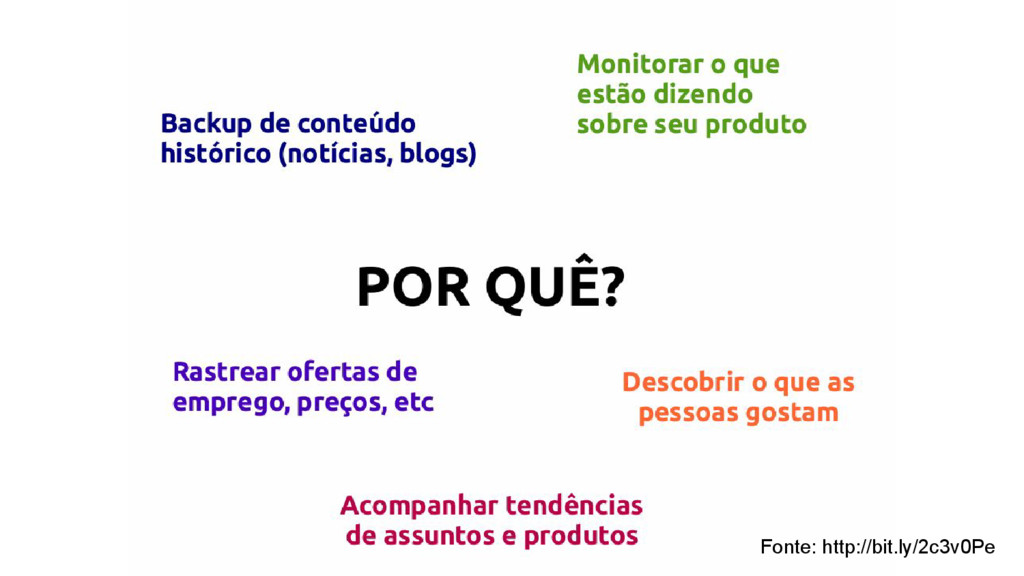
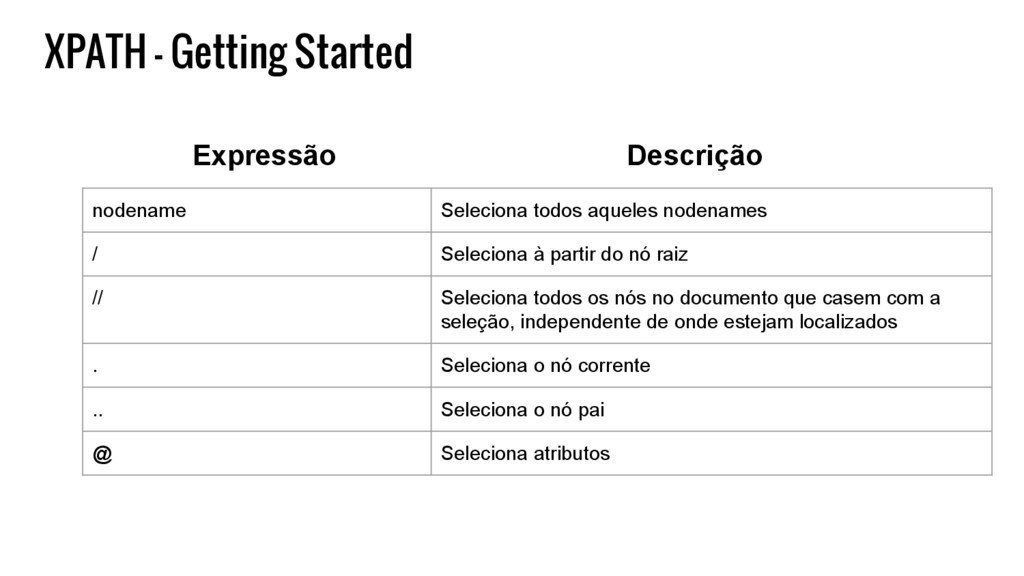
filho do elemento bookstore /bookstore/book[last()] Seleciona o último elemento book filho do elemento bookstore /bookstore/book[position()<3] Seleciona os 2 primeiros elementos “book” filho do elemento bookstore //title[@lang] Seleciona qualquer elemento title que possui atributo lang //title[@lang='en'] Seleciona qualquer elemento title que possui atributo “lang” com valor “en” /bookstore/book[price>35.00] Seleciona todos os elementos book com atributo price com valor maior a 35 Expressão Descrição
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![XPATH - Getting Started /bookstore/book[1] Seleciona o primeiro elemento book](https://files.speakerdeck.com/presentations/7cd053fc83354aa2b4d6693bd48b18d1/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}