Ops TT-Metalium GPU Programming Deep Learning Ops Collective Comms Ops VS. TT-Metalium C++ Host API TT-Metalium C++ Kernel API TT-NN C++ Host API GPU Kernel Language DNN CCL
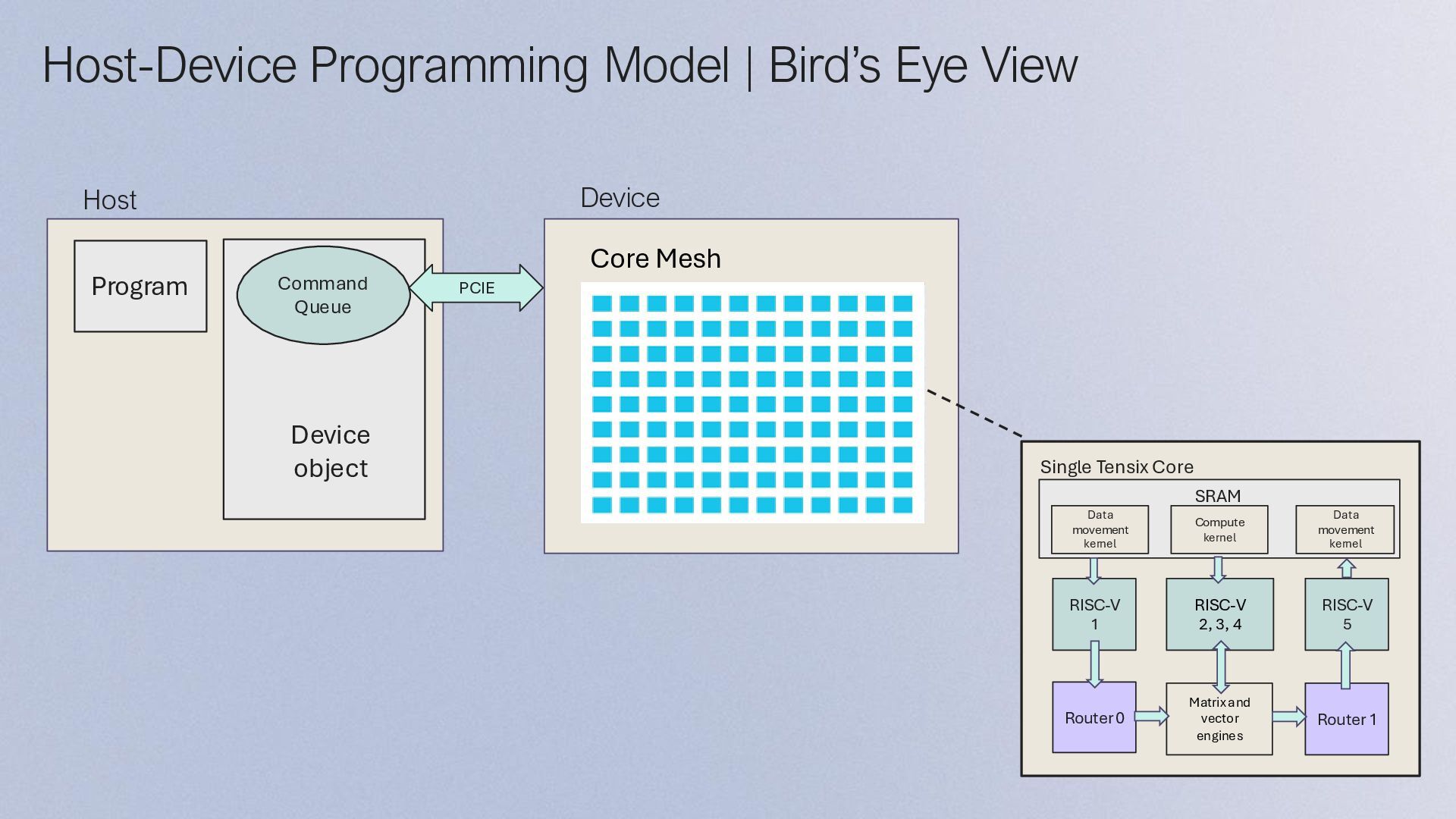
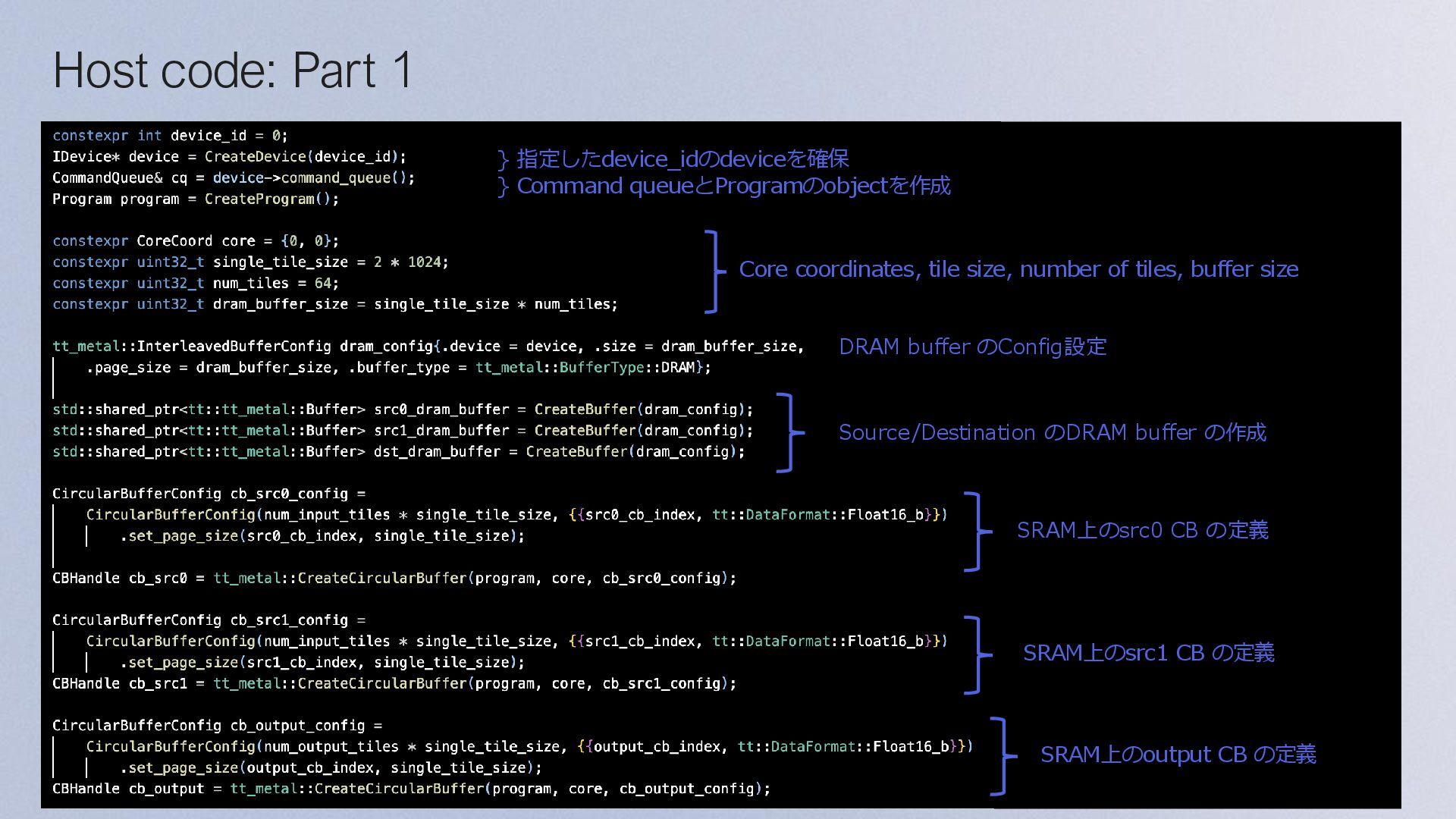
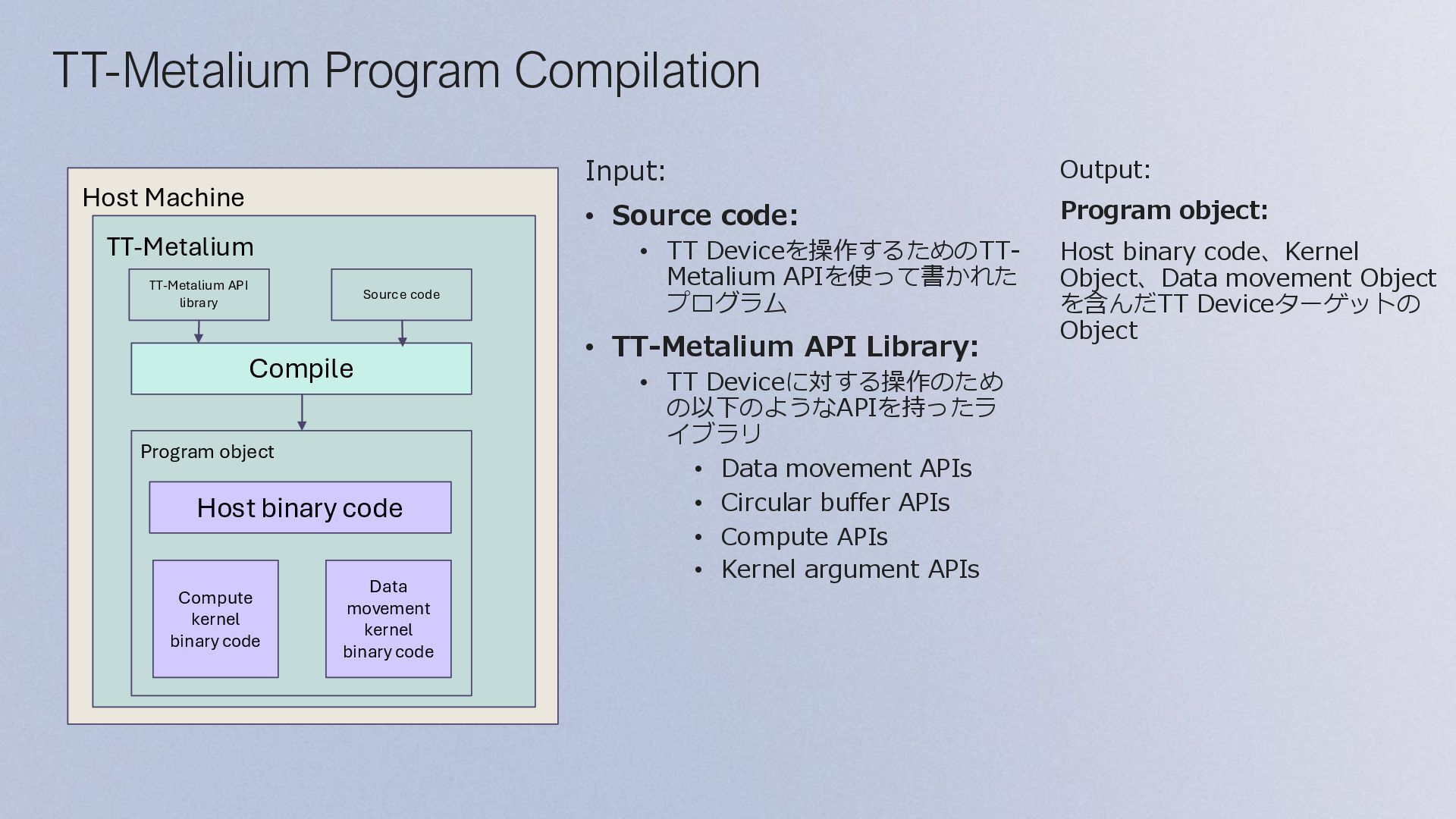
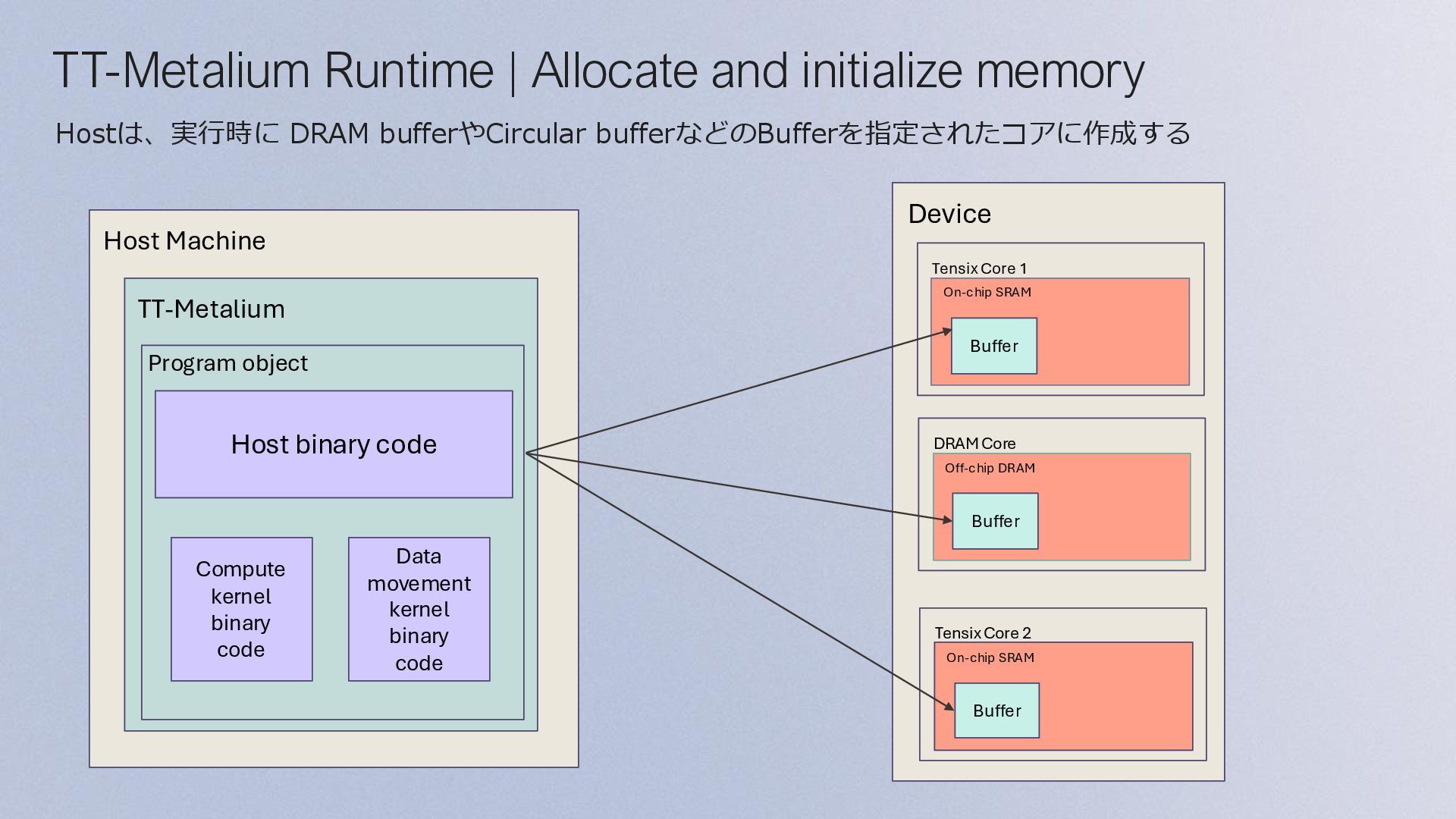
and Device: • device object の作成 • program objectを作成 • core coordinatesの指定 Initialize Program and Device Configure and Create Collaboration Mechanisms Configure and Create Kernels Dispatch Program to Device for Execution Finish Program Execution Allocate Device Memory and Initialize Source Data Allocate Device Memory: • DRAMとSRAMのメモリレイアウトを設定 (sharded or interleaved) • DRAM and SRAM buffer の作成 Initialize Source Data: • Source data用のベクトルを作成(buffers) • 作成したbuffersにSource dataを書き込み
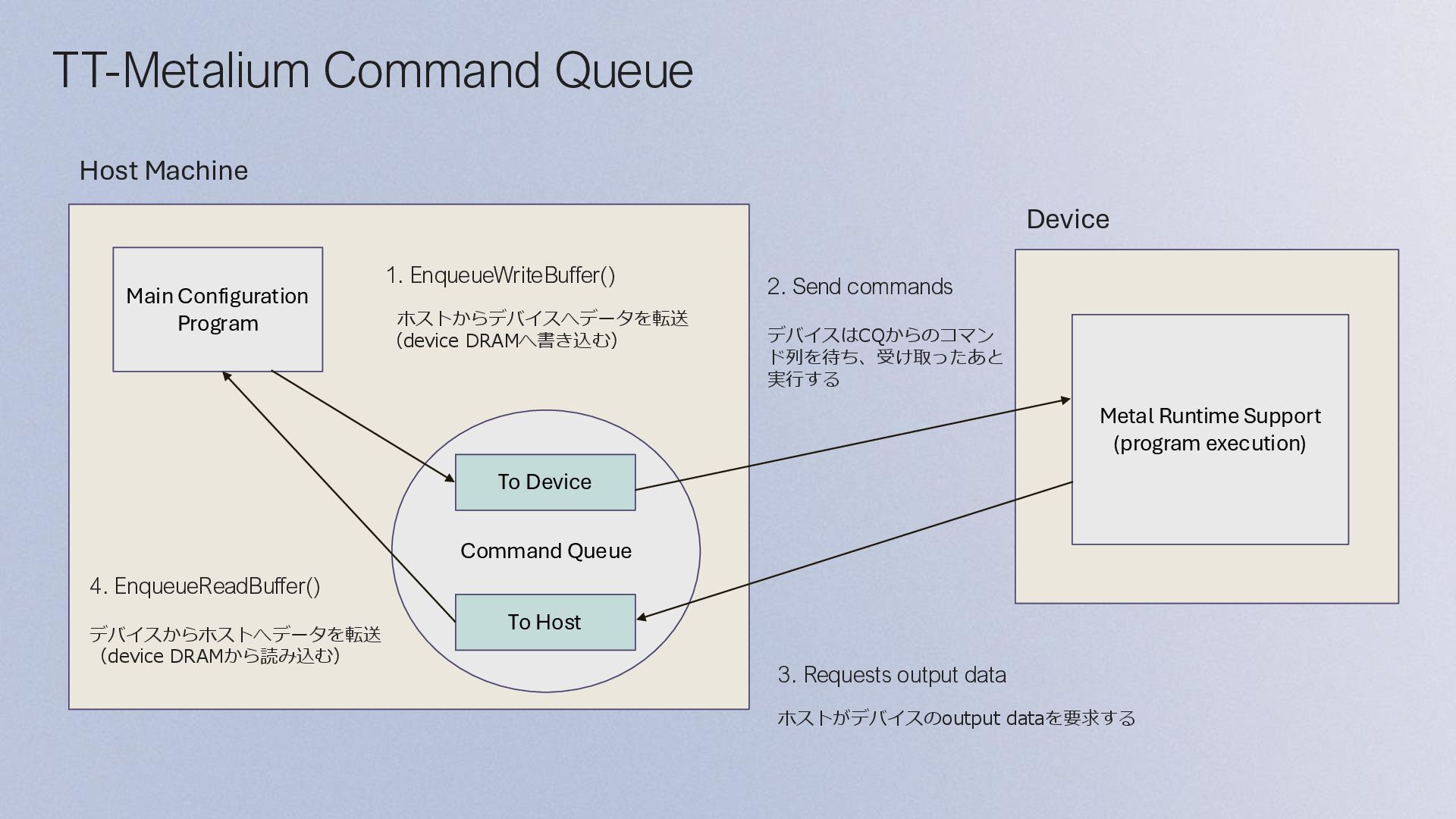
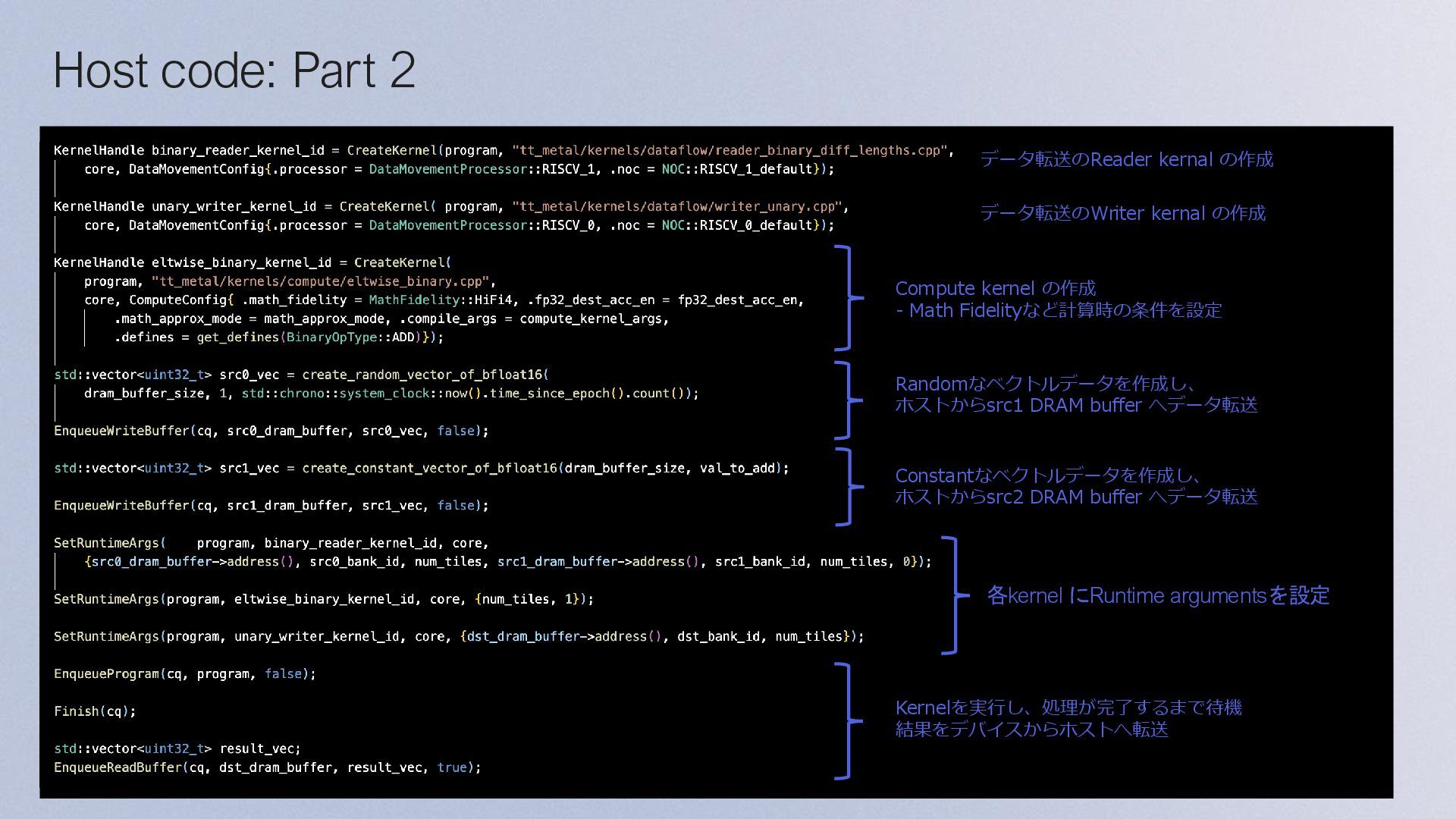
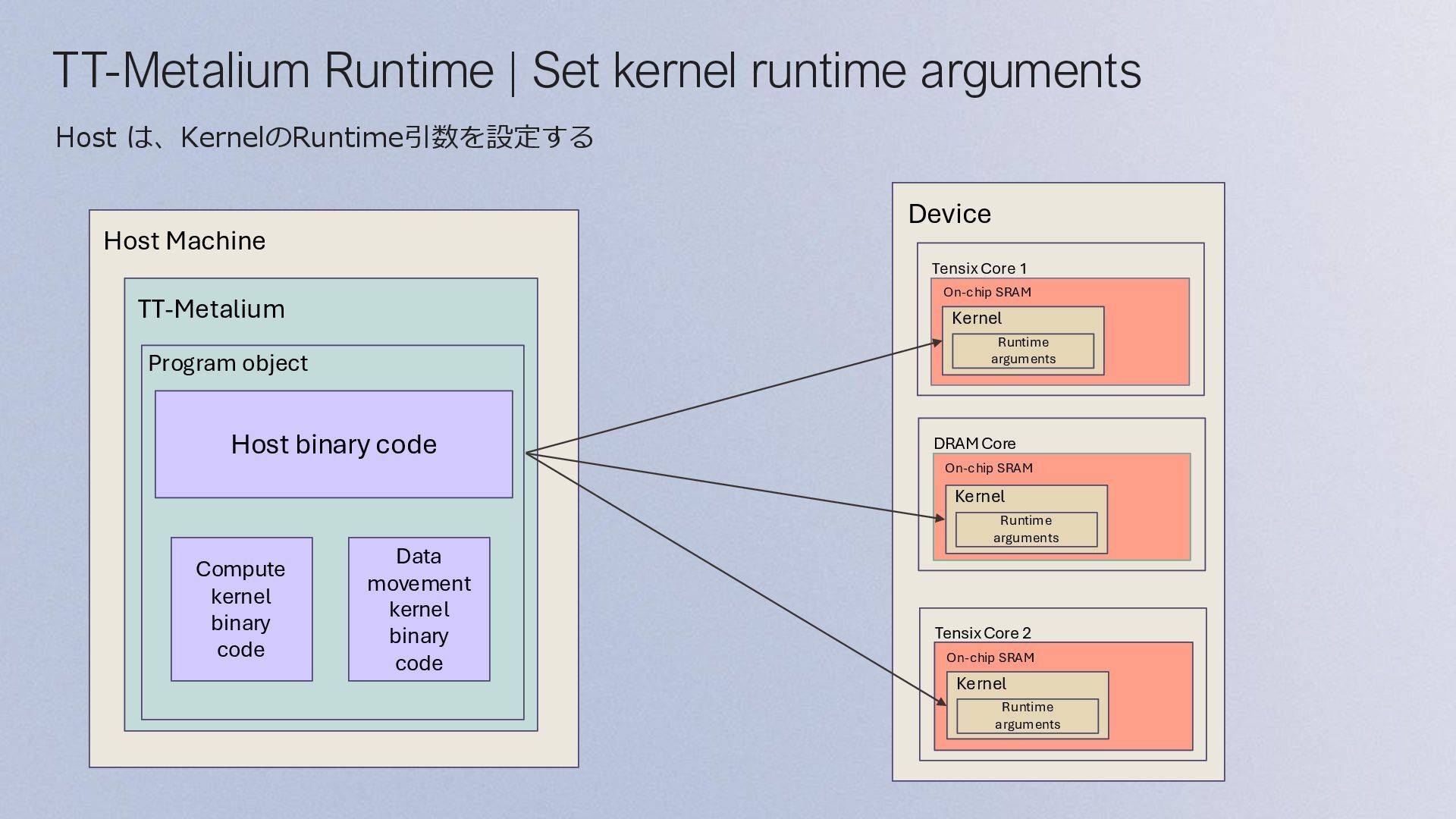
Execution: • 各kernel のRuntime引数を指定 • EnqueueProgram() がデバイスにプログラムを書き込み、実行する Main Configuration Program Initialize Program and Device Allocate Device Memory and Initialize Source Data Configure and Create Collaboration Mechanisms Configure and Create Kernels Dispatch Program to Device for Execution Finish Program Execution Finish Program Execution Finish Program Execution: • Finish() は、指定された CQ objectを通して、ディスパッチされたすべてのコマ ンドが完了するまでブロックする • EnqueueReadBuffer() は、デバイスの出力データをバッファからホストメモリ に読み込む • 最後に、デバイスをCloseする
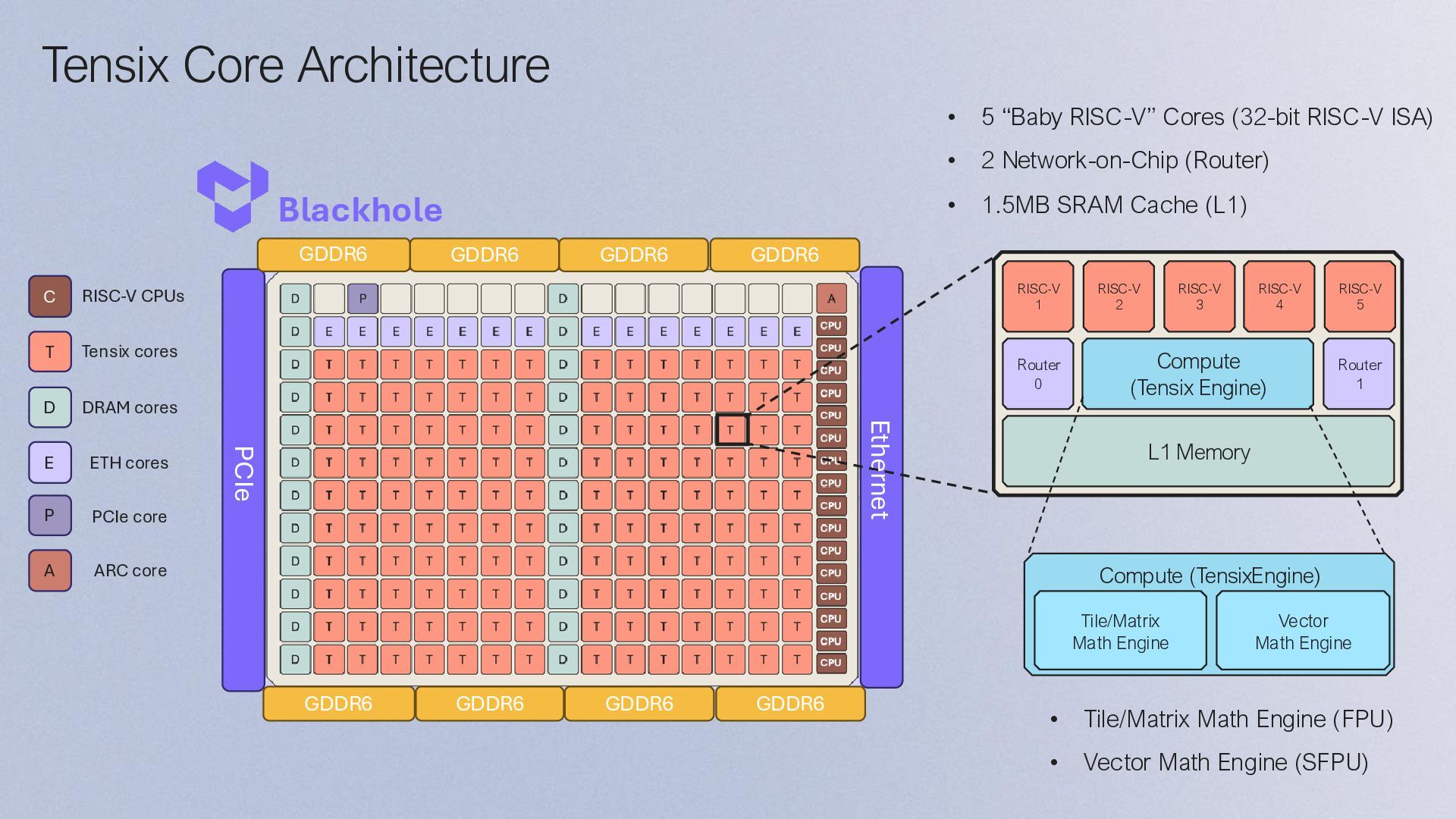
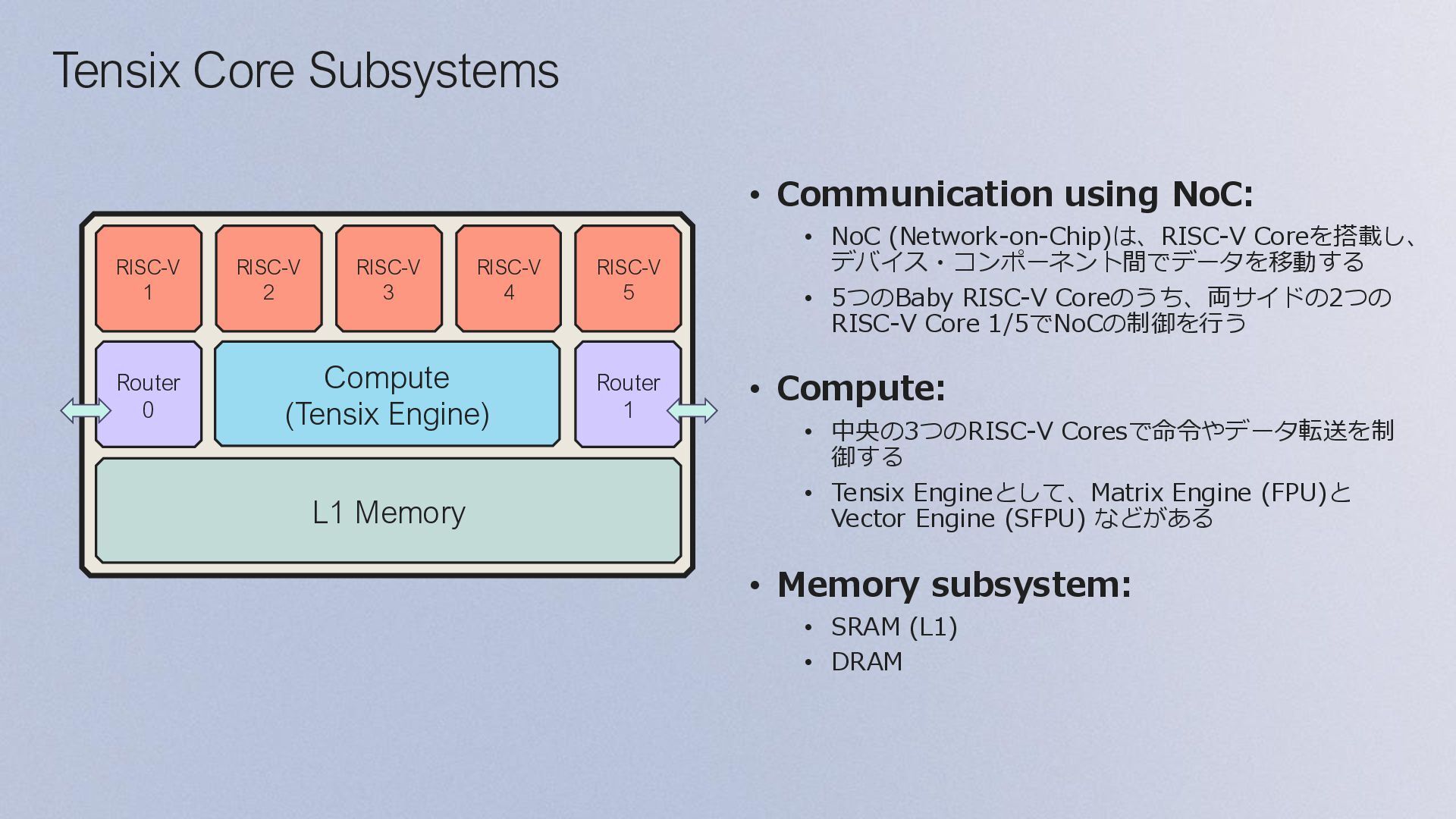
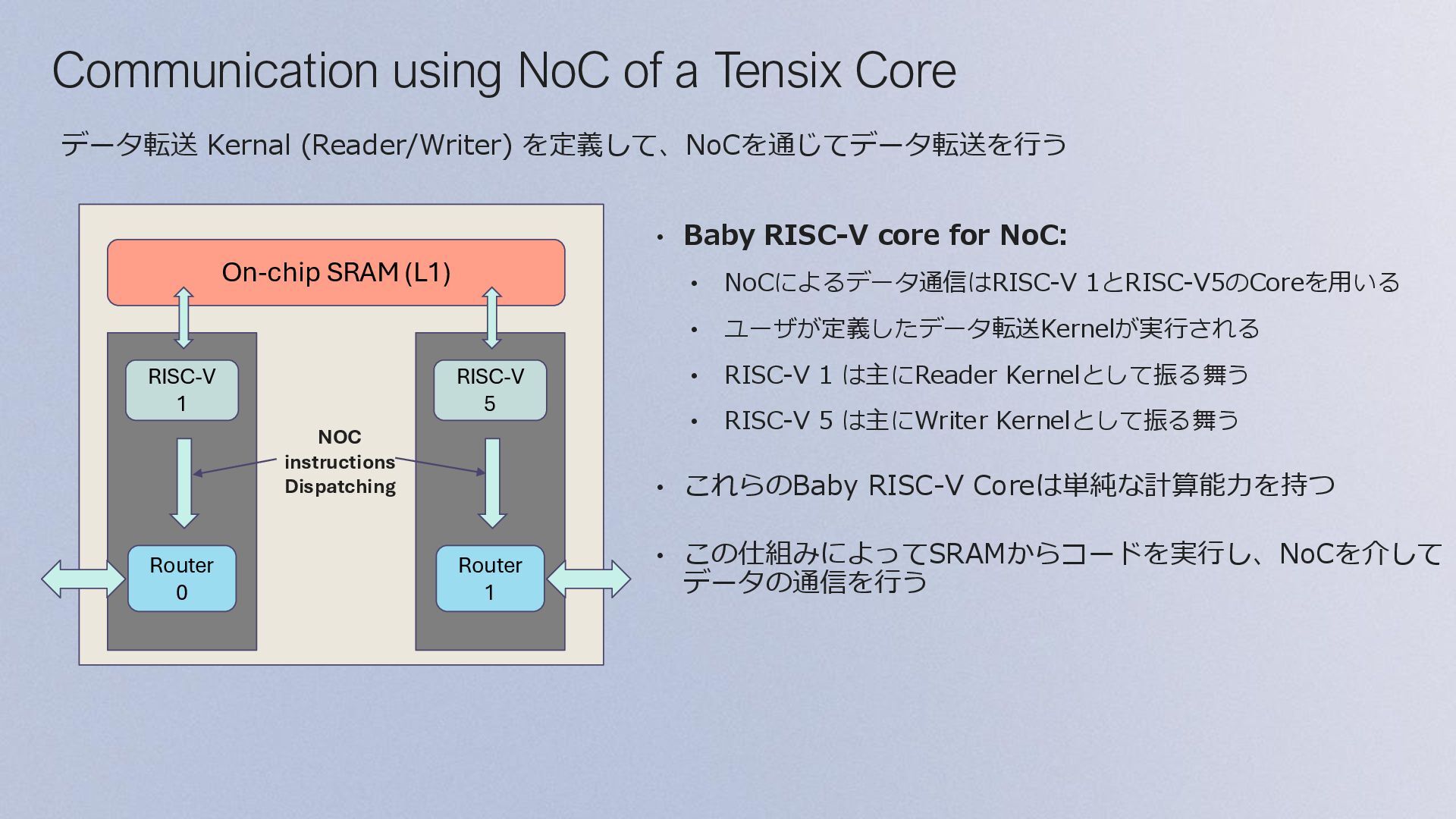
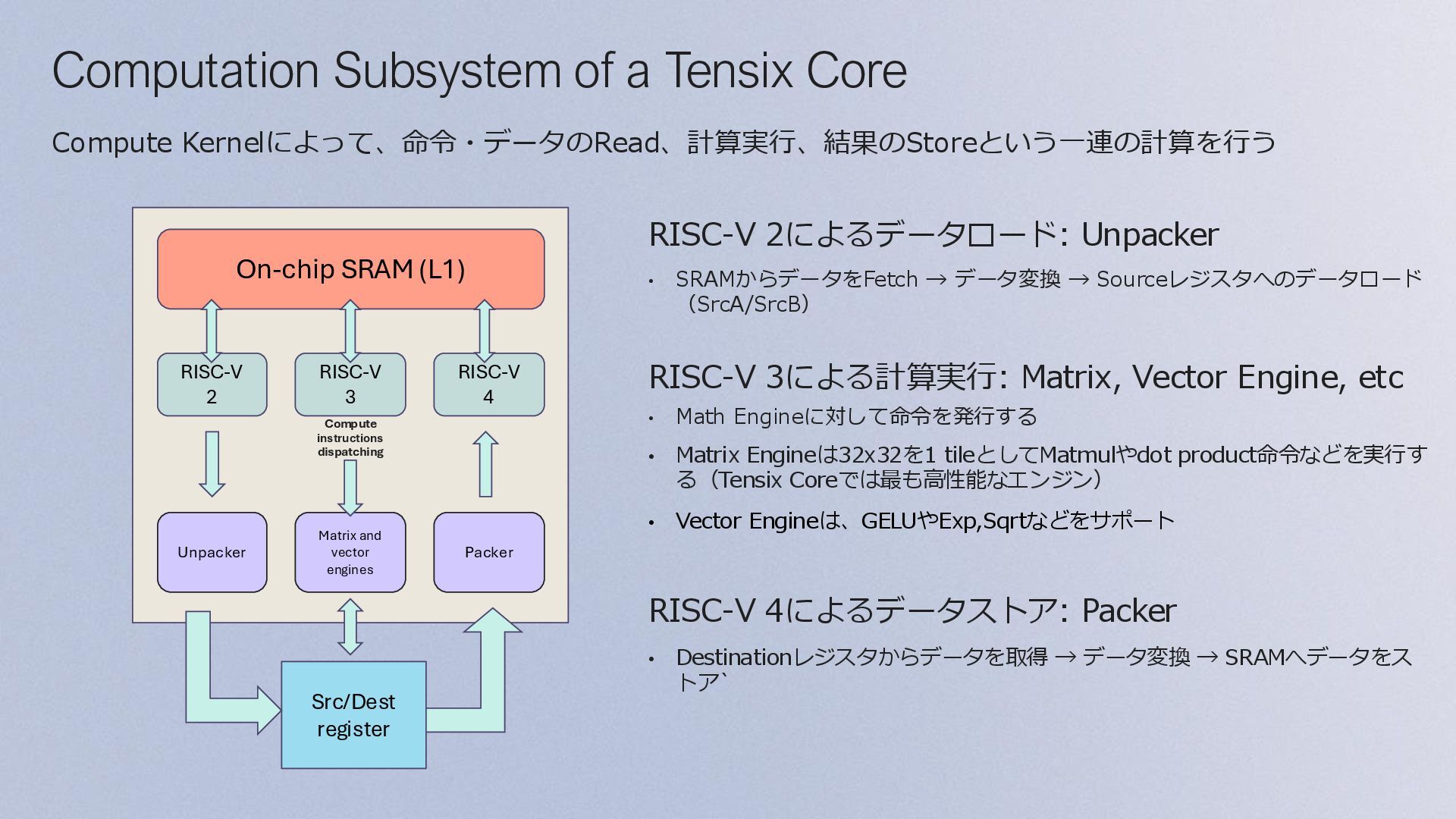
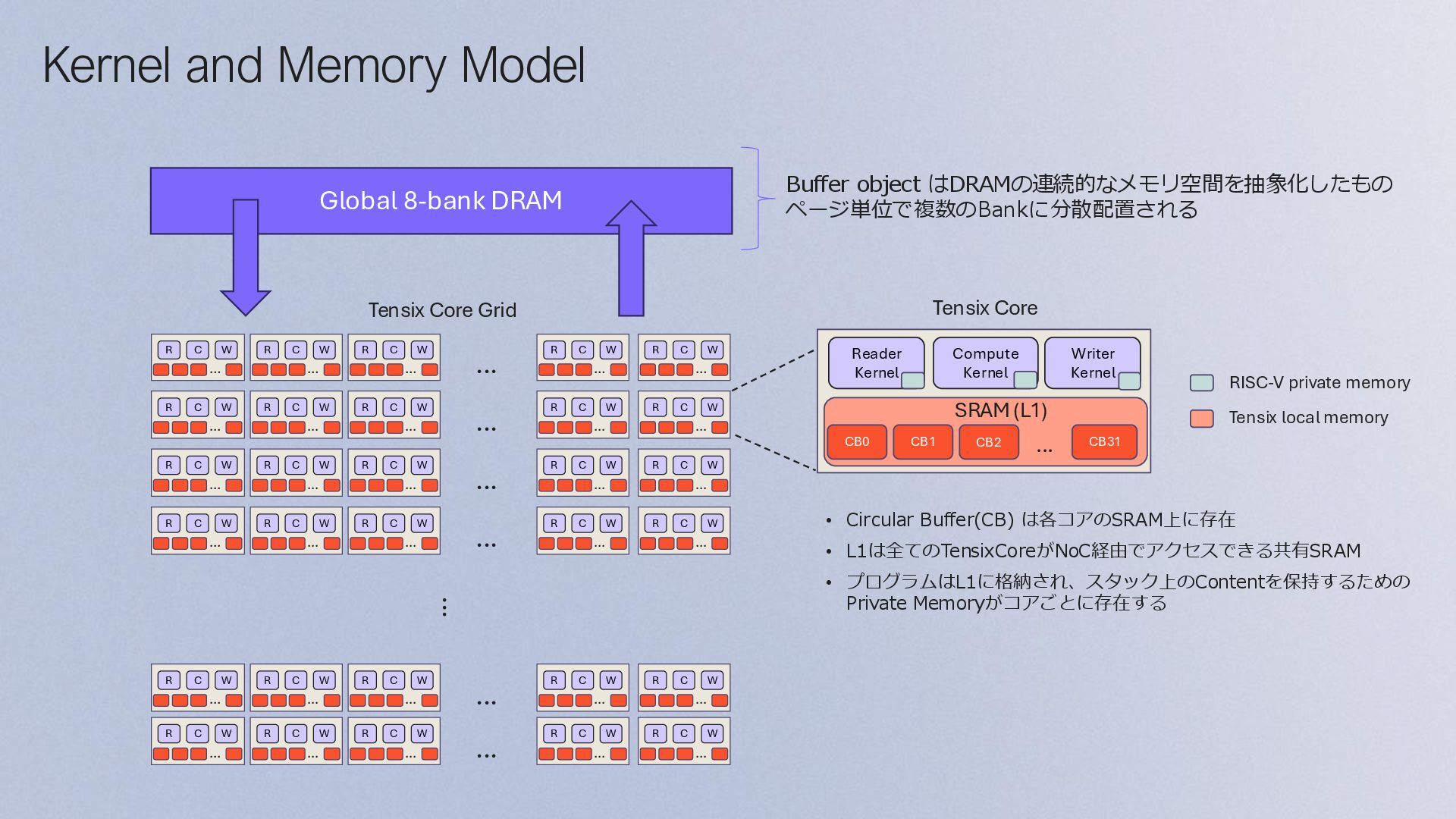
Coreを搭載し、 デバイス・コンポーネント間でデータを移動する • 5つのBaby RISC-V Coreのうち、両サイドの2つの RISC-V Core 1/5でNoCの制御を行う • Compute: • 中央の3つのRISC-V Coresで命令やデータ転送を制 御する • Tensix Engineとして、Matrix Engine (FPU)と Vector Engine (SFPU) などがある • Memory subsystem: • SRAM (L1) • DRAM Com e ( ensi Engine RISC V 2 RISC V 3 RISC V RISC V 5 RISC V Ro er Memory Ro er
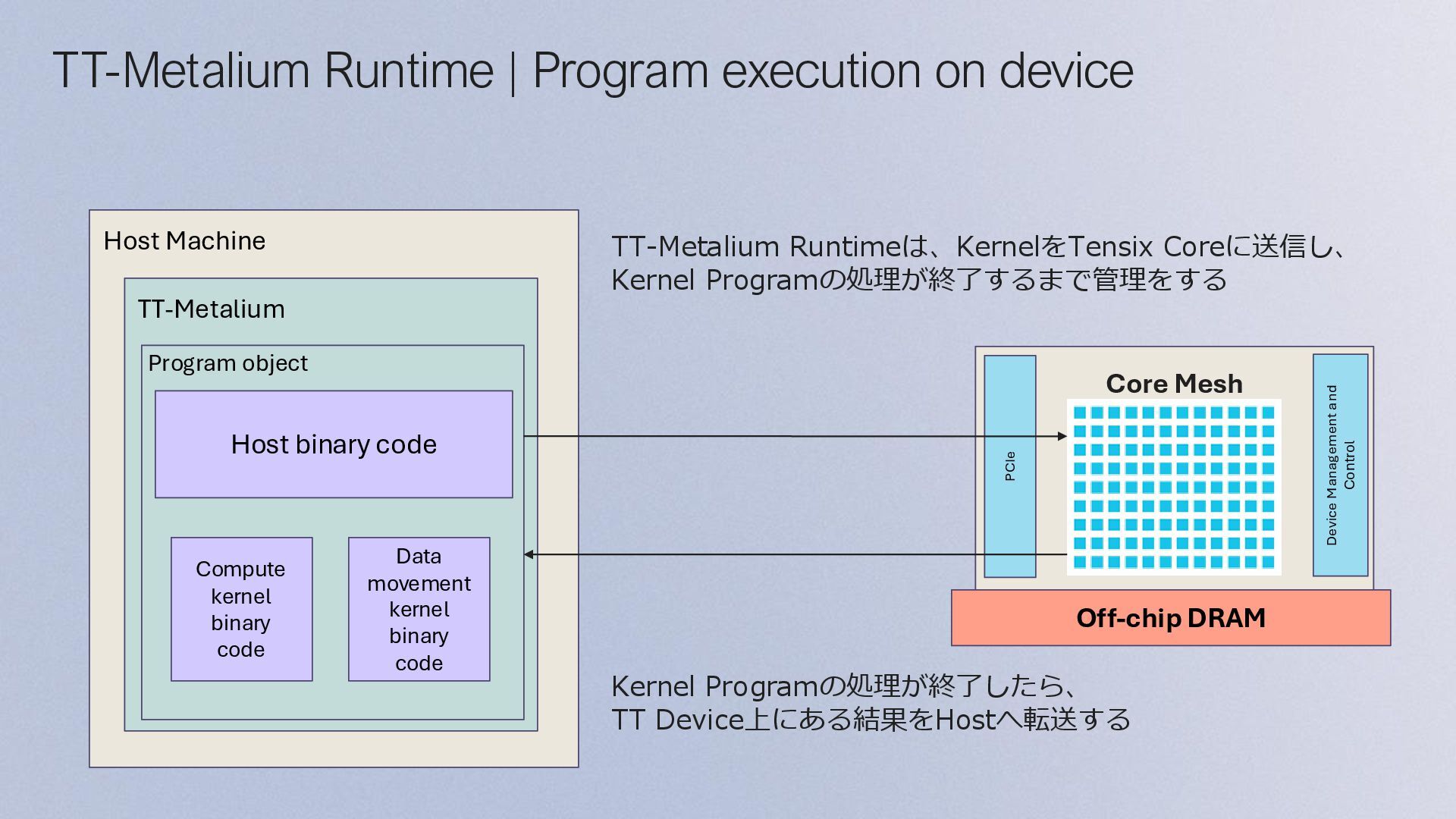
binary code Data movement kernel binary code TT-Metalium Runtime | Program execution on device Off-chip DRAM Core Mesh PCIe Device Management and Control Kernel Programの処理が終了したら、 TT Device上にある結果をHostへ転送する TT-Metalium Runtimeは、KernelをTensix Coreに送信し、 Kernel Programの処理が終了するまで管理をする
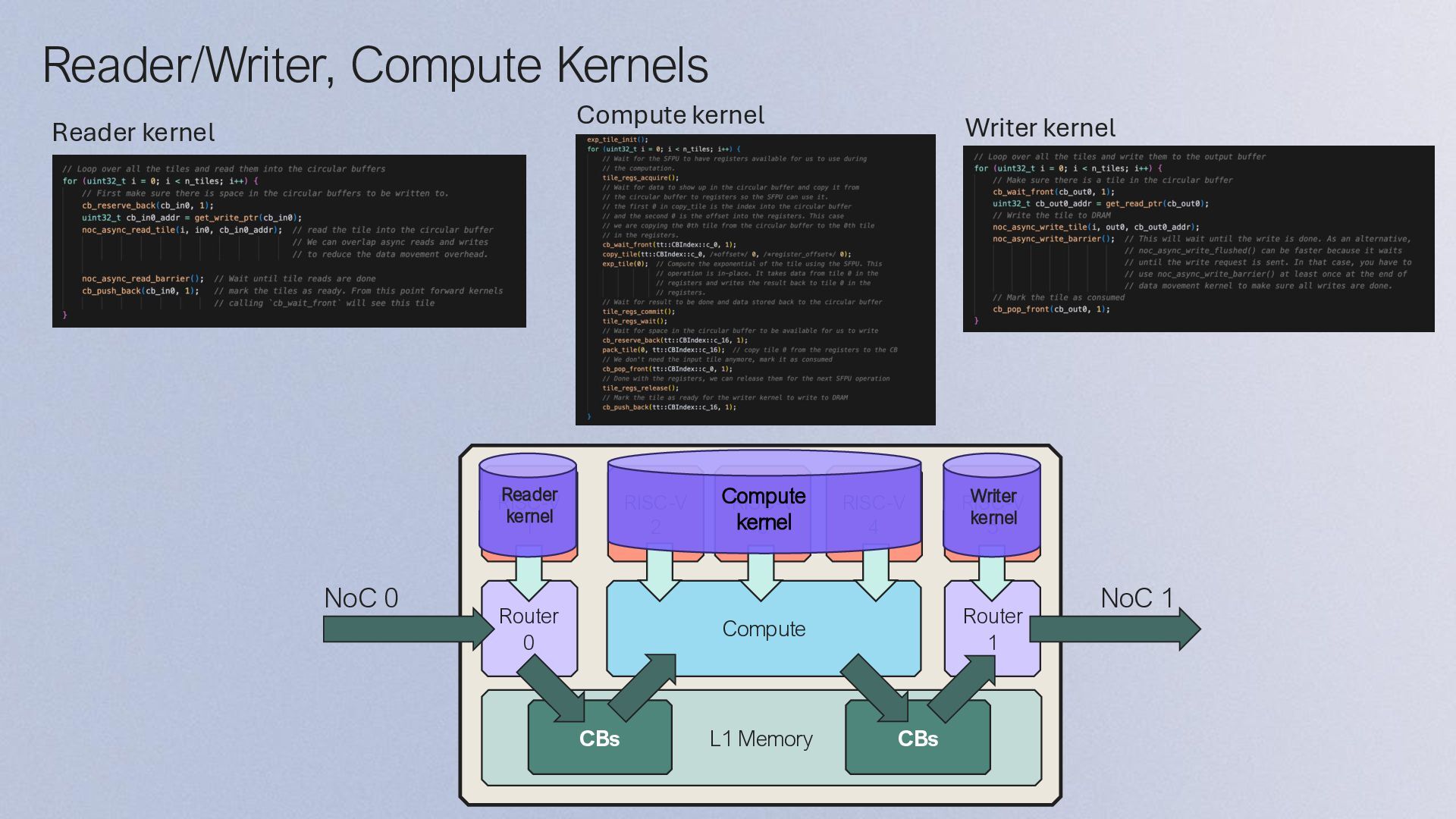
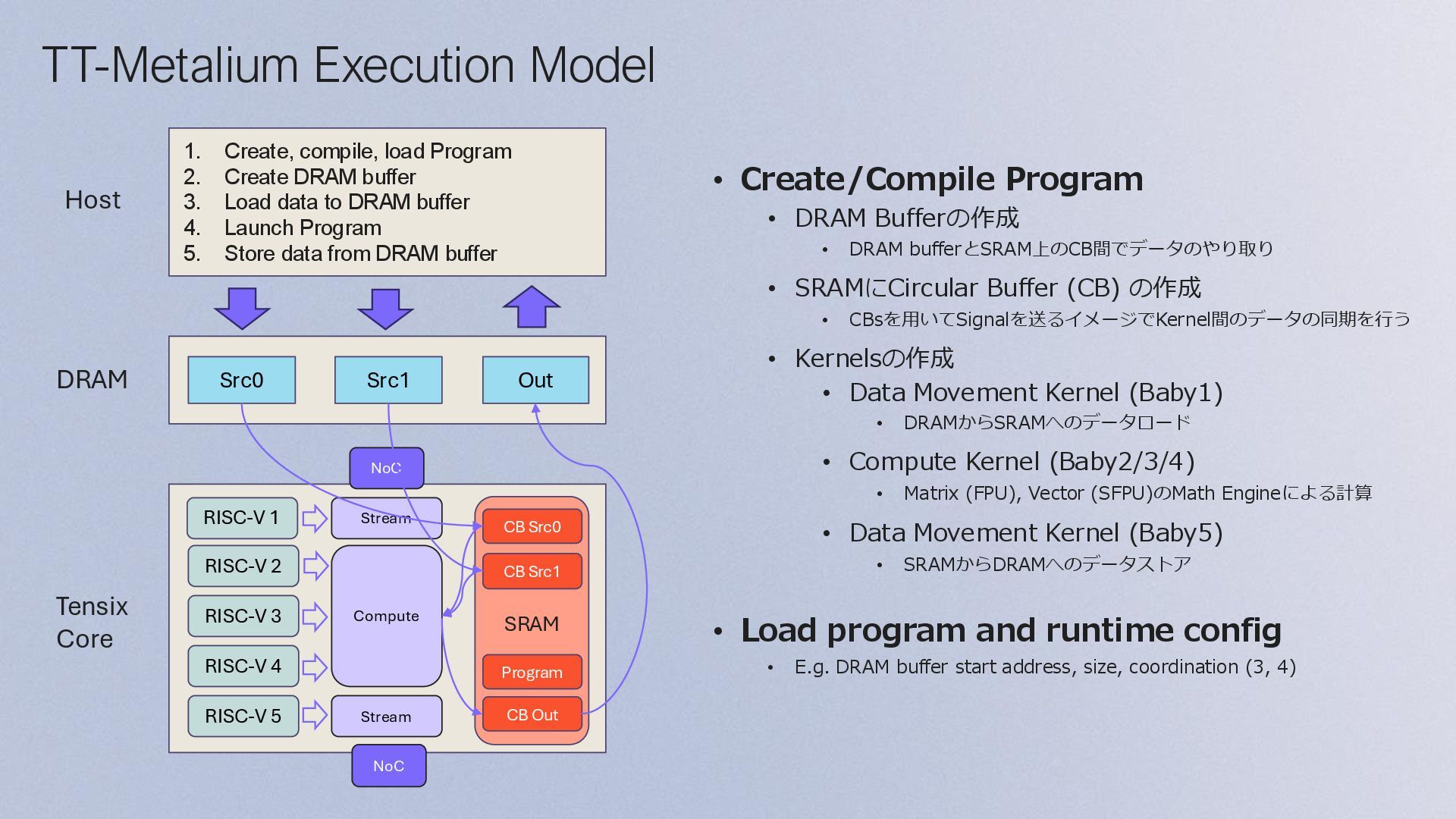
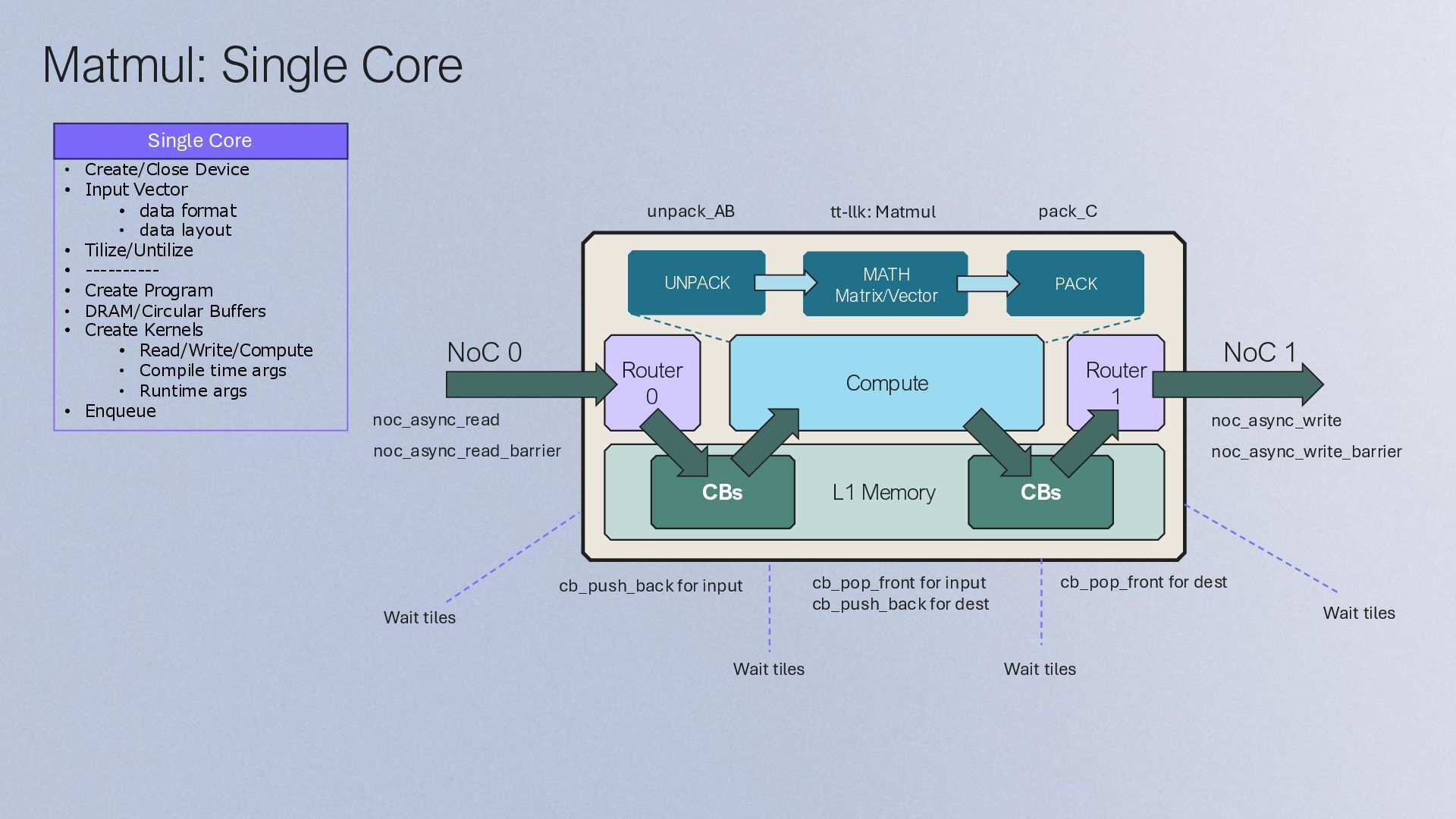
DRAM bufferとSRAM上のCB間でデータのやり取り • SRAMにCircular Buffer (CB) の作成 • CBsを用いてSignalを送るイメージでKernel間のデータの同期を行う • Kernelsの作成 • Data Movement Kernel (Baby1) • DRAMからSRAMへのデータロード • Compute Kernel (Baby2/3/4) • Matrix (FPU), Vector (SFPU)のMath Engineによる計算 • Data Movement Kernel (Baby5) • SRAMからDRAMへのデータストア • Load program and runtime config • E.g. DRAM buffer start address, size, coordination (3, 4) 1. Create, compile, load Program 2. Create DRAM buffer 3. Load data to DRAM buffer 4. Launch Program 5. Store data from DRAM buffer Stream Src0 RISC-V 1 Src1 Out RISC-V 2 RISC-V 3 RISC-V 4 RISC-V 5 Compute Stream NoC NoC CB Src0 CB Src1 Program CB Out Host DRAM Tensix Core SRAM
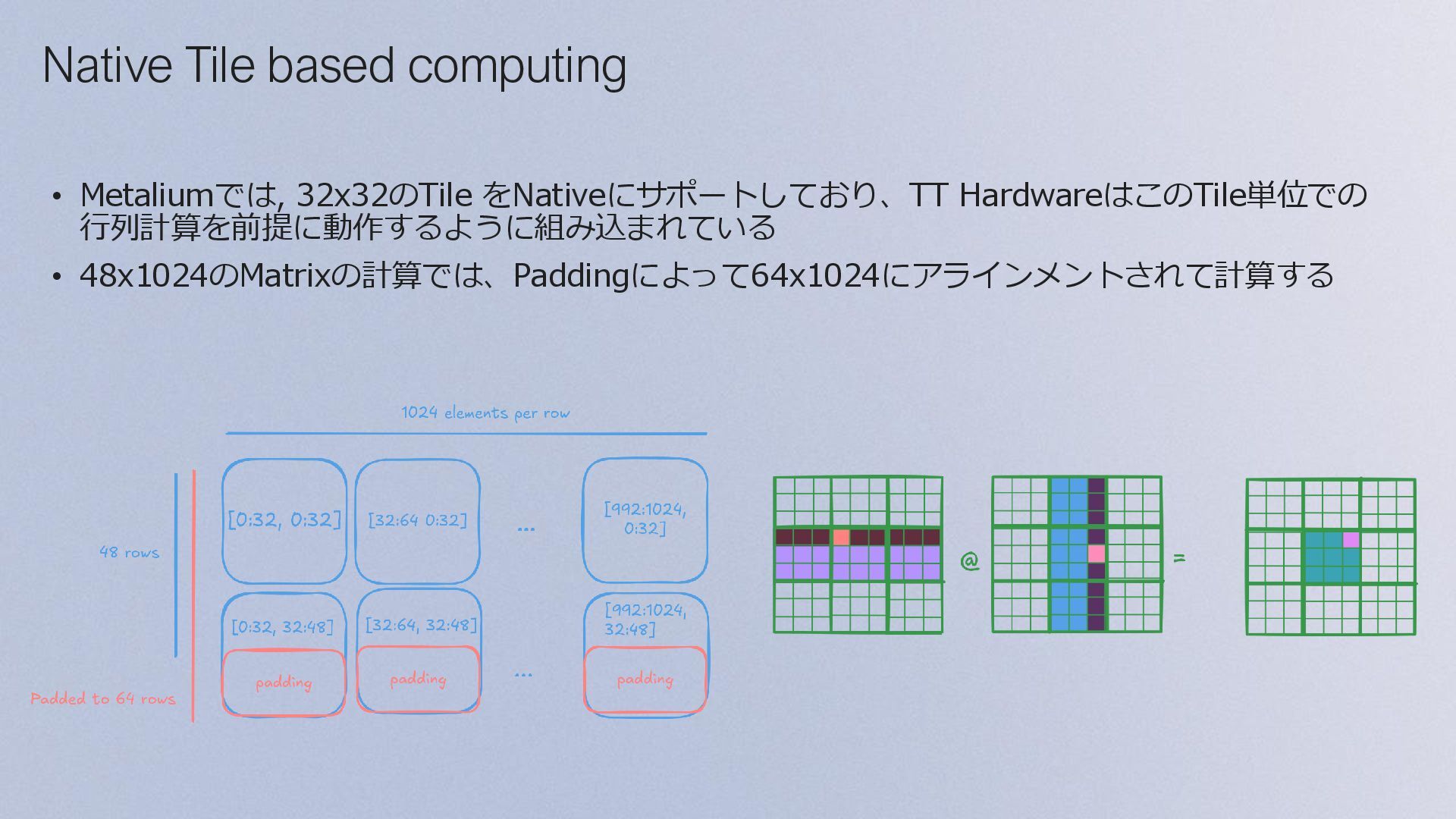
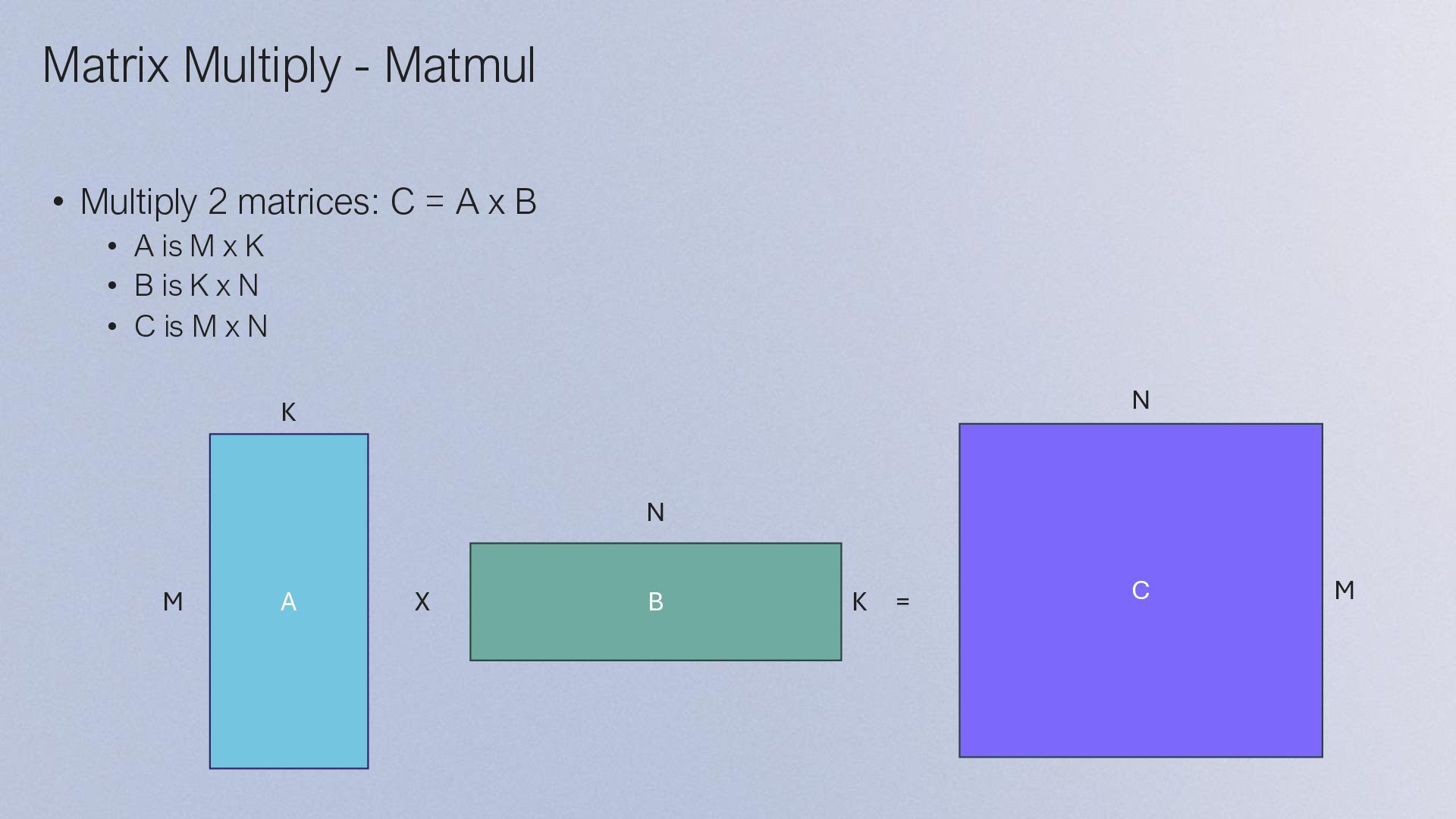
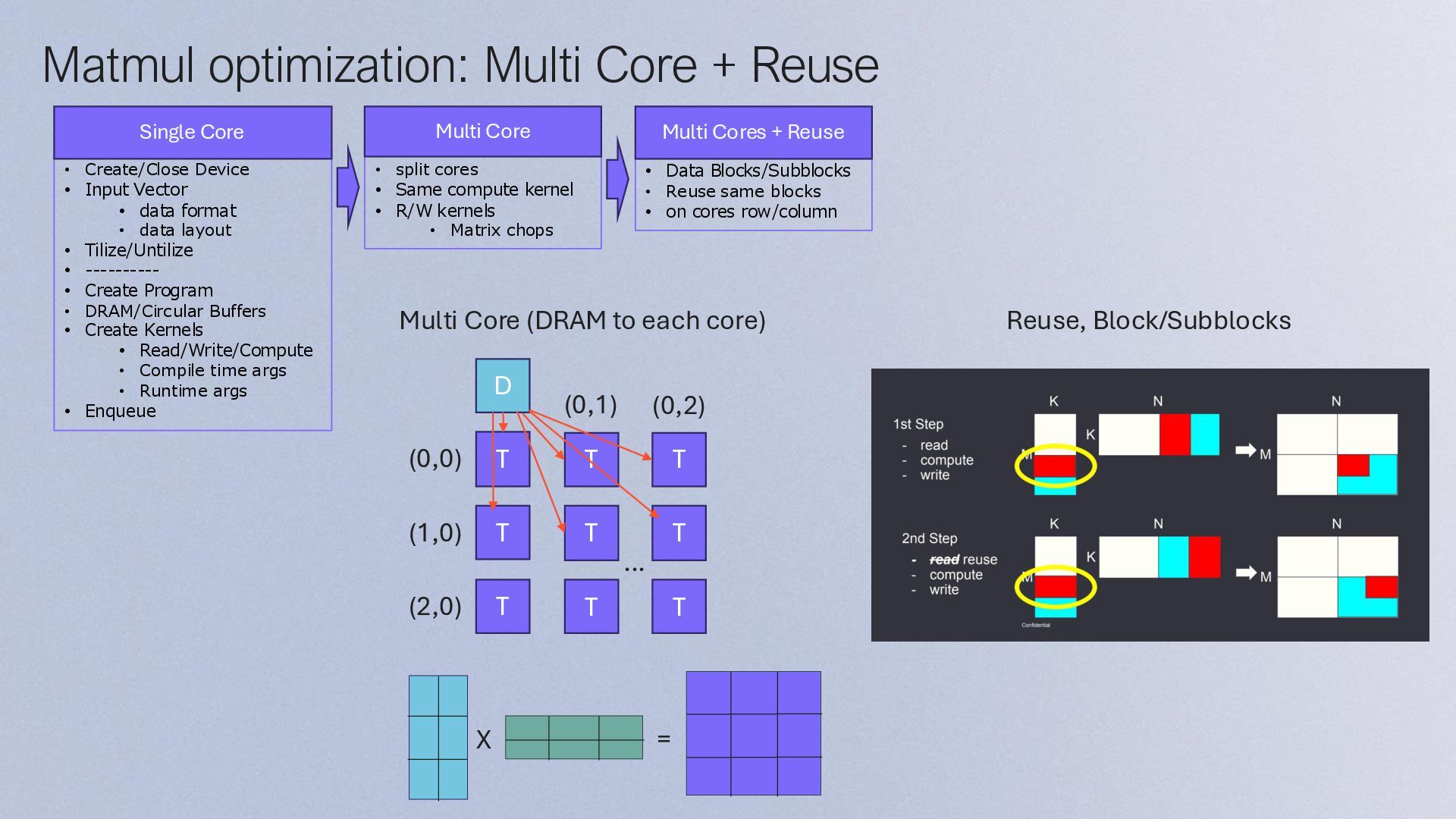
Input Vector • data format • data layout • Tilize/Untilize • ---------- • Create Program • DRAM/Circular Buffers • Create Kernels • Read/Write/Compute • Compile time args • Runtime args • Enqueue • Data Blocks/Subblocks • Reuse same blocks • on cores row/column • split cores • Same compute kernel • R/W kernels • Matrix chops Multi Core Multi Cores + Reuse Multi Core (DRAM to each core) Single Core T T T T T T T T T D (0,0) (1,0) (2,0) (0,1) (0,2) X = Reuse, Block/Subblocks
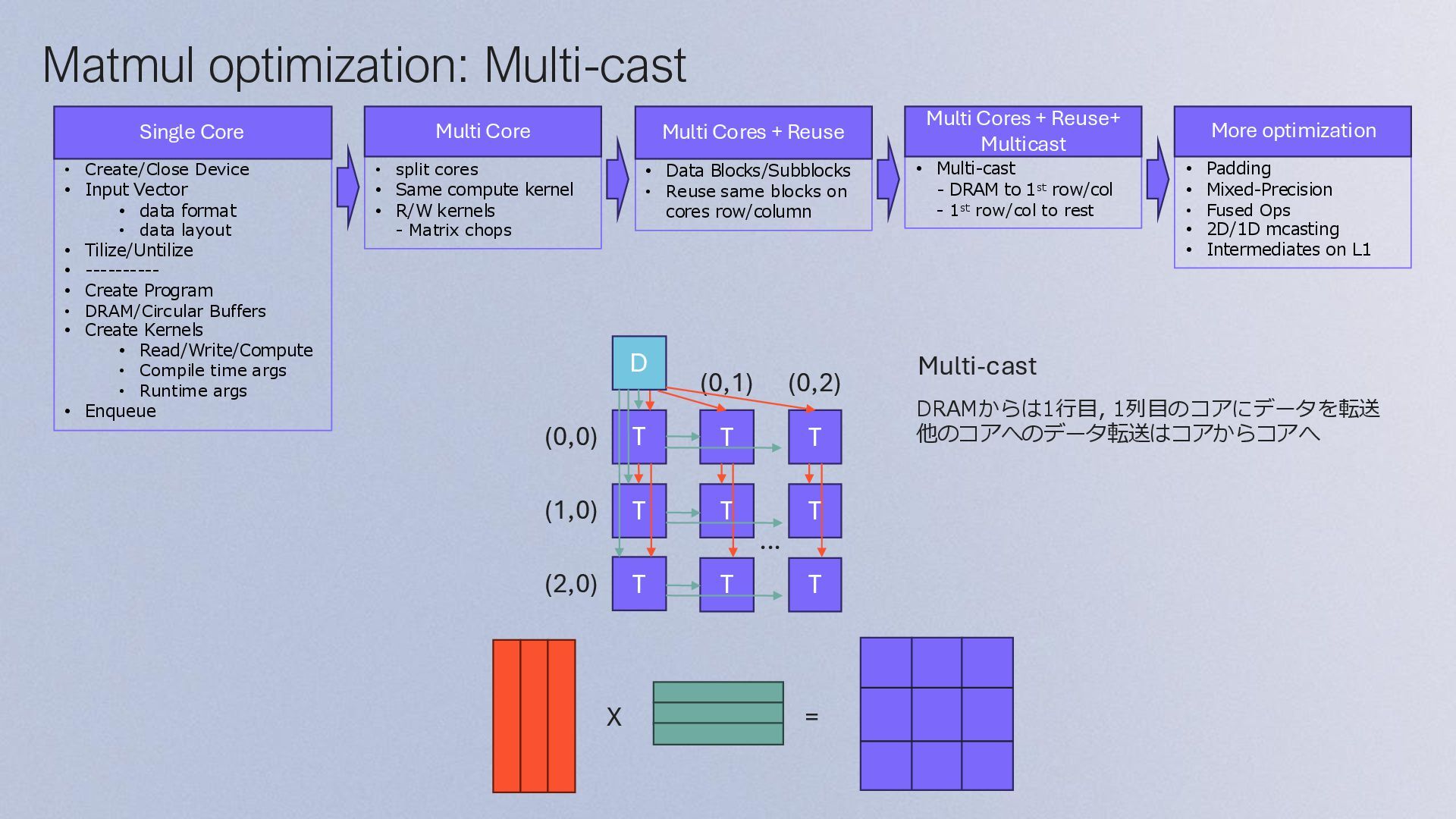
data format • data layout • Tilize/Untilize • ---------- • Create Program • DRAM/Circular Buffers • Create Kernels • Read/Write/Compute • Compile time args • Runtime args • Enqueue Single Core • Data Blocks/Subblocks • Reuse same blocks on cores row/column • split cores • Same compute kernel • R/W kernels - Matrix chops Multi Core Multi Cores + Reuse • Multi-cast - DRAM to 1st row/col - 1st row/col to rest Multi Cores + Reuse+ Multicast • Padding • Mixed-Precision • Fused Ops • 2D/1D mcasting • Intermediates on L1 More optimization Multi-cast T T T T T T T T T D (0,0) (1,0) (2,0) (0,1) (0,2) X = DRAMからは1行目, 1列目のコアにデータを転送 他のコアへのデータ転送はコアからコアへ
• TT-Metalium Tech Reports • Programming Examples • Matmul Example • Matmul SingleCore Example • Matmul MultiCore Example • Matmul MultiCore Optimized Example • tt-isa-documentation • Memory on Tenstorrent by Martin • Tenstorrent Wormhole Series Part7: Bits of the Matmul by Corsix
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
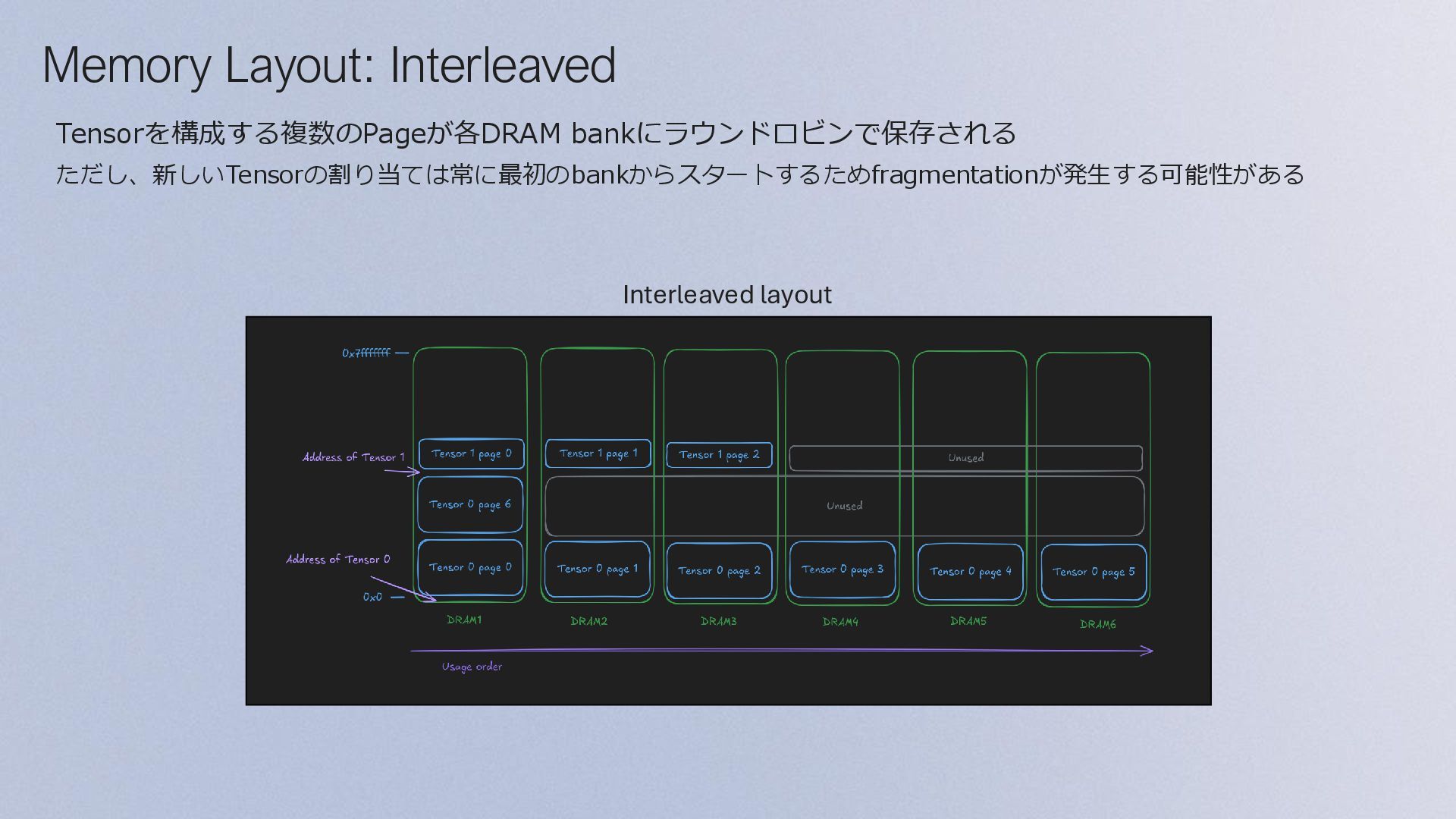
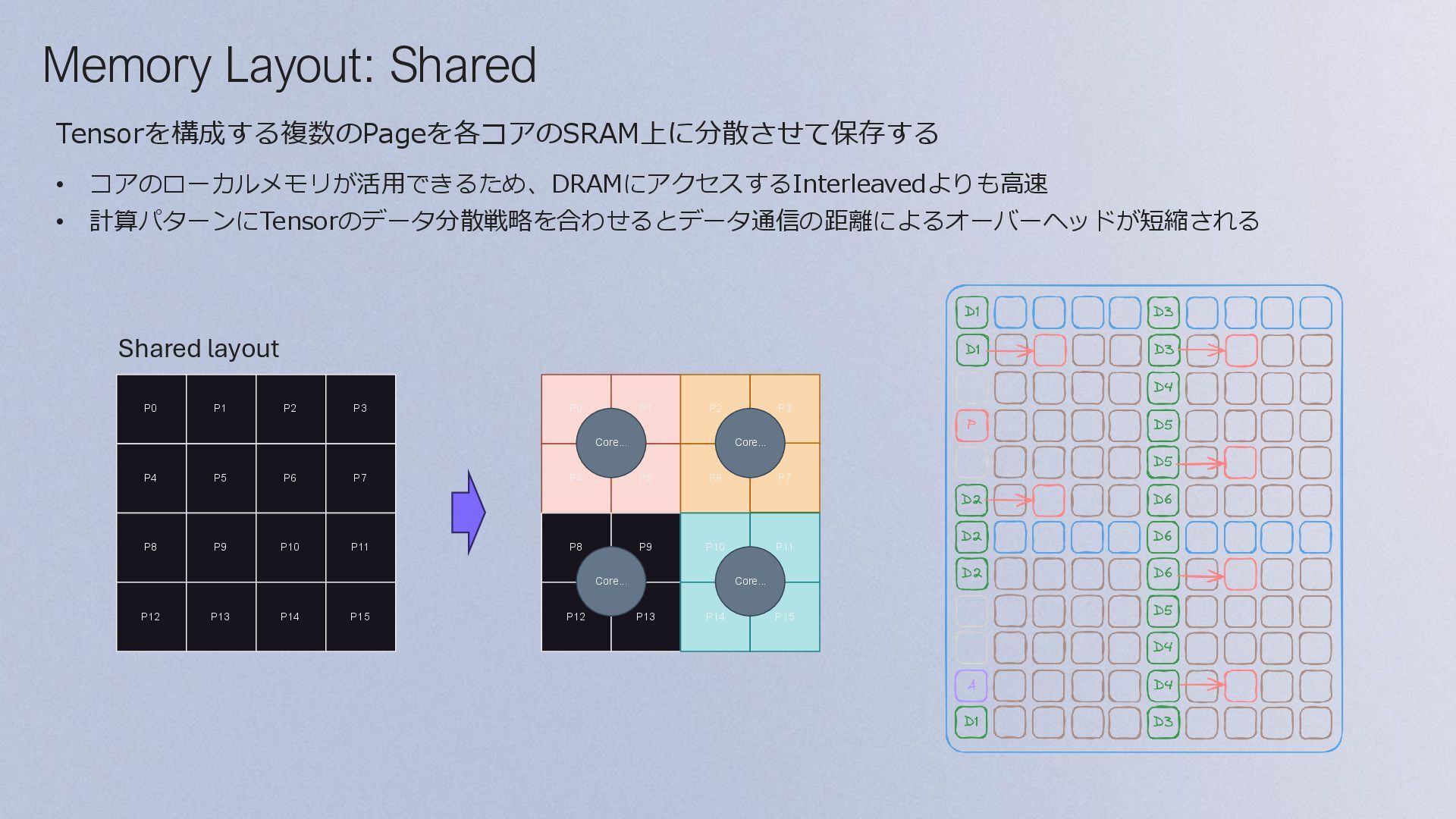
![Tensor Layout Page 0 = [0,0 to 0,63] Page 1](https://files.speakerdeck.com/presentations/8774c59d5ca3458d9614b9748b2eb902/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}