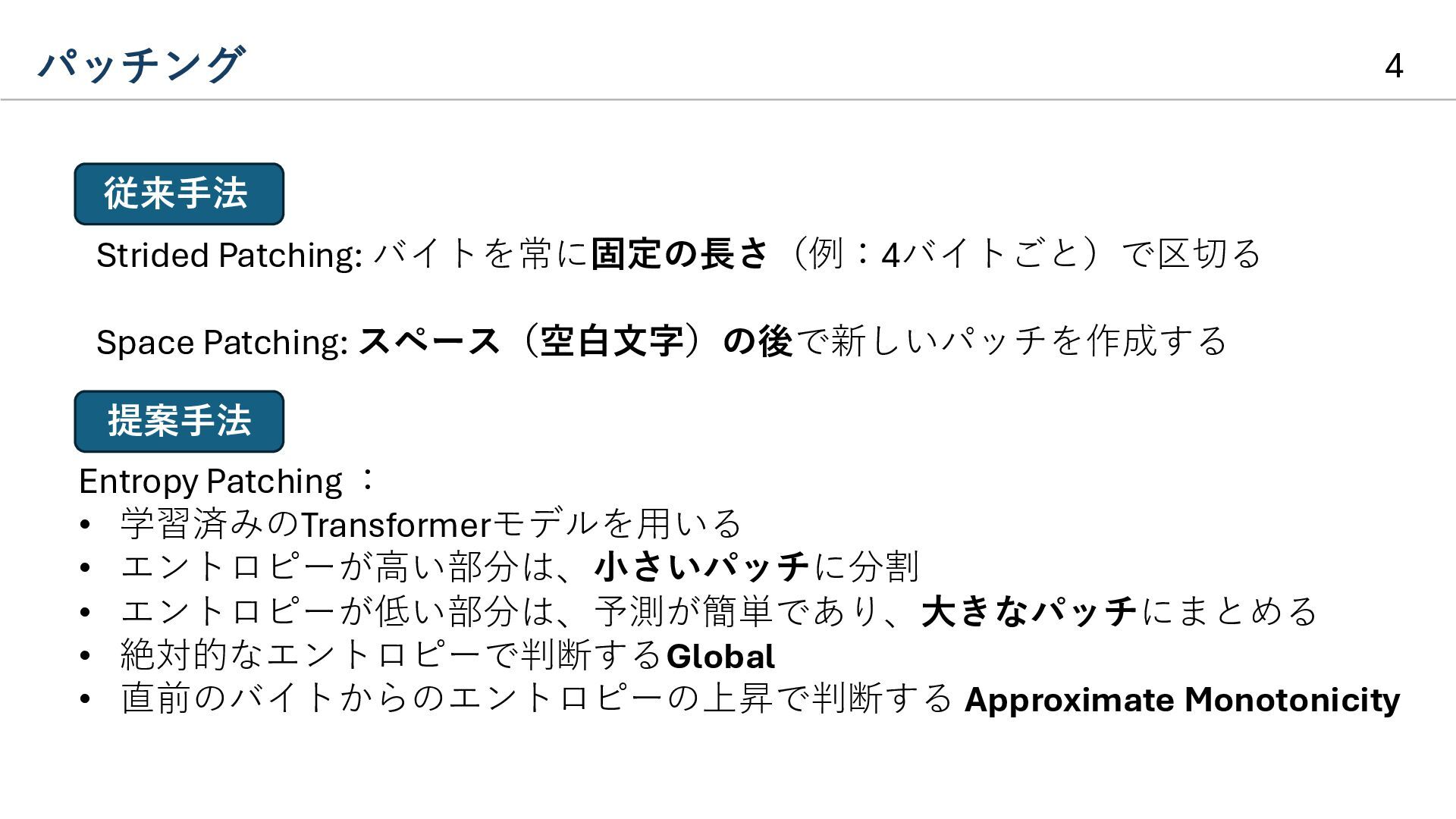{kind=link}
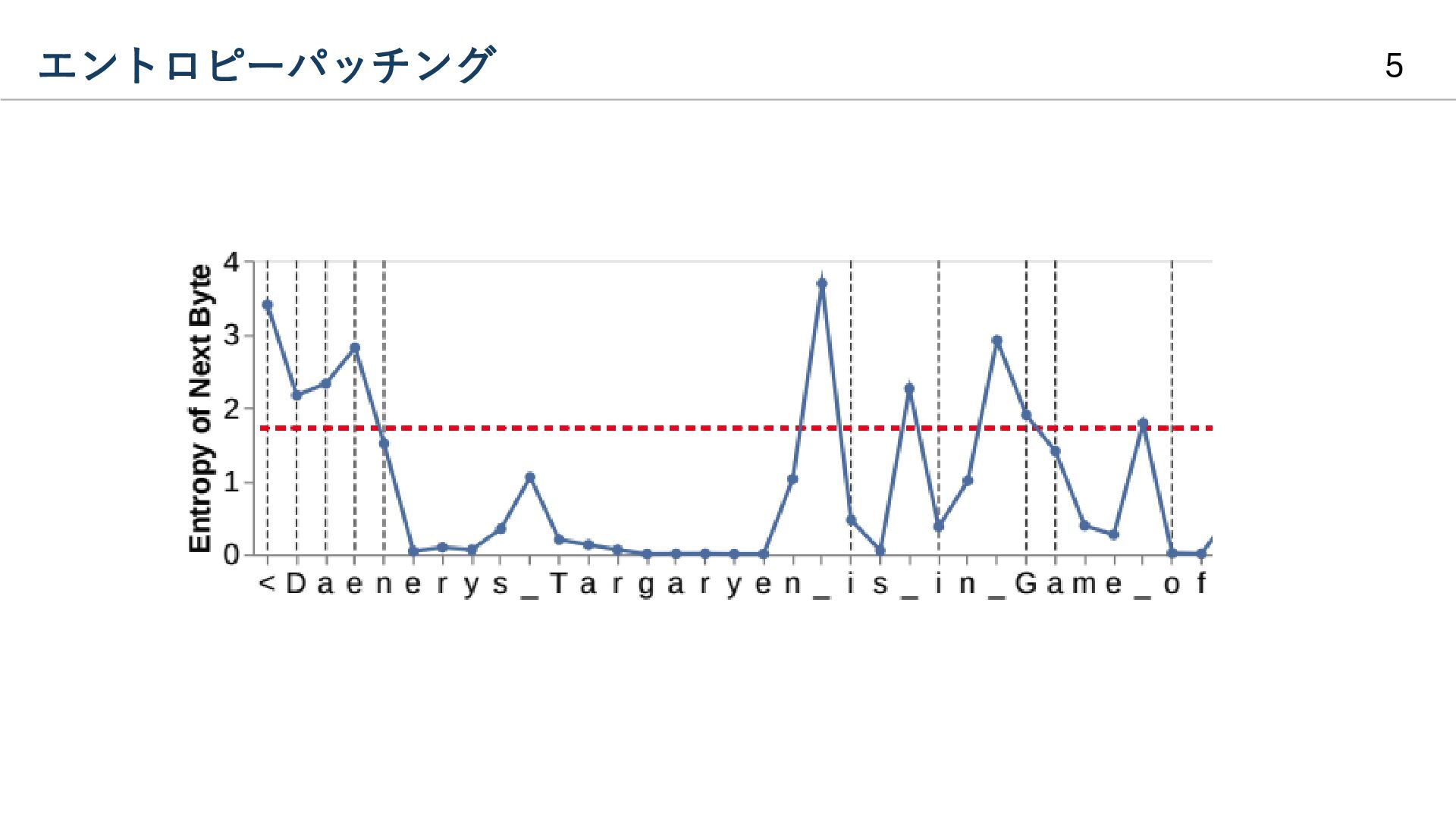{kind=link}
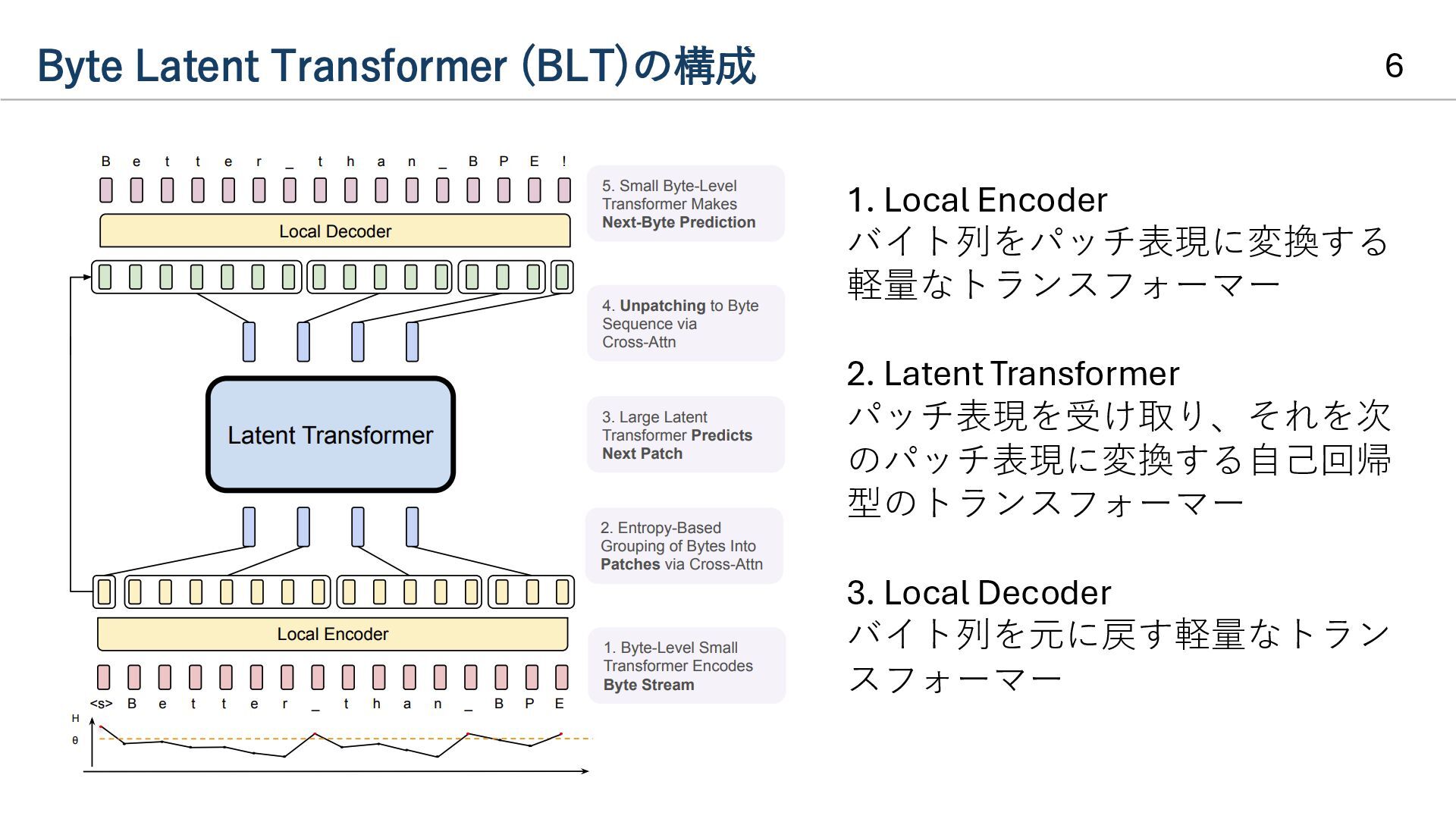{kind=link}
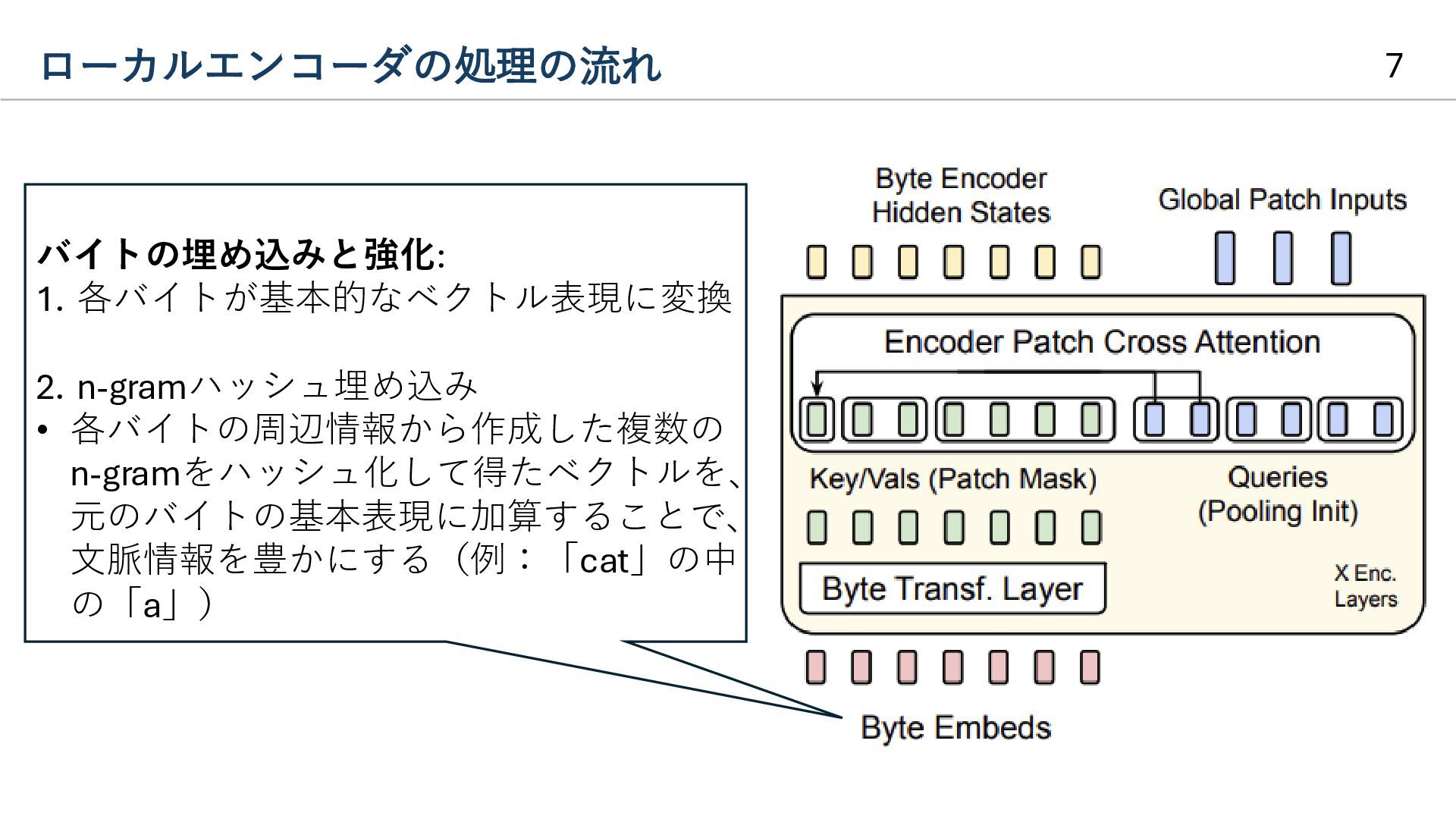{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}