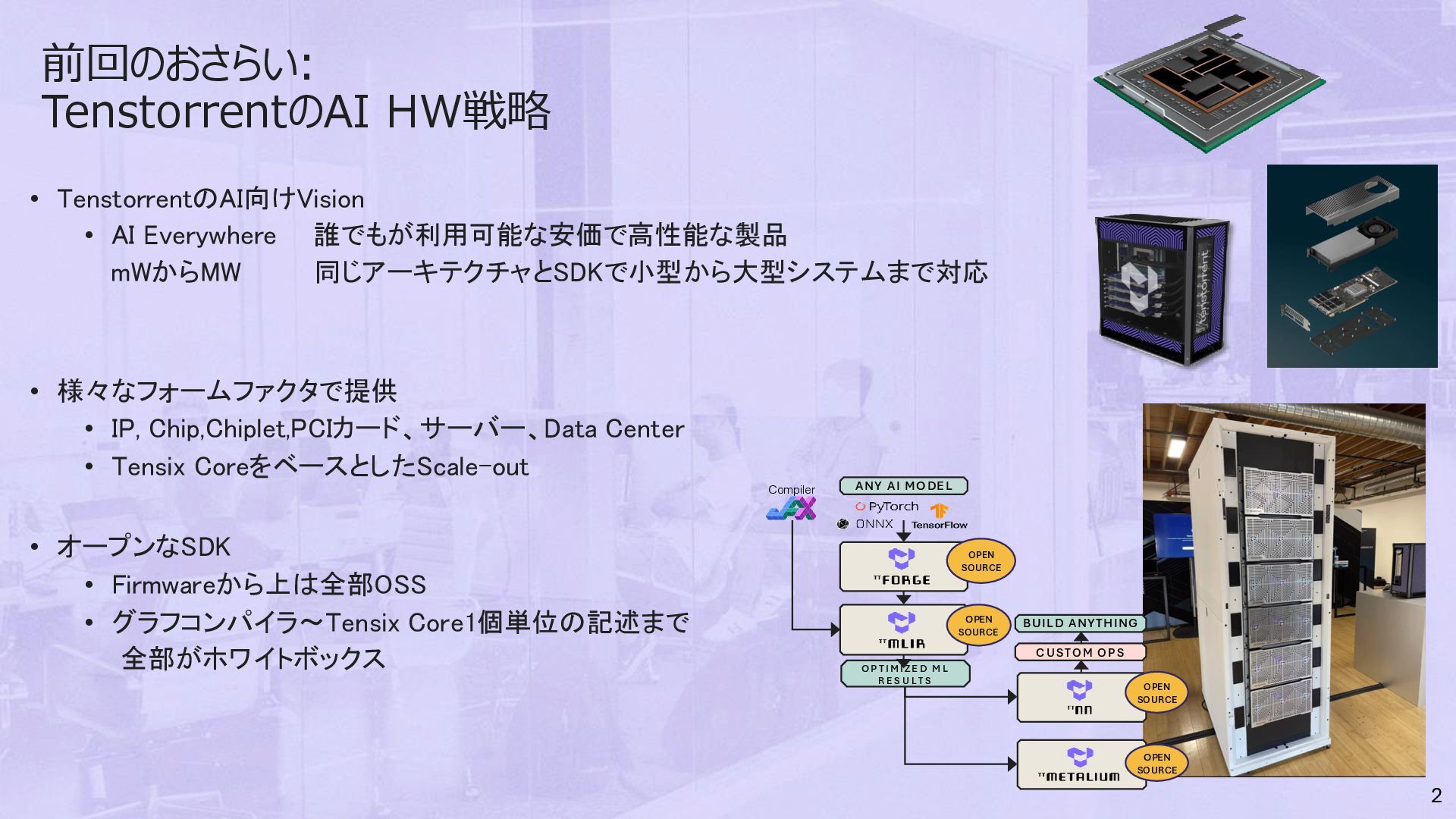
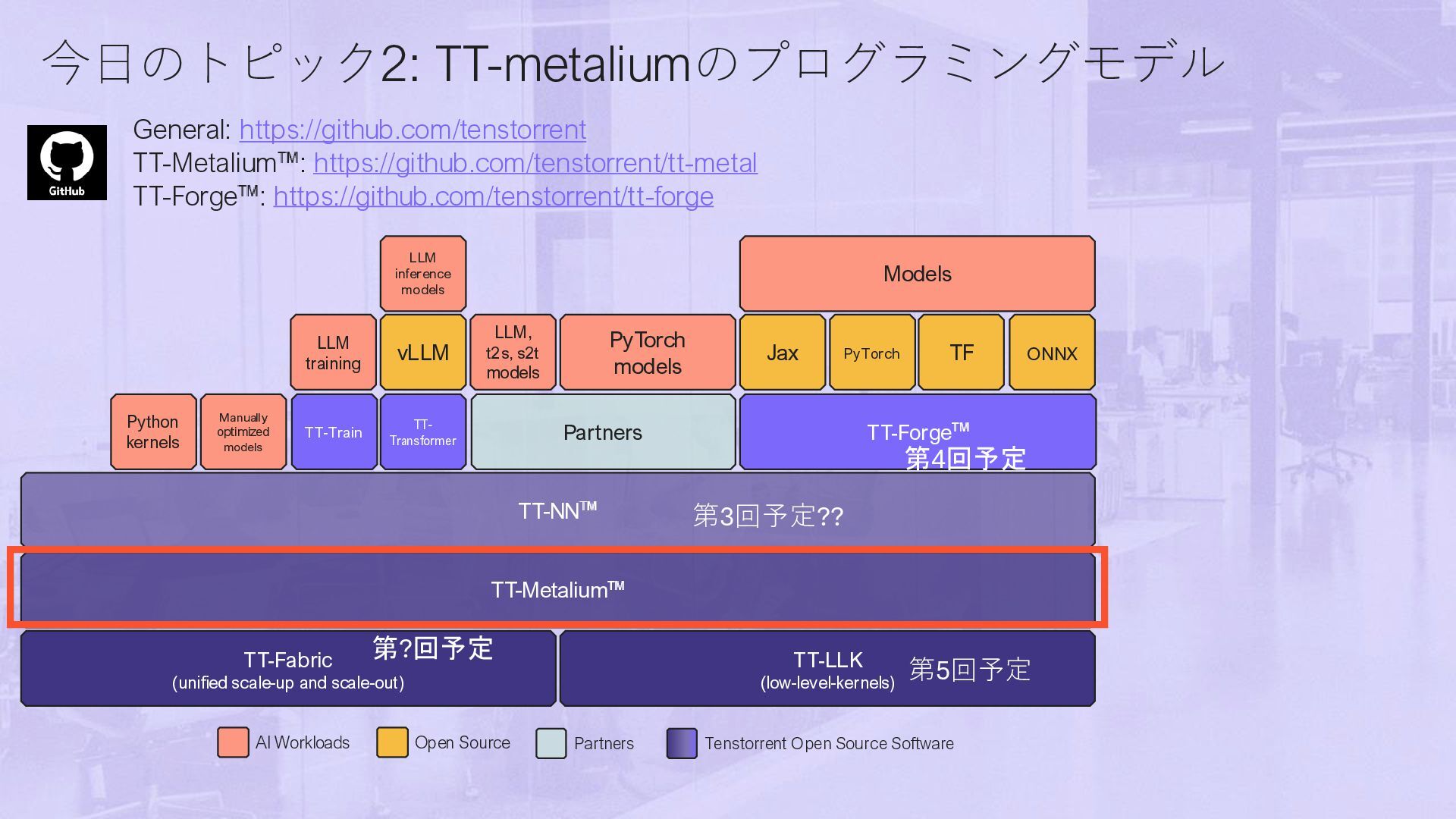
同じアーキテクチャとSDKで小型から大型システムまで対応 • 様々なフォームファクタで提供 • IP, Chip,Chiplet,PCIカード、サーバー、Data Center • Tensix CoreをベースとしたScale-out • オープンなSDK • Firmwareから上は全部OSS • グラフコンパイラ〜Tensix Core1個単位の記述まで 全部がホワイトボックス 2 ANY AI MO DE L OPEN SOURCE OPEN SOURCE O P T I M I ZE D M L R E S U L T S CUSTOM OPS BUILD ANYTHING OPEN SOURCE OPEN SOURCE Compiler
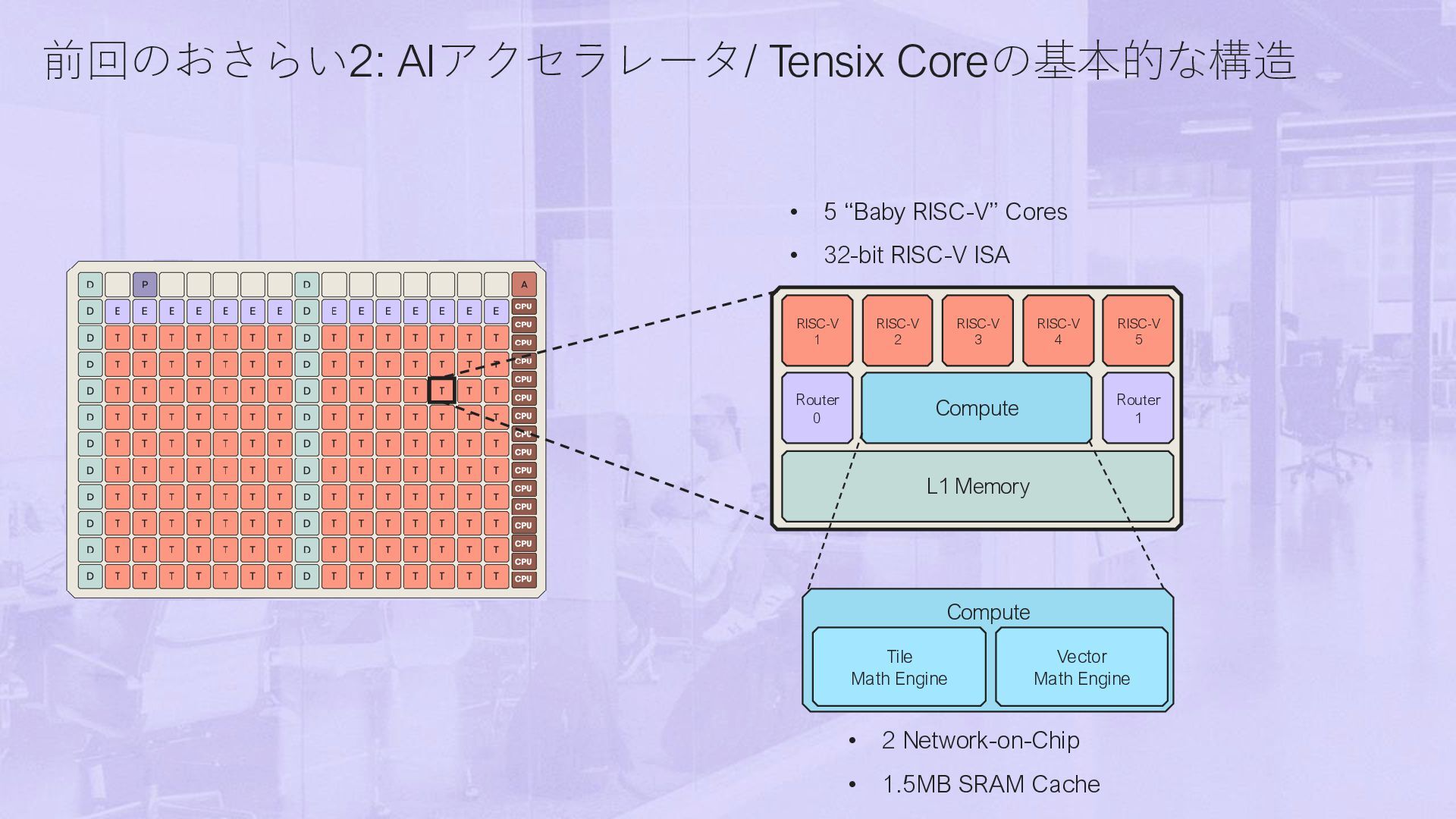
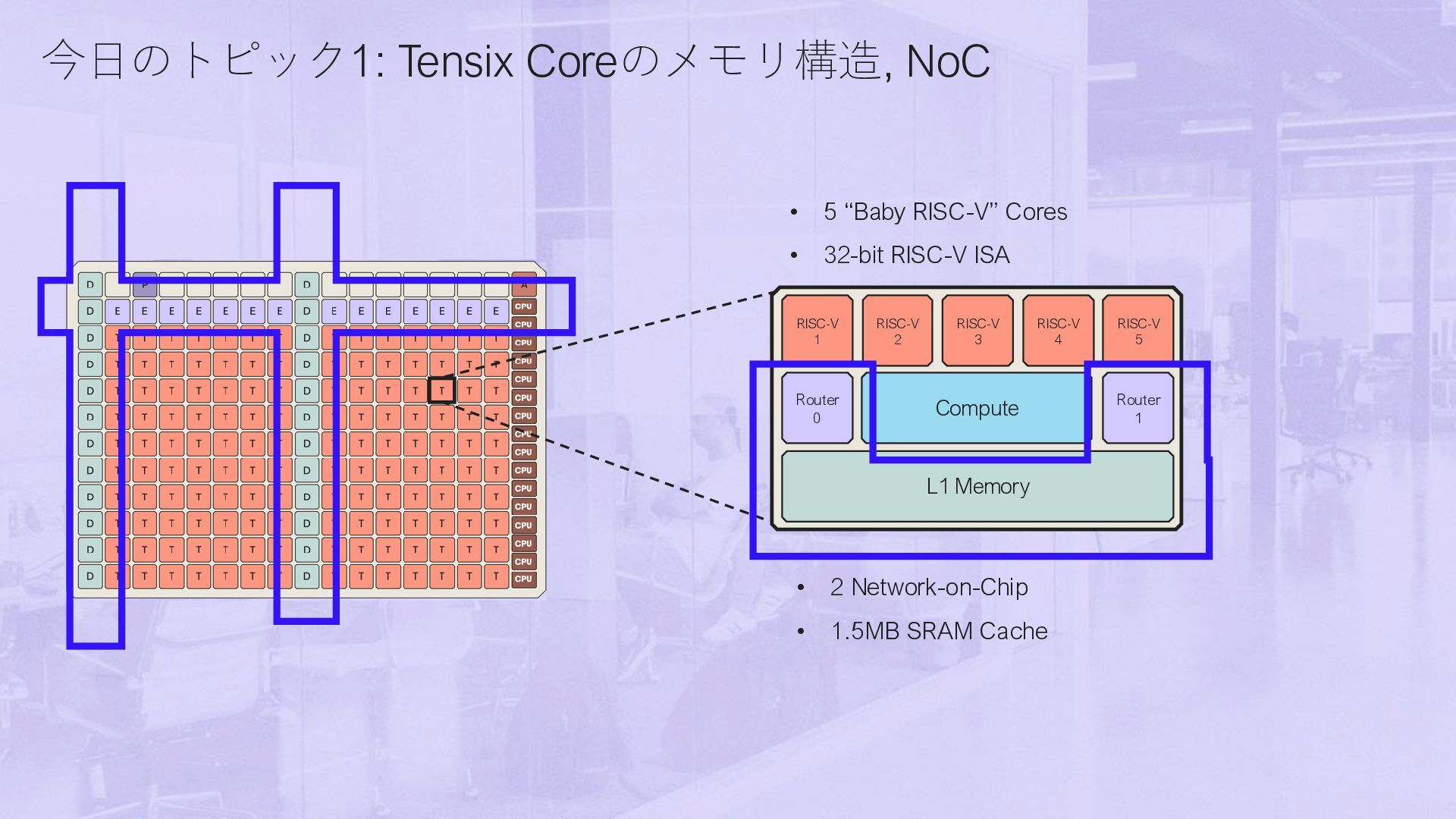
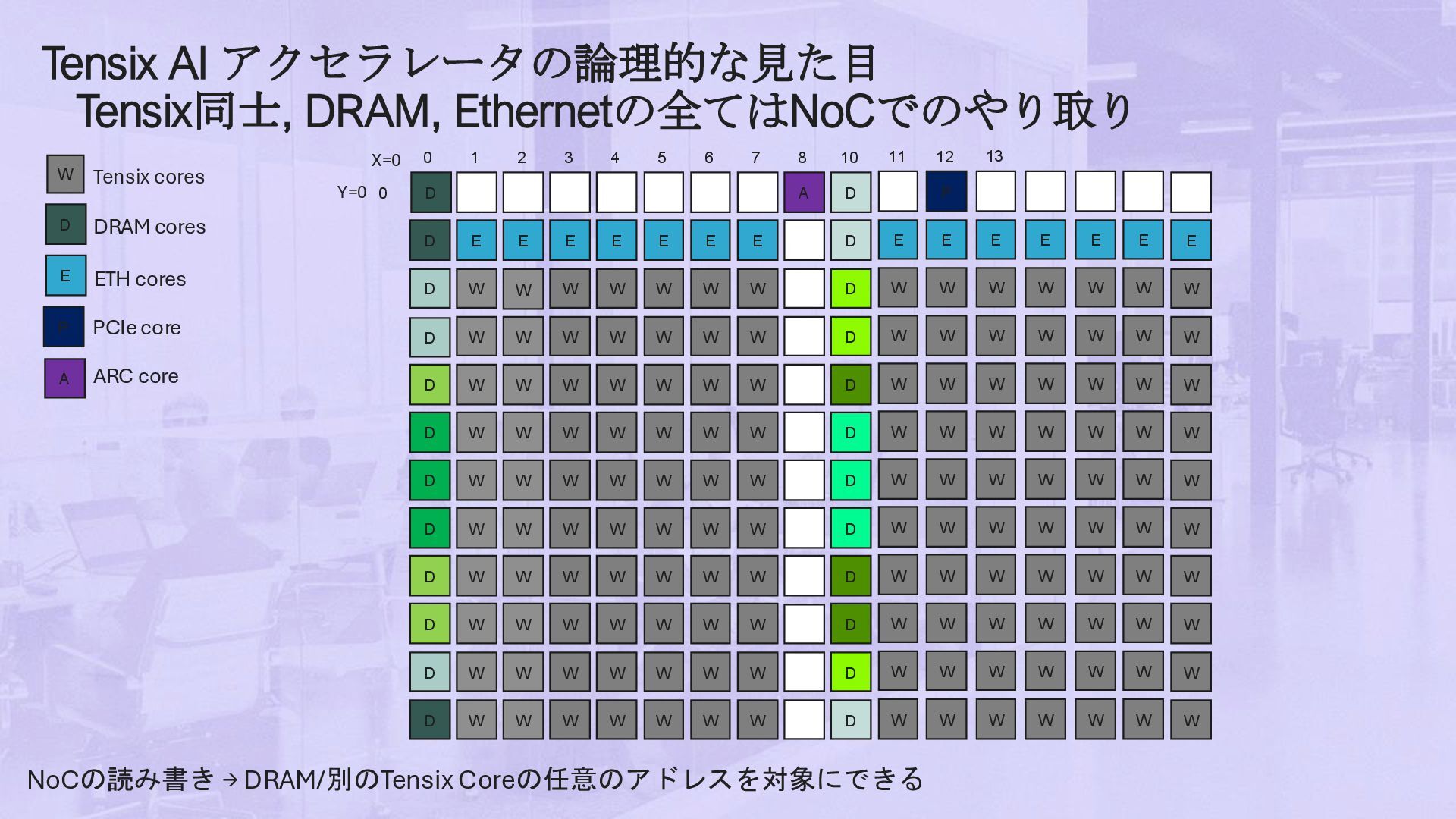
DRAM cores E ETH cores P PCIe core A ARC core A D E E E E E E E D W W W W W W W D W W W W W W W D W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W 1 2 3 4 5 6 7 8 10 0 0 W D D D D D D D D D D D W W W W W W D X=0 Y=0 E W W W W W W W W W 11 W P E W W W W W W W W W 12 W E W W W W W W W W W 13 W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W D NoCの読み書き → DRAM/別のTensix Coreの任意のアドレスを対象にできる
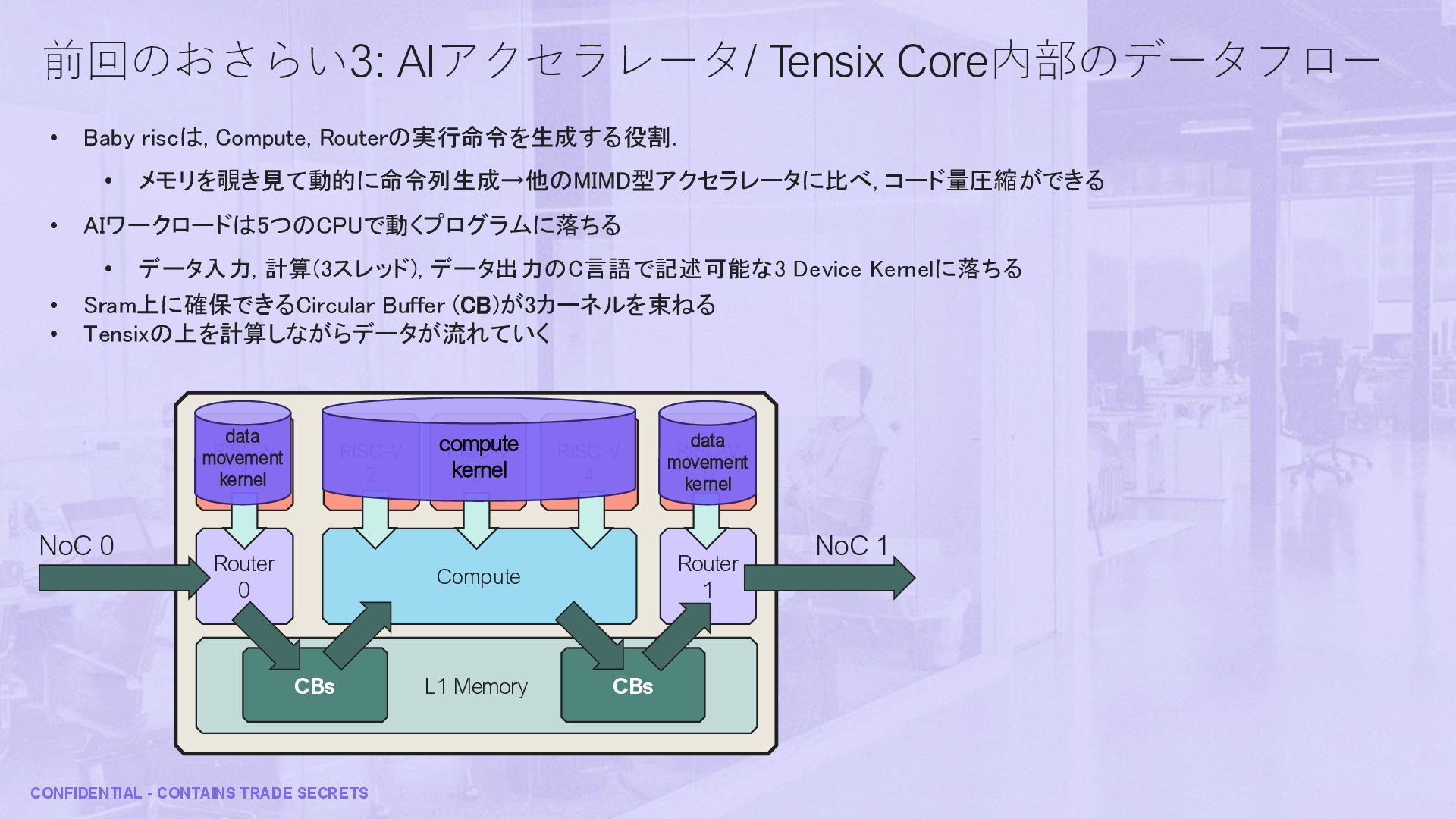
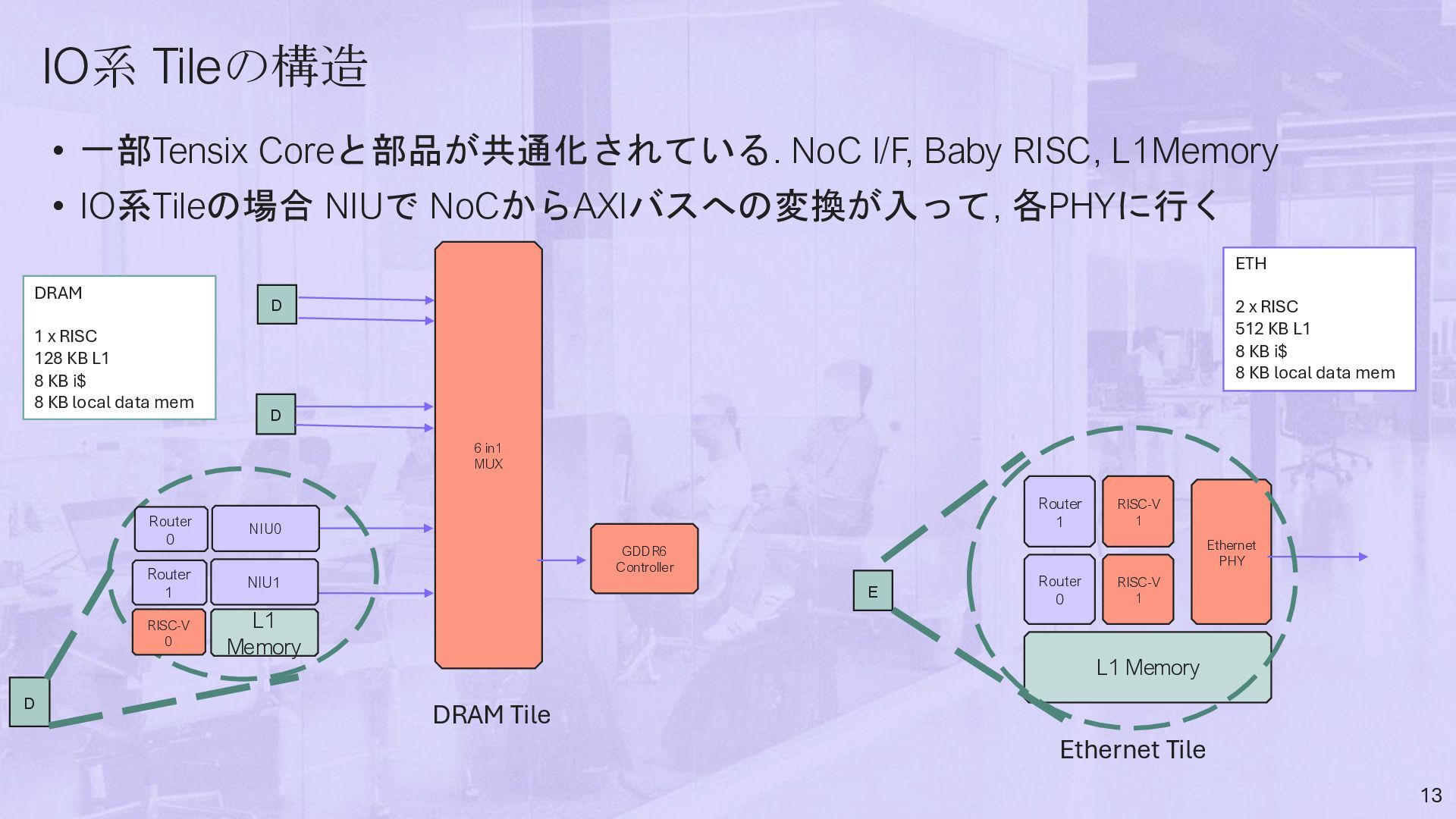
• IO系Tileの場合 NIUで NoCからAXIバスへの変換が入って, 各PHYに行く 13 GDDR6 Controller RISC-V 1 Router 0 L1 Memory RISC-V 1 Router 1 Ethernet PHY 6 in1 MUX D D D DRAM Tile Ethernet Tile E ETH 2 x RISC 512 KB L1 8 KB i$ 8 KB local data mem DRAM 1 x RISC 128 KB L1 8 KB i$ 8 KB local data mem RISC-V 0 Router 1 L1 Memory NIU1 Router 0 NIU0
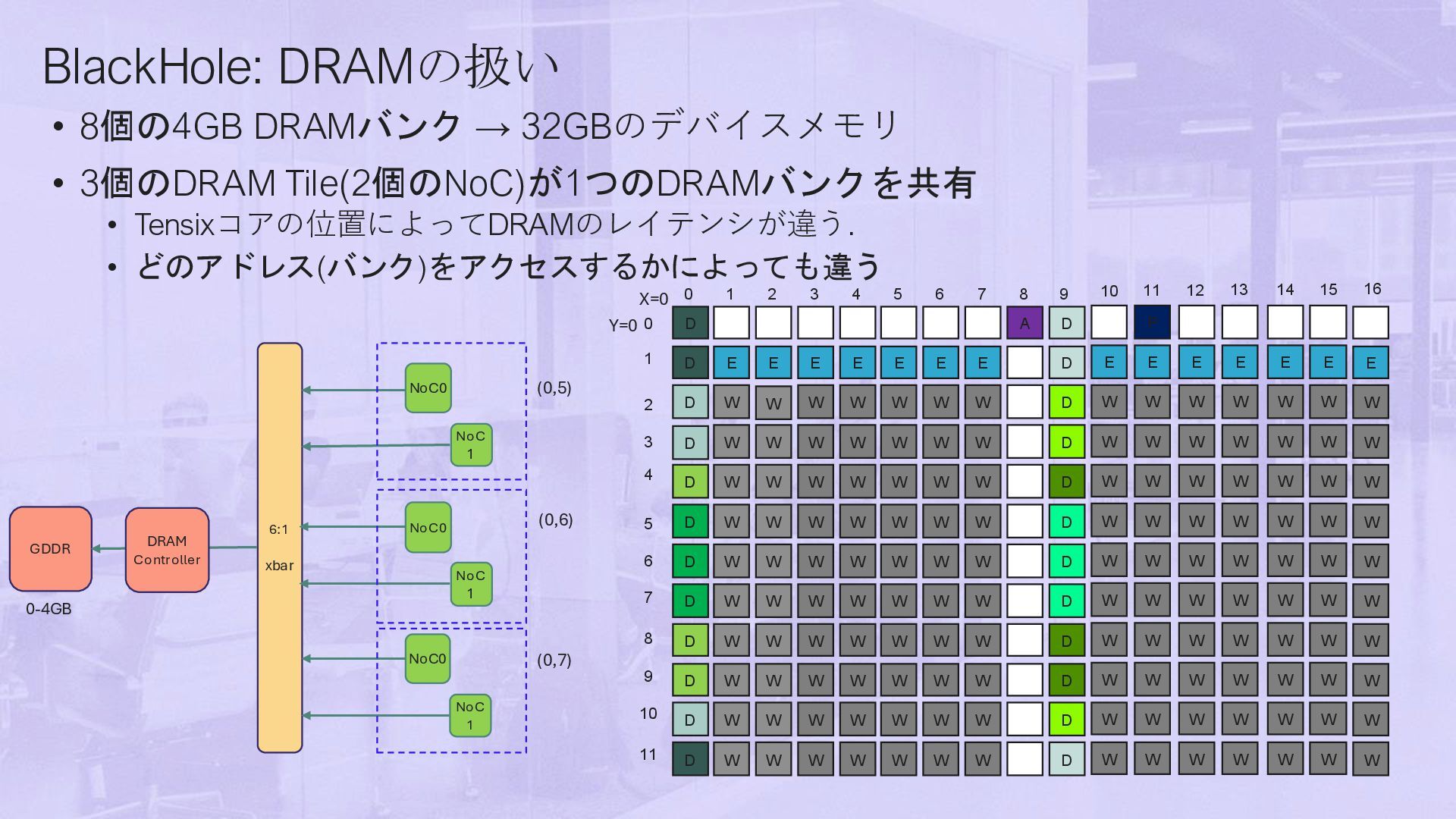
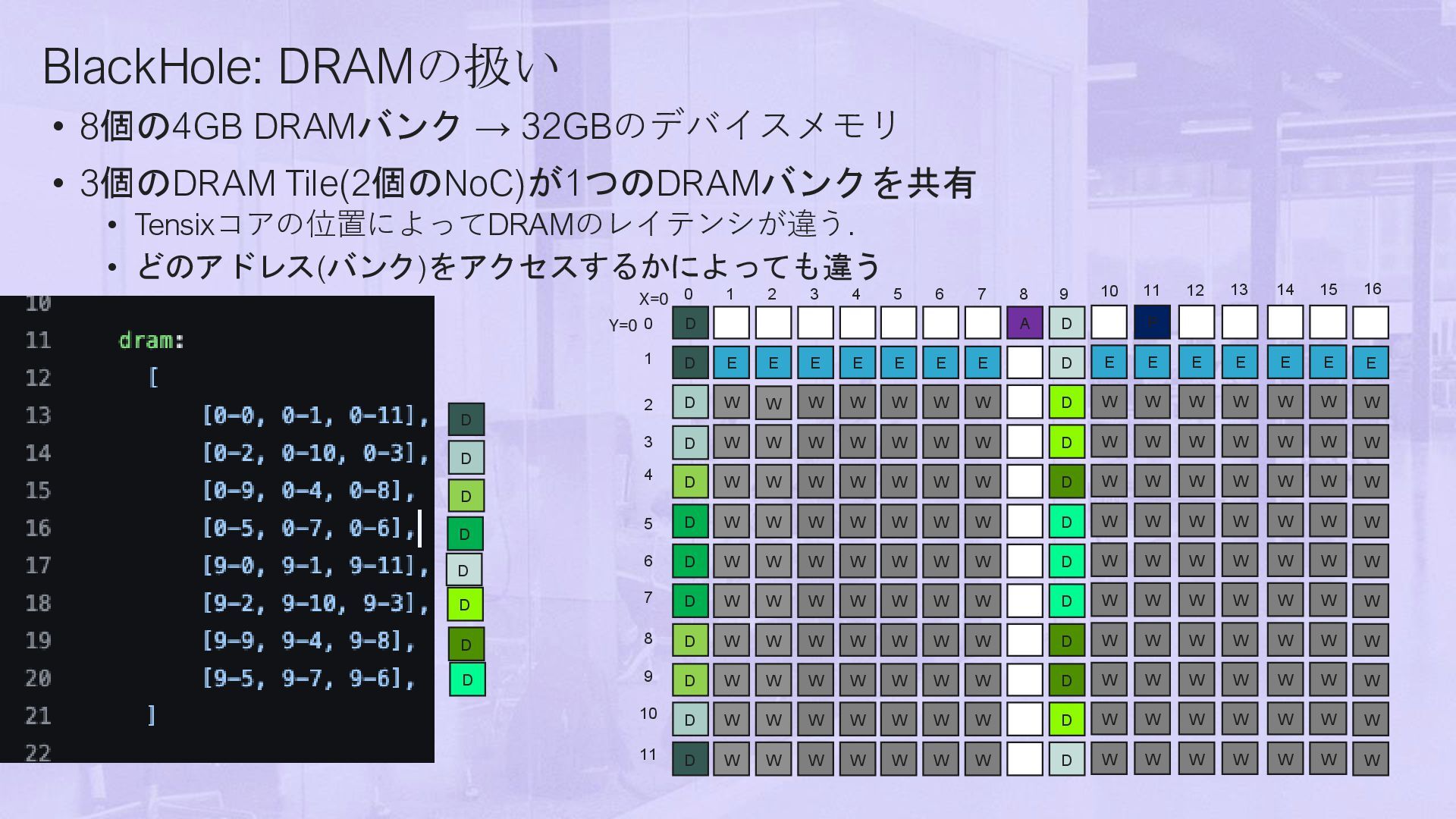
• Tensixコアの位置によってDRAMのレイテンシが違う. • どのアドレス(バンク)をアクセスするかによっても違う (0,5) (0,6) (0,7) 0-4GB NoC0 NoC 1 6:1 xbar NoC0 NoC 1 NoC0 NoC 1 GDDR DRAM Controller A D E E E E E E E D W W W W W W W D W W W W W W W D W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W 1 2 3 4 5 6 7 8 10 0 0 W D D D D D D D D D D D W W W W W W D X=0 Y=0 E W W W W W W W W W 11 W P E W W W W W W W W W 12 W E W W W W W W W W W 13 W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W D 14 15 16 9 7 6 5 4 3 2 1 8 11 10 9
• Tensixコアの位置によってDRAMのレイテンシが違う. • どのアドレス(バンク)をアクセスするかによっても違う A D E E E E E E E D W W W W W W W D W W W W W W W D W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W 1 2 3 4 5 6 7 8 10 0 0 W D D D D D D D D D D D W W W W W W D X=0 Y=0 E W W W W W W W W W 11 W P E W W W W W W W W W 12 W E W W W W W W W W W 13 W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W D 14 15 16 9 7 6 5 4 3 2 1 8 11 10 9 D D D D D D D D
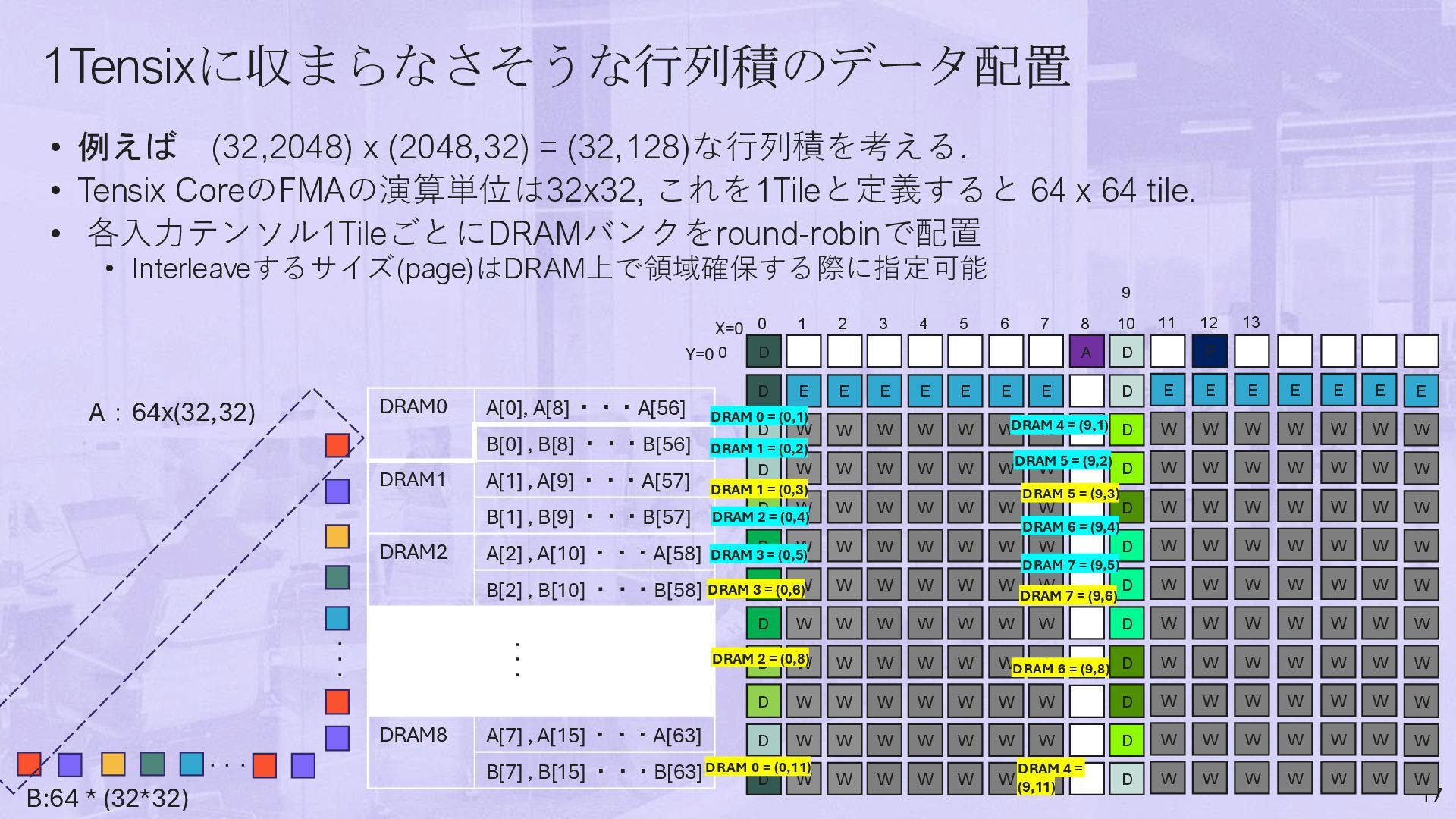
CoreのFMAの演算単位は32x32, これを1Tileと定義すると 64 x 64 tile. • 各入力テンソル1TileごとにDRAMバンクをround-robinで配置 • Interleaveするサイズ(page)はDRAM上で領域確保する際に指定可能 17 A:64x(32,32) B:64 * (32*32) 9 ・・・ ・・・ DRAM0 A[0], A[8] ・・・A[56] B[0] , B[8] ・・・B[56] DRAM1 A[1] , A[9] ・・・A[57] B[1] , B[9] ・・・B[57] DRAM2 A[2] , A[10] ・・・A[58] B[2] , B[10] ・・・B[58] DRAM8 A[7] , A[15] ・・・A[63] B[7] , B[15] ・・・B[63] ・・・ A D E E E E E E E D W W W W W W W D W W W W W W W D W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W 1 2 3 4 5 6 7 8 10 0 0 W D D D D D D D D D D D W W W W W W D X=0 Y=0 E W W W W W W W W W 11 W P E W W W W W W W W W 12 W E W W W W W W W W W 13 W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W D DRAM 0 = (0,11) DRAM 1 = (0,3) DRAM 2 = (0,8) DRAM 3 = (0,6) DRAM 4 = (9,11) DRAM 5 = (9,3) DRAM 6 = (9,8) DRAM 7 = (9,6) DRAM 0 = (0,1) DRAM 1 = (0,2) DRAM 2 = (0,4) DRAM 3 = (0,5) DRAM 4 = (9,1) DRAM 5 = (9,2) DRAM 6 = (9,4) DRAM 7 = (9,5)
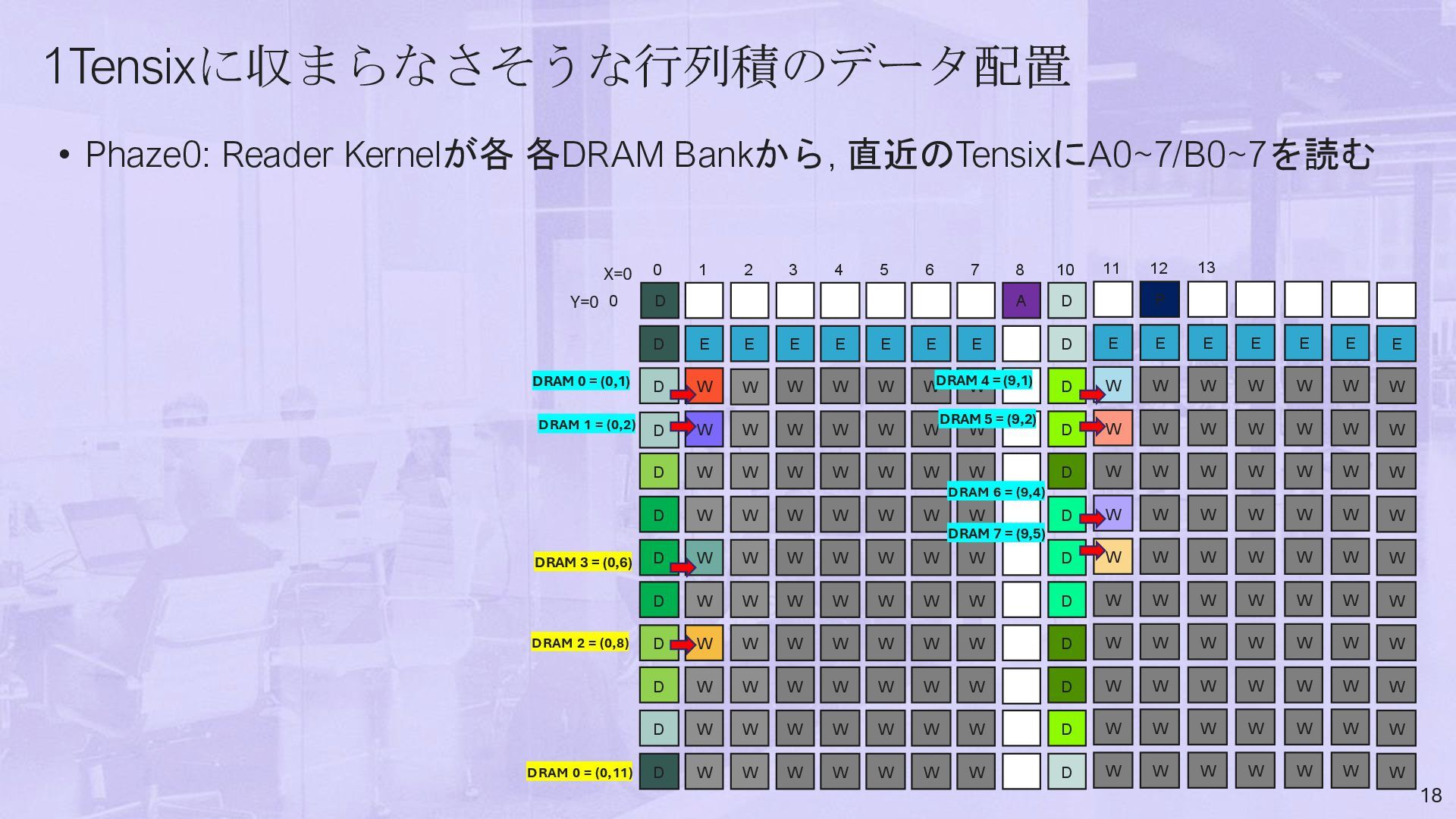
A D E E E E E E E D W W W W W W W D W W W W W W W D W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W 1 2 3 4 5 6 7 8 10 0 0 W D D D D D D D D D D D W W W W W W D X=0 Y=0 E W W W W W W W W W 11 W P E W W W W W W W W W 12 W E W W W W W W W W W 13 W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W D DRAM 0 = (0,11) DRAM 2 = (0,8) DRAM 3 = (0,6) DRAM 0 = (0,1) DRAM 1 = (0,2) DRAM 4 = (9,1) DRAM 5 = (9,2) DRAM 6 = (9,4) DRAM 7 = (9,5)
B[8~15]を読む 19 9 A D E E E E E E E D W W W W W W W D W W W W W W W D W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W 1 2 3 4 5 6 7 8 10 0 0 W D D D D D D D D D D D W W W W W W D X=0 Y=0 E W W W W W W W W W 11 W P E W W W W W W W W W 12 W E W W W W W W W W W 13 W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W D DRAM 0 = (0,11) DRAM 2 = (0,8) DRAM 3 = (0,6) DRAM 0 = (0,1) DRAM 1 = (0,2) DRAM 4 = (9,1) DRAM 5 = (9,2) DRAM 6 = (9,4) DRAM 7 = (9,5)
読む • Phaze2: phaze1の計算結果, 読み出し値を使って (以下略 ・ ・ ・ ここまでNoC0で DRAMからTensixへデータ配布 20 9 A D E E E E E E E D W W W W W W W D W W W W W W W D W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W 1 2 3 4 5 6 7 8 10 0 0 W D D D D D D D D D D D W W W W W W D X=0 Y=0 E W W W W W W W W W 11 W P E W W W W W W W W W 12 W E W W W W W W W W W 13 W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W D DRAM 0 = (0,11) DRAM 2 = (0,8) DRAM 3 = (0,6) DRAM 0 = (0,1) DRAM 1 = (0,2) DRAM 4 = (9,1) DRAM 5 = (9,2) DRAM 6 = (9,4) DRAM 7 = (9,5)
• Phaze2: phaze1の計算結果, 読み出し値を使って (以下略 ・ ・ ・ • PhazeM: Tensixから値を集約 (Reduction Kernel) 21 9 A D E E E E E E E D W W W W W W W D W W W W W W W D W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W 1 2 3 4 5 6 7 8 10 0 0 W D D D D D D D D D D D W W W W W W D X=0 Y=0 E W W W W W W W W W 11 W P E W W W W W W W W W 12 W E W W W W W W W W W 13 W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W D DRAM 0 = (0,11) DRAM 2 = (0,8) DRAM 3 = (0,6) DRAM 0 = (0,1) DRAM 1 = (0,2) DRAM 4 = (9,1) DRAM 5 = (9,2) DRAM 6 = (9,4) DRAM 7 = (9,5)
• Phaze2: phaze1の計算結果, 読み出し値を使って (以下略 ・ ・ ・ • PhazeM: Tensixから値を集約 (Reduction Kernel) • PhazeN: 結果をDRAMに書き戻し PhazeM,NはNoC1を使う 22 9 A D E E E E E E E D W W W W W W W D W W W W W W W D W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W 1 2 3 4 5 6 7 8 10 0 0 W D D D D D D D D D D D W W W W W W D X=0 Y=0 E W W W W W W W W W 11 W P E W W W W W W W W W 12 W E W W W W W W W W W 13 W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W D DRAM 0 = (0,11) DRAM 2 = (0,8) DRAM 3 = (0,6) DRAM 0 = (0,1) DRAM 1 = (0,2) DRAM 4 = (9,1) DRAM 5 = (9,2) DRAM 6 = (9,4) DRAM 7 = (9,5)
TensorをL1メモリにだけ貼り付けるオプション有〼 23 9 A D E E E E E E E D W W W W W W W D W W W W W W W D W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W W W W W W W D W 1 2 3 4 5 6 7 8 10 0 0 W D D D D D D D D D D D W W W W W W D X=0 Y=0 E W W W W W W W W W 11 W P E W W W W W W W W W 12 W E W W W W W W W W W 13 W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W E W W W W W W W W W W D DRAM 0 = (0,11) DRAM 2 = (0,8) DRAM 3 = (0,6) DRAM 0 = (0,1) DRAM 1 = (0,2) DRAM 4 = (9,1) DRAM 5 = (9,2) DRAM 6 = (9,4) DRAM 7 = (9,5)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1Tensixに収まらなさそうな行列積のデータ配置 • Phaze0:Reader Kernelが各DRAM Bankから, 直近のTensixにA0~7/B0~7を読む • Phaze1:Phaze0で読んだ値を使ってCompute Kernelが部分行列積しつつ, A[8~15],](https://files.speakerdeck.com/presentations/8fad26c84a884bb582ed0cb3bcfa4312/slide_18.jpg){kind=link}
![1Tensixに収まらなさそうな行列積のデータ配置 • Phaze0:各DRAM Bankから, 直近のTensixにA0~7/B0~7を読む • Phaze1:読んだ値を使ってCompute Kernelが部分行列積しつつ, A[8~15], B[8~15]を](https://files.speakerdeck.com/presentations/8fad26c84a884bb582ed0cb3bcfa4312/slide_19.jpg){kind=link}
![1Tensixに収まらなさそうな行列積のデータ配置 • Phaze0:各DRAM Bankから, 直近のTensixにA0~7/B0~7を読む • Phaze1:読んだ値を使ってCompute Kernelが部分行列積しつつ, A[8~15], B[8~15]を読む](https://files.speakerdeck.com/presentations/8fad26c84a884bb582ed0cb3bcfa4312/slide_20.jpg){kind=link}
![1Tensixに収まらなさそうな行列積のデータ配置 • Phaze0:各DRAM Bankから, 直近のTensixにA0~7/B0~7を読む • Phaze1:読んだ値を使ってCompute Kernelが部分行列積しつつ, A[8~15], B[8~15]を読む](https://files.speakerdeck.com/presentations/8fad26c84a884bb582ed0cb3bcfa4312/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}