人間の作成した『良い駄洒落』とLLMによる自動生成の『悪い駄洒落』を LLMに“見分けさせる”ことで「駄洒落とは何か?」をLLMに学ばせる ▪ 被験者実験と機械的な評価指標ともに 提案手法は既存手法よりも優れた駄洒落を作れていると評価された ▪ 日本語の駄洒落データベースのみを使用したにも関わらず、 英語の駄洒落の生成に成功した例も見られた 布団が飛ばされた 布団が吹っ飛んだ I shout whenever I notice ice cream I scream when I see ice cream SFT: Supervised Fine-Tuning, 教師ありの標準的な訓練方法。訓練データを真似するように学習する。 DPO: Direct Preference Optimization (Rafailov et al., 2024)。良い例と悪い例の生成される確率差を最大化する訓練方法。
Formalization and Conformance Testing of RABAC Security Policies for Business Processes ◼ has developed a unified and highly automated model-driven framework enabling the formalization and conformance testing of RABAC security policies (covering RBAC, ABAC, and data-driven constraints) for business processes. The framework was experimented with and evaluated in a simulated business process (simulation) and two real- world ones (the loan approval process (LA) and the payment request process (PR)). [experimental results] ◼ has introduced 20 OCL invariant patterns (IPs), including nine RBAC-driven IPs, six ABAC-driven IPs, and five data-driven IPs, to facilitate the formalization of RABAC security policies for processes. ◼ proposed an ABAC metamodel essential to creating ABAC policy representation models for processes. ABAC policies for simulation LA PR No. of rules 5 2 2 Data input manually 72 4 9 Data obtained automatically (symbols) 191 54 43 RBAC policies for simulation LA PR Data input manually 224 50 136 Data obtained automatically (symbols) 1738 382 820 [proposed ABAC metamodel] [proposed framework]
▪ ある時点での人の存在している人数から割合を割り出して,それぞれの位置で適切 なプライバシ保護の度合いを導き,それぞれの位置で適した保護を行う手法を提案 研究事例(プライバシ保護) 人の存在確率を考慮した位置情報プライバシ保護 [1] Miguel et al. Geo-indistinguishability: Differential privacy for location-based systems. In Proceedings of the 2013 ACM SIGSAC conference on Computer & communications security, pp. 901–914, 2013. 人間の存在できる位置 は地図上で限られてい るため,同じ度合いで 保護したとしても,見 破られやすい位置が存 在する!
that tracks vehicles traveling on map • TRAPP[2] : SUMO-based framework to provide a solution in traffic flow problem in a city with decentralized optimization tools Adaptation Plan Policy in Traffic Routing for Priority Vehicle Background • Automated Traffic Routing Problem (ATRP) in urban area • Motivating Problem in Priority Vehicle: • How to avoid traffic congestion • How to handle unexpected situation [1] Wuttke, J., Brun, Y., Gorla, A., & Ramaswamy, J. (2012). Traffic routing for evaluating self-adaptation. ICSE Workshop on Software Engineering for Adaptive and Self-Managing Systems [2] Gerostathopoulos, et al. "TRAPPed in Traffic? A Self-Adaptive Framework for Decentralized Traffic Optimization." 2019 IEEE/ACM 14th International Symposium on Software Engineering for Adaptive and Self-Managing Systems (SEAMS). IEEE, 2019. Using ADASIM: • Reduced the mean travel time 40% - 50% • Maintained adequate level of traffic congestionn Mean travel time Using SUMO: Optimizations: • There is a decrease of trip overhead by 7% • Removing the outliers data
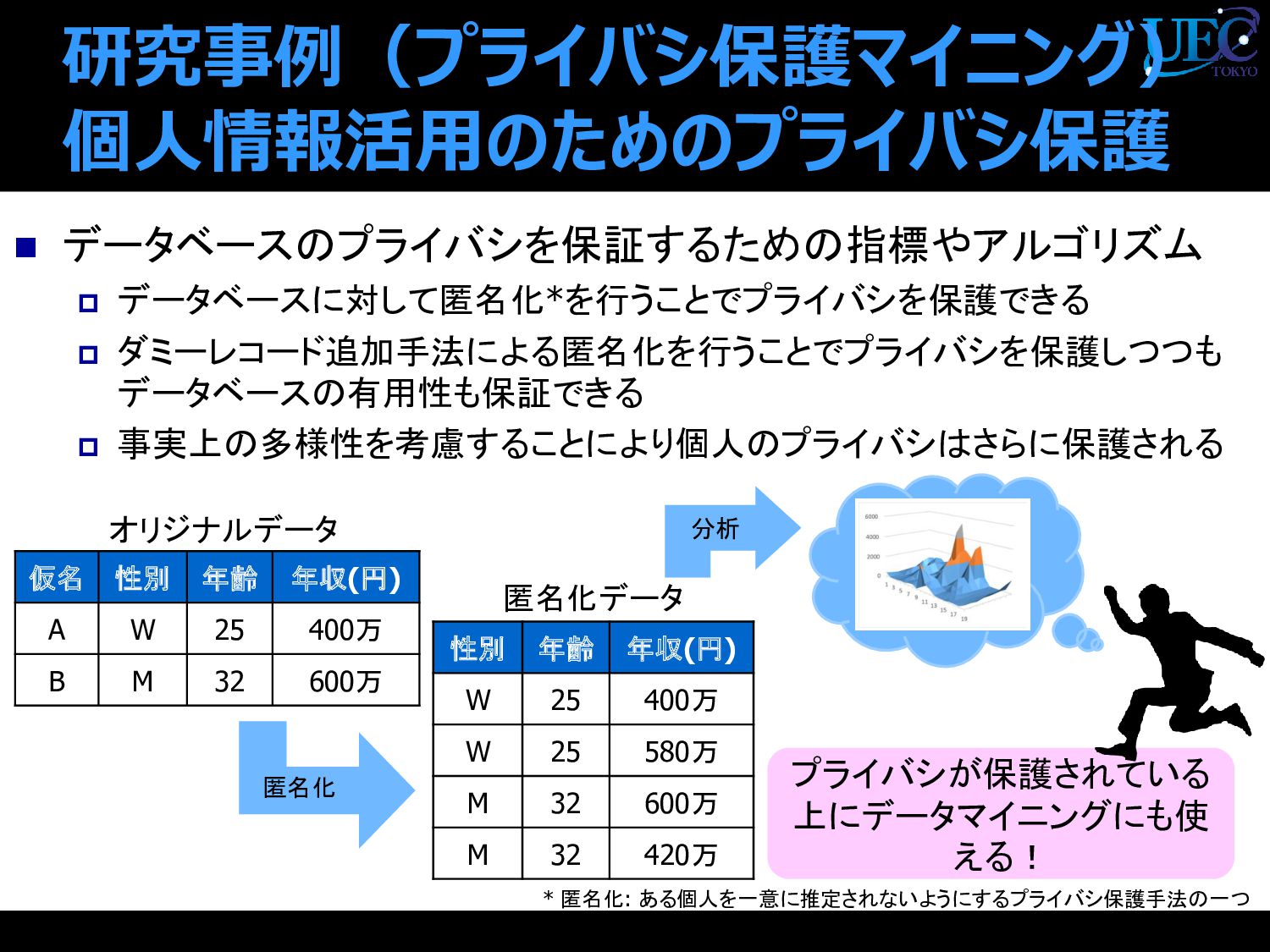
個人情報活用のためのプライバシ保護 * 匿名化: ある個人を一意に推定されないようにするプライバシ保護手法の一つ 仮名 性別 年齢 年収(円) A W 25 400万 B M 32 600万 性別 年齢 年収(円) W 25 400万 W 25 580万 M 32 600万 M 32 420万 オリジナルデータ 匿名化データ プライバシが保護されている 上にデータマイニングにも使 える! 匿名化 分析
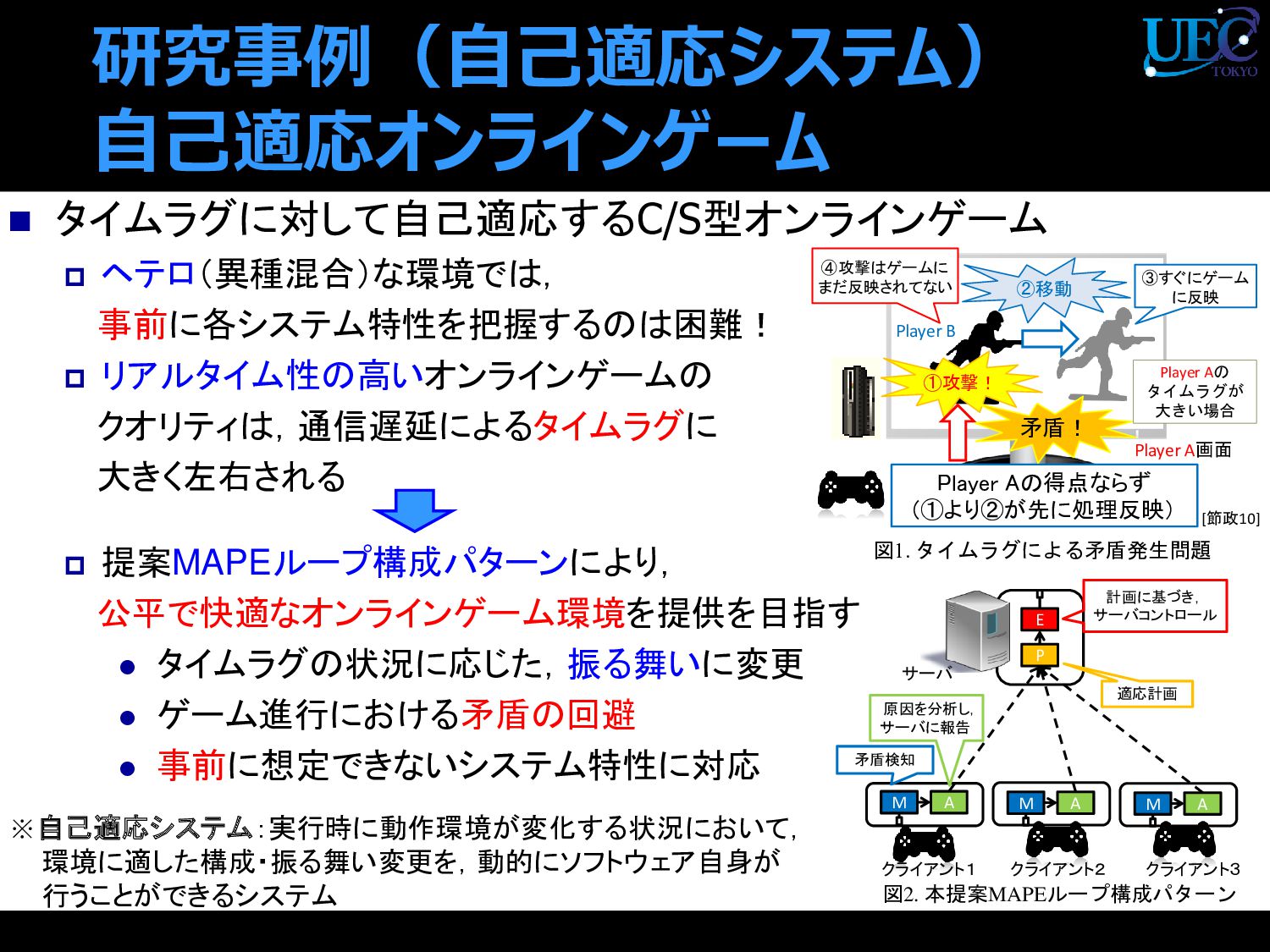
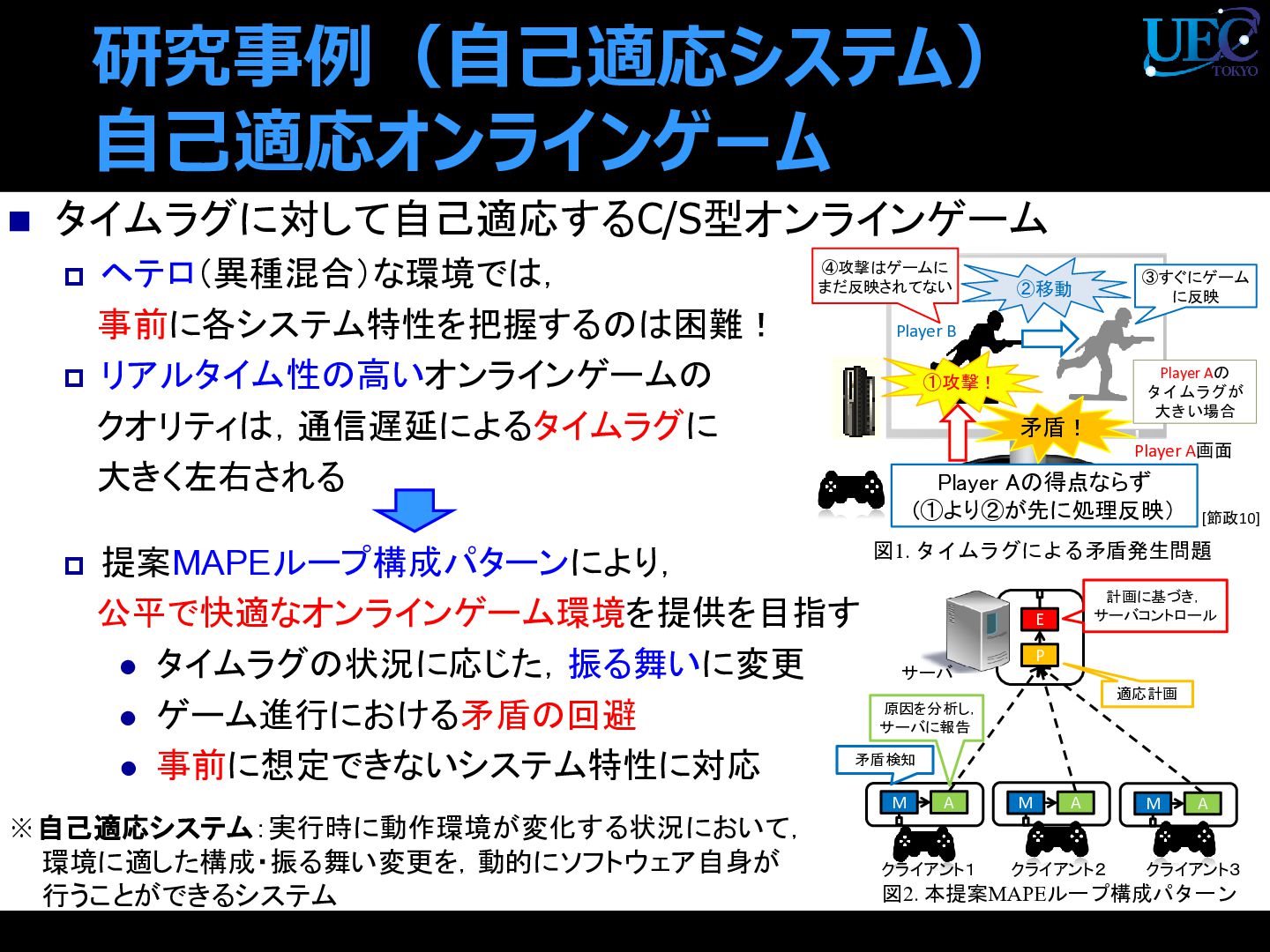
提案MAPEループ構成パターンにより, 公平で快適なオンラインゲーム環境を提供を目指す ⚫ タイムラグの状況に応じた,振る舞いに変更 ⚫ ゲーム進行における矛盾の回避 ⚫ 事前に想定できないシステム特性に対応 研究事例(自己適応システム) 自己適応オンラインゲーム 図1. タイムラグによる矛盾発生問題 図2. 本提案MAPEループ構成パターン E M A P M A M A クライアント1 クライアント2 クライアント3 サーバ 計画に基づき, サーバコントロール 矛盾検知 適応計画 原因を分析し, サーバに報告 Player A画面 ①攻撃! ②移動 Player Aの得点ならず (①より②が先に処理反映) Player B ④攻撃はゲームに まだ反映されてない 矛盾! ③すぐにゲーム に反映 [節政10] Player Aの タイムラグが 大きい場合 ※自己適応システム:実行時に動作環境が変化する状況において, 環境に適した構成・振る舞い変更を,動的にソフトウェア自身が 行うことができるシステム
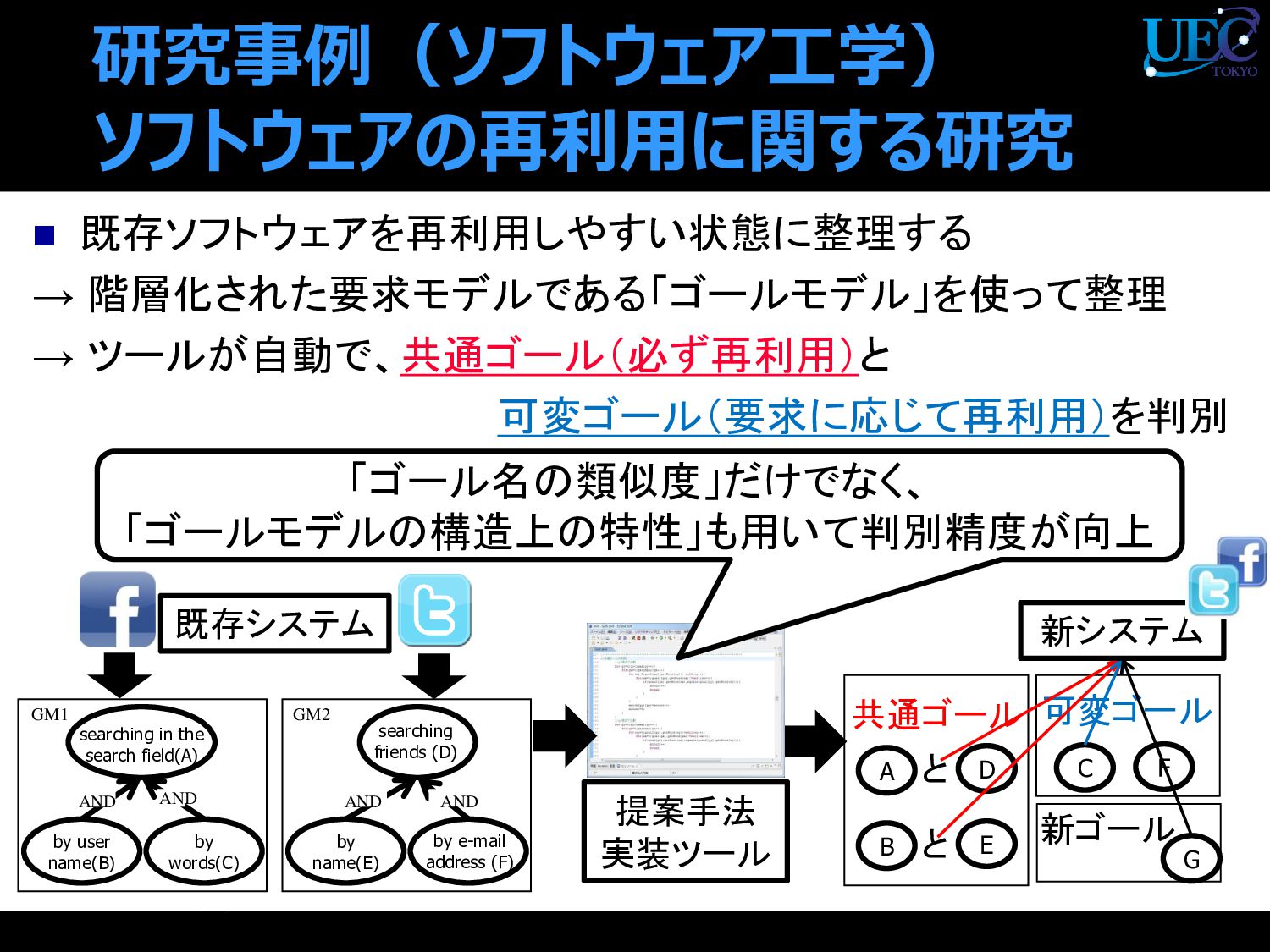
A D 共通ゴール C 可変ゴール と B E と F 提案手法 実装ツール 0 searching in the search field(A) by user name(B) AND AND by words(C) searching friends (D) by name(E) AND AND by e-mail address (F) GM1 GM2 「ゴール名の類似度」だけでなく、 「ゴールモデルの構造上の特性」も用いて判別精度が向上 http://netdna.copyblogger.com/images/flogo.jpg 新ゴール G 新システム 既存システム
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
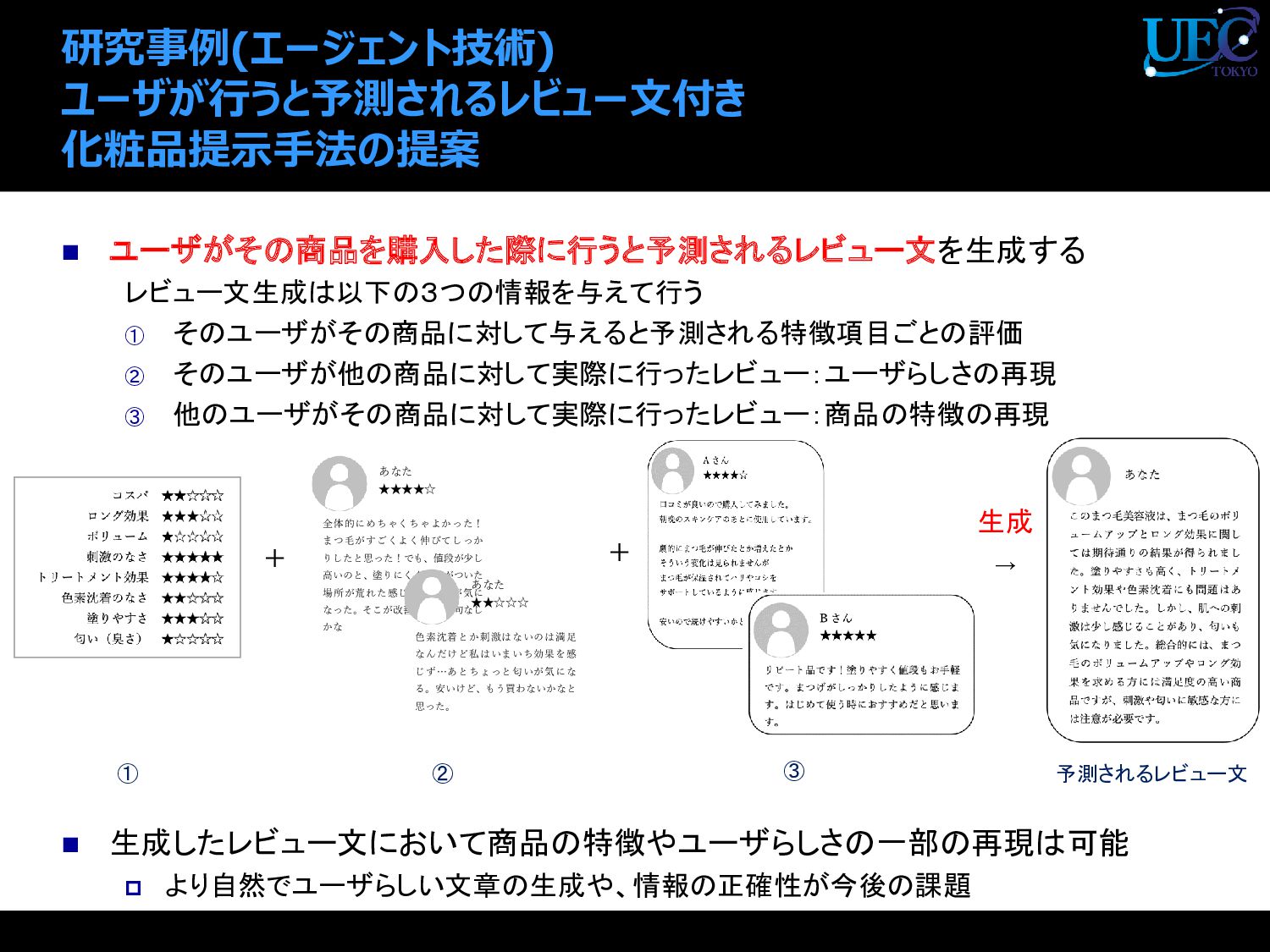{kind=link}
{kind=link}
{kind=link}
{kind=link}
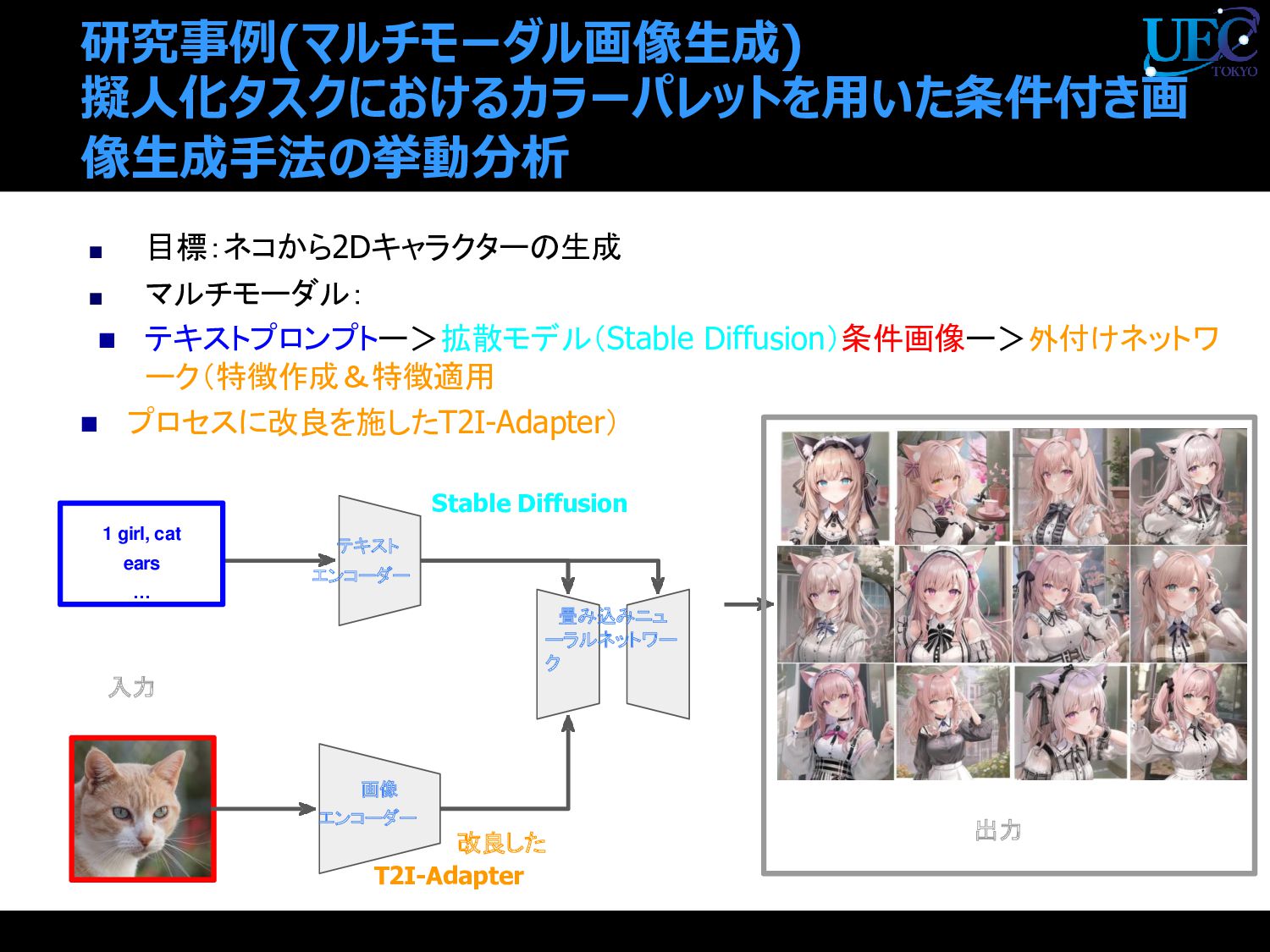{kind=link}
{kind=link}
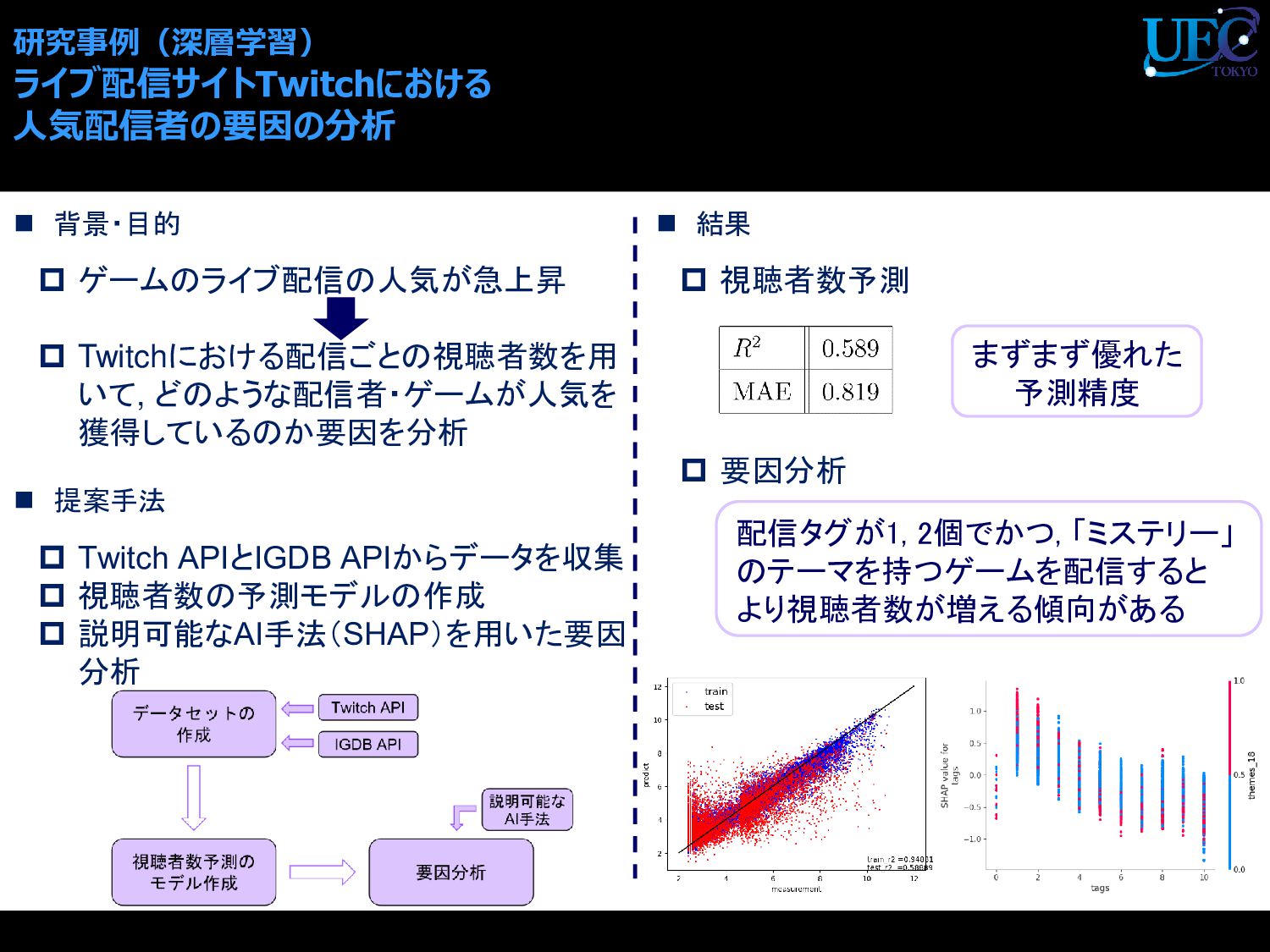{kind=link}
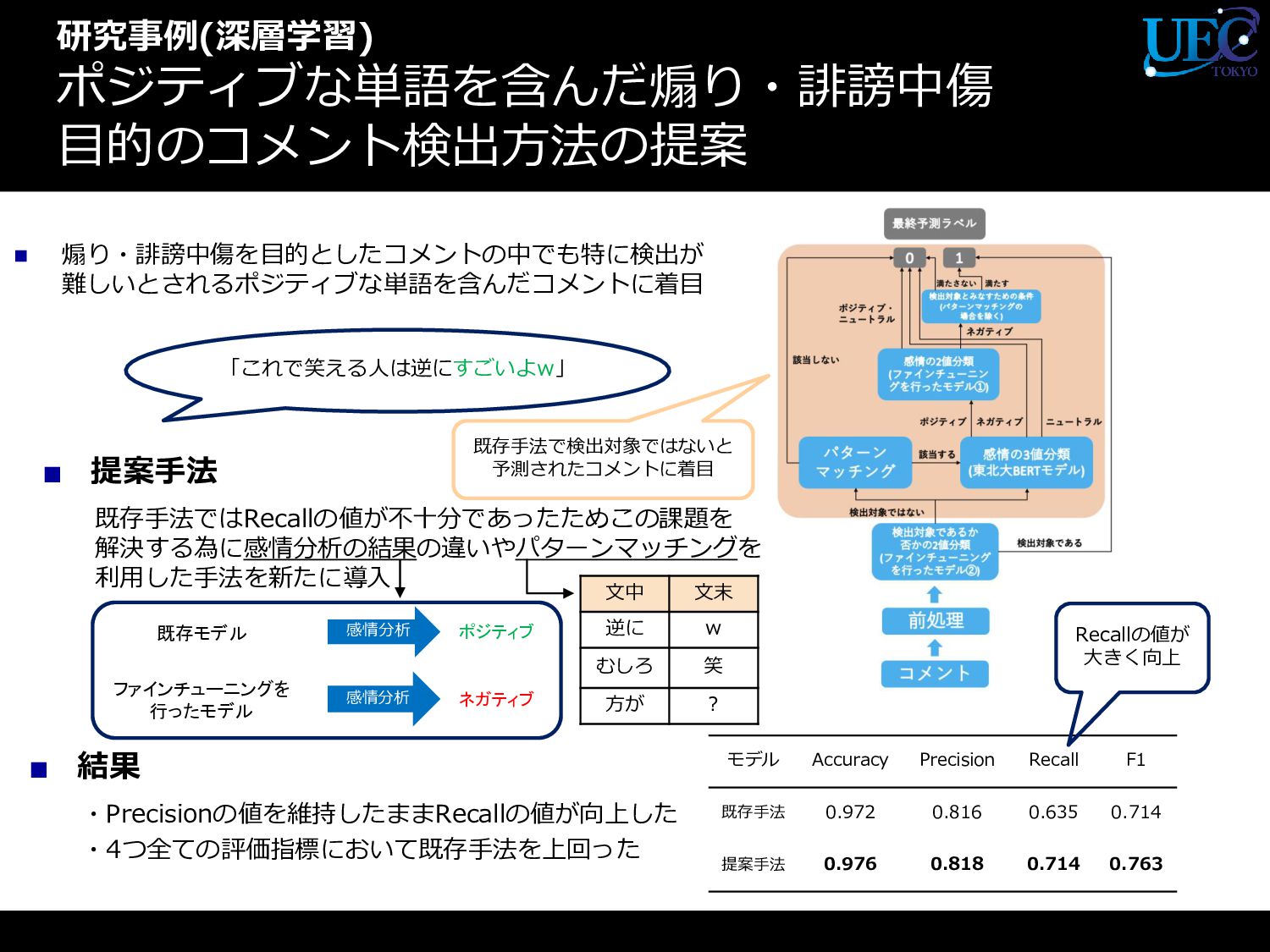{kind=link}
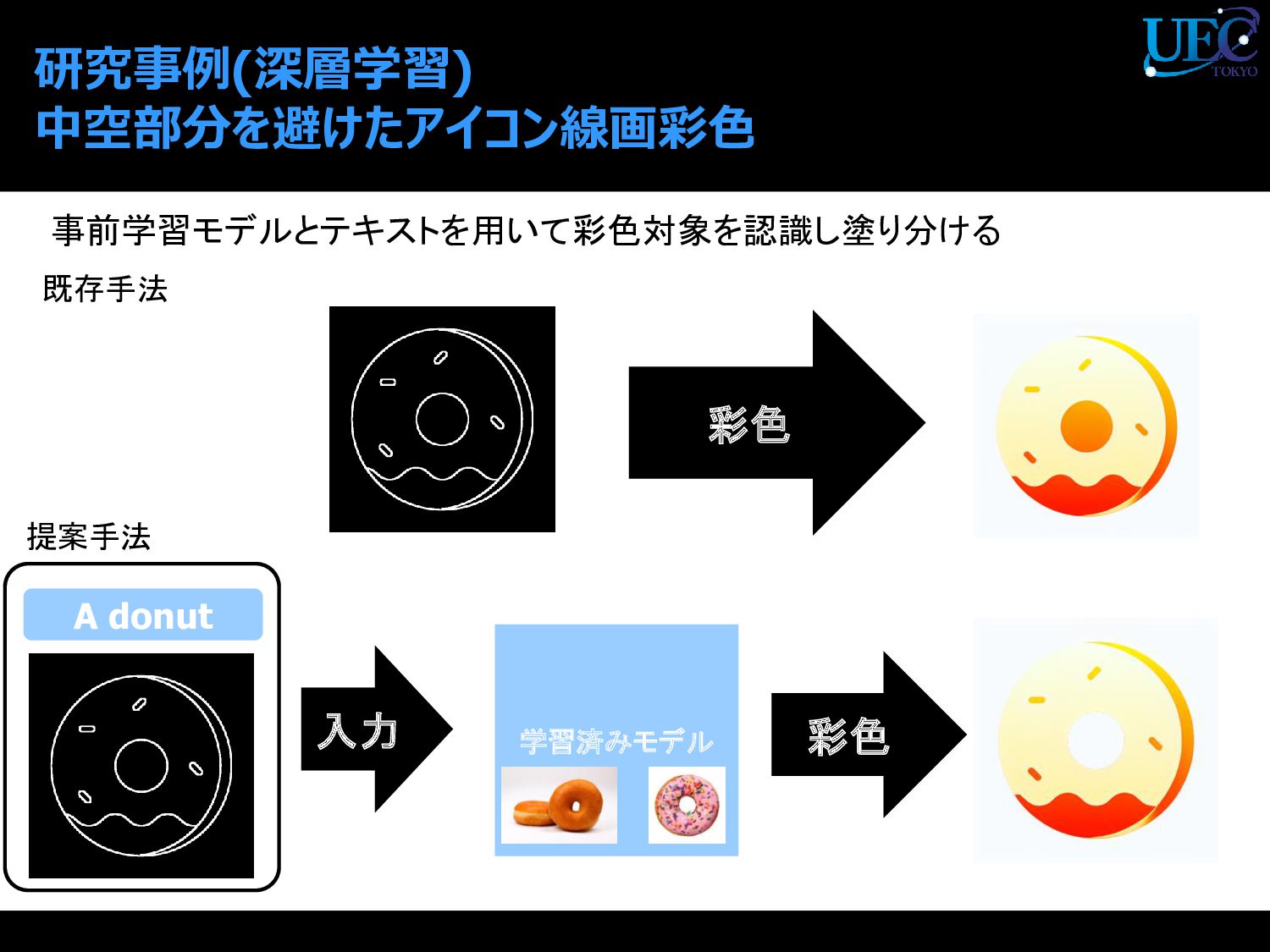{kind=link}
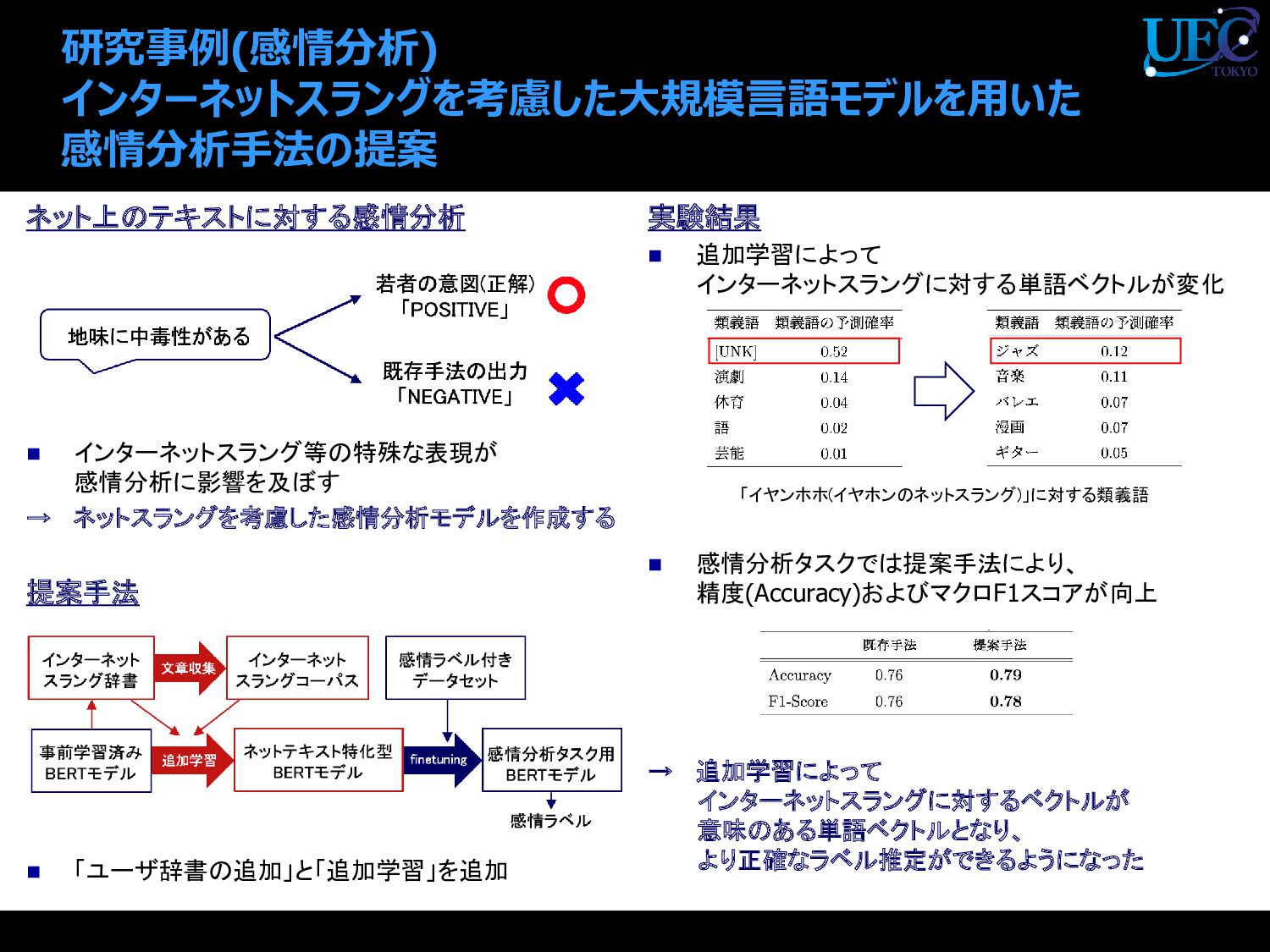{kind=link}
![研究事例(深層強化学習) ゼロショット協調と介入率を考慮した 深層強化学習による格闘ゲームサポートAI ◼ 格闘ゲームで連敗し、飽きてプレイをやめてしまうプレイヤを減らすために格闘 ゲームのサポートAIを提案 学習を共にしていなかった人間プレイヤの支援が必要 [学習結果] [被験者実験]](https://files.speakerdeck.com/presentations/0d30923de3d845e7a84b2ce833c0920e/slide_16.jpg){kind=link}
{kind=link}
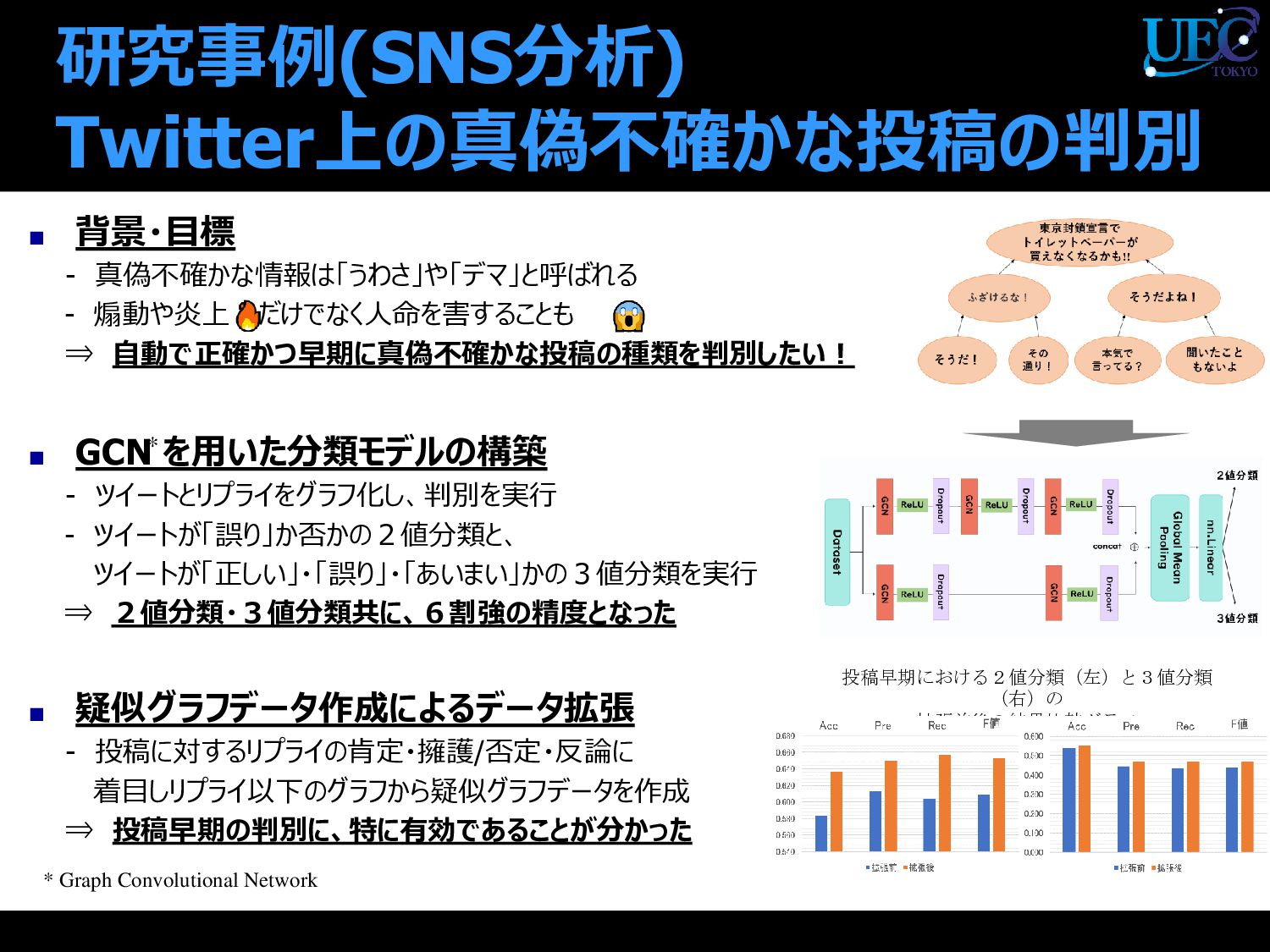{kind=link}
{kind=link}
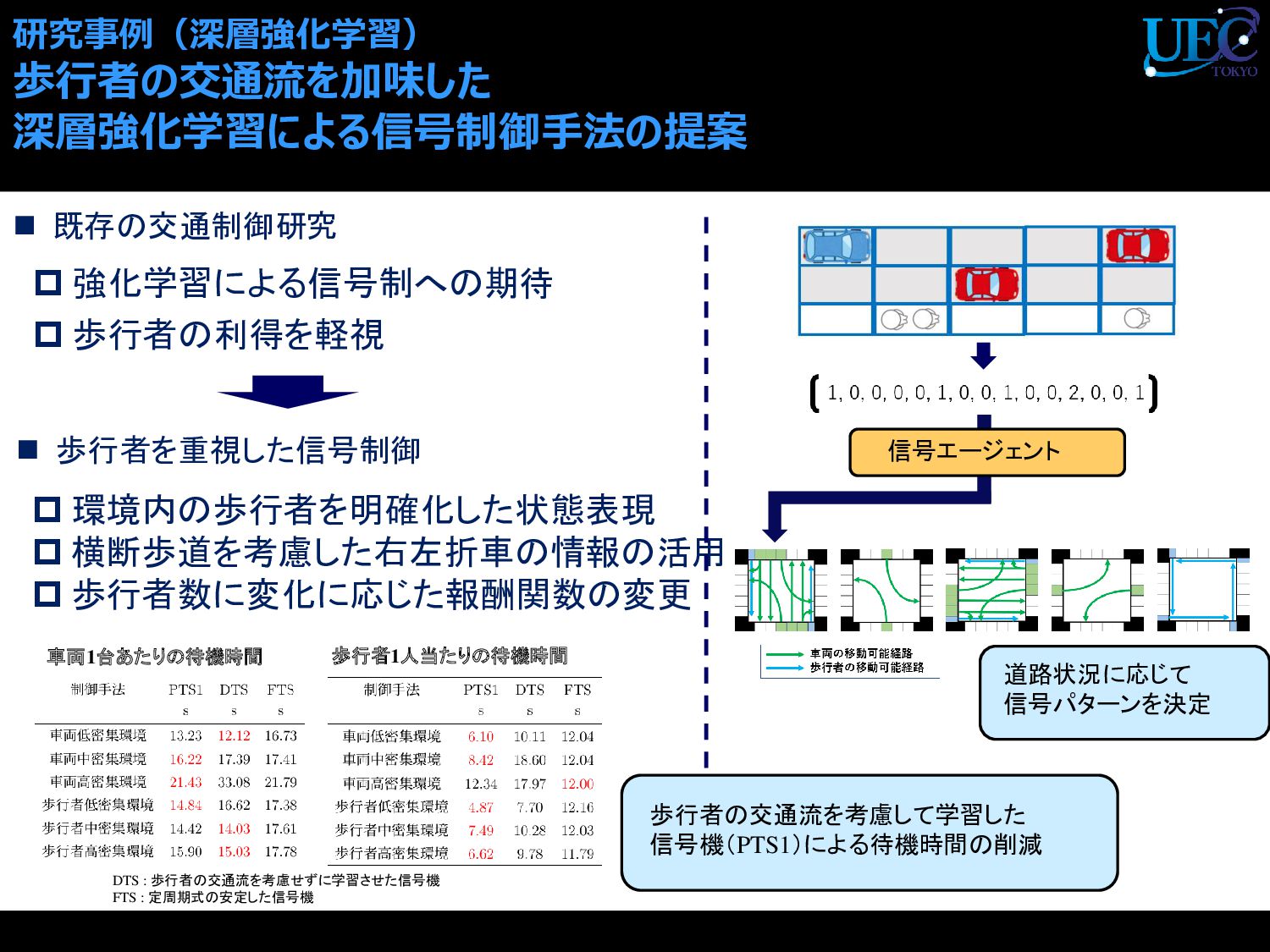{kind=link}
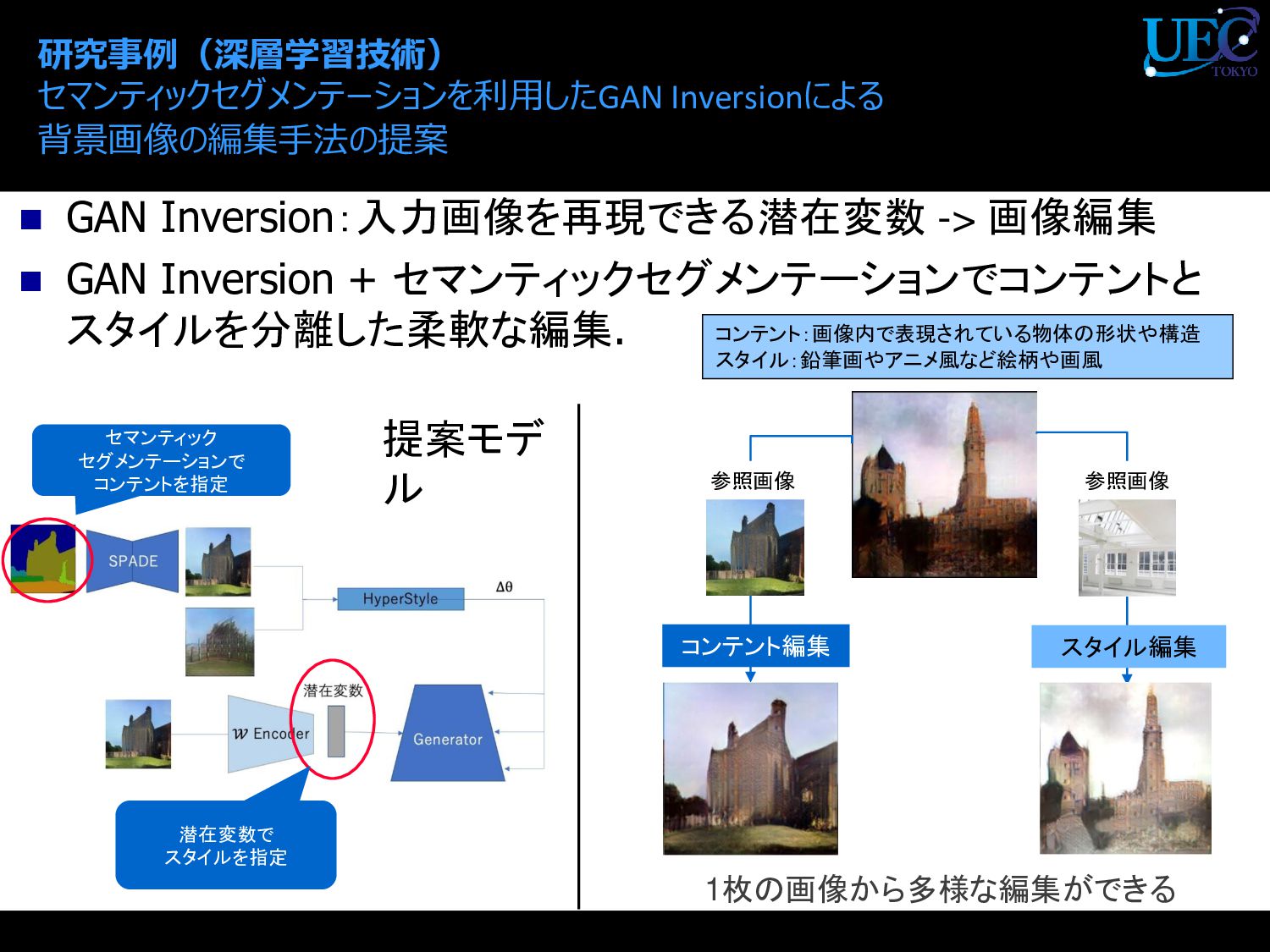{kind=link}
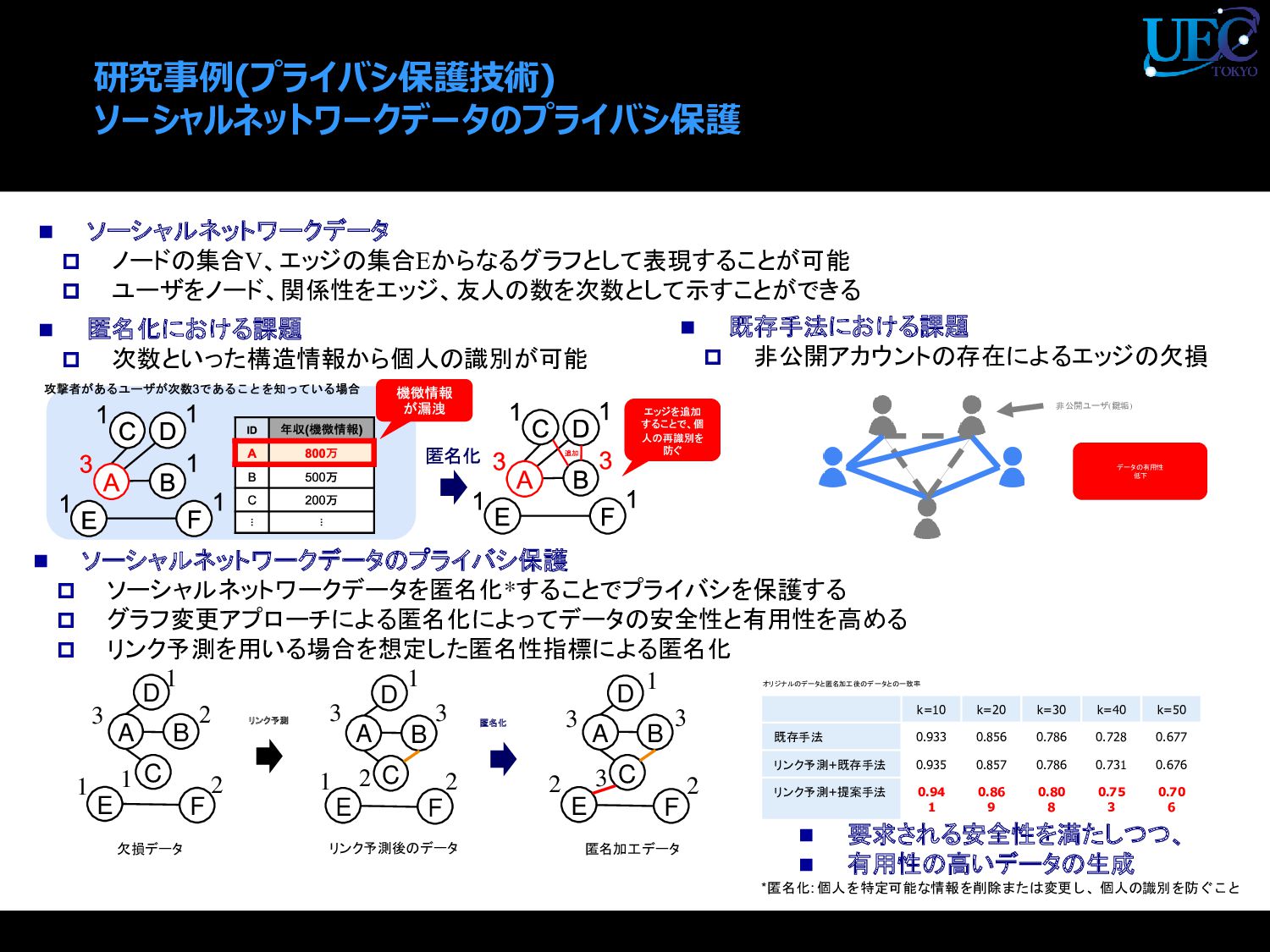{kind=link}
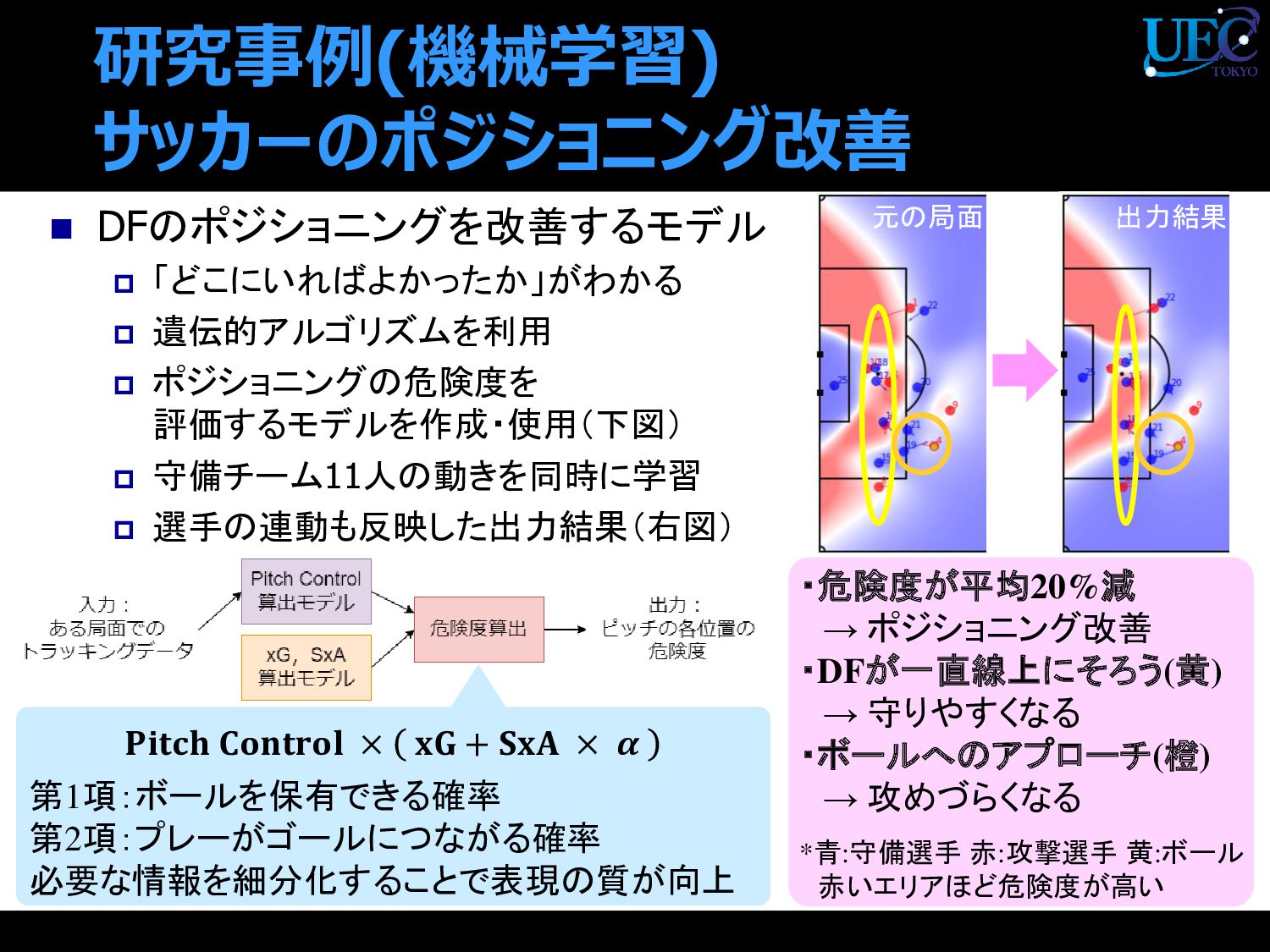{kind=link}
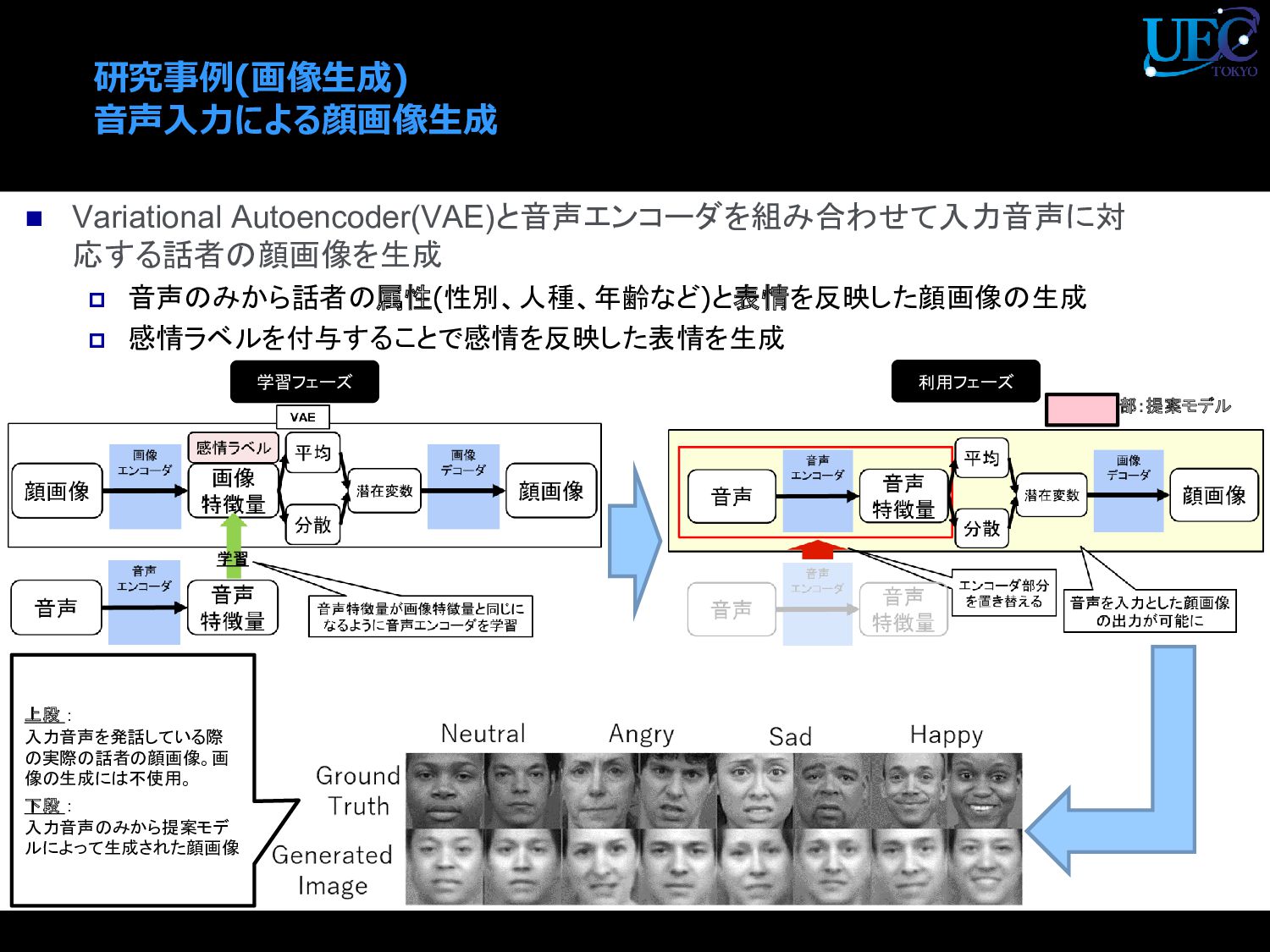{kind=link}
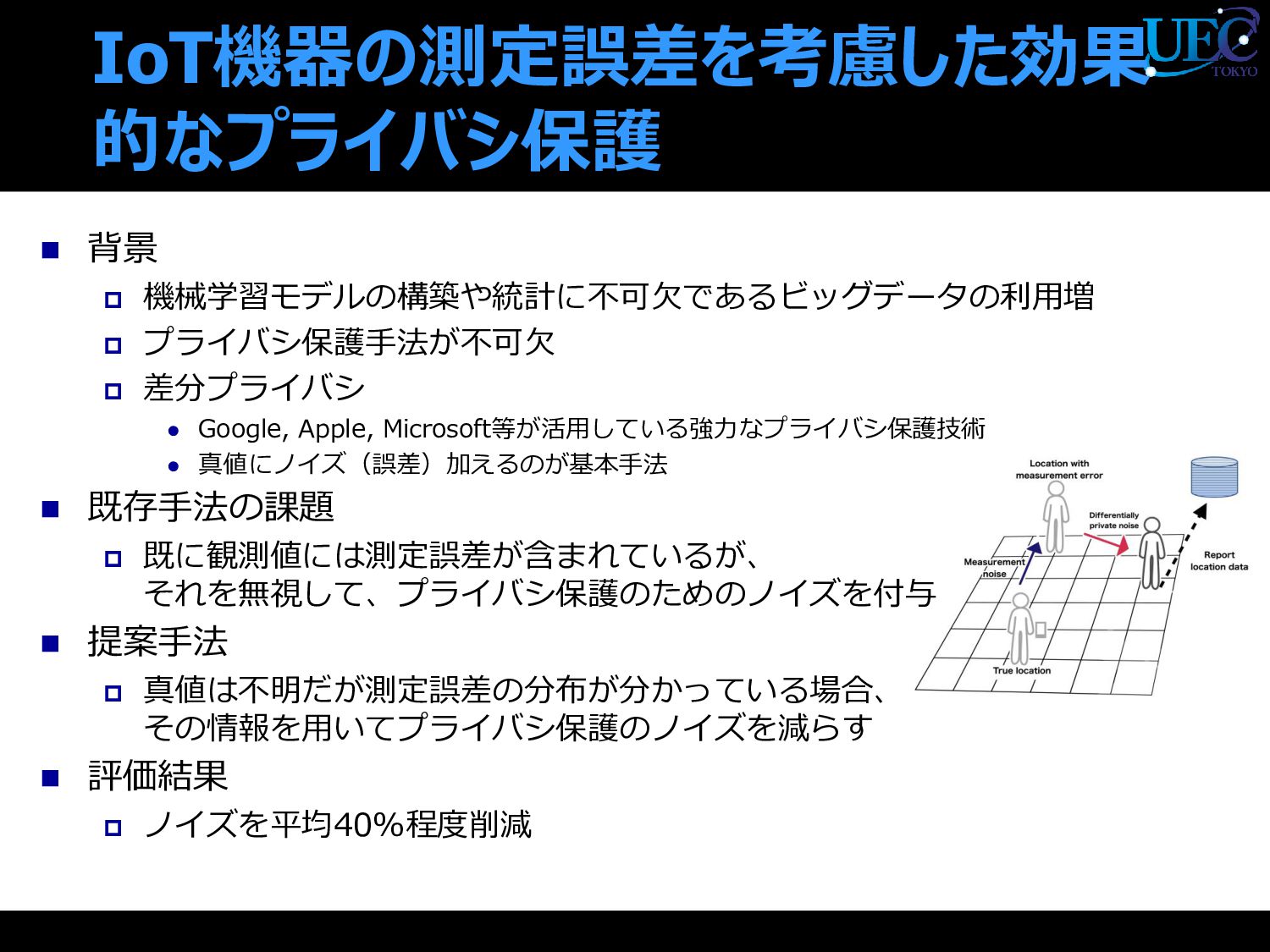
![▪ 直接的にユーザの位置情報を公開していなくても,ユーザの位置情報を用いて統計 処理を行なった値から個人を特定できる場合がある ▪ ユーザの位置情報に誤差(ノイズ)を加えてデータベースに保存し統計処理を行うこ とによって,真の位置を見破ることが難しくなる一定のプライバシ基準を満たすこ とが可能(Geo-Indistinguishability)[1] ▪ 位置の性質によって必要なプライバシ保護の度合いは異なるが,プライバシの保護 の度合いを単純に大きくすると誤差も大きくなるためデータの有用性が低下する](https://files.speakerdeck.com/presentations/0d30923de3d845e7a84b2ce833c0920e/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
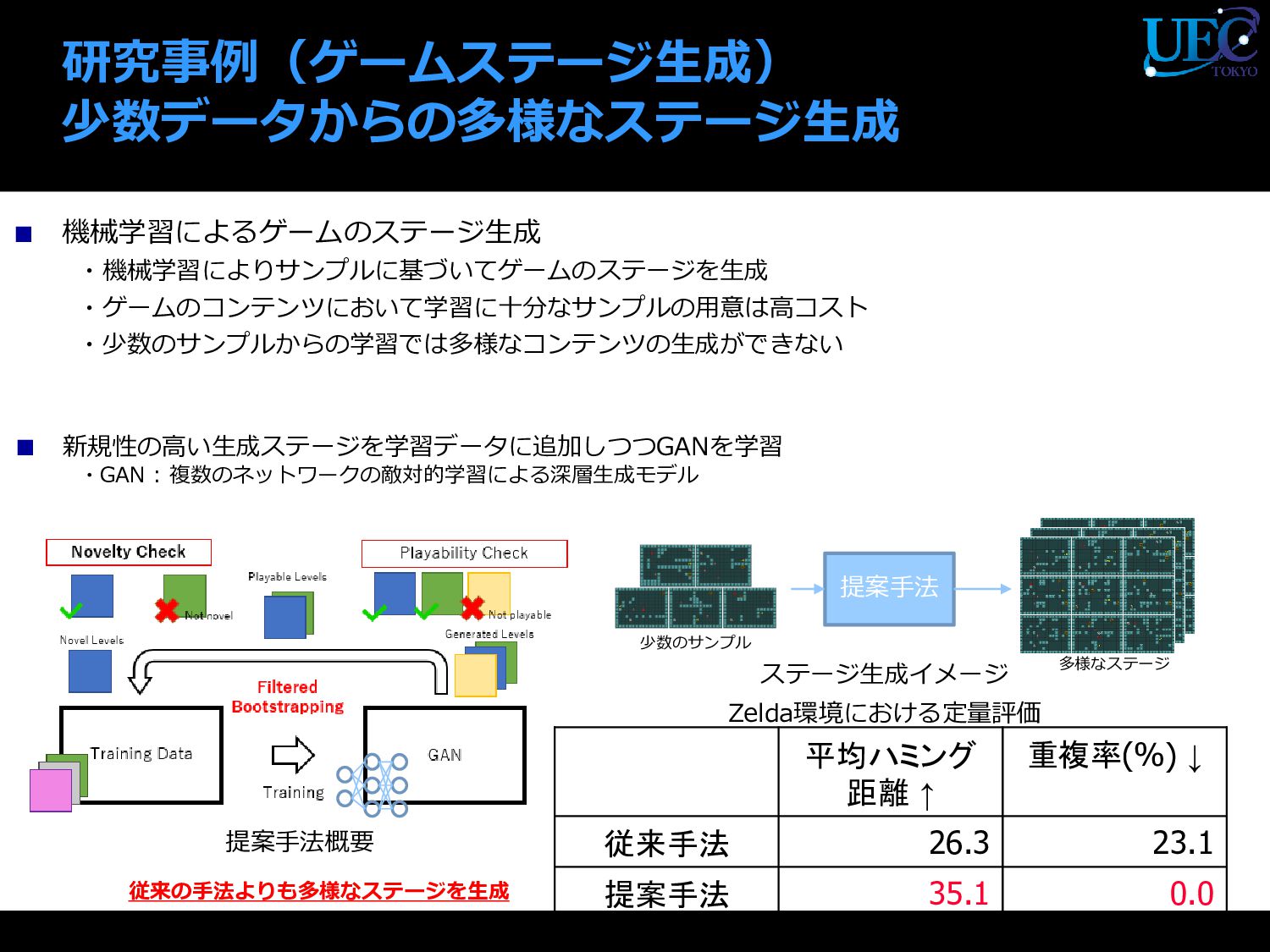{kind=link}
{kind=link}
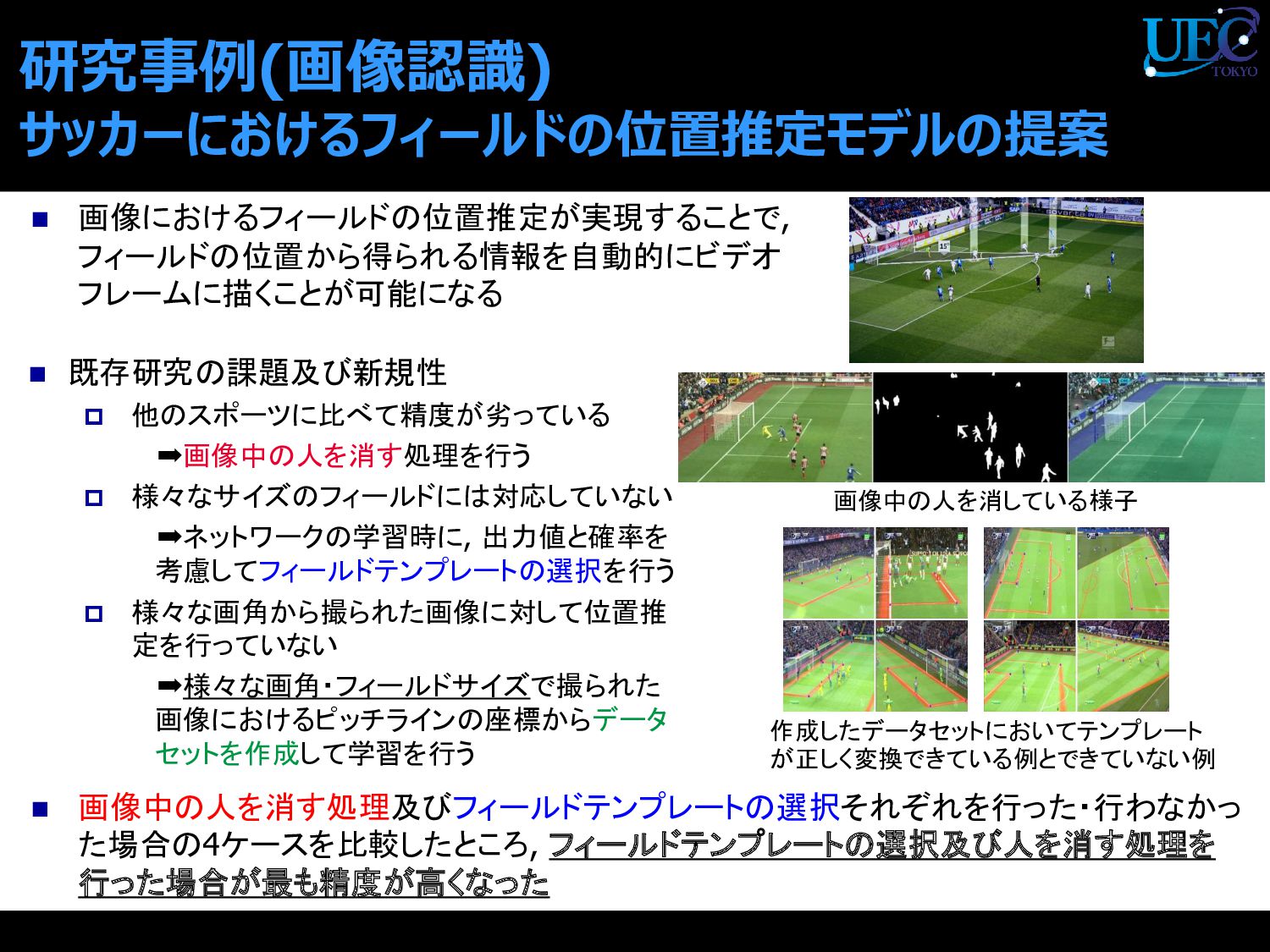{kind=link}
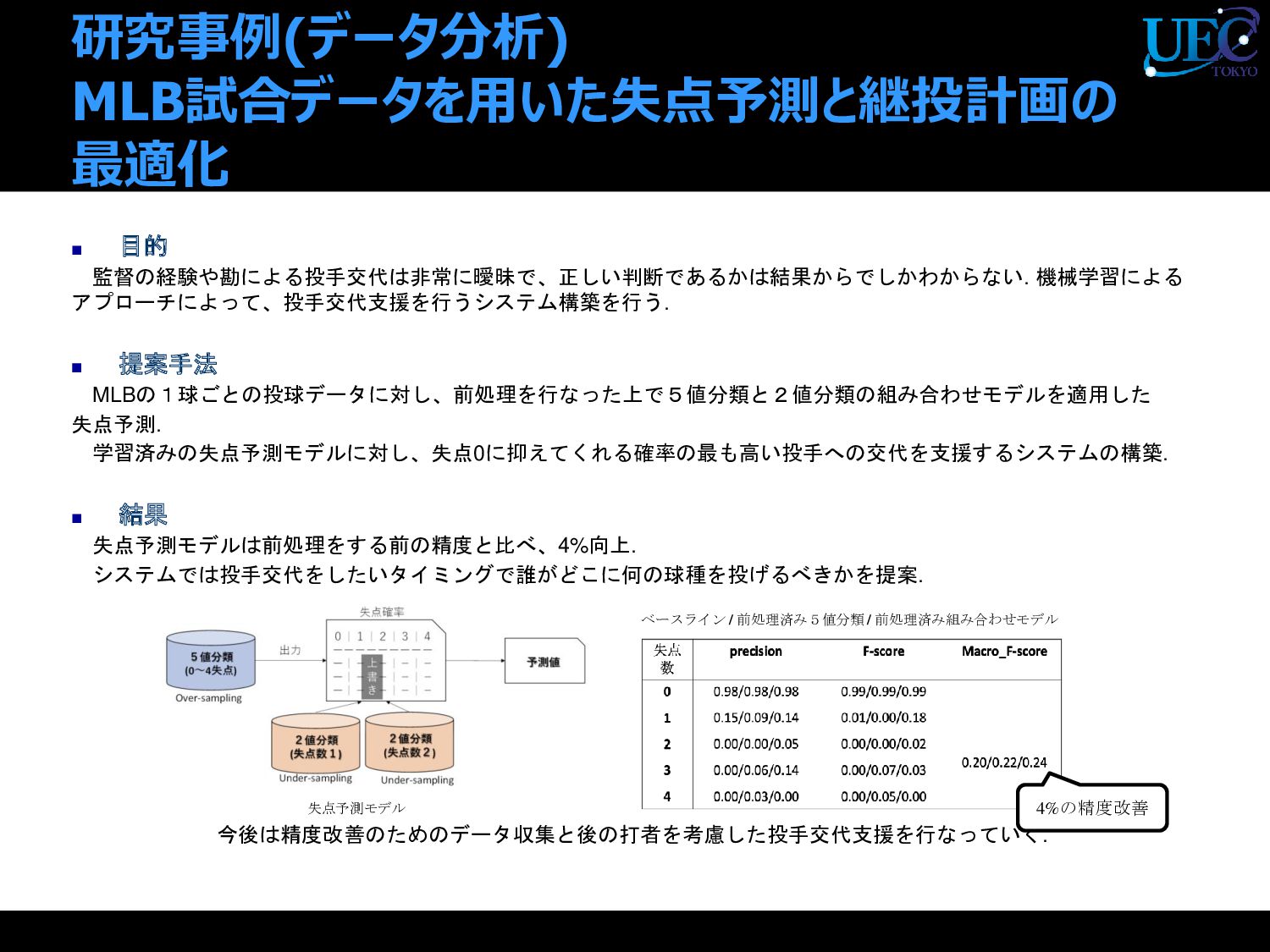{kind=link}
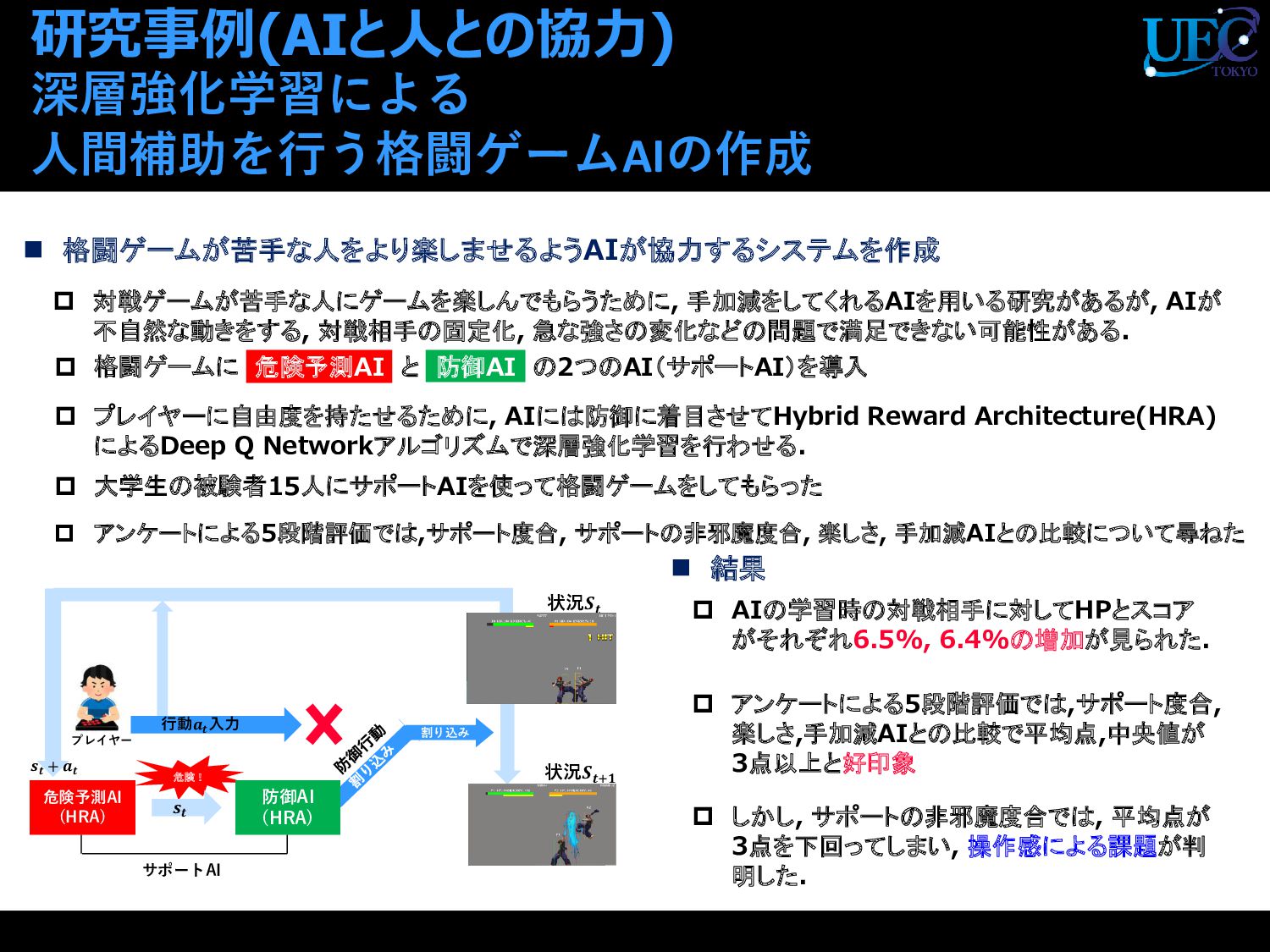{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
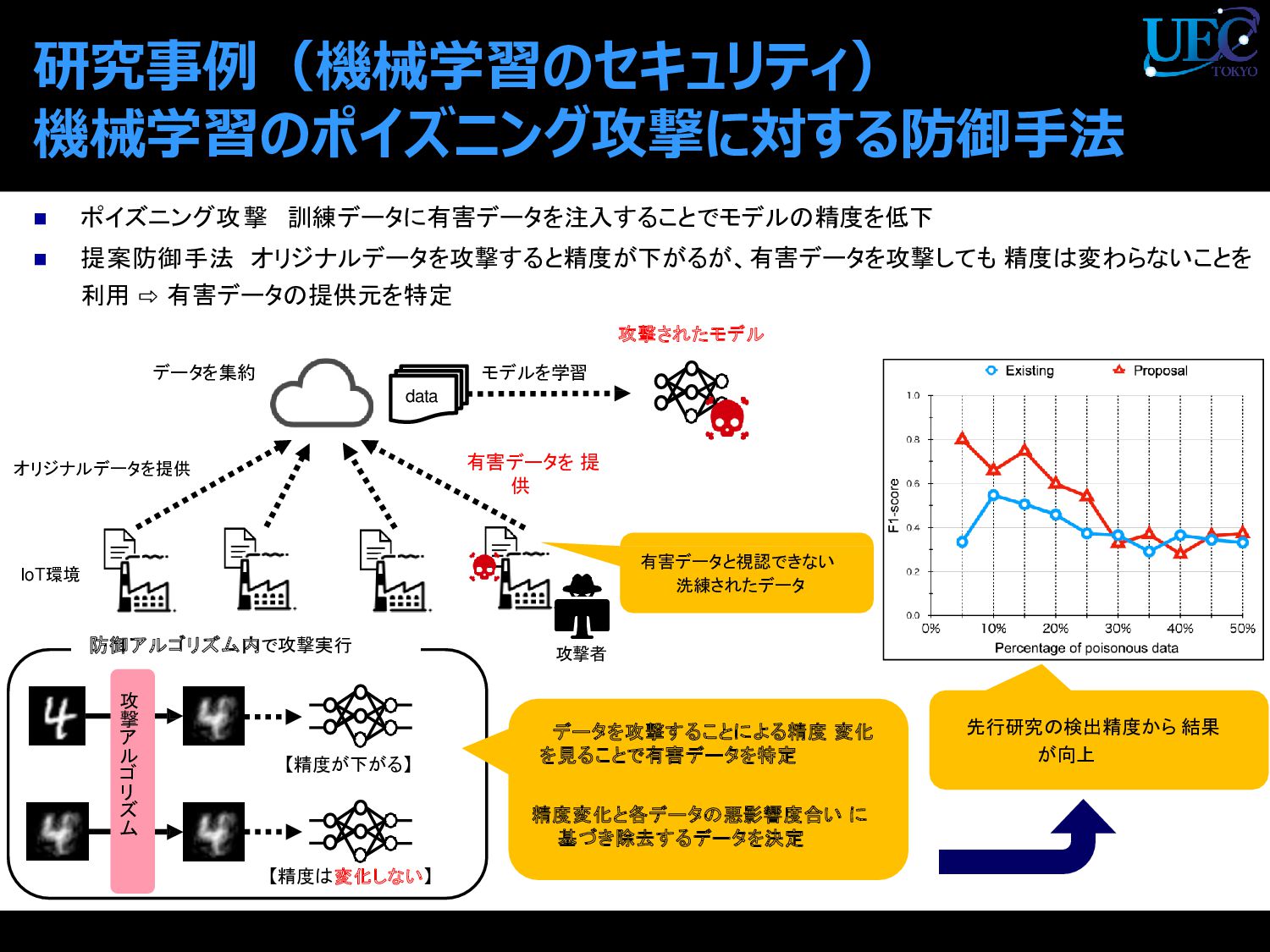{kind=link}
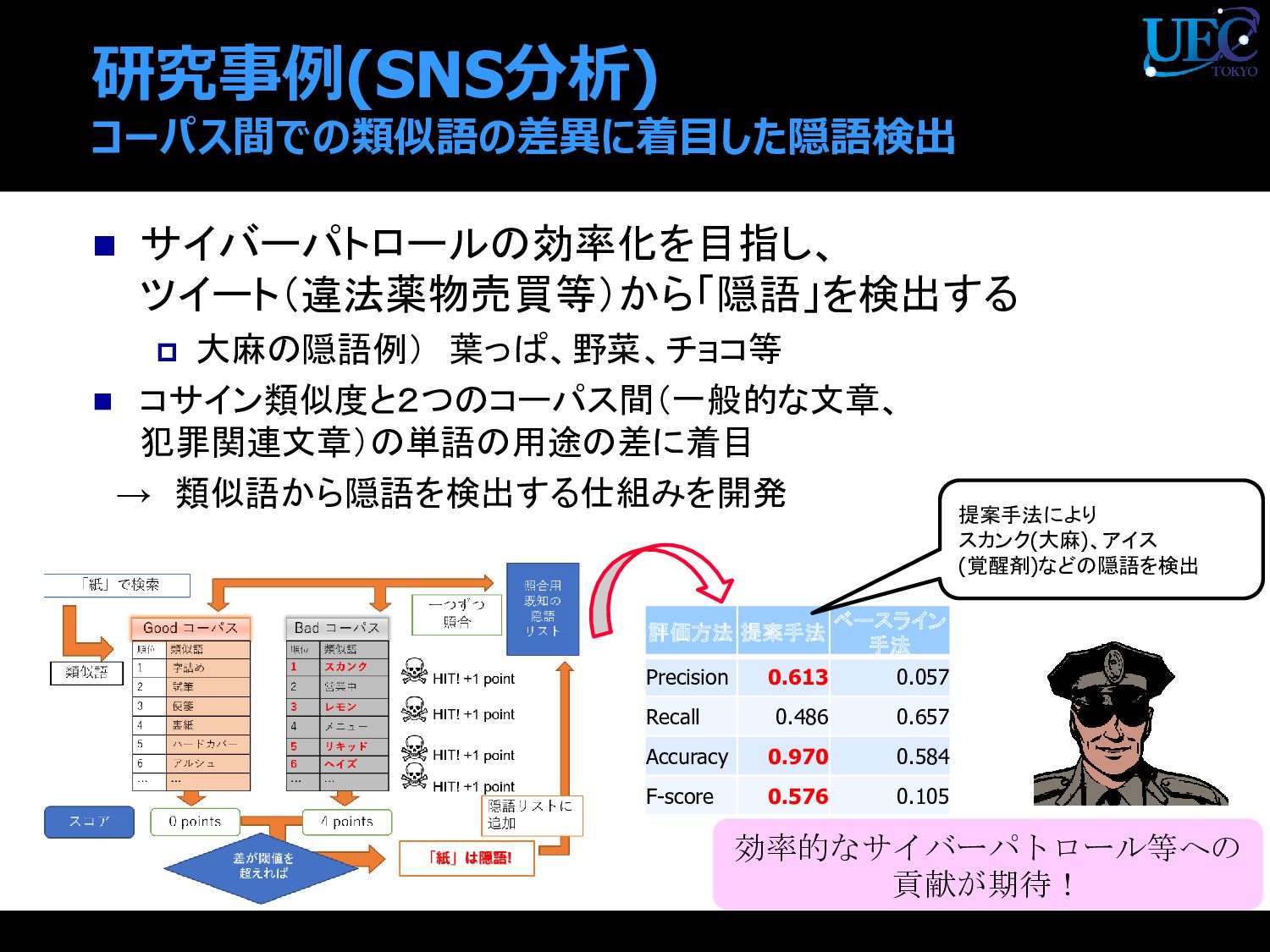{kind=link}
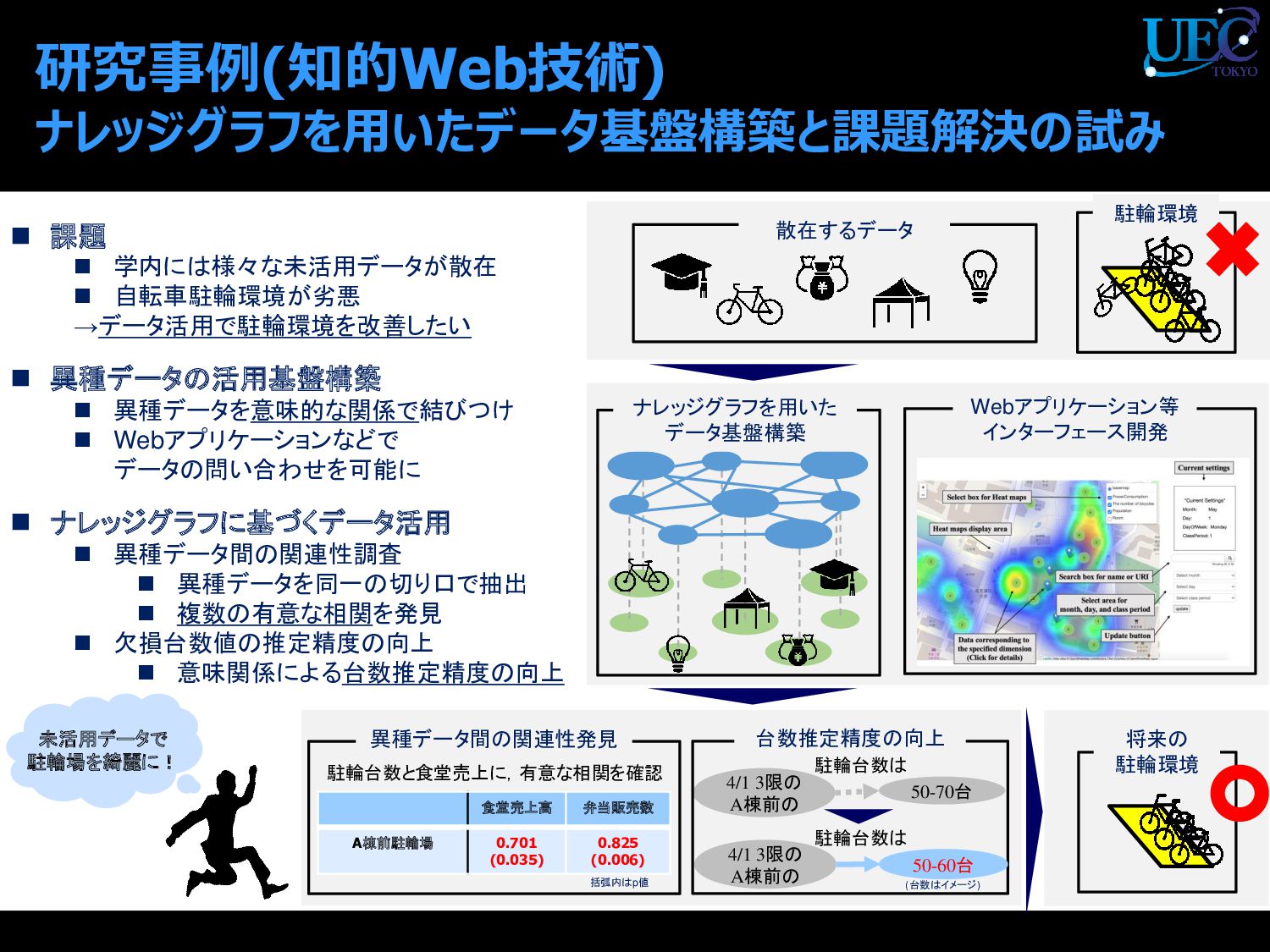{kind=link}
{kind=link}
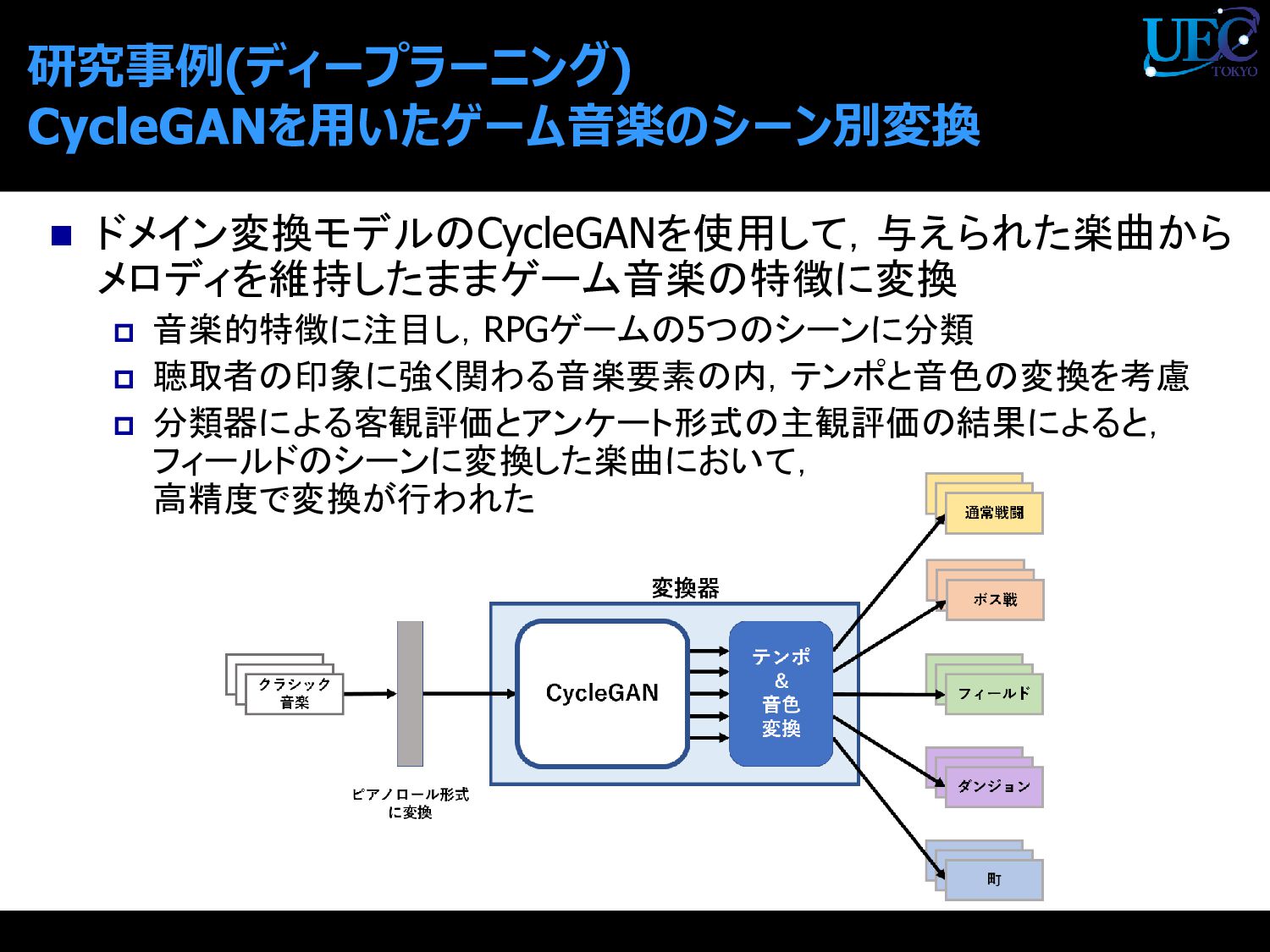{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
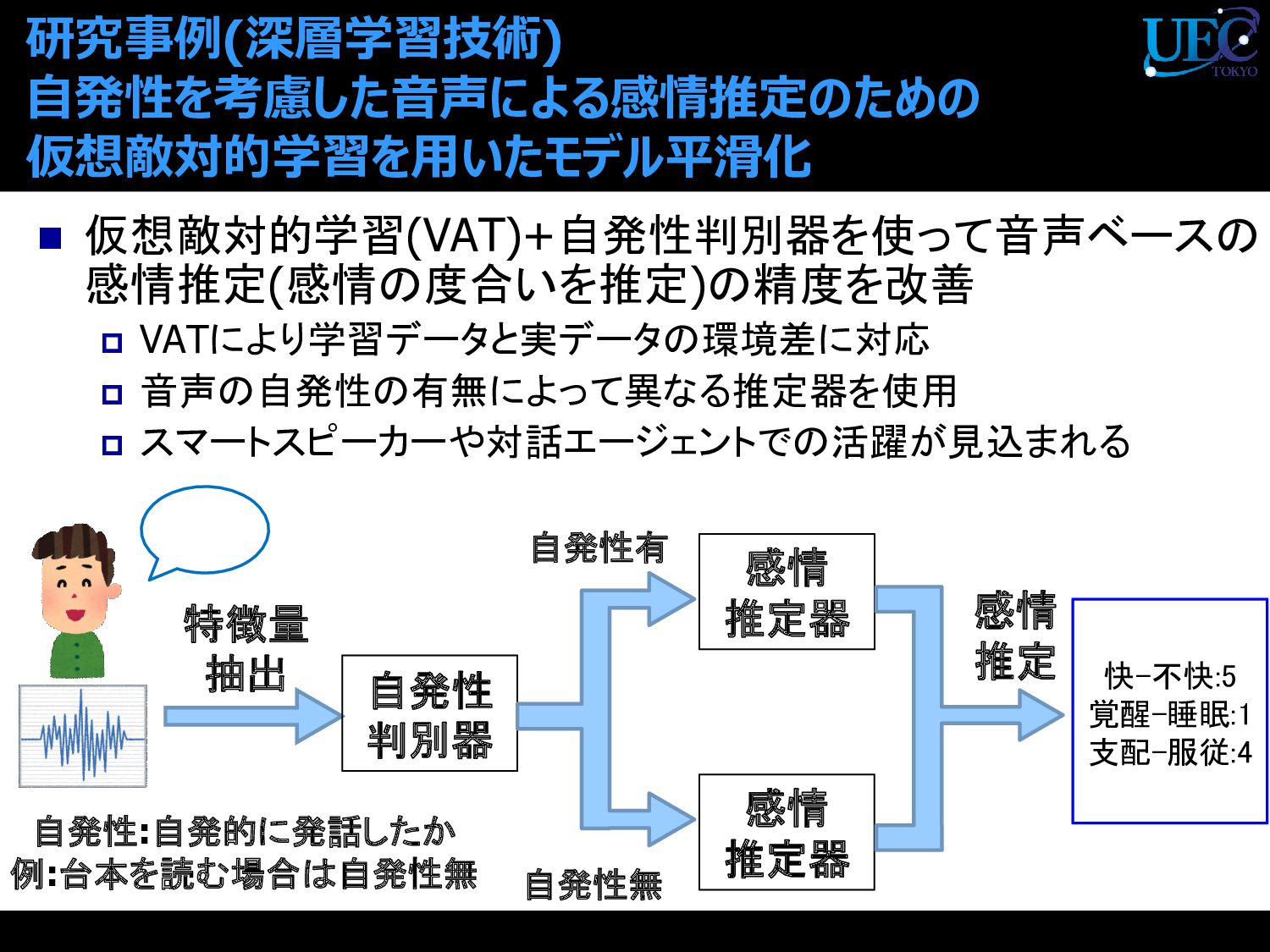{kind=link}
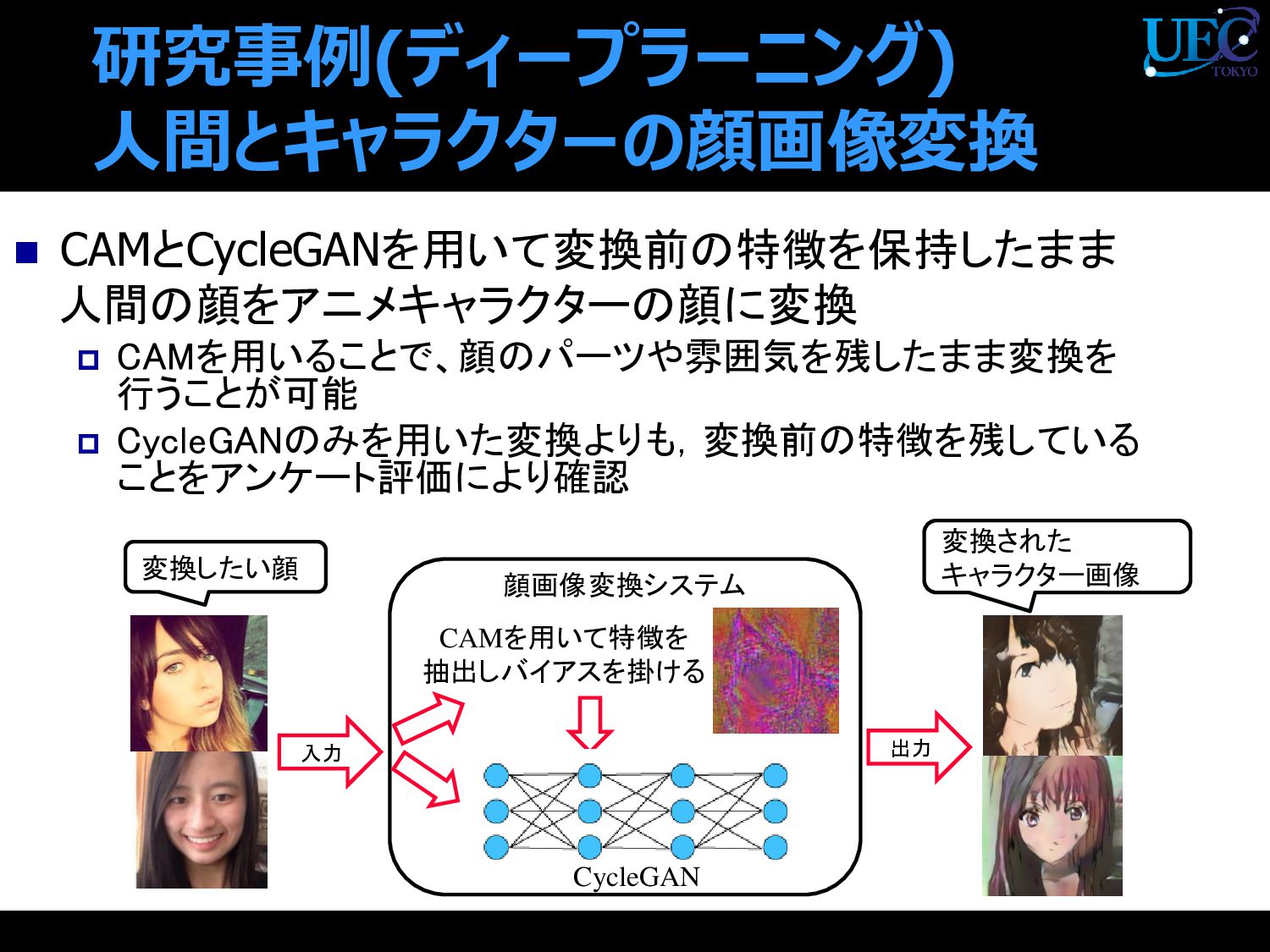{kind=link}
{kind=link}
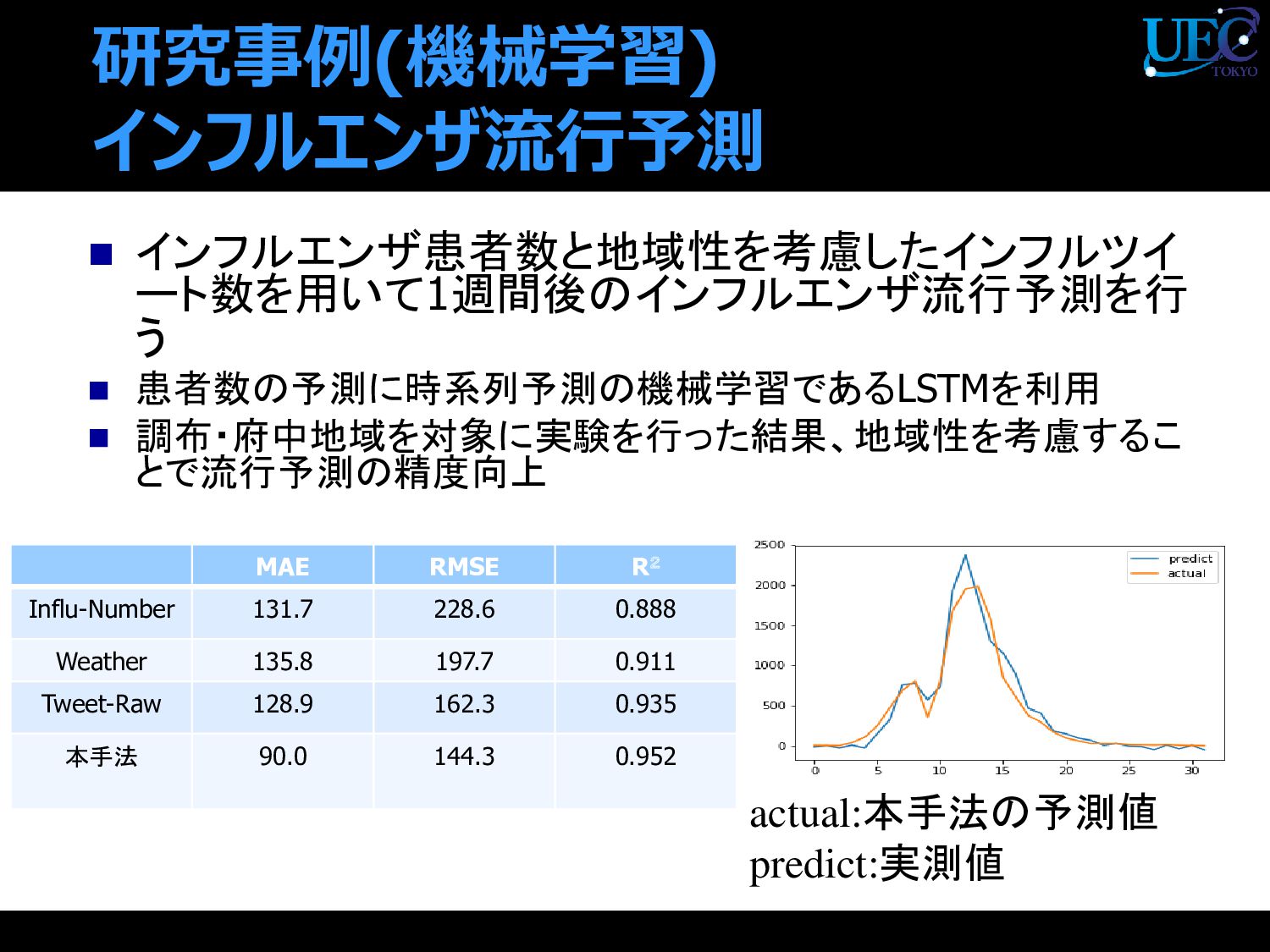{kind=link}
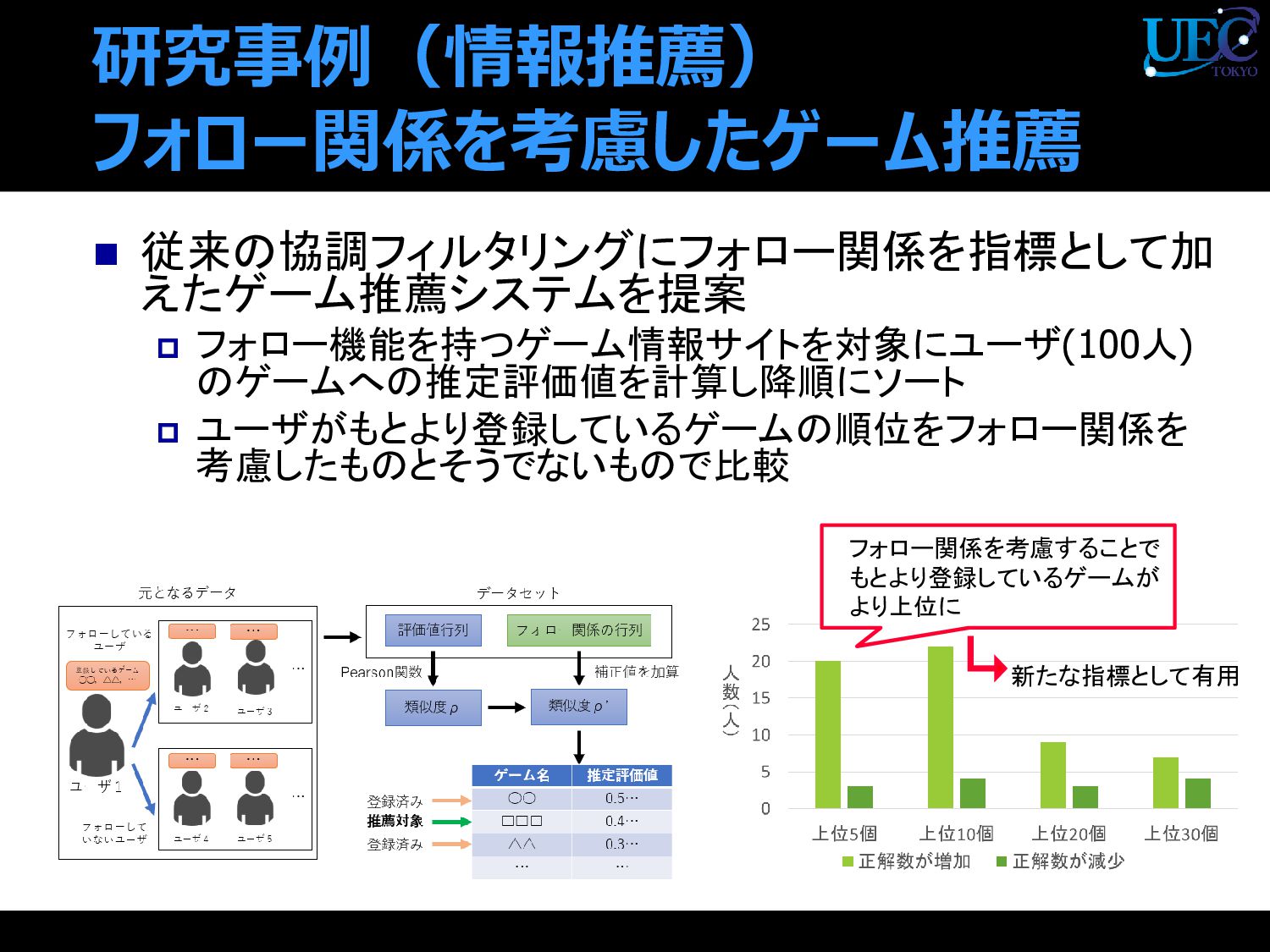{kind=link}
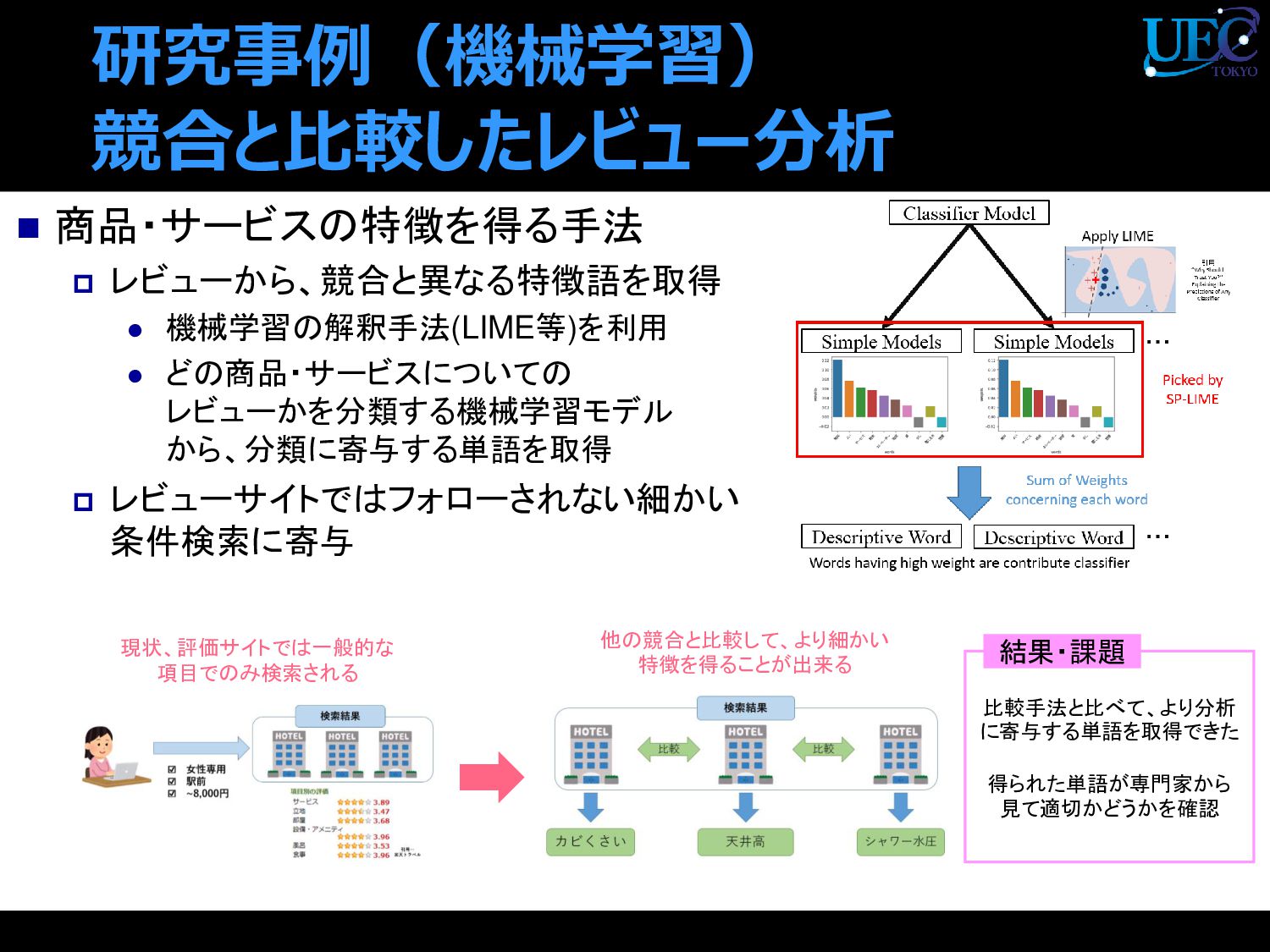{kind=link}
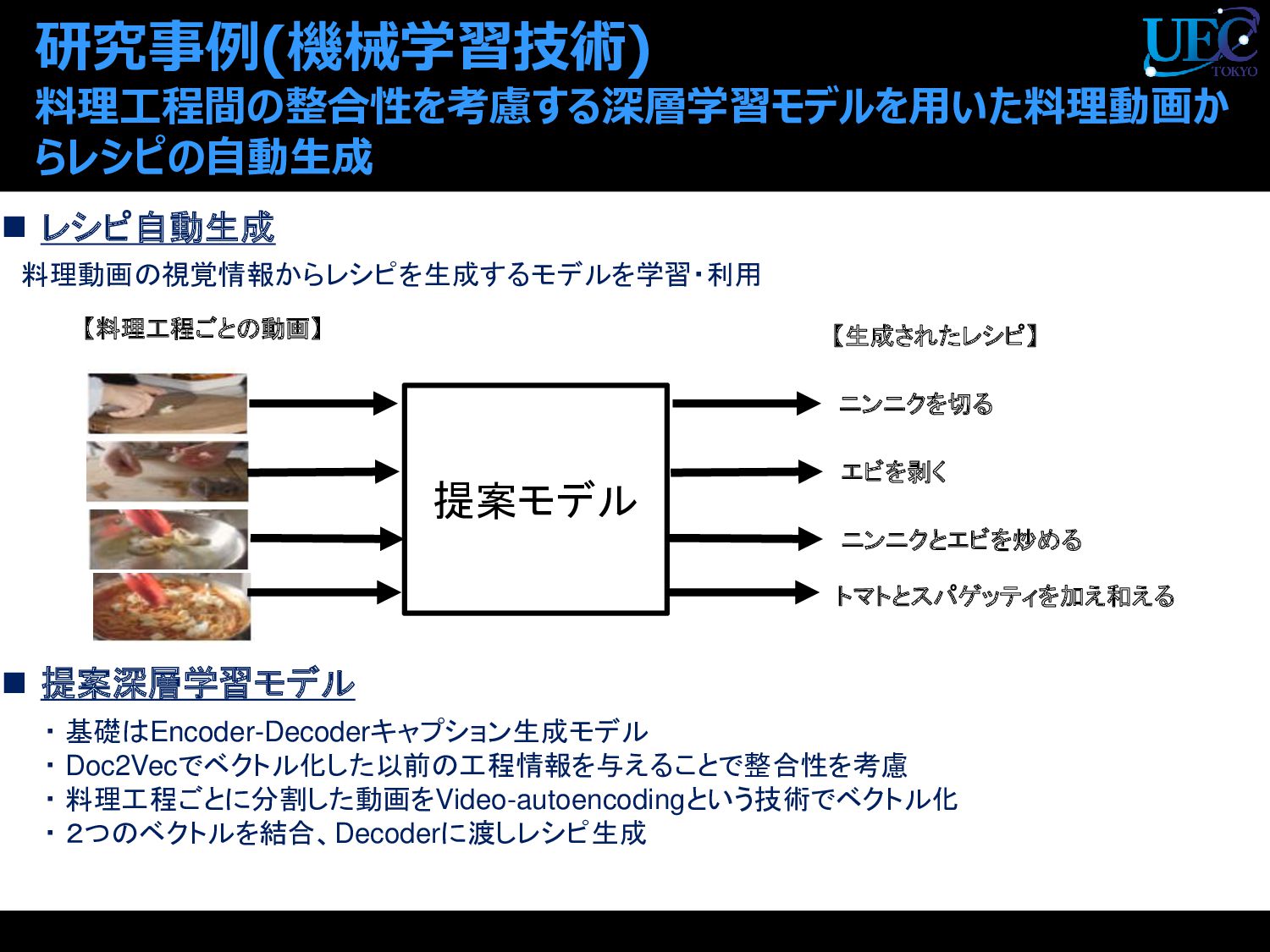{kind=link}
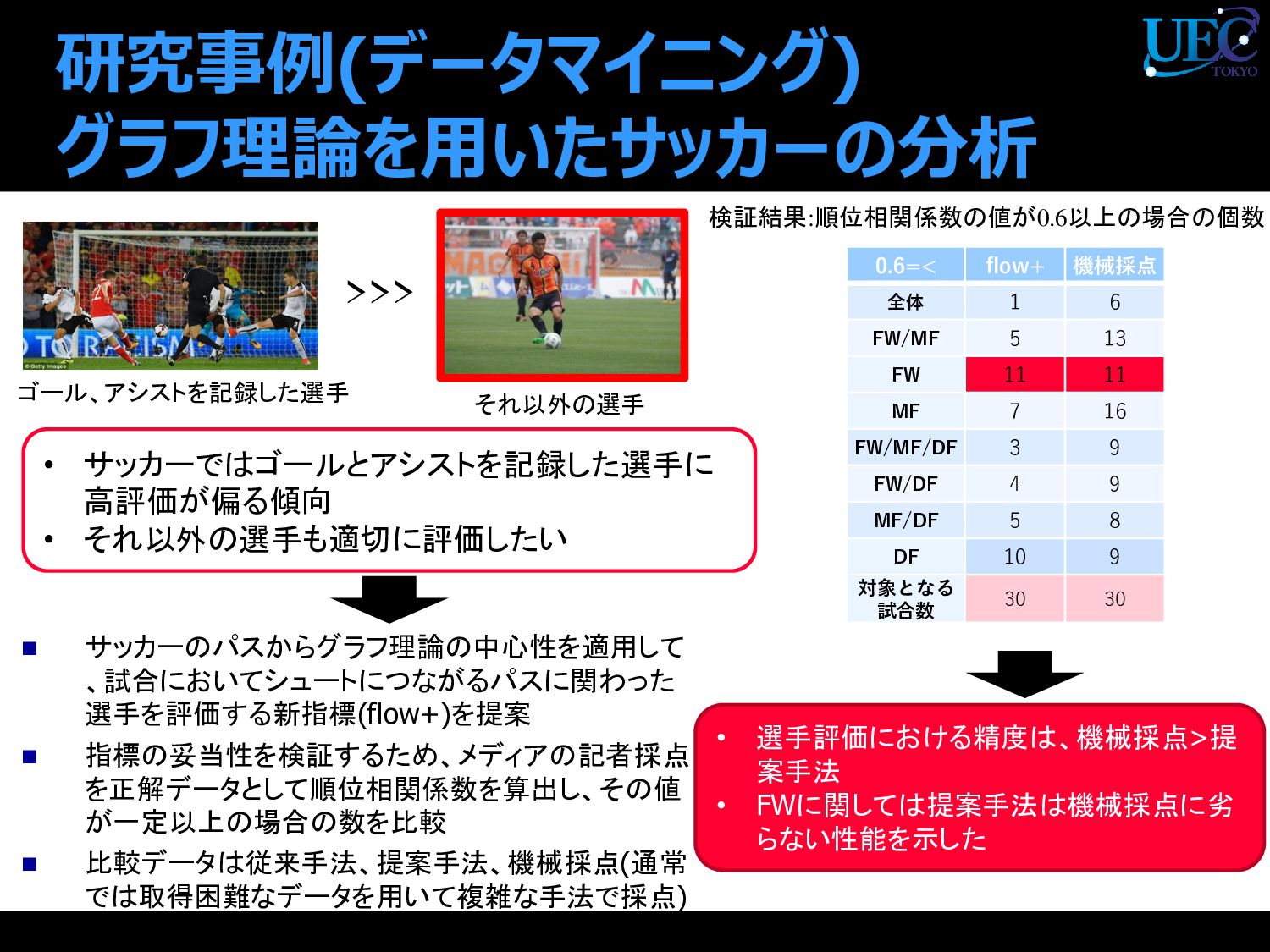{kind=link}
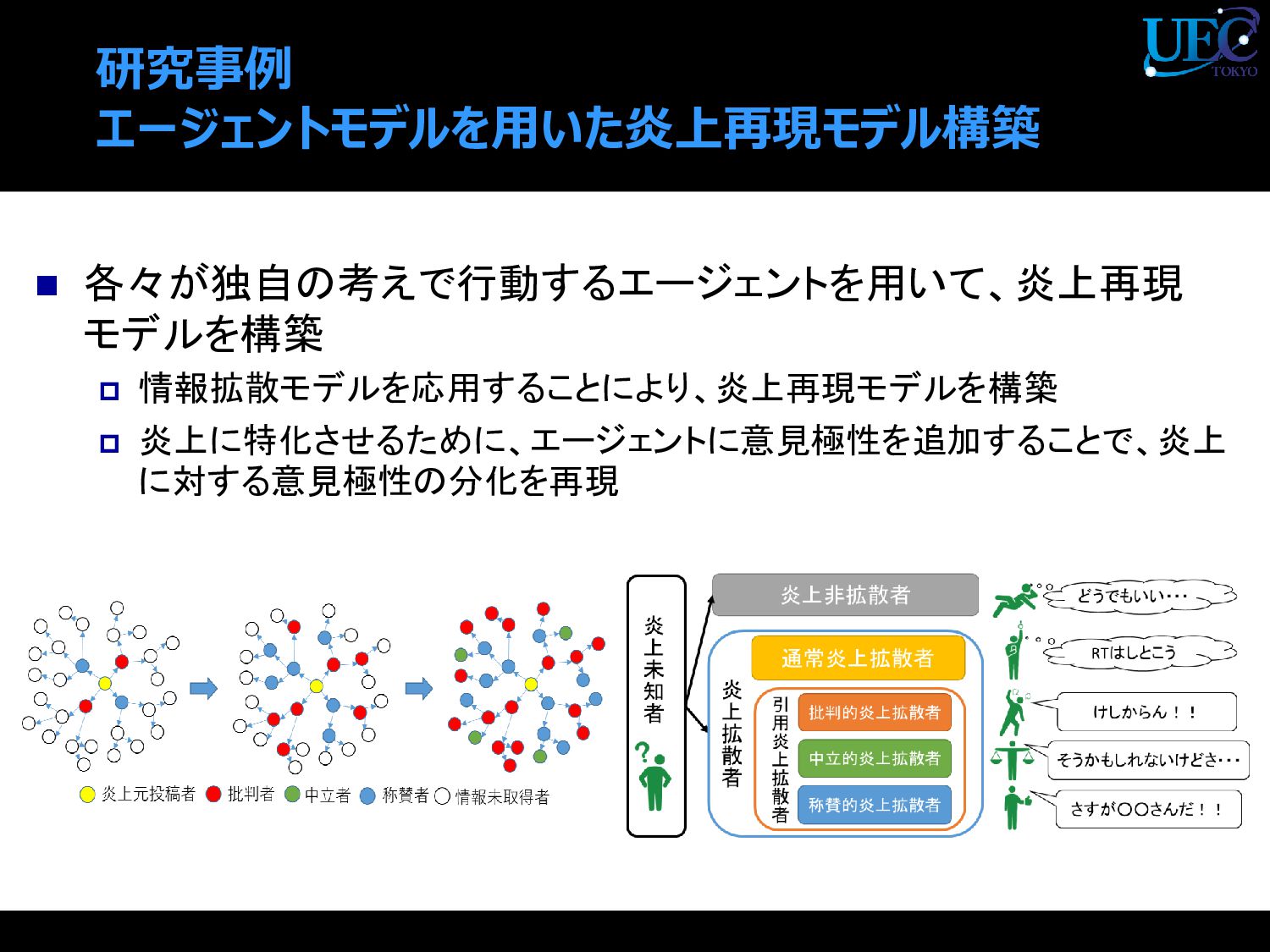{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
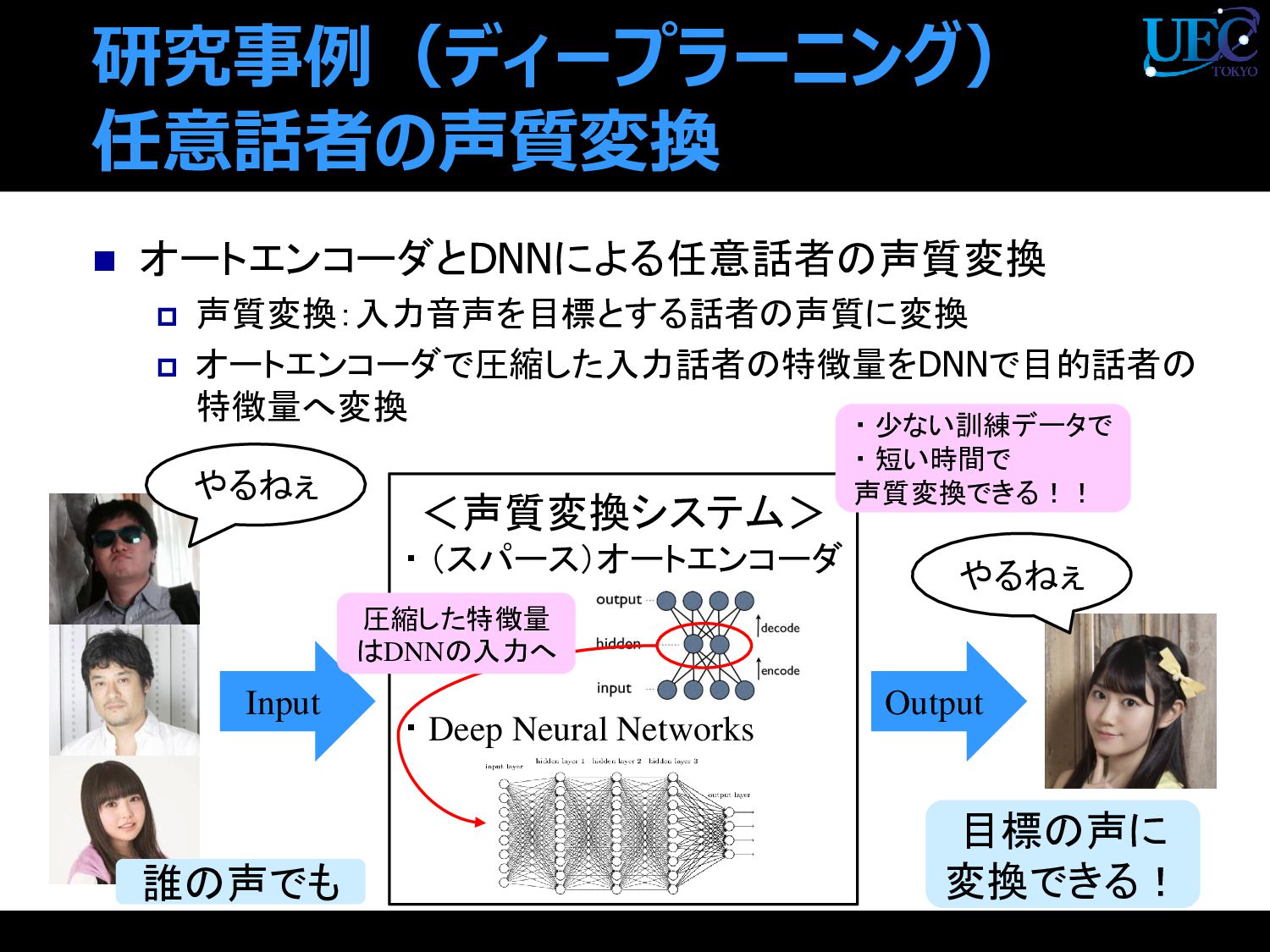{kind=link}
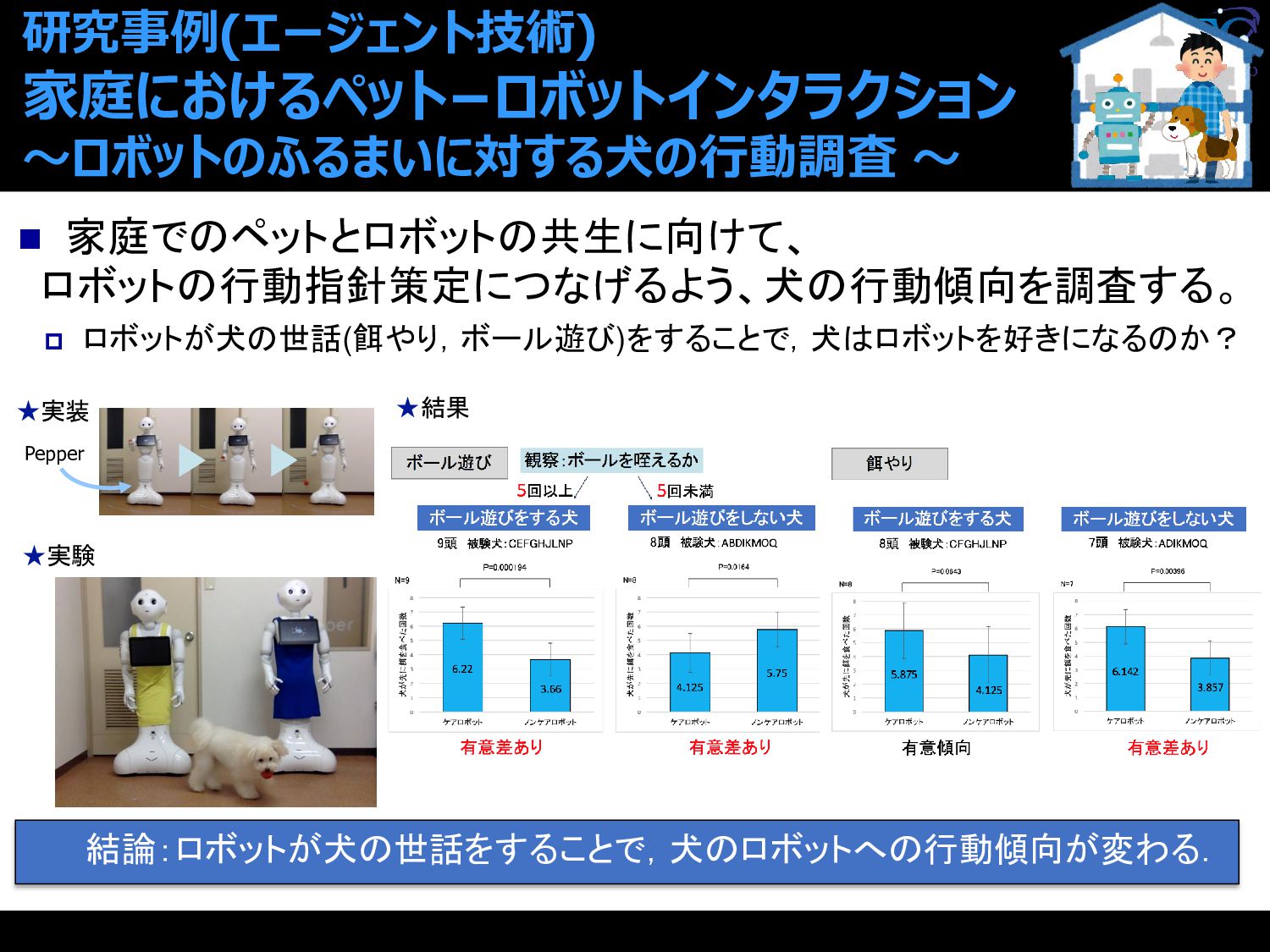{kind=link}
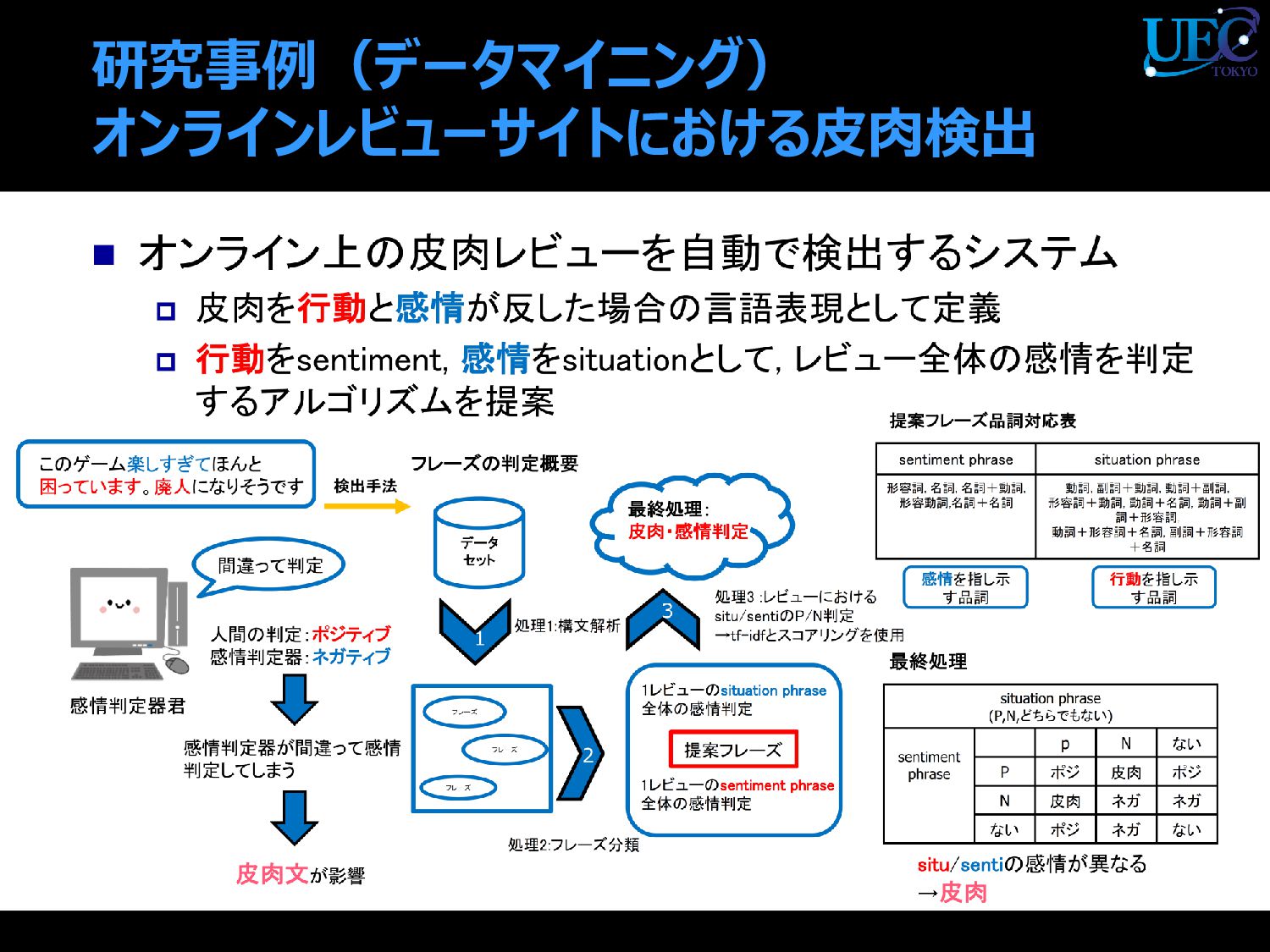{kind=link}
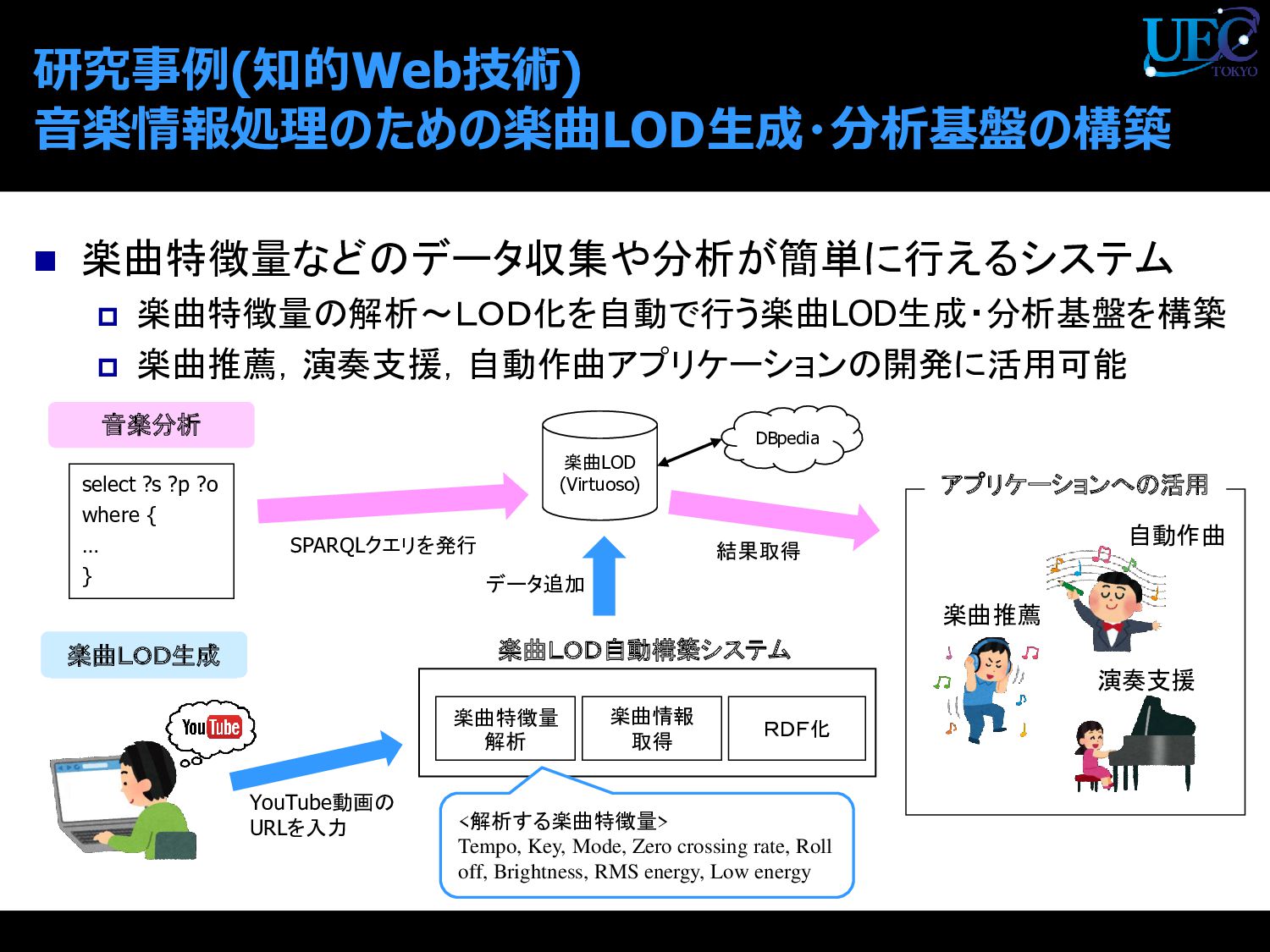{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Results Approach Existing Research • ADASIM[1]: a discrete event simulator](https://files.speakerdeck.com/presentations/0d30923de3d845e7a84b2ce833c0920e/slide_80.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
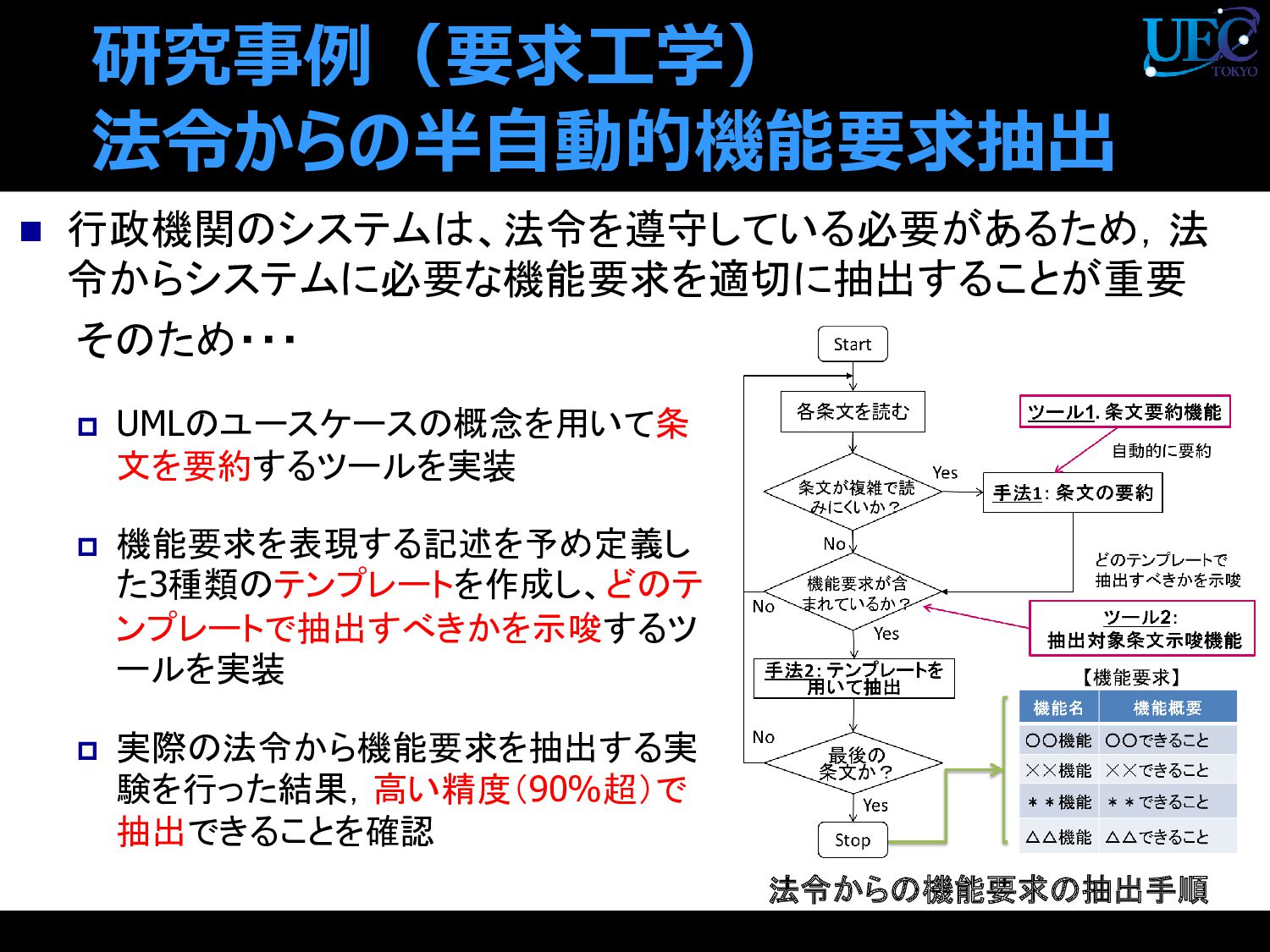{kind=link}
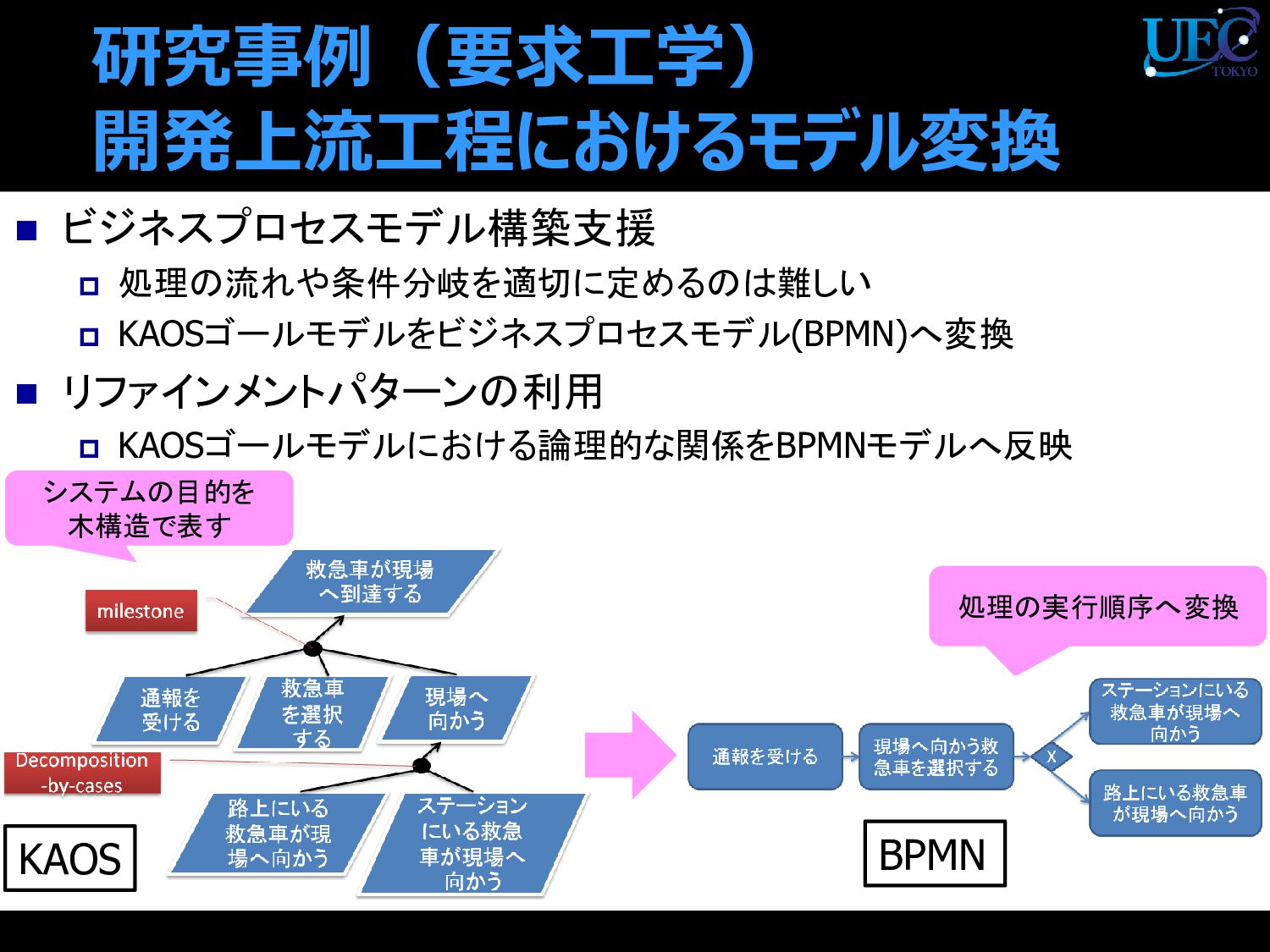{kind=link}
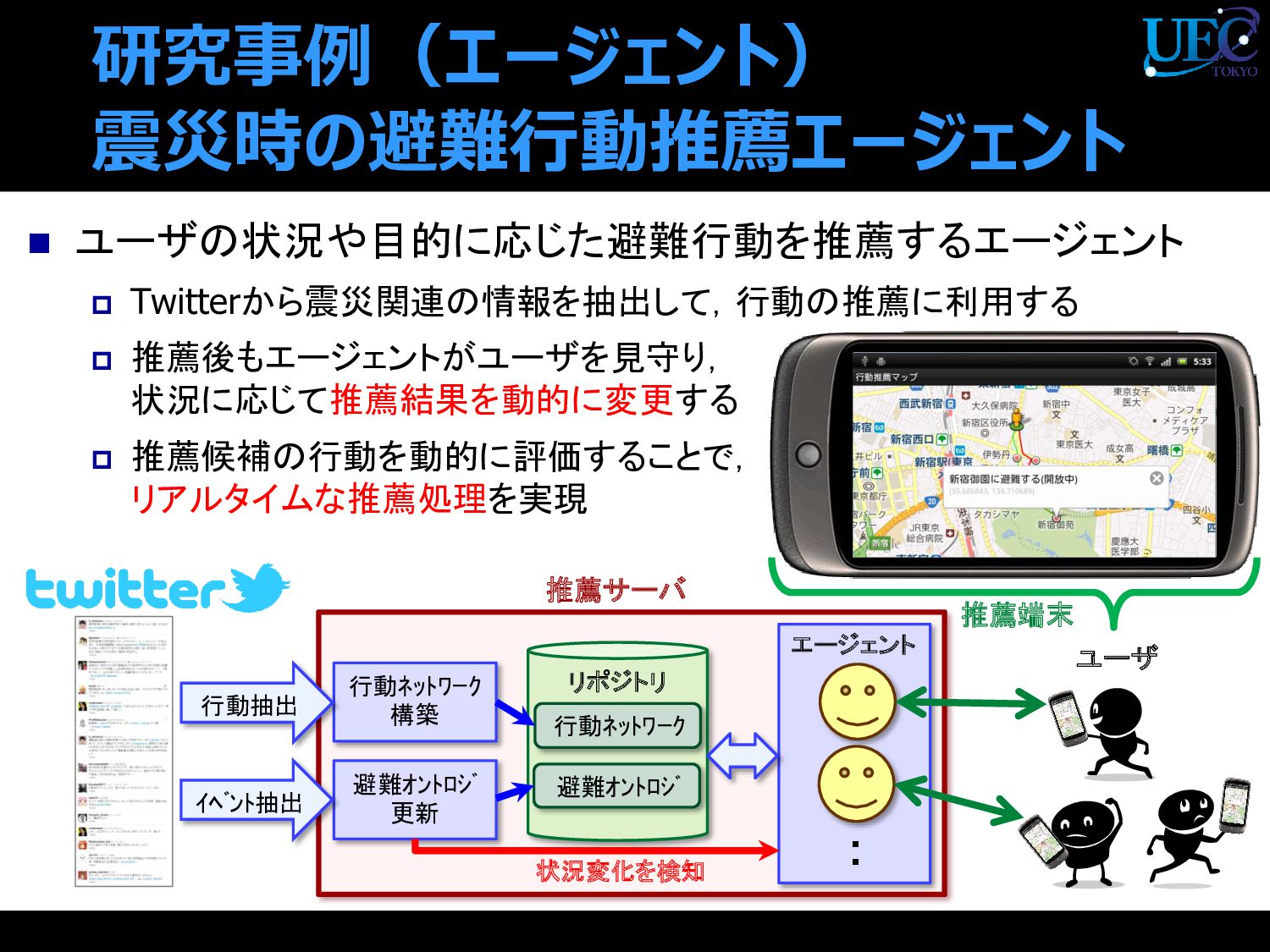{kind=link}
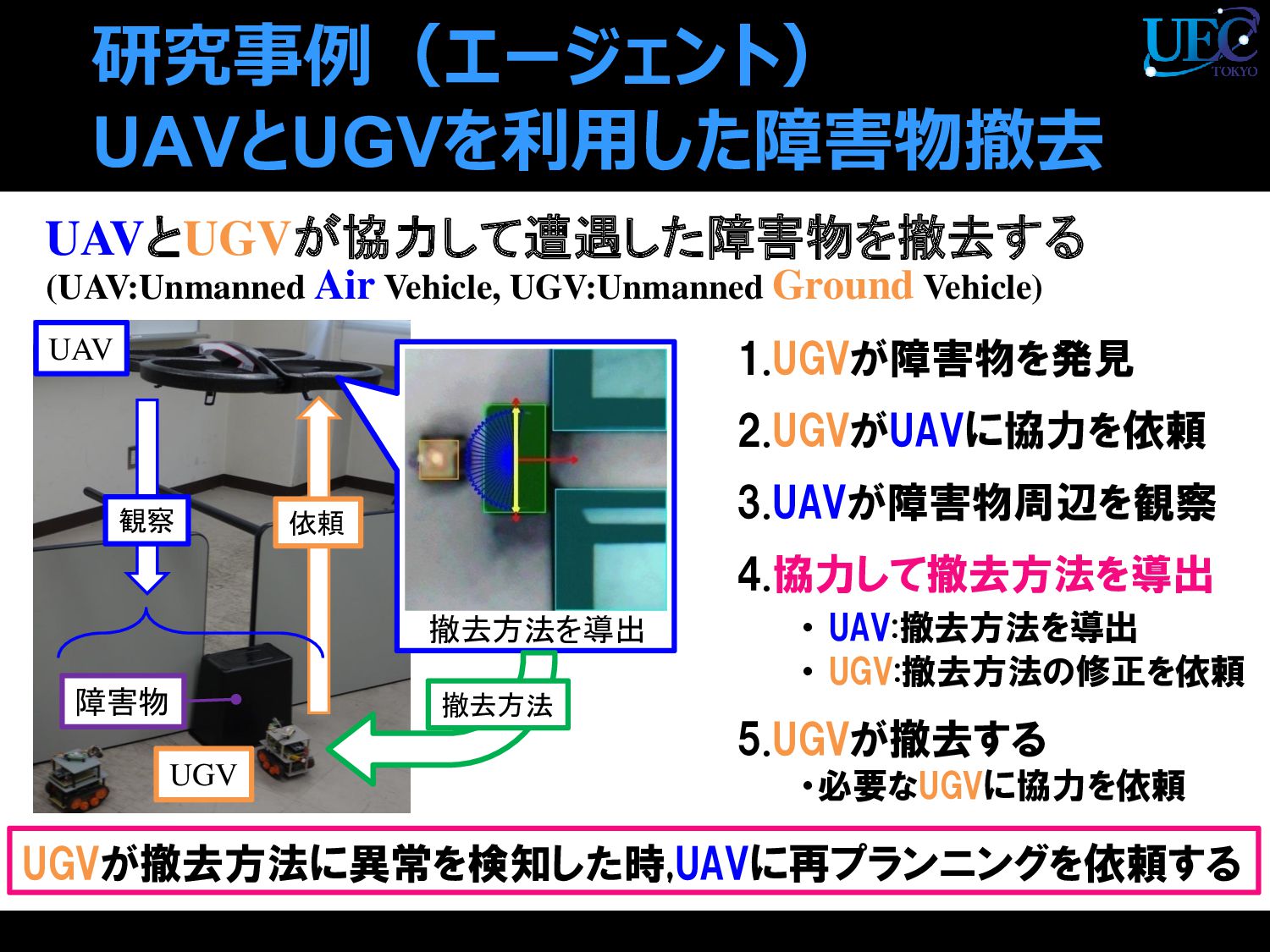{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
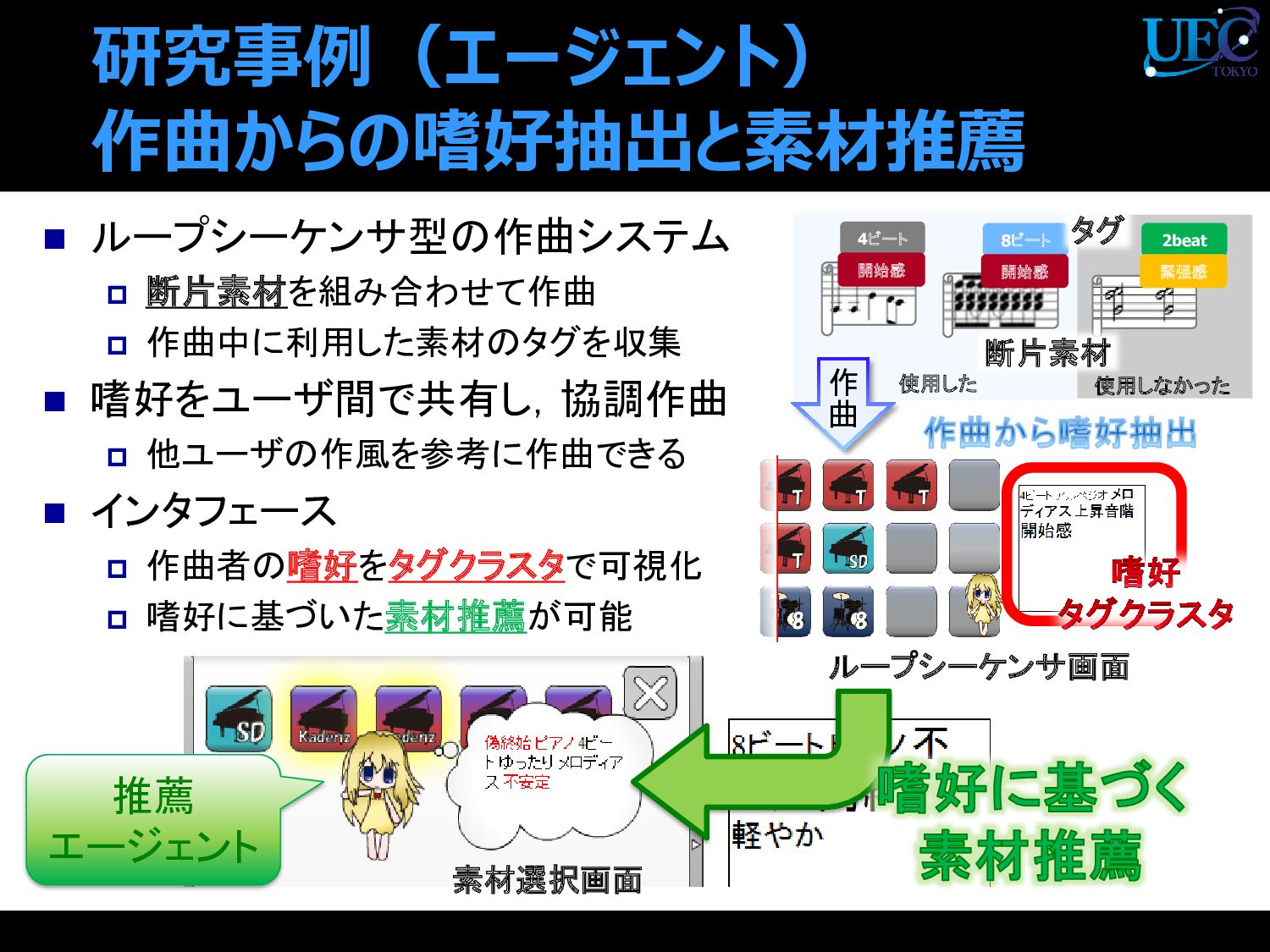{kind=link}
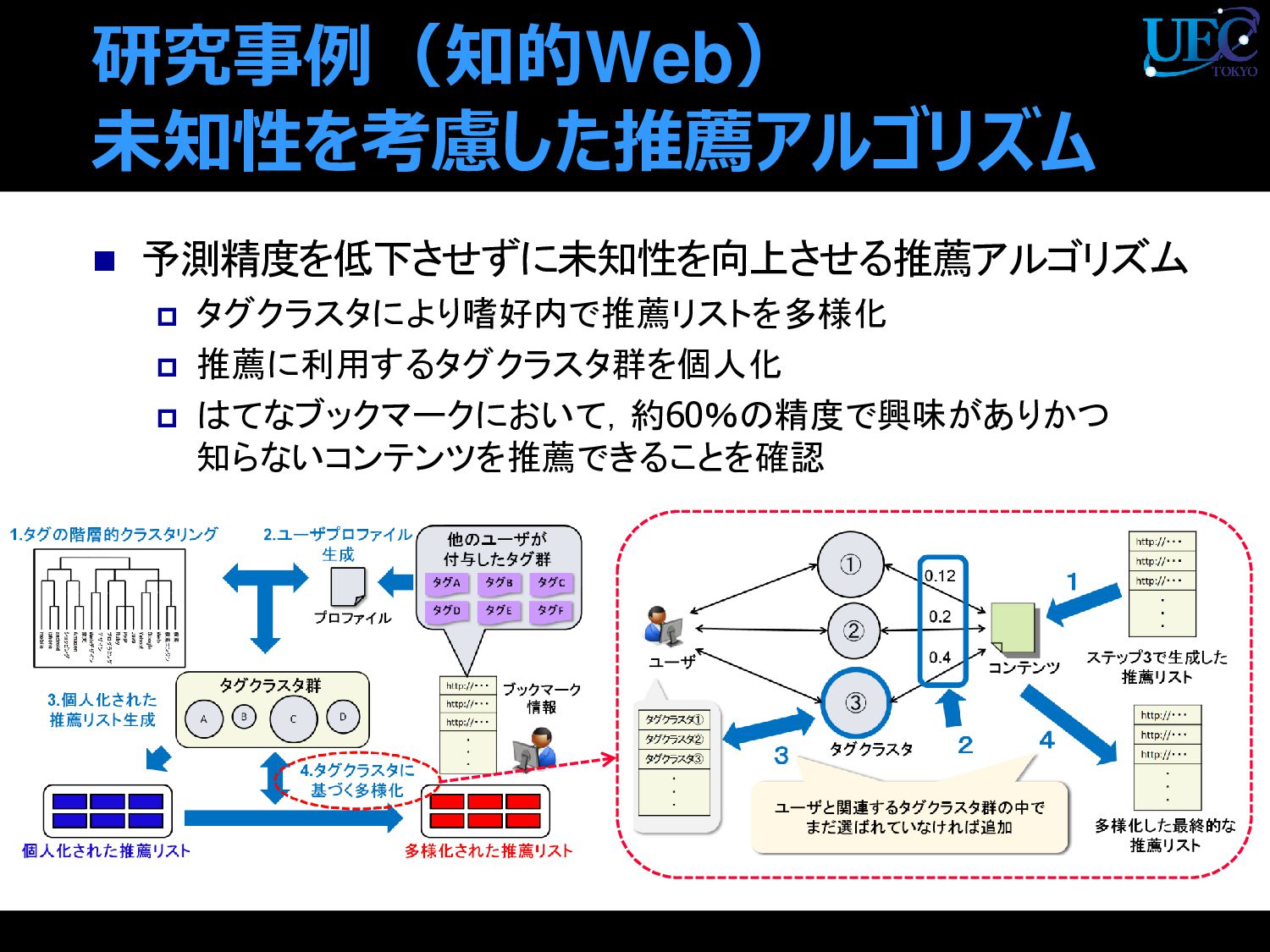{kind=link}
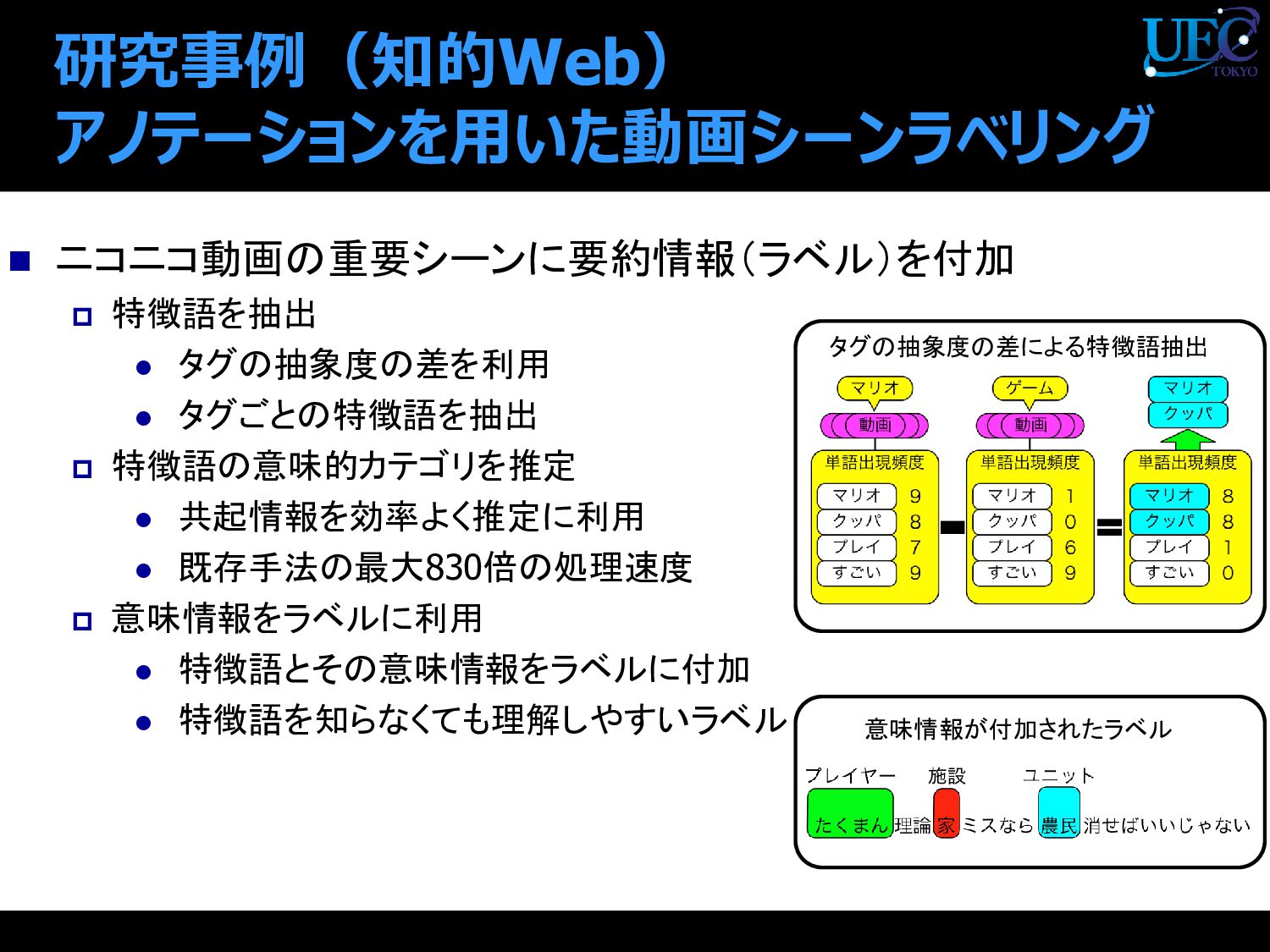{kind=link}
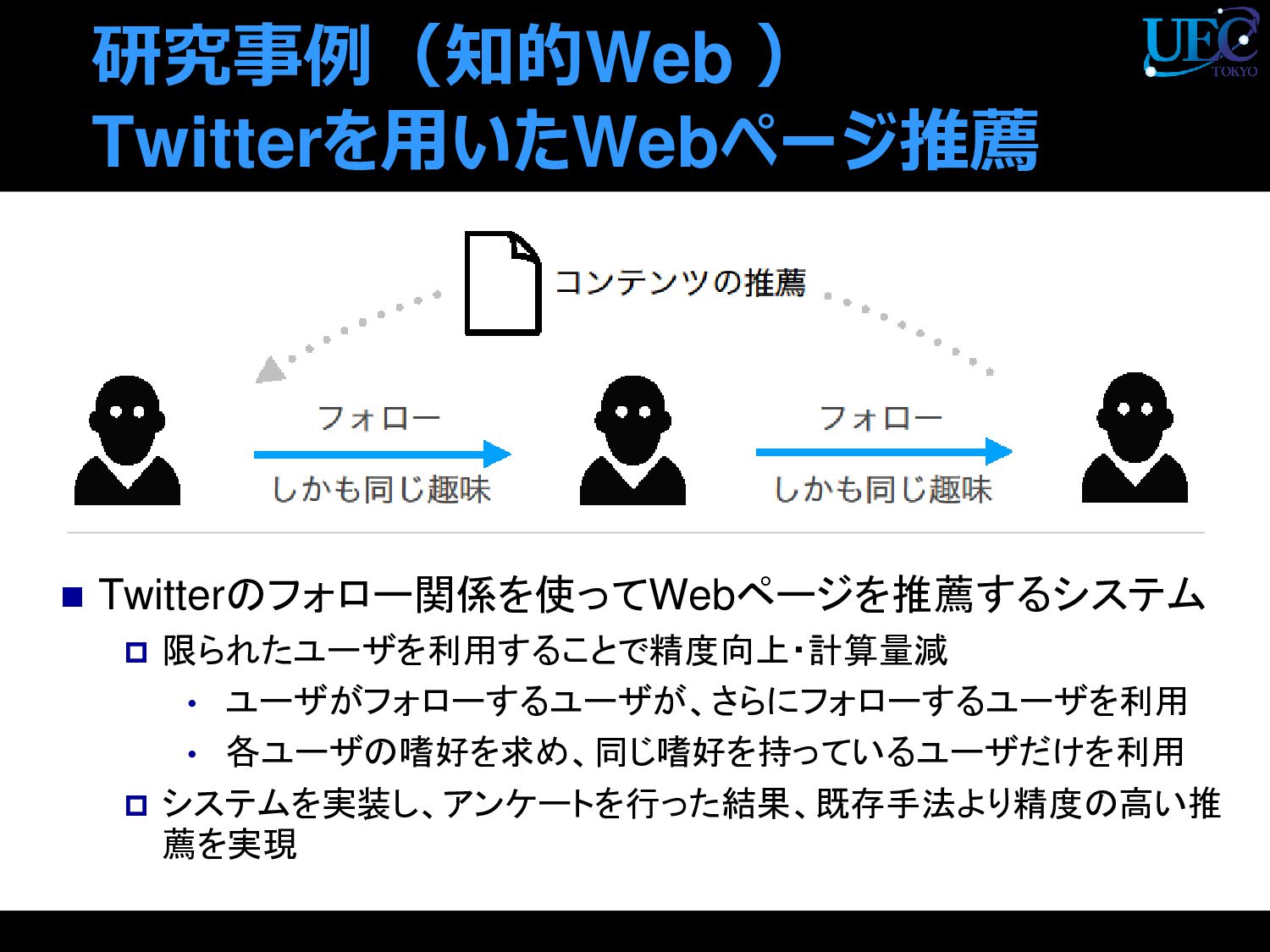{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
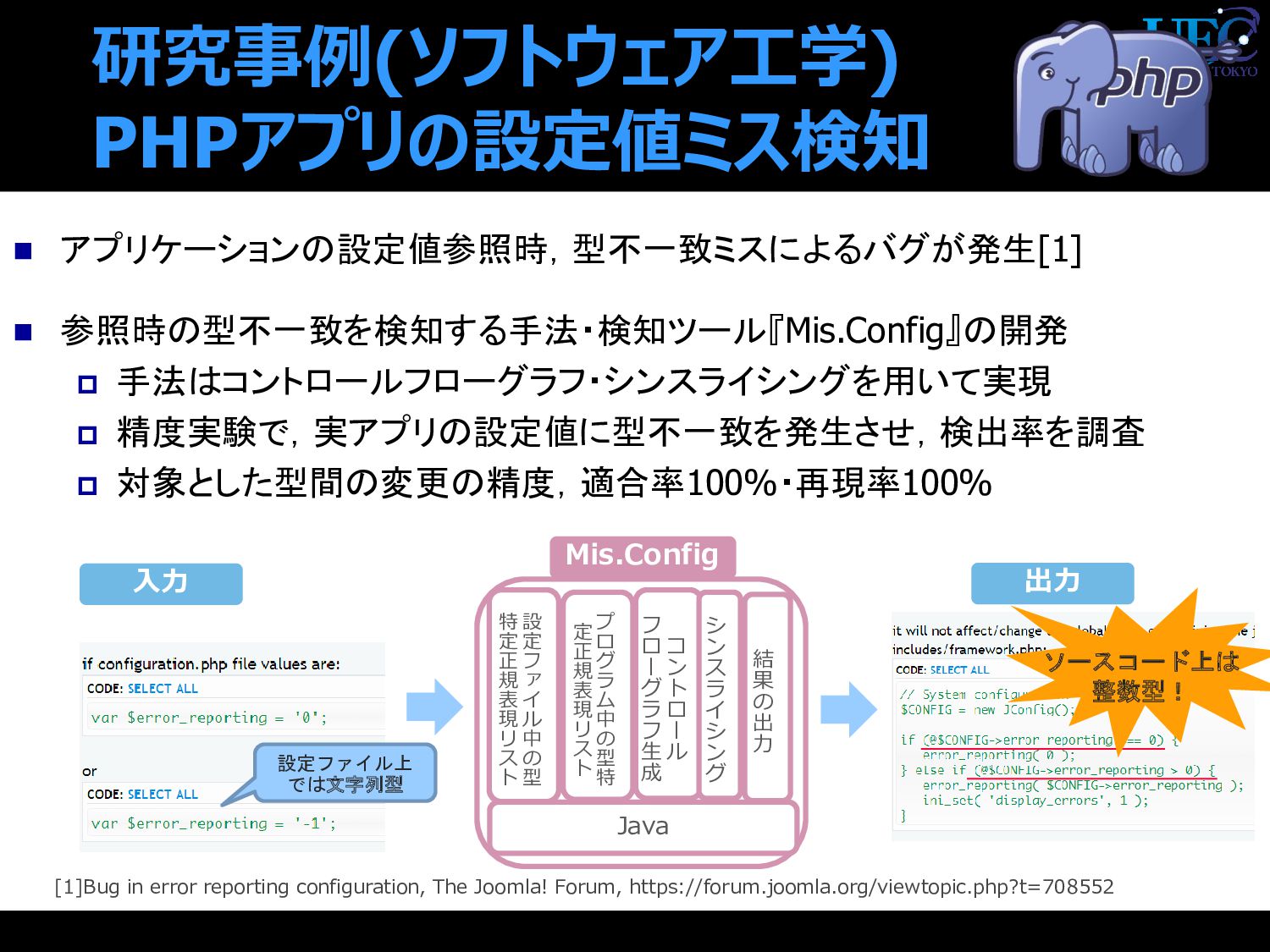
![研究事例(ソフトウェア工学) PHPアプリの設定値ミス検知 ◼ アプリケーションの設定値参照時,型不一致ミスによるバグが発生[1] ◼ 参照時の型不一致を検知する手法・検知ツール『Mis.Config』の開発 手法はコントロールフローグラフ・シンスライシングを用いて実現 精度実験で,実アプリの設定値に型不一致を発生させ,検出率を調査](https://files.speakerdeck.com/presentations/0d30923de3d845e7a84b2ce833c0920e/slide_104.jpg){kind=link}
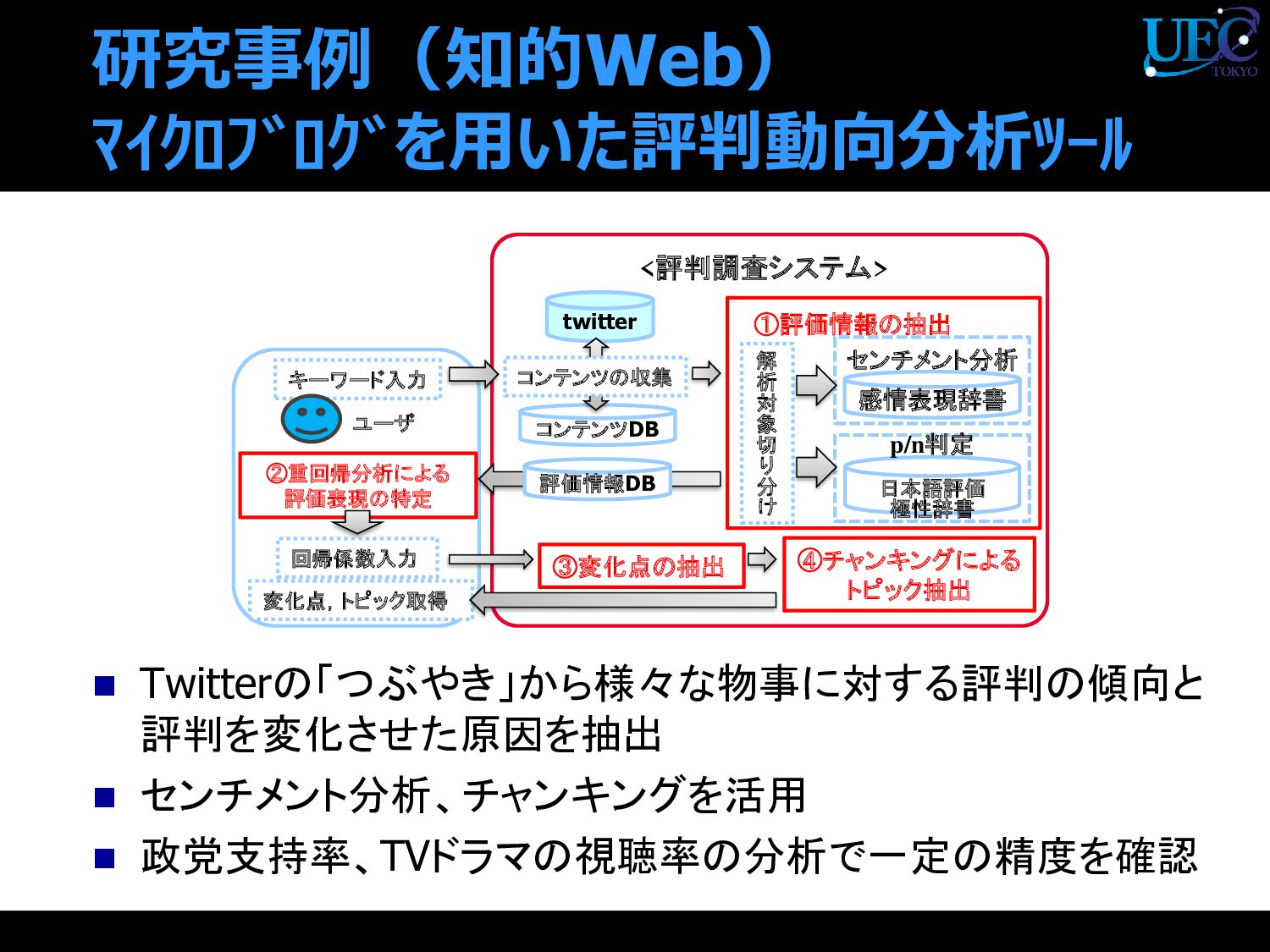{kind=link}
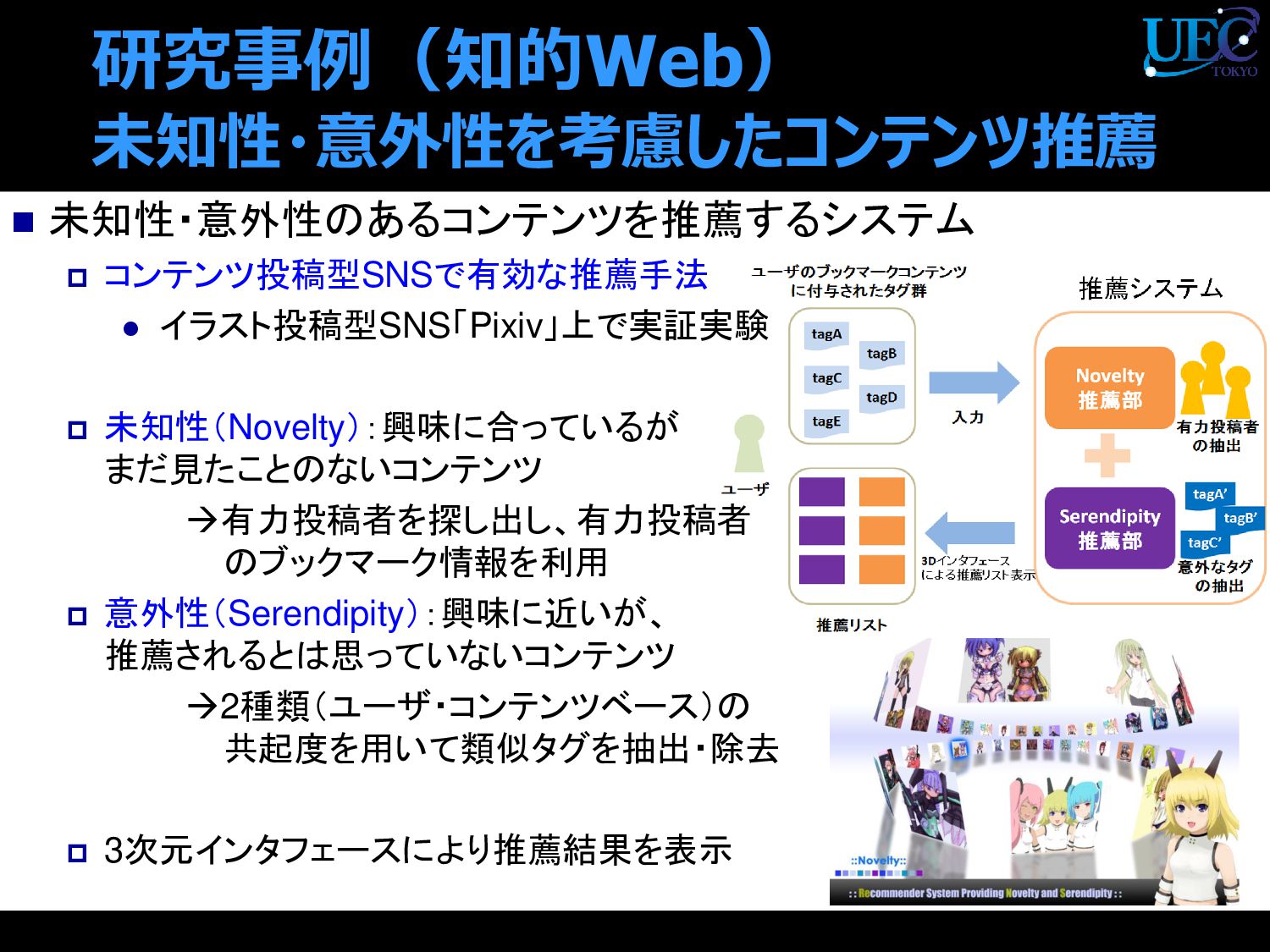{kind=link}
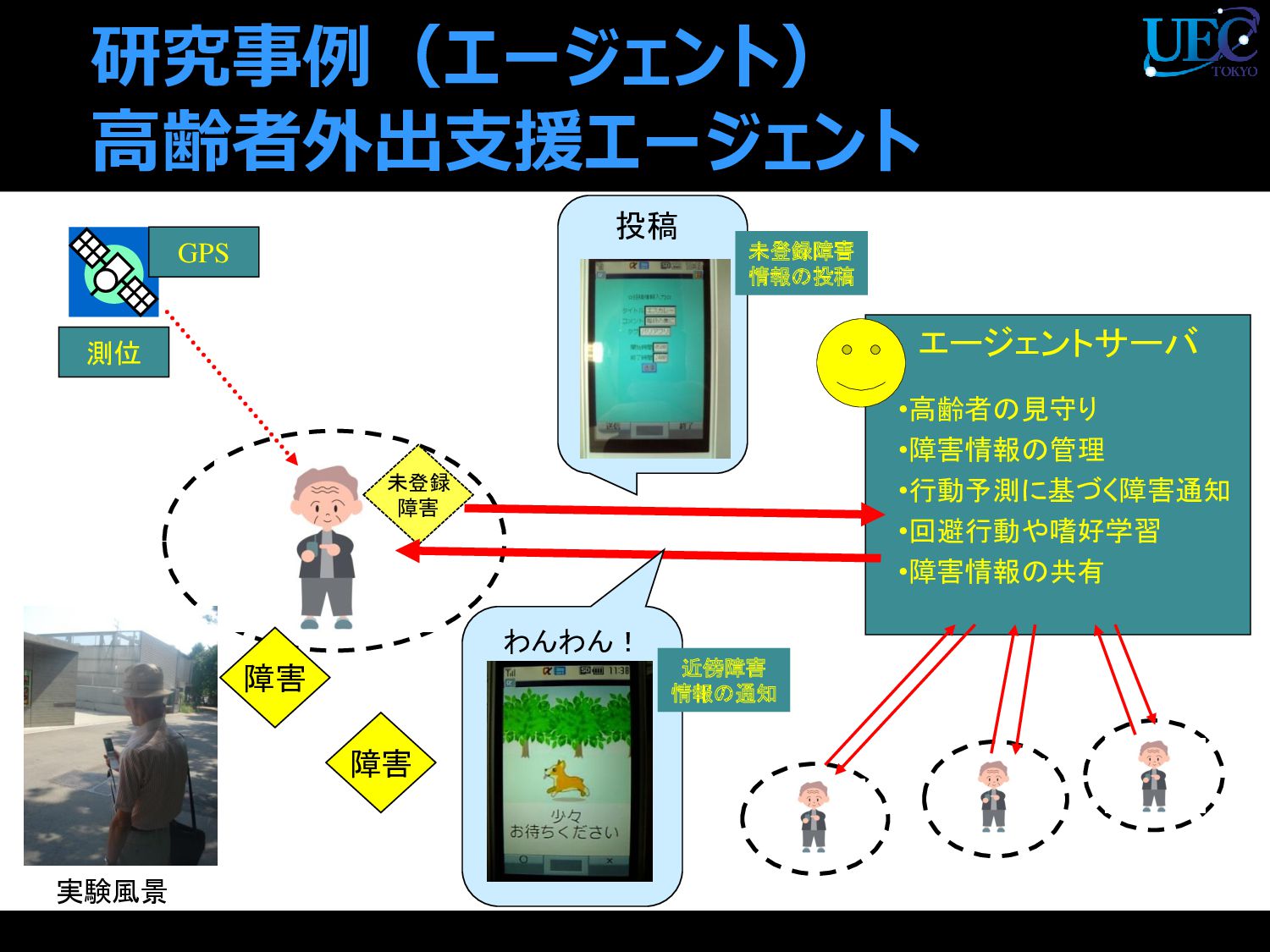{kind=link}
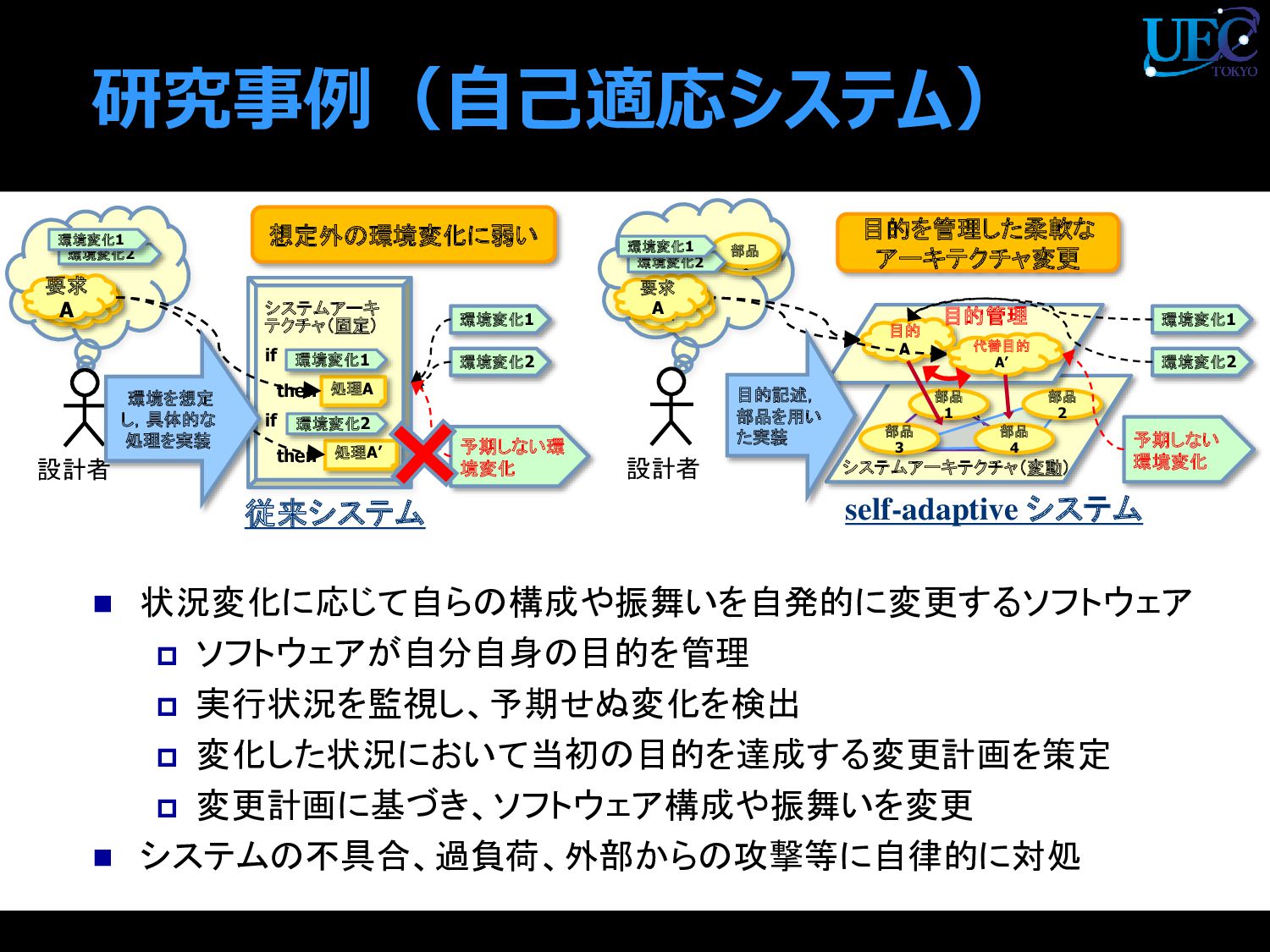{kind=link}
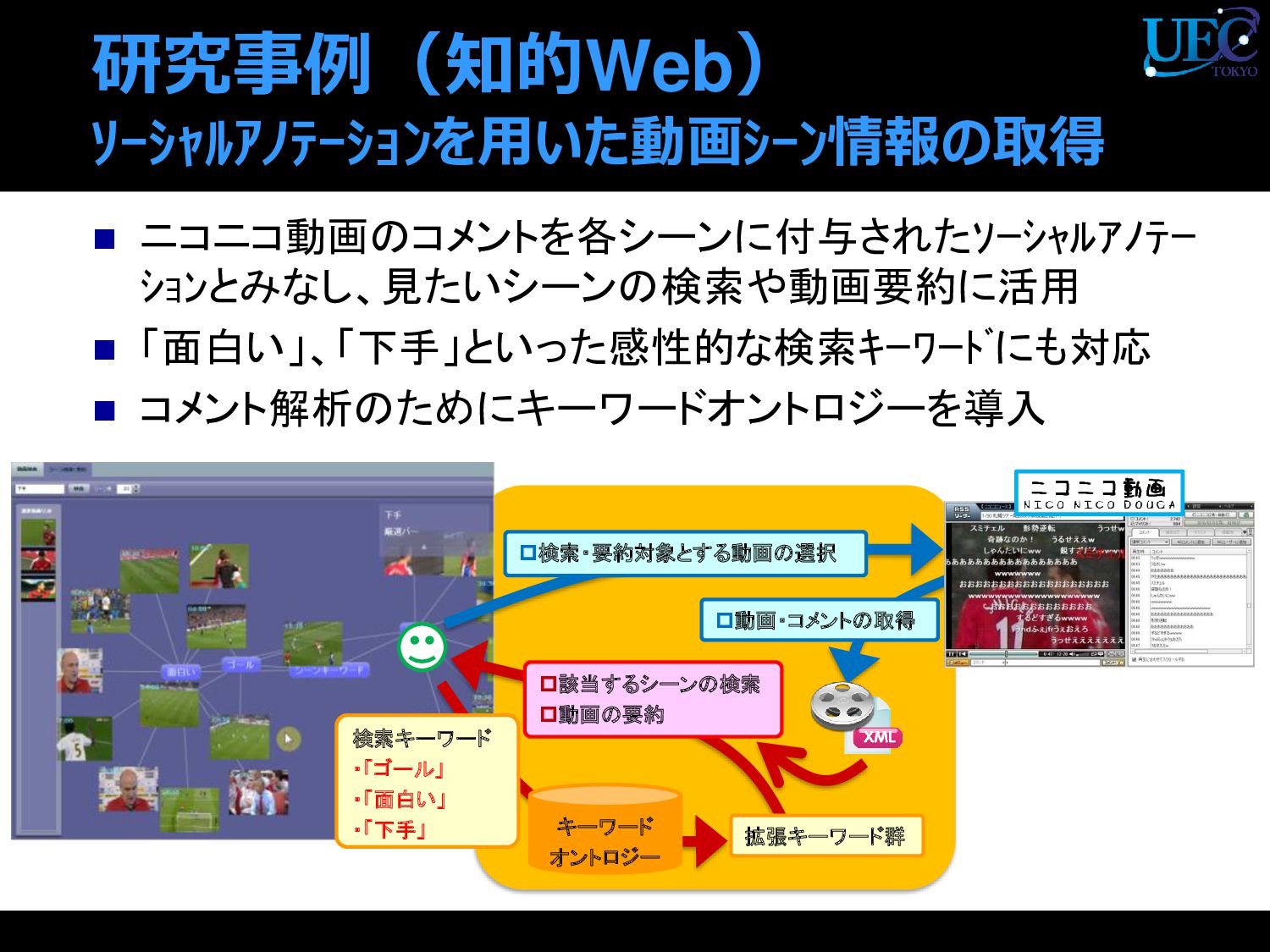{kind=link}
{kind=link}
{kind=link}
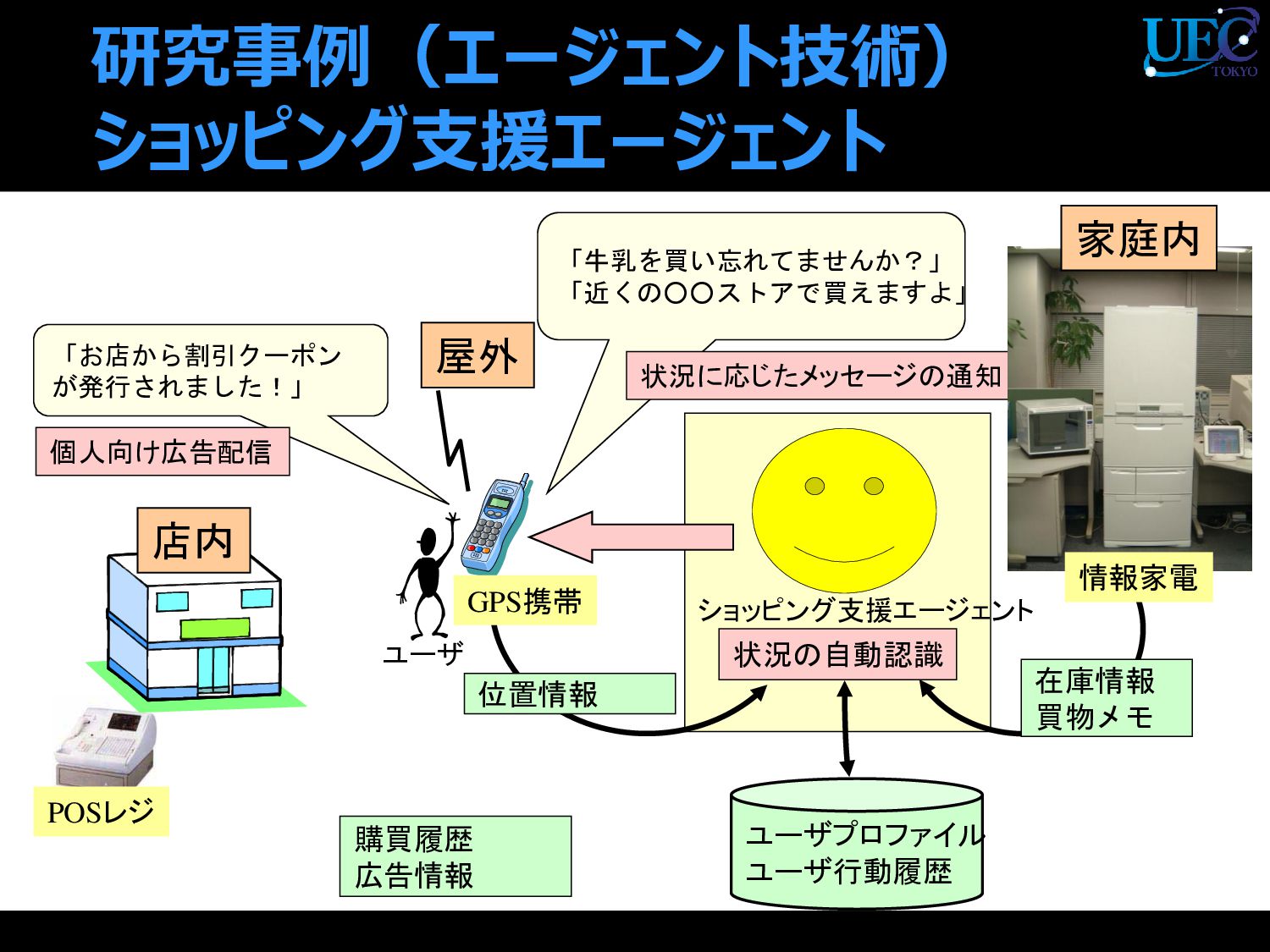{kind=link}
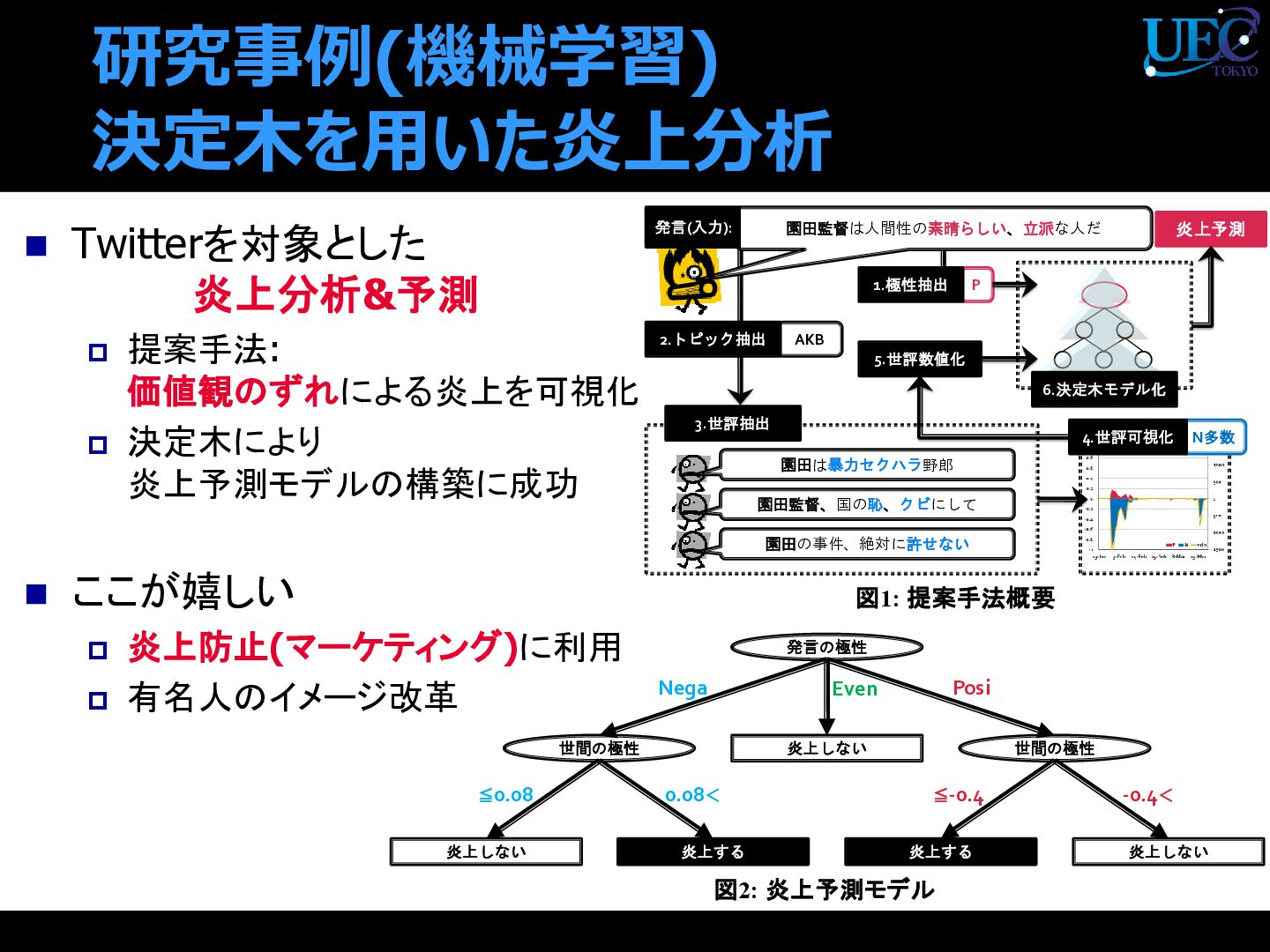{kind=link}
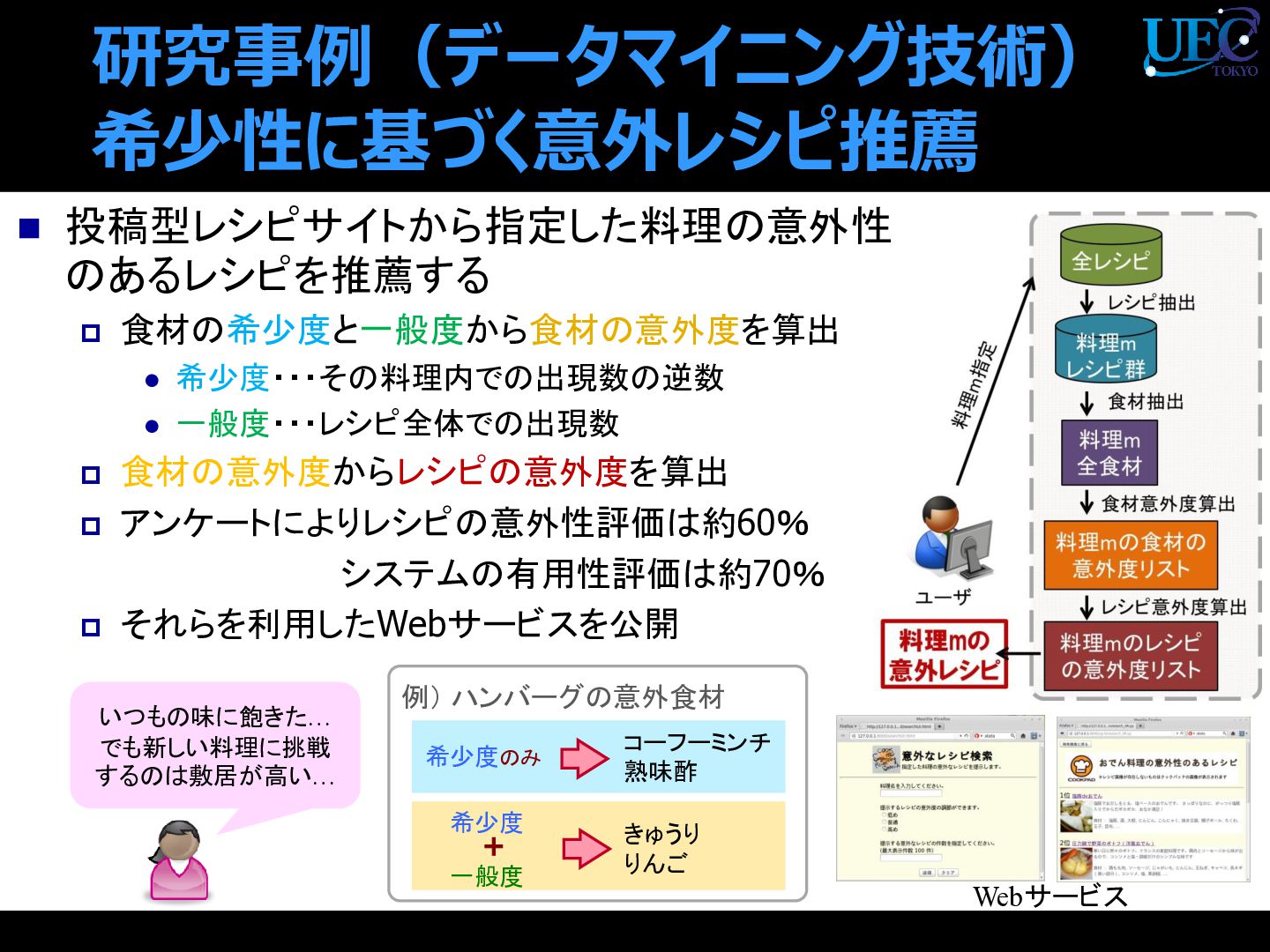{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
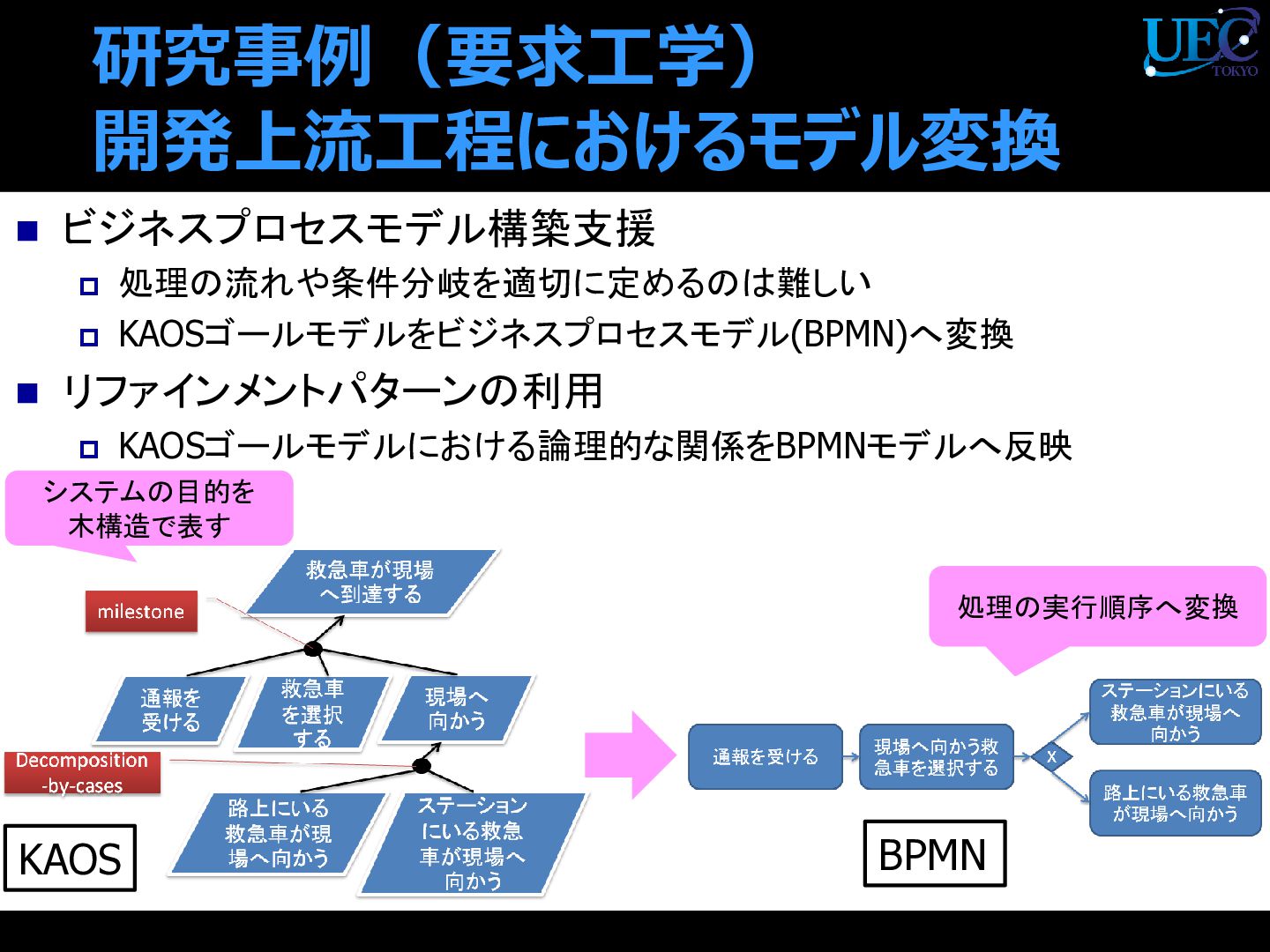{kind=link}
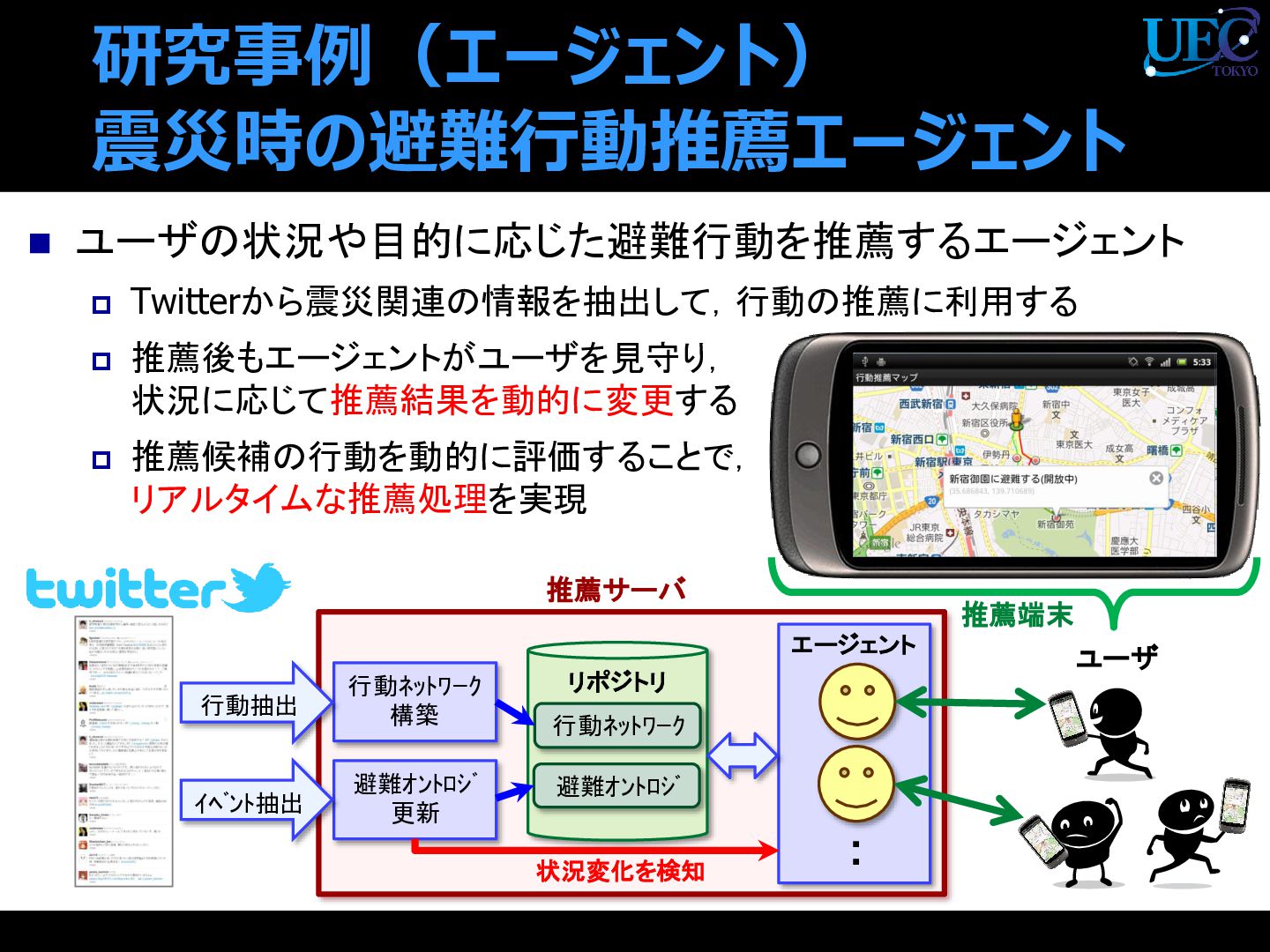{kind=link}
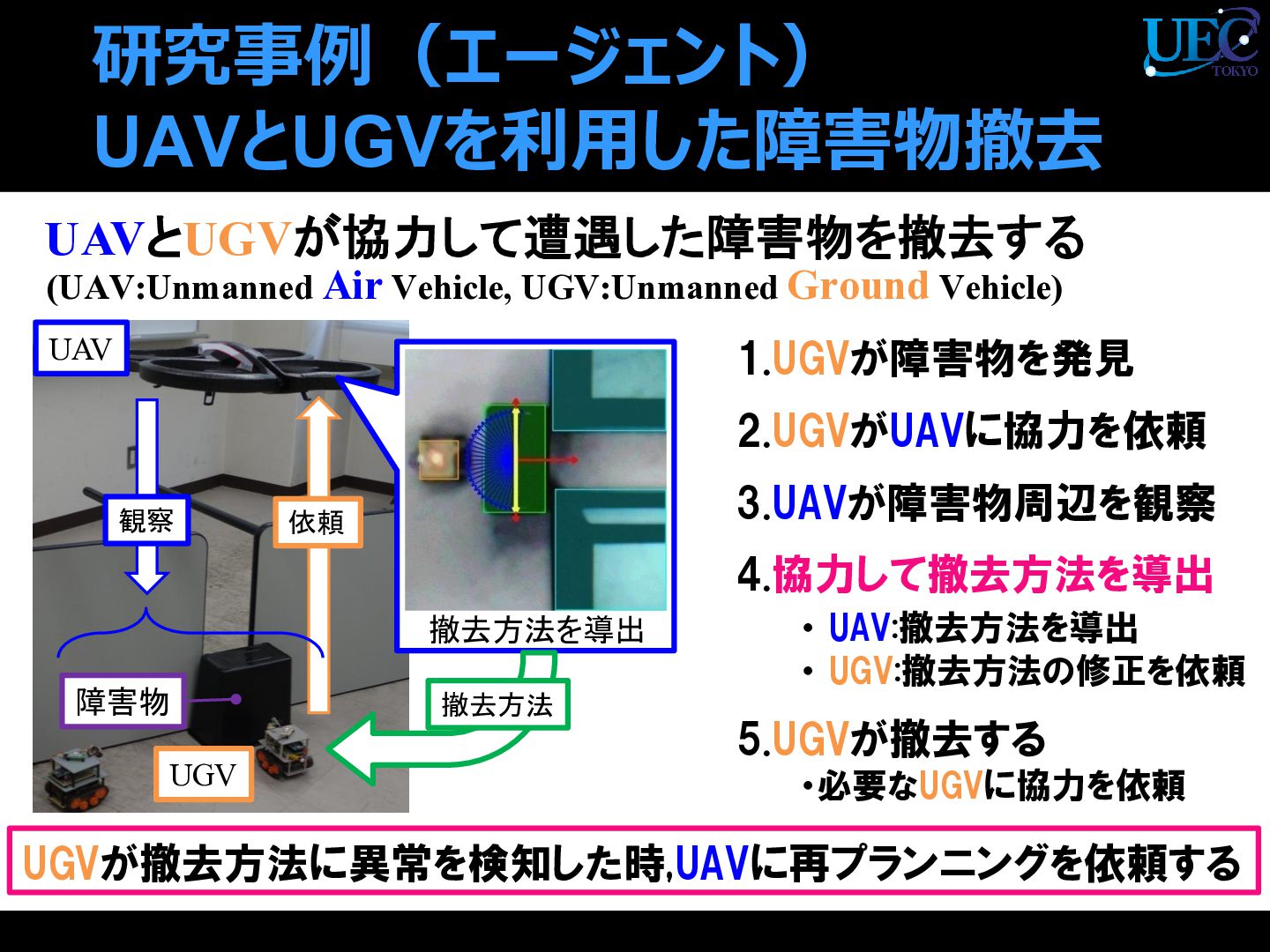{kind=link}
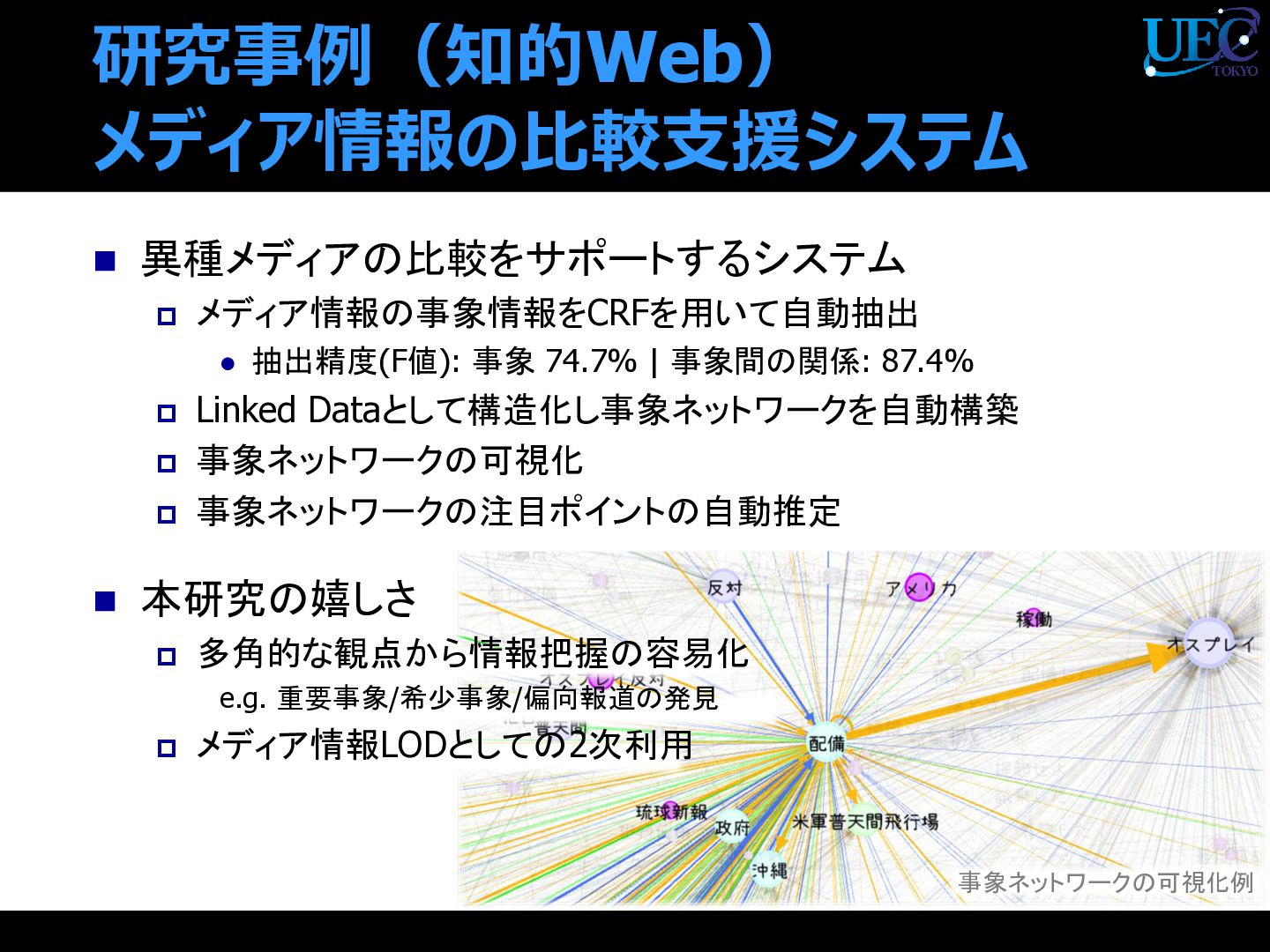{kind=link}
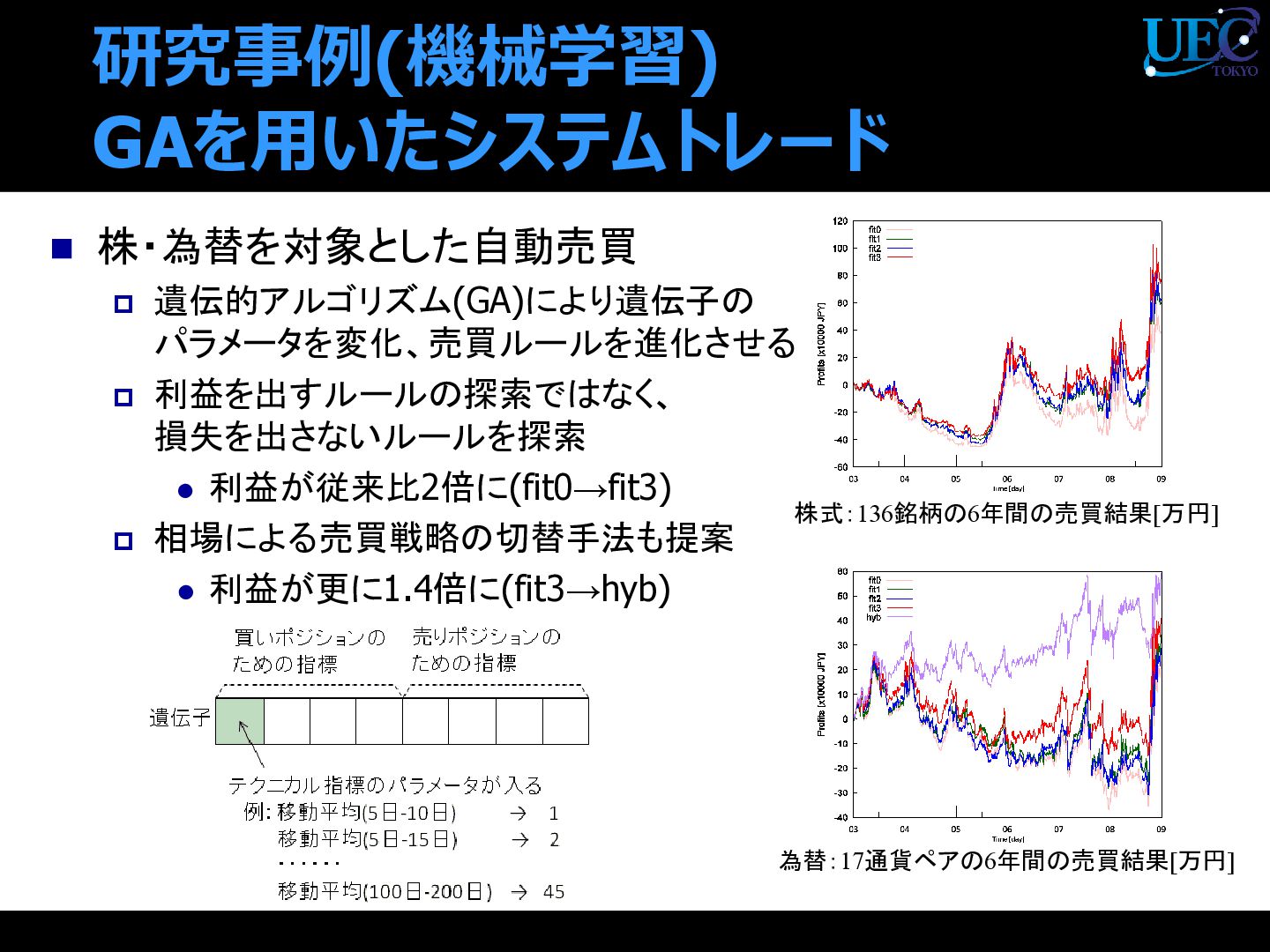{kind=link}
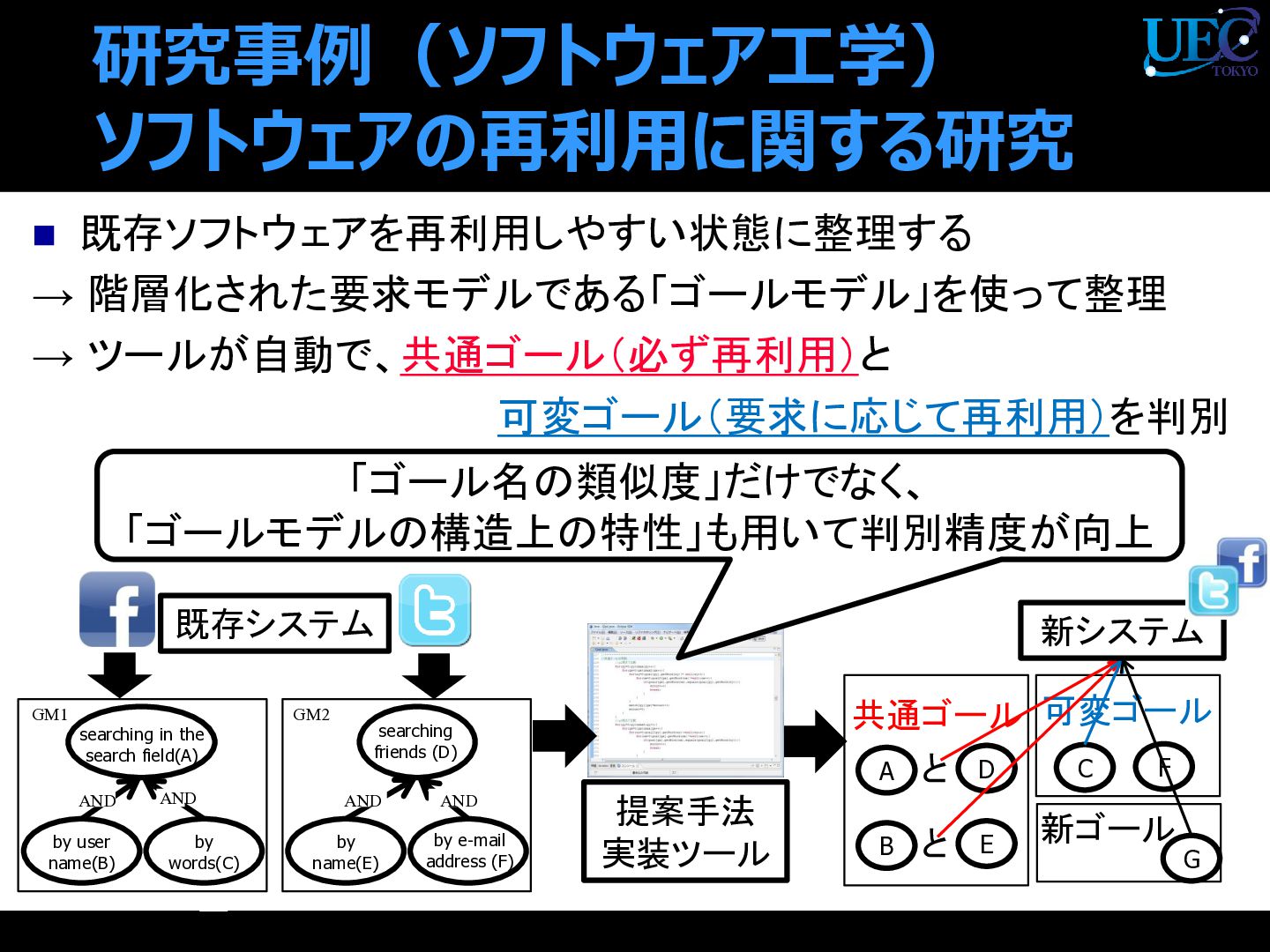{kind=link}
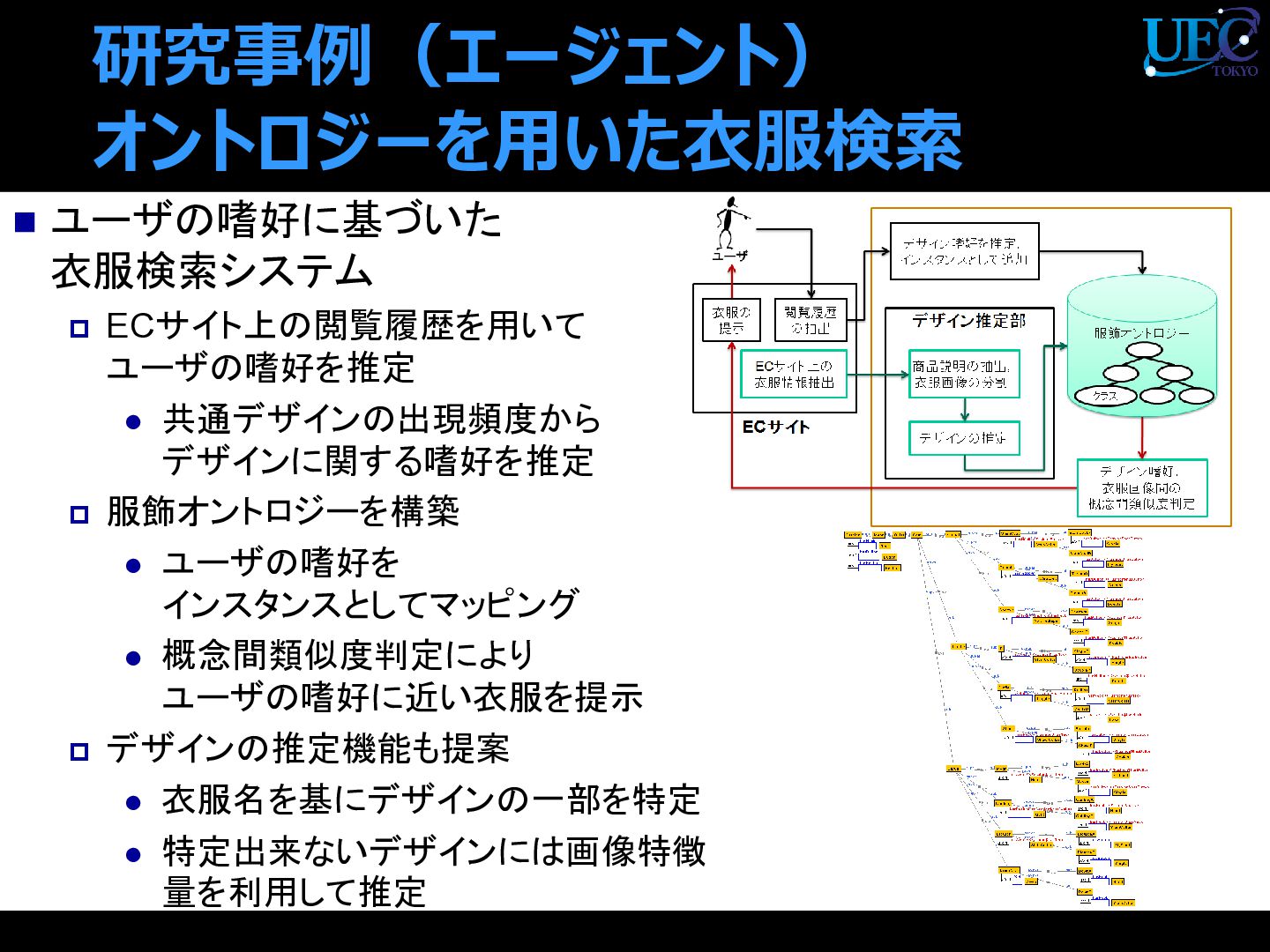{kind=link}
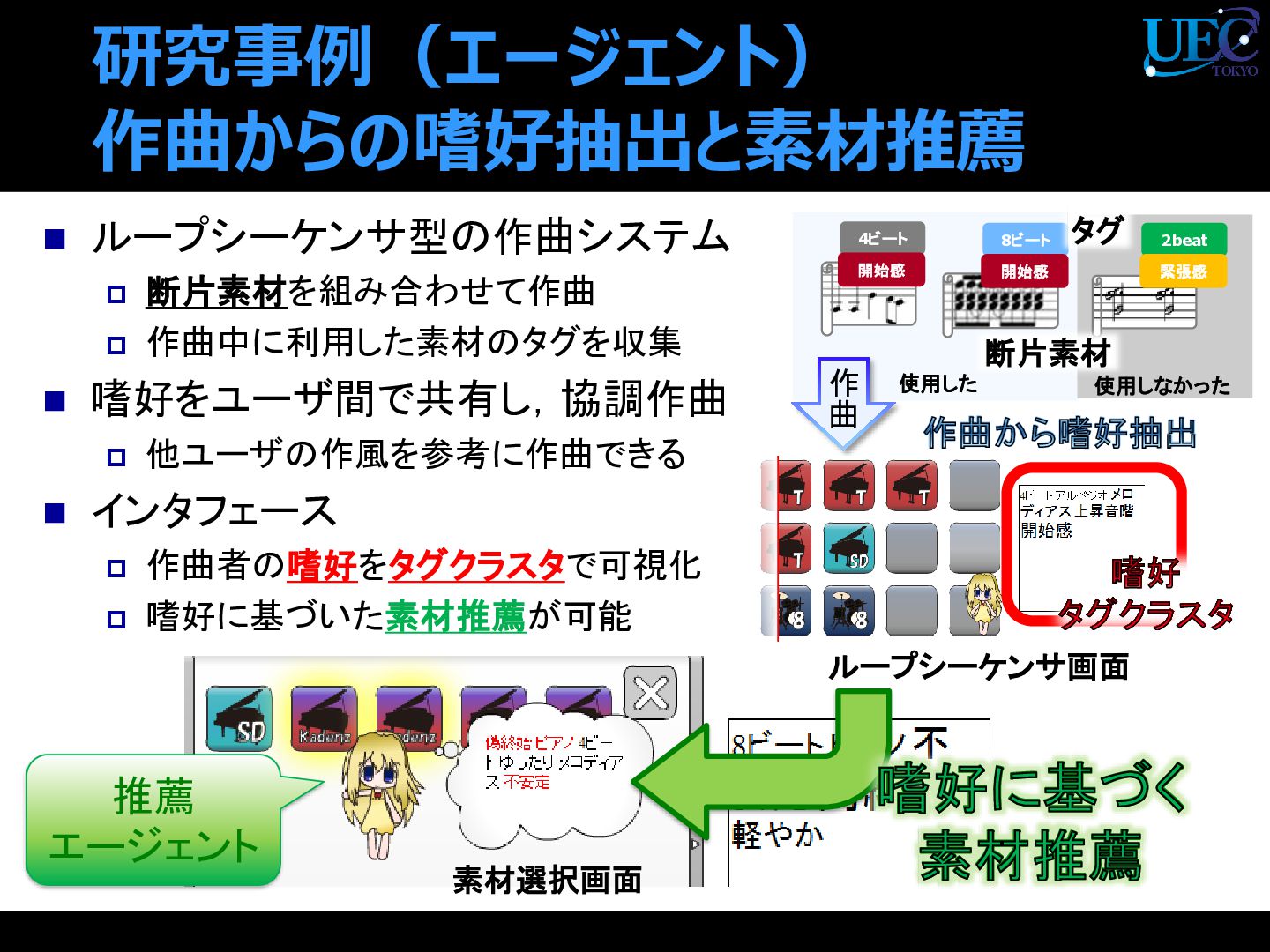{kind=link}
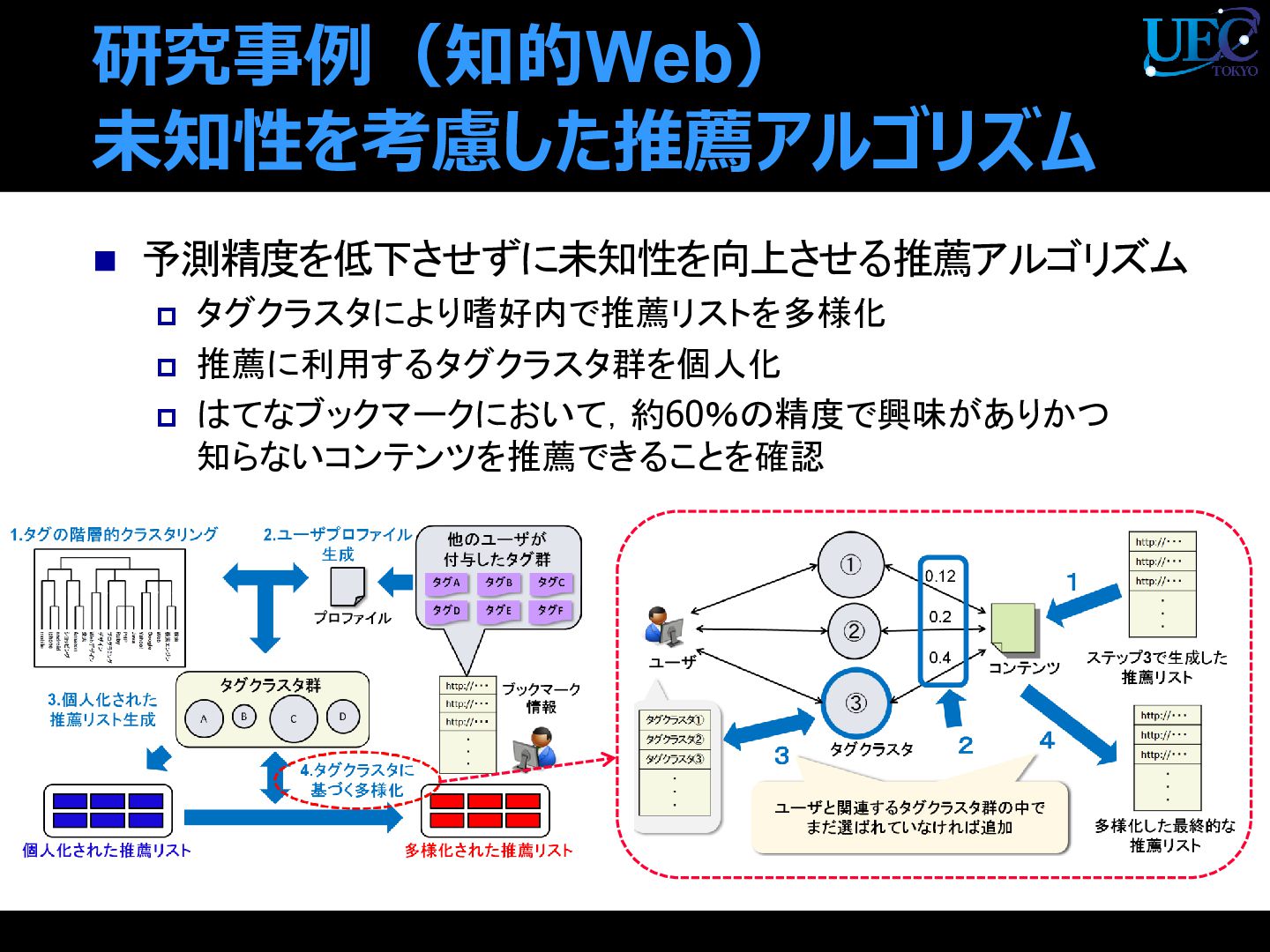{kind=link}
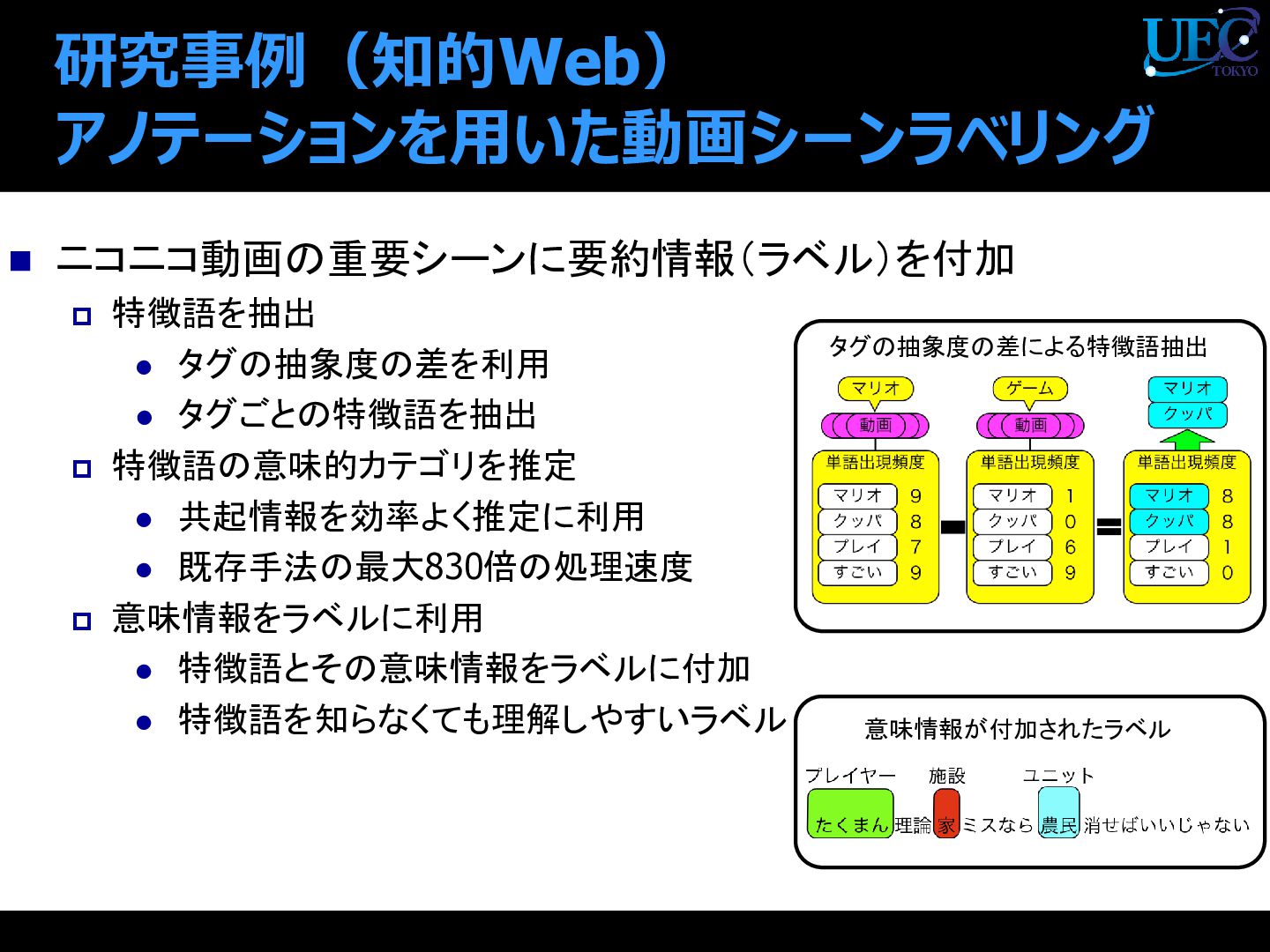{kind=link}
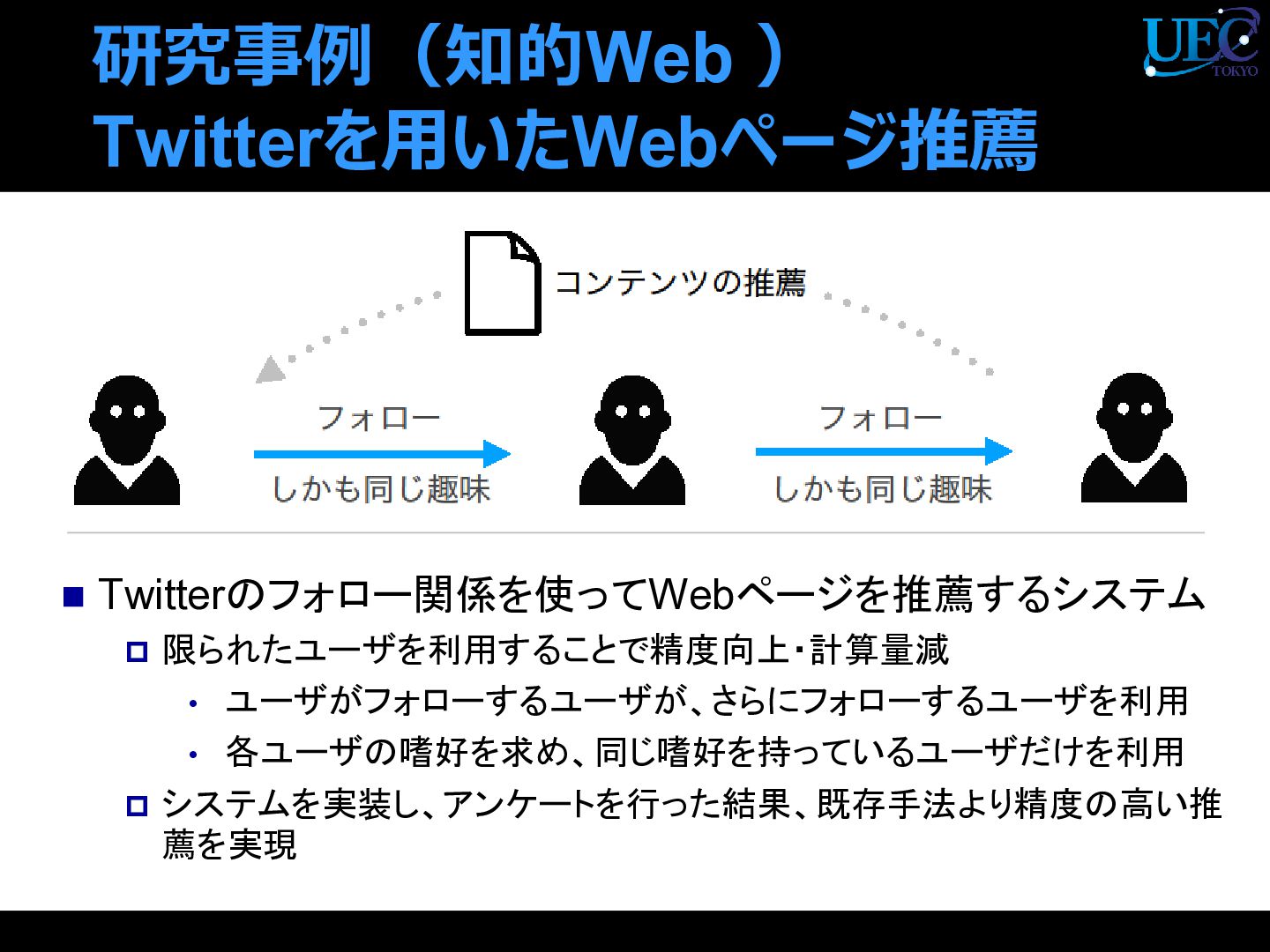{kind=link}
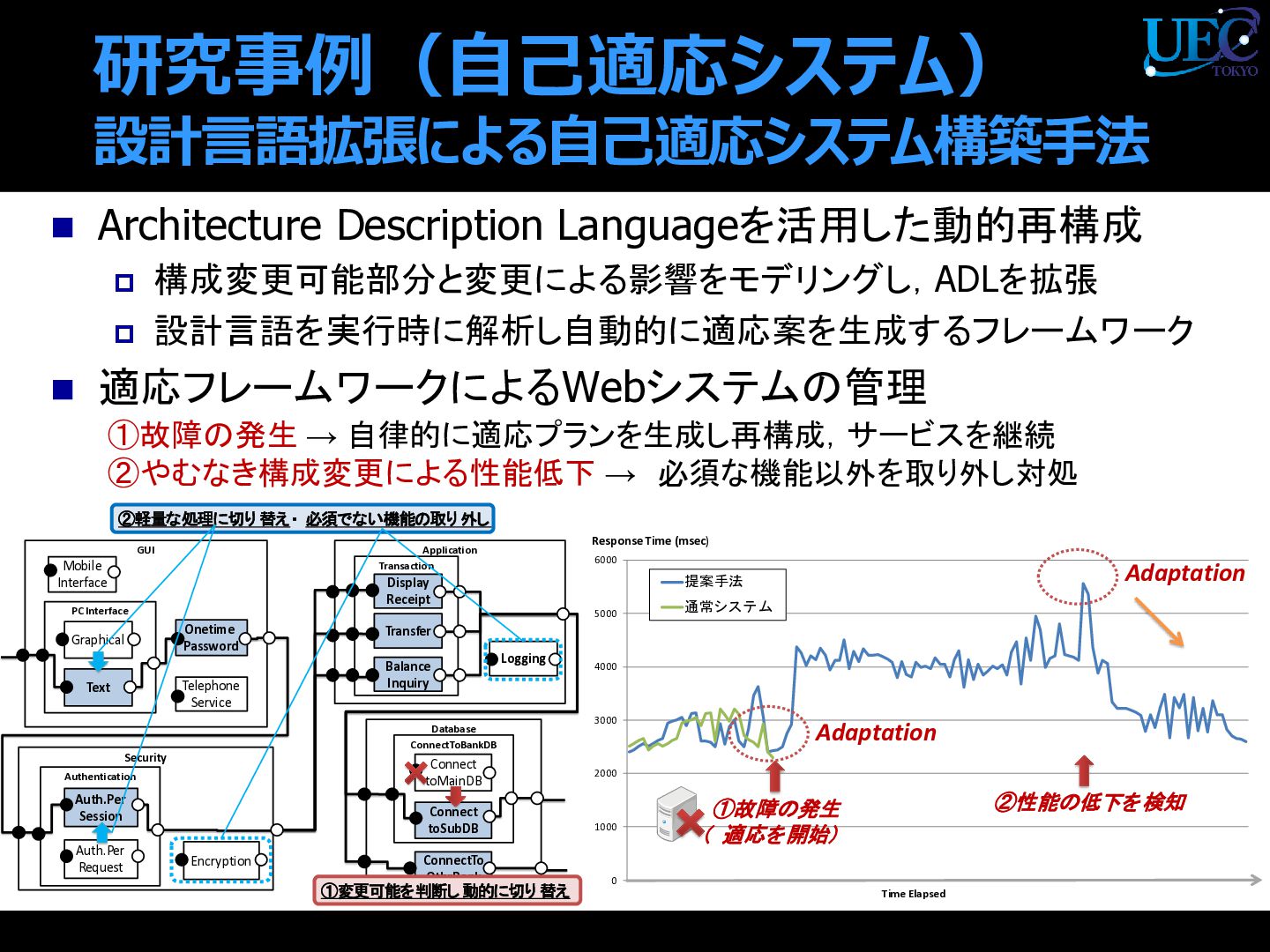{kind=link}
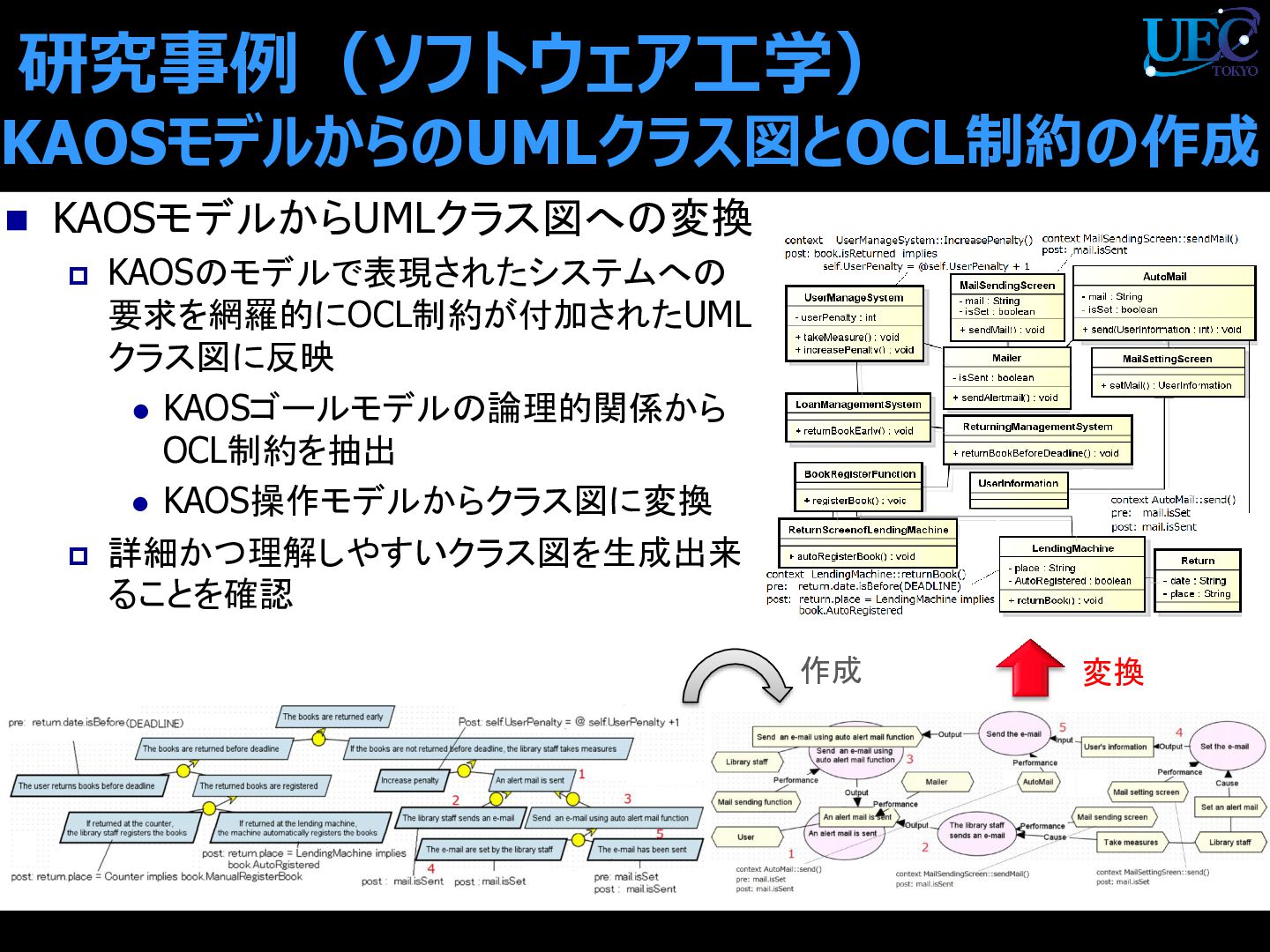{kind=link}
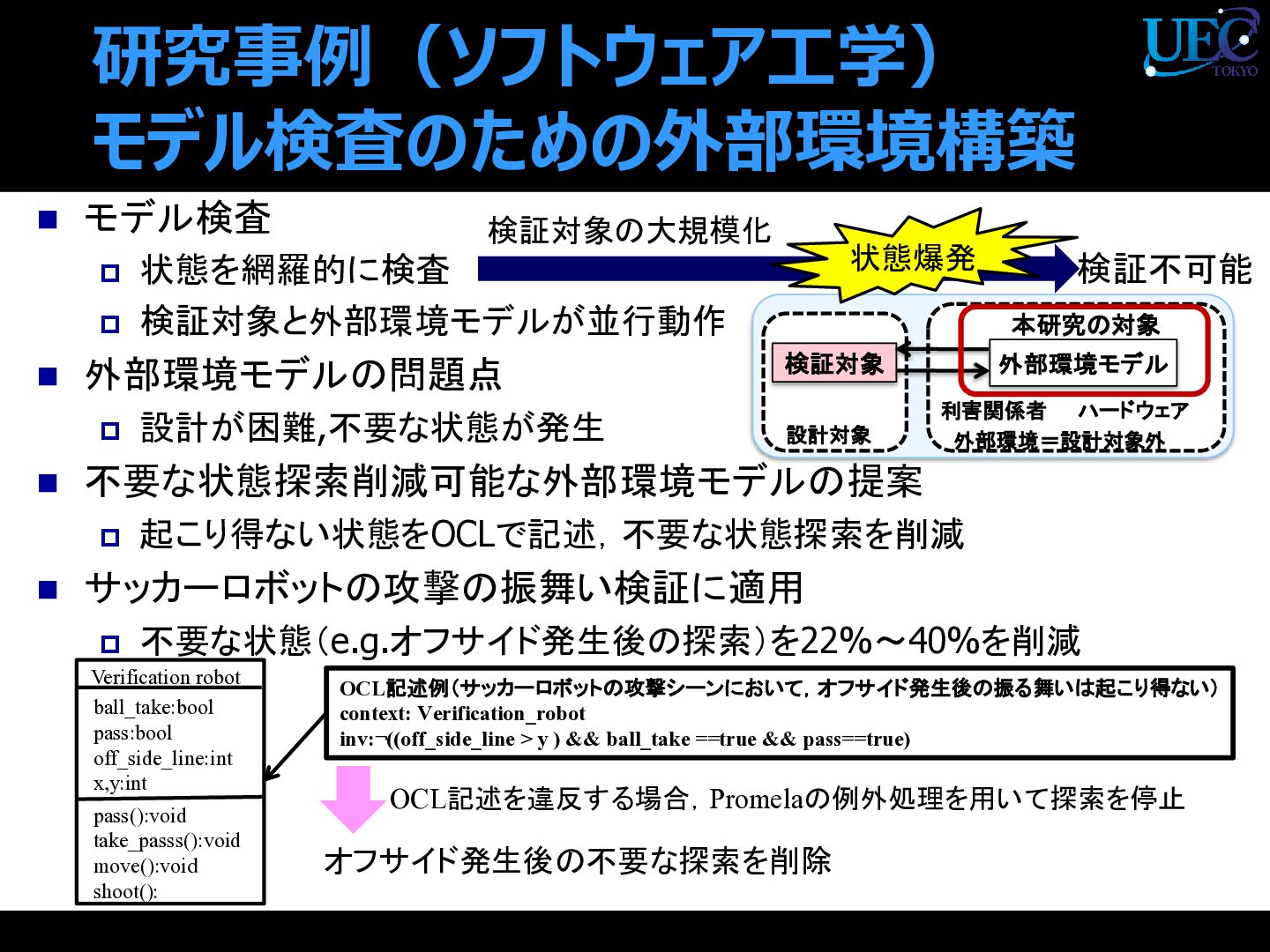{kind=link}
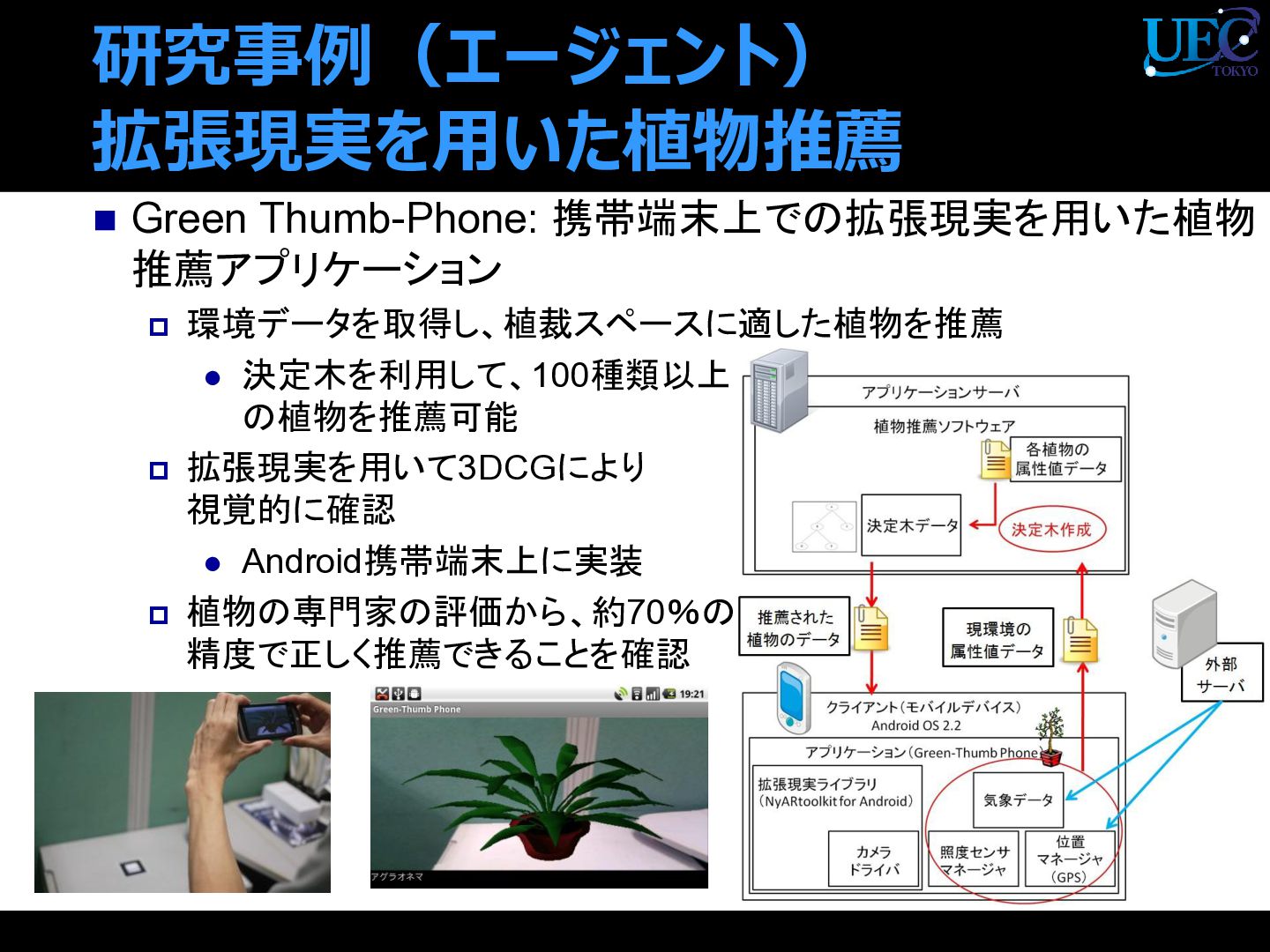{kind=link}
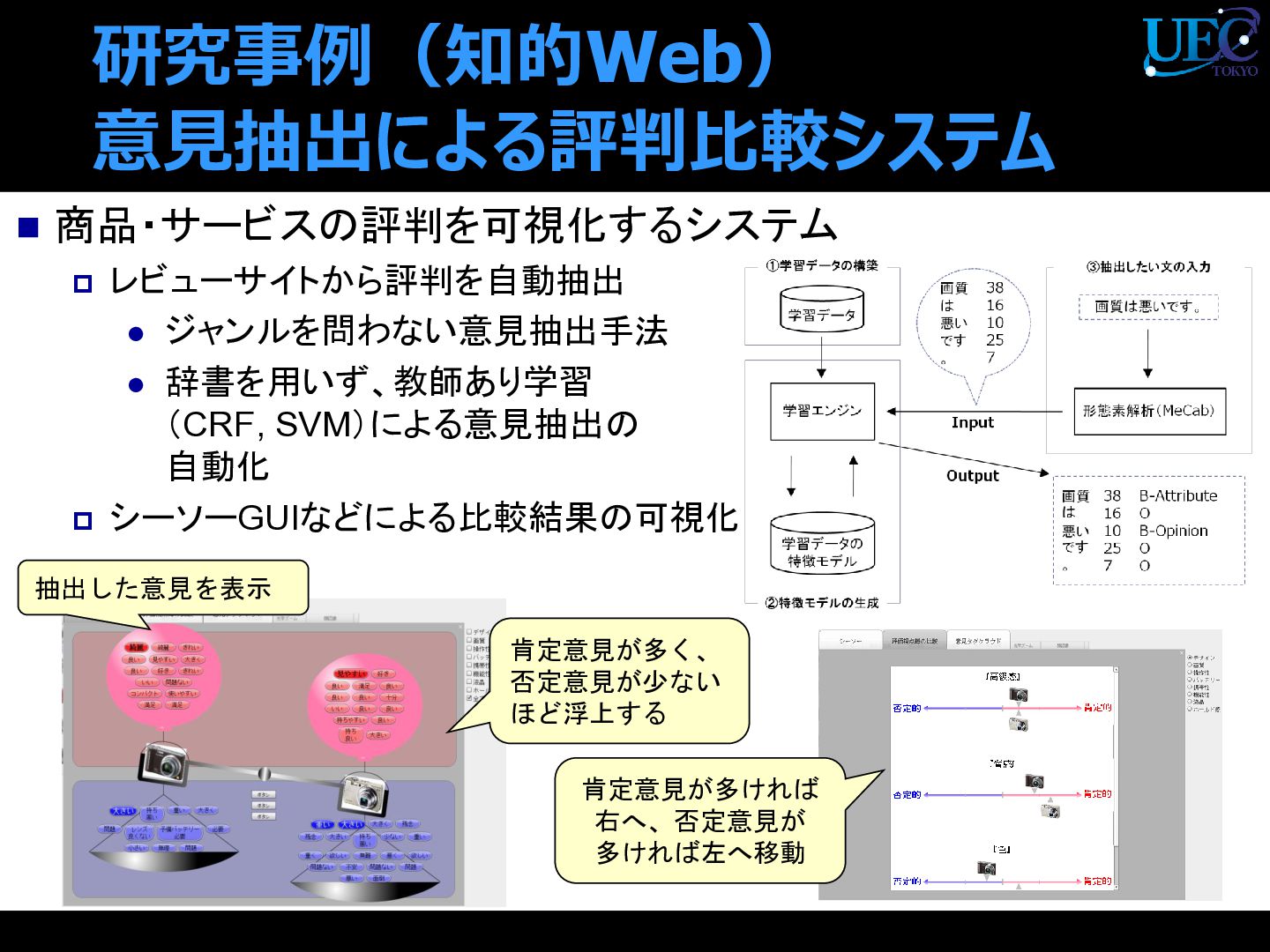{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
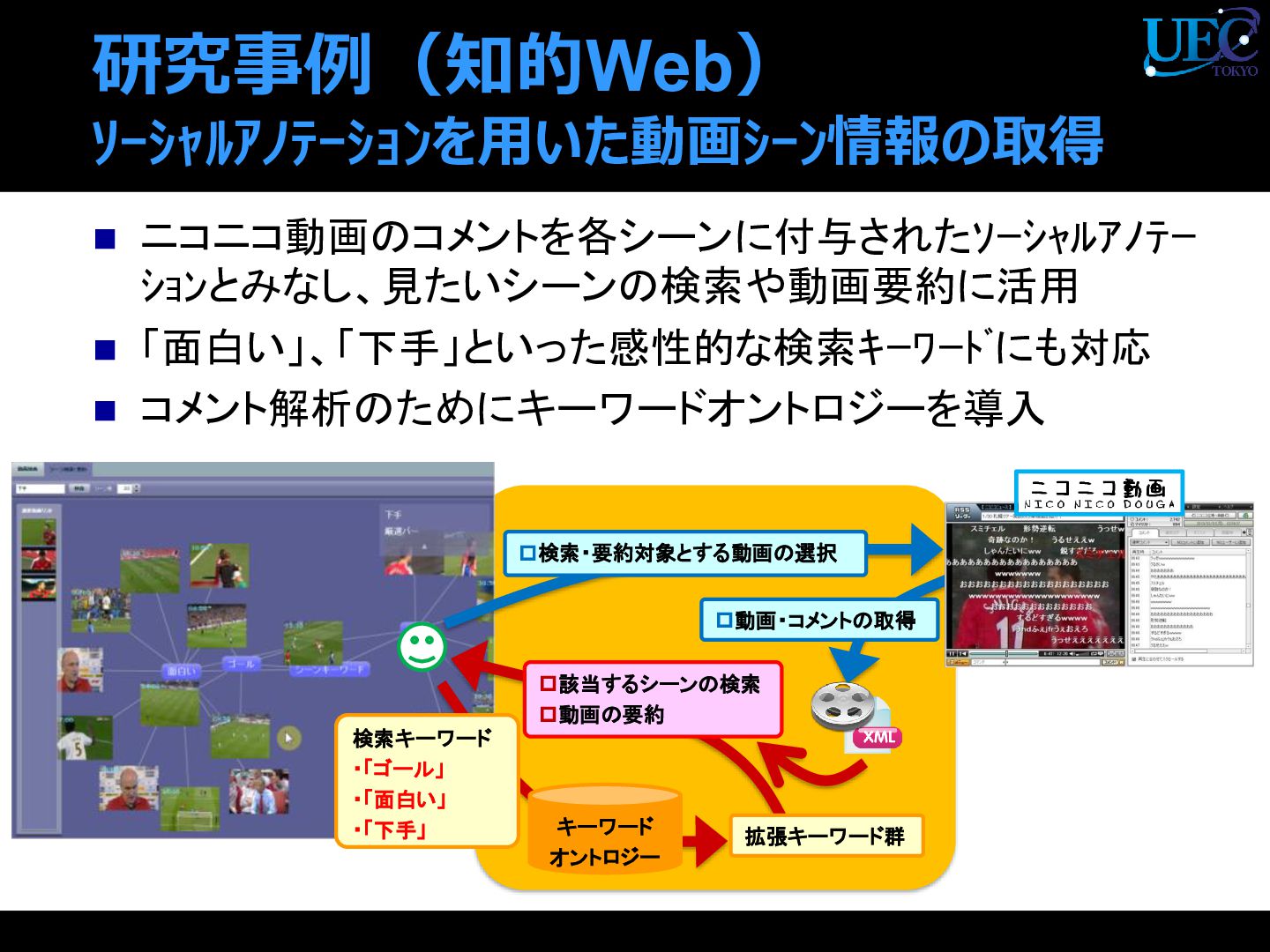{kind=link}
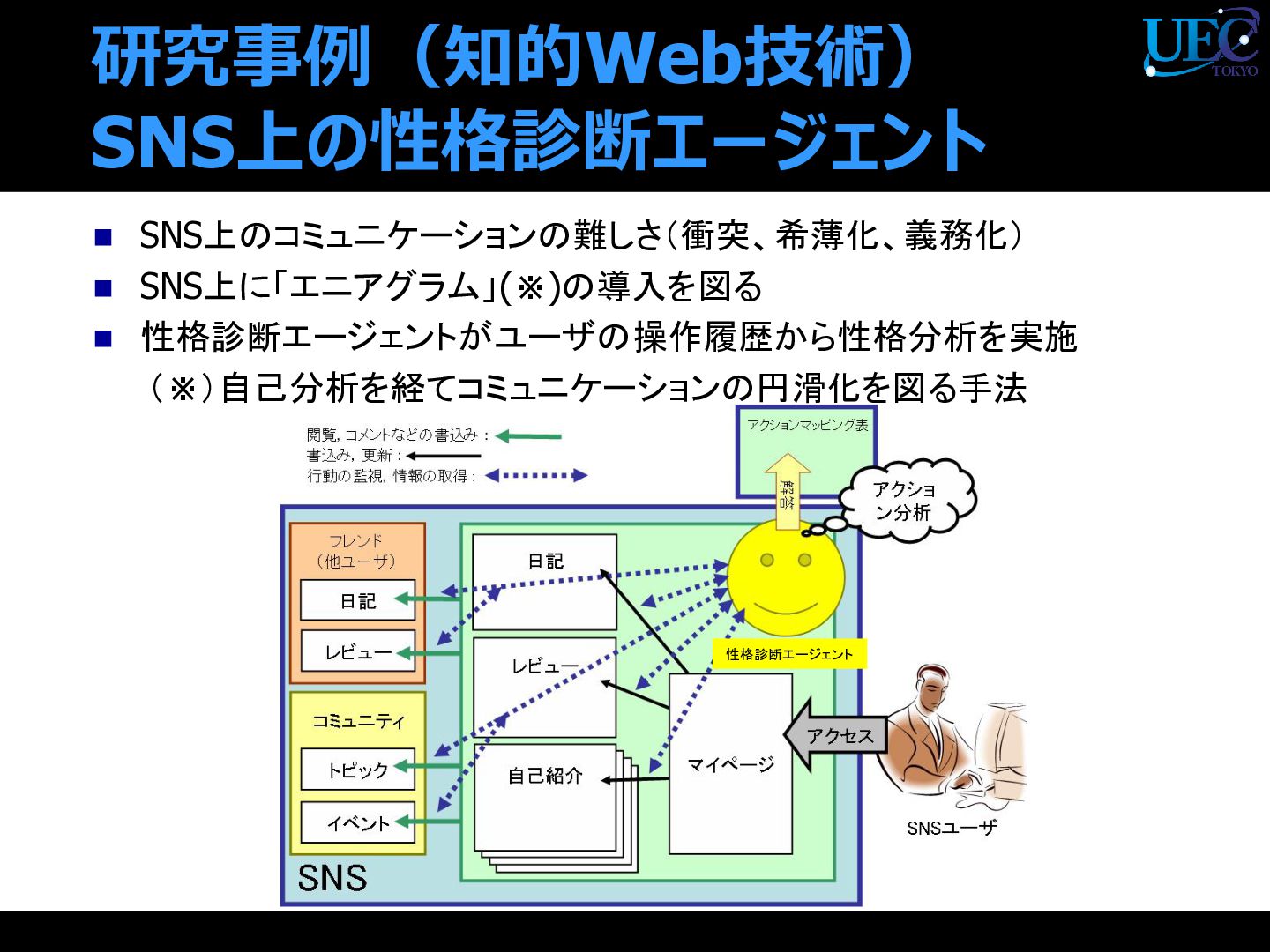{kind=link}
{kind=link}
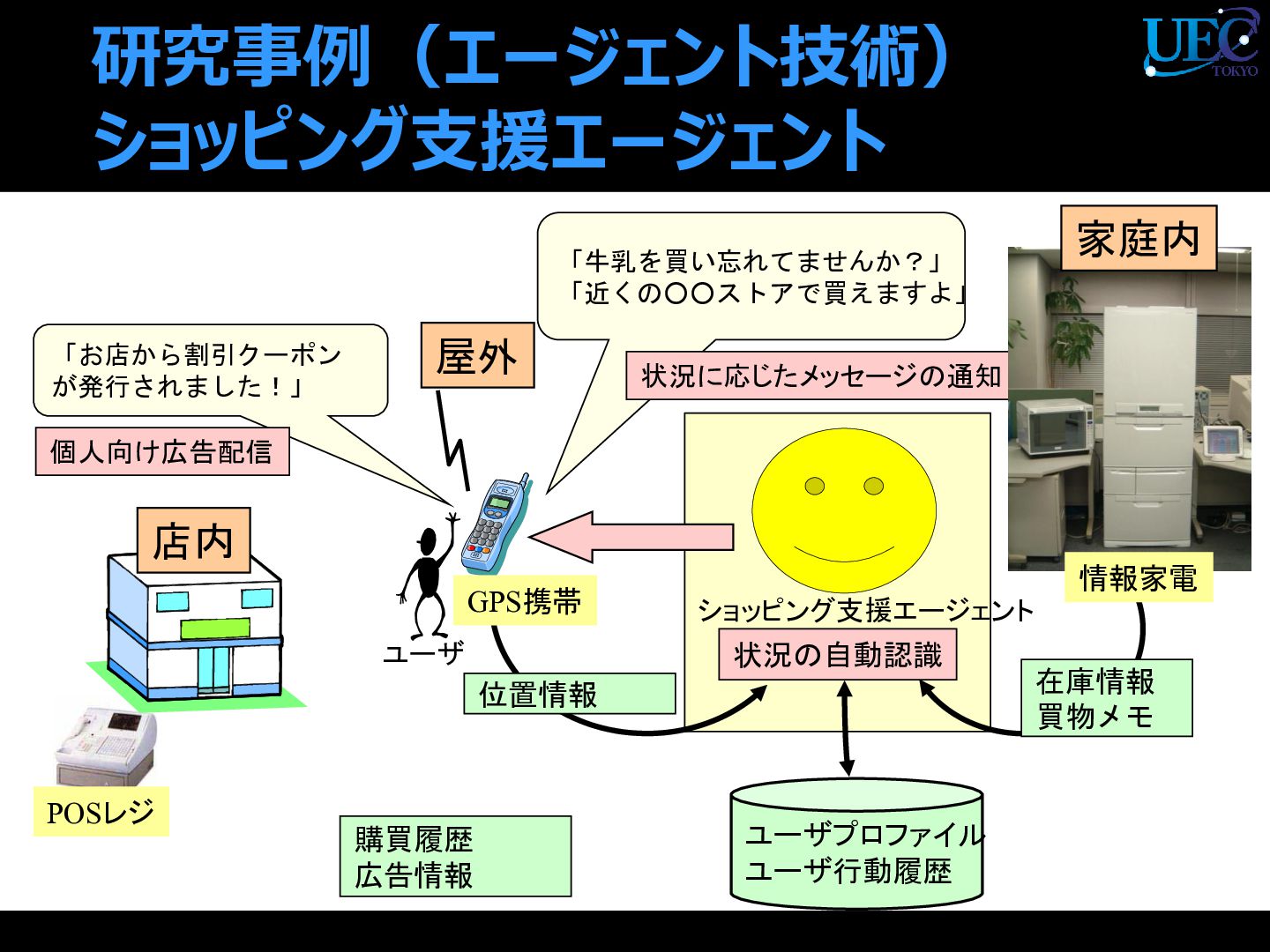{kind=link}