search space • Elasticsearch & OpenSearch Consultant • OpenSearch Ambassador https://opensearch.org/ambassadors/ • Maintainer for the OpenSearch Kubernetes Operator • CTO & Founder of BigData Boutique https://bigdataboutique.com/ • Creator of Pulse for OpenSearch https://pulse.support/ About Me
7.10) • 100% Open Source (Apache 2.0) • Notable OpenSearch Foundation members • AI and Vector Search Ready (and improving) • Rich Ecosystem & Tools • Well Understood and Supported • Managed Service Options: AWS, Aiven, Instaclustr https://docs.opensearch.org/latest/vector-search/ai-search/index/ Why OpenSearch?
and BM25 • Fast Where it falls short: • Query has to exactly match terms in docs ◦ no semantic understanding ◦ synonyms • Scoring challenges • Can’t support AI / Agentic workloads
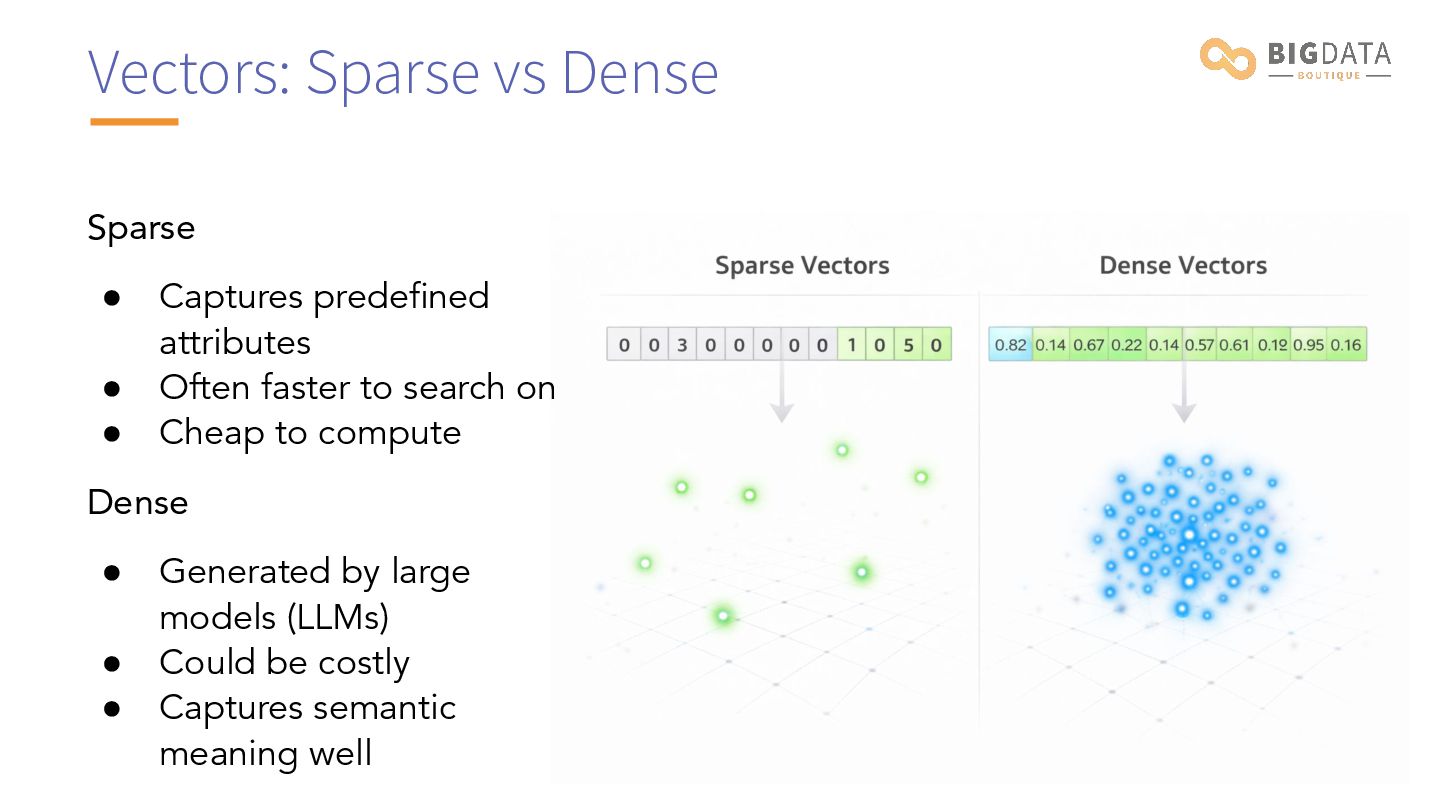
{ "affordable": 2.1, "electric": 1.9, "cars": 1.8, "vehicle": 1.3, # not in original text! "ev": 1.1, # not in original text! "cheap": 0.9, # not in original text! "price": 0.7, # not in original text! "battery": 0.5, # not in original text! "tesla": 0.3, # not in original text! } Sparse Vectors - SPLADE
LLM generates a hypothetical document: "Black holes form when massive stars exhaust their nuclear fuel and undergo gravitational collapse. When a star with a mass greater than approximately 20-25 solar masses reaches the end of its life, the core collapses under its own gravity, and if the remaining mass exceeds the Tolman-Oppenheimer-Volkoff limit, no known force can prevent complete collapse into a singularity..." Step 2 — Embed this fake document (not the original query) Step 3 — Use that embedding to search your corpus via ANN HyDE (Hypothetical Document Embeddings)
positive?" (focusing on avoiding false positives) Recall: "Of all actual positive items, how many did the search find?" (focusing on avoiding false negatives) Precision and Recall
precision • Often involves additional methods • Reciprocal Rank Fusion (RRF) to merge highly ranked results from multiple search methods (like keyword and vector search) into a single, more relevant list, giving higher importance to documents appearing high in multiple lists, making it ideal for hybrid search. • BTW, we really like Cohere Embed for text embeddings: https://bigdataboutique.com/blog/cohere-embed-4-reducing-memory-foo tprint-with-no-loss-in-search-quality-dfb1d7 Hybrid Search
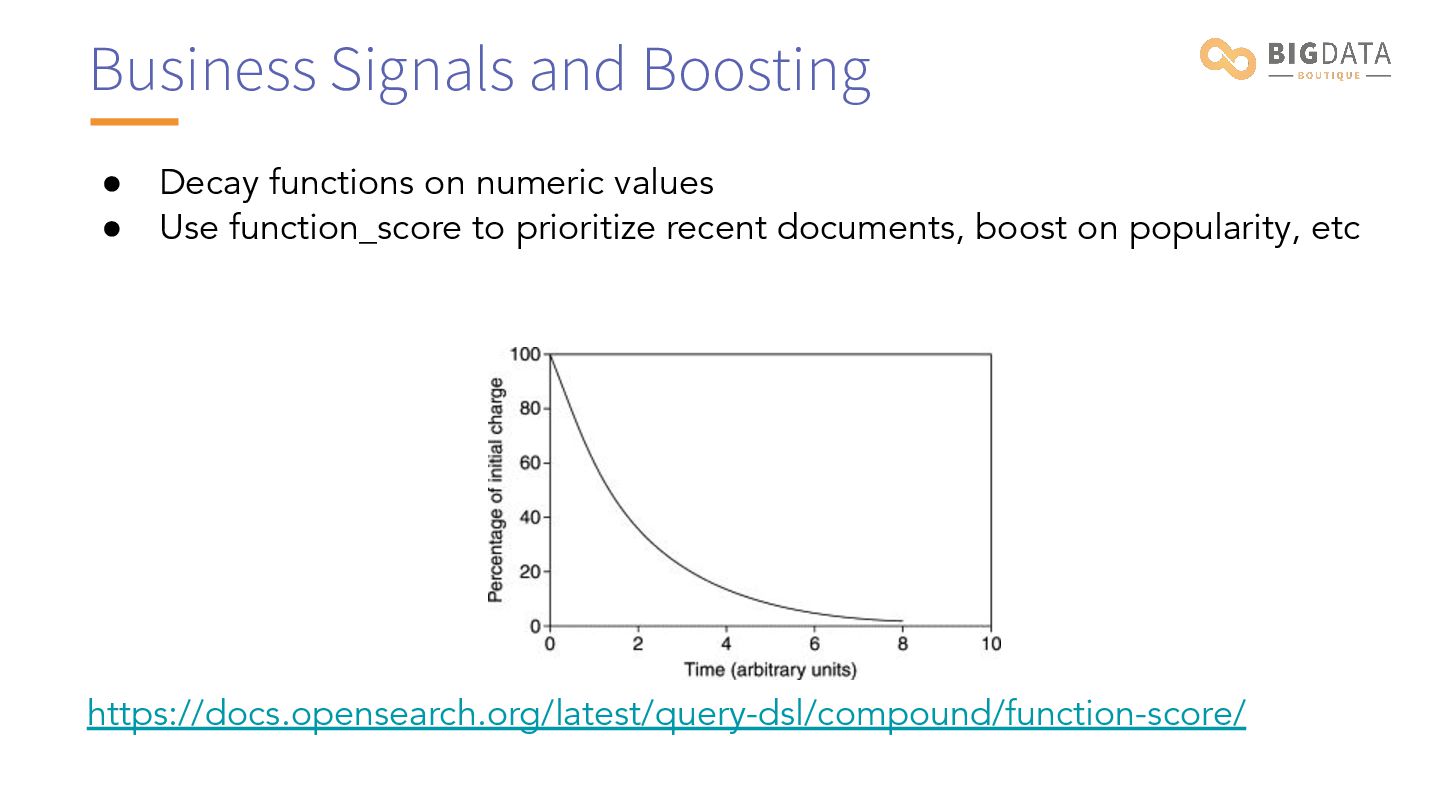
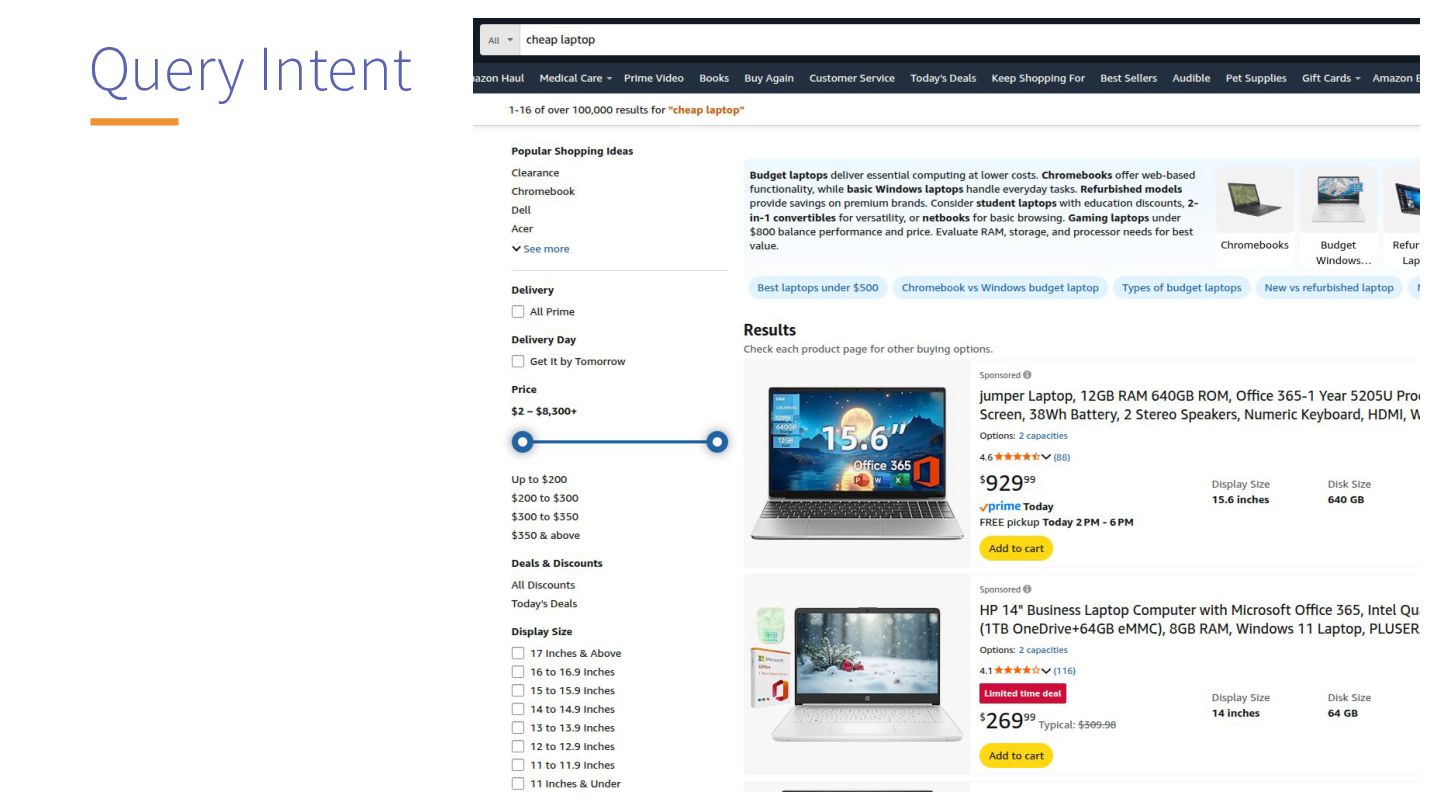
use-case would have different concerns: • Internal knowledge base (freshness, good recall metric) • eCommerce (heavy on business signals, query intent understanding)
applications • Getting started with vectors never been so easy • Use Hybrid Search and RRF • Don’t forget Relevance Evaluation • Query Intent understanding is easy to start with and highly recommended Tutorial you could follow: https://bigdataboutique.com/blog/recipes-to-vectors-using-opensearch-as-vector -database-aba607
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
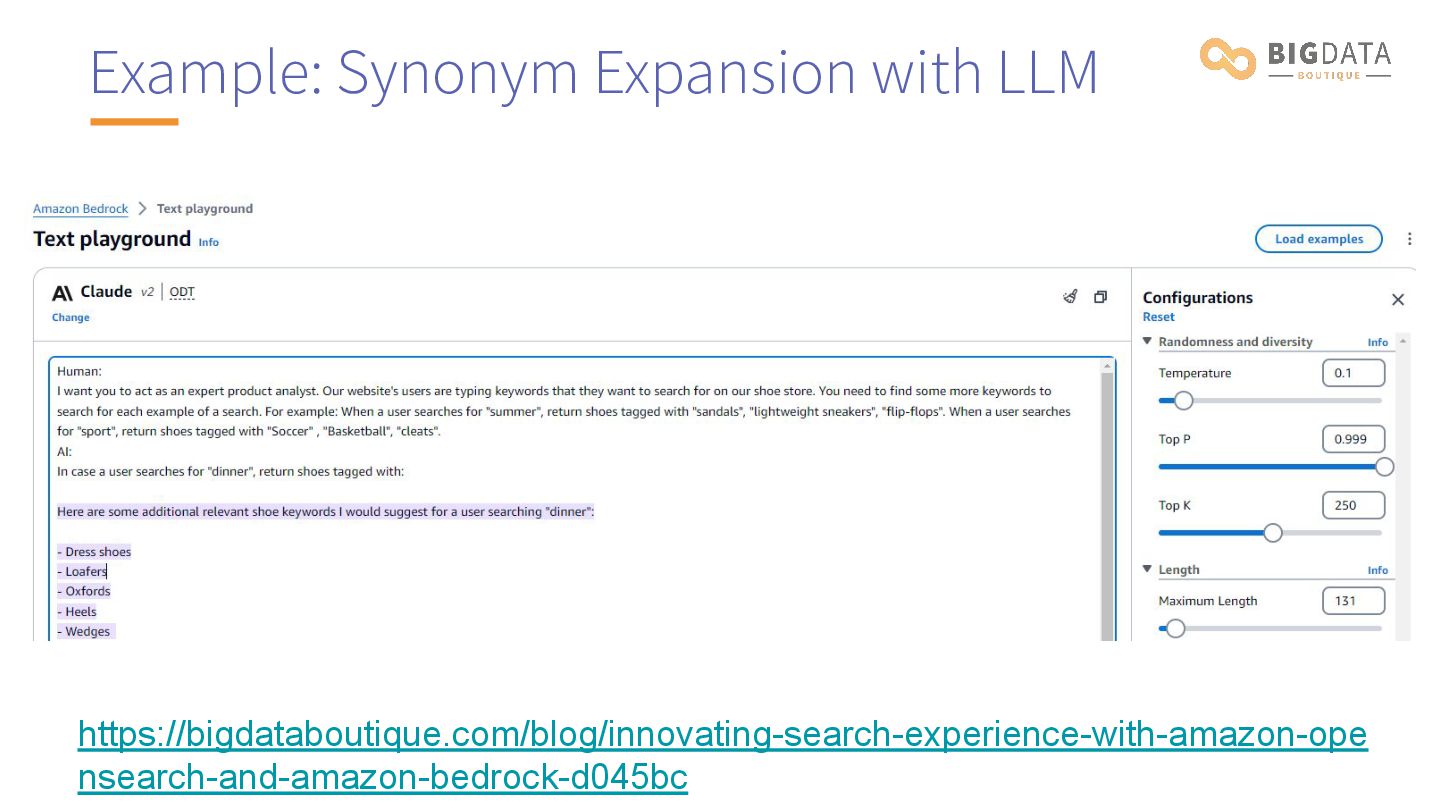{kind=link}
{kind=link}
{kind=link}
{kind=link}
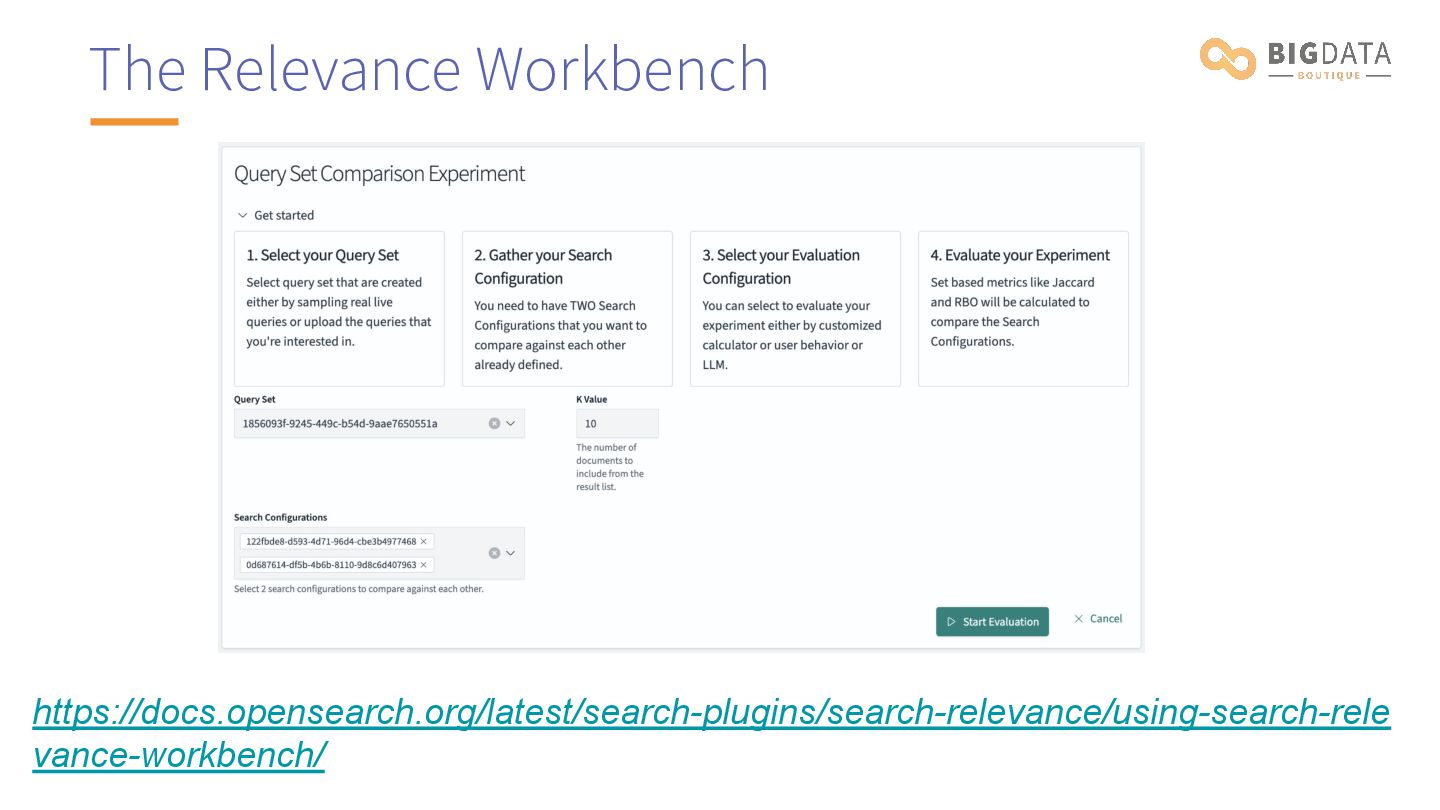{kind=link}
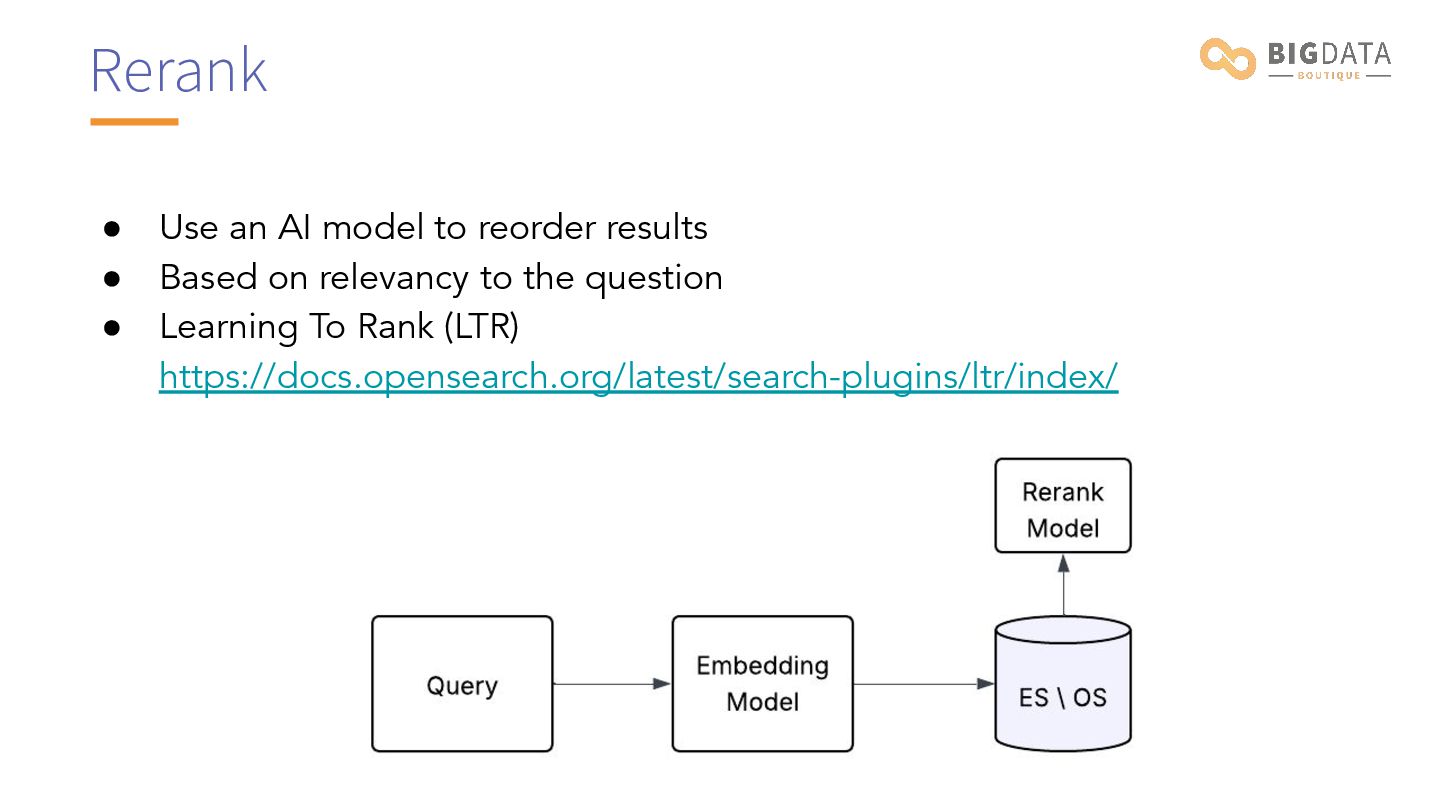{kind=link}
{kind=link}
{kind=link}
![bigdataboutique.com [email protected] Contact](https://files.speakerdeck.com/presentations/ffa7decd2fd349a8af51140288093b03/slide_32.jpg){kind=link}