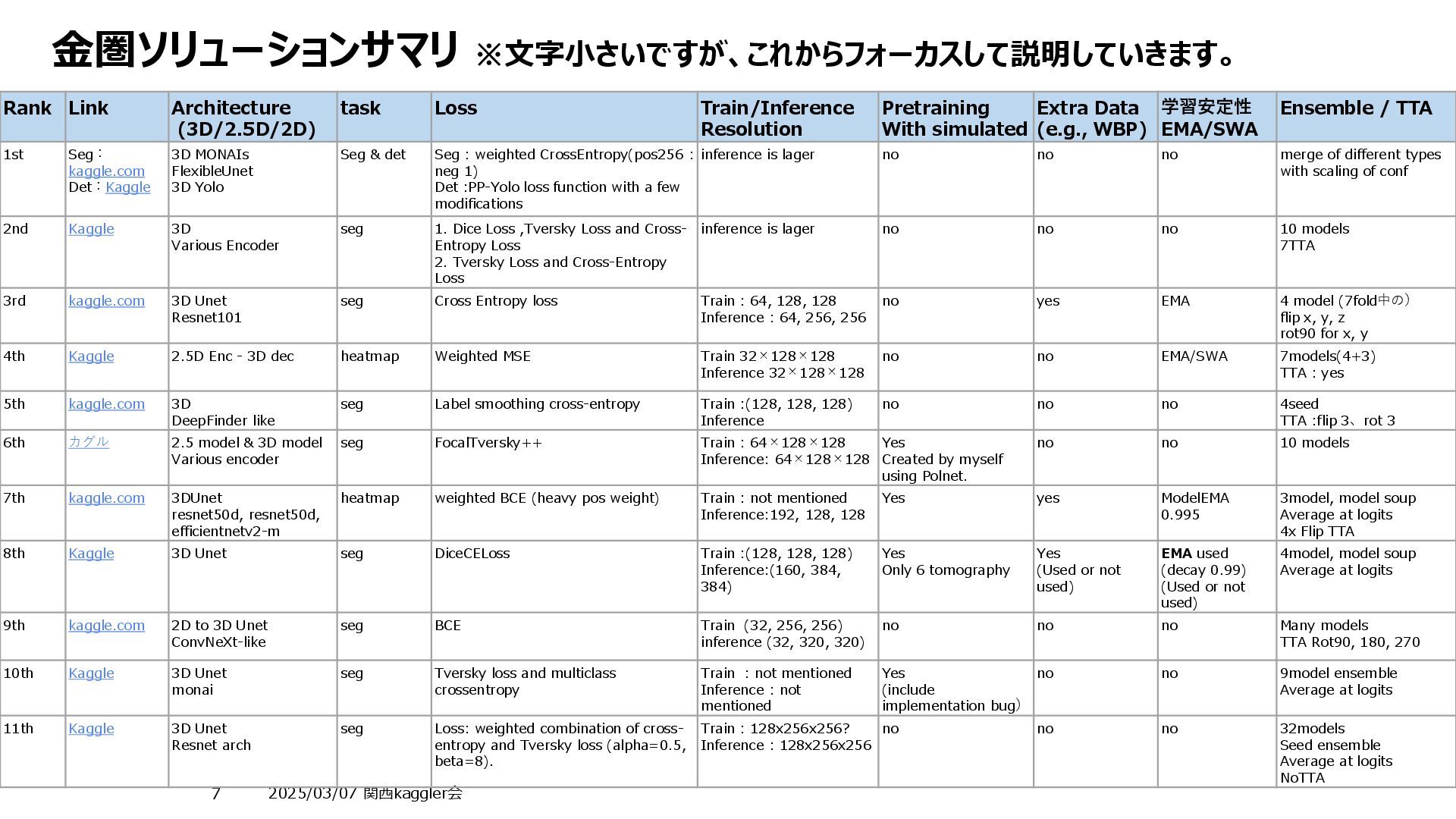
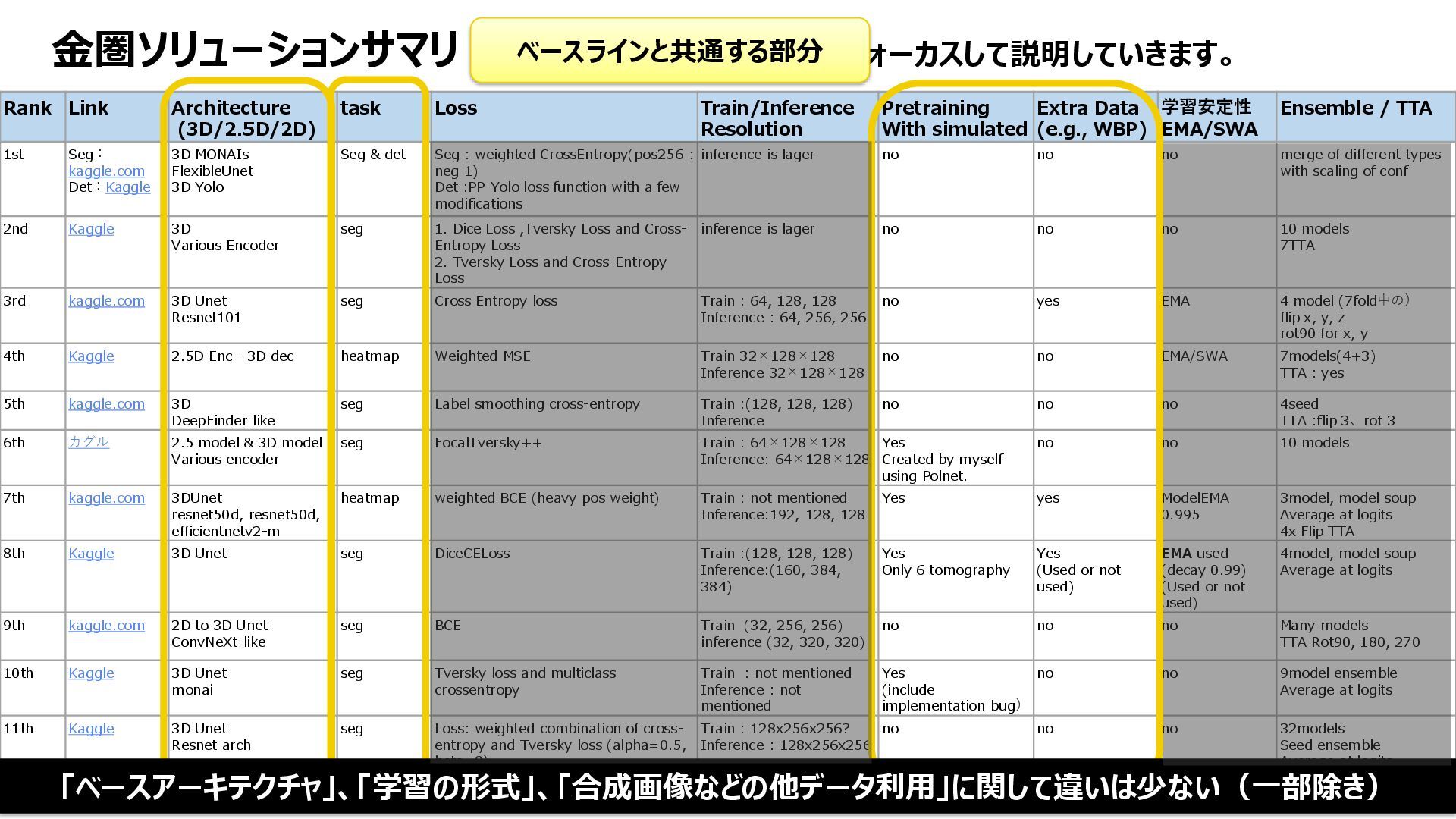
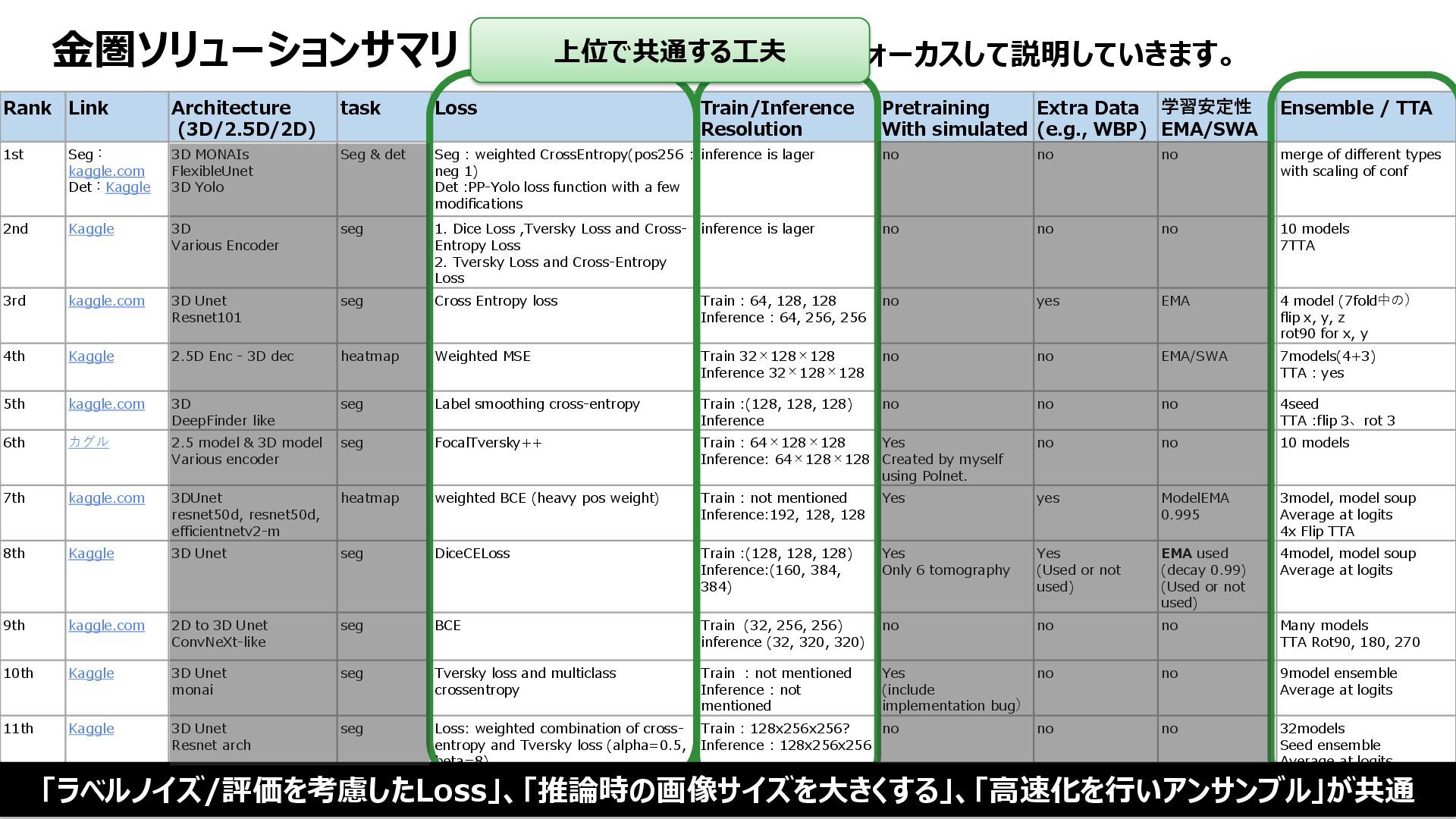
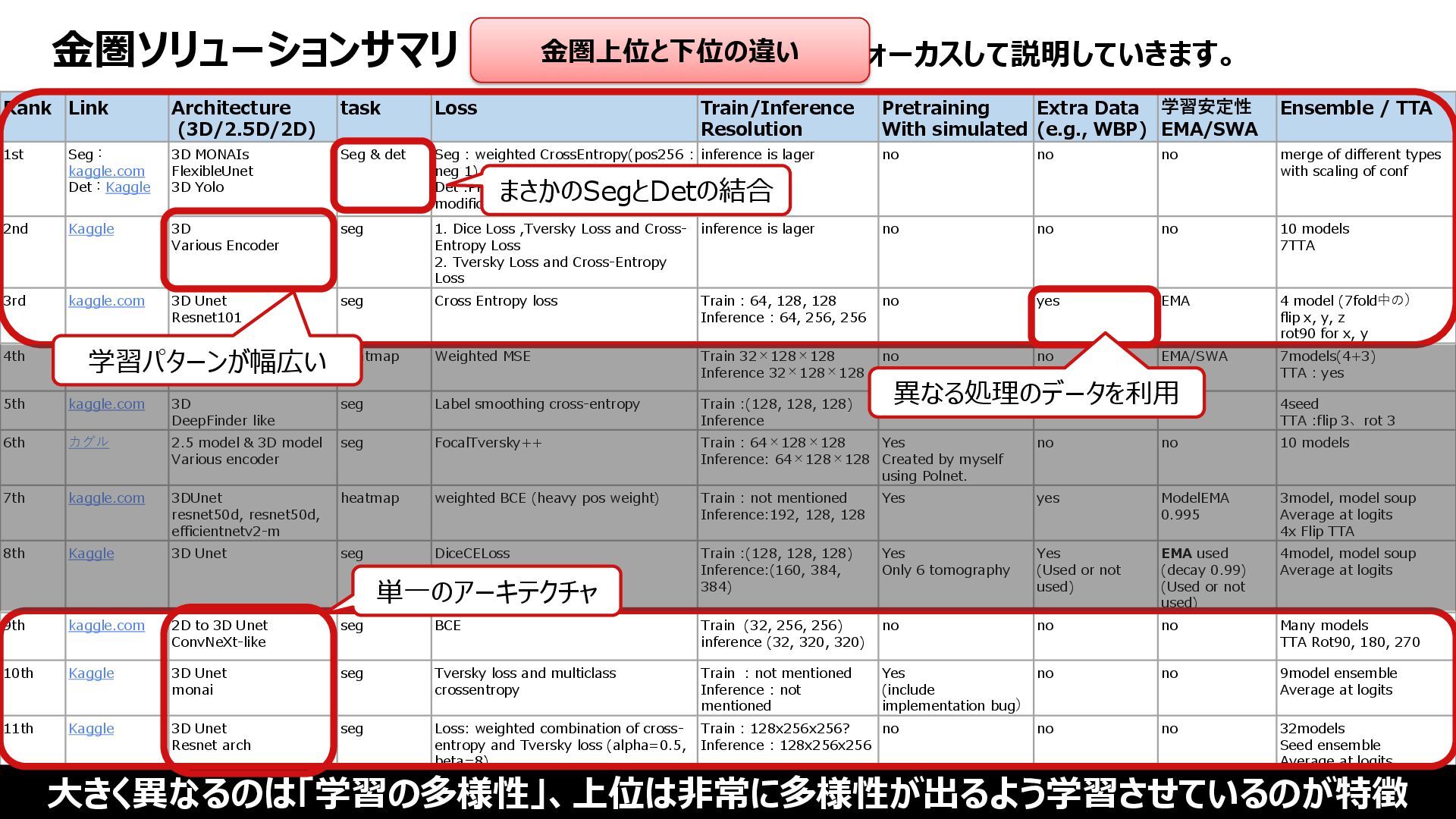
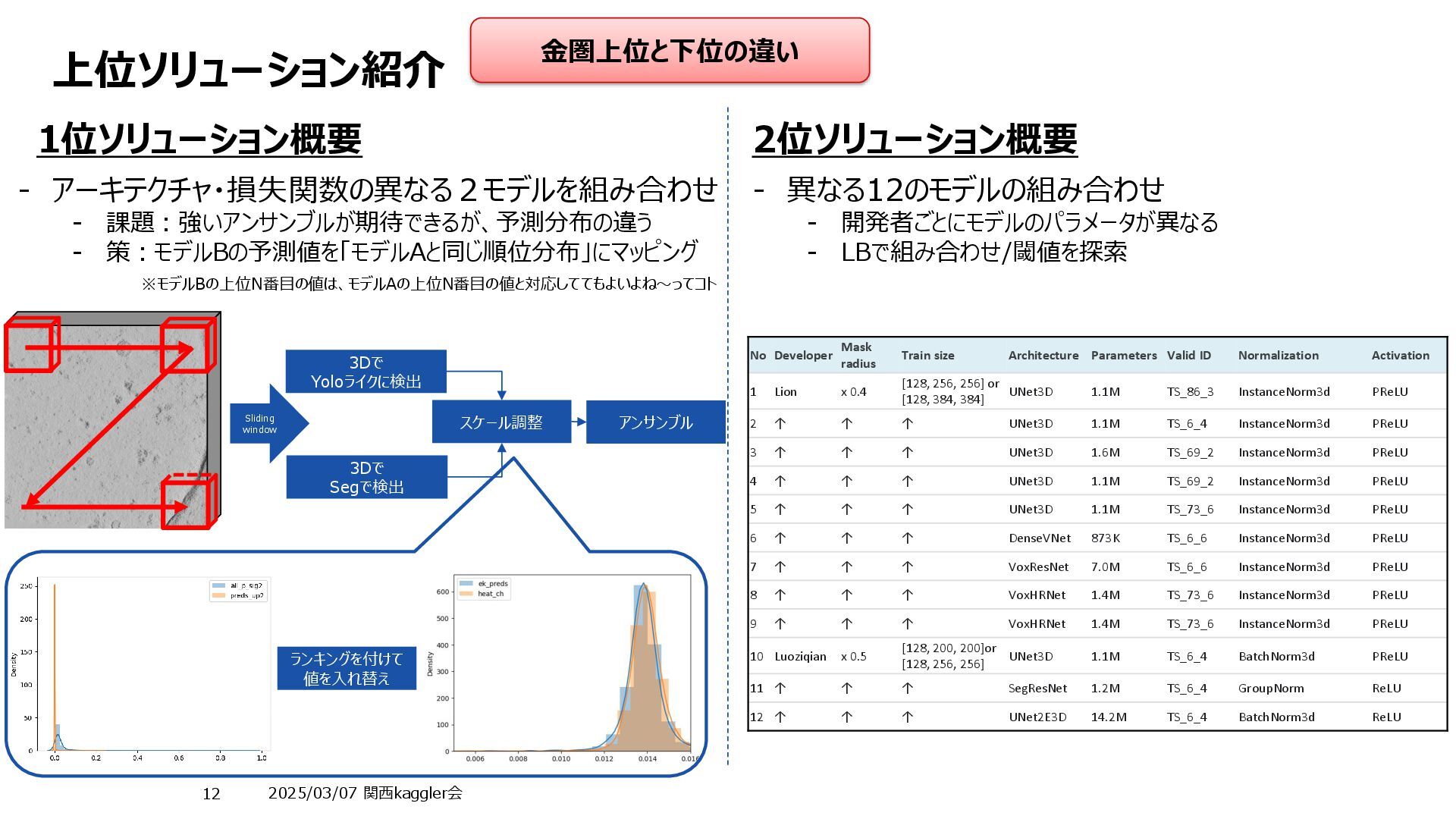
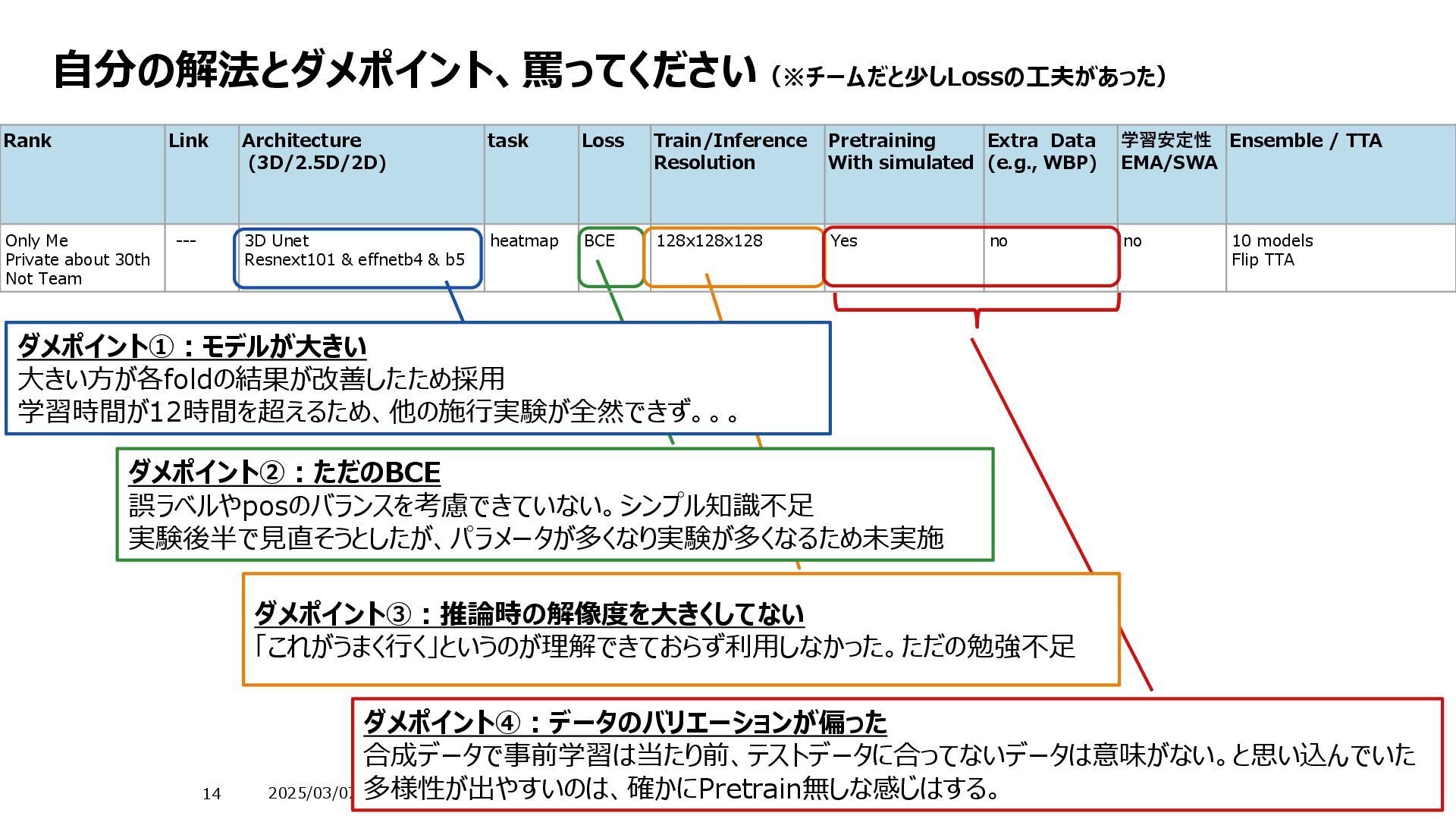
Resolution Pretraining With simulated Extra Data (e.g., WBP) 学習安定性 EMA/SWA Ensemble / TTA 1st Seg: kaggle.com Det:Kaggle 3D MONAIs FlexibleUnet 3D Yolo Seg & det Seg : weighted CrossEntropy(pos256 : neg 1) Det :PP-Yolo loss function with a few modifications inference is lager no no no merge of different types with scaling of conf 2nd Kaggle 3D Various Encoder seg 1. Dice Loss ,Tversky Loss and Cross- Entropy Loss 2. Tversky Loss and Cross-Entropy Loss inference is lager no no no 10 models 7TTA 3rd kaggle.com 3D Unet Resnet101 seg Cross Entropy loss Train : 64, 128, 128 Inference : 64, 256, 256 no yes EMA 4 model (7fold中の) flip x, y, z rot90 for x, y 4th Kaggle 2.5D Enc - 3D dec heatmap Weighted MSE Train 32×128×128 Inference 32×128×128 no no EMA/SWA 7models(4+3) TTA : yes 5th kaggle.com 3D DeepFinder like seg Label smoothing cross-entropy Train :(128, 128, 128) Inference no no no 4seed TTA :flip 3、rot 3 6th カグル 2.5 model & 3D model Various encoder seg FocalTversky++ Train : 64×128×128 Inference: 64×128×128 Yes Created by myself using Polnet. no no 10 models 7th kaggle.com 3DUnet resnet50d, resnet50d, efficientnetv2-m heatmap weighted BCE (heavy pos weight) Train : not mentioned Inference:192, 128, 128 Yes yes ModelEMA 0.995 3model, model soup Average at logits 4x Flip TTA 8th Kaggle 3D Unet seg DiceCELoss Train :(128, 128, 128) Inference:(160, 384, 384) Yes Only 6 tomography Yes (Used or not used) EMA used (decay 0.99) (Used or not used) 4model, model soup Average at logits 9th kaggle.com 2D to 3D Unet ConvNeXt-like seg BCE Train (32, 256, 256) inference (32, 320, 320) no no no Many models TTA Rot90, 180, 270 10th Kaggle 3D Unet monai seg Tversky loss and multiclass crossentropy Train : not mentioned Inference : not mentioned Yes (include implementation bug) no no 9model ensemble Average at logits 11th Kaggle 3D Unet Resnet arch seg Loss: weighted combination of cross- entropy and Tversky loss (alpha=0.5, beta=8). Train : 128x256x256? Inference : 128x256x256 no no no 32models Seed ensemble Average at logits NoTTA 金圏ソリューションサマリ ※文字小さいですが、これからフォーカスして説明していきます。 大きく異なるのは「学習の多様性」、上位は非常に多様性が出るよう学習させているのが特徴 金圏上位と下位の違い 単一のアーキテクチャ まさかのSegとDetの結合 学習パターンが幅広い 異なる処理のデータを利用
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}