Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2020.10-にゃーにゃーマップvol.4(Uber H3 Index)
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
w2or3w
October 30, 2020
430
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2020.10-にゃーにゃーマップvol.4(Uber H3 Index)
w2or3w
October 30, 2020
More Decks by w2or3w
See All by w2or3w
2021.09-DeployDeGo!!
w2or3w
0
27
2021.08-CICD-01
w2or3w
0
65
2021.06-Deploy-de-Go!!
w2or3w
0
44
2021.04-YOTEIASOBI vol.1 (Amplify, Cognito, Google Calendar)
w2or3w
0
320
2020.12-浜松IT合同勉強会2020
w2or3w
0
310
2020.09-JAWS UG SONIC(コロナ対策サイト+にゃーにゃーマップvol.3)
w2or3w
0
350
2020.07-にゃーにゃーマップvol.2(CloudSearch)
w2or3w
0
360
2020.06-にゃーにゃーマップvol.1
w2or3w
0
350
2020.03-サーバーレスWebアプリ制作で学ぶAppSync
w2or3w
0
350
Featured
See All Featured
Building AI with AI
inesmontani
PRO
1
1.1k
Navigating Team Friction
lara
192
16k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
800
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Prompt Engineering for Job Search
mfonobong
0
370
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
260
GraphQLとの向き合い方2022年版
quramy
50
15k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Transcript
サーバーレスWebアプリ制作で学ぶ にゃーにゃーマップ vol.4 2020.10.30 JAWS UG 浜松 2or3
ナカムラ ツカサ 2(ツー) or(~か) 3(サン) 38才 リーマンアプリケーションエンジニア 最近サーバーレスアプリ制作にお熱です! 好き :
川や雪山で遊ぶこと JAWS-UG歴 : 約1年 @w2or3w 自己紹介
自己紹介 2019年 6月~ 最初の2,3ヶ月 ぼんやり参加 ↓ 2019年 9月頃 何かやらねば事件 →
2019年〜10, 11, 12月 1つ目の作品『Mosaic』 ダッシュで制作 &進捗報告at勉強会 ↓ みなぎってきてる (37才)
自己紹介 みなぎってきてる (37才) ↓ 2020年 3〜4月 コロナ対策サイトに 関わったりしながら、、 → 2020年
4〜5月 2つ目の作品 『にゃーにゃーマップ』制作 ↓ ますますみなぎる 38才 となるか!?
サーバーレスWebアプリ制作で学ぶ にゃーにゃーマップ vol.4 2020.10.30 JAWS UG 浜松 2or3
• AWSを活用したサーバーレスWebアプリ • 新型コロナ対策サイトで利用されていた技術の更なるキャッチアップ • テイクアウトサイトの乱立。すぐ動ける人達への尊敬。 • ワタシもコロナにかこつけたアプリを作ってみたかった。 • 店舗やメディアの情報をキュレーションしたマップベースのWebアプリ
• Stay NEAR, Enjoy NEAR (近くで楽しむ) がコンセプト • 絶賛学習 & 拡張中。 サーバーレスWebアプリ 『にゃーにゃーマップ』とは? https://near-near-map.w2or3w.com
サーバーレスWebアプリ 『にゃーにゃーマップ』最近のアップデート https://near-near-map.w2or3w.com
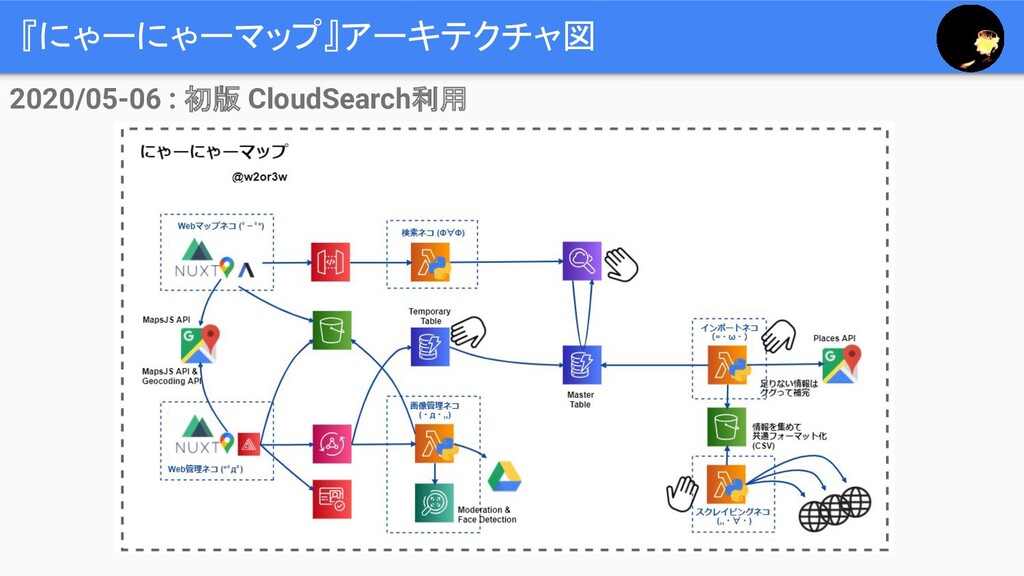
『にゃーにゃーマップ』アーキテクチャ図 Stay Near, Enjoy Near 2020/05-06 : 初版 CloudSearch利用
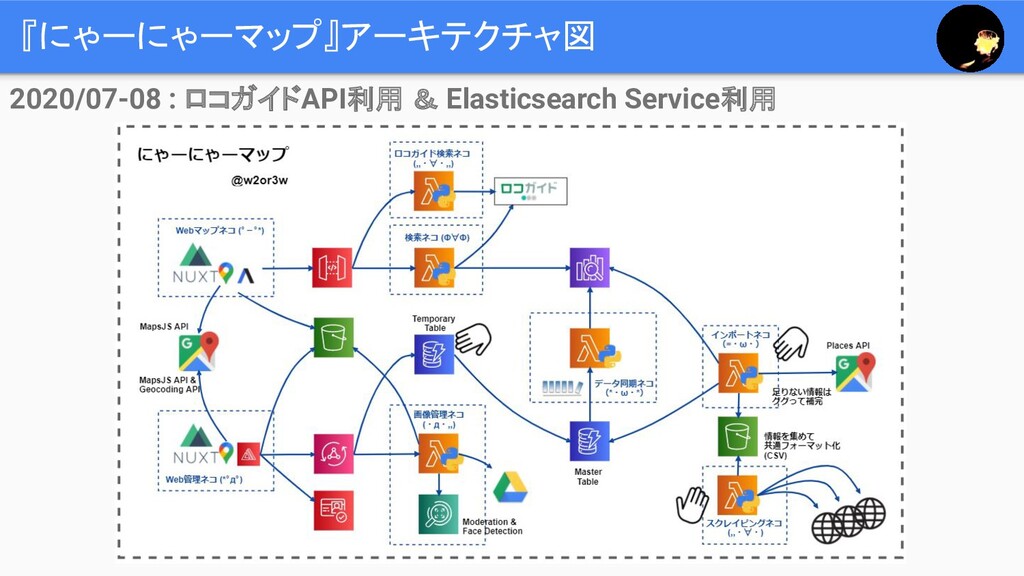
『にゃーにゃーマップ』アーキテクチャ図 Stay Near, Enjoy Near 2020/07-08 : ロコガイドAPI利用 & Elasticsearch
Service利用
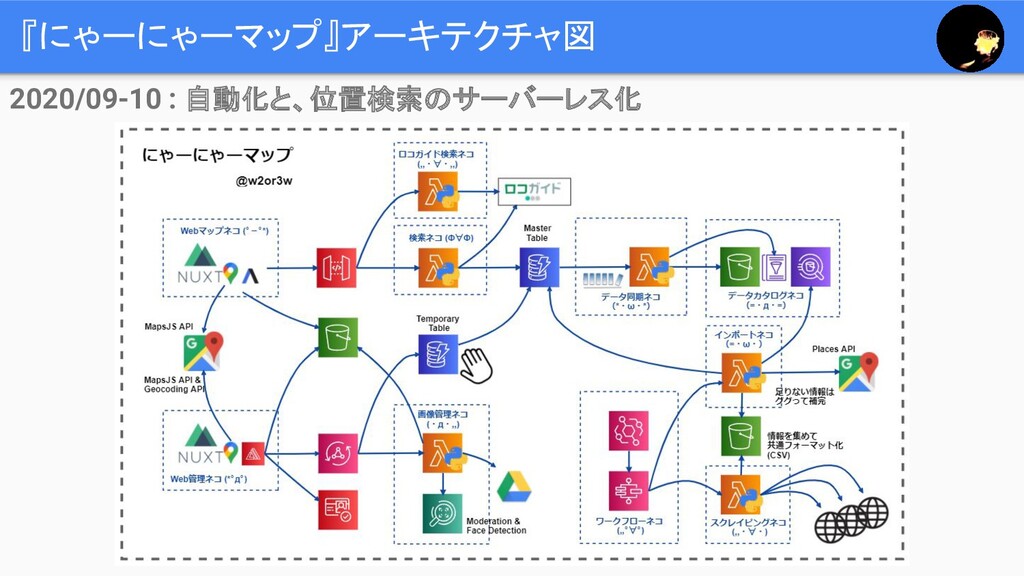
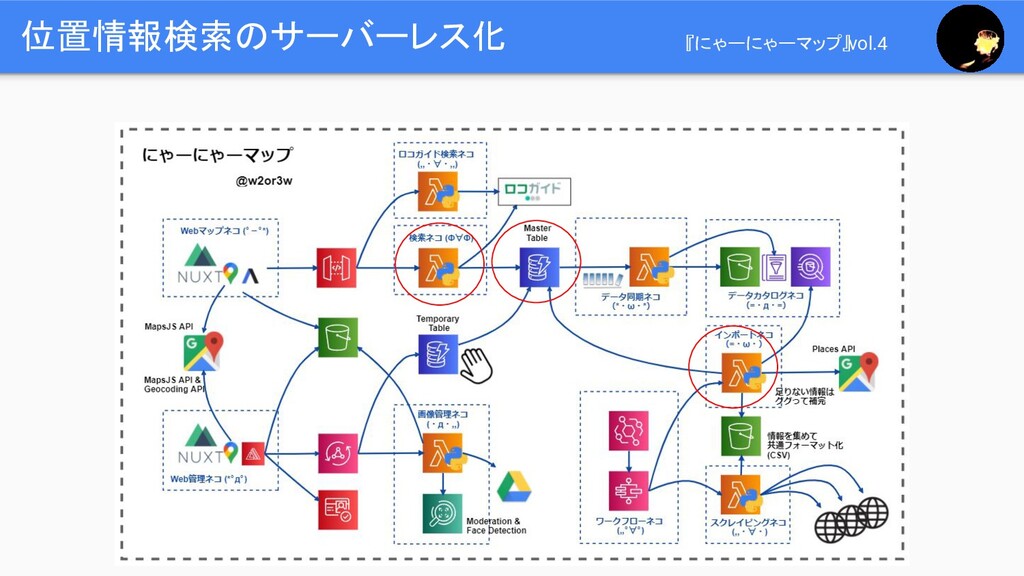
『にゃーにゃーマップ』アーキテクチャ図 2020/09-10 : 自動化と、位置検索のサーバーレス化
『にゃーにゃーマップ』 vol.4 1.位置情報検索のサーバーレス化 #Geohash #H3 #DynamoDB #LocalSecondaryIndex #Python 2.スクレイピングとインポートの自動化 #EventBridge
#StepFunctions #Lambda #DynamoDB #DynamoDBStream #S3 #Athena #DataCatalog (近くの情報を取ってくるやつ) 今日のテーマ
『にゃーにゃーマップ』 vol.4 1.位置情報検索のサーバーレス化 #Geohash #H3 #DynamoDB #LocalSecondaryIndex #Python 2.スクレイピングとインポートの自動化 #EventBridge
#StepFunctions #Lambda #DynamoDB #DynamoDBStream #S3 #Athena #DataCatalog (近くの情報を取ってくるやつ) 今日のテーマ
位置情報検索のサーバーレス化 『にゃーにゃーマップ』vol.4
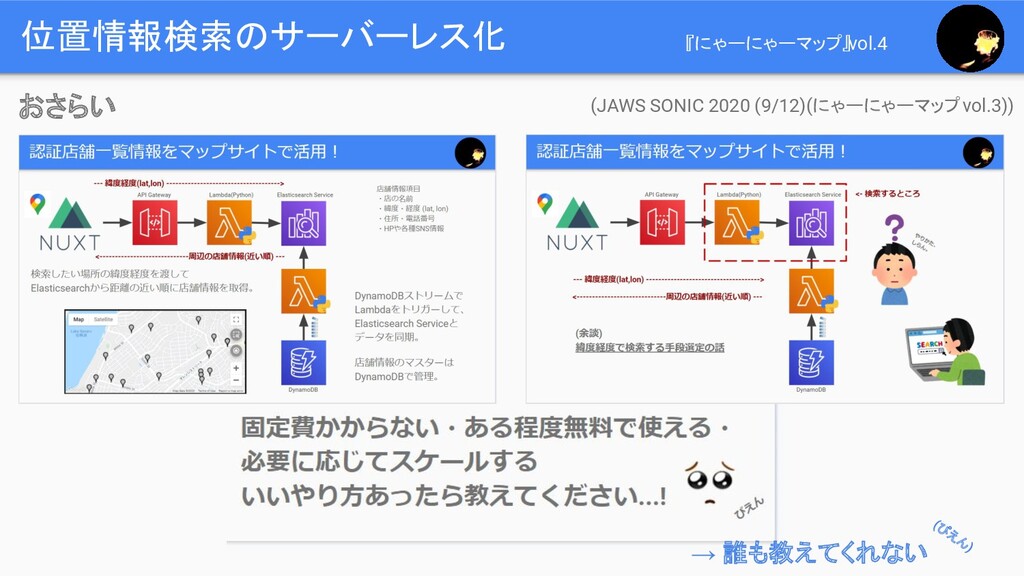
位置情報検索のサーバーレス化 (JAWS-UG浜松 7月の勉強会(にゃーにゃーマップ vol.2)) 『にゃーにゃーマップ』vol.4 こんなの サーバーレス じゃない..!! おさらい
位置情報検索のサーバーレス化 (JAWS SONIC 2020 (9/12)(にゃーにゃーマップ vol.3)) → 誰も教えてくれない (ぴ え
ん ) 『にゃーにゃーマップ』vol.4 おさらい
位置情報検索のサーバーレス化 『にゃーにゃーマップ』vol.4 できた!
位置情報検索のサーバーレス化 https://medium.com/google-cloud-jp/how-to-use-bigtable-for-geolocation-d5f424023be3 『にゃーにゃーマップ』vol.4 参考にした情報
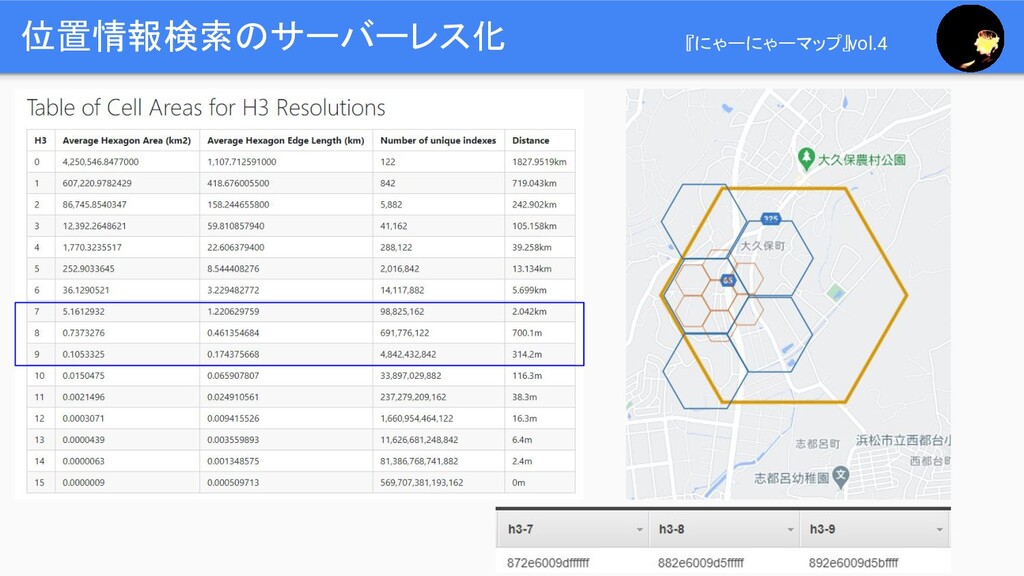
位置情報検索のサーバーレス化 https://eng.uber.com/h3/ 『にゃーにゃーマップ』vol.4
位置情報検索のサーバーレス化 『にゃーにゃーマップ』vol.4
位置情報検索のサーバーレス化 • タイプ • タイトル • 電話番号 • 住所 •
緯度経度 • h3index9 • h3index8 • h3index7 • : Local Secondary Index インポートするところ 『にゃーにゃーマップ』vol.4 店舗の位置 ↓
位置情報検索のサーバーレス化 セカンダリインデックス 1.グローバルセカンダリインデックス 2.ローカルセカンダリインデックス DynamoDB の キー と インデックス プライマリーキー
1.パーティションキー 2.パーティションキー + ソートキー 『にゃーにゃーマップ』の キー と インデックス プライマリーキー : タイプ + GUID (余談 : 昔は電話番号にしてたけど辞めた ) セカンダリインデックス : タイプ + h3index9 : タイプ + h3index8 : タイプ + h3index7 この中にある(=h3index) 複数店舗情報をSelect !! ↑ タイプ (※テーブル作成時にしか作れない。 ) (※プライマリーキーは重複できない。 セカンダリインデックスは重複できる。 ) 『にゃーにゃーマップ』vol.4
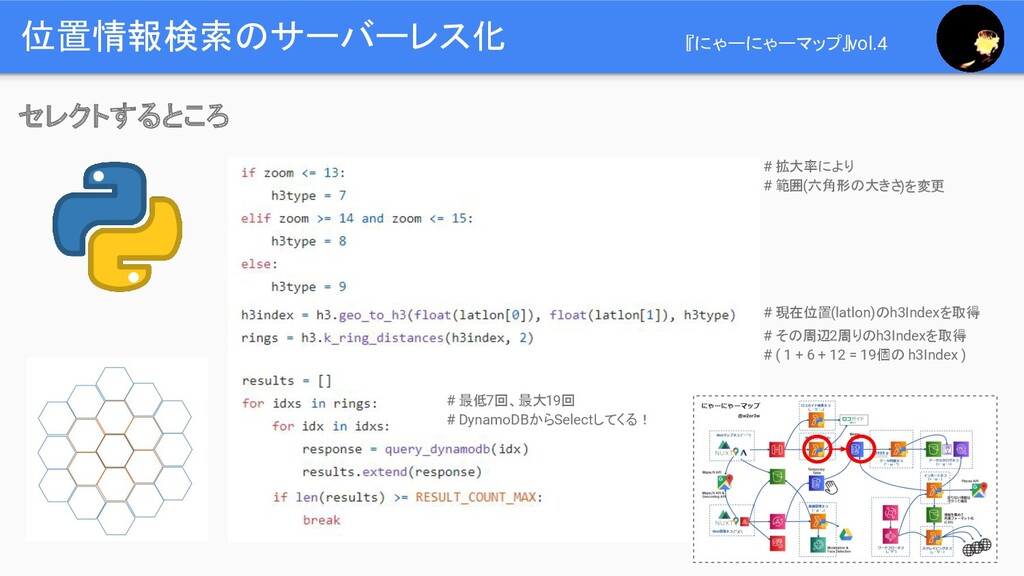
位置情報検索のサーバーレス化 セレクトするところ # 拡大率により # 範囲(六角形の大きさ)を変更 # 現在位置(latlon)のh3Indexを取得 # その周辺2周りのh3Indexを取得
# ( 1 + 6 + 12 = 19個の h3Index ) # 最低7回、最大19回 # DynamoDBからSelectしてくる! 『にゃーにゃーマップ』vol.4
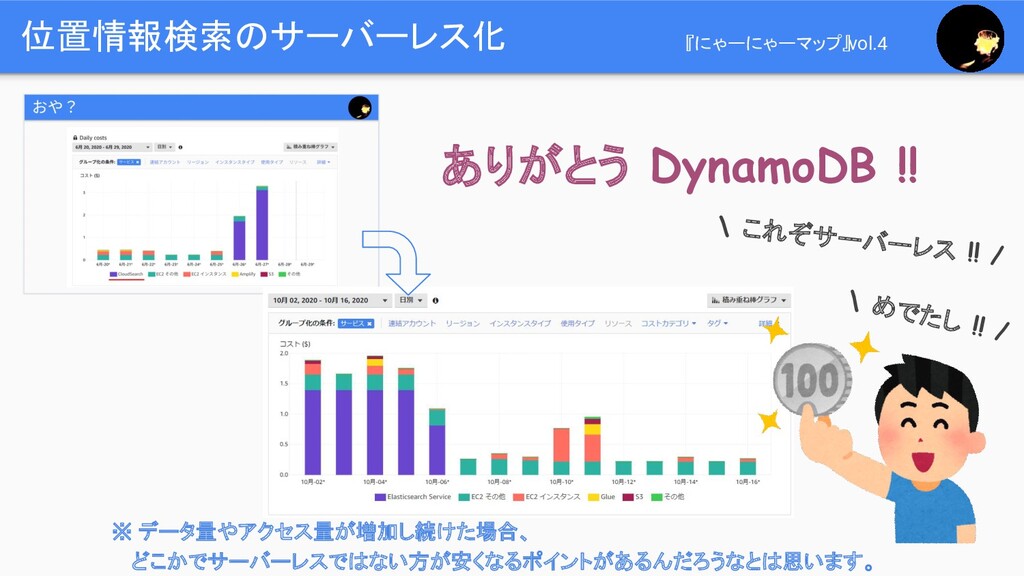
位置情報検索のサーバーレス化 『にゃーにゃーマップ』vol.4 ありがとう DynamoDB !! \ めでたし !! / \
これぞサーバーレス !! / ※ データ量やアクセス量が増加し続けた場合、 どこかでサーバーレスではない方が安くなるポイントがあるんだろうなとは思います。
『にゃーにゃーマップ』 vol.4 1.位置情報検索のサーバーレス化 #Geohash #H3 #DynamoDB #LocalSecondaryIndex #Python 2.スクレイピングとインポートの自動化 #EventBridge
#StepFunctions #Lambda #DynamoDB #DynamoDBStream #S3 #Athena #DataCatalog (近くの情報を取ってくるやつ) 今日のテーマ
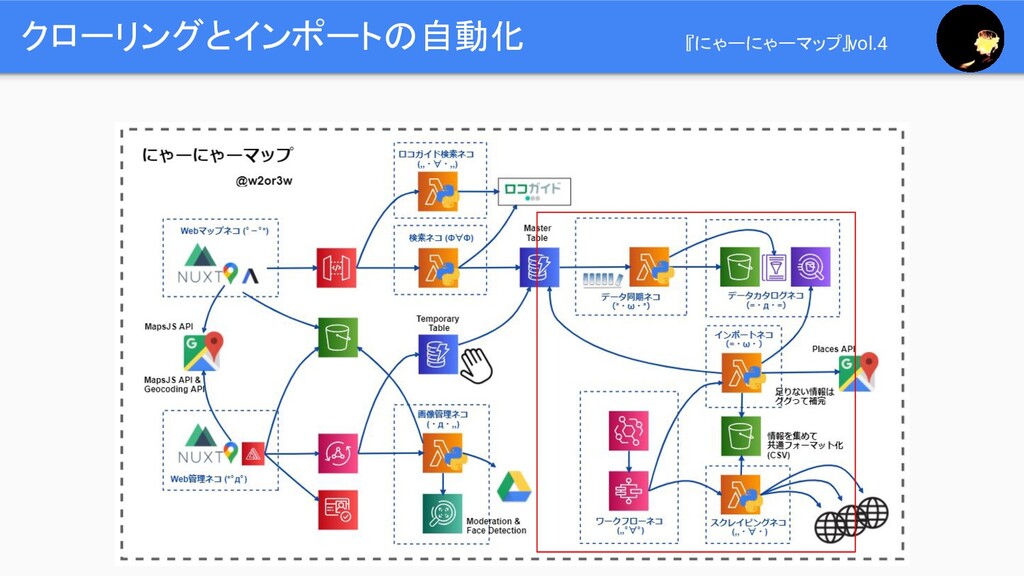
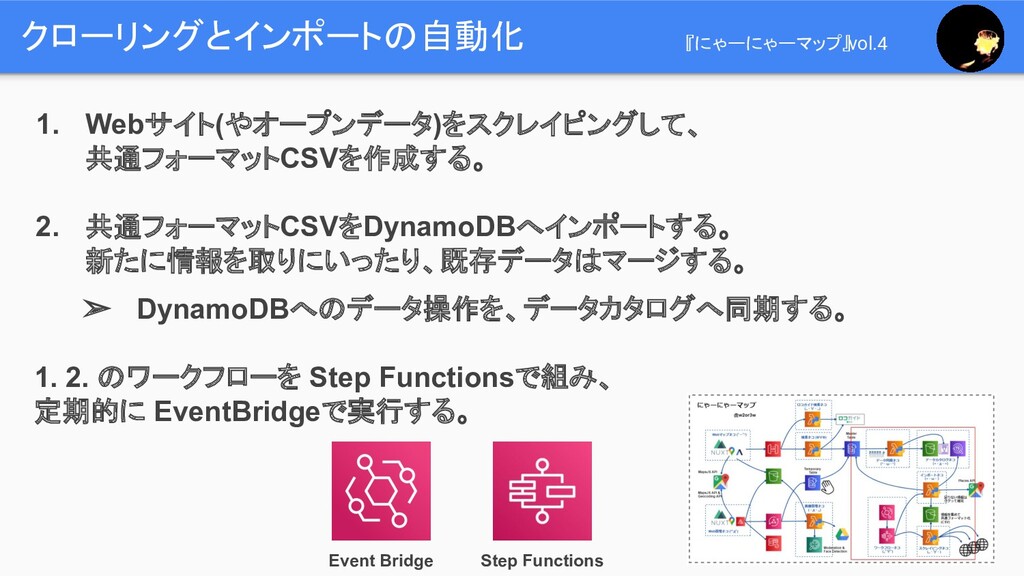
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 1. Webサイト(やオープンデータ)をスクレイピングして、 共通フォーマットCSVを作成する。 2. 共通フォーマットCSVをDynamoDBへインポートする。 新たに情報を取りにいったり、既存データはマージする。 ➢ DynamoDBへのデータ操作を、データカタログへ同期する。
1. 2. のワークフローを Step Functionsで組み、 定期的に EventBridgeで実行する。 Event Bridge Step Functions
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 1. Webサイト(やオープンデータ)をスクレイピングして、 共通フォーマットCSVを作成する。 • type : food /
drink / life / mask / outdoor / hotspring / plant • title : 店舗名称 • address : 住所 (フォーマット特に指定なし) • tel : 電話番号 (ハイフン無し) • homepage : 店舗ホームページのアドレス • fb, insta, twitter : 各種SNSのアドレス • media1~5 : その他メディアのアドレス • locoguide_id : ロコガイドの混雑ランプ対応している場合はその ID • star : 認証店舗(1)やGoToEat(2)をビットフラグで保持 スクレイピングは Python の Beautiful Soup というライブラリを利用したよ
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 2. 共通フォーマットCSVをDynamoDBへインポートする。 新たに情報を取りにいったり、既存データはマージする。 • type, title, address, media1~5,
locoguide_id, star => csv値の値をそのままマージ • latlon : Google Places API「title address」で検索して取得する • tel, homepage : csv値 (無い場合 Google Places API 「title address」で検索して取得してみる) • fb, insta, twitter : csv値 ( + homepageのindexをクローリングして探してみる) • h3-9,8,7 : h3.geo_to_h3(lat, lon)で取得する • has_xframe_options : homepage, media1~5 レスポンスヘッダに「X-Frame-Options」があるかどうか? (=IFrame表示を許可しているか?) クローリングだけでは捕りきれない情報はググって補完! \ ないしょだよ /
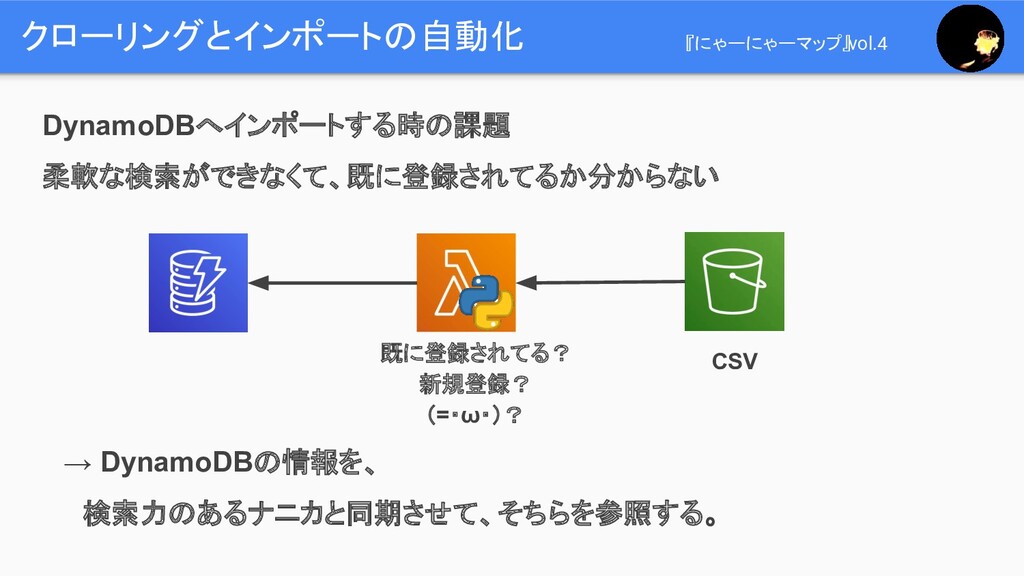
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 DynamoDBへインポートする時の課題 柔軟な検索ができなくて、既に登録されてるか分からない 既に登録されてる? 新規登録? (=・ω・)? CSV → DynamoDBの情報を、
検索力のあるナニカと同期させて、そちらを参照する。
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 CSV DynamoDBの情報を、 検索力のあるナニカと同期させて、そちらを参照する。 ナニカ 更新内容を ストリーミング 同期 ←
レプリカ ↑ マスター インポートネコ (=・ω・) 電話番号で検索とか できるようになる。
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 DynamoDBのレプリカ何にする? RDS ? Elasticsearch ? < そんなばかな!
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 DynamoDBのレプリカ何にする? Athena !! < よし! ※ バックエンドでインポートするときにしか参照しない
( = 同時に大量のリクエストが発生しない & 多少遅くても問題ない ) から、採用できる。 S3 !! &
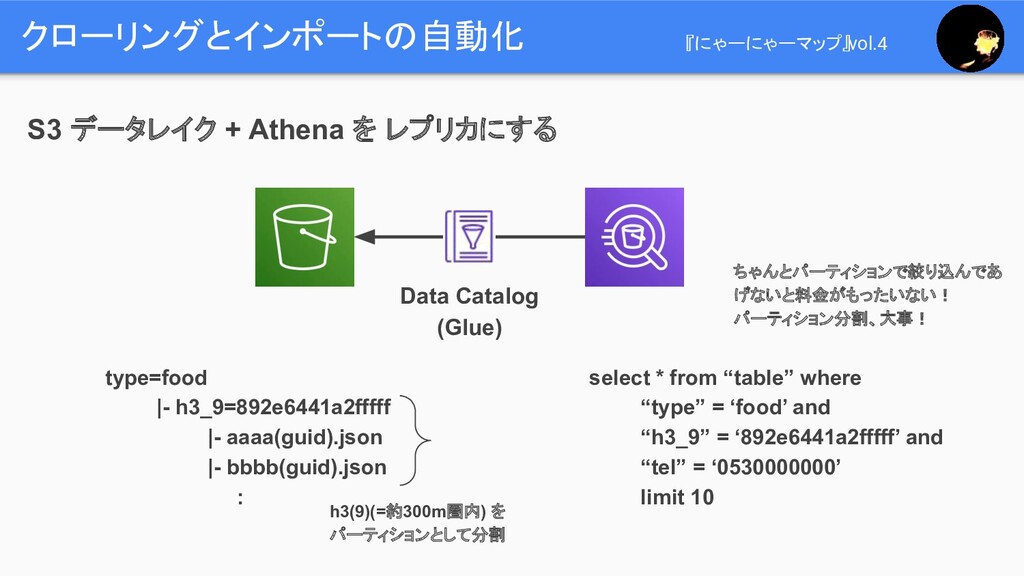
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 S3 データレイク + Athena を レプリカにする Data Catalog
(Glue) type=food |- h3_9=892e6441a2fffff |- aaaa(guid).json |- bbbb(guid).json : h3(9)(=約300m圏内) を パーティションとして分割 select * from “table” where “type” = ‘food’ and “h3_9” = ‘892e6441a2fffff’ and “tel” = ‘0530000000’ limit 10 ちゃんとパーティションで絞り込んであ げないと料金がもったいない! パーティション分割、大事!
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 S3 データレイク + Athena を レプリカにする 手順: 1.
S3にファイルを保存しておく。 2. Glueのクローラを作成し、実行する。 (入力元はS3、出力先は新規データカタログとする) 3. Athenaでクエリ出来ることを確認する。 ※インポートで発生するデータ同期時に、 パーティションが増えた場合はデータカタログへ追加する必要あり。 (そうしないとAthenaで参照できない) alter table "tablename" add if not exists partition ( “p_type”='food', “h3_9”='892e6441a2fffff' ) location 's3://bucketname/type=food/h3_9=892e6441a2fffff/'
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 CSV DynamoDBの情報を、S3・データカタログと同期させて、 Athenaから参照できるようにする。 更新内容を ストリーミング ← レプリカ ↑
マスター インポートネコ (=・ω・) 電話番号で検索とか できるようになる。 同期 (データ・パーティション) 検索ネコ (Ф∀Ф)
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 1. Webサイト(やオープンデータ)をスクレイピングして、 共通フォーマットCSVを作成する。 2. 共通フォーマットCSVをDynamoDBへインポートする。 新たに情報を取りにいったり、既存データはマージする。 ➢ DynamoDBへのデータ操作を、データカタログへ同期する。
定期的に 1. 2. のワークフローを Step Functionsで実行する。 Event Bridge Step Functions
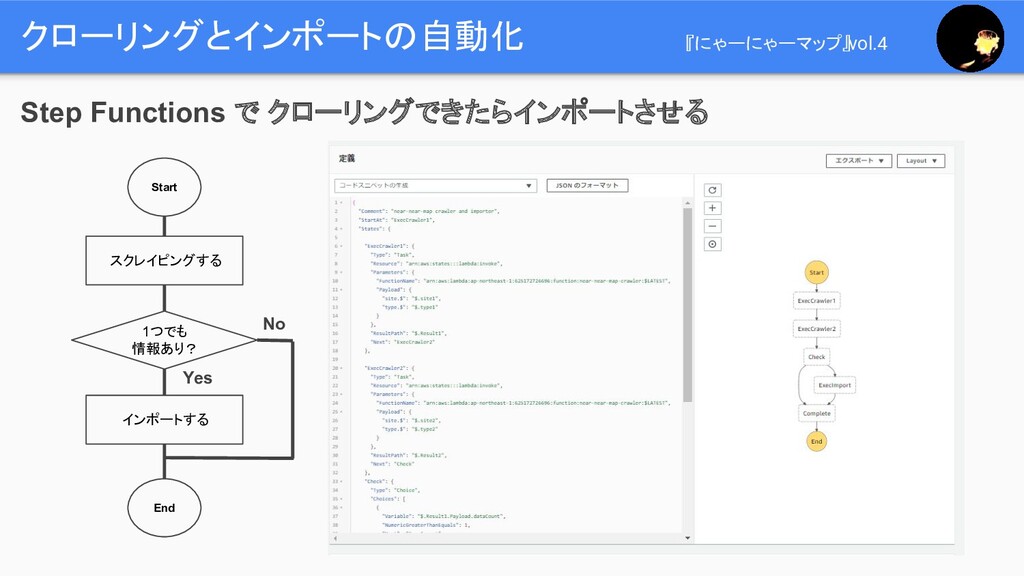
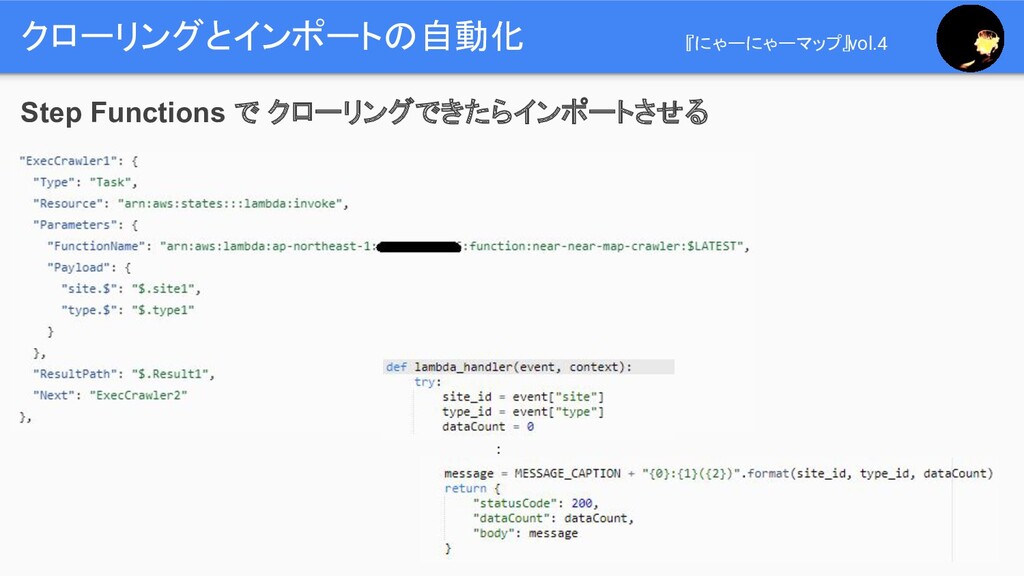
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 Step Functions で クローリングできたらインポートさせる Start スクレイピングする 1つでも 情報あり?
インポートする End Yes No
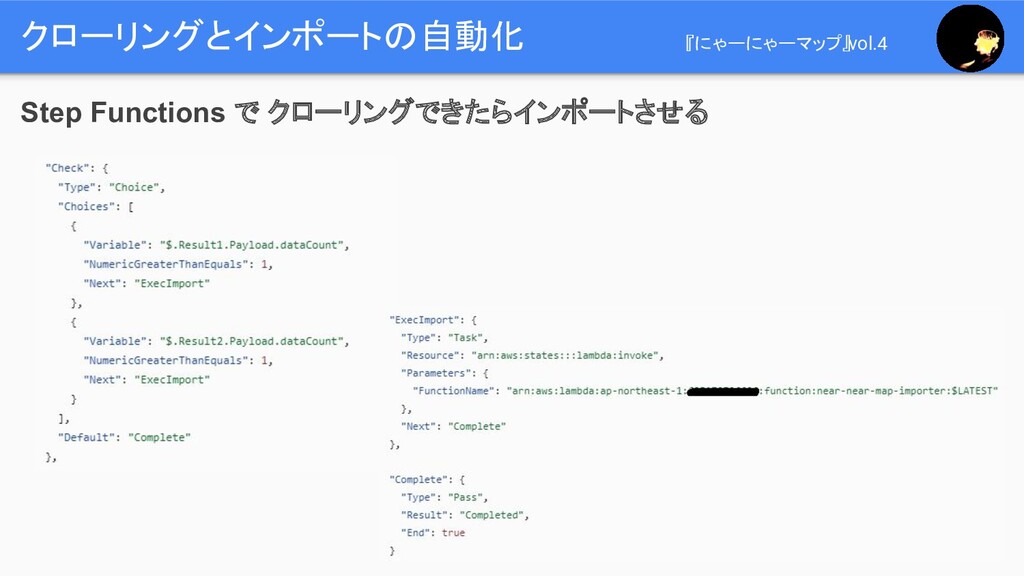
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 Step Functions で クローリングできたらインポートさせる :
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 Step Functions で クローリングできたらインポートさせる
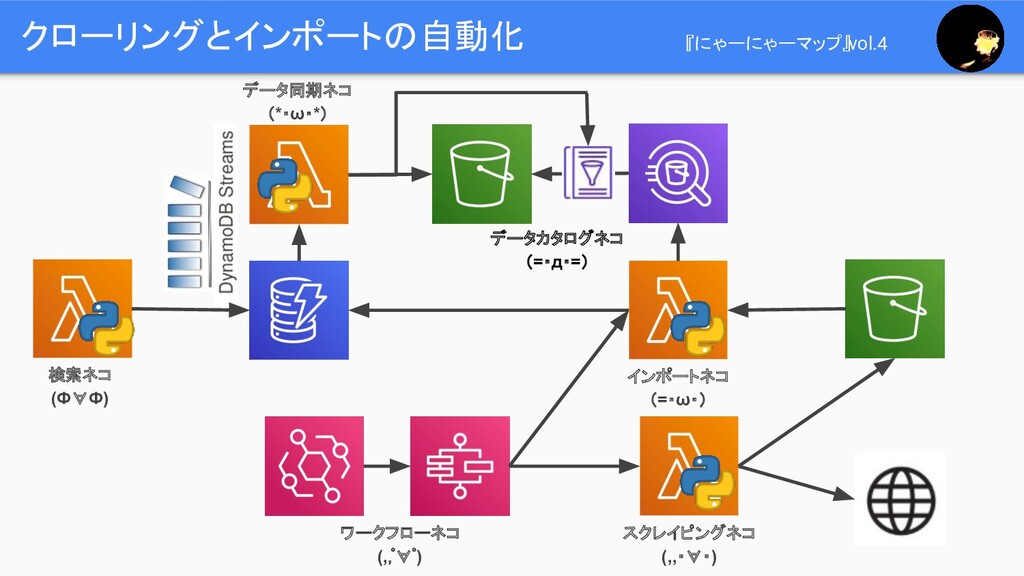
クローリングとインポートの自動化 『にゃーにゃーマップ』vol.4 スクレイピングネコ (,,・∀・) インポートネコ (=・ω・) 検索ネコ (Ф∀Ф) ワークフローネコ (,,゚∀゚)
データ同期ネコ (*・ω・*) データカタログネコ (=・д・=)
Thank You !!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}