◦ インプットデータの品質問題 (例: ECサイト、出会い系コミュニティサイト ) • bot開発: 前処理が本番 - 無価値な単語をどうやって弾くか ? ◦ 例 - 名詞,固有名詞: EV(電気自動車),新型コロナウイルス ,12月5日,37ドル ◦ 人間にとっての「有意味な単語」と計算結果での「特徴語」は一致しない ◦ 辞書の品質維持 • アーキテクチャ: 軽量なモジュール単位実装 + 疎結合 ◦ 軽量に作る: 素pythonスクリプト、flaskでの簡易実装優先 (大きいFW/ORM使わない) ◦ 小さいAPIをタスクキューで繋げる : モノリシックを避ける + 並列実行リソースの最適化 ◦ プログラミングの学習としては微妙 (Leetcode等の方が良い)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
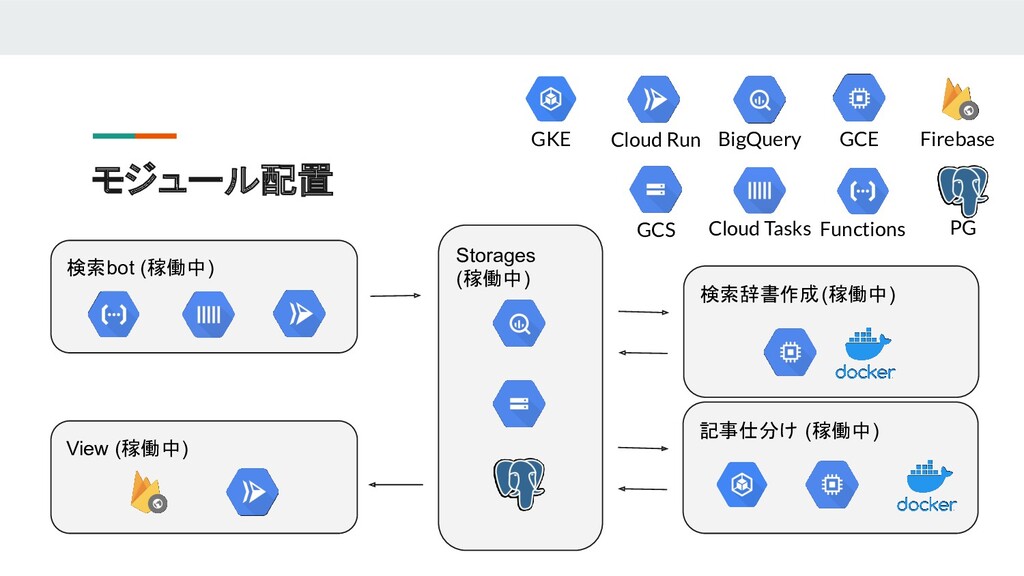{kind=link}
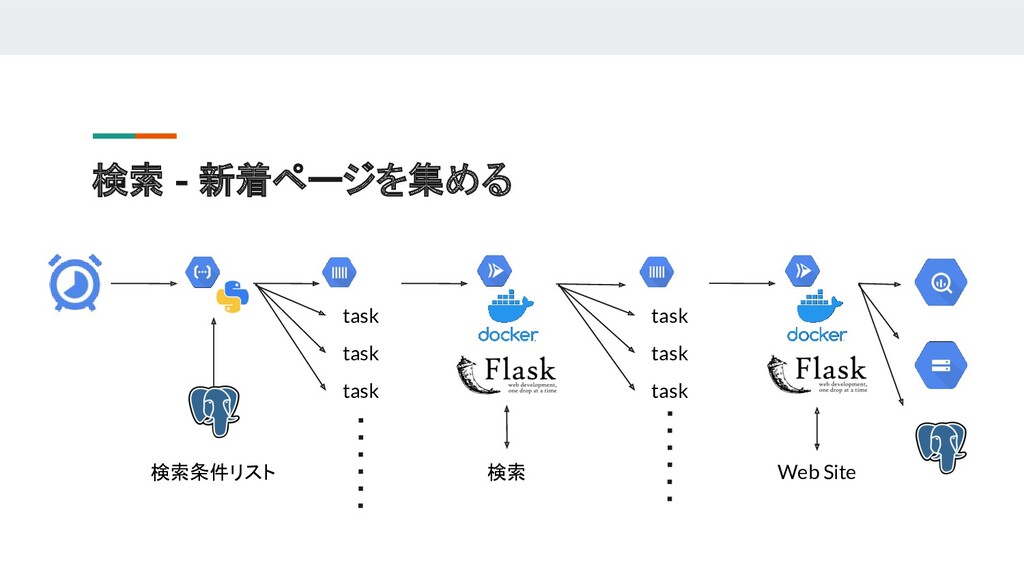{kind=link}
{kind=link}
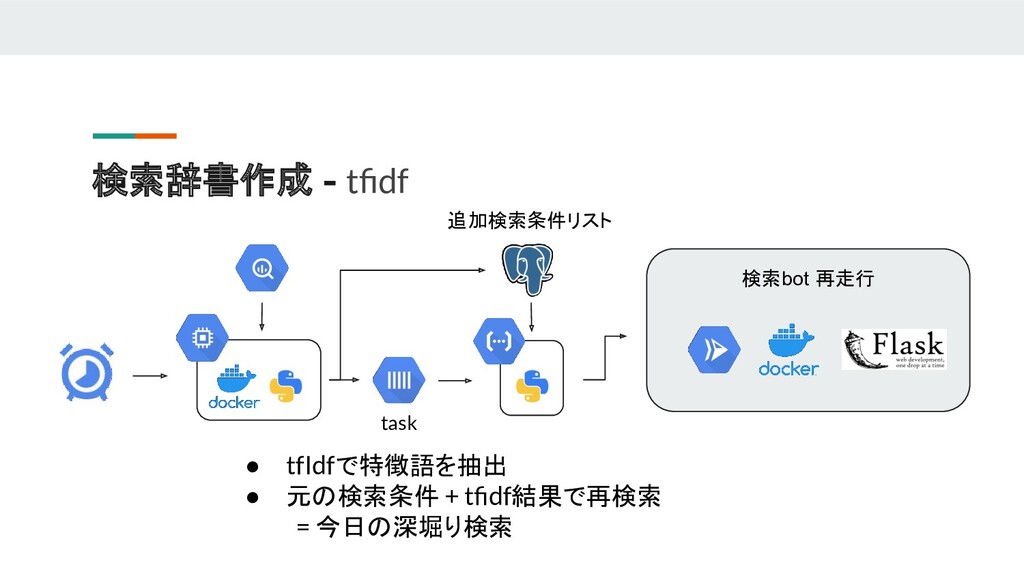{kind=link}
{kind=link}
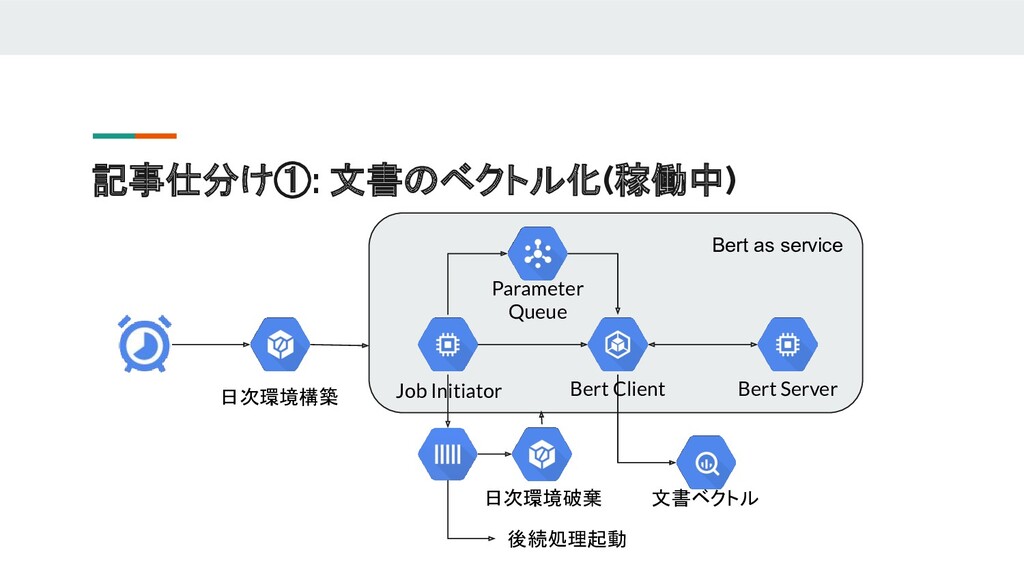{kind=link}
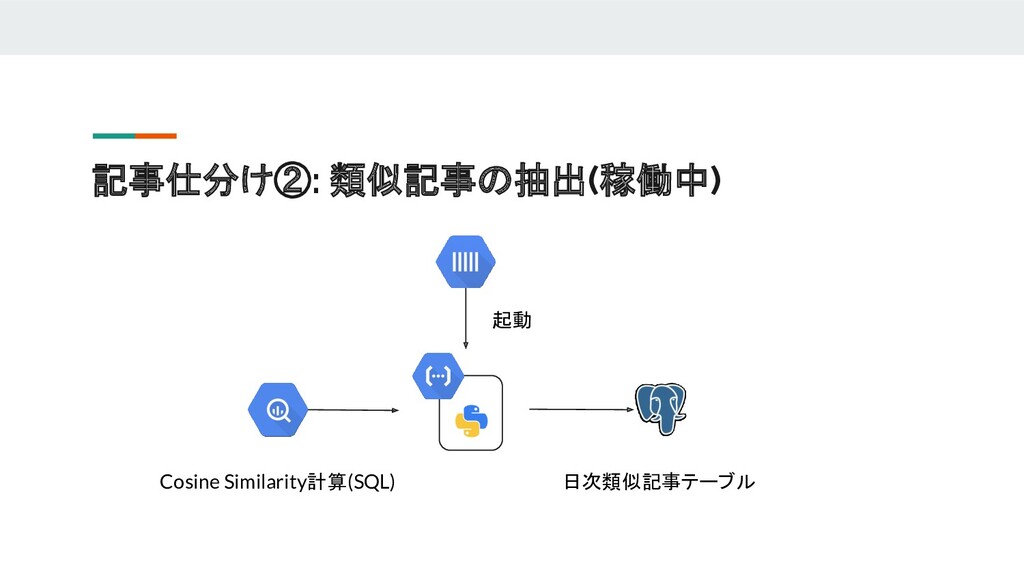{kind=link}
{kind=link}
{kind=link}
{kind=link}