Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LMDX / 論文紹介 LMDX:Language Model-based Document ...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
ymicky06
October 11, 2024
87
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LMDX / 論文紹介 LMDX:Language Model-based Document Information Extraction and Localization
ymicky06
October 11, 2024
More Decks by ymicky06
See All by ymicky06
Agentic AI in 30min
ymicky06
5
380
freeeのOCR開発における Amazon SageMaker Ground Truthの活用 / SageMaker Ground Truth for OCR at freee
ymicky06
0
170
Kaggleのたんぱく質コンペで銅メダルとった話 / Get Bronze medal on Kaggle Competition
ymicky06
0
470
Kaggle鳥コンペ反省会 / Retrospective Birt Competition on Kaggle
ymicky06
0
290
Featured
See All Featured
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
510
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
420
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Design in an AI World
tapps
1
260
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Odyssey Design
rkendrick25
PRO
2
730
Bash Introduction
62gerente
615
220k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Transcript
論文紹介 LMDX:Language Model-based Document Information Extraction and Localization micky @
AI Lab
背景 • Visual Rich Document(VRD) Understanding 分野が近年発展してい る。 その中でも、半構造体文書(請求書、税務申告書、給与明細、領収書、 etc.)から指定された項目に該当する値を抽出するdocument
information extraction(IE)タスクが産業界でもアカデミアでも注目され ている https://arxiv.org/abs/2309.10952
document information extractionの難しさ • 多様なテンプレート、情報のレイアウト • スタンプや手書き文字 • 文書の回転やコントラスト •
高い精度が求められ、文書内のドキュメントのどこから情報を抽出した のかを示す必要がある ◦ 人間による確認や修正のしやすさ • 限られたアノテーションリソース
この論文の貢献 • LLMを利用して学習データなしでも、ドキュメント内の正確な位置を示し ながら、document IEタスクを実行できるプロンプトの提案 • LLMのアーキテクチャを変更することなく、ドキュメントの空間情報を LLMに伝えるレイアウトエンコーディング方法の提案 • LLMのレスポンスを文書内の抽出された実体と位置情報にデコードし、
ハルシネーションをなくすアルゴリズムを提案 • LMDXのデータ効率を複数の公開されているベンチマークで評価、特 にデータ数が少ない領域において大きなSOTAを達成
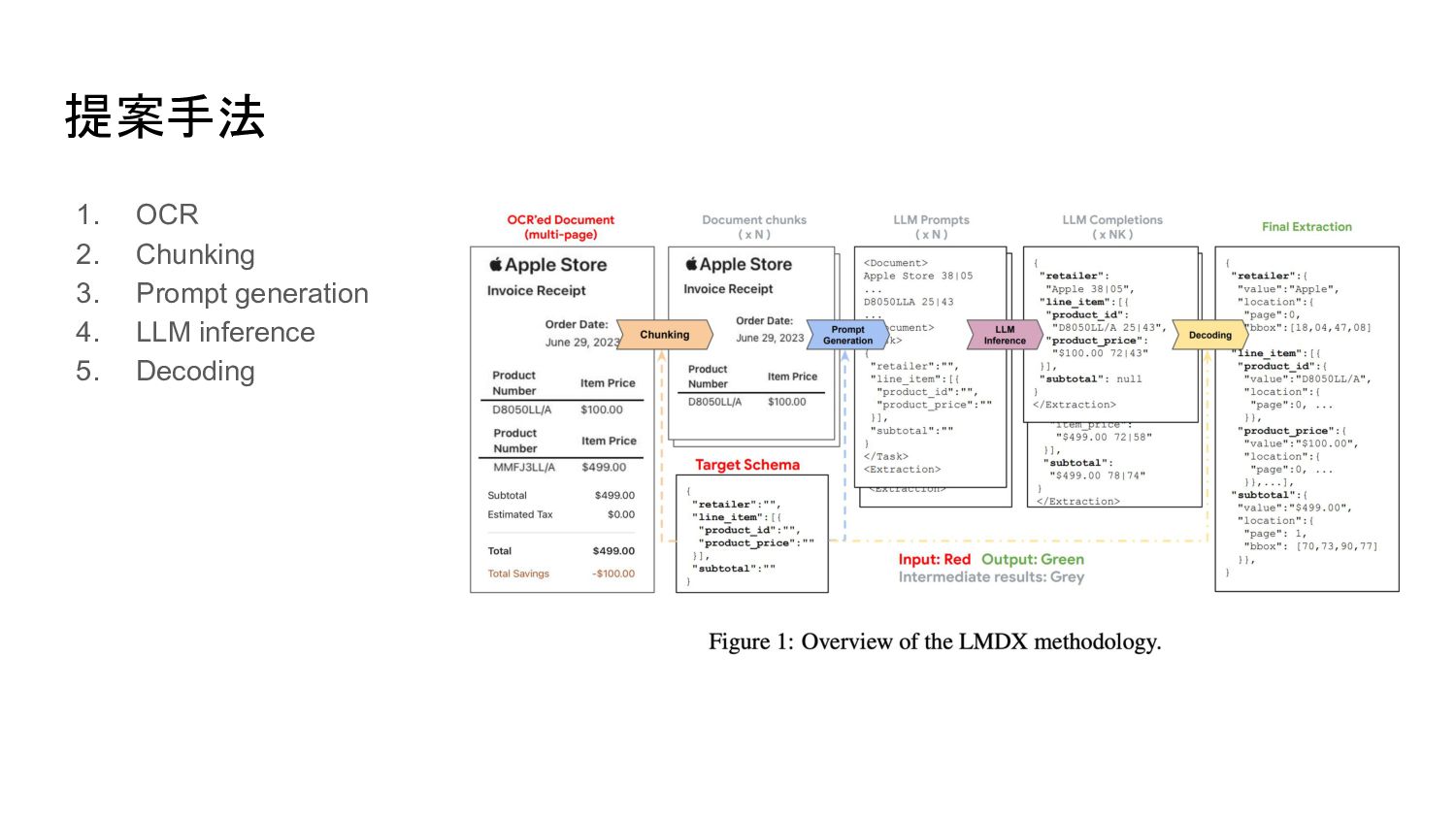
提案手法 1. OCR 2. Chunking 3. Prompt generation 4. LLM
inference 5. Decoding
1. OCR • 既存のOCRサービスを使用して画 像中のテキストと位置情報を取得 する
2. Chunking • 文章は任意の長さを受け付ける必要があるが、LLMには入力長の限 界があるため以下のアルゴリズムでChunkingする ◦ ページごとに分割し、文書チャンクを作成 ◦ プロンプトを含めた文書チャンクがトークン入力長収まるように最後から削る ◦
削られたチャンクを新しい文書チャンクとみなして入力長に収まるように同様の処 理を繰り返す
3. Prompt Generation • ChunkingされたN個の文書チャンクに対してプロンプトを作る • 以下の方法が含まれる ◦ ドキュメント情報、タスク説明、スキーマ •
ドキュメントの表現方法 ◦ 「<セグメント内のテキスト情報> XX|YY」という形式でテキ ストセグメントをすべて結合 ◦ 座標情報を正規化してB個のバケットに量子化され、index 番号として表現 ◦ ここはいろいろなバリエーションが考えられる ▪ セグメント・ビニングの粒度、座標の表現数 ◦ 論文の設定は行単位セグメント、B=100、2つのセンター座 標
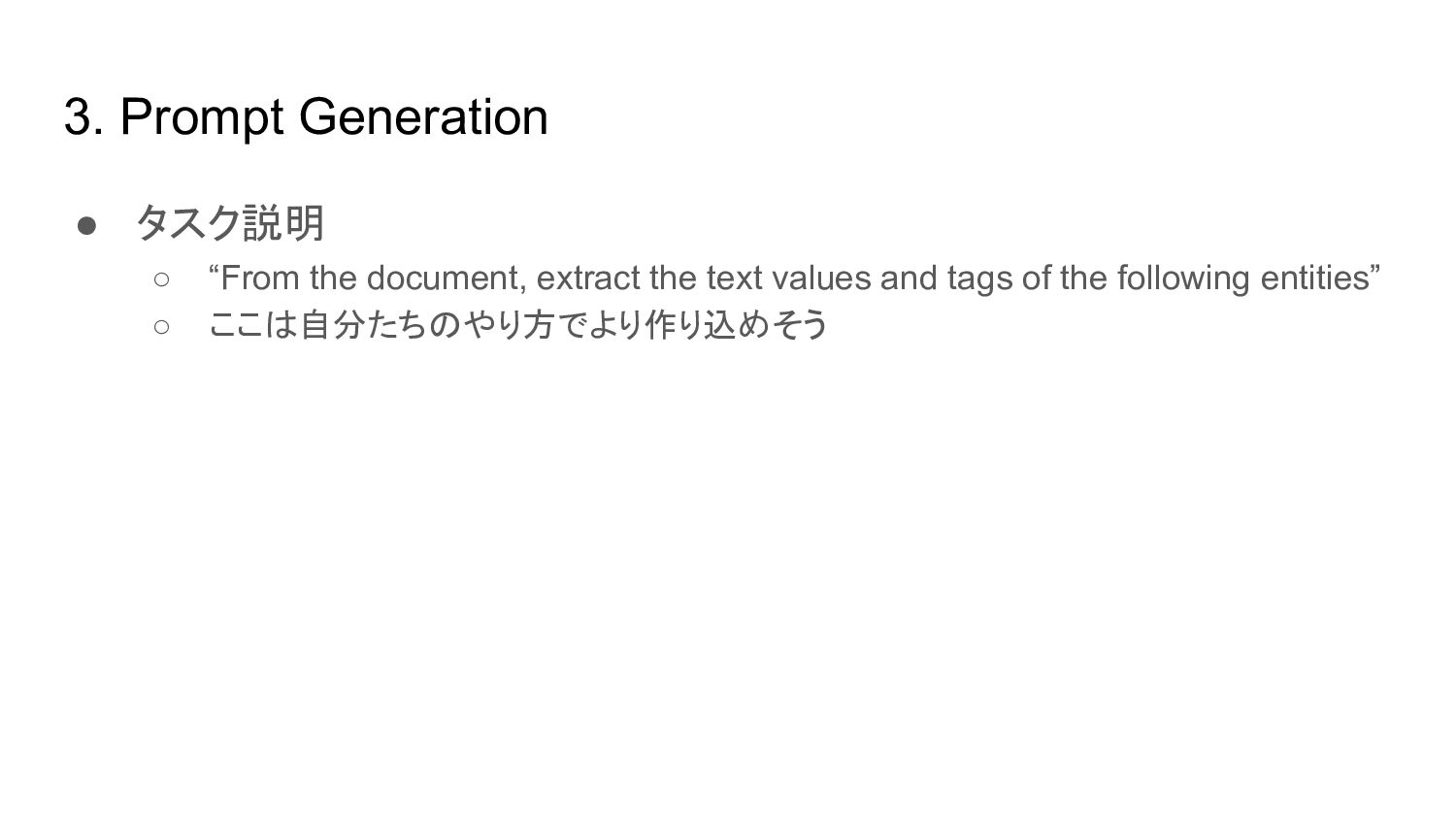
3. Prompt Generation • タスク説明 ◦ “From the document, extract
the text values and tags of the following entities” ◦ ここは自分たちのやり方でより作り込めそう
3. Prompt Generation • 抽出対象のスキーマ ◦ json形式で表現 ▪ key: 抽出したいエンティティの種類
▪ value: 形式(型) ◦ 例:{"foo": "", "bar": [{"baz": []}]}
4. LLM inference • json形式で出力 • entityはプロンプトのドキュメント情報と同じ形式で出力させる ◦ 座標情報を含む。これを使用して文書中のどこから抽出したかを判定 ◦
< text on segment1 > XX|YYsegment1\n < text on segment2 > XX|Y Ysegment2\n … ▪ fine tuningしない場合、こんなにうまく出力してくれるのか謎 ◦ 見つけられなかったエンティティは null or [] で表現 ◦ チャンクごとのN個のプロンプトそれぞれに対してK回推論を行い、最終的な出力を 決定する ▪ 後述するがこれはそんなに必要ないかも
5. Decoding • スキーマに指定していないのに抽出された entityは破棄 • 単一の値を抽出するように指定したのに複数の値が抽出されていた場合、最も出現頻度 の高いものを採用 • LLMの生出力を最終的に欲しい
entityと座標に変換する • 座標情報をもとに文書中の該当するテキストセグメントを特定、抽出されたテキストが正確 に元のテキストと一致しているかどうかを検証 ◦ ハルシネーション防止 • 抽出したentityに含まれるすべての単語セグメントを包含する最小の bboxを計算し、entity のbboxを計算 • 同文書チャンクのK個の出力をentity種ごとに多数決で決める • etc
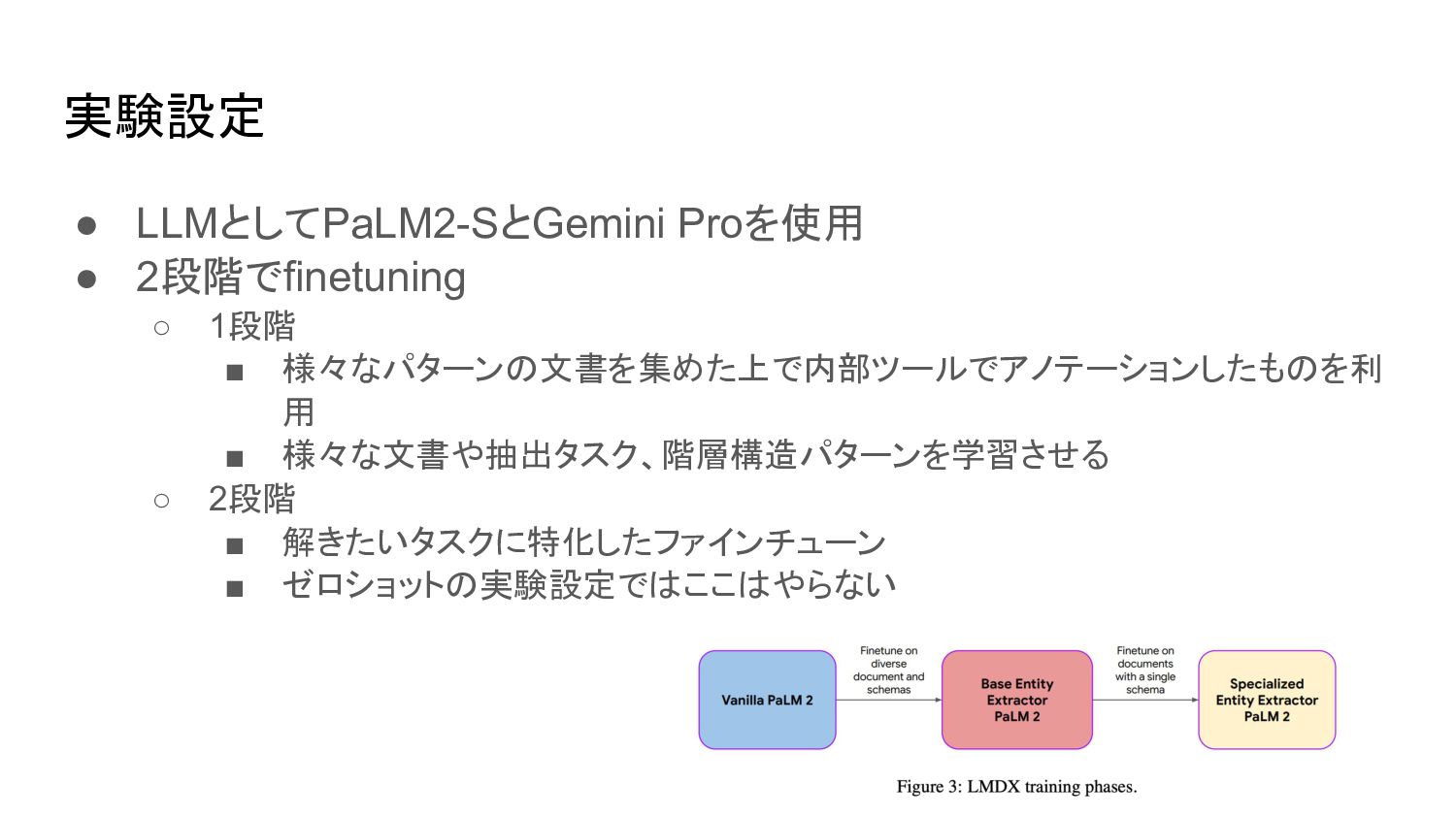
実験設定 • LLMとしてPaLM2-SとGemini Proを使用 • 2段階でfinetuning ◦ 1段階 ▪ 様々なパターンの文書を集めた上で内部ツールでアノテーションしたものを利
用 ▪ 様々な文書や抽出タスク、階層構造パターンを学習させる ◦ 2段階 ▪ 解きたいタスクに特化したファインチューン ▪ ゼロショットの実験設定ではここはやらない
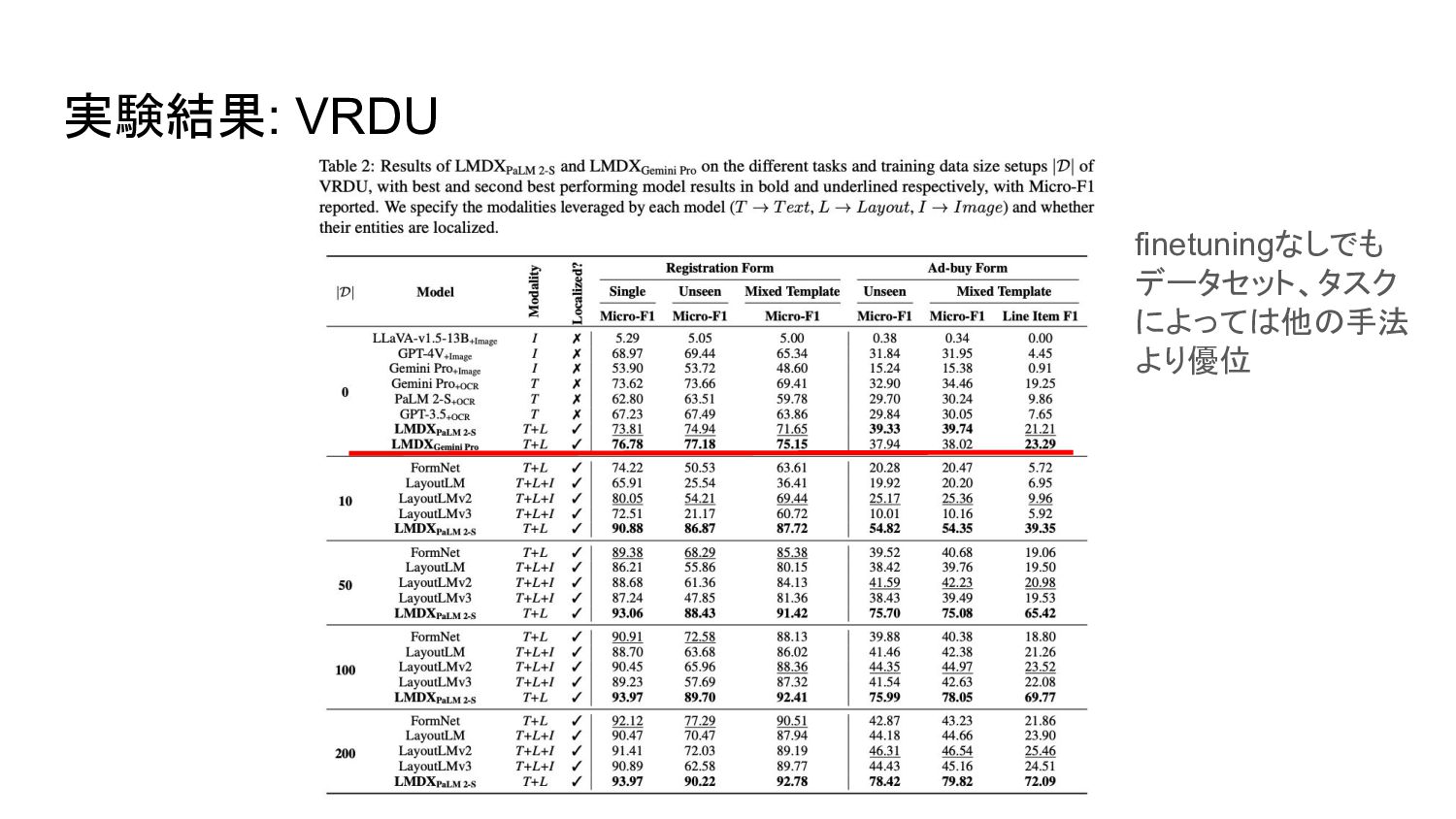
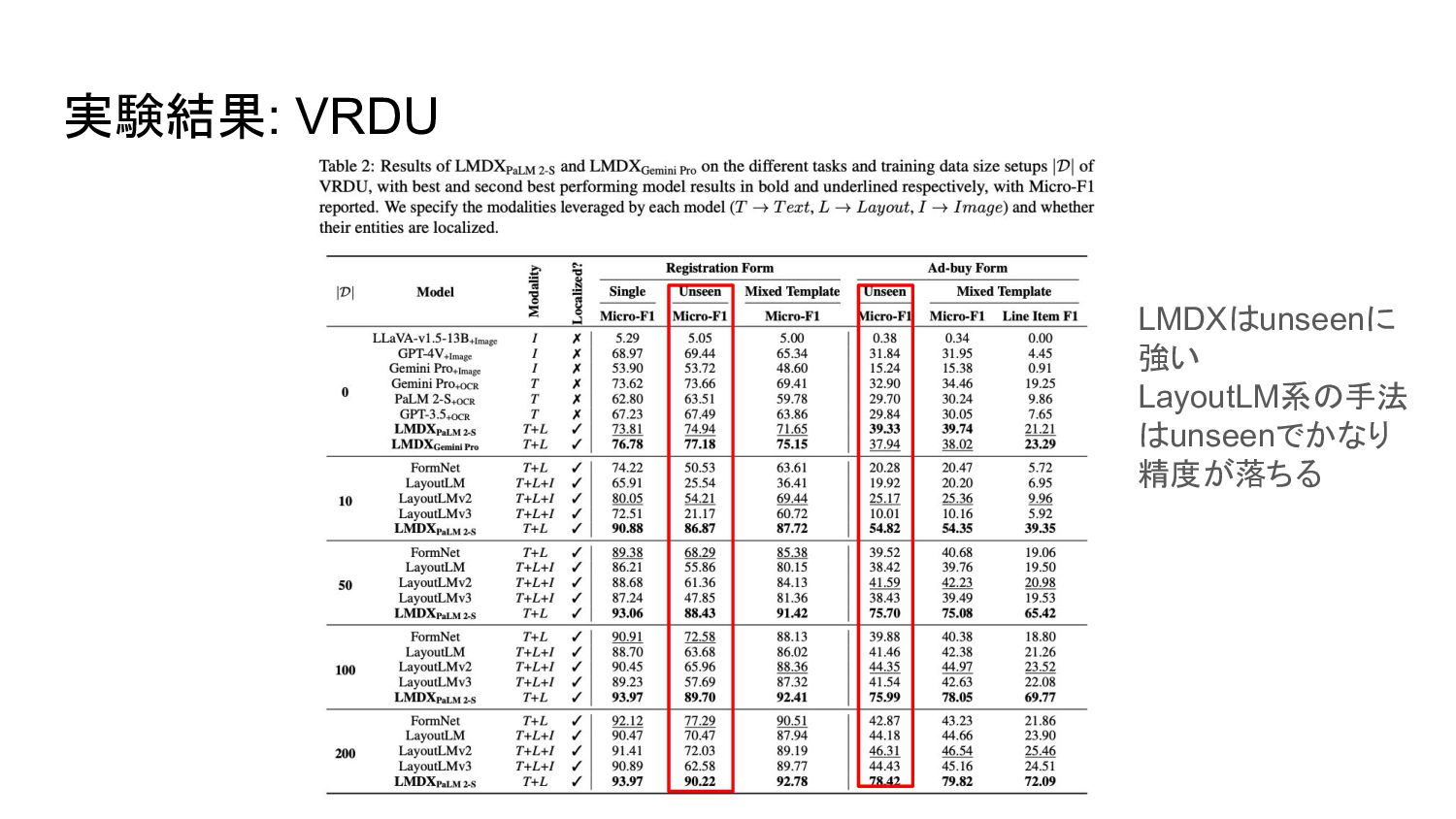
データセット • Visually Rich Document Understanding (VRDU) ◦ registration form
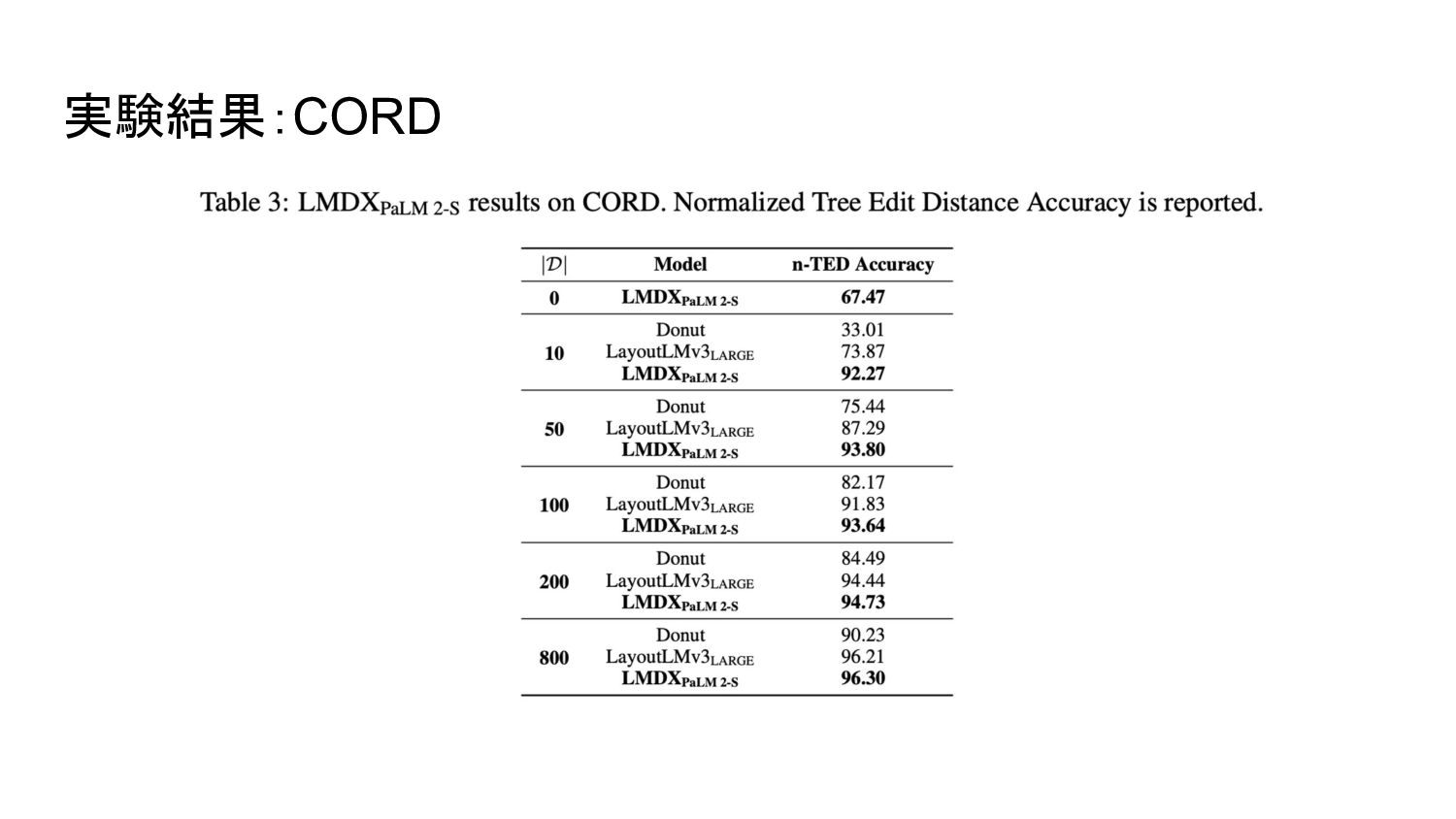
◦ ad-buy form • Consolidated Receipt Dataset (CORD) ◦ インドネシアの店舗の領収書データセット
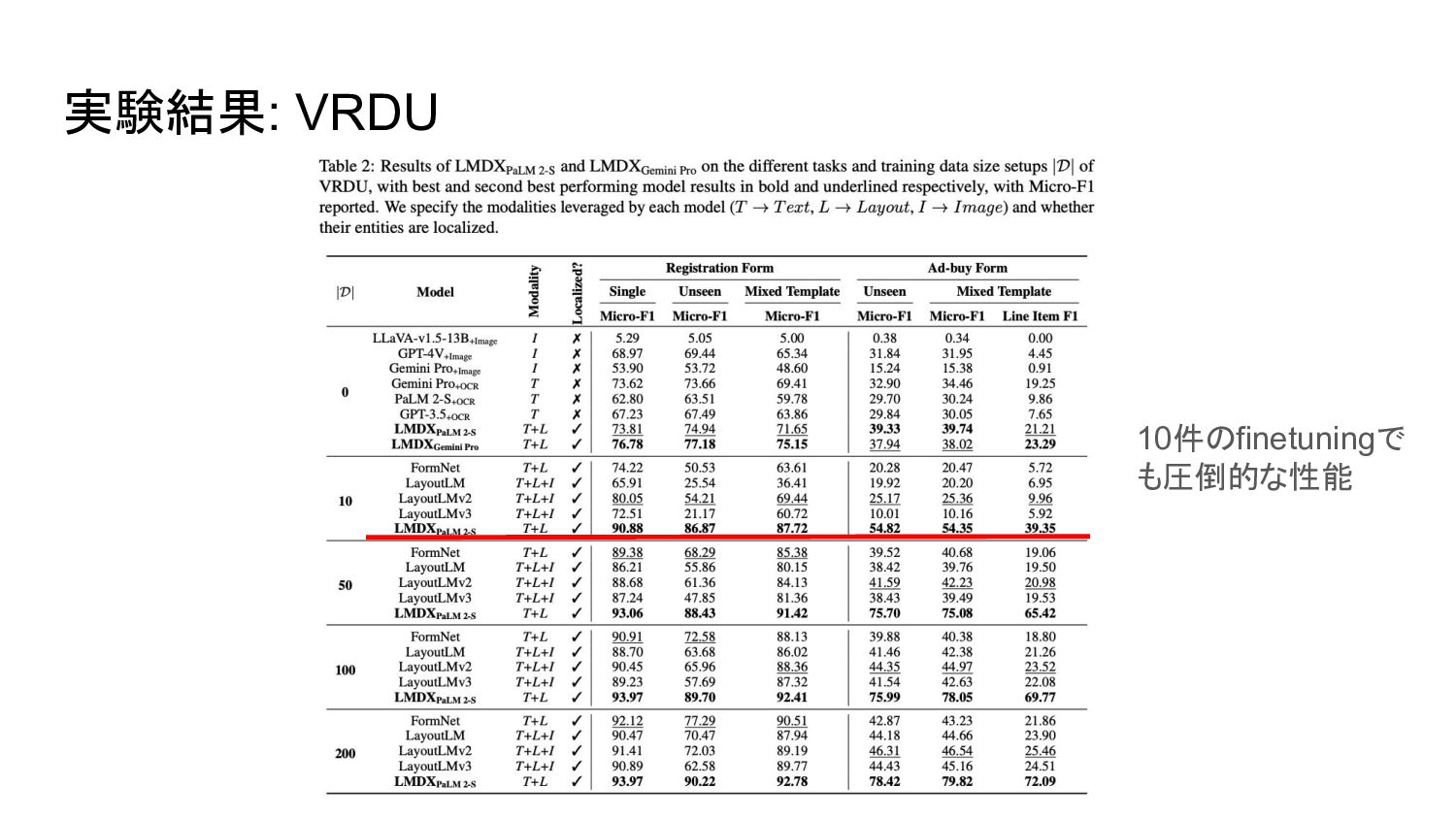
実験結果: VRDU 10件のfinetuningで も圧倒的な性能
実験結果: VRDU finetuningなしでも データセット、タスク によっては他の手法 より優位
実験結果: VRDU LMDXはunseenに 強い LayoutLM系の手法 はunseenでかなり 精度が落ちる
実験結果:CORD
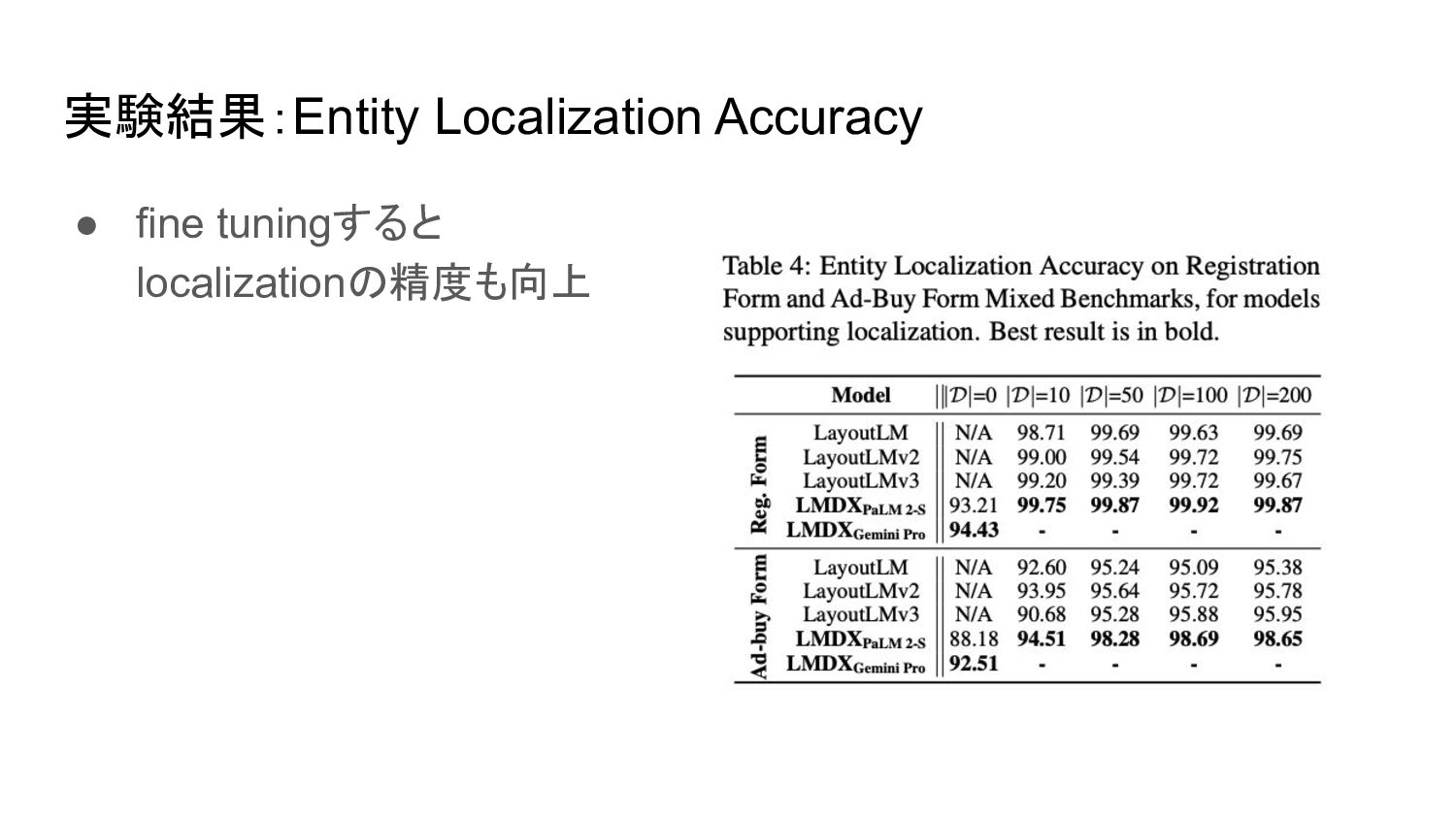
実験結果:Entity Localization Accuracy • fine tuningすると localizationの精度も向上
Ablation Study • 第一段階のfinetuningをしないと精度が かなり落ちる • 座標のエンコードも重要 • 同じ文書チャンクをK回投げるのはそこま で精度に影響ない
• 見つけられなかったエンティティは null or [] でしない場合も性能劣化 ◦ 面白い
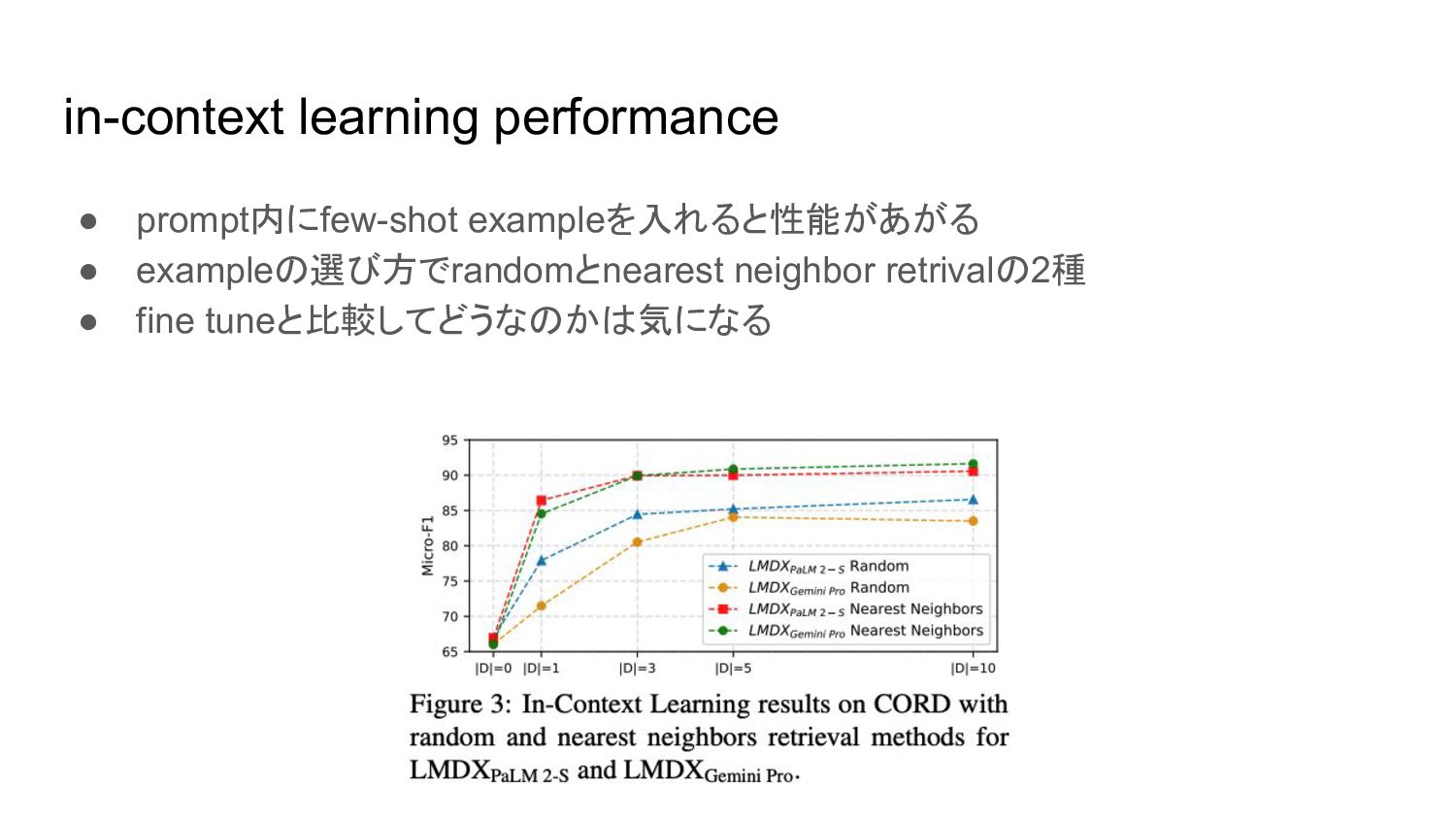
in-context learning performance • prompt内にfew-shot exampleを入れると性能があがる • exampleの選び方でrandomとnearest neighbor retrivalの2種
• fine tuneと比較してどうなのかは気になる
Error Analysis • 上の例は意味のことなるセグメントが 同じセグメントになってしまうことで起 きる ◦ あるあるなやつ • 下は付近に同じようなentityがある場
合に間違えている ◦ 位置情報のエンコーディングの方法限 界?
所感 • アルゴリズムやプロンプトの詳細が書いてあって参考になる ◦ 特に座標のエンコーディングあたり • 手元のデータでfinetuningなしでどれくらい性能でるか試してみたい • エラー分析の例はあるあるだなと思った •
今後もこの分野はLLMベースの手法がメインになっていくのだろうか?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}