or misleading documentation, • learning curve, • few or no experts on the market, • slow adoption rate, • dependencies on other OSS, • (sometimes) lack of support
deep dive instead, • engage with community, • remove OSS barriers - contribute back, • release your software - share, • grow experts in your company - educate, • evaluate-hold-adopt cycle - experiment, • know your hardware & OS - tune, • be patient ;)
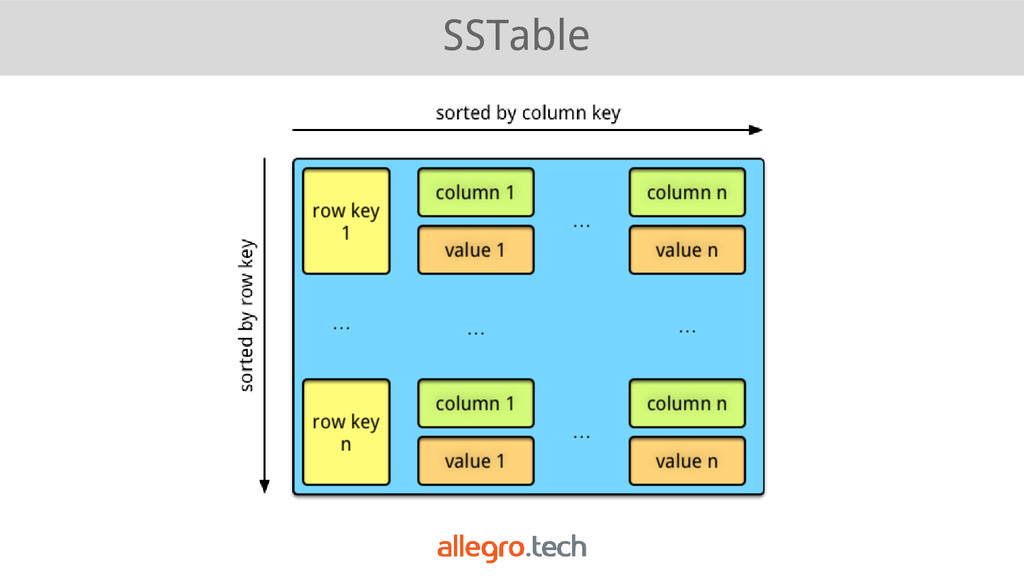
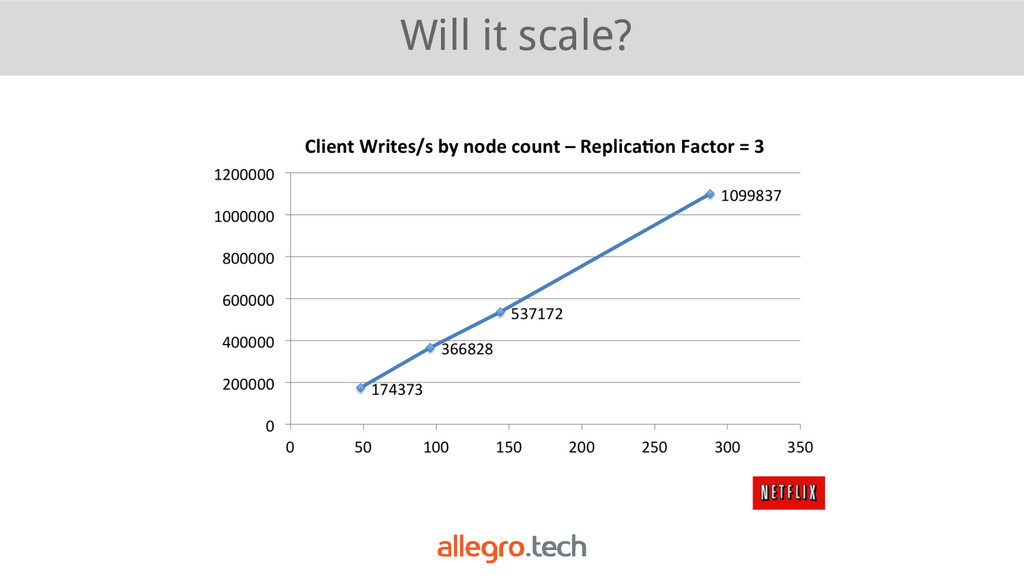
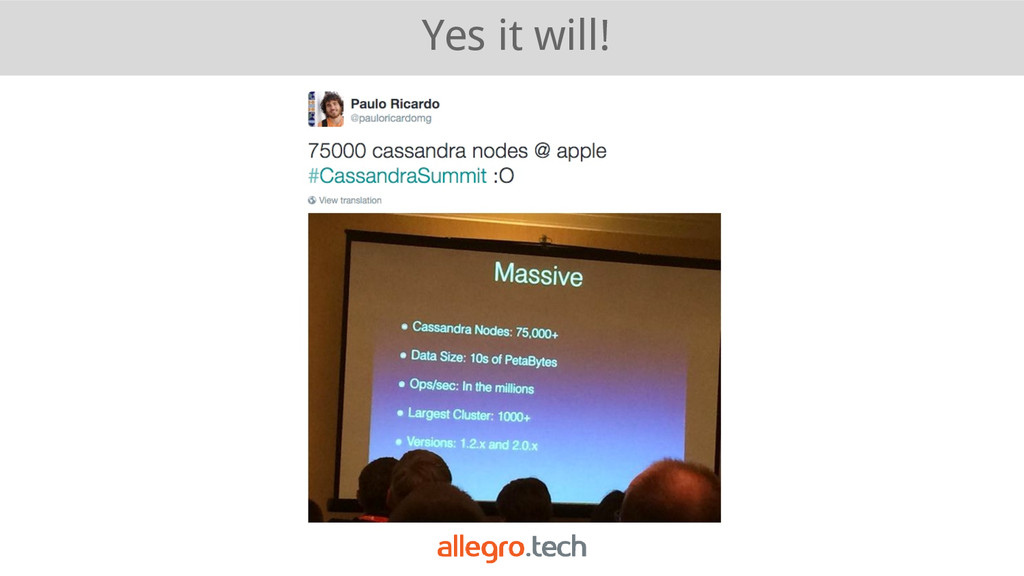
(with tunable C), • masterless architecture (p2p) with gossip protocol, • multi dc (a)synchronous replication, • consistent hashing (with virtual nodes), • support CQL (query language similar to SQL), • modeled after Dynamo, BigTable.
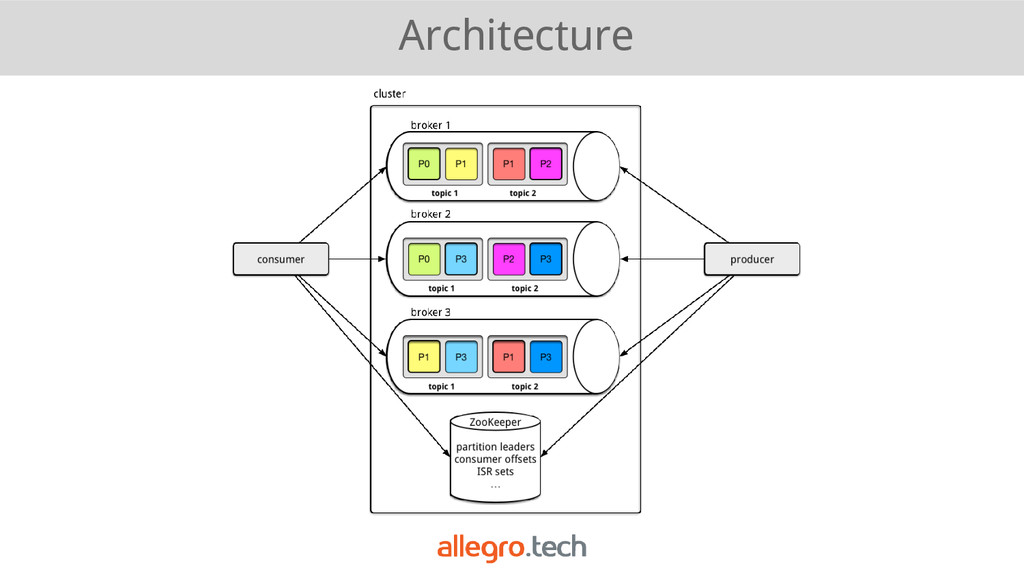
system (can lost data during partition), • (a)synchronous replication (tunable), • at-least-once delivery semantics, • ZooKeeper for partition leader election, • ISR (in-sync-replicas set) concept, • relies heavily on OS caches.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
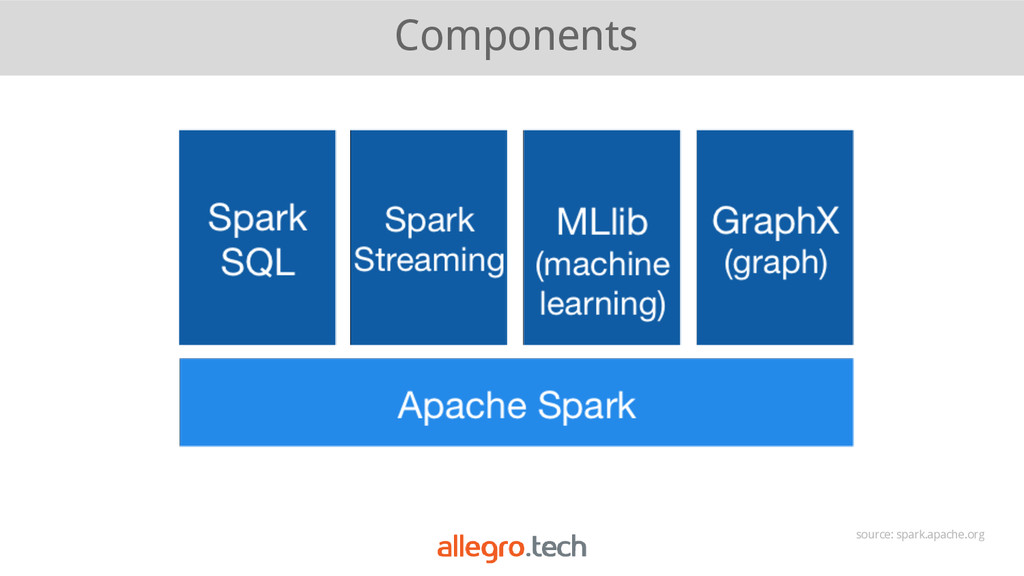{kind=link}
{kind=link}
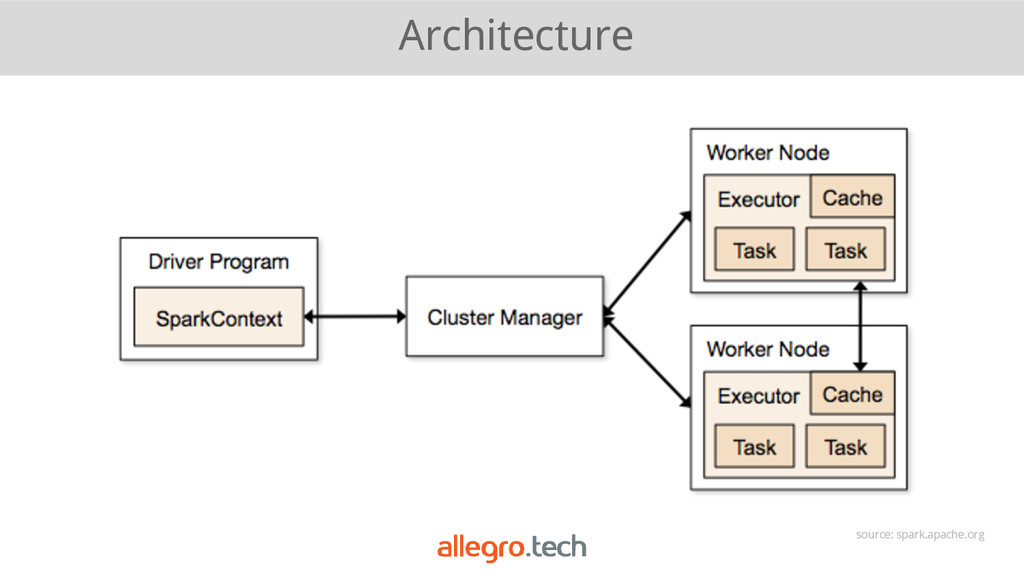{kind=link}
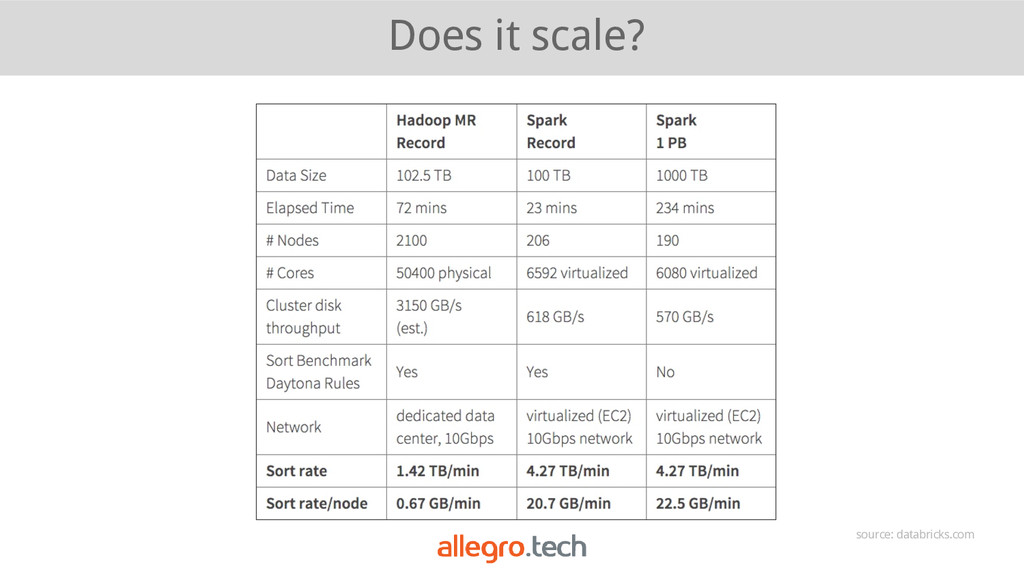{kind=link}
{kind=link}
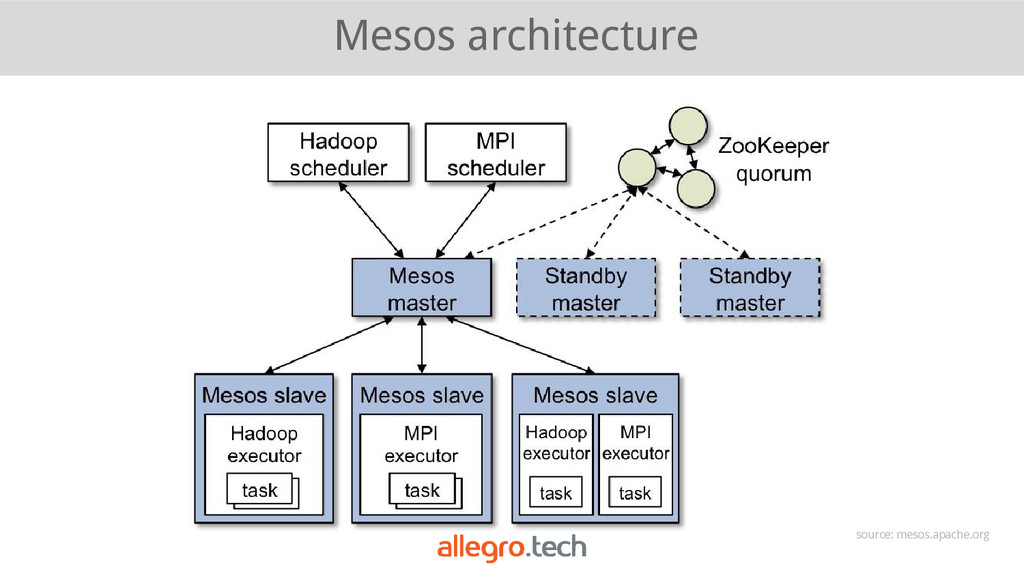{kind=link}
{kind=link}
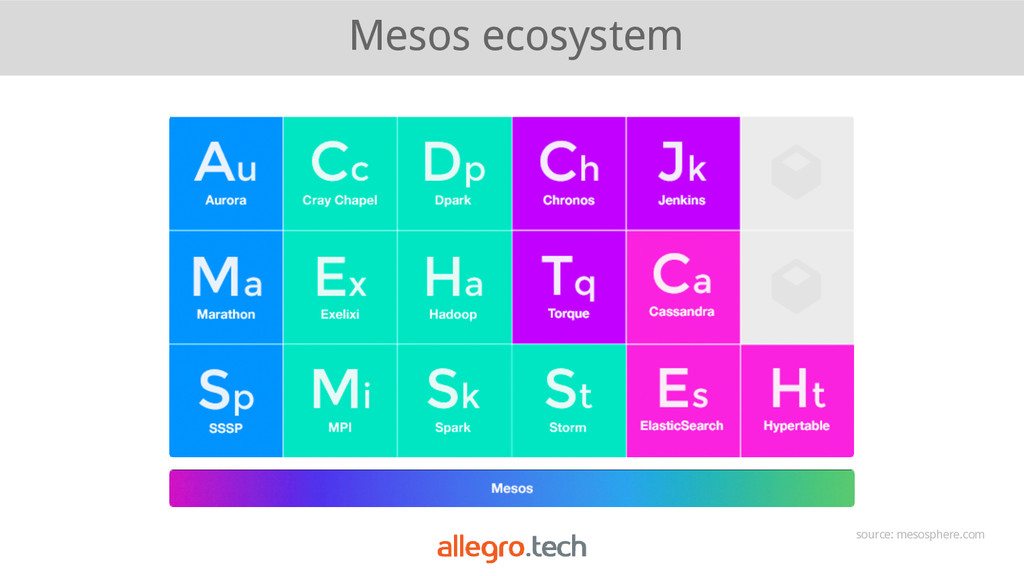{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}