Sesi ini akan membahas Sentimen Analisis sebagai bagian dari Natural Language Processing (NLP), mulai dari konsep dasar hingga implementasi praktis. Peserta akan diperkenalkan pada teknik NLP yang digunakan untuk memahami dan mengolah teks, termasuk tokenisasi, stemming, dan word embeddings. Selanjutnya, akan dijelaskan pendekatan pemodelan menggunakan Machine Learning tradisional seperti Naïve Bayes dan SVM, serta eksplorasi model Deep Learning seperti LSTM dan Transformer untuk meningkatkan akurasi analisis sentimen. Melalui sesi ini, peserta akan memperoleh pemahaman tentang bagaimana membangun pipeline Sentimen Analisis yang efektif dan aplikatif di berbagai industri.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
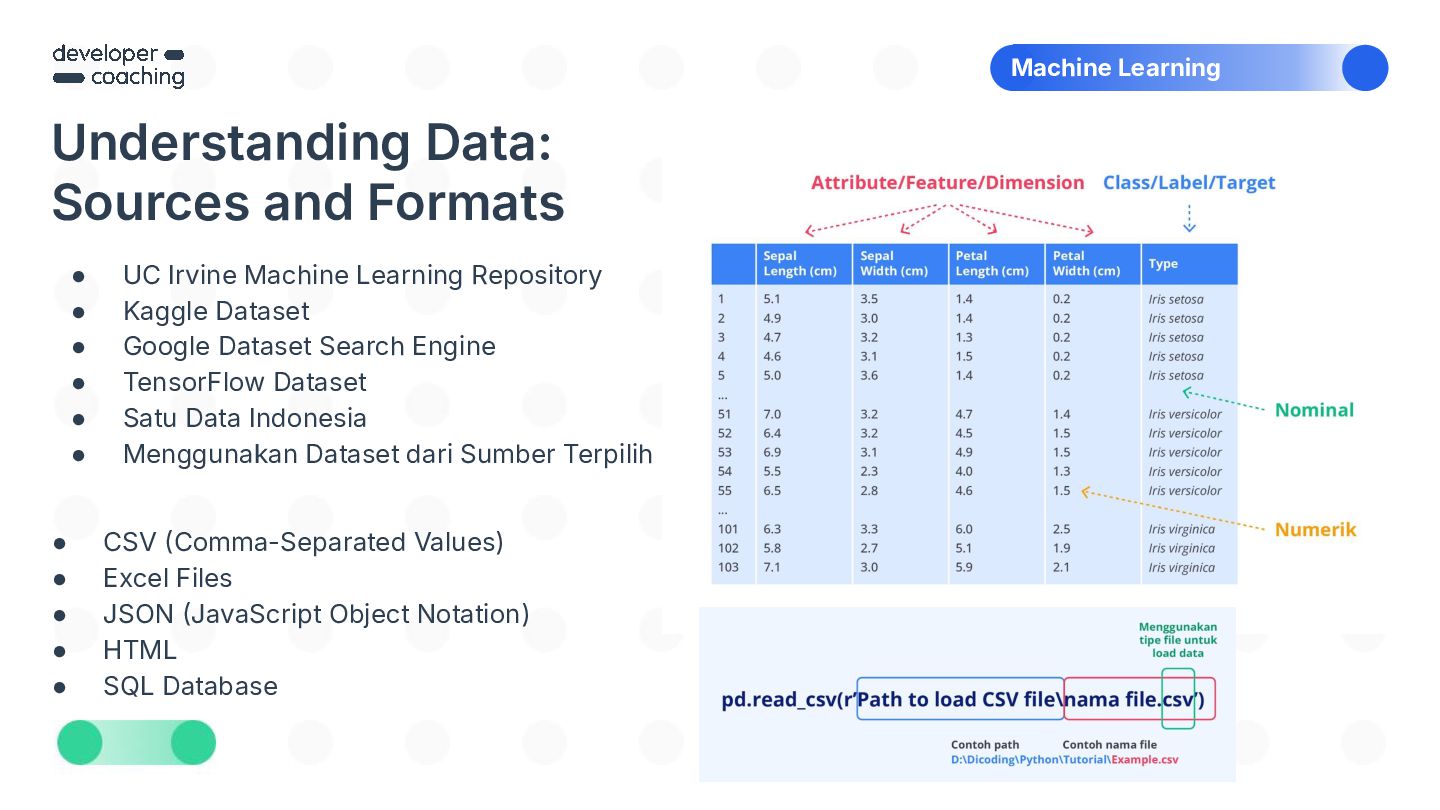{kind=link}
{kind=link}
{kind=link}
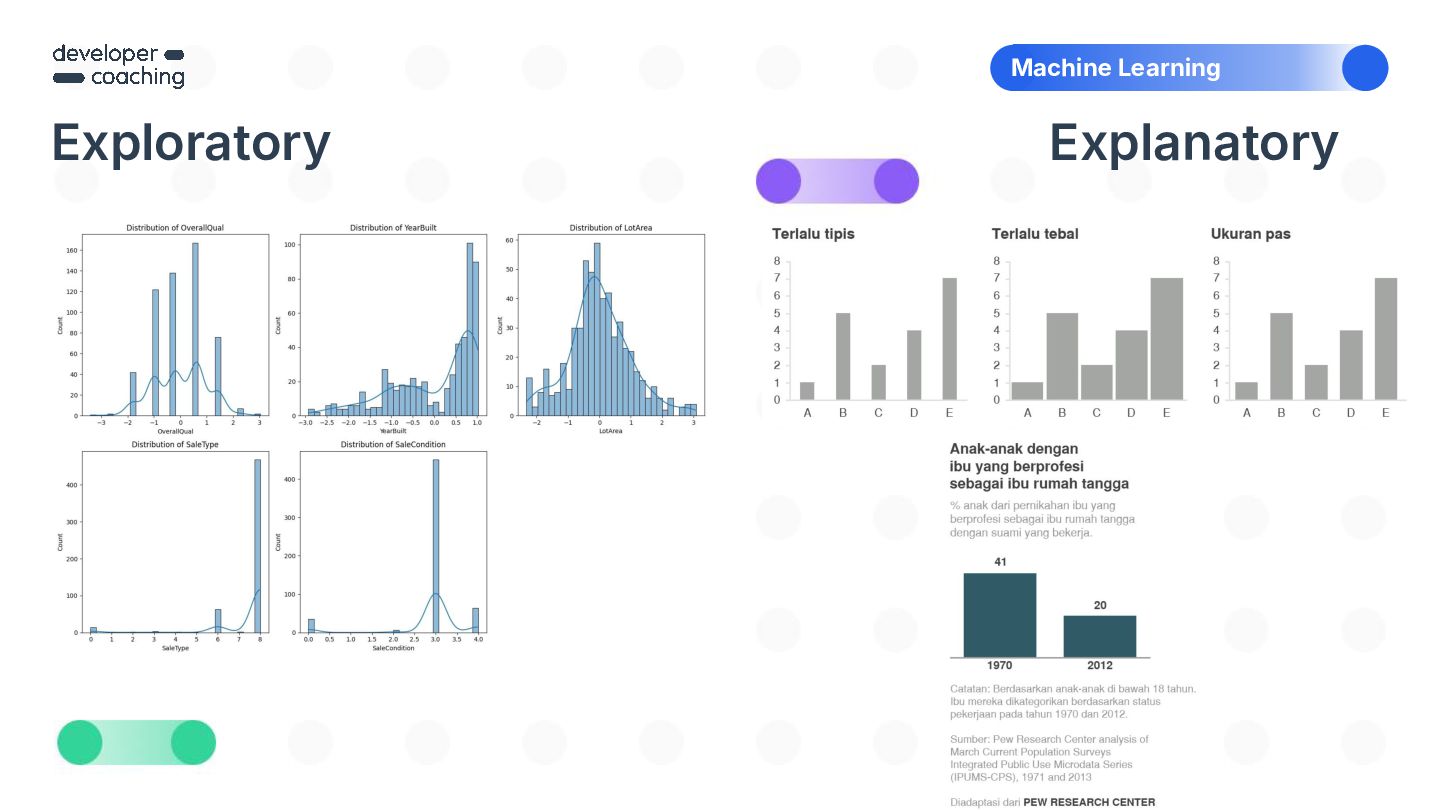{kind=link}
{kind=link}
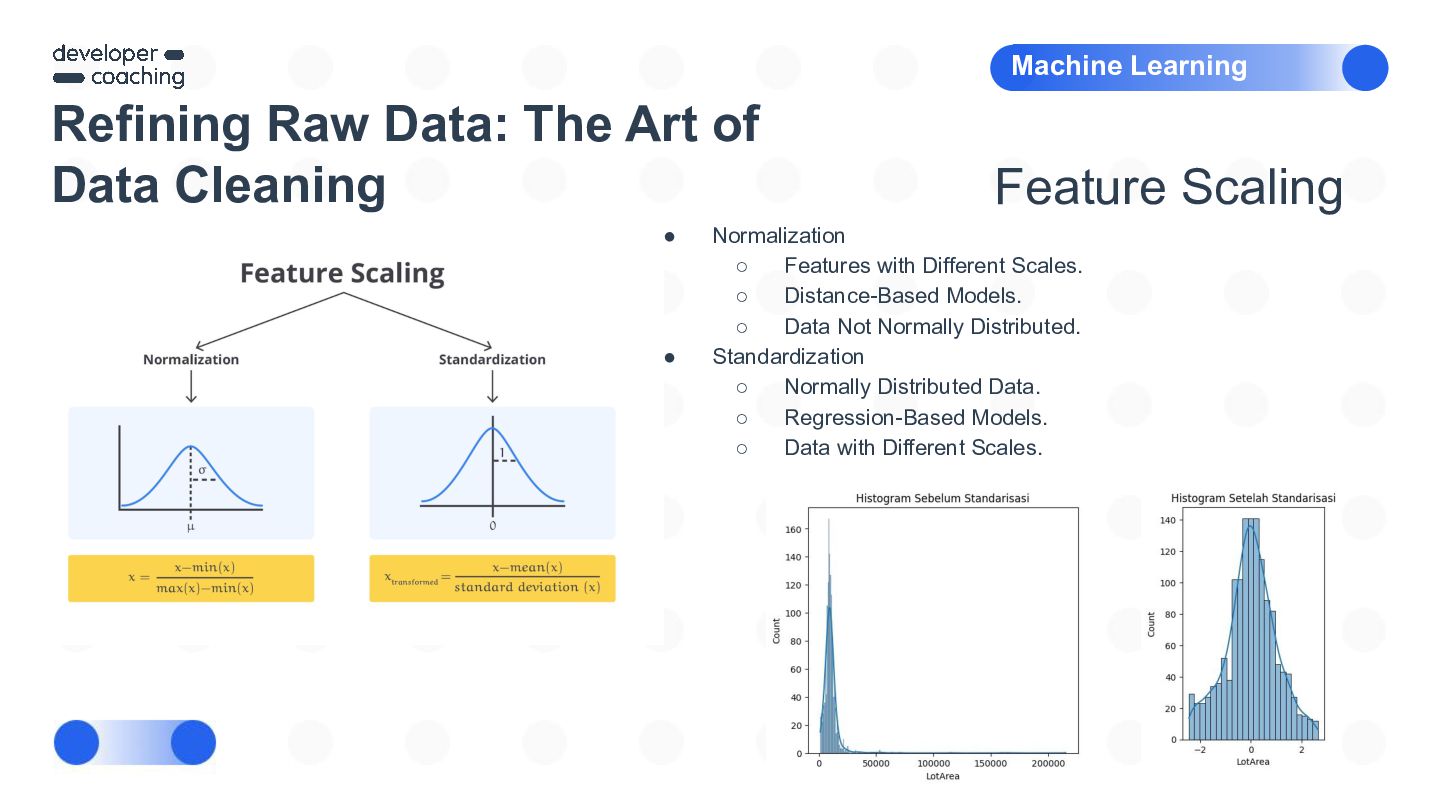{kind=link}
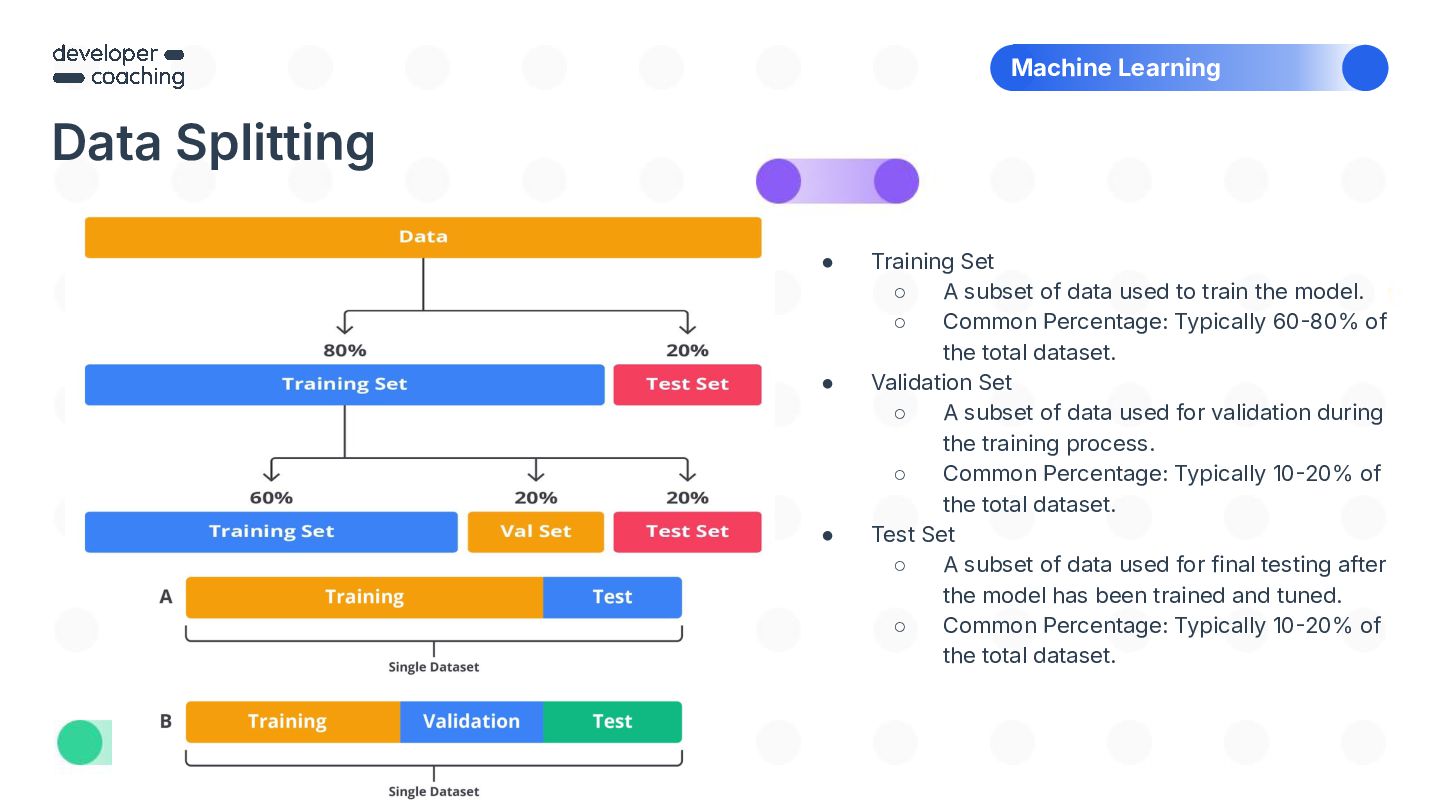{kind=link}
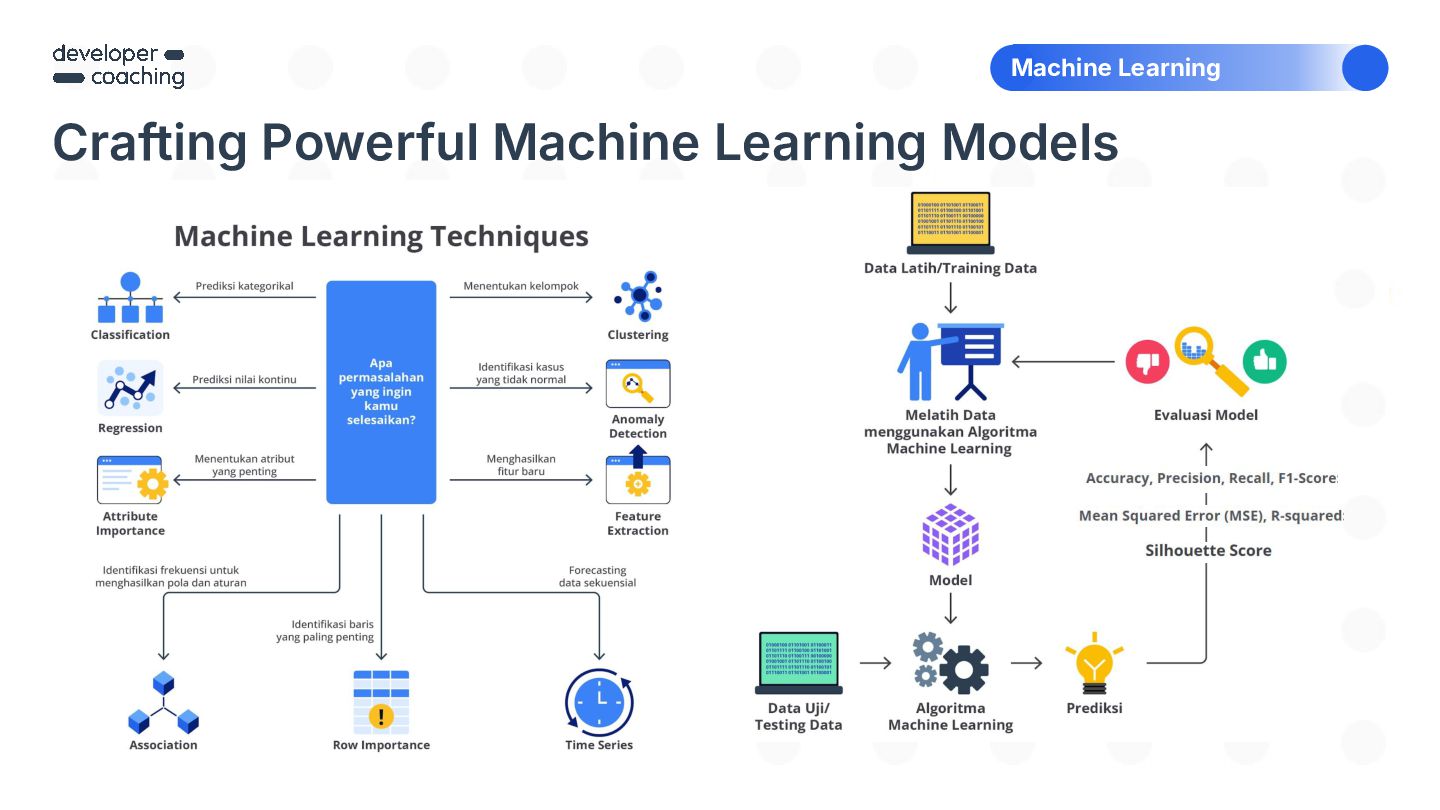{kind=link}
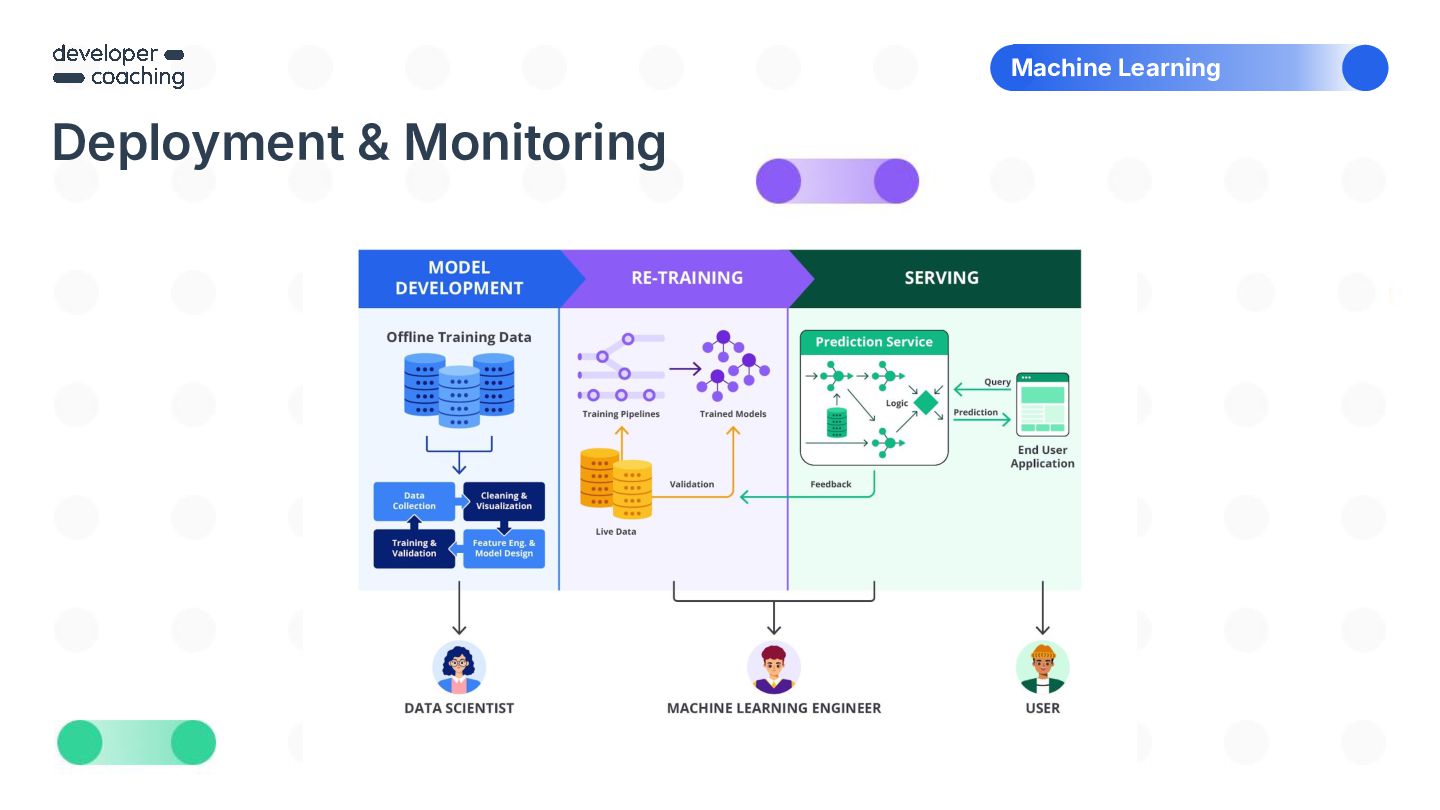{kind=link}
{kind=link}
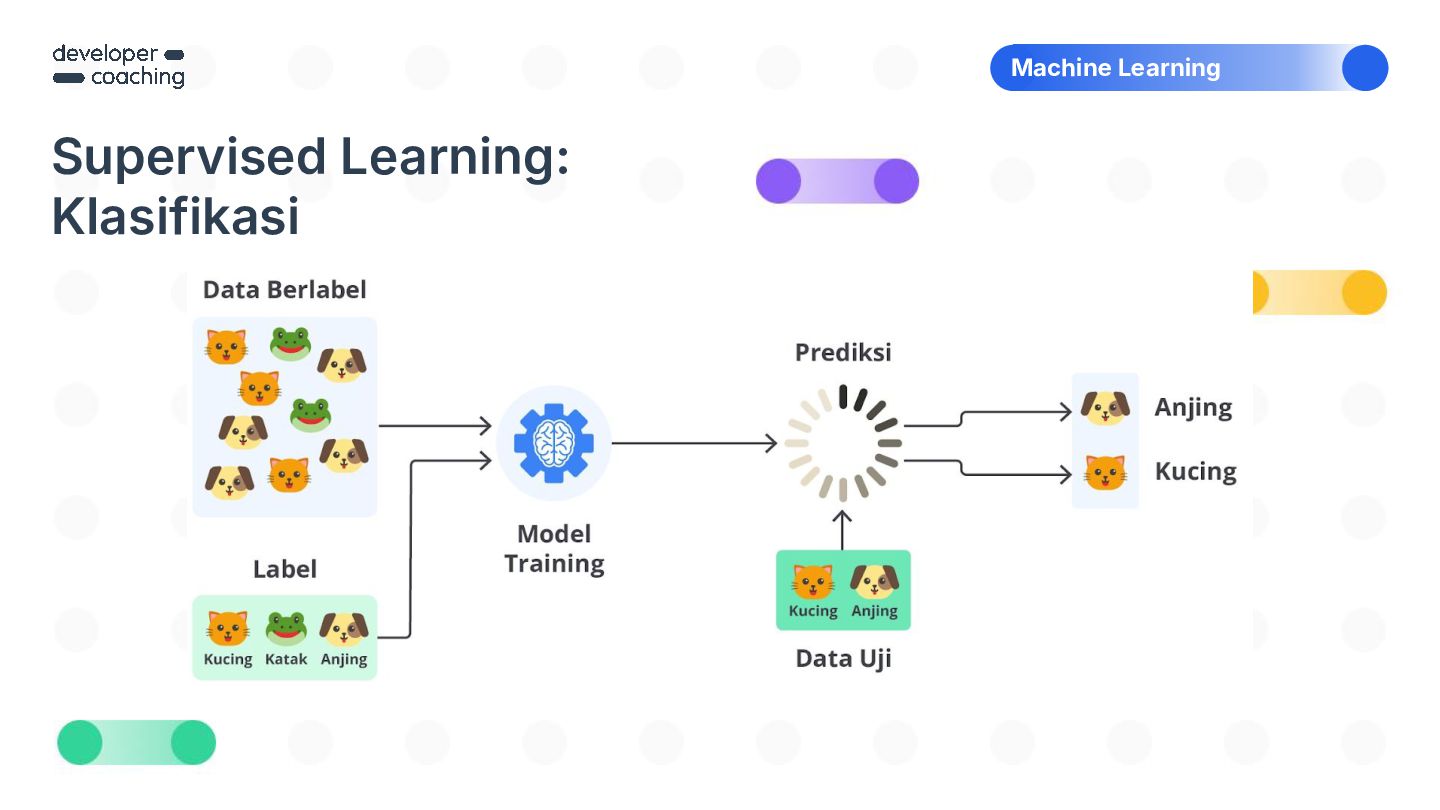{kind=link}
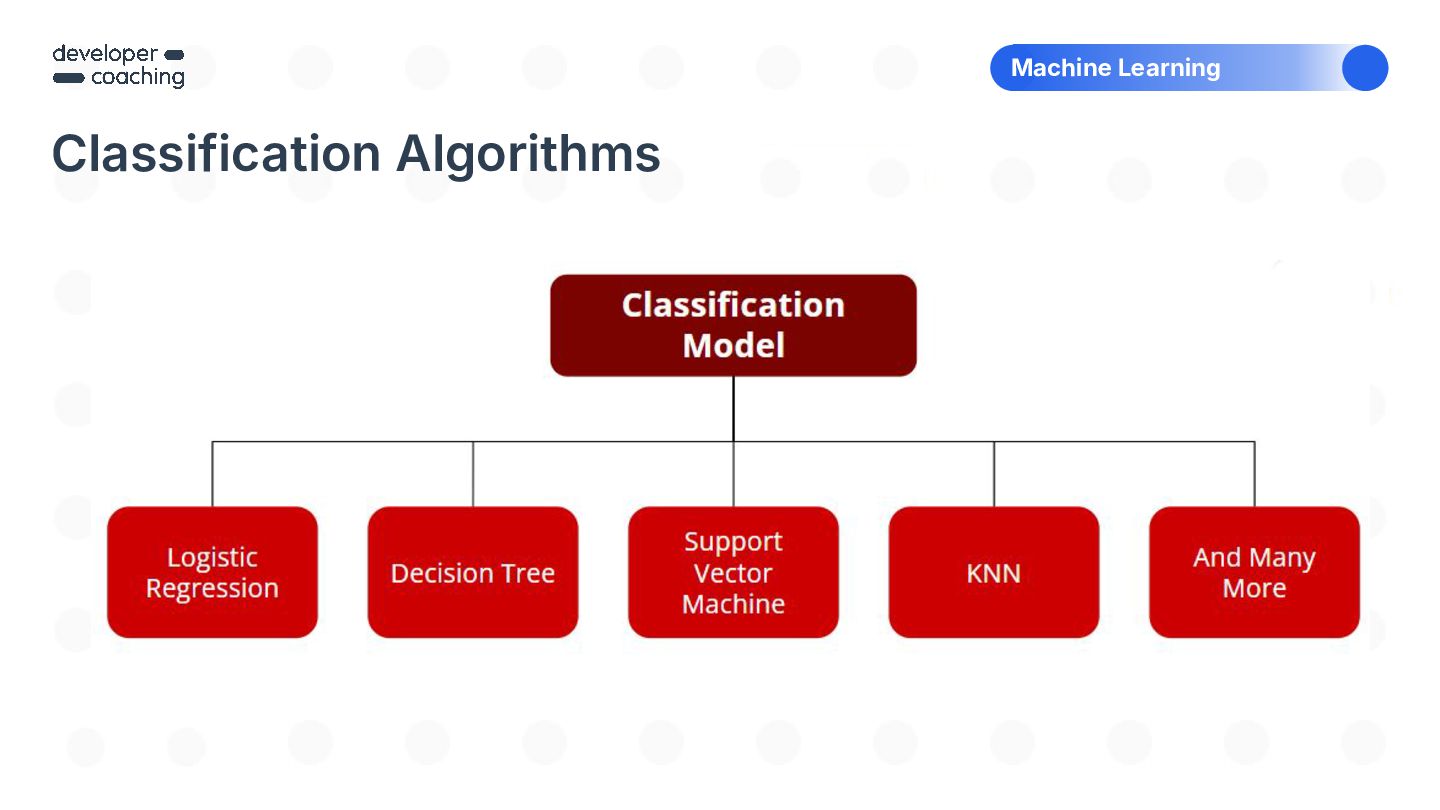{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}