APSIPA 2023 Toward Leveraging Pre-Trained Self-Supervised Frontends for Automatic Singing Voice Understanding Tasks: Three Case Studies
The presentation slide of "Yuya Yamamoto, Toward Leveraging Pre-Trained Self-Supervised Frontends for Automatic Singing Voice Understanding Tasks: Three Case Studies" at APSIPA ASC 2023.
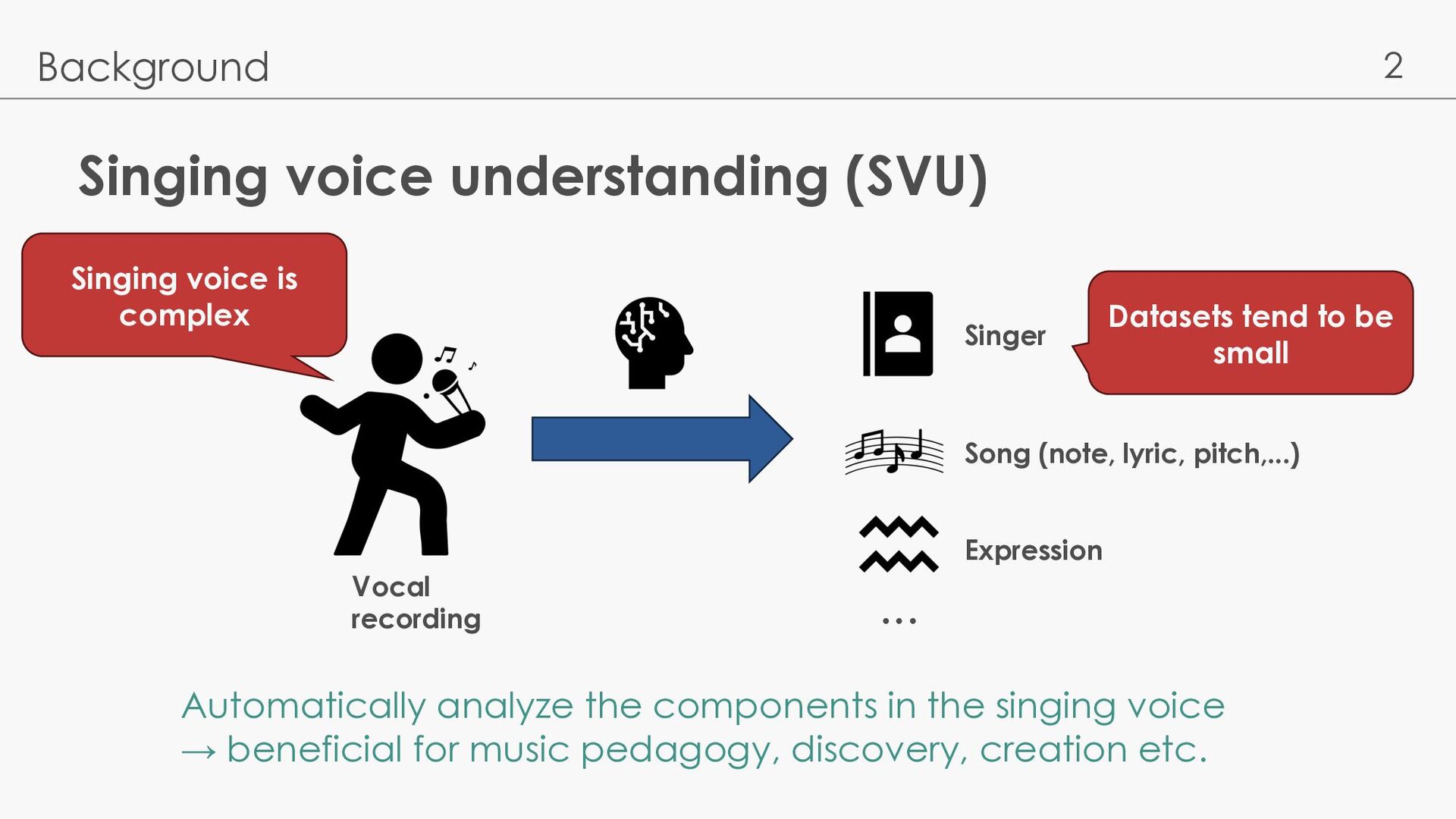
pitch,...) Expression ... Vocal recording Automatically analyze the components in the singing voice → beneficial for music pedagogy, discovery, creation etc. Singing voice is complex Datasets tend to be small
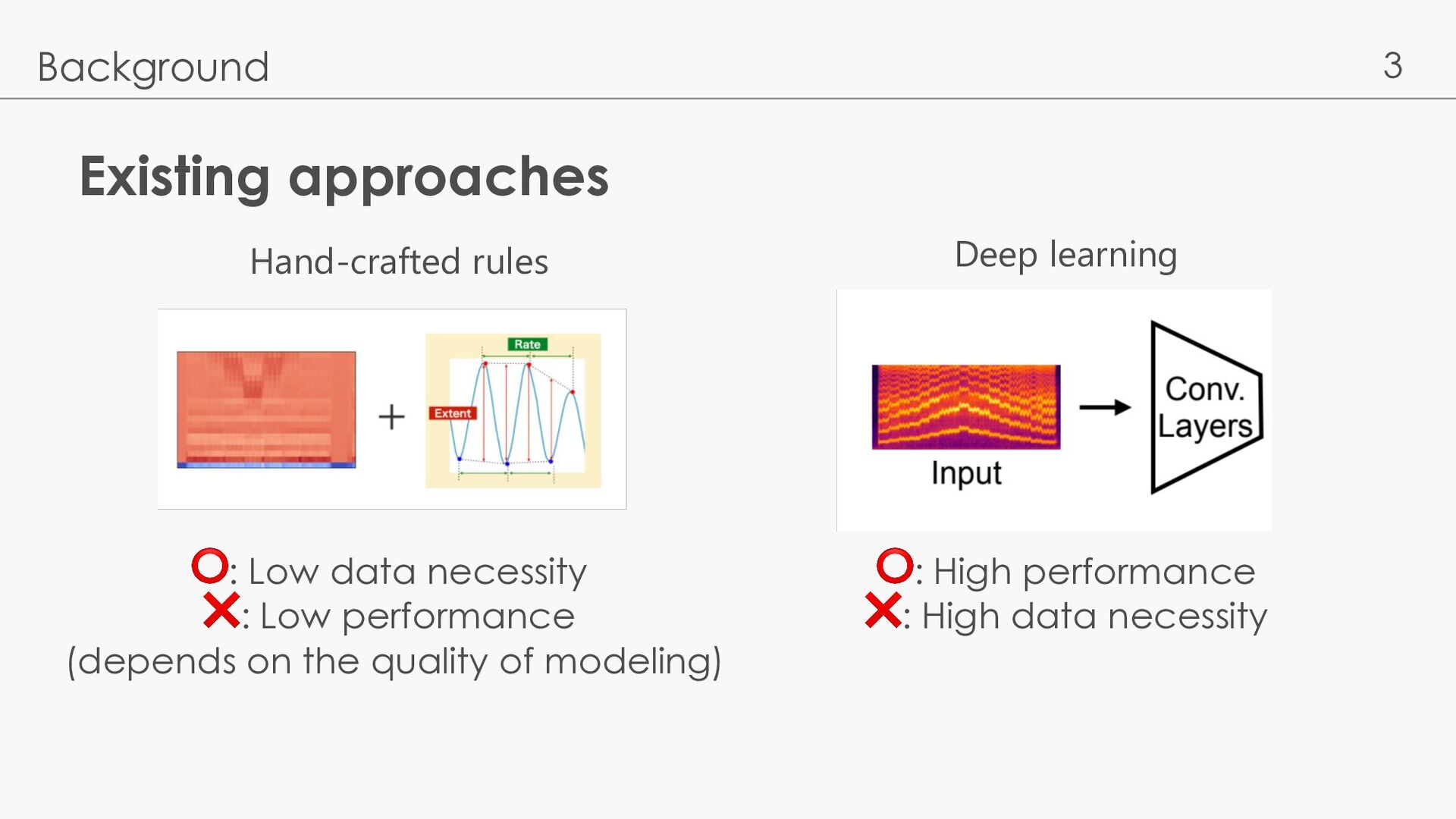
learning for Downstream tasks Rapidly emerging on speech (’20-: Wav2Vec2.0 [Baevski 20] etc.) and music (’21-: CLMR [Spijkervet 21], JukeMIR [Castellon 21] etc. ) domain Baevski, A., Zhou, Y., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A framework for self-supervised learning of speech representations NeurIPS 2020 Spijkervet, J., & Burgoyne, J. A. CONTRASTIVE LEARNING OF MUSICAL REPRESENTATIONS. ISMIR 2021 Castellon, R., Donahue, C., & Liang, P. (2021). Codified audio language modeling learns useful representations for music information retrieval. ISMIR 2021.
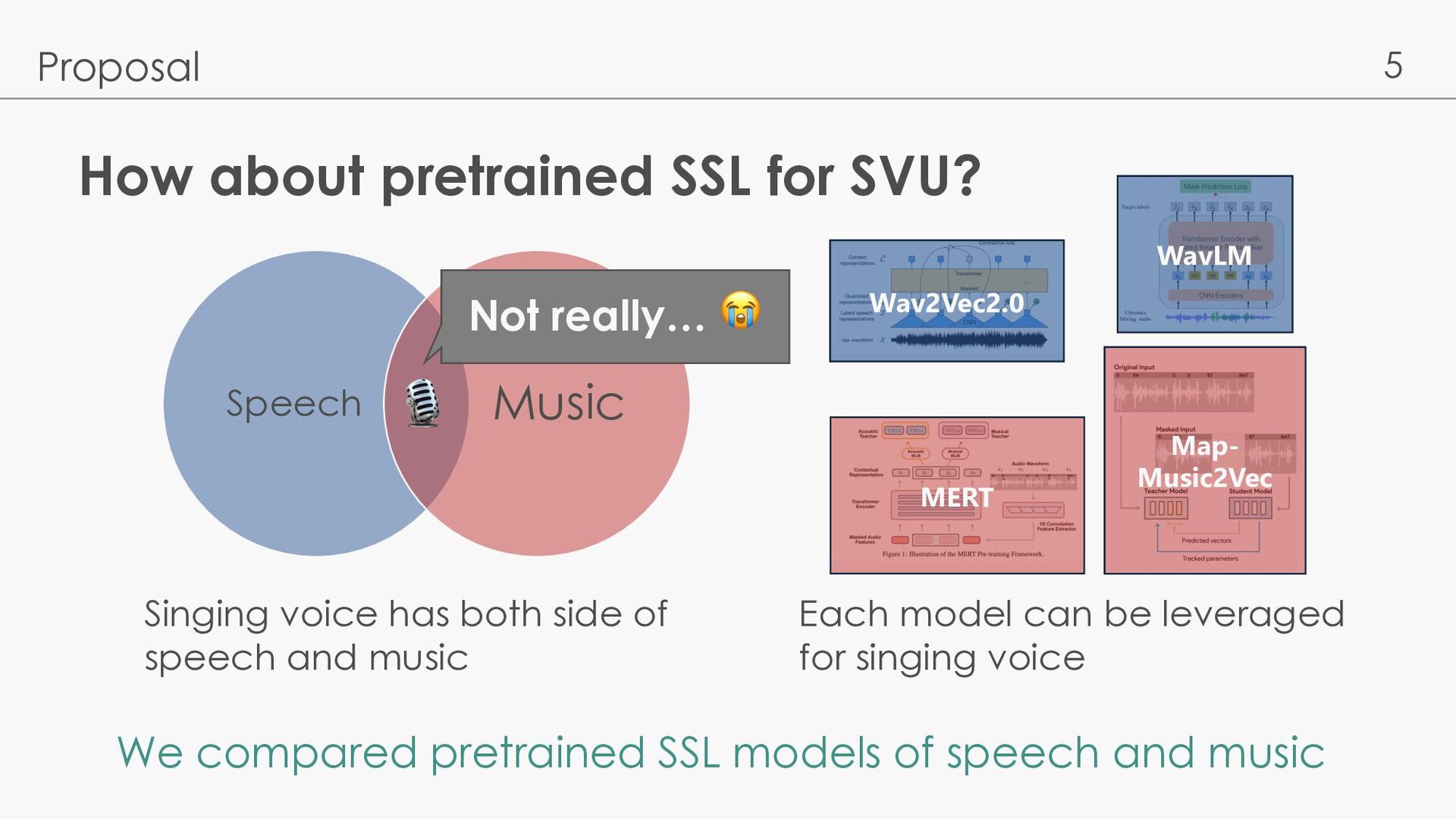
has both side of speech and music Speech Music 🎙 Each model can be leveraged for singing voice Wav2Vec2.0 WavLM MERT Map- Music2Vec We compared pretrained SSL models of speech and music Not really… 😭
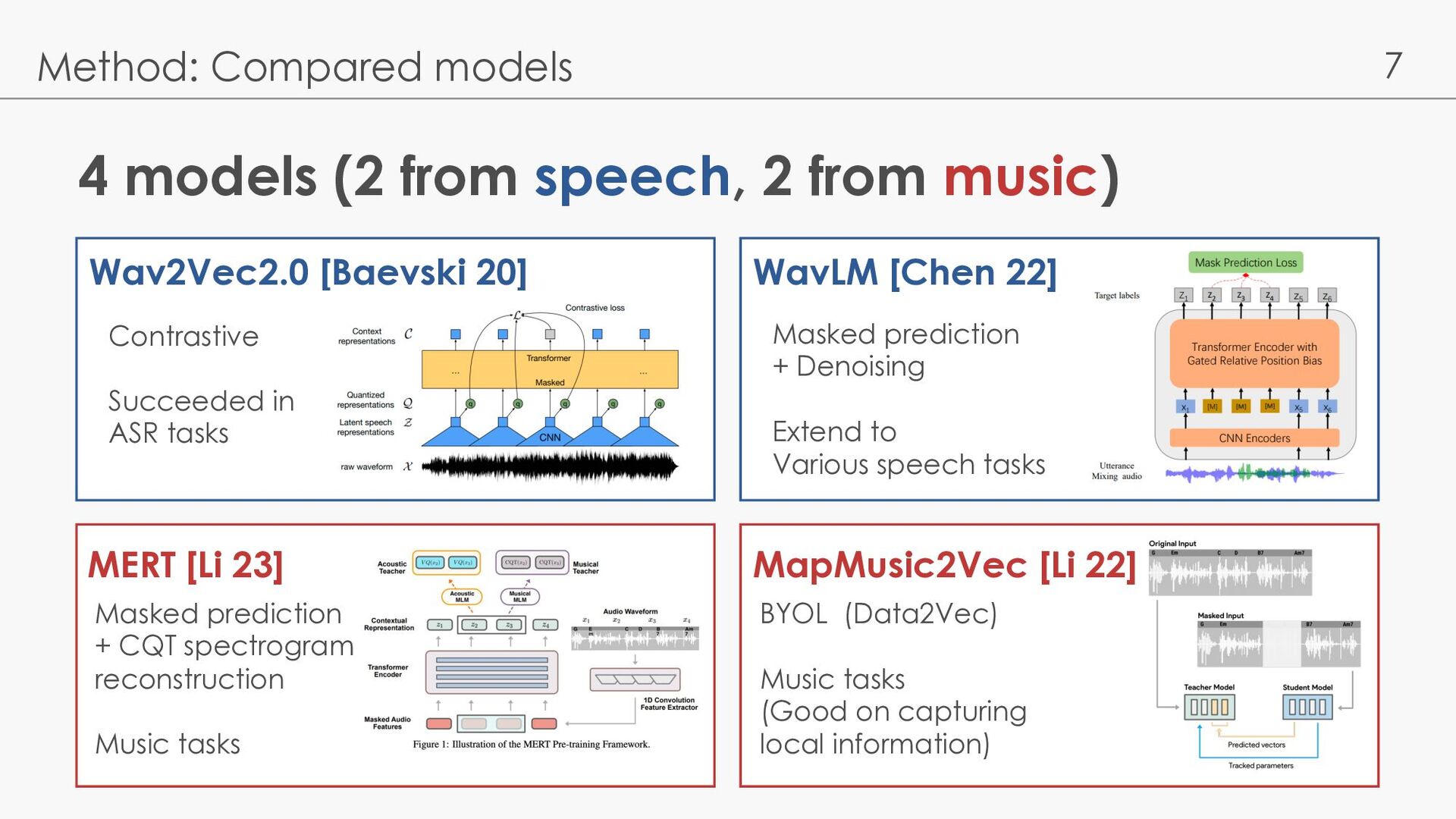
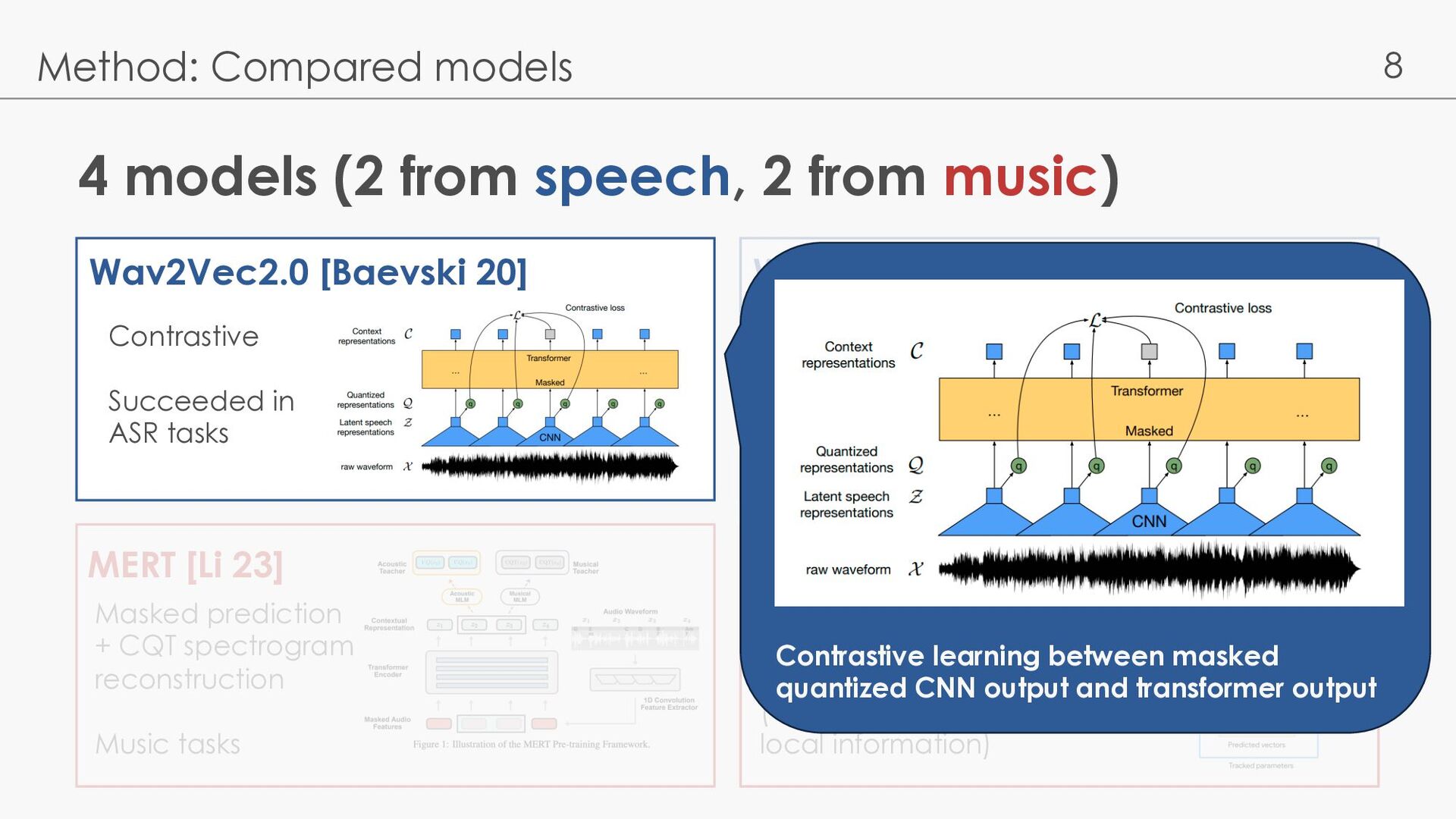
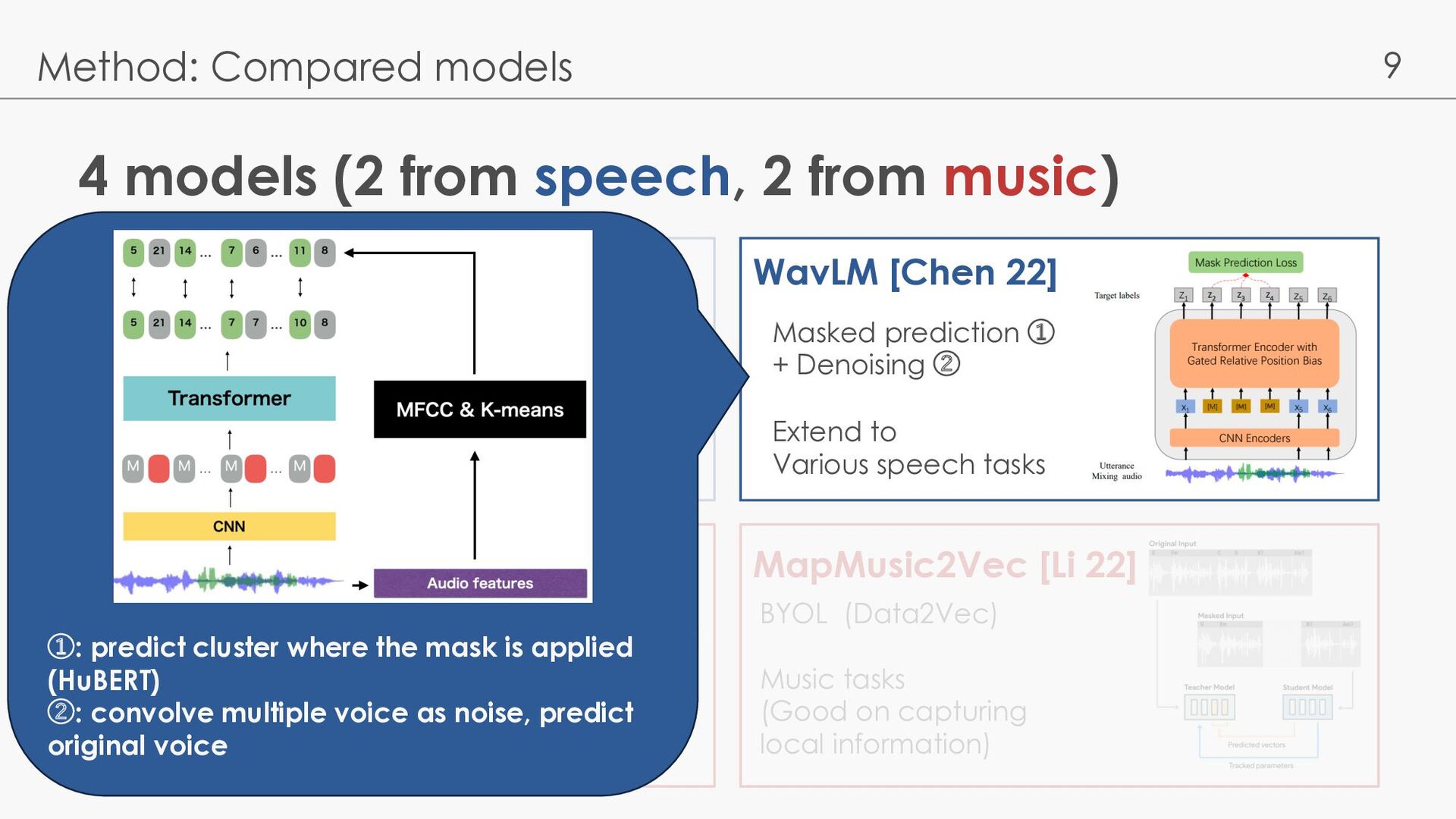
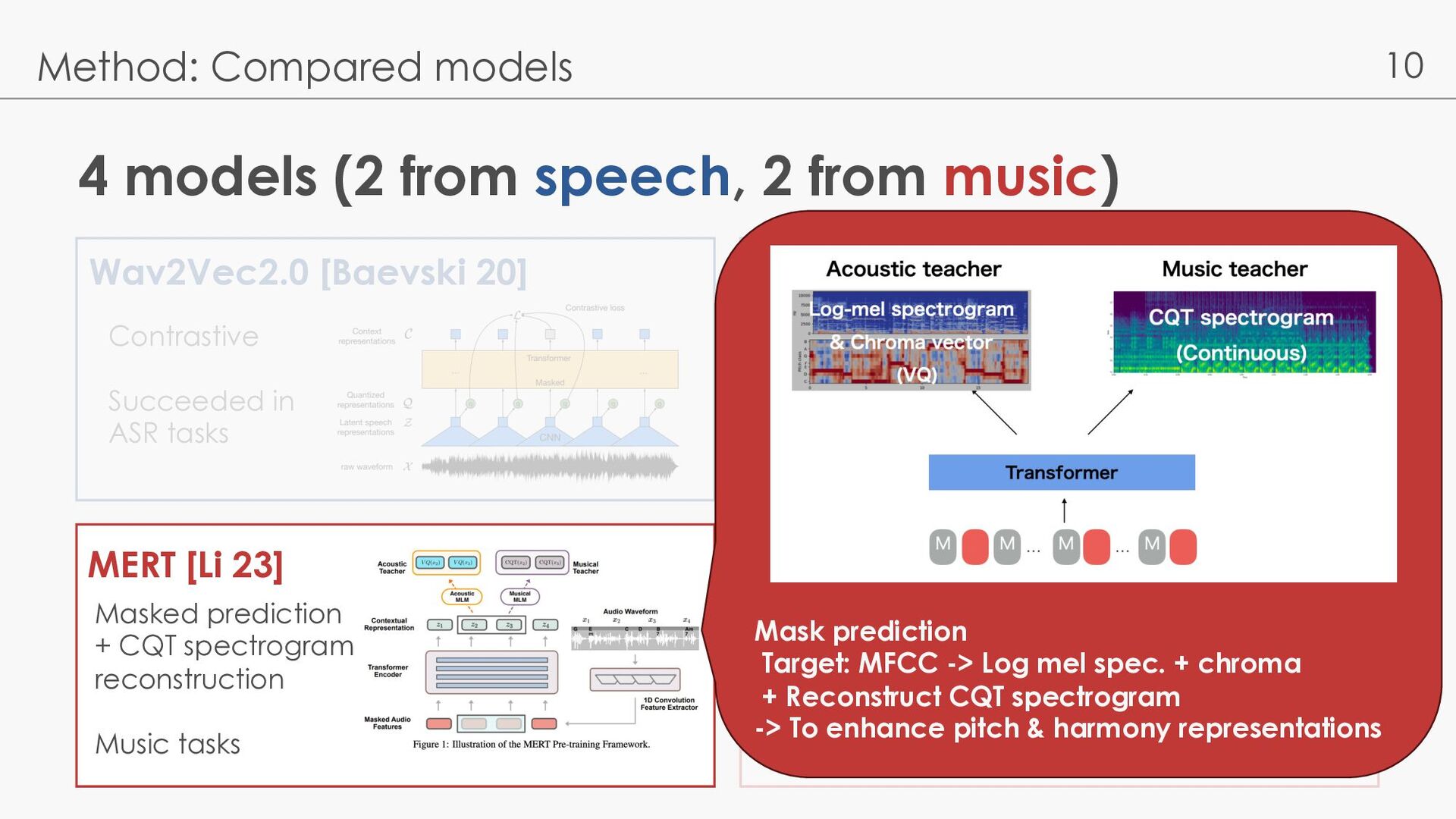
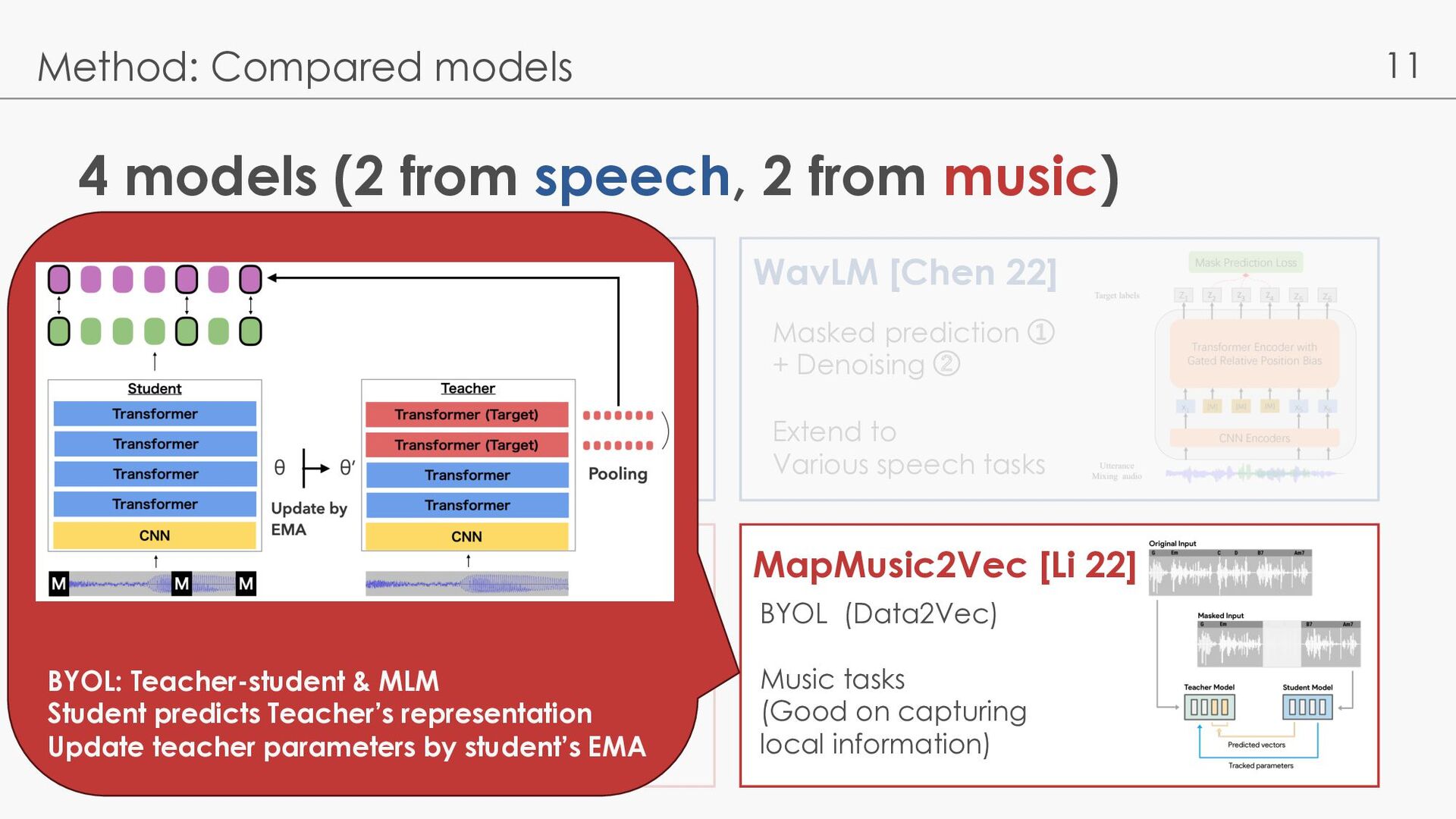
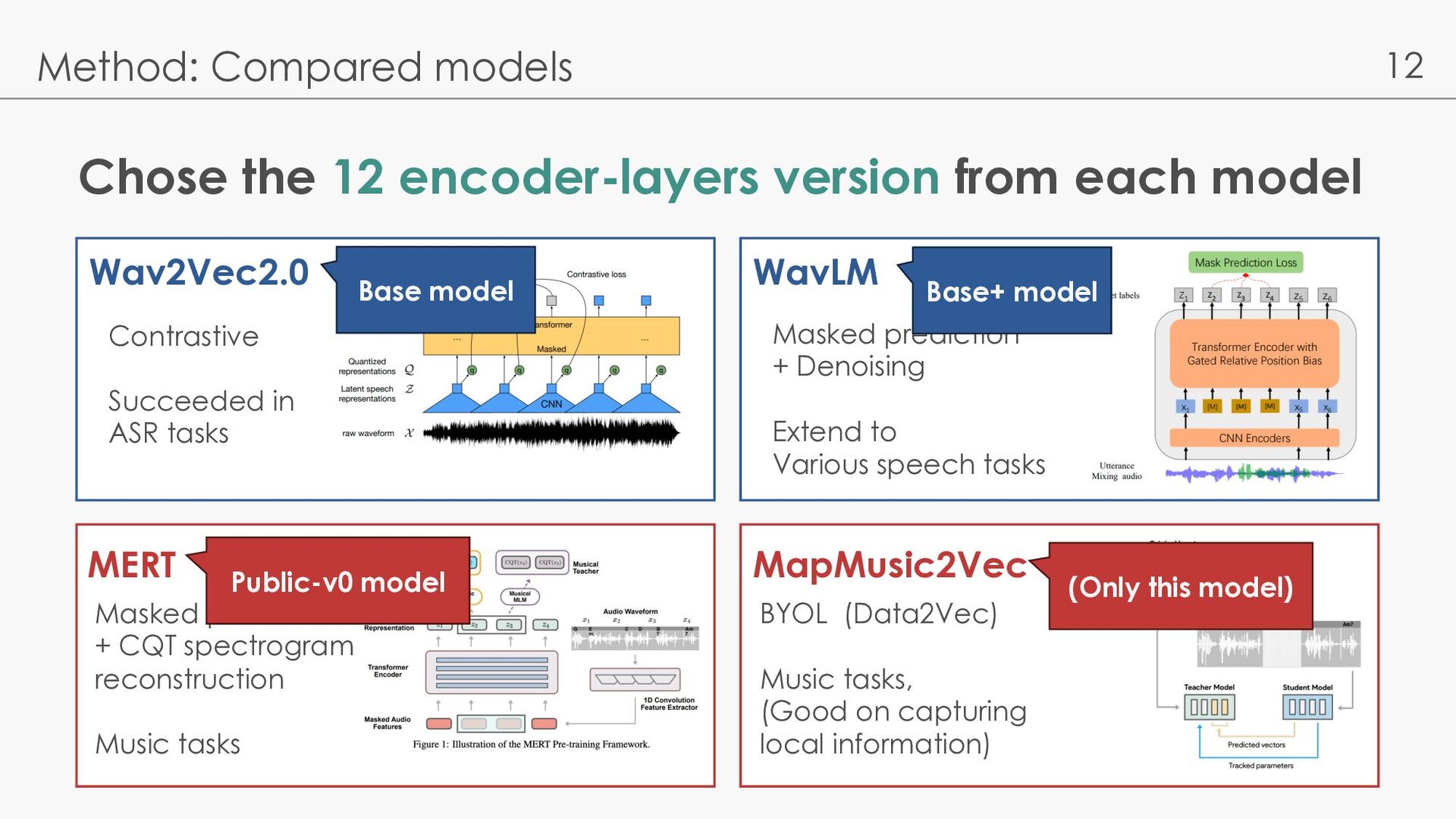
Compared models Wav2Vec2.0 [Baevski 20] MERT [Li 23] WavLM [Chen 22] MapMusic2Vec [Li 22] Contrastive Succeeded in ASR tasks Masked prediction + Denoising Extend to Various speech tasks Masked prediction + CQT spectrogram reconstruction Music tasks BYOL (Data2Vec) Music tasks (Good on capturing local information)
Compared models Wav2Vec2.0 [Baevski 20] MERT [Li 23] WavLM [Chen 22] MapMusic2Vec [Li 22] Contrastive Succeeded in ASR tasks Masked prediction + Denoising Extend to Various speech tasks Masked prediction + CQT spectrogram reconstruction Music tasks BYOL (Data2Vec) Music tasks (Good on capturing local information) Contrastive learning between masked quantized CNN output and transformer output
Compared models Wav2Vec2.0 [Baevski 20] MERT [Li 23] WavLM [Chen 22] MapMusic2Vec [Li 22] Contrastive Succeeded in ASR tasks Masked prediction ① + Denoising ② Extend to Various speech tasks Masked prediction + CQT spectrogram reconstruction Music tasks BYOL (Data2Vec) Music tasks (Good on capturing local information) ①: predict cluster where the mask is applied (HuBERT) ②: convolve multiple voice as noise, predict original voice
Compared models Wav2Vec2.0 [Baevski 20] MERT [Li 23] WavLM [Chen 22] MapMusic2Vec [Li 22] Contrastive Succeeded in ASR tasks Masked prediction ① + Denoising ② Extend to Various speech tasks Masked prediction + CQT spectrogram reconstruction Music tasks BYOL (Data2Vec) Music tasks (Good on capturing local information) BYOL: Teacher-student & MLM Student predicts Teacher’s representation Update teacher parameters by student’s EMA
Compared models Wav2Vec2.0 MERT WavLM MapMusic2Vec Contrastive Succeeded in ASR tasks Masked prediction + Denoising Extend to Various speech tasks Masked prediction + CQT spectrogram reconstruction Music tasks BYOL (Data2Vec) Music tasks, (Good on capturing local information) Base model Base+ model Public-v0 model (Only this model)
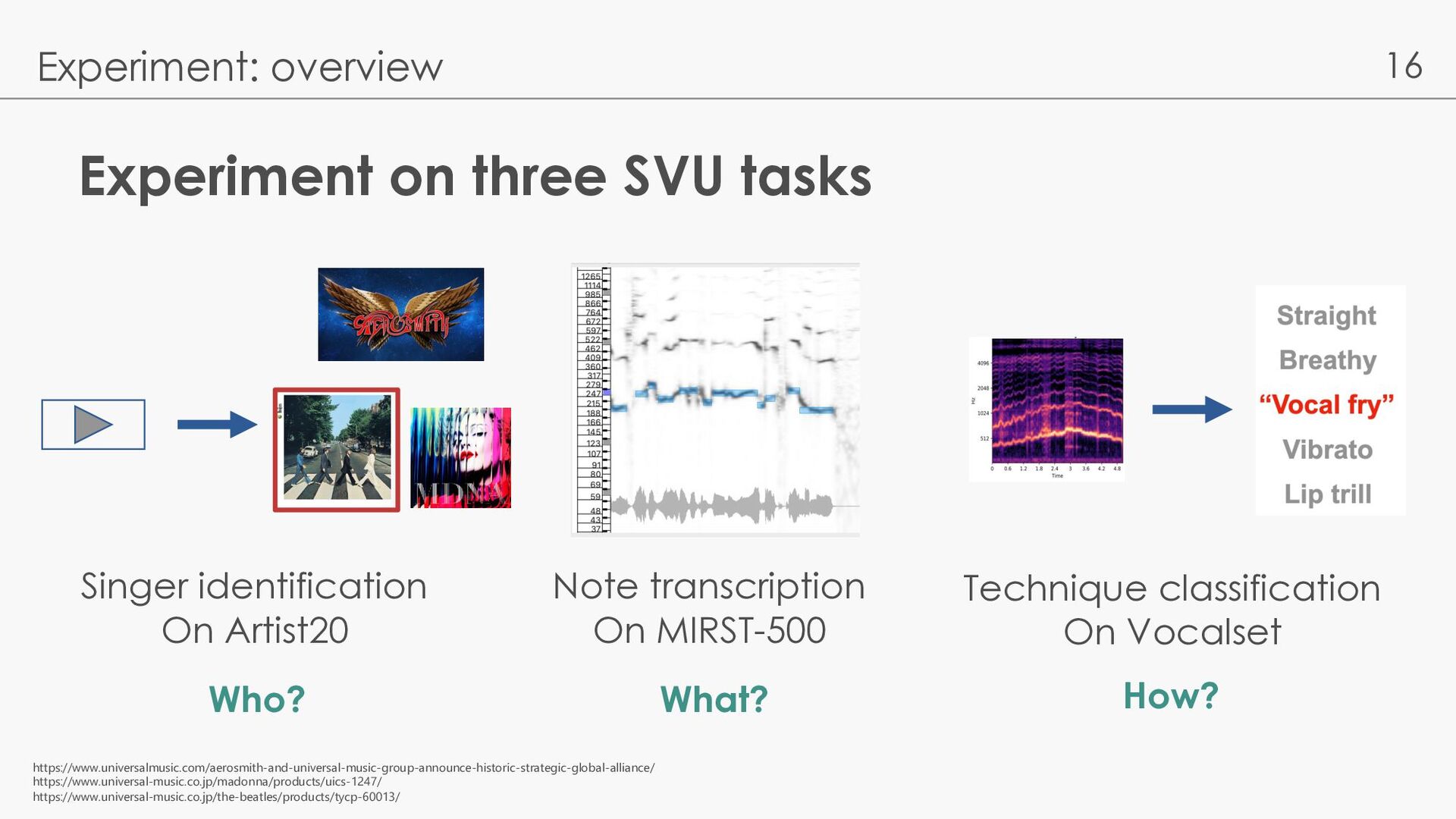
dataset [Ellis 07] l 20 famous artists sung in EN l Each artist has 6 album l Train: Dev: Test = 4:1:1 by album l Separated & 5s-chunked vocal l Removed silence by RMS thresholding l Baseline l CRNN model [Hsieh 20] l Evaluation metrics l F1-score, Top-2 and Top-3 acc. For test set Experiment: Singer identification D. Ellis (2007). Classifying Music Audio with Timbral and Chroma Features, ISMIR 2007 Hsieh, T. H., Cheng, K. H., Fan, Z. C., Yang, Y. C., & Yang, Y. H. (2020, May). Addressing the confounds of accompaniments in singer identification. ICASSP 2020 - All SSL models outperformed baseline - Speech models are better on F1-score
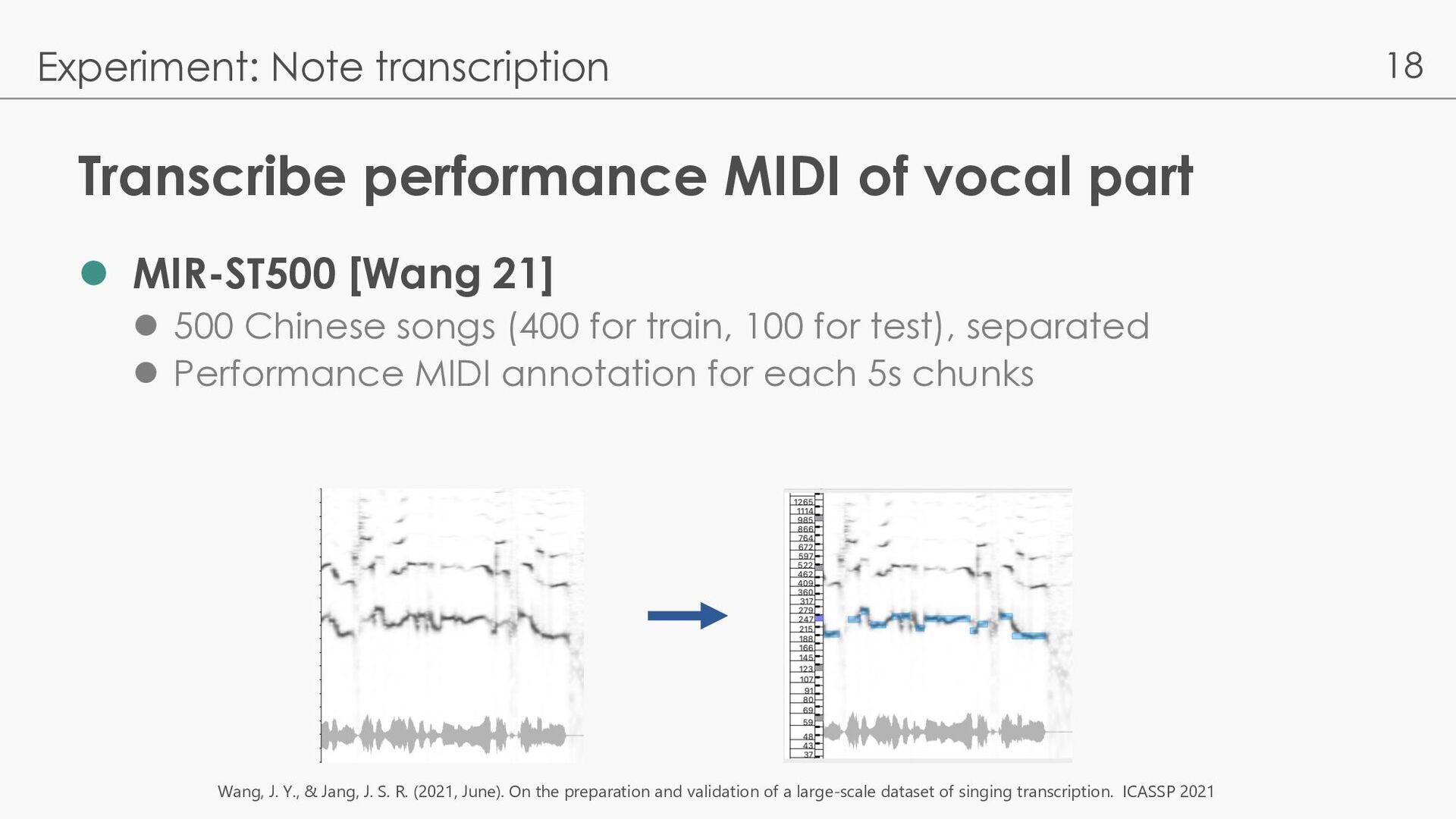
21] l 500 Chinese songs (400 for train, 100 for test), separated l Performance MIDI annotation for each 5s chunks Experiment: Note transcription Wang, J. Y., & Jang, J. S. R. (2021, June). On the preparation and validation of a large-scale dataset of singing transcription. ICASSP 2021
Pitch (MIDI Number) l F1-score that considers... l COn: onset l COnP: + pitch l COnPOff: + offset l Tolerance: l Pitch: ±50 cent l Onset: ±50ms l Offset: ±20% duration Experiment: Note transcription Molina, E., Barbancho-Perez, A. M., Tardon-Garcia, L. J., & Barbancho-Perez, I. (2014). Evaluation framework for automatic singing transcription., ISMIR 2014
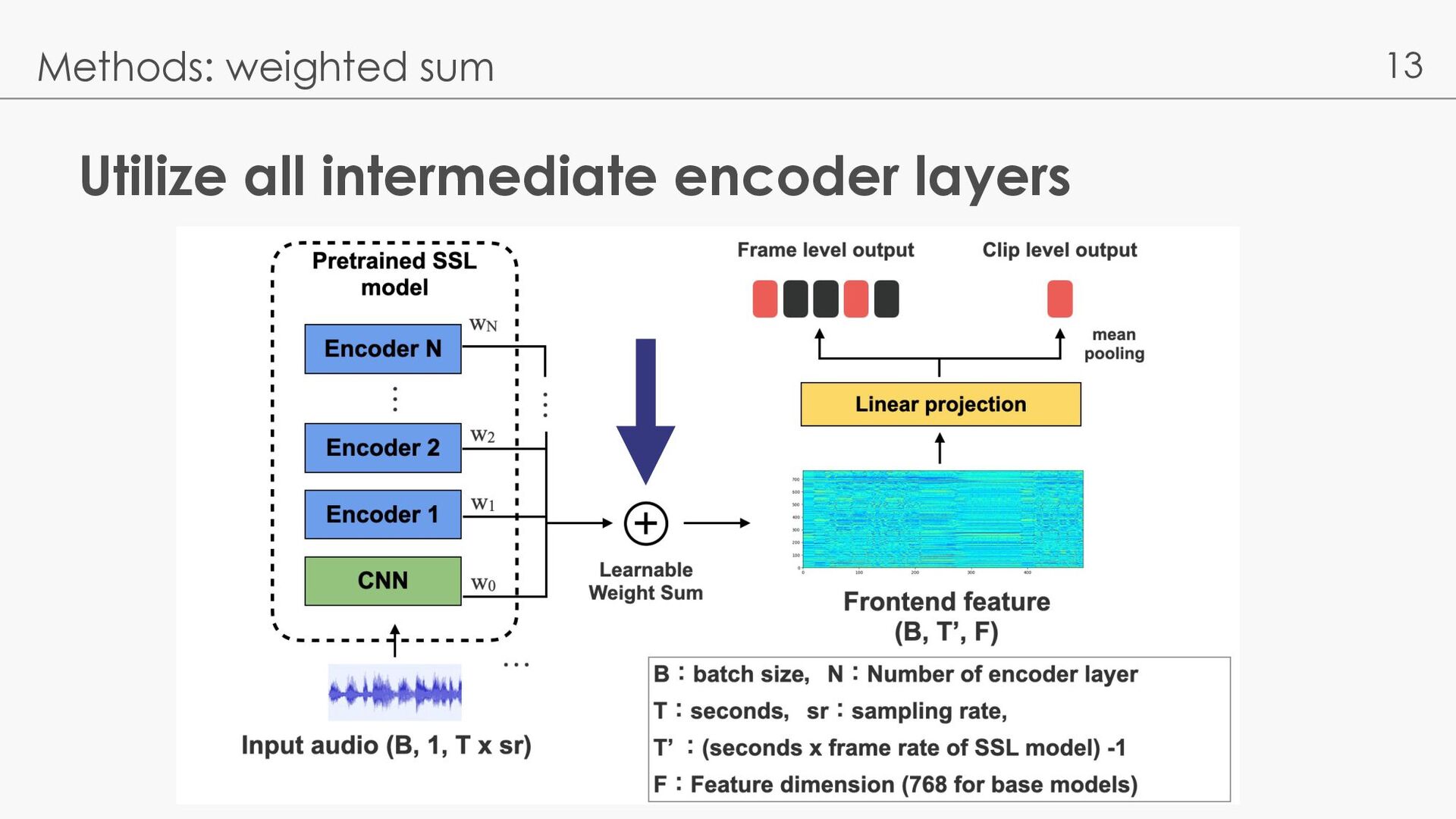
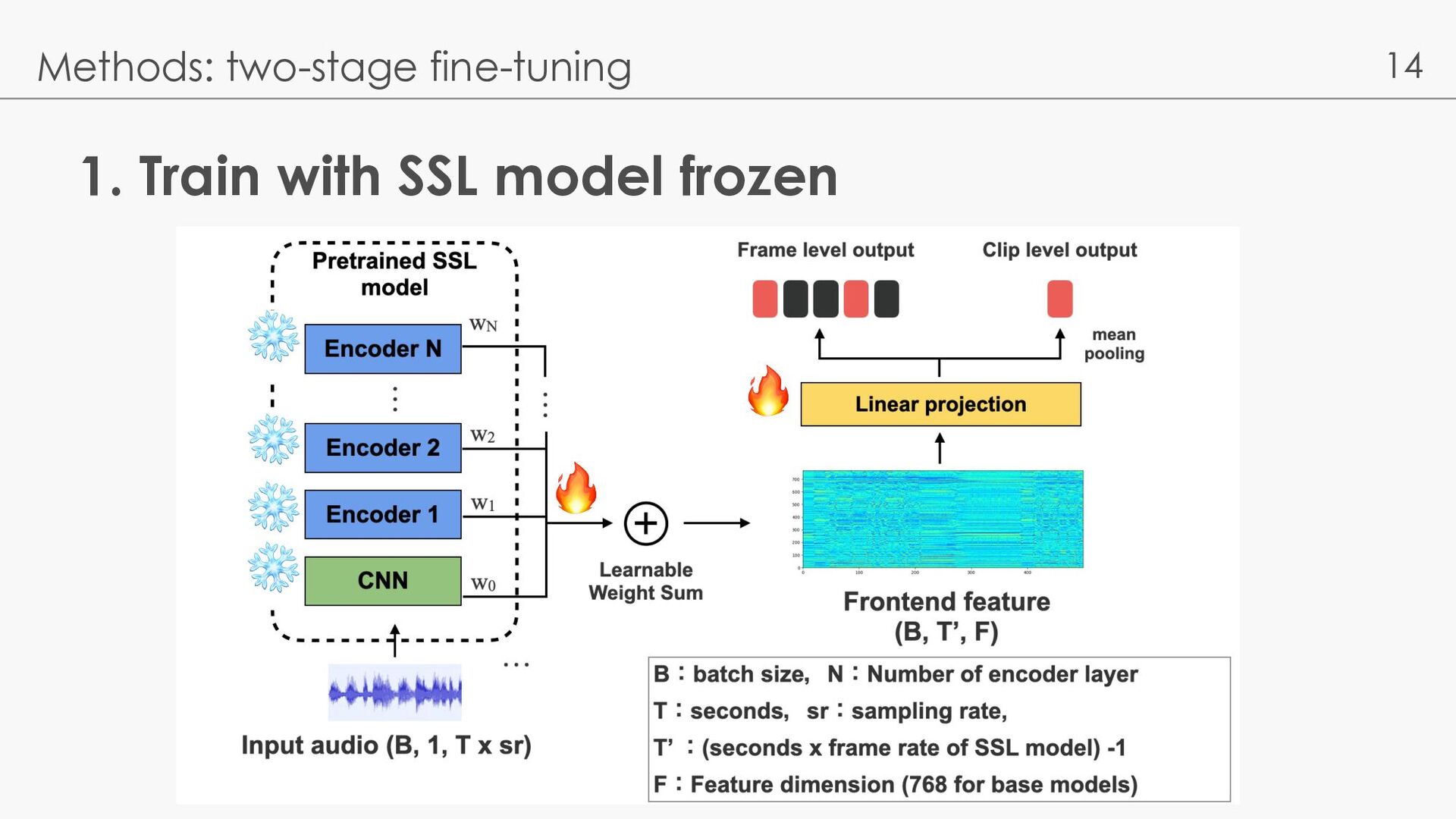
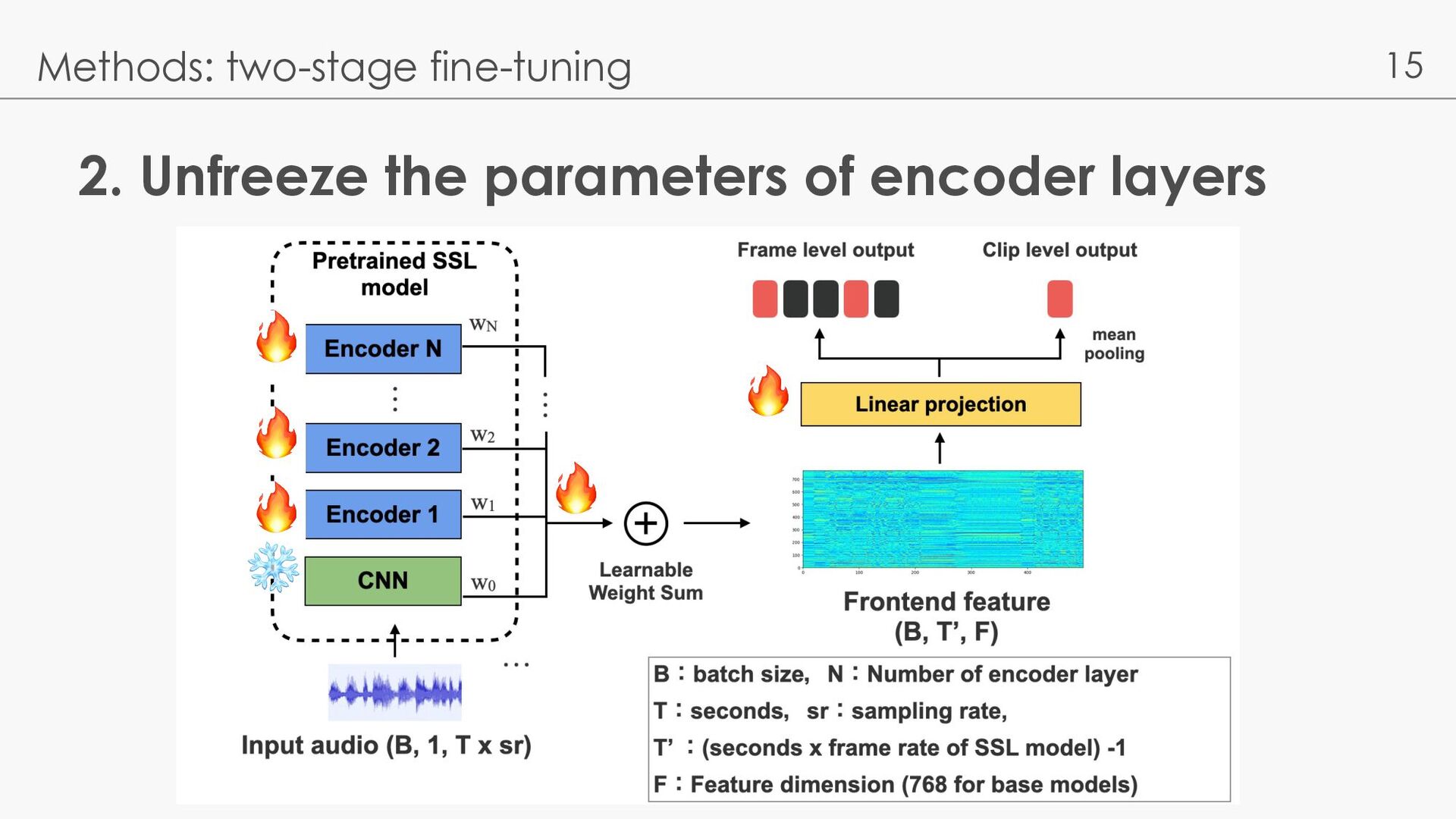
l Baseline: l EfficientNet-b0 [Wang 21] l JDCnote [Kum 22]: utilize pseudo label via vocal melody extraction l Wav2Vec2-Large [Gu 23]: Wav2Vec2.0 Large model + Last layer - Music models are better, especially on pitch - Comparable with Wav2Vec2-Large → weight sum is effective? Kum, S., Lee, J., Kim, K. L., Kim, T., & Nam, J. (2022, May). Pseudo-label transfer from frame-level to note-level in a teacher-student framework for singing transcription from polyphonic music. ICASSP 2022 Gu, X., Zeng, W., Zhang, J., Ou, L., & Wang, Y. (2023). Deep Audio-Visual Singing Voice Transcription based on Self-Supervised Learning Models. arXiv preprint arXiv:2304.12082.
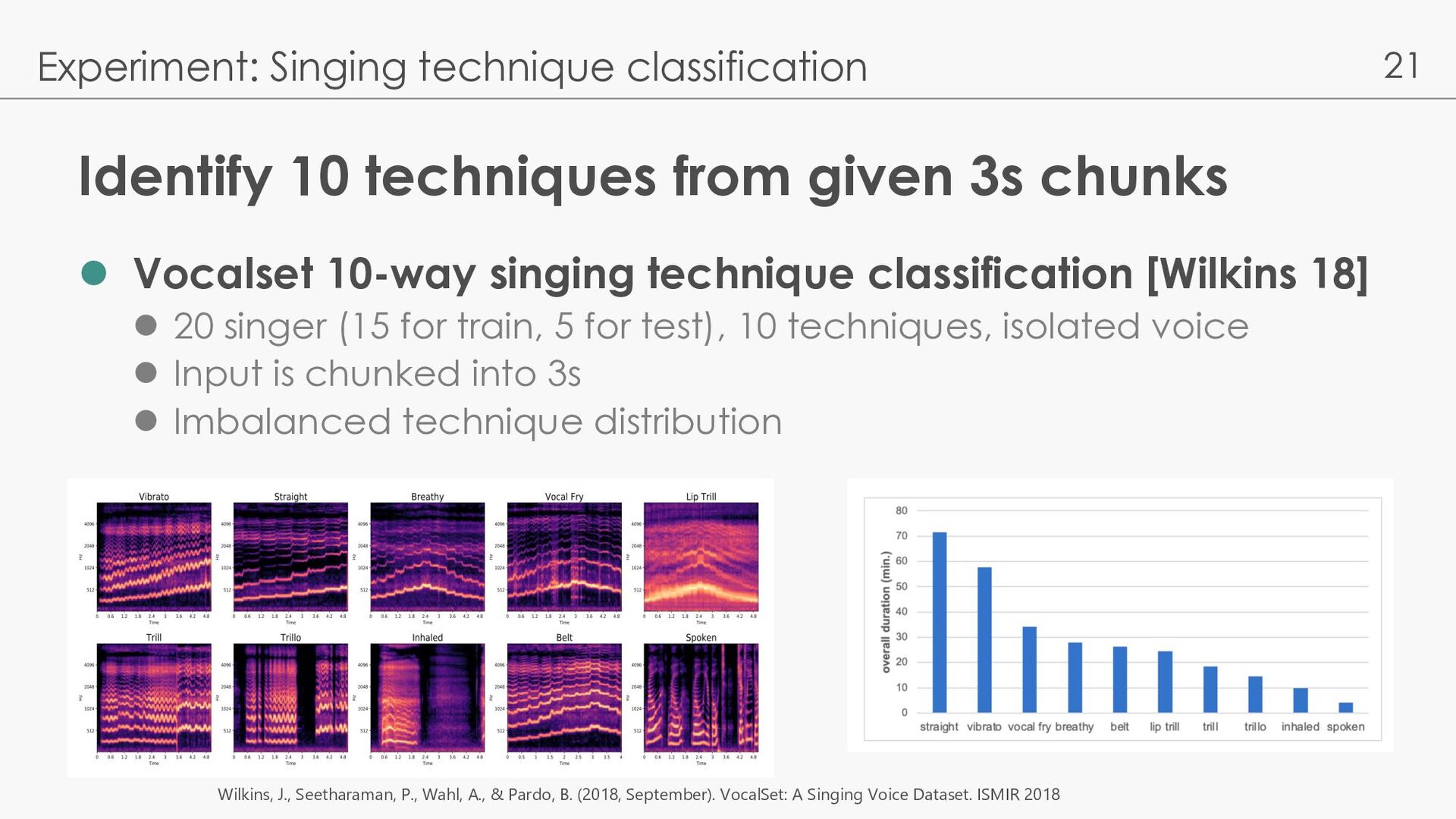
10-way singing technique classification [Wilkins 18] l 20 singer (15 for train, 5 for test), 10 techniques, isolated voice l Input is chunked into 3s l Imbalanced technique distribution Experiment: Singing technique classification Wilkins, J., Seetharaman, P., Wahl, A., & Pardo, B. (2018, September). VocalSet: A Singing Voice Dataset. ISMIR 2018
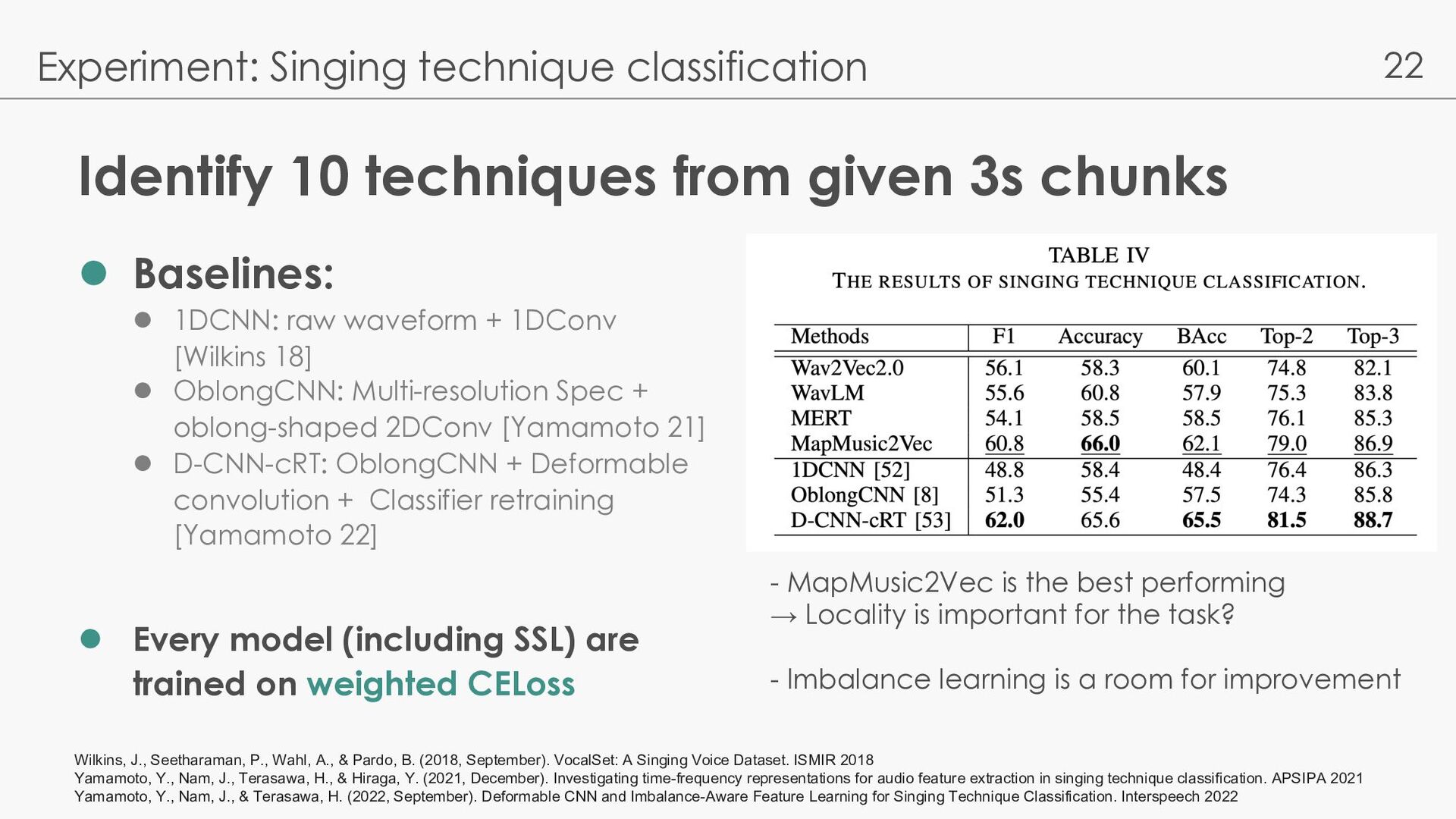
l 1DCNN: raw waveform + 1DConv [Wilkins 18] l OblongCNN: Multi-resolution Spec + oblong-shaped 2DConv [Yamamoto 21] l D-CNN-cRT: OblongCNN + Deformable convolution + Classifier retraining [Yamamoto 22] l Every model (including SSL) are trained on weighted CELoss Experiment: Singing technique classification - MapMusic2Vec is the best performing → Locality is important for the task? - Imbalance learning is a room for improvement Wilkins, J., Seetharaman, P., Wahl, A., & Pardo, B. (2018, September). VocalSet: A Singing Voice Dataset. ISMIR 2018 Yamamoto, Y., Nam, J., Terasawa, H., & Hiraga, Y. (2021, December). Investigating time-frequency representations for audio feature extraction in singing technique classification. APSIPA 2021 Yamamoto, Y., Nam, J., & Terasawa, H. (2022, September). Deformable CNN and Imbalance-Aware Feature Learning for Singing Technique Classification. Interspeech 2022
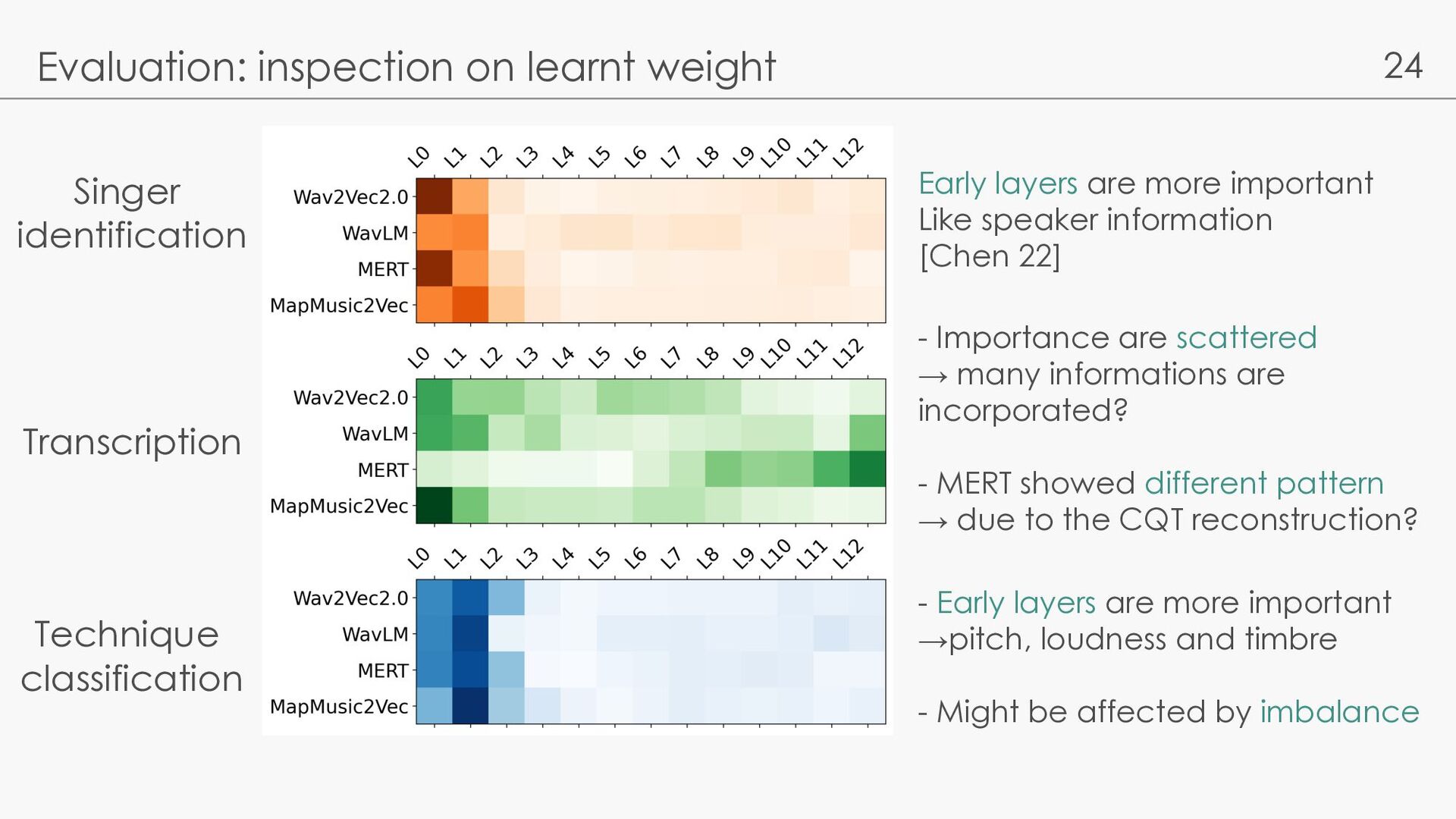
classification Early layers are more important Like speaker information [Chen 22] - Importance are scattered → many informations are incorporated? - MERT showed different pattern → due to the CQT reconstruction? - Early layers are more important →pitch, loudness and timbre - Might be affected by imbalance
a certain potential for SVU l Every model showed comparable performance on each task l How to adapt to singing voice more? l Way of finetuning (e.g., Adapter, LoRA), domain adaptation, etc. l Setting of downstream task l Investigation on more SVU tasks l Unexplored components : phoneme, lyric, loudness, vocal mixing, etc. l Variation: Singer diarization, Pitch extraction, Technique detection, etc. Discussion & future work
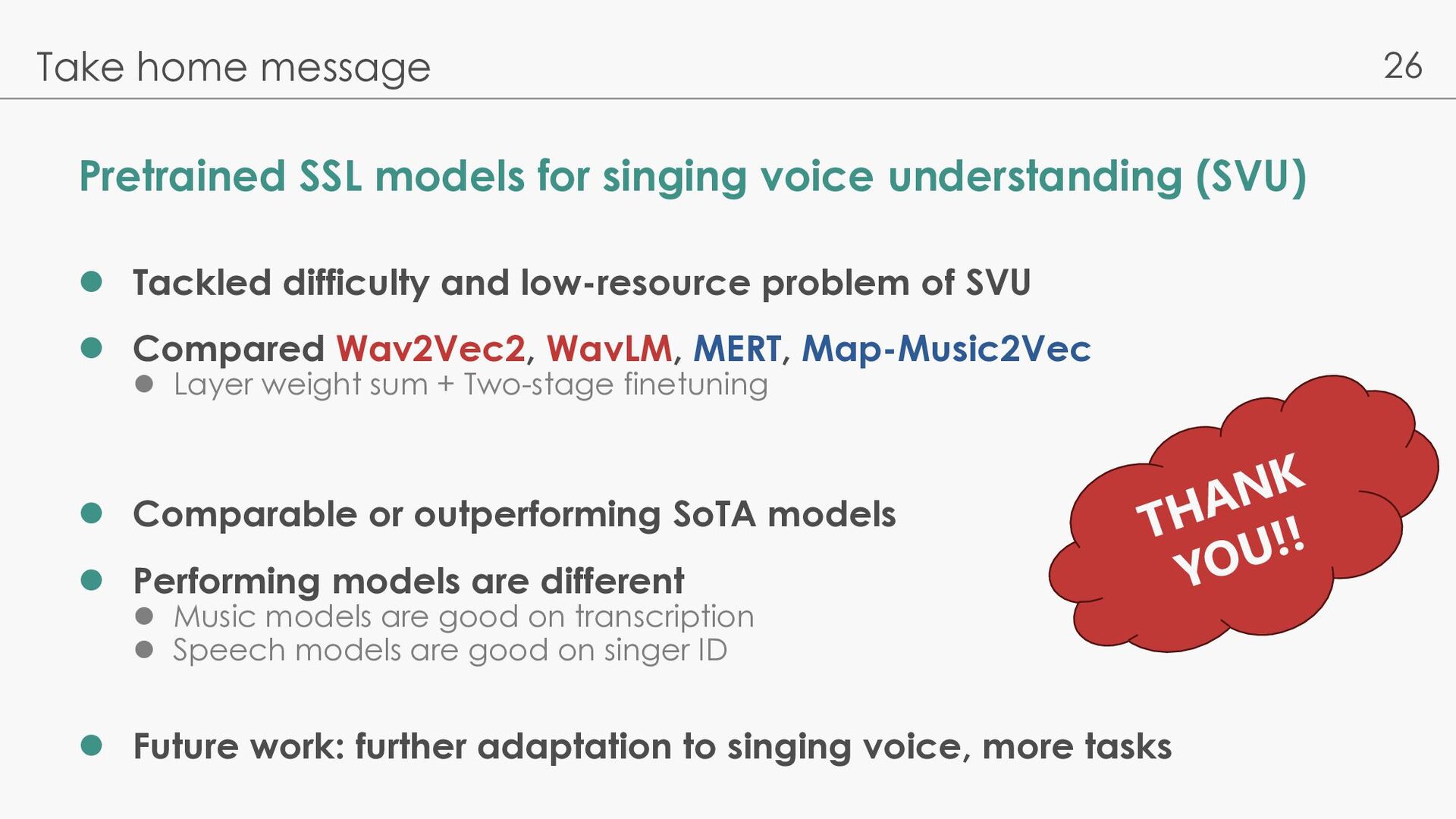
Tackled difficulty and low-resource problem of SVU l Compared Wav2Vec2, WavLM, MERT, Map-Music2Vec l Layer weight sum + Two-stage finetuning l Comparable or outperforming SoTA models l Performing models are different l Music models are good on transcription l Speech models are good on singer ID l Future work: further adaptation to singing voice, more tasks Take home message THANK YOU!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![19 Evaluation metrics [Molina 14] l Estimates onset, offset, and](https://files.speakerdeck.com/presentations/f3fe064a195747d284dc2c17dfd0b686/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}