Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
atmaCup#17-3rd Place Solution-
Search
syurenuko
October 17, 2024
920
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
atmaCup#17-3rd Place Solution-
atmaCup#17振り返り会(
https://atma.connpass.com/event/333637
)の発表資料です。
syurenuko
October 17, 2024
Featured
See All Featured
4 Signs Your Business is Dying
shpigford
187
22k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
230
Un-Boring Meetings
codingconduct
0
340
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Agile that works and the tools we love
rasmusluckow
331
22k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
460
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
640
Site-Speed That Sticks
csswizardry
13
1.2k
Code Reviewing Like a Champion
maltzj
528
40k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Transcript
atmaCup#17 3rd Place Solution ~初手LLMのすすめ~ @syurenuko 2024/10/17 atmaCup#17振り返り会
自己紹介 • どこかの企業の研究開発職一年目 • 大学時代の専攻:複雑系科学 • 数時間〜数日間の短期コンペが好き X:@syurenuko kaggle:kaggle.com/syurenuko atmaCup:guruguru.science/syurenuko
コンペの課題 「 おすすめされるレビューがなにか?を予測せよ!」 ユーザーの属性と商品に対するレビューのデータから、その商品がおすすめされたかどうかを2値分類で予測する 開催期間2024/8/29 18:00〜2024/8/31 18:00(48時間) 評価指標ROC-AUC train.csv/test.csv •
Clothing ID: 衣服のID • Age: レビューをしている人の年齢 • Title: レビューのタイトル • Review Text: レビューの本文 • Rating: レビューでつけた点数。 train.csvのみ提供 • Positive Feedback Count: 他のユーザーからつけられたイイネの数。 • Recommended IND: 予測対象。レビューした人が、この商品をおすすめするかどうかを予測する。 clothing_master.csv • Clothing ID: 衣服のID。train.csvとtest.csv の Clothing ID と紐付けられる。 • DIvision/Department/Class Name: 衣服のカテゴリ。右に行くほど細かいカテゴリ。
3位解法 概要 Gemma2-9B(instruction tuning)・Llama3.1-70B(instruction tuning)・Qwen2-72B 4bit量子化されたモデルを QLoRAでFine-Tuning(SequenceClassification) 15モデルの予測値を加重平均でアンサンブル CV戦略 KFold(1fold)で精度確認→Full
Train(All Data) でepoch数を決め打ちで学習 5fold回さないと完全なoof予測値が得られない等のデメリットがあるが、48時間しか無いので今回は試行回数を優先した 基本的に1epochで十分な精度が出ていた テキスト処理 Clothing ID + Age + Title + Review Text + Positive Feedback Count(clothing_master.csvは未使用) 実行環境 vast.aiでGPUインスタンスをレンタル 3rd Place Solution(atmaCup#17 discussion ) https://www.guruguru.science/competitions/24/discussions/f312bbe9-453b-4500-a5d2-2d250f519773 ※Qwen2-72Bがinstruction tuningモデルではないのは model pathを間違えたからです。
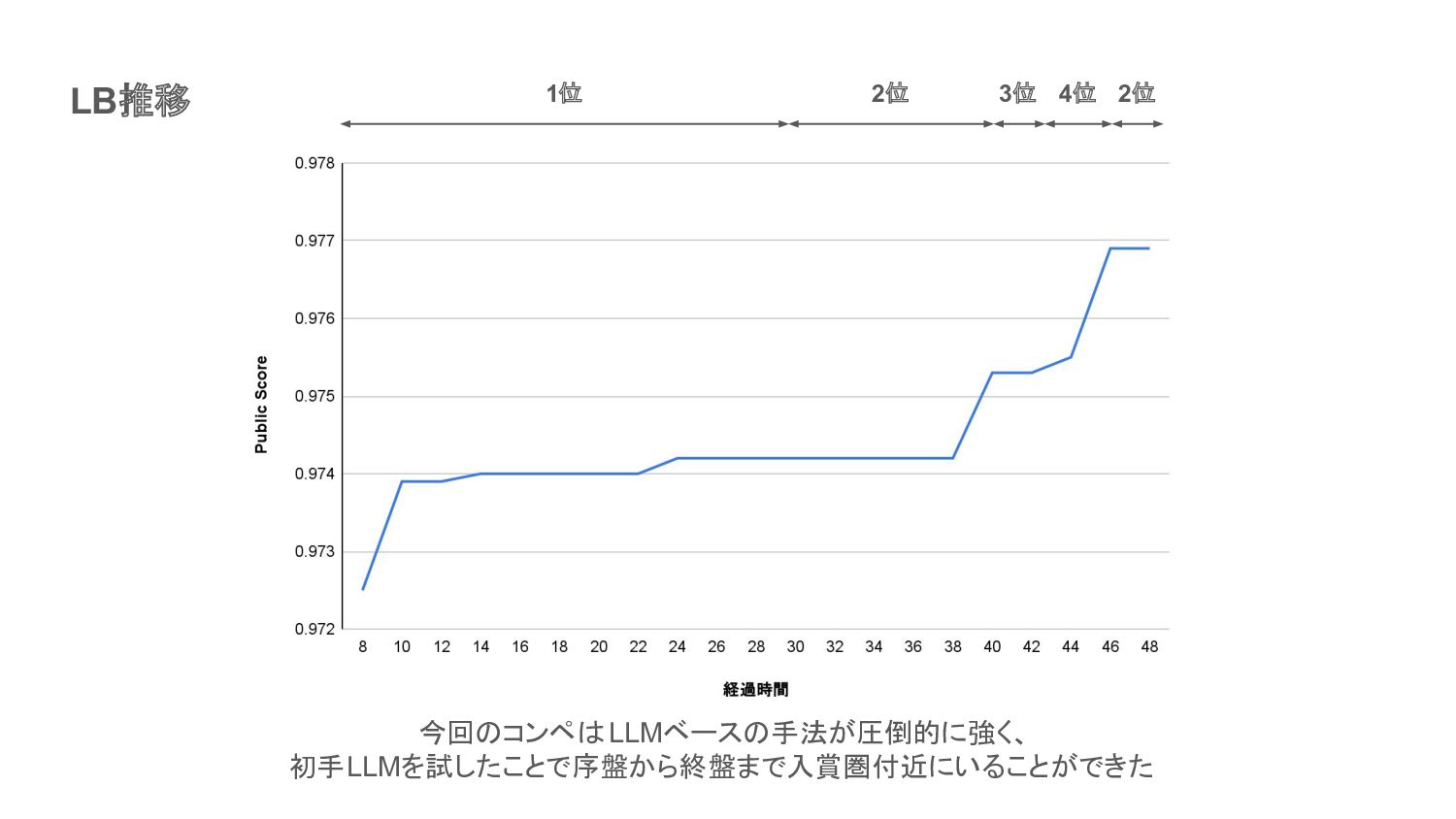
LB推移 今回のコンペはLLMベースの手法が圧倒的に強く、 初手LLMを試したことで序盤から終盤まで入賞圏付近にいることができた 1位 2位 3位 4位 2位
取り組みの特徴 1. 初手DeBERTaを選択せず、最初から最後までLLM 2. 70B(700億)パラメータのLLMをFine-Tuning
なぜ初手LLMを選択したのか?
なぜ初手LLMを選択したのか?① 2023年秋にkaggle GrandmasterのPsiの投稿を見た Google翻訳(一部抜粋): 最近のコンテストやプロジェクトで私が最も 驚いたのは、分類や回帰などの古典的なタ スクに対して LLM が実際にどれほどうまく 微調整できるかということでした。
私たちの 実験では、 LLM は常に Deberta モデルを 上回るか、それを補完することができまし た。 https://x.com/ph_singer/status/1716444775333712143?s=46&t=b7W2--TQhCyHpdXdr5hFCA 2023/10/23 @ph_singer
Google翻訳: Roberta/Deberta は、そのサイズからす ると依然として素晴らしいものです。しか し、LLM は分類に関しては私が考えて いたよりもはるかに優れています。 実 際、最近の Kaggle
コンテストでは、分類 と回帰の LLM が優勝しています。副次 的な利点は、デコーダーによるキャッシュ です。 https://x.com/ph_singer/status/1727437419514098082?s=46&t=b7W2--TQhCyHpdXdr5hFCA 2023/11/23 @ph_singer
なぜ初手LLMを選択したのか?② LMSYSコンペの上位解法がLLMで占めていた https://www.kaggle.com/competitions/lmsys-chatbot-arena
初手LLMで取り組んだこと
5つのカラムを結合し、テキスト化 <bos><Clothing ID>: Clothing ID\n\n<Age>: Age\n\n<Title>: Title\n\n<Review Text>: Review Text\n\n<Positive
Feedback Count>: Positive Feedback Count<eos>
モデル選択 unslothの軽量モデル(unsloth/gemma-2-9b-it-bnb-4bit)を使用 unslothとは? • LLMのFine-Tuningを高速かつ省メモリで行うことができるライブラリ • 量子化されたモデルを直接ロードするので高速でメモリ効率に優れている • HuggingFaceと互換性アリ https://unsloth.ai
gemma2-9b • Googleが開発した最新のローカル LLM(2024年10月時点) • 9B(90億)のパラメータを持つ it • instruction tuning(指示チューニング)されたモデル
• ベースモデルが特定のタスクや指示に対応できるように調整されている • 今回のコンペではベースモデルよりも instruction tuningモデルの方が精度が良かった bnb-4bit • bitsandbytes(bnb)によって4bitの精度で量子化されているモデル • 量子化により高速化と省メモリを実現 gemma-2-9b-it-bnb-4bit
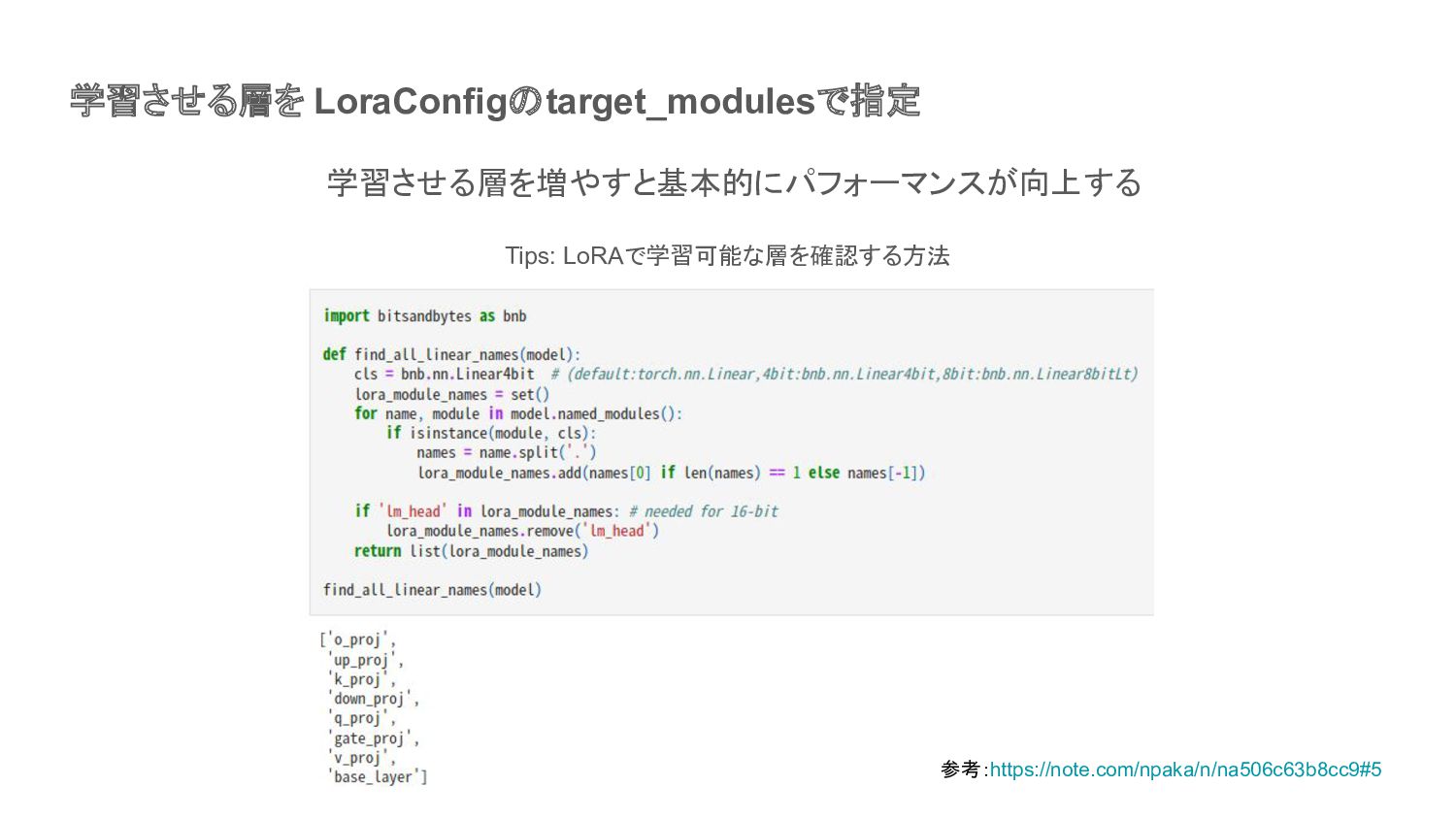
学習させる層を LoraConfigのtarget_modulesで指定 参考:https://note.com/npaka/n/na506c63b8cc9#5 Tips: LoRAで学習可能な層を確認する方法 学習させる層を増やすと基本的にパフォーマンスが向上する
学習&推論 Full Train(1epoch)の学習は約40分で完了、消費されるVRAMは10GB弱 テストデータの推論にかかった時間は約10分 vast.aiでRTX3090をレンタル(一時間あたり0.25~0.30$くらい) (途中からRTX3090→RTX4090に変えると学習と推論にかかる時間が約半分になった)
初手LLMの結果 開始8時間時点でLBトップ Private最終6位相当のスコアがsingle modelで出る
9Bでこのスコア!? じゃあパラメータ数の多いLLMを使ったらもっとスコア上がるのでは? ワクワク
9Bでこのスコア!? じゃあパラメータ数の多いLLMを使ったらもっとスコア上がるのでは? ※結論:初手のGemma2-9Bよりスコア出ませんでした ワクワク
700億パラメータのLLMをFine-Tuningする
700億パラメータの LLMをFine-Tuningする 選ばれたモデル • unsloth/Meta-Llama-3.1-70B-Instruct-bnb-4bit • unsloth/Qwen2-72B-Instruct-bnb-4bit • unsloth/Qwen2-72B-bnb-4bit ※Qwen2-72Bのinstruction
tuningモデルを選択したつもりでしたがmodel pathを間違えてベースモデルを使用
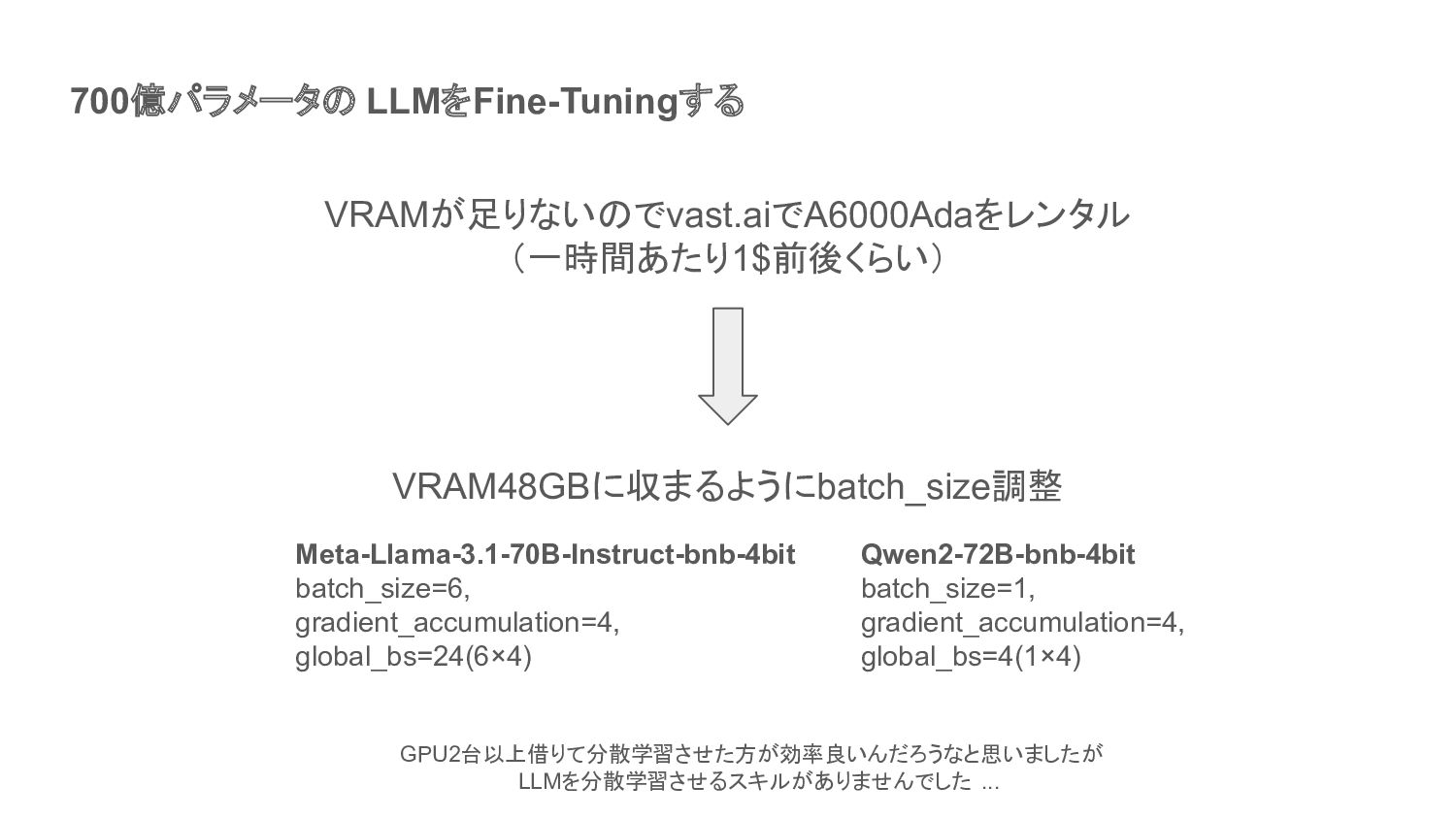
700億パラメータの LLMをFine-Tuningする VRAMが足りないのでvast.aiでA6000Adaをレンタル (一時間あたり1$前後くらい) VRAM48GBに収まるようにbatch_size調整 GPU2台以上借りて分散学習させた方が効率良いんだろうなと思いましたが LLMを分散学習させるスキルがありませんでした ... Meta-Llama-3.1-70B-Instruct-bnb-4bit batch_size=6,
gradient_accumulation=4, global_bs=24(6×4) Qwen2-72B-bnb-4bit batch_size=1, gradient_accumulation=4, global_bs=4(1×4)
700億パラメータの LLMをFine-Tuningした結果 Lllama3.1-70Bの学習速度の速さに驚いた(逆に Qwen2が遅い?) Meta-Llama-3.1-70B-Instruct-bnb-4bit 0.9736 0.9758 約3時間 Qwen2-72B-bnb-4bit 0.9734 0.9748 約10時間
(参考)gemma-2-9b-it-bnb-4bit 0.9739 0.9774 約40分 Qwen2-72B-Instruct-bnb-4bit 0.9742 0.9767 約10時間 コンペ期間中に試せなかった Qwen2-72Bのinstruction tuningモデルのlate sub検証結果 Public Private 学習時間
なぜパラメータ数を増やしても精度が伸びなかったのか? ※あくまで個人の考察です • パラメータ数が少なくても十分な精度が出る課題だった →LB全体のROC-AUCスコアが0.9後半と高めで、タスクの難しさが低めだったと考えられる →パラメータ数が増えることの恩恵があまりない? • 量子化やLoRAの低ランク近似によるFine-Tuningでは本来の性能を引き出すのが難しい? →高速化と省メモリの恩恵がある一方で、精度や学習の安定性とトレードオフの関係になりやすい →(現実的ではないが)フルパラメータで
Fine-Tuningしたら結果は変わるかも • 純粋に自分自身のLLM力が足りていない...? →今後の課題
実験結果まとめ • LLMは全体的に強かった • どのモデルもinstraction tuningモデルの方が精度が高かった • パラメータ数を増やせば必ず精度が上がるわけではない • 短期コンペでも700億パラメータのFine-Tuningを回しきれる!
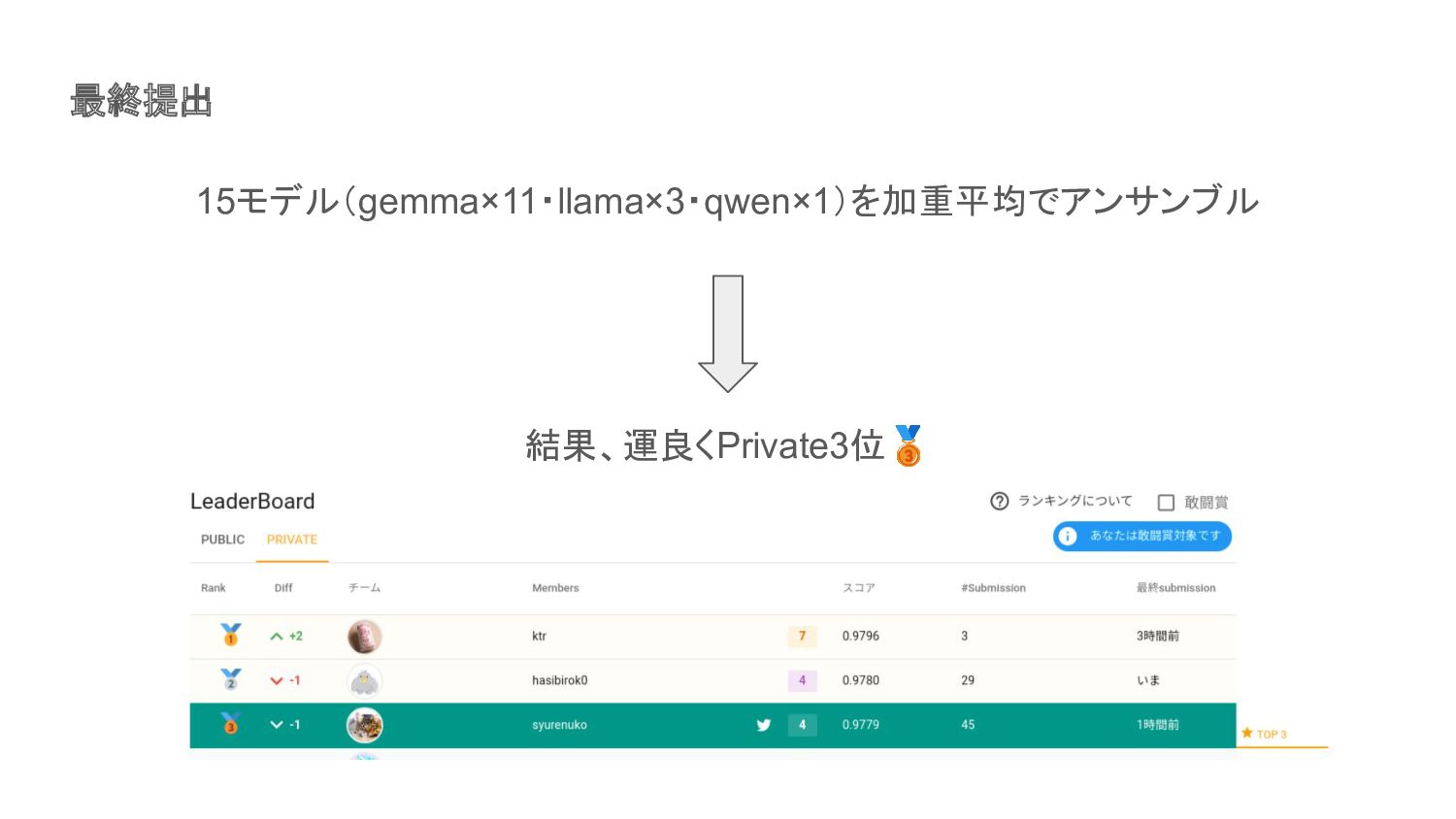
最終提出 15モデル(gemma×11・llama×3・qwen×1)を加重平均でアンサンブル 結果、運良くPrivate3位🥉
late sub検証:量子化によるスコア低下があるのか調べる unsloth/gemma-2-9b-it-bnb-4bit(量子化あり) 0.9739 0.9774 google/gemma-2-9b-it(量子化なし) 0.9754 0.9781 Public Private
(モデル以外の条件を同じにして検証) 量子化なしの方がスコアが良い結果
今回のコンペ最大の謎 なぜLLMがDeBERTaよりも強かったのか?
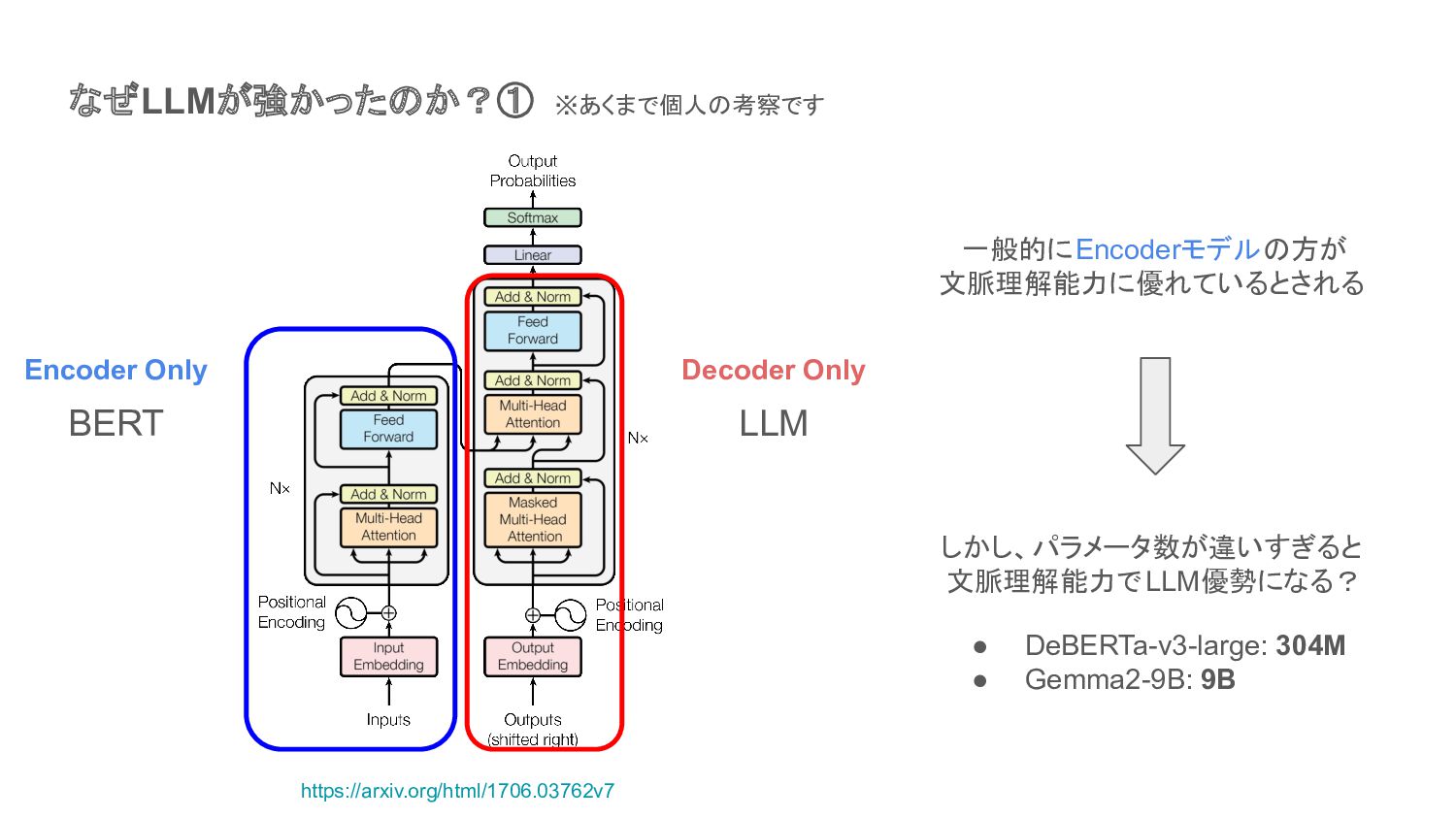
なぜLLMが強かったのか?① ※あくまで個人の考察です https://arxiv.org/html/1706.03762v7 Encoder Only BERT Decoder Only LLM 一般的にEncoderモデルの方が
文脈理解能力に優れているとされる しかし、パラメータ数が違いすぎると 文脈理解能力でLLM優勢になる? • DeBERTa-v3-large: 304M • Gemma2-9B: 9B
なぜLLMが強かったのか?② ※あくまで個人の考察です 今回のコンペのデータがLLMの事前学習データに含まれているのでは? https://atma.connpass.com/event/333637 atmaCup#17のconnpass上でのイベント募集ページ
コンペ終了後に投稿された discussion (@chikuwabu_qedさん) https://www.guruguru.science/competitions/24/discussions/d57bc416-56fa-454a-a071-743597b29293 • 約7年前にkaggle上で公開されたWomen's E-Commerce Clothing Reviews データ
セットが元データ? • 2016年頃のスクレイピングデータ (=web上に実際に存在したデータ) クローリングされた元データが LLMの 事前学習データに含まれているのでは?
感想 atmaCup運営の皆様ありがとうございました! • 700億パラメータのLLMを個人でFine-Tuningする良い経験ができた • 高速化やメモリ効率の重要性を身にしみて感じた • 今回のコンペをきっかけにLLMに対する興味が増した • 時間制約がシビアな短期コンペは楽しい!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}